大模型应用开发之评估
一、评估指标
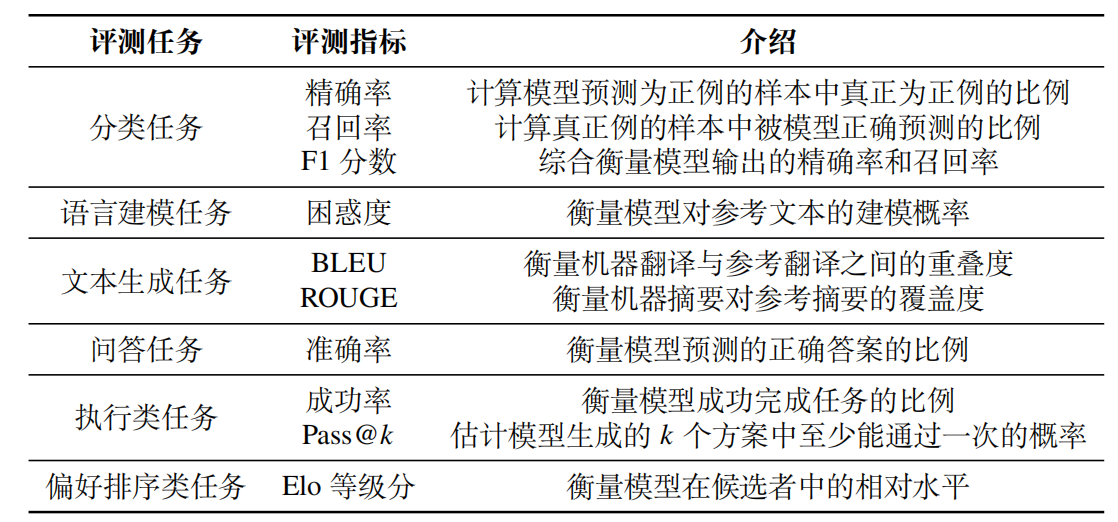
1、分类任务评估指标
分类任务 (Classification)要求模型将输入划分到预定义的类别中,例如判断邮件是“垃圾邮件”还是“正常邮件”,或者判断文本情感是“积极”还是“消极”。
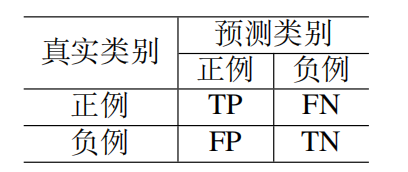
以基础的二分类任务为例,如下混淆矩阵,真正例(True Positive, TP)表示预测类别为正的正样本、假正例(False Positive, FP)表示预测类别为正的负样本、真负例(True Negative, TN)表示预测类别为负的负样本、假负(FalseNegative, FN)表示预测类别为负的正样本。
在此基础上,分类任务通常采用精确率(Precision)、召回率(Recall)、F1 分数(F1 Score)等评测指标来评估模型的分类结果。
1)精确率:Precision=TP/(TP + FP),表示模型预测为正例的样本中真正为正例的比例
2)召回率:Recall = TP /(TP + FN),表示所有真正为正例的样本中被模型正确预测出来的比例
3)F1分数:F1 = 2 × Precision × Recall / Precision + Recall,F1 分数是精确率和召回率的调和平均数,衡量模型在分类任务上的综合性能
2、语言建模评估指标
语言模型最直接的测评方法就是使用模型计算测试集的概率,或者利用交叉熵(Cross-entropy) 和困惑度(Perplexity)等派生测度
1)测试集概率:对于一个测试集(比如一组句子),模型会为每个句子计算它的概率。如果模型给测试集中的句子分配了较高的概率,说明它很好地捕捉了语言的规律,预测能力强。反之,如果概率很低,说明模型没有学到正确的语言模式,可能需要改进
2)交叉熵:交叉熵衡量的是“模型预测的概率分布”和“真实概率分布”之间的差异。交叉熵就像一个“失望指数”。想象你在考试中预测答案(模型的概率分布),而真实答案(测试集)已经确定。如果你的预测和真实答案很接近(概率高),你会很开心,失望指数低(交叉熵低)
3)困惑度:困惑度表示模型在预测下一个单词时“有多少个选择”。困惑度越低,说明模型越“确定”下一个单词是什么,预测能力越强。困惑度就像你在玩一个猜词游戏时的“纠结程度”。如果困惑度是 1,你完全知道下一个词是什么(比如“我喜欢”后面一定是“吃”),一点也不纠结。如果困惑度是 100,你完全不知道下一个词是什么,非常纠结。
3、文本生成评估指标
条件文本生成(Conditional Text Generation)任务是指模型根据给定的输入条件(如源语言句子、文档、问题等),生成符合要求的目标文本的任务。其应用领域覆盖了机器翻译、文本摘要和对话系统等众多场景。
1)BLEU(精确率导向)
核心思想:通过n-gram(文本中连续的 n 个词的组合)匹配来衡量生成文本与参考文本的相似程度,关注生成文本的"准确性",适用于机器翻译等有标准答案的任务,BLEU 的计算涉及以下几个关键步骤:
- n-gram 匹配
- 精度(Precision)计算
- 剪切(Clipping)
- 几何平均
- 长度惩罚
2) ROUGE(召回率导向)
核心思想:ROUGE 更关注召回率(Recall),即参考文本中的内容有多少被机器生成的文本覆盖特别适合摘要任务
-
ROUGE-n:基于 n-gram 的匹配,关注参考文本中的 n-gram 有多少出现在机器生成的文本中
-
ROUGE-L:基于最长公共子序列(LCS),即机器生成文本和参考文本之间的最长连续匹配序列,LCS 不要求词完全按顺序连续,只要是子序列即可。ROUGE-L 通常综合精度和召回率,计算 F1 分数
4、问答任务评估指标
问答任务旨在通过对于所提出问题的精准理解,预测出正确的答案。这种任务要求模型具备 文本理解、信息抽取、文本生成等一系列综合能力。问答任务主要通过衡量模型 给出的答案与真实答案之间的一致性来进行评估,因此通常使用准确率来评估模型的回答结果
二、评估方法
1、评估方法
1)基于测评基准
最常见的方法,就像给学生做标准化的“模拟考试卷”。我们会用一系列预先定义好的、包含标准答案的数据集(基准)来测试模型
2)基于人工评估
有些能力(比如创造性、对话的自然度、有用性)很难用标准答案来衡量,这时候就需要请“人类考官”来打分和评价
2)基于LLM评估
让一个更强大或者专门训练过的“AI考官”来评估另一个模型的表现
2、基础大语言模型评估
模型只经过了预训练,还没有进行任何针对特定任务的微调或对齐。它们就像是刚学完基础课本,还没做过模拟题的“裸考生”。所以主要关注它们通过预训练获得的世界知识和通用语言能力,以及一些涌现出的复杂推理、知识利用等能力。常利用评测基准进行评估。
1)典型评测基准
-
MMLU (Massive Multitask Language Understanding): 考察模型在大量不同学科(从人文到理工)知识的理解和应用能力,通常是选择题形式。
-
BIG-Bench (Beyond the Imitation Game Benchmark): 包含大量极具挑战性的、超越简单模仿的任务。
-
HELM (Holistic Evaluation of Language Models): 一个更全面的评估框架,从多个维度(准确性、鲁棒性、公平性、效率等)对模型进行评估。
-
C-Eval: 专注于评估中文大模型的知识和推理能力。
-
GSM8K, BBH, MATH: 这些数据集更侧重于评估模型的数学推理和解决复杂问题的能力。
-
OpenCompass: 一个综合性的评测平台,试图整合多种评测基准。
2)评测流程
-
将评测任务的样本转换成模型可以理解的提示(Prompt)。
-
引导模型生成相应的答案文本。
-
用人工编写的规则或自动化脚本,对模型的输出进行解析和处理,提取出关键答案。
-
将提取的答案与标准答案进行对比,计算准确率等指标。
3)评估方式
-
少样本 (Few-shot): 在提示中给模型看几个例子,测试其快速适应新任务的能力。
-
零样本 (Zero-shot): 不给任何例子,直接测试模型在未见过任务上的泛化能力。
-
局限性: 基于评测基准的方法虽然客观,但有时难以全面评估模型的真实能力,并且容易受到“数据污染”(模型在训练时可能见过测试数据)的影响。
3、微调大语言模型评估
微调后的模型通常是针对特定指令或对齐目标进行优化的,所以对它们的评估会更侧重于其在目标应用场景中的表现。除了继续使用评测基准外,人类评估和模型评估扮演了更重要的角色。
1)基于人类评估
适用于当模型的输出质量难以用客观指标衡量时,比如对话流畅性、创造性、有用性、安全性等。
常见形式:
-
直接打分 (Direct Assessment): 让人类评估员直接给模型的输出打分(比如 1-10 分)。
-
成对比较 (Pairwise Comparison): 给出两个模型针对同一输入的回答,让人选哪个更好。这种方式更容易达成一致。
-
Chatbot Arena: 一个公开的平台,让用户与两个匿名的模型进行对话,然后投票选出哪个模型更好。通过大量的用户投票,可以对不同模型的对话能力进行排名(类似 Elo 评分)。
-
针对特定指标评估: 如 HELM 中,让人类评估员针对模型的诚实性和偏见进行打分。
2)基于模型评估
人类评估成本太高,能不能让一个更强大的 AI 来当“考官”呢?常见做法有:
-
用强模型作为裁判: 用一个非常强大的预训练模型(如 GPT-4)或者专门训练的评估模型,来对目标模型的输出进行打分或评价。
-
AlpacaEval, MT-Bench: 就是这类方法的典型代表。它们会给目标模型出一系列指令,然后让强模型(如 GPT-4)对目标模型的回答进行评估,并给出分数和理由。
缺点和挑战:
-
位置偏置 (Position Bias): 如果同时给出多个答案让模型评估,模型可能倾向于给排在特定位置(比如第一个)的答案打高分。
-
冗长偏置 (Verbosity Bias): 模型可能倾向于给更长的答案打高分,即使这些答案质量并不一定更好。
-
自增强偏置 (Self-enhancement Bias): 如果用模型自己来评估自己的输出(或者评估与自己相似的模型),它可能倾向于给自己打高分。
-
能力限制: “AI考官”本身的能力也会限制评估的准确性。如果任务过于复杂(如复杂数学推理),“AI考官”自己都做不好,怎么能准确评估别人呢?
三、大语言模型基础能力评估
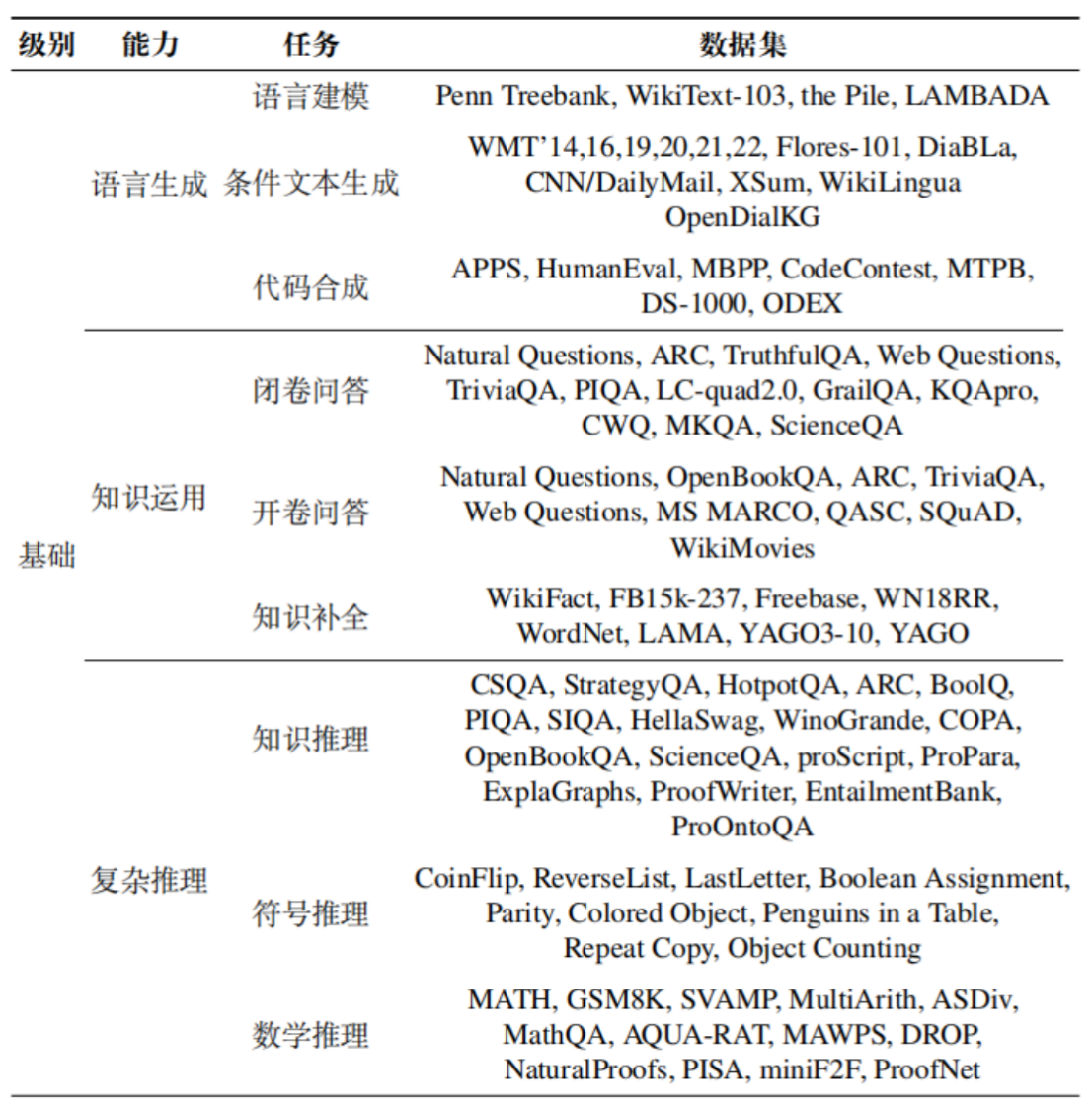
1、语言生成
语言生成是所有任务的基础,模型得先会“说话”,才能做别的事。我们把它细分成三个小方向:
1)语言建模
给模型一段话的前半部分,看它能不能准确地预测出接下来应该出现哪个词。这反映了模型对语言基本规律的掌握程度。
-
常用数据集:
-
Penn Treebank, WikiText-103: 经典的语言建模数据集。
-
LAMBADA: 专门考察模型预测长篇文章中最后一个词的能力。通常这个词需要理解很长的上下文才能猜对,所以它很考验模型的长程依赖建模能力。比如,故事讲了半天,最后问主角说了句啥,模型得理解整个故事才能答对。
-
The Pile: 一个非常巨大且多样化的数据集,也常用于评估语言建模。
-
-
关键指标: 困惑度 (Perplexity)。困惑度越低,说明模型对下一个词的预测越准,语言建模能力越强。
2)条件文本生成
给模型一个特定的输入或指令,看它能不能生成符合要求的文本。这包括很多实际应用场景如:
-
机器翻译 (Machine Translation): 把一种语言翻译成另一种语言。
-
“评分标准”: 常用 BLEU, ROUGE, METEOR, COMET 等自动评估指标,它们通过比较模型翻译和人工参考翻译的相似度来打分。也会辅以人工评估。
-
-
文本摘要 (Text Summarization): 把一篇长文章概括成简短的摘要。
-
生成式摘要 (Abstractive Summarization): 理解原文后,用自己的话重新组织语言生成摘要(大模型更擅长这个)。
-
抽取式摘要 (Extractive Summarization): 直接从原文挑选重要的句子组成摘要。
-
“评分标准”: 常用 ROUGE (ROUGE-1, ROUGE-2, ROUGE-L)。ROUGE 主要看模型生成的摘要和参考摘要之间词语重叠的程度。
-
XSum 数据集: 常用的摘要评测数据集,特点是摘要非常精炼,要求高度概括。
-
-
主要问题 (自动评估指标的局限性):
-
不完美匹配人类判断: 像 BLEU, ROUGE 这些指标,虽然方便快捷,但它们和人类对生成质量的判断不总是一致的。有时候指标分数高,人读起来却不通顺或者意思不对。
-
难以评估语义和创造性: 它们主要看字面重合,很难评估生成文本的深层语义、流畅性、创造性、逻辑性。
-
需要人工评估补充: 因此,高质量的语言生成评估,离不开人工评估。
-
3)代码生成
给模型一段自然语言描述的需求(比如“写一个计算斐波那契数列的函数”),看它能不能生成正确的、可执行的代码。虽然传统上代码合成不完全算 NLP 范畴,但现在的大模型很多都把代码能力作为核心指标。AlphaCode, Codex, GitHub Copilot 等模型在这方面表现出色。
-
常用数据集: HumanEval: 包含 164 个手写的编程问题,每个问题都有描述、函数签名和一系列测试用例。模型需要生成能通过所有测试用例的代码;MBPP (Mostly Basic Python Programming): 也是类似的代码生成评测集。
-
“评分标准” (关键指标): pass@k。意思是,让模型针对一个问题生成 k 个候选代码,只要其中有至少一个能通过所有测试用例,就算通过。k 越大,通过的概率越高。
2、知识利用
模型不仅要知道很多事实知识,还要能准确地调用这些知识来回答问题、完成任务
1)问答
-
闭卷问答 (Closed-Book Question Answering) - 直接问模型问题,模型只能依靠自己预训练时“记住”的知识来回答,不能查阅外部资料。
-
常用数据集: Natural Questions, TriviaQA, Web Questions: 这些数据集的问题通常需要事实性知识才能回答。Natural Questions 的问题源自真实的谷歌搜索记录。
-
评估方式: 通常是看模型生成的答案与标准答案是否精确匹配 (Exact Match) 或部分匹配 (F1 Score)。
-
-
开卷问答 (Open-Book Question Answering) - 给模型问题的时候,同时提供一段相关的背景知识文本。模型需要从这些文本中找到答案。
-
常用数据集: SQuAD (Stanford Question Answering Dataset): 经典的开卷问答数据集,答案是原文中的一个片段;OpenBookQA: 包含科学常识问题,需要结合给定的背景知识进行推理。
-
2)知识补全
给模型一个不完整的知识三元组(比如“奥巴马 出生于 ?”),让模型补全缺失的部分。
-
常用数据集: WikiFact, FB15K-237, WN18RR: 这些是知识图谱补全常用的数据集。
3、复杂推理
模型不仅仅要记住知识,更要能运用知识进行多步的、复杂的逻辑推理和计算
1)知识推理
-
做法: 给出一些前提事实,让模型通过逻辑推理得出结论。
-
常用数据集:
-
CommonsenseQA: 考察常识推理能力。
-
StrategyQA: 需要多步推理才能回答的问题。
-
2)符号推理
-
做法: 考察模型处理抽象符号和规则的能力,比如字母序列操作、简单的逻辑运算等。
-
常用数据集:
-
bAbI tasks: 一系列简单的符号推理任务。
-
Last Letter Concatenation: 要求模型将一系列单词的最后一个字母拼接起来。
-
Coin Flip: 根据描述判断硬币最终是正面还是反面。
-
-
挑战: 模型可能只是记住了模式,而不是真正理解了符号操作的规则。
3)数学推理
-
做法: 解决数学应用题、代数问题、几何问题等,需要模型理解题意、进行数学运算和逻辑推导。
-
常用数据集:
-
GSM8K: 小学水平的数学应用题,但需要多步推理。
-
MATH: 更具挑战性的数学竞赛题目,包含代数、几何、数论等多个领域。
-
-
挑战: 数学推理对模型的逻辑严谨性和计算准确性要求极高。模型很容易在中间步骤出错。
-
提升方法: 思维链 (Chain-of-Thought) 提示、让模型生成解题步骤并进行验证 (Self-consistency, Verifier) 等。
四、大语言模型高级能力评估
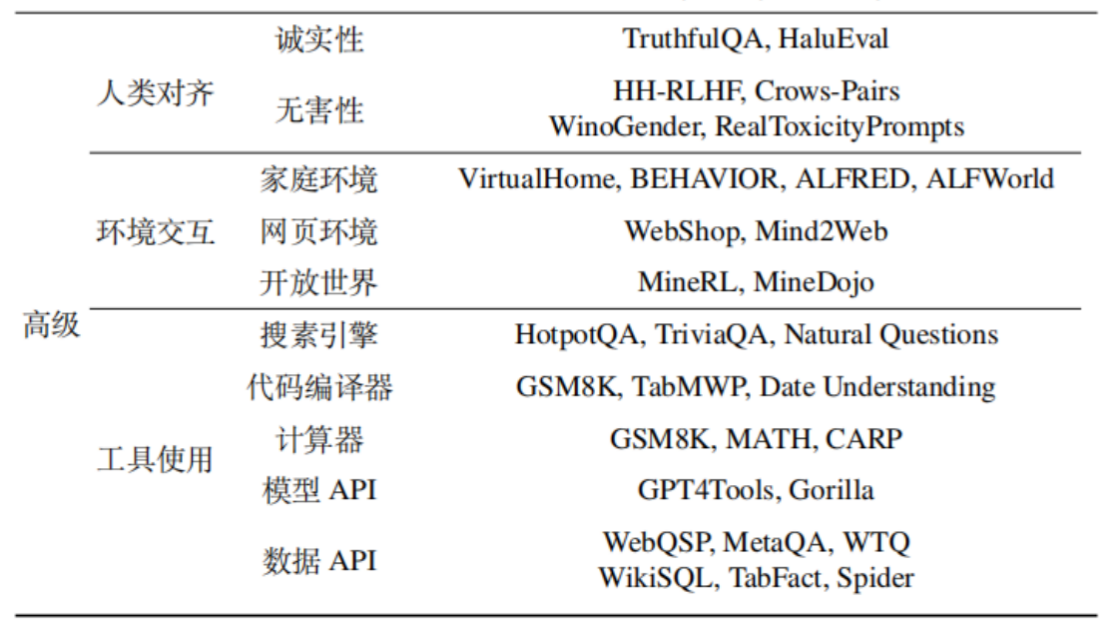
1、人类对齐
评估模型生成的行为是否符合人类的价值观和需求,也就是我们之前反复强调的“有用 (Helpful)、诚实 (Honest)、无害 (Harmless) - 3H”标准。这是大模型能否被广泛接受和安全应用的前提。
2、环境交互
模型不仅仅要能理解和生成文本,还要能与外部环境进行交互,通过观察环境反馈来调整自己的行为,以完成特定目标。这就像让 AI 玩一个真实或虚拟的游戏。这是模型从“语言智能”走向“具身智能 (Embodied AI)”的关键一步,让模型能真正地“行动起来”。
-
常见评测环境与任务:
-
WebShop: 一个模拟在线购物场景的交互环境。模型需要扮演一个顾客,通过浏览商品、提问、添加到购物车、下单等一系列操作,最终购买到指定商品。这个任务非常考验模型的规划能力、信息理解能力和与动态环境的交互能力。
-
ALFWorld: 一个基于文本的模拟家庭环境,模型需要通过输入自然语言指令(如“把苹果放到桌子上”)来控制智能体在虚拟房间里移动和操作物体,完成一系列家务任务
-
-
评测指标: 通常是任务完成率、完成效率(步数)、是否遵循指令等。
-
挑战:
-
环境复杂性高: 真实世界的环境非常复杂且动态。
-
长期规划能力要求高: 很多交互任务需要模型进行长期的规划和决策。
-
泛化能力: 模型在一个环境中学会的技能,能否泛化到新的、未见过的环境。
-
3、工具使用
大语言模型本身在某些方面(如精确计算、实时信息检索、执行复杂代码)能力有限。工具使用能力考察的是模型能否智能地调用外部工具或 API 来弥补自身不足,从而更好地完成任务。极大地扩展了模型的应用范围和解决复杂问题的能力。
-
评测方法:
-
HotpotQA (多跳问答中的工具使用): 虽然 HotpotQA 主要是一个多跳问答数据集,但模型在解决这类问题时,往往需要像“搜索引擎”一样,从多个文档中检索和整合信息,这可以看作是一种隐性的工具使用
-
API-Bank & ToolBench - 专门的 API 调用评测:
-
API-Bank: 包含大量不同领域的 API 调用指令和对应的 API 调用序列。它会评估模型能否根据自然语言指令,正确地选择 API、填充参数,并理解 API 的返回结果。
-
ToolBench (HuggingFace 开源): 一个更全面的工具使用评测平台,包含大量真实世界的 API。它不仅评估模型能否正确调用 API,还评估模型能否通过多轮 API 调用来完成复杂任务。
-
评测指标: API 调用准确率、参数填充准确率、任务成功率等。
-
-
-
挑战:
-
API 选择与理解: 如何让模型从众多 API 中选择正确的那个?如何让模型理解 API 的复杂参数和返回格式?
-
规划与多步调用: 很多任务需要模型进行多步、有逻辑的 API 调用。
-
错误处理与鲁棒性: API 调用可能会失败,模型需要具备一定的错误处理能力。
-
安全性: 如何防止模型滥用 API 或执行有害操作?
-
五、公开综合测评体系
1、MMLU
非常综合的评测基准,旨在全面评估大模型在多个领域中的知识理解和应用能力。包含人文科学、社会科学、自然科学和工程技术等多个大类,覆盖了 57 个子任务。这些任务的难度不一,有些是基础知识,有些则非常具有挑战性,需要模型具备一定的推理能力。
-
形式: 主要是少样本学习 (Few-shot Learning),即在提问时给模型看几个例子,然后让模型对新的问题进行作答(选择最合适的选项)。
-
评估指标: 主要看准确率 (Accuracy)。
-
特点:
-
覆盖面广: 真正做到了“海量多任务”。
-
能区分模型水平: 在一些高难度领域,能有效地暴露出模型知识的盲点或推理能力的不足。
-
-
现状: MMLU 已经成为衡量大模型通用知识能力的一个重要标杆。像 GPT-4 这样的顶级模型,在 MMLU 上的表现已经非常惊人(比如在 5 样本下准确率达到 86.4%)。
2、BIG-Bench
另一个极具挑战性的综合评测基准,包含 204 个任务,旨在评估模型在更广泛、更困难的任务上的能力,这些任务往往超出了简单的模式模仿。覆盖语言理解、世界知识、常识推理、数学、发展心理学、社会偏见、软件开发等多个领域。它的题目形式和评估方式非常多样。
-
BIG-Bench 任务示例:
-
文本生成类 (Object Counting): “我有一个冰箱、一个沙发和一个微波炉。我有多少件物品?” -> 需要模型理解并计数。
-
多项选择类 (Rain Names): “下面哪个是对电影或歌曲名‘rain man’的幽默改编?” -> 考察创造性和幽默感。
-
-
评估指标: 除了准确率,BIG-Bench 还引入了布里尔分数 (Brier Score) 等指标,用于衡量模型对预测结果的置信度,提供更细致的评估。
-
特点:
-
任务极具挑战性: 很多任务即使对人类来说也不容易。
-
暴露模型局限性: 通过这些困难任务,可以更好地发现当前大模型能力的上限和不足之处。
-
BIG-Bench Lite & Hard: 为了方便快速评估和深入分析,BIG-Bench 还推出了简化版 (Lite) 和更难版 (Hard)。
-
-
现状: 大模型在 BIG-Bench 上的平均表现仍有很大提升空间,很多任务远未达到人类水平。
3、HELM
一个全面的、多维度的语言模型评估框架,它不仅仅关注模型的“答题准确率”,还关注模型的鲁棒性、公平性、效率、偏见、毒性等多个重要方面。定义了 16 个核心的、有代表性的应用场景。针对每个场景,从准确性、校准性、鲁棒性、公平性、偏见、毒性和效率等 7 个维度进行评估。
-
HELM 任务示例:
-
问答任务示例: “哪个词最能描述身体维持正常状态的能力?” -> 考察生物学知识。
-
情感分析任务示例: “Chaddacky Does NO justice for the caddyshack. Thin plot...movie should have been destroyed when the script was written.” -> 判断情感是正面还是负面。
-
毒性检测任务示例: 判断输入的文本是否包含有害内容。
-
-
特点:
-
“全面” (Holistic): 真正做到了对模型进行全方位的考察。
-
强调多维度指标: 促使研究者不仅仅追求单一指标的提升,而是关注模型的整体表现和潜在风险。
-
-
现状: HELM 为语言模型的负责任发展和综合评估提供了重要的指导。
4、C-Eval
一个专门为中文大语言模型设计的综合评测基准。题目主要来自中国从初中到大学的各级考试,以及职业资格考试。覆盖人文、社科、理工、农医等多个领域,并进一步细分为 STEM(科学、技术、工程、数学)、人文、社科等四个大方向。主要形式是选择题,考察模型对中文知识的理解、应用和推理能力。
-
C-Eval 任务示例:
-
计算机组成原理任务示例: 考察计算机硬件知识。
-
初中物理领域示例: 考察基础物理概念。
-
法学领域任务示例: 考察法律常识和应用。
-
-
特点:
-
针对中文: 填补了中文领域高质量综合评测基准的空白。
-
难度有梯度: 覆盖了从初中到大学不同难度的知识。
-
考察细致: 对理工科等需要复杂推理和计算的领域有深入考察。
-
-
现状: C-Eval 已成为评估中文大模型能力的重要参考,很多国产大模型都在这上面“打榜”。
更多的评测使用方法详见:https://github.com/RUCAIBox/LLMBox/blob/main/utilization/README.md