世界模型:AGI突破口?一文了解NVIDIA Cosmos 平台
Yann LeCun 等大佬都曾公开表示,未来 AI 需要理解物理世界,具备持久记忆、推理和计划能力,才能继续进化。仅仅依靠文本训练的大型语言模型,无法实现人类水平的人工智能,因为它们不理解真实的物理世界。“世界模型”是通往强人工智能的关键路径,因为它让AI不再仅靠死记硬背数据(如大模型那样),而是能像人一样,形成对世界的抽象理解。要实现AGI,需要先在“世界模型”取得突破。
目前,Google、Meta 和 NVIDIA 都在世界模型领域积极布局。Google 旗下 DeepMind 于 2024 年 12 月发布 Genie 2 模型,作为大型基础世界模型,其侧重游戏制作领域,可根据文本和图像实时生成交互式 3D 场景(支持物体交互、动画、光照模拟),推动 AI 复杂环境创建能力突破。
2025 年 5 月 Google I/O 大会上,谷歌宣布正将 Gemini 模型向世界模型扩展,目标是使其理解物理世界并实现推理行动。现场展示了 Flow(电影制作画布)和 Veo 3(物理感知视频模型)等工具,强调世界模型技术已融入创意应用。Meta 则通过研究视频联合嵌入预测架构 V-JEPA,证明了 AI 可无先验理解直觉物理,V-JEPA 在自监督预训练中展现出对直观物理的理解,超越了基于像素的预测模型和多模态 LLM 。
NVIDIA 基于 Apache 2 开源协议的Cosmos平台(Cosmos World Foundation Model Platform),也正是朝着这一方向迈进,通过虚拟物理模拟和数据生成,为物理 AI 提供了安全高效的训练环境,成为连接大模型走向现实世界的关键桥梁。
本文为大家进行详细解析NVIDIA Cosmos平台,进而了解当前世界模型的进展。
物理 AI 发展困境与NVIDIA Cosmos 平台
物理 AI 作为 AI 领域中极具潜力的分支,配备了传感器和执行器,具备观察世界并与之互动、修改的能力,有望将人类从危险、繁重或乏味的物理任务中解放出来。想象一下,在未来,机器人可以在恶劣的工业环境中高效作业,自动驾驶汽车能够在复杂的路况下安全行驶,这些场景的实现都离不开物理 AI 的发展。
然而,物理 AI 在训练数据的获取上困难重重。由于所需数据必须包含观察和行动交织的序列,而这些行动可能会对物理世界产生扰动,在 AI 发展的初期阶段,探索性行动可能会对系统和世界造成严重损害,这使得物理 AI 的发展较为缓慢。就好比让一个新手在没有任何模拟训练的情况下直接驾驶真车在闹市中穿梭,很可能会引发事故,而物理 AI 在真实世界中获取数据就如同这样危险且低效。
NVIDIA 的Cosmos 平台的出现就是为解决这一难题。Cosmos 是 NVIDIA 推出的世界基础模型平台,能依据文本、图像、视频及机器人传感器或运动数据等输入,生成基于物理规律的高保真视频,用于辅助自动驾驶、机器人开发等物理 AI 领域的模型训练、评估,还能实现视频搜索理解、多宇宙模拟预测等功能 ,并支持开发者微调构建定制世界模型 。
Cosmos 平台通过生成式世界基础模型等技术手段,帮助 AI 更好地理解物理世界,具体体现在以下几个方面:
-
提供基础模型支持:Cosmos 平台拥有一系列世界基础模型(WFM),这些模型经过大规模训练,使用了超过 2000 万小时的真实世界数据,涵盖人类互动、环境、工业、机器人和驾驶数据等多个领域。模型分为扩散模型和自回归模型两类,能够接受文本、图像或视频的提示,生成具有物理感知的高保真视频,模拟和预测机器人和自主系统的真实结果,从而让 AI 学习物理世界的运行规律,对物理现象做出判断。
-
助力数据处理与优化:Cosmos 平台集成了高级分词器和加速数据处理管道。高级分词器可以将复杂的数据简化,帮助模型更好地理解和处理数据;加速数据处理管道能够快速处理大量视频数据,例如英伟达的 NeMo Curator 可以在 14 天内处理 2000 万小时的视频数据,为 AI 学习物理世界提供了高效的数据支持。
-
模拟物理环境与交互:Cosmos 平台与英伟达的 Omniverse 平台深度整合,Omniverse 是一个基于物理规律的模拟平台,可以创建高度逼真的虚拟环境。Cosmos 赋予 AI “物理直觉”,Omniverse 为这种 “直觉” 提供了可以施展的舞台,使 AI 能够在虚拟环境中观察、分析和预测各种物理现象,进行各种尝试,不用担心造成损失,还能创造出大量带有物理规律的模拟数据,有助于提高 AI 的学习效率,让 AI 更好地理解物理世界中的物体关系、运动规律以及各种物理交互。
-
支持模型定制与微调:开发者可以利用 Cosmos 平台提供的工具和框架,根据自己的需求对预训练的世界基础模型进行微调,创建出专门针对特定目标的专用模型,以满足不同物理 AI 应用场景的需求,进一步提高 AI 在不同领域对物理世界的理解和应用能力。
Cosmos平台架构与核心组件
Cosmos平台主要包含视频管理器、视频标记器、预训练世界基础模型、世界基础模型后训练示例以及护栏等组件,各组件协同工作,为物理 AI 提供支持。
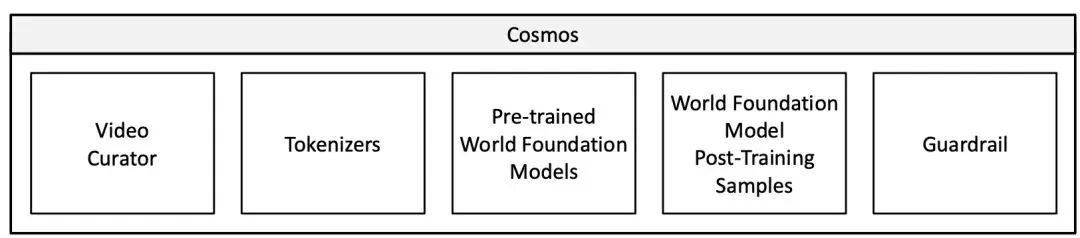
(图:Cosmos核心组件架构图)
从整体架构来看,它就像是一个精密的机器,每个组件都是不可或缺的零件,共同驱动着物理 AI 的发展。视频管理器负责处理原始视频数据,为模型训练提供高质量的素材;视频标记器将视频数据转化为适合模型处理的格式;预训练世界基础模型则是平台的核心,学习现实世界的物理规律和自然行为;后训练示例展示了模型在不同应用场景中的具体应用;护栏系统则保障了模型的安全使用,防止有害输入和输出。
数据管理:视频管理器
数据处理流程:视频管理器通过一系列复杂步骤处理原始视频数据。先进行视频分割,将长视频按镜头变化分割成片段。接着进行转码,统一视频编码格式为高质量 mp4,提升数据加载稳定性和效率。然后依次进行运动过滤、视觉质量过滤、文本过滤和视频类型过滤,去除无用视频片段,调整数据分布。之后用 VLM 为视频添加描述,进行语义去重,减少数据冗余,最后将处理后的视频分片存储。
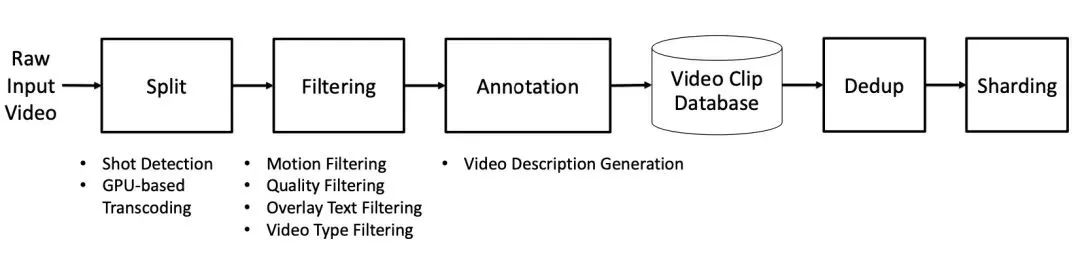
(图:视频管理器主要步骤)
数据多样性:使用的视频数据集涵盖驾驶、手部动作、人类运动等多种类别,丰富的数据能提升模型泛化能力。这些数据来自于专有视频数据集和公开的互联网视频,通过精心筛选和处理,为模型提供了广泛的视觉体验,使其能够学习到不同场景下的物理规律和视觉特征。例如,在训练一个用于智能仓储机器人的物理 AI 模型时,手部动作和人类运动数据可以帮助模型更好地理解人类操作物体的方式,而驾驶数据则可以让模型学习到物体在不同速度和环境下的运动模式,从而使机器人在复杂的仓储环境中能够更准确地执行任务。
数据表示:视频标记器
标记器类型与优势:Cosmos Tokenizer 包含连续和离散两种类型的视频标记器,具有因果性,能实现图像和视频的联合训练,且在推理时不受视频时长限制。其架构采用编码器 - 解码器结构,结合小波变换和因果操作,有效捕捉数据时空依赖关系。
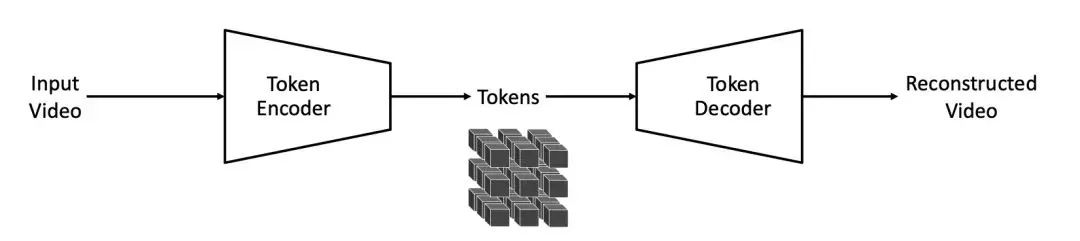
(图:Cosmos Tokenizer)
在这个架构中,编码器将输入视频转化为紧凑的令牌表示,解码器则根据这些令牌重建视频。小波变换的应用使得模型能够在更紧凑的视频表示上进行操作,减少了像素信息的冗余,提高了处理效率。例如,在处理一段长时间的监控视频时,Cosmos Tokenizer 能够快速将其转化为高效的令牌表示,同时保留关键的时空信息,为后续的模型处理节省了大量资源。
训练与性能:采用联合训练策略,分阶段使用不同损失函数优化。在多个图像和视频基准数据集上评估,Cosmos Tokenizer 在重建质量和推理效率上表现优异,压缩率高且速度快。
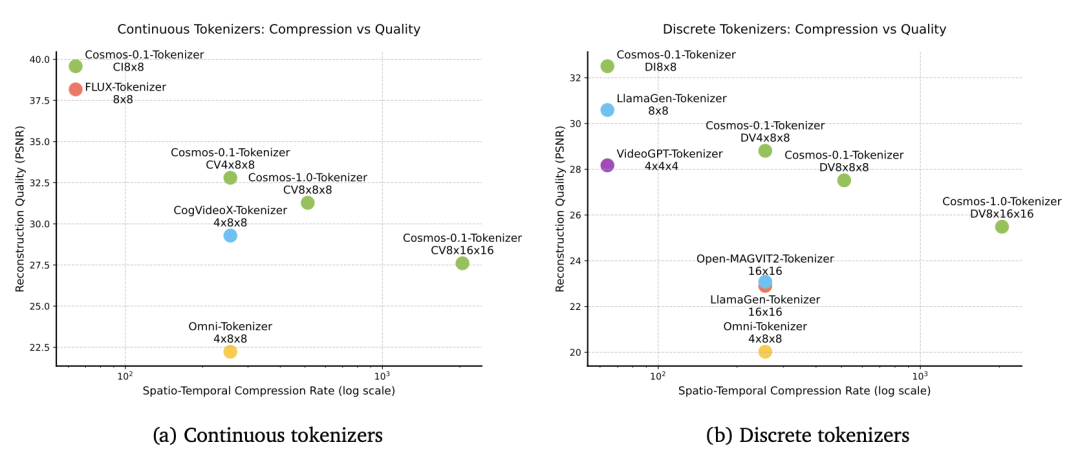
(图:时空压缩率方面,连续(左)和离散(右)标记化器的比较)
在训练过程中,先使用 L1 损失和基于 VGG-19 特征的感知损失进行第一阶段训练,优化模型对图像和视频内容的重建能力;第二阶段引入光流损失和 Gram - 矩阵损失,处理重建视频的时间平滑性和图像清晰度问题。在一些实验中,Cosmos Tokenizer 在 DAVIS 数据集上实现了比现有令牌器高达 +4 dB PSNR 的重建质量提升,且运行速度快了 12 倍。这一性能提升在实际应用中具有重要意义,比如在实时视频分析场景中,能够更快地处理视频流,提供更及时准确的分析结果。
模型构建:预训练世界基础模型
扩散模型:基于扩散模型的 WFM 采用特定损失函数和架构设计。如在架构上,通过 3D patchification 处理输入,将视频的潜在表示转换为适合网络处理的格式;采用混合位置嵌入,包括 3D factorized Rotary Position Embedding(RoPE)和可学习的绝对位置嵌入,提高模型对不同尺寸、长宽比和视频长度的适应性;跨注意力机制用于整合语言信息,使模型能够根据文本提示生成视频;同时进行了 Query-key 归一化和 AdaLN-LoRA 优化,提高训练稳定性和减少参数数量。训练时采用联合图像和视频训练、渐进训练等多种策略,并通过 FSDP 和 CP 技术实现高效扩展。
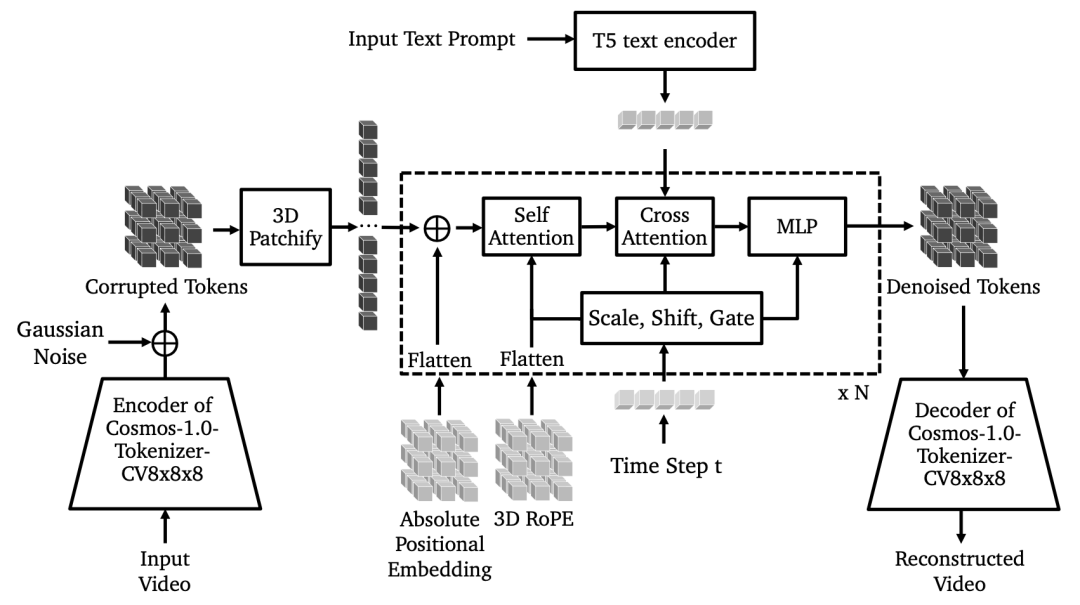
(图:Cosmos-1.0-扩散世界基础模型的整体架构)
在联合训练中,通过交替优化图像和视频批次,利用丰富的图像数据集提升模型性能;渐进训练则分阶段逐步提高视频分辨率和长度,使模型能够更好地学习复杂的视觉特征。例如,在训练一个用于模拟城市交通场景的 WFM 时,通过联合图像和视频训练,模型可以同时学习到静态的城市道路布局和动态的车辆行驶情况,渐进训练则让模型从低分辨率、短时长的视频模拟逐渐过渡到高分辨率、长时间的复杂场景模拟。
自回归模型:自回归 WFM 将世界模拟生成视为下一个令牌预测任务。架构上添加 3D 感知位置嵌入、跨注意力和 QKNormalization。训练分多阶段进行,包括基于视频预测目标的训练和引入文本条件的训练,并通过张量并行和序列并行技术扩展模型。此外,还采用了推测解码等优化技术提升推理速度,引入扩散解码器解决离散标记化带来的问题。
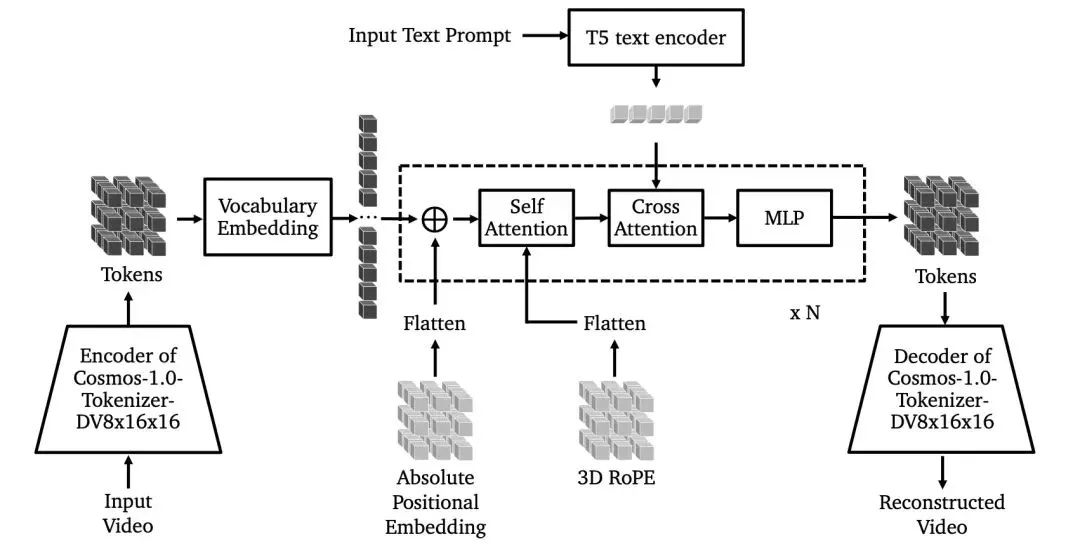
(图:Cosmos-1.0-自回归模型)
在多阶段训练中,模型逐渐学习到视频的动态模式和文本与视频之间的关系;推测解码技术通过并行预测多个后续令牌,有效加速了推理过程;扩散解码器则通过将离散令牌转换为连续令牌,提高了视频生成的质量。比如在一个智能建筑管理系统中,自回归 WFM 可以根据当前的建筑环境视频和文本指令,快速预测未来的环境变化,并生成相应的视频模拟,为建筑管理者提供决策支持。
模型评估:从 3D 一致性和物理对齐两个方面评估预训练 WFM。在 3D 一致性评估中,针对静态场景,使用特定数据集和指标,结果显示 Cosmos WFMs 在生成 3D 一致视频上表现出色;在物理对齐评估中,通过模拟物理场景,对比模型输出和真实视频,发现模型在预测物理场景时存在一定局限性,需改进数据处理和模型设计。
在 3D 一致性评估中,通过量化几何一致性和视图合成一致性等指标,发现 Cosmos WFMs 生成的视频在满足极线几何约束和合成新颖视图方面表现优异;而在物理对齐评估中,虽然模型在一定程度上能够预测物体的运动,但在处理复杂物理场景时,仍存在与物理规律不符的情况。例如,在模拟一个物体在斜面上的滑动时,模型可能会出现物体运动轨迹不符合牛顿力学定律的情况,这就需要进一步优化数据处理和模型结构,使其更好地符合物理现实。
应用拓展:后训练世界基础模型
相机控制:通过对 Cosmos-1.0-Diffusion-7B-Video2World 进行相机姿态条件微调,使其成为 3D 世界模拟器。使用 DL3DV-10K 数据集,添加相机控制条件并进行训练。评估显示,该模型在生成视频质量和 3D 一致性上优于基线模型,能有效实现相机控制,模拟不同场景。
在训练过程中,通过连接采样的潜在嵌入和 Plücker 嵌入,实现相机控制条件的添加;在评估中,与 CamCo 模型对比,Cosmos 模型在相机轨迹对齐和视频生成质量上表现更优,能够生成更符合 3D 世界结构的视频。比如在一个虚拟旅游应用中,用户可以通过该模型控制虚拟相机,以不同的角度和路径游览虚拟景点,获得更加真实和沉浸式的体验。
机器人操作:针对指令式视频预测和基于动作的下一帧生成两个任务,分别使用 Cosmos-1X 和 Bridge 数据集对预训练 WFM 进行微调。评估结果表明,微调后的模型在指令跟随、物体持久性等方面表现更好,能更好地预测机器人动作结果。
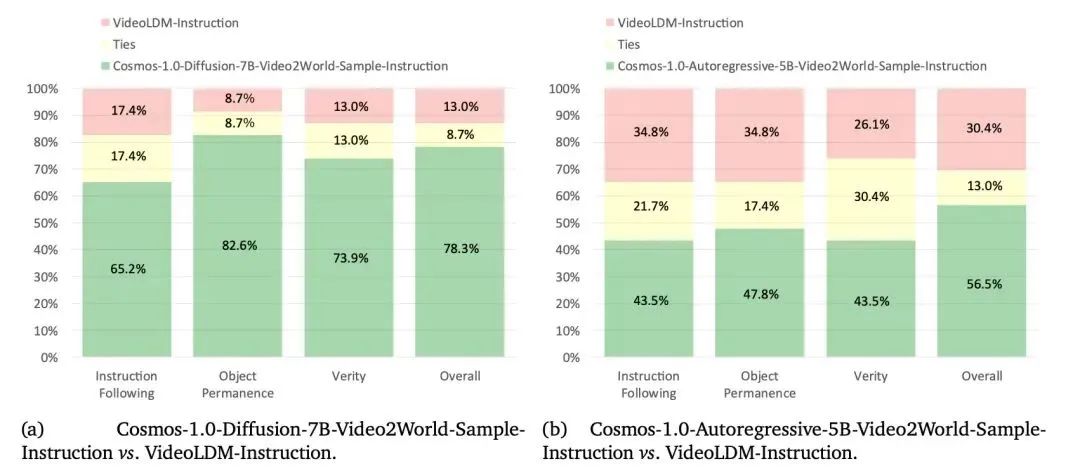
(图 :基于指令的视频预测在Cosmos-1X数据集上的人工评估结果)
在指令式视频预测任务中,通过计算 T5 嵌入并添加到基础模型的微调中,使模型能够根据文本指令预测机器人的动作视频;在基于动作的下一帧生成任务中,通过添加动作嵌入模块,将动作向量融入模型,提高了对机器人动作结果的预测准确性。在工业生产中,机器人可以根据这些微调后的模型,准确地执行人类下达的复杂指令,完成如零件组装、物料搬运等任务,提高生产效率和准确性。
自动驾驶:利用内部的 Real Driving Scene(RDS)数据集对预训练 WFM 进行微调,构建多视图世界模型。通过修改架构,添加视图嵌入和轨迹控制条件,使模型能生成多视图视频,并在视频生成质量、多视图一致性和轨迹跟随准确性上表现优异。

(图 :由Cosmos-1.0-Diffusion-7B-Text2World-Sample-MultiView生成的文本条件样本)
在构建多视图世界模型时,通过独立使用相同的位置嵌入并添加视图嵌入,使模型能够处理不同视图的信息;通过添加轨迹控制条件,模型能够生成符合给定轨迹的驾驶场景视频,为自动驾驶训练提供了有力支持。例如,在自动驾驶汽车的训练中,多视图世界模型可以模拟各种路况和驾驶场景,让自动驾驶系统在虚拟环境中进行大量的测试和学习,提高其在真实道路上的安全性和可靠性。
安全保障:护栏系统
预护栏:通过关键字阻断和 Aegis 护栏双重机制,对输入提示进行筛查,阻止有害提示进入模型,防止生成不安全内容。关键字阻断通过对输入提示进行词法分析,与预定义的有害关键字列表进行匹配,一旦发现匹配项,立即拒绝该提示;Aegis 护栏则基于经过大量数据训练的 LLM 模型,对提示进行语义分析,识别潜在的有害内容,进一步提高了安全性。例如,当用户输入包含暴力、恐怖等有害关键字的提示时,关键字阻断机制会迅速拦截;而对于一些隐晦的有害语义提示,Aegis 护栏能够通过语义理解进行识别和阻止,确保模型不会生成不良内容。
后护栏:利用视频内容安全过滤器和面部模糊过滤器,对生成的视频进行处理,确保输出符合安全标准。同时,通过红队测试不断优化护栏系统。
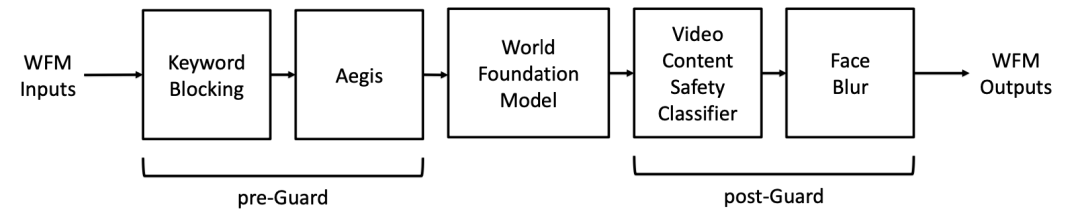
(图 :Cosmos Guardrail包括 前护栏和后护栏)
视频内容安全过滤器通过对视频帧进行分类,识别不安全内容;面部模糊过滤器则使用 RetinaFace 等先进的面部检测模型,对视频中的面部区域进行模糊处理,保护个人隐私。红队测试通过使用各种标准和对抗性示例对系统进行攻击,发现并修复潜在的安全漏洞,不断提升护栏系统的性能。在一些涉及公众场合监控视频生成的应用中,后护栏系统可以确保生成的视频不会泄露个人隐私信息,同时保证视频内容不包含任何危险或不良信息。
NVIDIA Cosmos世界基础模型最新进展
2025 年 3 月 18 日,GTC 大会上NVIDIA 宣布推出全新 NVIDIA Cosmos世界基础模型(WFM)的重大更新,引入开放式、可完全定制的物理 AI 开发推理模型,让开发者能以前所未有的方式控制世界生成。还推出了两款由 NVIDIA Omnivers和 Cosmos 平台提供支持的新蓝图,为机器人和自动驾驶汽车后训练提供大规模可控合成数据生成引擎。
2025 年 5 月 20 日,推出 Cosmos - Reason1 系列模型:NVIDIA 宣布推出 Cosmos - Reason1 系列模型,包括 7B 参数的 Cosmos - Reason1 - 7B 和 56B 的 Cosmos - Reason1 - 56B。该系列模型采用 “理论 + 实践” 的训练方式,先用 400 万段带注释的视频给 AI 进行物理知识培训,将现实世界拆解成空间、时间、基础物理三大知识模块并细分成 16 个专业科目。同时设计了 “双本体系统”,使 AI 不仅能看懂视频中的动作,还能推理出隐藏信息。在物理常识测试和具身推理测试中,Cosmos - Reason1 的成绩比之前的模型有显著提升。
NVIDIA 的 Cosmos 平台为物理 AI 构建了全链路解决方案,覆盖数据处理、模型训练、场景应用及安全防护等核心环节。尽管当前世界基础模型在物体状态持续性模拟、复杂物理规则适配等维度仍存优化空间,但随着技术迭代与数据积累,其在机器人操控、自动驾驶仿真等场景的落地潜力将持续释放,加速物理 AI 从理论走向工业级应用。这一技术路径与Yann LeCun 提出的「AI 需理解物理世界」的进化方向高度契合 —— 未来,依托 Cosmos 等基础设施,物理 AI 有望突破感知与行动的认知壁垒,成为通往通用 AGI 的关键支点。