【大模型原理与技术-毛玉仁】第三章 Prompt工程
3 Prompt工程
3.1 Prompt工程简介
Prompt的定义
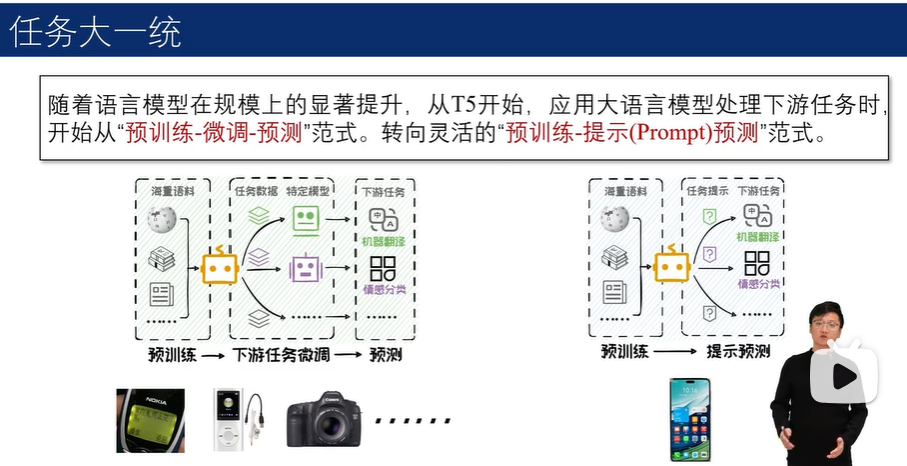
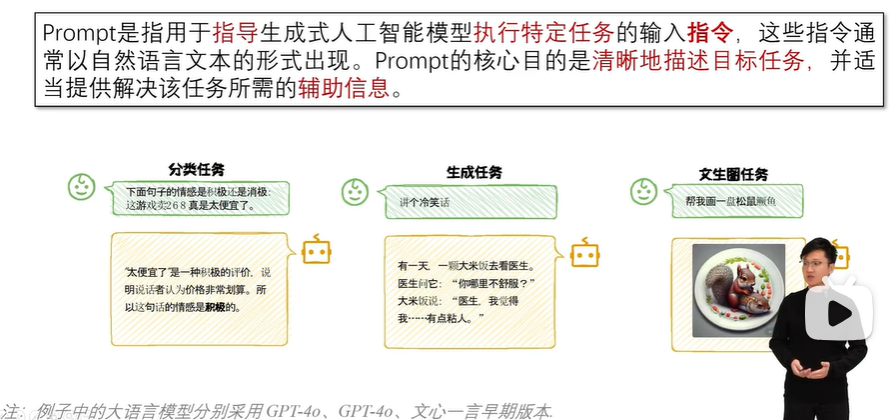

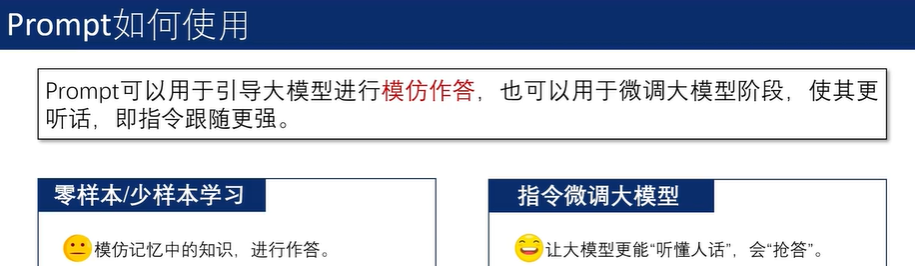
Prompt工程的定义




Prompt分词向量

在 Prompt 进入大模型之前,需要将它拆分成一个Token 的序列,其中Token 是承载语义的最小单元,标识具体某个词,并且每个 Token 由 Token ID 唯一标识。将文本转化为 Token 的过程称之为分词(Tokenization)。
为实现有效分词,首先需构建一个包含大语言模型所能识别的所有 Token 的词表,并依据该词表进行句子拆分。在构建大语言模型的词表时,分词器依赖于分词算法,如BBPE、BBPE
和WordPiece等,这些算法通过分析语料库中的词频等信息来划分Token。
为了有助于模型更准确地理解词义,同时减少生成常用词所需的Token 数量,词表中收录了语料库中高频出现的词语或短语,形成独立的Token。例如,“干脆”一词在词表中以一个Token 来表示。
为了优化Token 空间并压缩词表大小,构建词表时会包含了一些特殊的 Token,这些 Token 既能单独表示语义,也能通过两两组合,表示语料库中低频出现的生僻字。例如,“浣”字使用两个Token,“æµ”和“£”,来表示。
通过这种处理方式,词表既能涵盖常见的高频词汇,又能通过Token 组合灵活表达各类稀有字符。
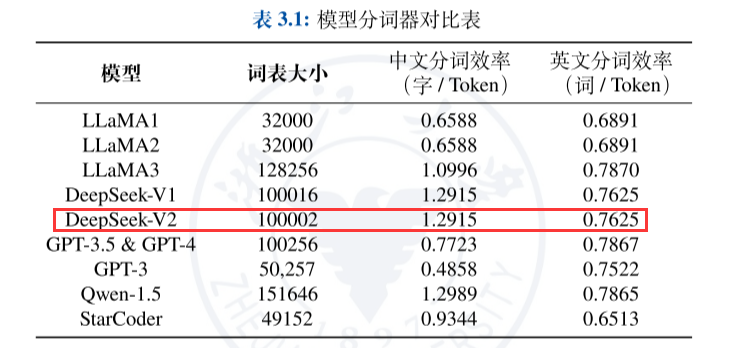
像 DeepSeek 、Qwen 这类中文开源大语言模型,对中文分词进行了优化,平均每个Token 能够表示 1.3 个字(每个字仅需 0.7 个Token 即可表示),一些常用词语和成语甚至可以直接用一个Token 来表示。
单个 Token 承载更多的语义,模型在表达同样的文本时,只需要输出更少的 Token,显著提升了推理效率。
在完成分词之后,这些Token 随后会经过模型的嵌入矩阵(Embedding Matrix)处理,转化为固定大小的表征向量。这些向量序列被直接输入到模型中,供模型理解和处理。
在模型生成阶段,模型会根据输入的向量序列计算出词表中每个词的概率分布。模型从这些概率分布中选择并输出对应的 Token,这些 Token 再被转换为相应的文本内容。
Prompt工程的意义
Prompt工程的意义:垂域任务、数据增强、智能代理。
应用Prompt工程可以将大语言模型构建为智能代理(Intelligent Agent,IA)。智能代理,又叫做智能体,能够感知环境、自主采取行动以实现目标,并通过学习或获取知识来提高其性能。
例如,斯坦福大学利用 GPT-4 模拟了一个虚拟西部小镇,多个基于 GPT-4 的智能体在其中生活和互动,他们根据自己的角色和目标自主行动,进行交流,解决问题,并推动小镇的发展。整个虚拟西部小镇的运转都是由 Prompt 工程驱动的。
如何设计Prompt,在大模型的辅助下完成项目的选题
3.2 上下文学习
上下文学习的定义
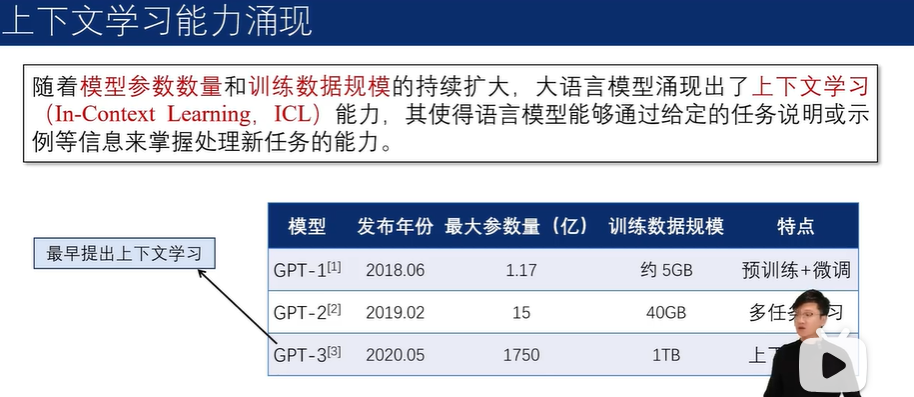
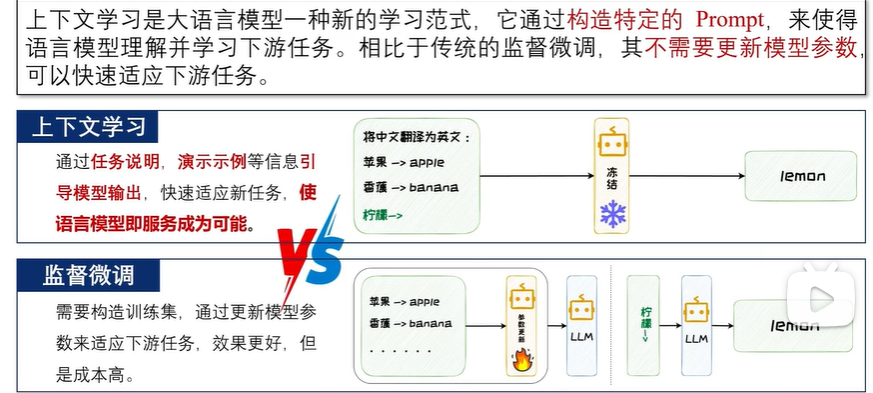
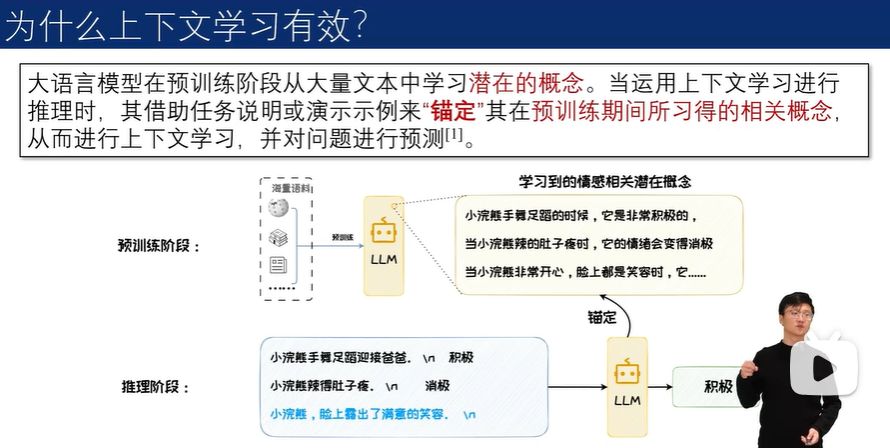

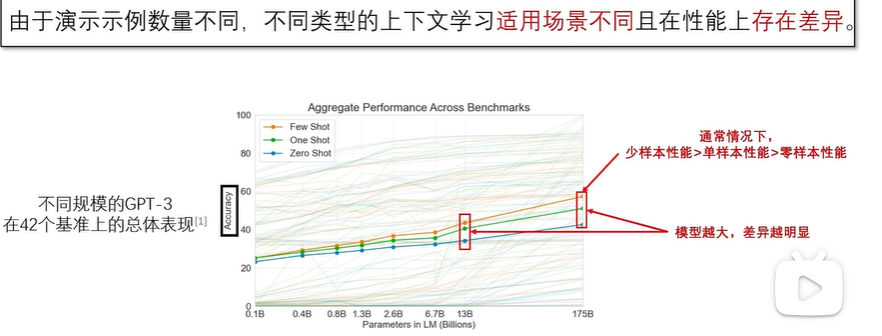
示例的增加,会显著提升模型在特定任务上的表现。但是,也会显著增加模型推理时的计算成本。
演示示例选择

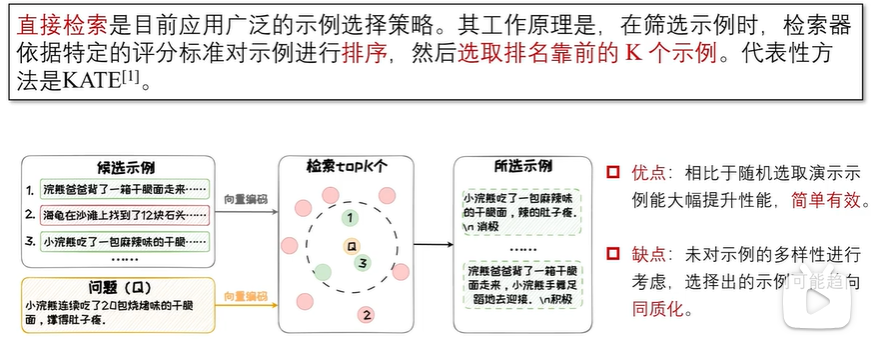

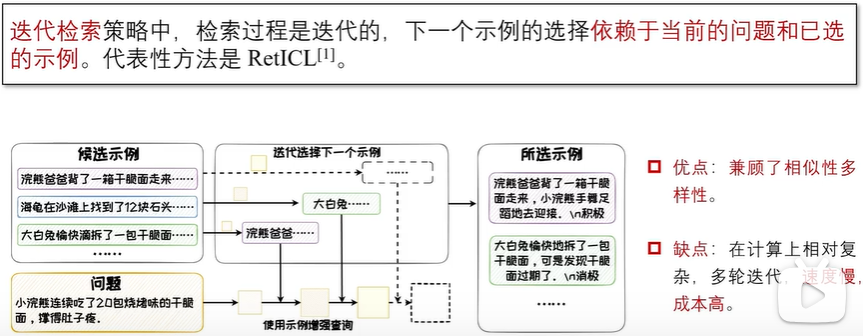
性能影响因素(预训练数据、预训练模型、演示示例)


预训练模型对上下文学习的性能影响主要体现在模型参数规模上。当模型参数达到一定的规模时,上下文学习才能得以涌现。通常,模型的参数数量需达到亿级别及以上。常见的拥有上下文学习能力的模型中,规模最小的是来自阿里巴巴通义实验室的Qwen2-0.5B 模型,具有 5 亿参数。一般而言,模型的规模越大,其上下文学习性能也越强 。此外,模型的架构和训练策略也是影响上下文学习性能的重要因素。


一些复杂推理任务,例如算术、代码等,仅仅给出输入和输出不足以让模型掌握其中的推理过程。在这种情况下,以思维链的形式构造示例,即在输入和输出之间添加中间推理步骤,能帮助模型逐步推理并学习到更复杂的映射关系。
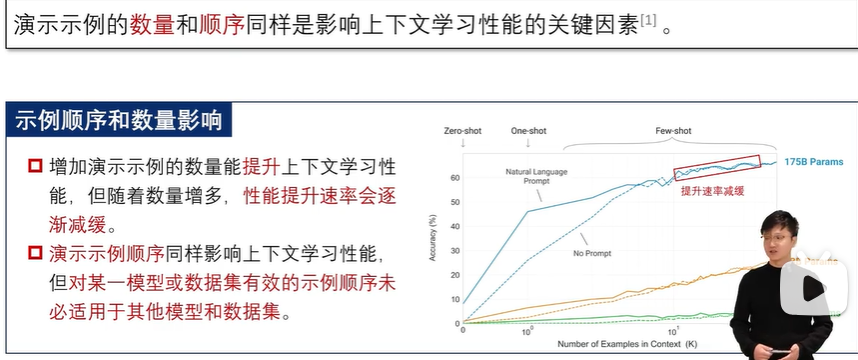
3.3 思维链
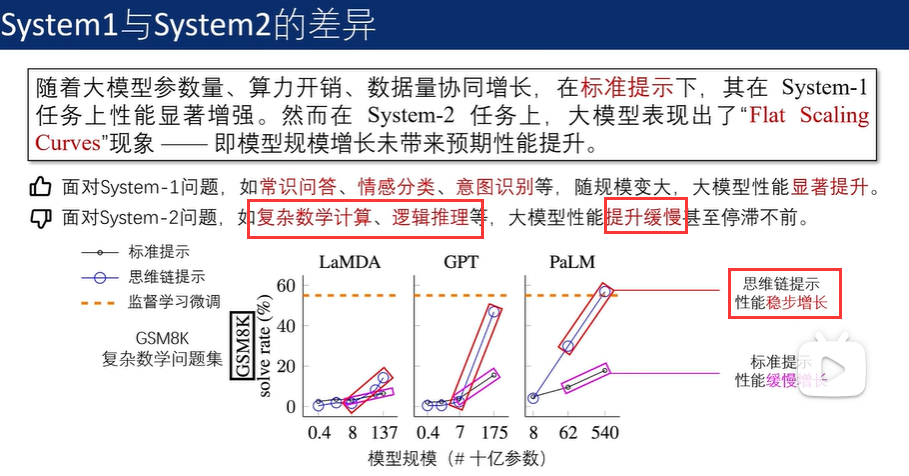
思维链提示的意义


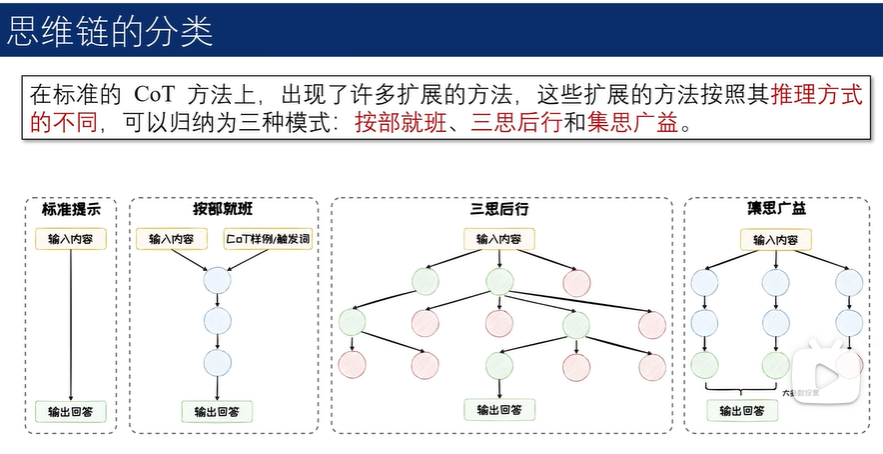
按部就班






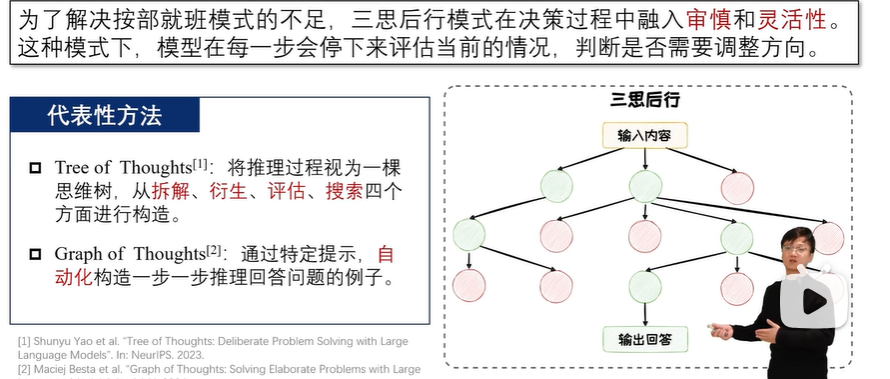
三思后行


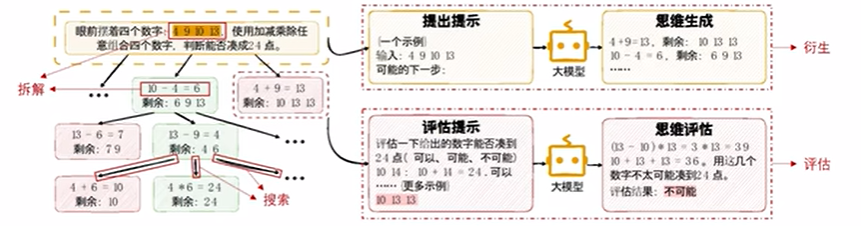
衍生的两种模式:
样本启发以多个独立的示例作为上下文,增大衍生空间,适合于创意写作等思维空间宽泛的任务;
命令提示在Prompt中指明规则和要求,限制衍生空间,适用于 24 点游戏等思维空间受限的任务。
评估的两种模式:
投票模式中,模型在多节点中选择,依据票数决定保留哪些节点;
打分模式中,模型对节点进行评分,依据评分结果决定节点的保留。
集思广益




GPT-o1



3.4 Prompt技巧
Prompt技术 + Prompt技巧 → 输出优质内容
规范Prompt编写




![]()

上述第二个例子的上下文不够丰富,并且单个例子则包含了大量与问题无关的细节,这些冗余信息不仅使上下文显得不明确,还可能加重模型处理信息的负担,导致模型难以准确把握问题的核心,进而影响其回答的准确性。


在第二个例子中,如果模型输出的答案是一个自由格式的文本字符串,那么提取具体信息就需要进行复杂的字符串解析,而不是像JSON等结构化格式那样可以直接提取,这就给后续对于结果的处理与使用带来了麻烦。


合理归纳提问


这一过程包括两个关键步骤:分步引导和归纳总结。
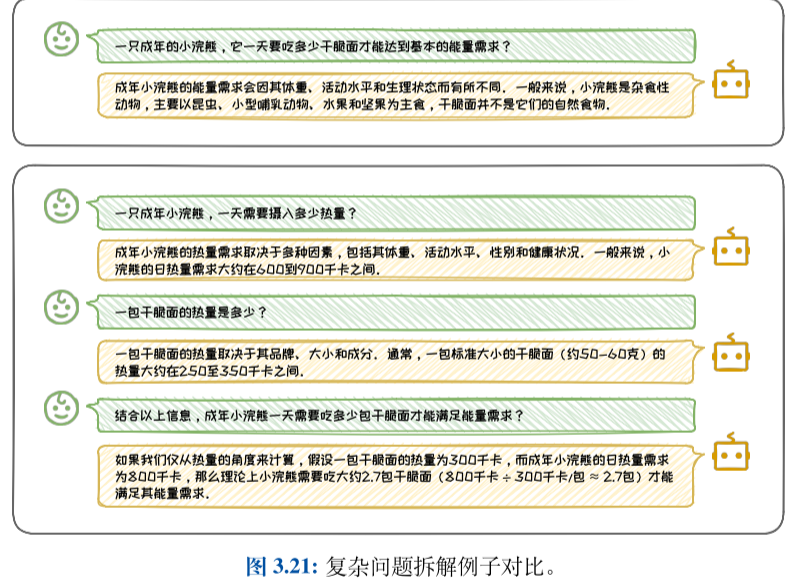

深入追问的形式是指用户可以根据大语言模型的输出继续发问来深入挖掘特定话题的深层信息。

扩展追问是一种在大语言模型给出回答的基础上,进一步要求模型提供更多相关信息或例子的提问方式,其目的在于拓宽讨论的广度。

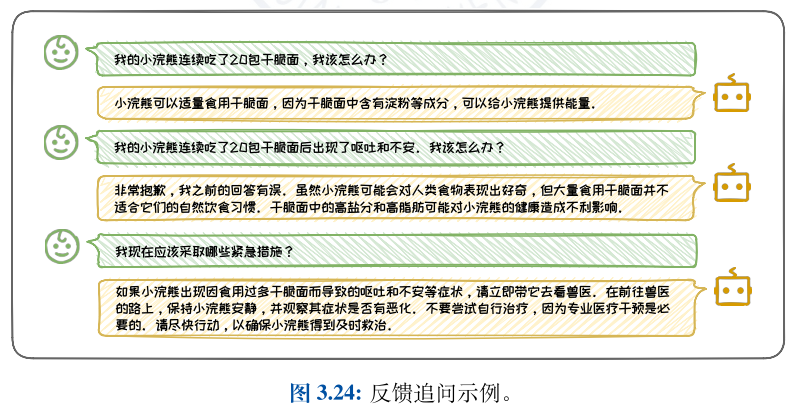
反馈追问的形式是在大语言模型的输出不符合预期或存在错误时,提供反馈,指出问题所在,并请求模型进行更正或澄清。
适时使用CoT




CoT技术应用于参数量超过千亿的巨型模型时,能够显著提升其性能。



善用心理暗示





Prompt长度压缩问题


3.5 Prompt工程应用
基于大语言模型的Agent
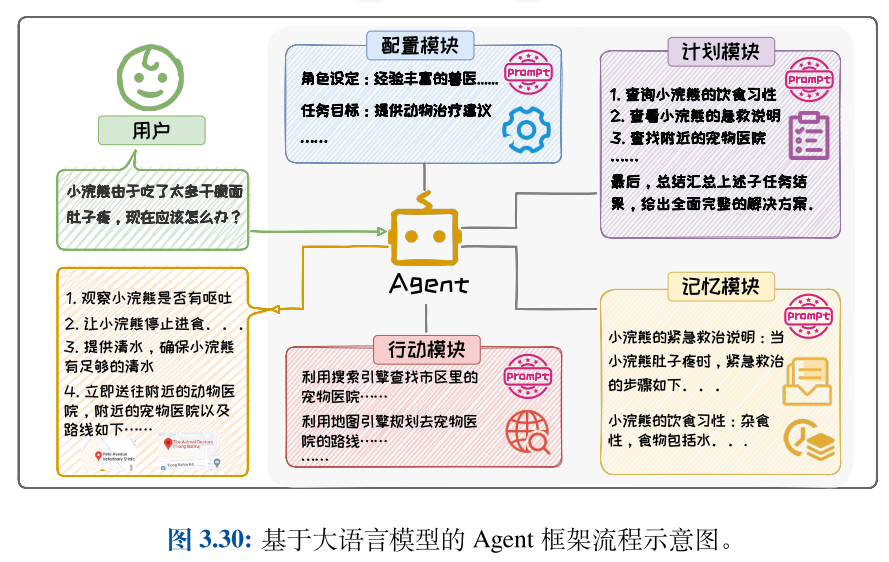
智能体(Agent)是一种能够自主感知环境并采取行动以实现特定目标的实体。作为实现通用人工智能(AGI)的有力手段,Agent 被期望能够完成各种复杂任务,并在多样化环境中表现出类人智能。
一个经典的Agent 框架,该框架主要由四大部分组成:配置模块(Profile)、记忆模块(Memory)、计划模块(Planning)和行动模块(Action)。Prompt 工程技术贯穿整个Agent 流程,为每个模块提供支持。

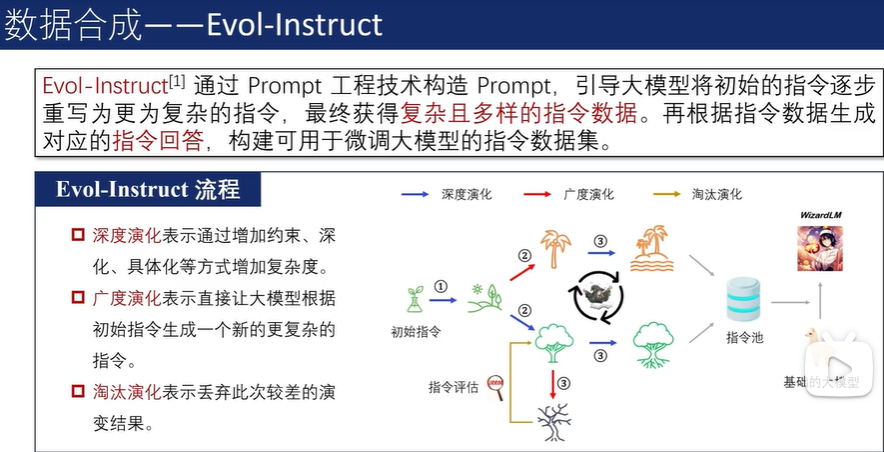
数据合成
Self-Instruct 通过 Prompt 工程技术构建 Prompt,通过多步骤调用大语言模型,并依据已有的少量指令数据,合成大量丰富且多样化的指令数据。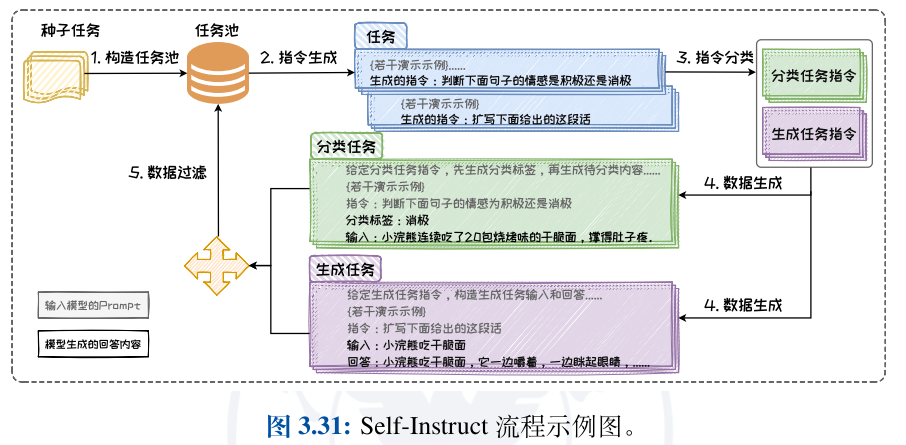
Text-to-SQL
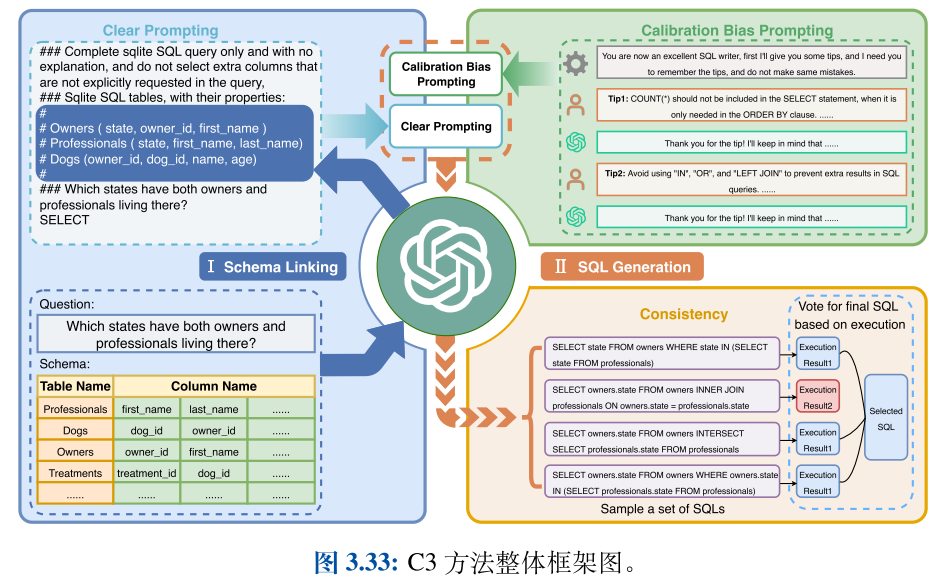
Text-to-SQL 技术可以将自然语言查询翻译成可以在数据库中执行的SQL语句,是实现零代码或低代码数据查询的有效途径。

最早使用大语言模型来做零样本 Text-to-SQL 的方法是 C3 。C3 的核心在于 Prompt 工程的设计,给出了如何针对 Text-to-SQL 任务设计 Prompt 来优化生成效果。如图3.33所示,C3 由三个关键部分组成:清晰提示(Clear Prompting)、提示校准(Calibration with Hints)和一致输出(Consistent Output),分别对应模型输入、模型偏差和模型输出。