【大模型原理与技术-毛玉仁】第一章 语言模型基础
1 语言模型基础
语言是概率的。并且,语言的概率性与认知的概率性也存在着密不可分的关系。语言模型(Language Models, LMs)旨在准确预测语言符号的概率。
1.1 基于统计的语言模型
n-grams 语言模型中的 n-gram 指的是长度为 n 的词序列。n-grams 语言模型通过依次统计文本中的 n-gram 及其对应的 (n-1)-gram 在语料库中出现的相对频率来计算文本w1:N 出现的概率。


注意:当n = 2时,称之为bigrams,其对前一个词进行考虑。
我们可以发现虽然“长颈鹿脖子长”并没有直接出现在语料库中,但是 bigrams 语言模型仍可以预测出“长颈鹿脖子长”出现的概率有 2/15。由此可见,n-grams 具备对未知文本的泛化能力。
在 n-grams 语言模型中,n 代表了拟合语料库的能力与对未知文本的泛化能力之间的权衡。
1.2 基于学习的语言模型
学习和统计的区别

基于学习的语言模型
学习的目的
在经验知识的指导下,求解未知的问题。
机器学习的目的
机器学习的目的在于减少泛化误差,即真实误差。
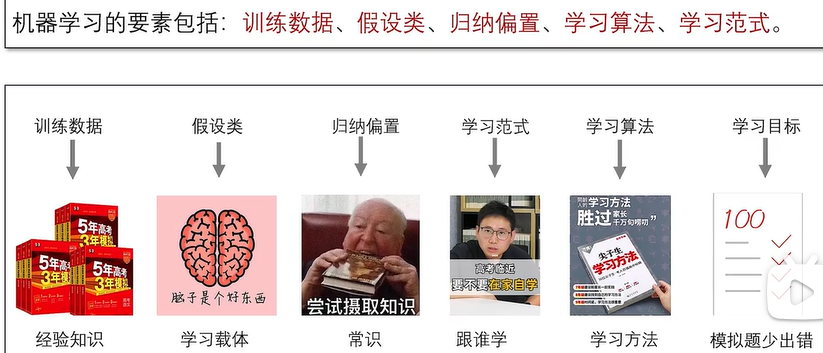
机器学习要素
1、训练数据
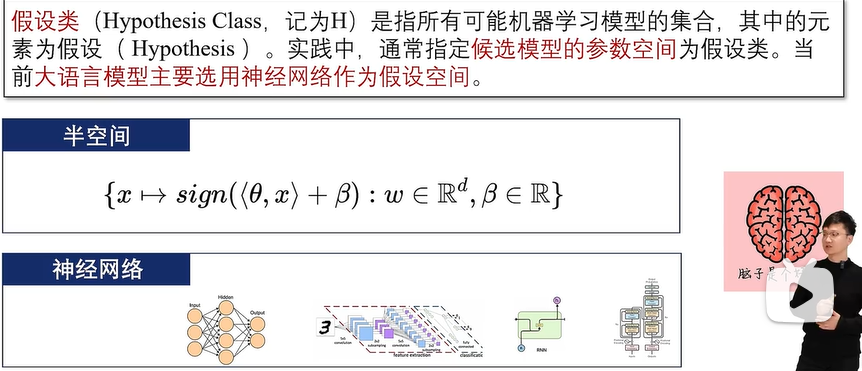
 2、假设类
2、假设类
3、归纳偏置

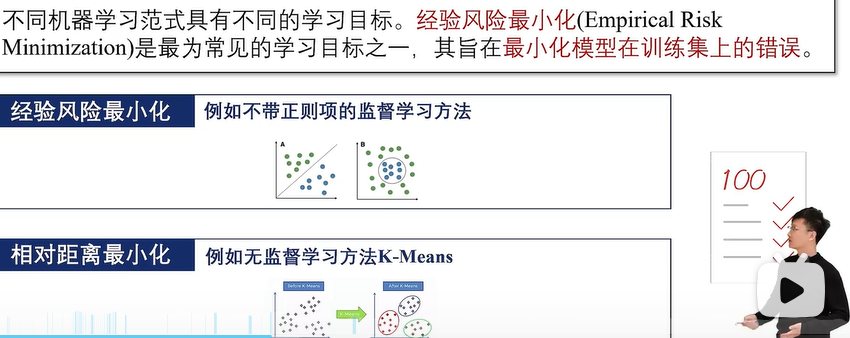
4、学习范式

5、学习算法


6、学习目标
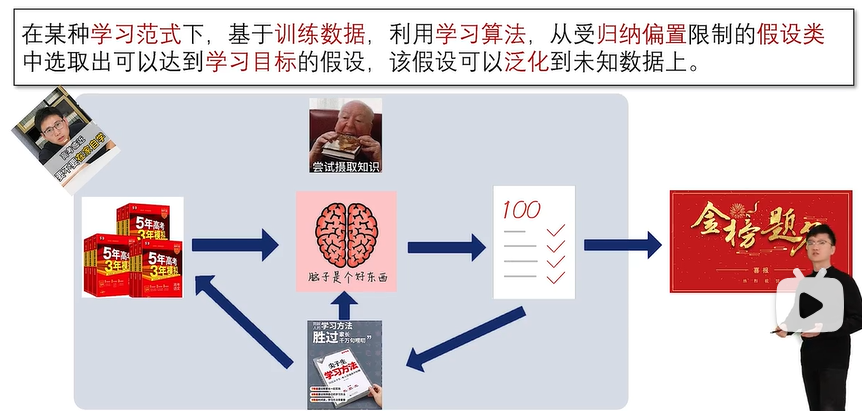
机器学习过程
1.3 RNN与Transformer
1.3.1 循环神经网络RNN
循环神经网络(Recurrent Neural Network, RNN)是一类网络连接中包含环路的神经网络的总称。基于RNN的语言模型,以词序列作为输入,基于被循环编码的上文和当前词来预测下一个词出现的概率。
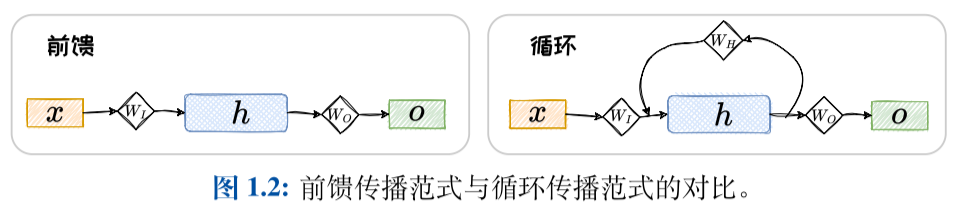
RNN 的网络结构中除了正向通路,还有一条环路将某层的计算结果再次反向连接回前面的层中。
在训练 RNN 时,涉及大量的矩阵联乘操作,容易引发梯度衰减或梯度爆炸问题。
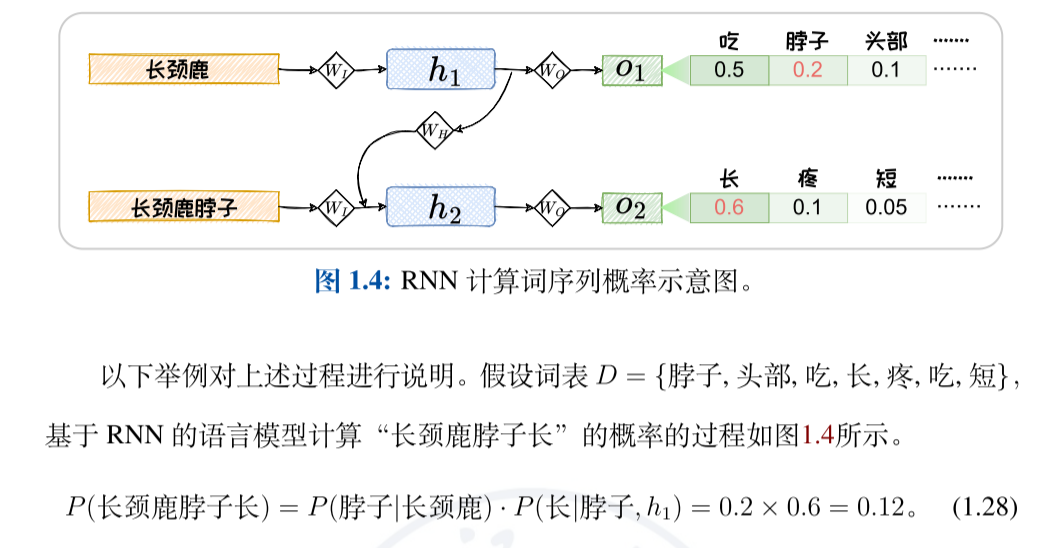
在这样一个元素一个元素依次串行输入的设定下,RNN 可以将历史状态以隐变量的形式循环叠加到当前状态上,对历史信息进行考虑,呈现出螺旋式前进的模式。
自回归:每次将本轮预测到的词拼接到本轮的输入上,输入给语言模型,完成下一轮预测。
上述“自回归”过程存在2个问题:错误级联放大;串行计算效率低。
所以引入Teacher Forcing。在Teacher Forcing中,每轮都仅将输出结果与“标准答案”(Ground Truth)进行拼接作为下一轮的输入。在图1.4所示的例子中,第二轮循环中,我们用“长颈鹿脖子”来预测下一个词“长”,而非选用 o1 中概率最高的词“吃”或者其他可能输出的词。
在Teacher Forcing 在训练中,模型将依赖于“标准答案”进行下一次的预测,但是在推理预测中,模型“自回归”的产生文本,没有“标准答案”可参考,这就是曝光偏差问题。
1.3.2 Transformer
Transformer 是一类基于注意力机制(Attention)的模块化构建的神经网络结构。给定一个序列,Transformer 将一定数量的历史状态和当前状态同时输入,然后进行加权相加。对历史状态和当前状态进行“通盘考虑”,然后对未来状态进行预测。
相较于RNN模型串行的循环迭代模式,Transformer 并行输入的特性,使其容易进行并行计算。
Transformer是由两种模块组合构建的模块化网络结构:
(1)注意力(Attention)模块;
(2)全连接前馈(Fully-connected Feedforwad)模块。
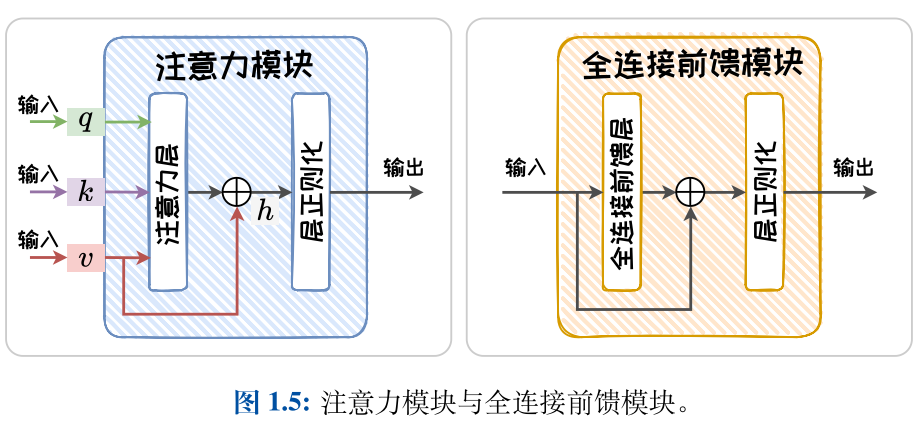
自注意力模块由自注意力层(Self-Attention Layer)、残差连接(Residual Connections)和层正则化(Layer Normalization)组成。
全连接前馈模块由全连接前馈层、残差连接和层正则化组成。
注意力层
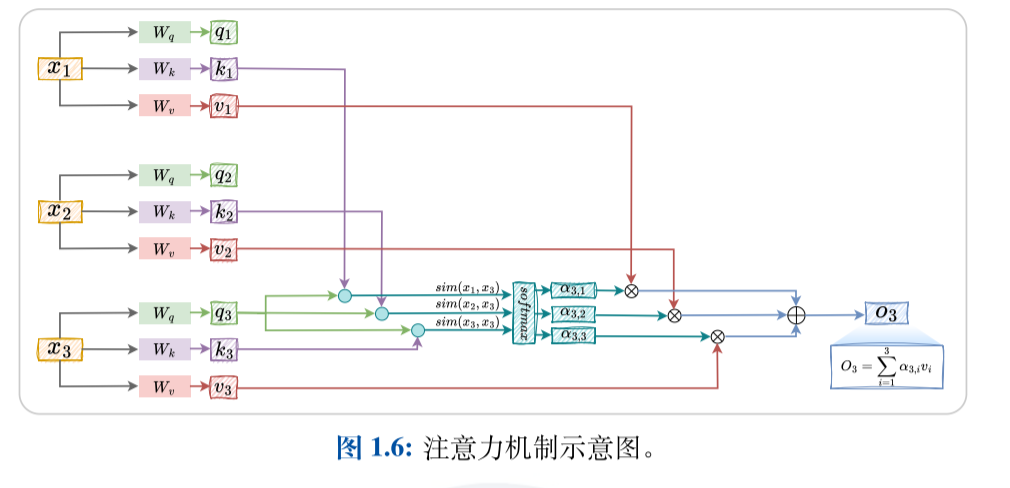
query和key用于计算自注意力的权重α, value 是对输入的编码。
sim(·, ·) 用于度量两个输入之间的相关程度,softmax 函数用于对此相关程度进行归一化。
全连接前馈层
全连接前馈层占据了Transformer近三分之二的参数,掌管着Transformer模型的记忆。其可以看作是一种 Key-Value 模式的记忆存储管理模块。全连接前馈层包含两层,两层之间由 ReLU 作为激活函数。
层正则化

残差连接
引入残差连接可以有效解决梯度消失问题。
在基本的 Transformer 编码模块中包含两个残差连接。第一个残差连接是将自注意力层的输入由一条旁路叠加到自注意力层的输出上,然后输入给层正则化。第二个残差连接是将全连接前馈层的输入由一条旁路引到全连接前馈层的输出上,然后输入给层正则化。
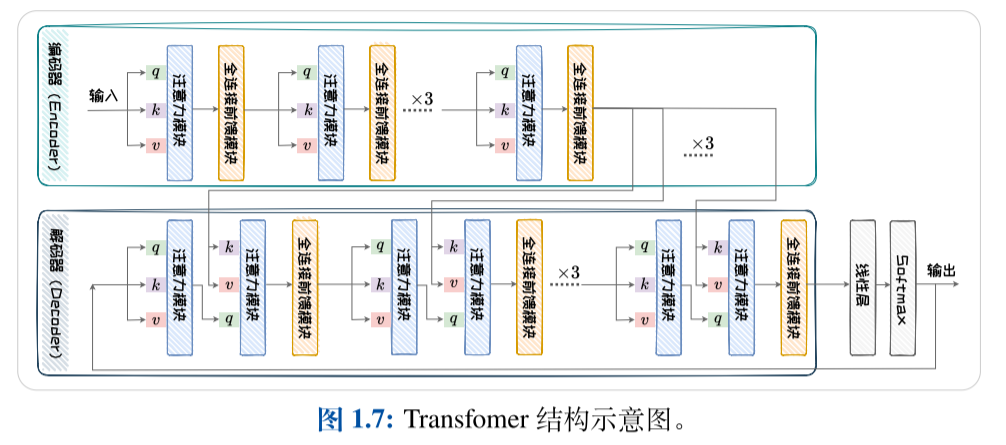
原始的 Transformer 采用 Encoder-Decoder 架构。
Encoder 部分由六个级联的 encoder layer 组成,每个encoder layer 包含一个注意力模块和一个全连接前馈模块。其中的注意力模块为自注意力模块(query,key,value 的输入是相同的)。Decoder 部分由六个级联的decoder layer 组成,每个 decoder layer 包含两个注意力模块和一个全连接前馈模块。其中,第一个注意力模块为自注意力模块,第二个注意力模块为交叉注意力模块
(query,key,value 的输入不同)
1.4 语言模型的采样和评测
1.4.1 语言模型的采样方法
语言模型的输出为一个向量,该向量的每一维代表着词典中对应词的概率。在采用自回归范式的文本生成任务中,语言模型将依次生成一组向量并将其解码为文本。两类主流的解码方法可以总结为 (1). 概率最大化方法; (2).随机采样方法
概率最大化方法
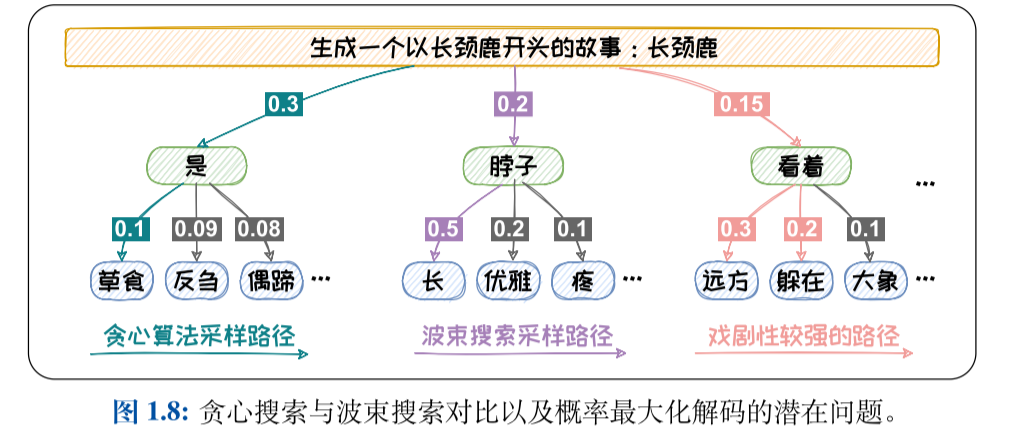
贪心搜索:贪心搜索在在每轮预测中都选择概率最大的词。当前概率大的词有可能导致后续
的词概率都很小。贪心搜索容易陷入局部最优,难以达到全局最优解。
波束搜索:波束搜索在每轮预测中都先保留b个可能性最高的词。从图1.8中可以看出如果我们采用 b = 2 的波束搜索方法,我们可以得到“是草食”,“是反刍”,“脖子长”,“脖子优雅”四个候选组合,对应的概率分别为:0.03,0.027,0.1,0.04。我们容易选择到概率最高的“脖子长”。
概率最大的文本通常是最为常见的文本,其所生成的文本缺乏多样性。为了增加生成文本的多样性,随机采样的方法在预测时增加了随机性。
随机采样方法
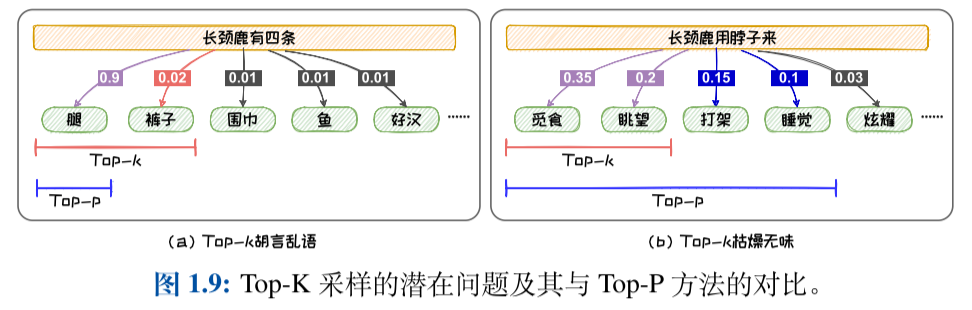
Top-k采样:指定候选词数量的方法对候选词进行选择。当候选词的分布的方差较大的时候,可能会导致本轮预测选到概率较小、不符合常理的词,从而产生“胡言乱语”;当候选词的分布的方差较小的时候,甚至趋于均匀分布时,固定尺寸的候选集中无法容纳更多的具有相近概率的词,导致候选集不够丰富,从而导致所选词缺乏新颖性而产生“枯燥无趣”的文本。
Top-p采样:划定候选词概率阈值的方法对候选词进行选择。其设定阈值p来对候选集进行选取。Top-P 采样可以避免选到概率较小、不符合常理的词,从而减少“胡言乱语”;其还可以容纳更多的具有相近概率的词,增加文本的丰富度,改善“枯燥无趣”。
Temperature机制:Temperature 机制可以对解码随机性进行调节。Temperature 机制通过Softmax函数中的自变量进行尺度变换,然后利用 Softmax 函数的非线性实现对分布的控制。当T > 1 时,Temperature 机制会使得候选集中的词的概率差距减小,分布变得更平坦,从而增加随机性。

1.4.2 语言模型的评测方法
内在评测
在内在评测中,测试文本通常由与预训练中所用的文本独立同分布的文本构成,不依赖于具体任务。最为常用的内部评测指标是困惑度(Perplexity)。由于测试文本和预训练文本同分布,预训练文本代表了我们想要让语言模型学会生成的文本,如果语言模型在这些测试文本上越不“困惑”,则说明语言模型越符合我们对其训练的初衷。
外在评测
在外在评测中,测试文本通常包括该任务上的问题和对应的标准答案,其依赖于具体任务。
基于统计指标的评测:BLEU是精度导向的指标,而ROUGE是召回导向的指标。

基于语言模型的评测:(1)基于上下文词嵌入(Contex-tual Embeddings)的评测方法;(2)基于生成模型的评测方法。典型的基于上下文词嵌入的评测方法是BERTScore。典型的基于生成模型的评测方法是G-EVAL。与BERTScore 相比,G-EVAL无需人类标注的参考答案。这使其可以更好的适应到缺乏人类标注的任务中。
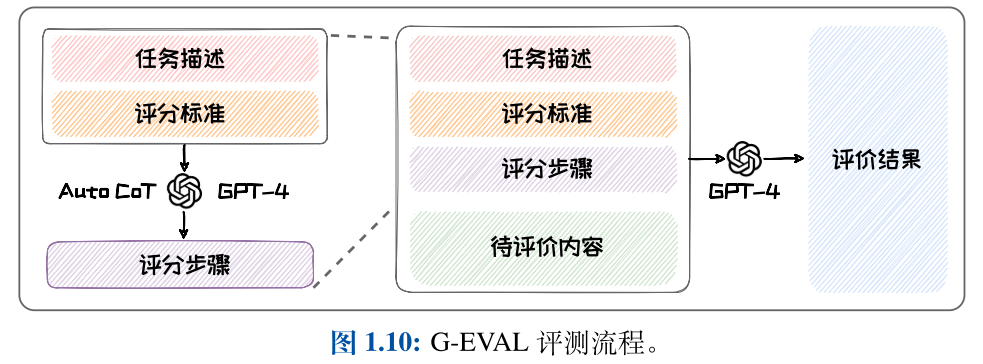
G-EVAL通过提示工程(Prompt Engineering)引导GPT-4输出评测分数。