【AI学习笔记】Coze平台实现生成小红书热门多图笔记
背景前摇&原视频教程:
最近总是在小红书上刷到多图组成的养生小妙招、效率提升小tips、退休奶奶疗愈语录等等这样的图文笔记,而且人物图像一眼就是AI画的。
当时我以为这个排版和文字是人工的,就让AI保持角色一致性画了下图,没想到在B站刷到了实现教程,才知道Coze平台已经支持很完善的一键出笔记的工作流了。
B站上优秀的视频教程:
对比了我主动搜索+推荐算法推送的教程,最后跟着UP @在下李君陌 的教程学完了整个工作流,确实成功实现了出图文笔记的效果。
原视频链接:https://www.bilibili.com/video/BV1Xa5QzpEKM/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
传送门
 而且这个UP特别好的是,把用到的演示文稿直接就放在了简介里,直接飞书就可以打开,无需再三连私信求资料,最后被卖课的反复骚扰,简直就是超级良心。
而且这个UP特别好的是,把用到的演示文稿直接就放在了简介里,直接飞书就可以打开,无需再三连私信求资料,最后被卖课的反复骚扰,简直就是超级良心。
因为原UP的视频已经很详细了,大家跟着学一定能顺利实践出真知,我就不再赘述UP的视频里面已经介绍的如何搭建工作流的相关过程了。本文只分享一些我个人遇到的问题和心得。
跟完教程后生成的图文笔记预期效果:
我这里选定的主题是“香港旅游”,想着顺带帮亲戚做个旅游攻略。







封面图+5张简单的图文笔记,效果还不错~
学习准备:
1.9.9的氪金费用,因为这个工作流有很多图像生成节点,可能Coze平台默认的额度不够用,必要时需要氪金开个个人进阶版,或者增购资源包。
2.至少两个小时的学习时间,原UP视频长约一个半小时,加上大家自己摸索、连图、调试的时间,如果是Coze新手,需要的时间会更长。
3.一些Coze平台的基础知识,至少知道如何搭建工作流和传递参数,让一个工作流完整跑起来。如果对Coze完全一无所知,建议先看Coze官方视频教程:传送门
https://www.bilibili.com/video/BV1zC35eFEyN?spm_id_from=333.788.videopod.sections&vd_source=cdfd0a0810bcc0bcdbcf373dafdf6a82
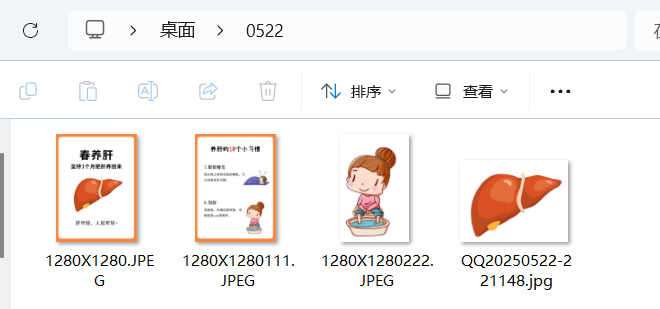
4.其他原视频UP在讲解过程中要求准备的东西,比如飞书演示文档(后面复制提示词会用到,或者实在没有的话,截图OCR文字识别也可),放在桌面上的几张组成模板用的底图。
正文:
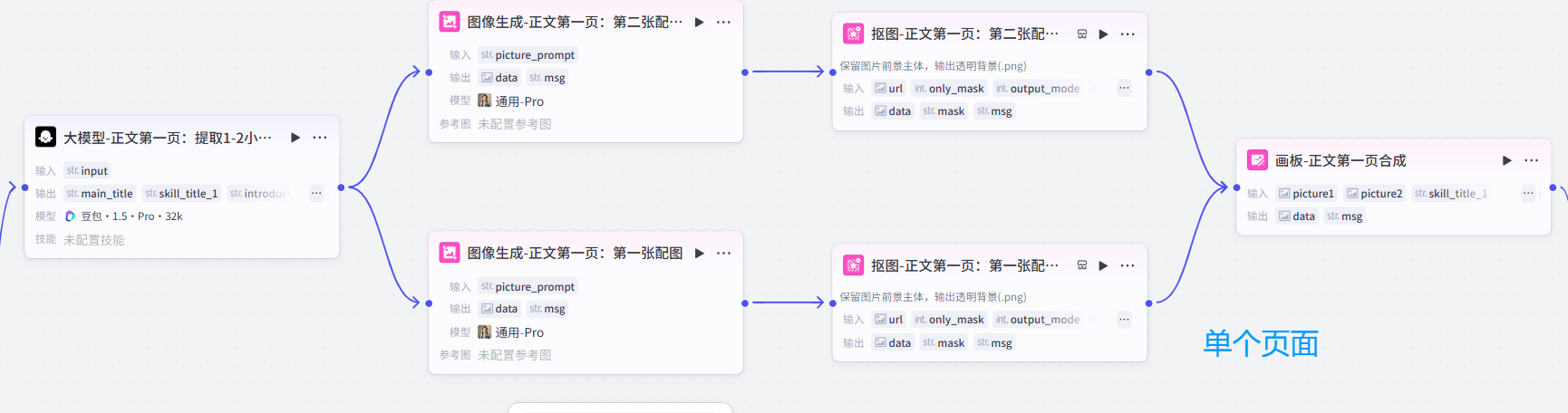
大家如果顺利跟着UP的视频走完了全流程以后,应该工作流会长下面这样:是一个能生成5张图文+一个主图封面的工作流,并且每个页面又有两张组成图片。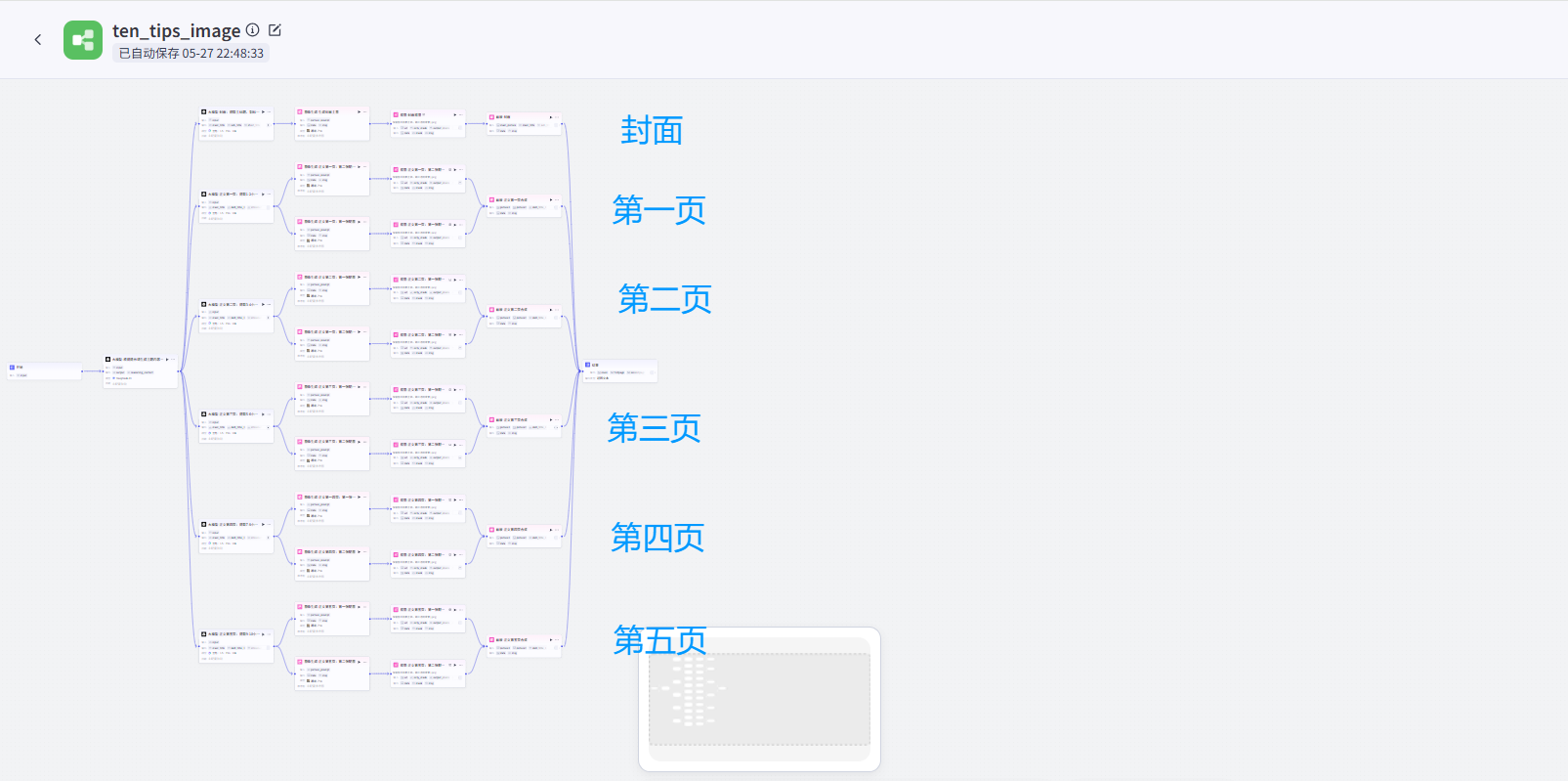

1.图像调用节点受限问题:
如果按照上面这样连接节点,逻辑是没问题的,但是调用起来会发现工作流会被中途中断,因为同时调用的图像节点太多了。
中道崩殂不说,还白烧了不少token,简直让人心疼。

B站视频评论区也有码友遇到这个问题,给出的解决方法是拆成几个工作流调用。
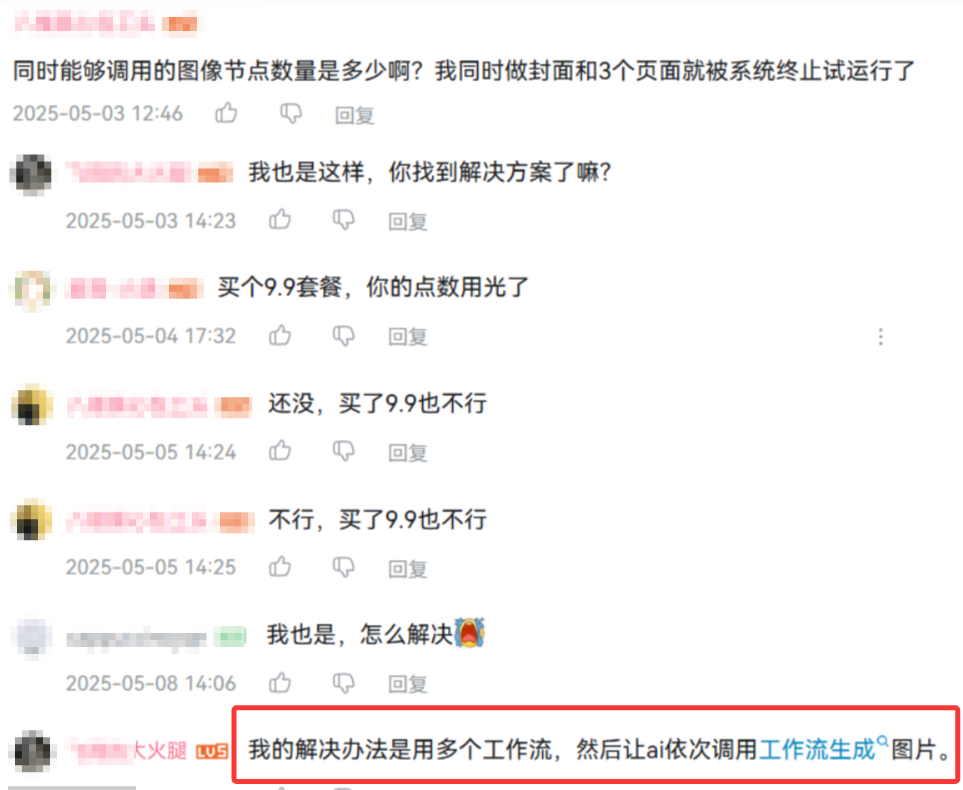
这样应该也可行,我没有自己尝试过,不过我采用了另一种方法来规避这个问题。
那就是——把工作流连成一条长直线!
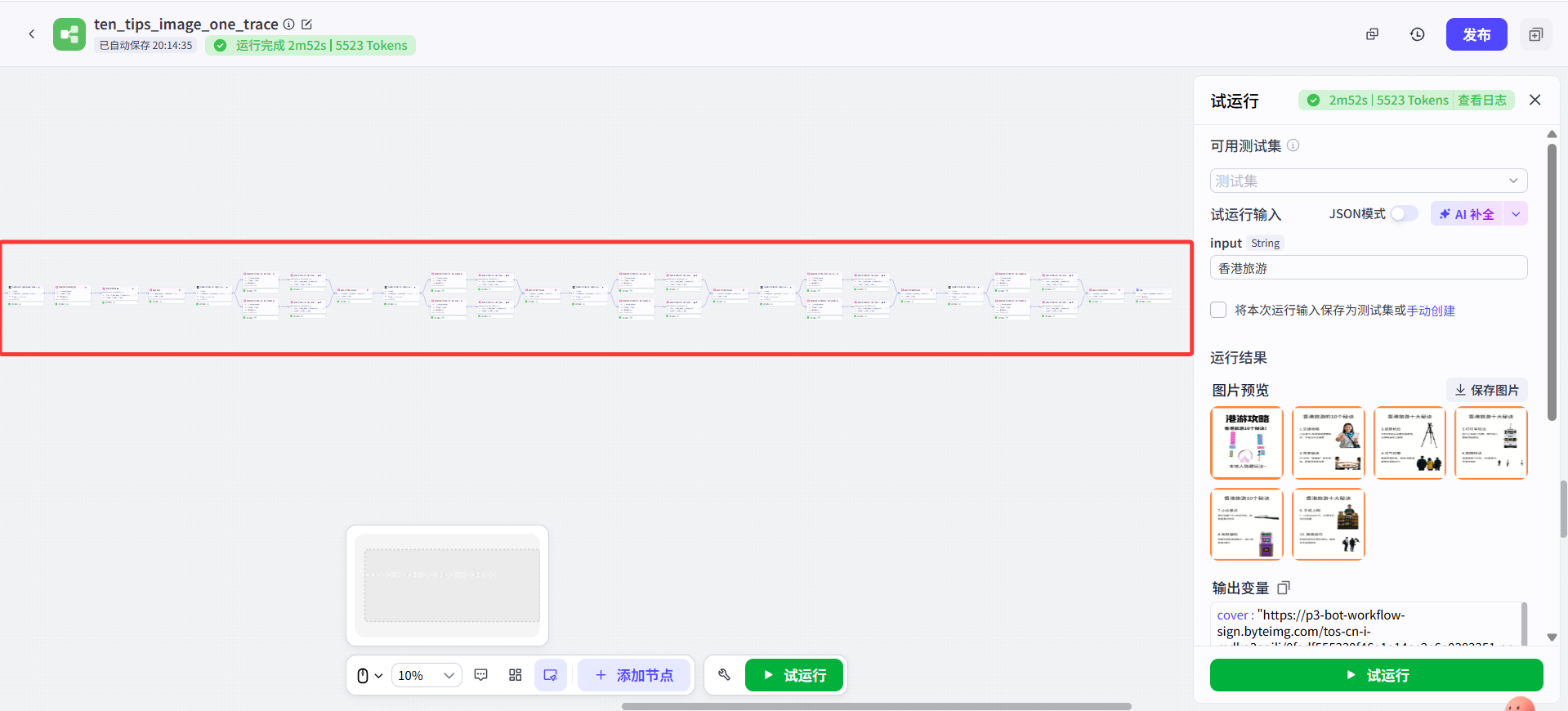
也就是说,把第一页的大模型节点和封面的画板节点连起来,再把第一页的画板节点和第二页的大模型节点连接起来。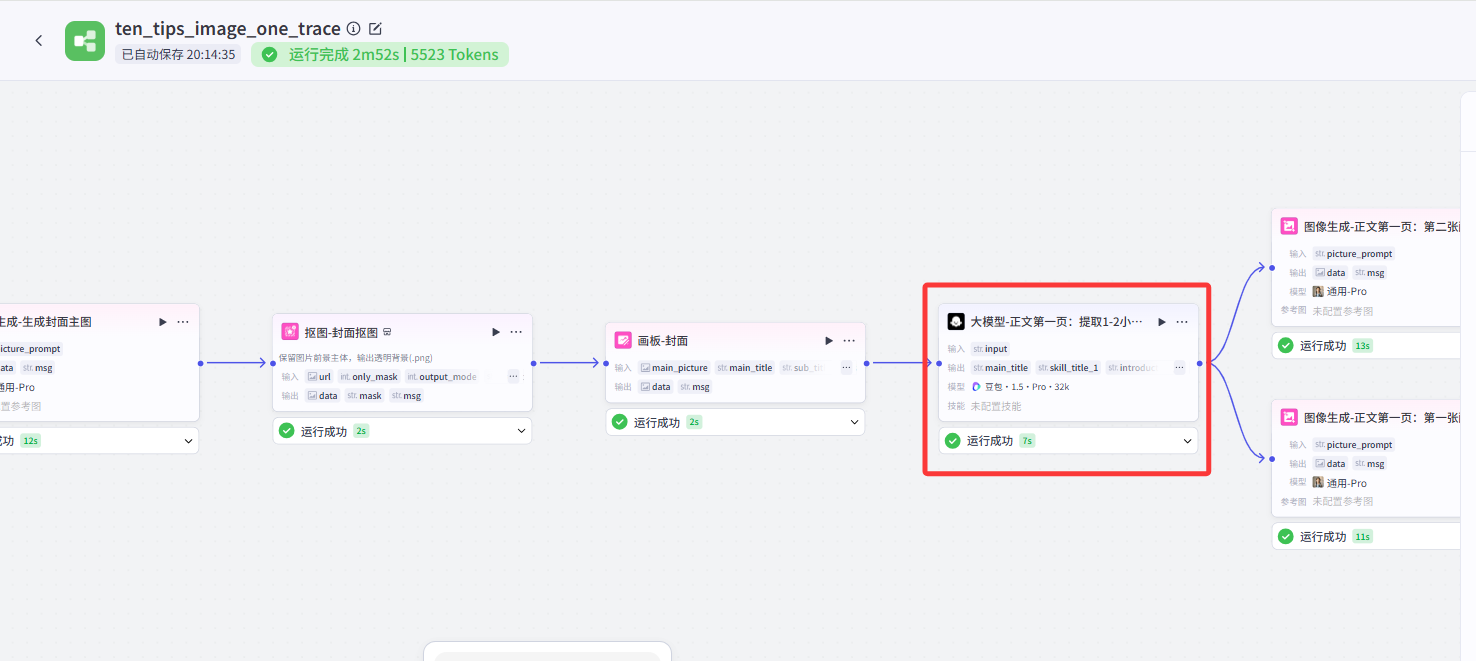
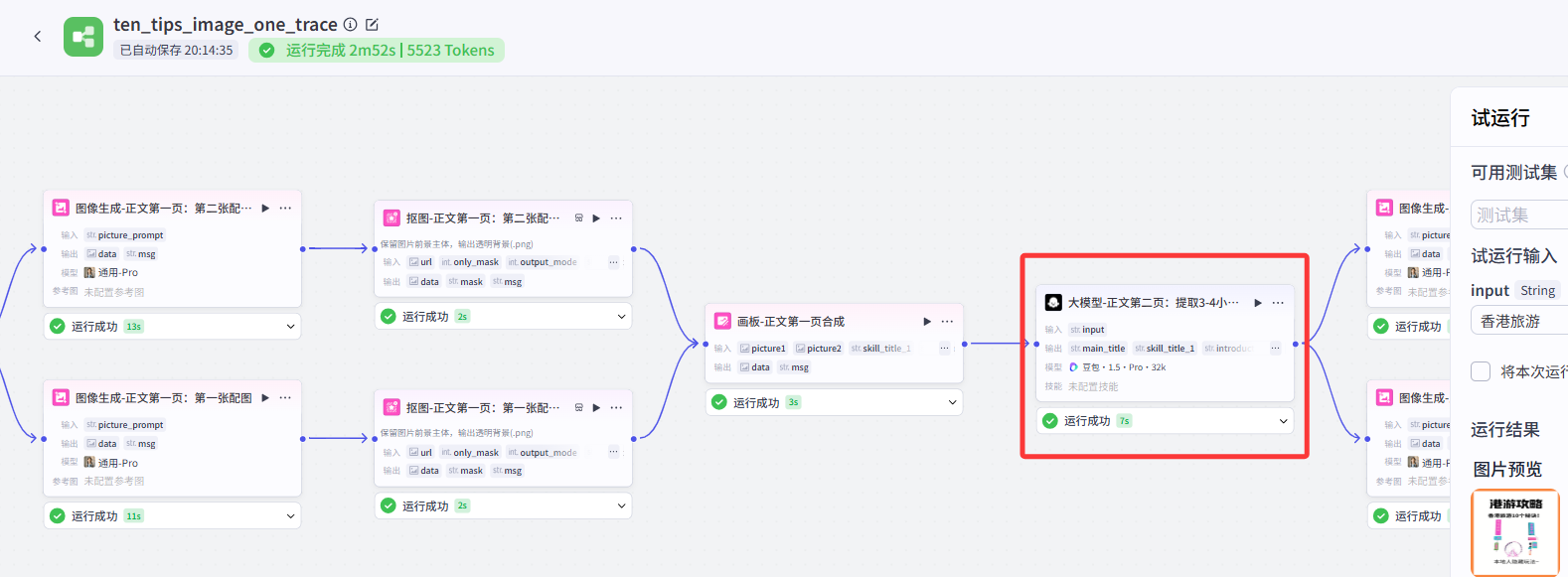 可以理解为,原作者那样的结构,封面、不同页之间是并联关系。大模型节点生成提示词以后,同时在生成封面和五页内容的图,这样就导致图像节点调用过多,超限制了。
可以理解为,原作者那样的结构,封面、不同页之间是并联关系。大模型节点生成提示词以后,同时在生成封面和五页内容的图,这样就导致图像节点调用过多,超限制了。
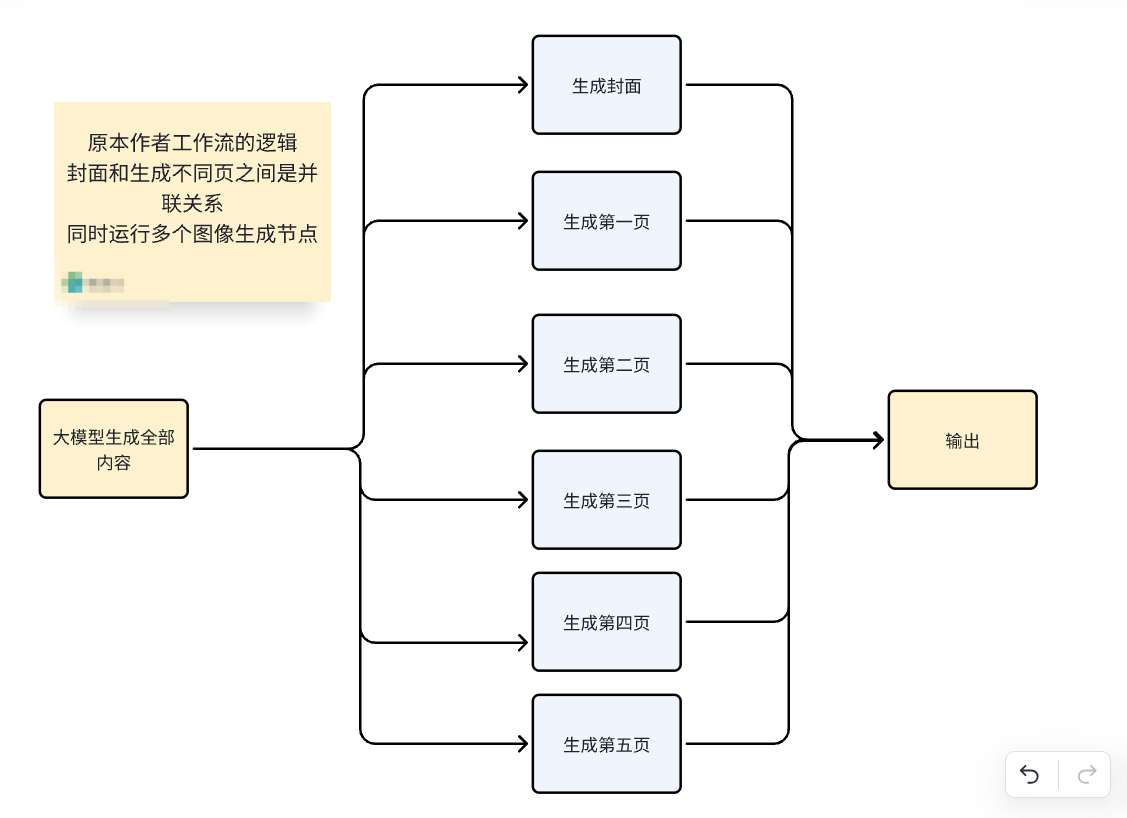
上图中单个浅蓝色的节点里面,构成了能组成一张单图的基本逻辑: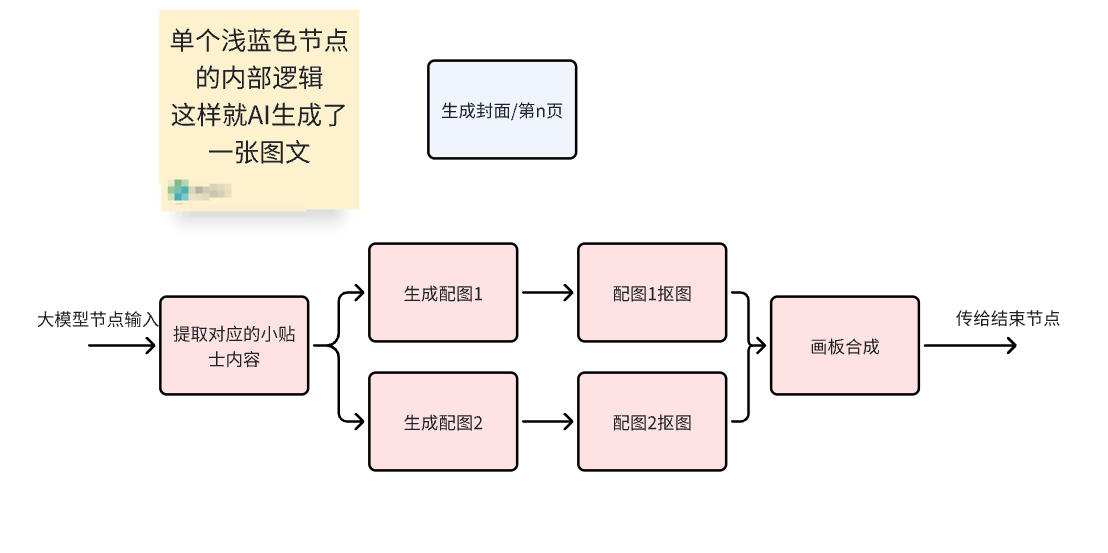
而我把封面和不同页的生成顺序变成了串联关系,先生成封面,再生成第一页,然后是第二页,单张图文笔记生成的逻辑并没有改变,所以不影响出图效果。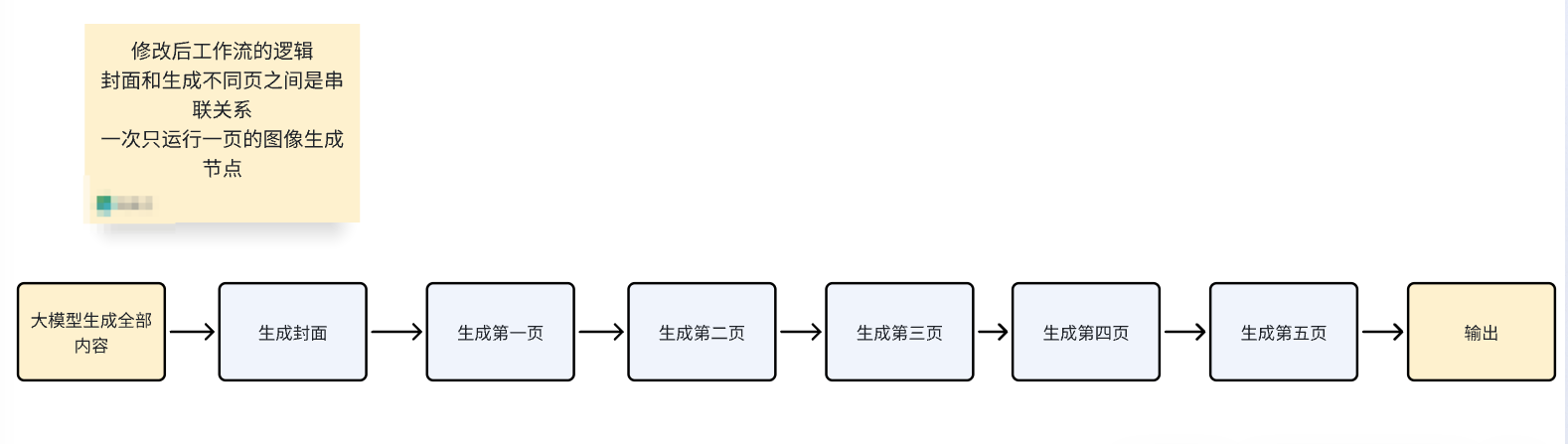
每个浅蓝色节点生成图片的逻辑依旧是这样,没有改变:
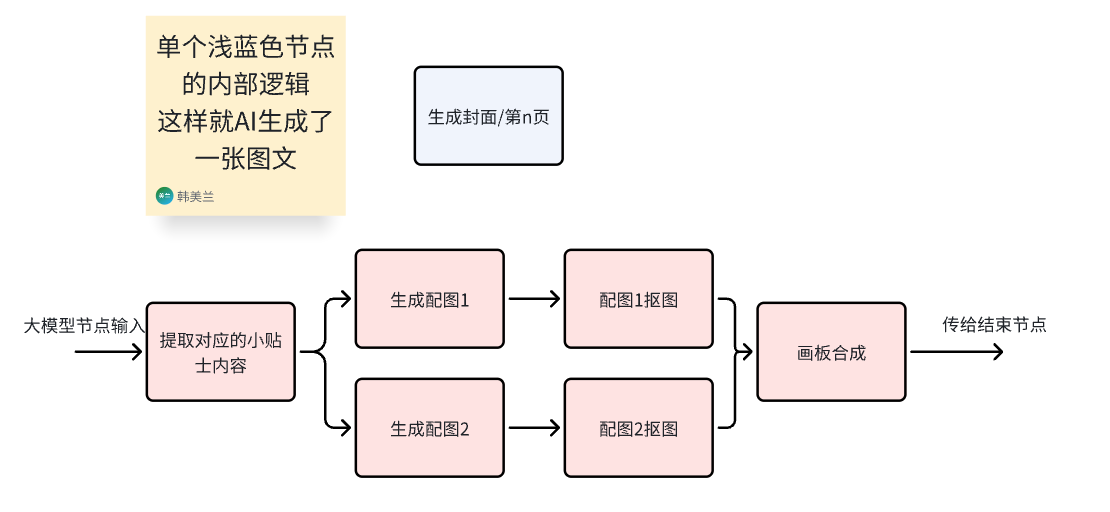
因为只要通路是连着的,后续的节点可得到前面任意节点的输出,所以并不影响每一页的大模型节点提取对应的小技巧,也不影响最后结束节点一次性输出五张图。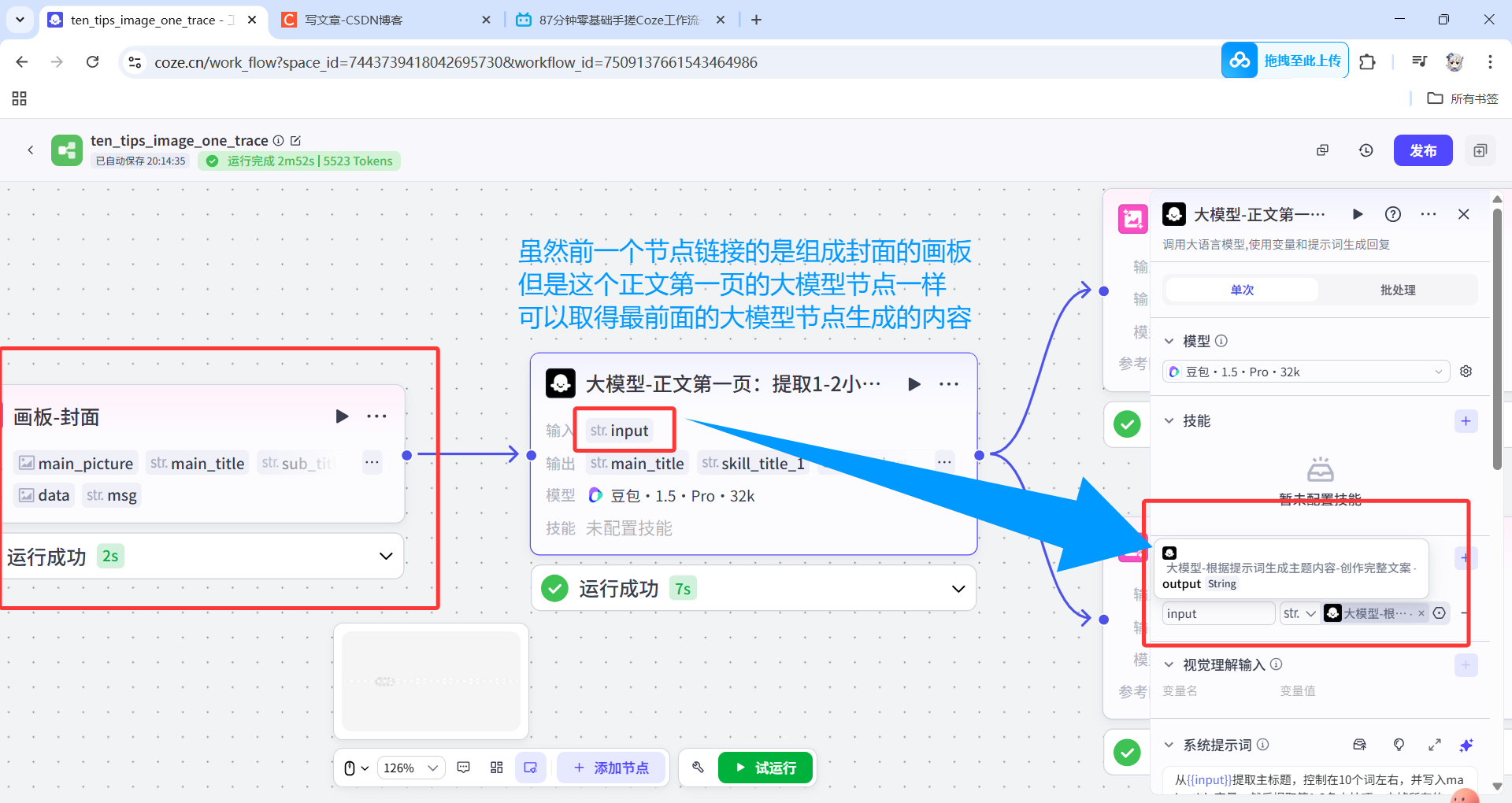
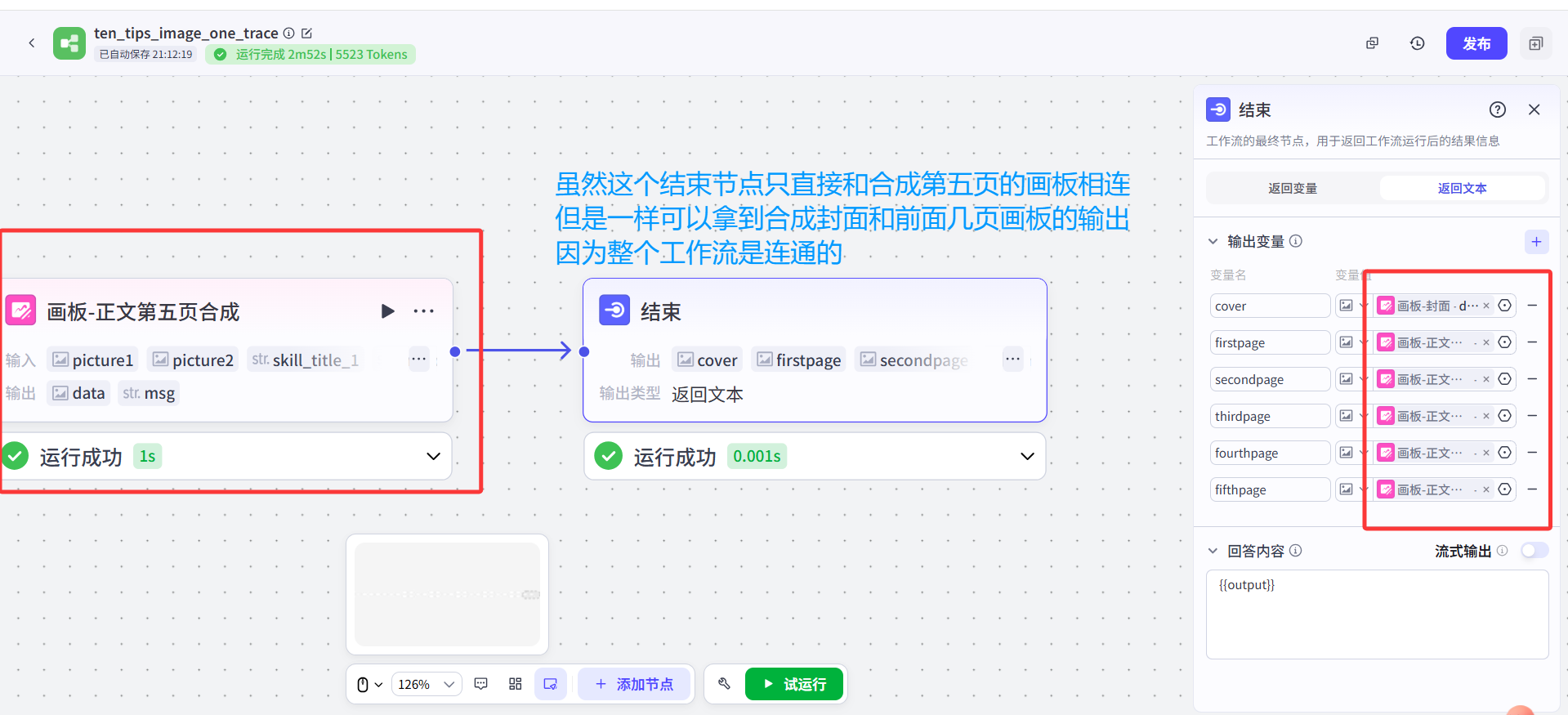
这样虽然运行速度稍微慢一些,但是一个工作流内就可以实现生成全部图文,并且不会报图像节点受限的问题。
当然,如果觉得这样摆成一长条不太美观的话,也可把生成单张页面的几个节点按shift选中(或者鼠标左键长按拖拽框选),把他们作为一个组合(可以自行选择是否封装工作流,这里我为了清晰没用封装),拖拽成一排排的。
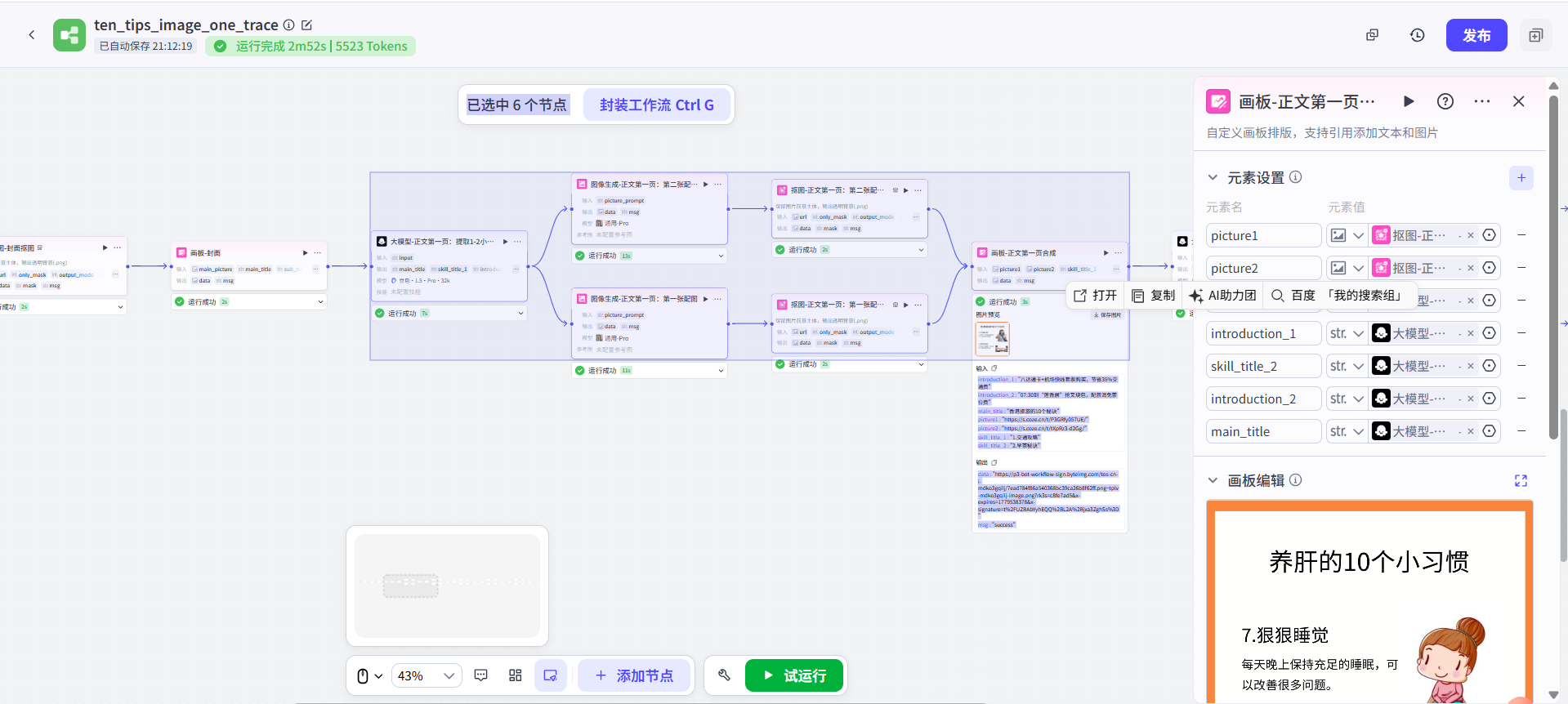
下面这样是不是就跟原视频UP的工作流比较像啦?其实在我按原UP的并联工作流改为串联逻辑以后,这就是这个串联工作流最初的样子。 其实我最开始演示的一条直线的工作流,就是现在这个工作流点击了“优化布局”按钮重排后,整个工作流被拉直后的结果。
其实我最开始演示的一条直线的工作流,就是现在这个工作流点击了“优化布局”按钮重排后,整个工作流被拉直后的结果。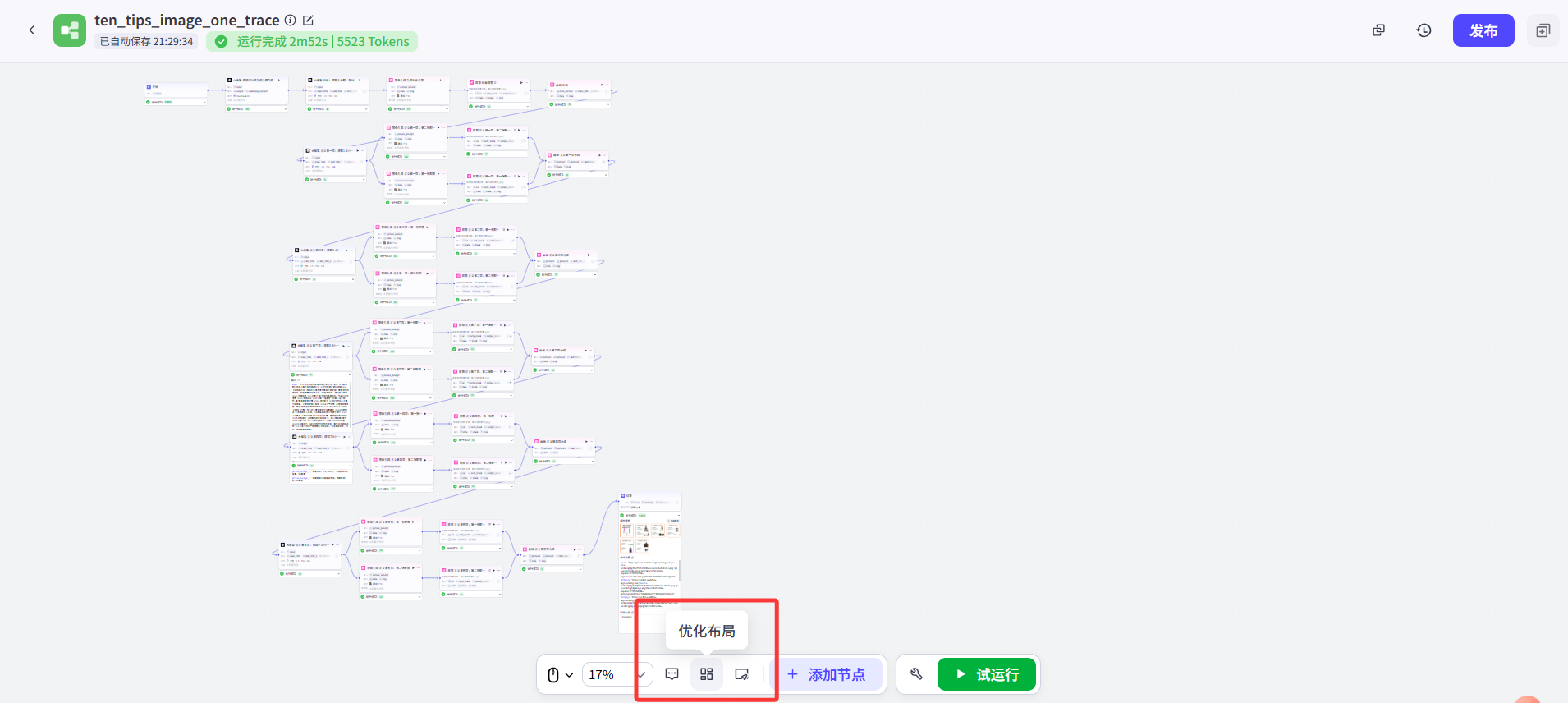
(串联工作流偶尔也会遇到执行不成功的情况,但多试几次就可以了!)
2.图片生成内容更宽泛:
原作者跟着做的模板是人类养生相关的,图片生成模型选的是“人像”,并且给了参考图,但这就导致图文笔记能生成的内容相对受限,很多图片都会画个人在中间。
但我希望做的主题是“香港旅游”,很多生成的贴士是跟旅游景点相关的,比如叮叮车、天星小轮,但是按照原来的设定,生成的很多配图主体物都是人,抠图完后基本上只剩下一个人的轮廓了,就跟我们的旅游场景不搭配。
我把所有节点选用的图像生成模型全部都改成了**“通用Pro”**,这样不但可以支持生成人像,也可以根据不同主题的提示词生成其他景物、美食等图片。通用模型画什么其实更多取决于得到什么提示词,如果前面生成提示词的大模型判断出来这个小贴士需要出现人物在画面里,通用模型也可生成。
原作者给的参考图我也去掉了,感觉有跟没有差别并不大,很多时候参考图并没有发挥其该有的作用,很多时候不但人物崩坏,还很重复,出现人长得有些相似,但是一致性又不够(就是倒像不像,很难说这俩是一个人,但又不是完全不像),画风还不统一(有的写实风,有的卡通风)、还有多手多脚、画面结构混乱等问题。
综合考虑感觉,不同小贴士之间人跟人长得一不一样并不重要,就算是养生场景,展示的路人A在泡脚,路人B在做操也没有关系。所以就让模型更自由发挥了。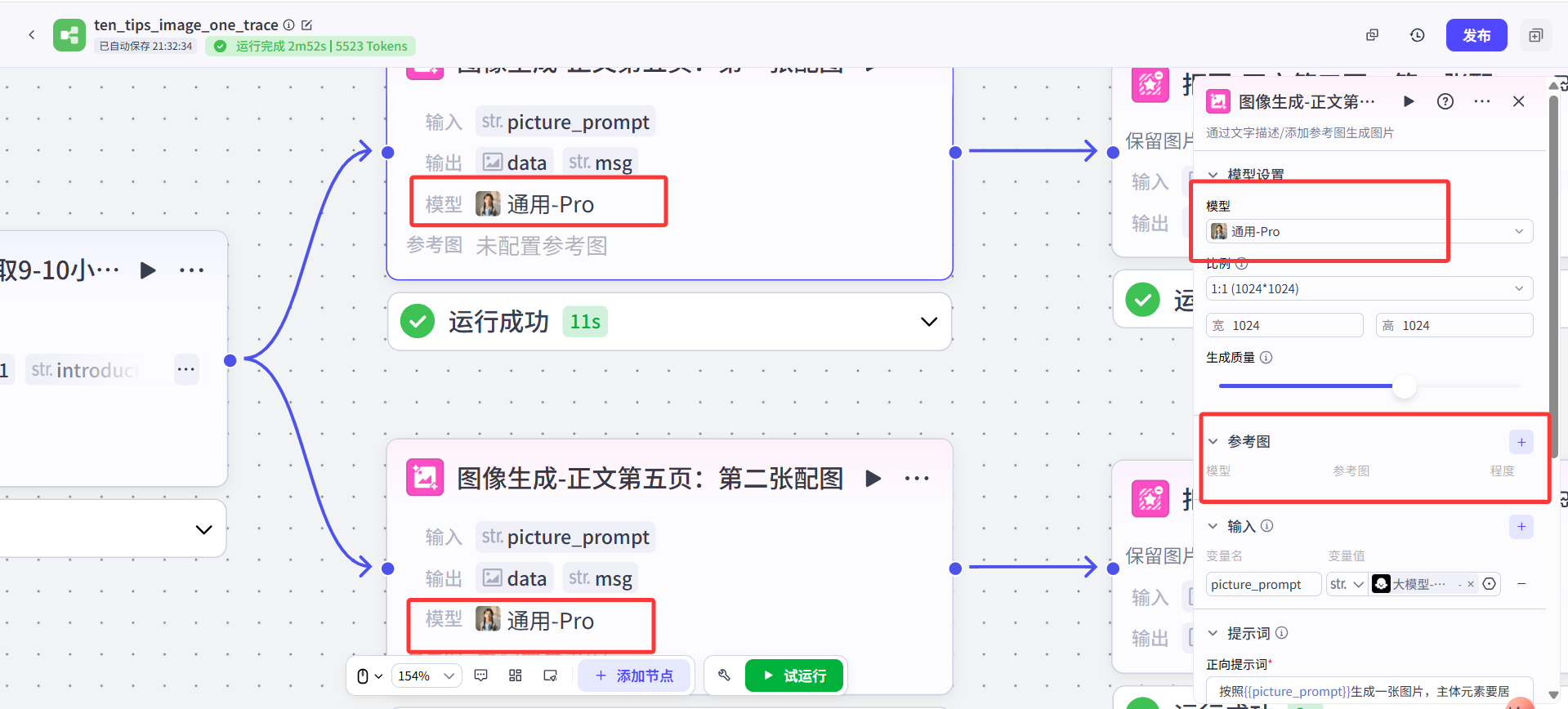
修改后,不但之前UP测试的养生、提效、告别拖延场景可适配,我想实现的旅游场景也能实现了。

3.实现图文效果的提示词:
这部分是我觉得很意外也很惊喜的点,我一直以为要生成这样有封面+五张图的内容,提示词会很复杂,这些一段那写一段,没想到总共就三个部分。
这里原视频作者写得就很好,并且因为其文档是公开分享的,我就直接截图了。
首先是这个最重要的大模型节点,除了决定吸睛的首图标题元素以外,还是后面几页内容的根基。
我一度以为要用很长的篇幅给大模型描述,我要做个什么样的小红书图文排版,各种跟他解释我整个排版要怎样关联,怎样布局…
结果居然是这样简单,就告诉他,我要主标题副标题短标题,有什么字数要求,还要按照标题生成10个符合要求的实操技巧,就完事了。
至于排版的部分,是搭建好的画板来解决,如果布局不好看,比如字数超了导致换行、没对齐,再跟大模型进一步调整限制字数的要求。

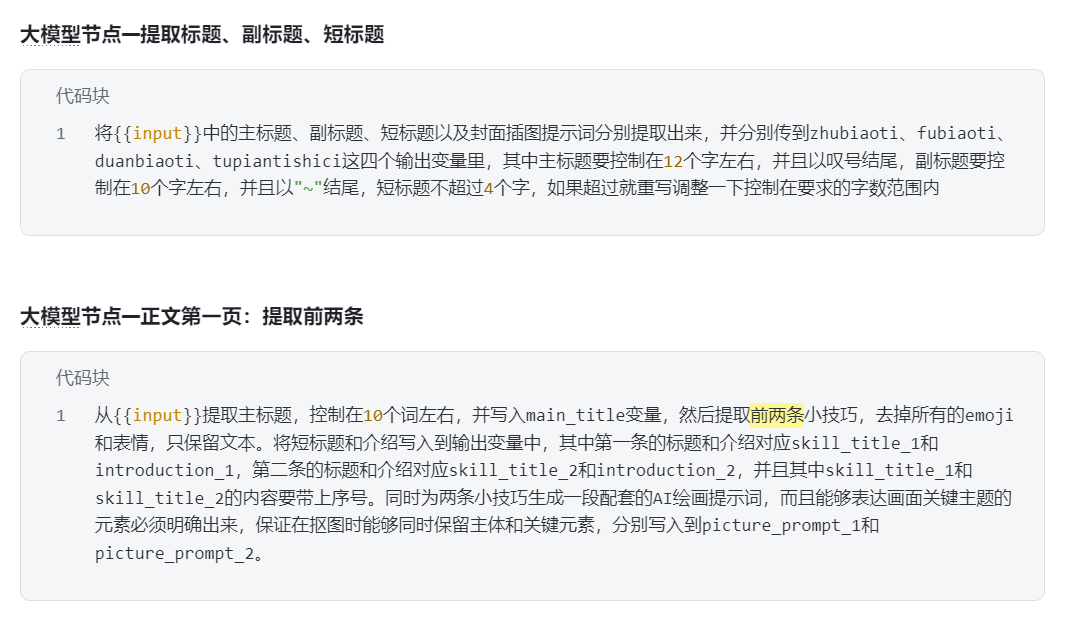
然后就是生成各页面的大模型节点,负责来提取前面生成的、自己负责的这部分小贴士的主题,并且以此进一步生成画图的提示词。
我以为提取内容这部分少说需要写代码,然后中间再把需求描述给GPT让它代劳实现代码逻辑,没想到大模型直接就把提取内容整个活做了。
原视频UP也说,简单的内容提取可以交给大模型做,确认它完成得也很优秀,免得我把需求给另外的AI描述半天,然后测试代码等折腾了。只需要针对不同页的大模型,把提取哪几条小技巧(下图黄色高亮部分,比如第一页提取1-2条小技巧,第二页提取3-4条小技巧…)改一下即可。
这段提示词同时还做了生成给后面的图像生成节点构造提示词的任务,甚至都没有分段或者分点,行云流水一气呵成,但是效果非常到位,看来模型对提示词的理解能力非常好,没用遗漏或者误解这一段话的好几个需求,可以说是《高端的食材只需要最简单的烹饪方式》?
最后就是生成图片的指令,这个就相对普通平常了,为了不至于抠完图后主体物被切掉太多部分,所以让周围留出一些距离。 整个过程是调用了三层大模型,第一层总大模型负责围绕用户输入的主题,生成标题和10个小贴士作为大的框架,第二层是每一页的大模型,负责专注自己的那部分小贴士,补全细化文本内容,并且生成给图像模型的提示词,第三层每张图的图像生成模型负责按照输入指令生成图片。
整个过程是调用了三层大模型,第一层总大模型负责围绕用户输入的主题,生成标题和10个小贴士作为大的框架,第二层是每一页的大模型,负责专注自己的那部分小贴士,补全细化文本内容,并且生成给图像模型的提示词,第三层每张图的图像生成模型负责按照输入指令生成图片。
简短总结:
整个工作流的结构,大模型、画图节点的调用方式,以及简明干练的提示词描述能力,很值得学习和借鉴,感谢原UP带来这么棒的教程。