2025-05-27 Python深度学习6——神经网络模型
文章目录
- 1 基本骨架
- 1.1 初始化
- 1.2 实现 `forward()` 方法
- 1.3 使用模型
- 2 卷积层(Convolution)
- 2.1 卷积操作
- 2.2 代码示例
- 3 池化层
- 3.1 池化操作
- 3.2 代码示例
- 4 非线性激活
- 4.1 ReLU
- 4.2 Sigmoid
- 4.3 代码实现
- 5 线性层
- 6 使用 Sequential
- 6.1 直接传入模块列表
- 6.2 使用 `OrderedDict` 命名层
- 6.3 代码示例
本文环境:
- Pycharm 2025.1
- Python 3.12.9
- Pytorch 2.6.0+cu124
1 基本骨架
nn.Module 是 PyTorch 中所有神经网络模块的基类,用于构建和管理深度学习模型。无论是简单的线性层(nn.Linear)还是复杂的 CNN(如 ResNet),它们都继承自 nn.Module。
-
基类作用
所有神经网络模块(层/模型)的基类,用于组织参数、定义前向传播。
-
关键特性
- 管理参数(如权重、偏置)和子模块(如卷积层、全连接层)。
- 必须实现 forward() 方法定义计算逻辑。
- 自动支持反向传播(通过 Autograd)。

1.1 初始化
-
在
__init__()方法中初始化模型属性。class MyModel(nn.Module):def __init__(self):super().__init__() # 必须调用父类初始化# 在这里定义模型层/参数
1.2 实现 forward() 方法

-
在
forward()方法中实现数据流的计算逻辑。 -
通过逐层运算完成输入到输出的映射。
def forward(self, input):# 定义前向传播逻辑output = input + 1return output
1.3 使用模型
# 实例化模型
model = MyModel()# 准备输入数据
x = torch.tensor(1)# 调用模型(会自动调用forward方法)
output = model(x) # 调用模型实例来触发前向传播print(output)

注意事项:
- 必须继承
nn.Module:所有自定义模型都应继承自nn.Module。 - 必须调用
super().__init__():在__init__方法中初始化父类。 - 实现
forward方法:定义模型的前向传播逻辑。 - 不要直接调用
forward:应该通过调用模型实例来触发前向传播。
2 卷积层(Convolution)
2.1 卷积操作
卷积操作通过滑动一个称为卷积核(或滤波器)的小矩阵对输入数据进行局部加权求和。
卷积操作的主要功能是提取局部特征:
- 底层卷积提取边缘、颜色变化等低级特征。
- 中层卷积提取纹理、图案等中级特征。
- 高层卷积提取物体部件等高级特征。
通过图像动画直观理解卷积的行为
(动画源:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md)。
Pytorch 中的卷积层:https://docs.pytorch.org/docs/stable/nn.html#convolution-layers。
| 卷积类型 | 输入维度 | 卷积核维度 | 典型应用场景 |
|---|---|---|---|
| Conv1d | (batch_size, channels, length) | (out_channels, in_channels, kernel_size) | 时序数据、文本、音频信号 |
| Conv2d | (batch_size, channels, height, width) | (out_channels, in_channels, kernel_height, kernel_width) | 图像处理、2D 特征图 |
| Conv3d | (batch_size, channels, depth, height, width) | (out_channels, in_channels, kernel_depth, kernel_height, kernel_width) | 视频处理、3D 医学图像 |
以 Conv2d 为例:

Conv2d 对输入的多通道信号(如 RGB 图像)执行二维卷积操作,提取空间特征。其数学表达式为:
o u t ( N i , C o u t j ) = b i a s ( C o u t j ) + ∑ k = 0 C i n − 1 w e i g h t ( C o u t j , k ) ⋆ i n p u t ( N i , k ) \mathrm{out}(N_i,C_{\mathrm{out}_j})=\mathrm{bias}(C_{\mathrm{out}_j})+\sum_{k=0}^{C_{\mathrm{in}}-1}\mathrm{weight}(C_{\mathrm{out}_j},k)\star\mathrm{input}(N_i,k) out(Ni,Coutj)=bias(Coutj)+k=0∑Cin−1weight(Coutj,k)⋆input(Ni,k)
其中:
- ⋆ \star ⋆ 表示 2D 互相关运算(实际实现中与卷积等价,但无需翻转核)。
- 输入尺寸: ( N , C i n , H i n , W i n ) (N,C_{\mathrm{in}},H_{\mathrm{in}},W_{\mathrm{in}}) (N,Cin,Hin,Win) 或 ( C i n , H i n , W i n ) (C_{\mathrm{in}},H_{\mathrm{in}},W_{\mathrm{in}}) (Cin,Hin,Win)。
- 输出尺寸: ( N , C o u t , H o u t , W o u t ) (N,C_{\mathrm{out}},H_{\mathrm{out}},W_{\mathrm{out}}) (N,Cout,Hout,Wout) 或 ( C o u t , H o u t , W o u t ) (C_{\mathrm{out}},H_{\mathrm{out}},W_{\mathrm{out}}) (Cout,Hout,Wout)。
- 输出尺寸公式:
H o u t = ⌊ H i n + 2 × padding [ 0 ] − dilation [ 0 ] × ( kernel_size [ 0 ] − 1 ) − 1 stride [ 0 ] + 1 ⌋ W o u t = ⌊ W i n + 2 × padding [ 1 ] − dilation [ 1 ] × ( kernel _ size [ 1 ] − 1 ) − 1 stride [ 1 ] + 1 ⌋ \begin{aligned}H_{out}&=\left\lfloor\frac{H_{in}+2\times\text{padding}[0]-\text{dilation}[0]\times(\text{kernel\_size}[0]-1)-1}{\text{stride}[0]}+1\right\rfloor\\W_{out}&=\left\lfloor\frac{W_{in}+2\times\text{padding}[1]-\text{dilation}[1]\times(\text{kernel}\_\text{size}[1]-1)-1}{\text{stride}[1]}+1\right\rfloor\end{aligned} HoutWout=⌊stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1⌋=⌊stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1⌋
| 参数 | 说明 | 示例值 |
|---|---|---|
in_channels | 输入通道数(如 RGB 图像为 3) | 3 |
out_channels | 输出通道数(卷积核数量) | 16 |
kernel_size | 卷积核尺寸(整数或元组) | 3 或 (3, 5) |
stride | 滑动步长(控制输出尺寸缩减) | 2 或 (2, 1) |
padding | 填充像素数(保持输入输出尺寸一致) | 1 或 (0, 1) |
padding_mode | 填充模式('zeros'、'reflect'、'replicate') | 'zeros' |
dilation | 空洞卷积的扩张率(增大感受野) | 2 |
groups | 分组卷积(groups=in_channels时为深度卷积) | 1(标准卷积) |
bias | 是否添加可学习偏置 | True |
2.2 代码示例
-
数据加载
- CIFAR-10 数据集:包含 10 类 32×32 彩色图像,共 60,000 张(50,000 训练 + 10,000 测试)。
transform=ToTensor():将 PIL 图像转换为 PyTorch 张量并归一化到 [0, 1] 范围。- DataLoader:实现批量加载 (batch_size=64) 和潜在的多进程数据加载。
import torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from torchvision import transforms# 加载CIFAR10数据集 dataset = torchvision.datasets.CIFAR10(root='./dataset', # 数据集存放路径train=False, # 是否为训练集download=True, # 是否下载数据集transform=transforms.ToTensor() # 数据预处理 )# 加载数据集 dataloader = DataLoader(dataset, batch_size=64) # 每个批次加载64张图片 -
定义模型
- 输入输出通道:3→9(CIFAR-10 是 RGB 三通道输入)。
- 卷积核参数:3×3大小,步长 1,无填充 (padding=0)。
- 输出尺寸计算:(32−3)/1+1=30,所以输出为 9 通道的 30×30 特征图。
# 定义模型 class MyModel(nn.Module):def __init__(self):# 调用父类的初始化方法super(MyModel, self).__init__()# 定义卷积层,输入通道数为3,输出通道数为9,卷积核大小为3,步长为1,填充为0self.conv1 = nn.Conv2d(3, 9, 3, stride=1, padding=0) -
可视化
- SummaryWriter:TensorBoard 日志记录工具。
reshape操作:将 9 通道输出转换为 3 通道组(因为 TensorBoard 默认显示 3 通道图像)。add_images:记录批次图像数据用于可视化对比。
# 实例化模型 model = MyModel()# 创建SummaryWriter对象,用于记录训练过程中的数据 writer = SummaryWriter('logs') step = 0 # 遍历数据集 for data in dataloader:imgs, targets = data # 获取图片和标签output = model(imgs).reshape((-1, 3, 30, 30)) # 将 9 通道输出转换为 3 通道组print(imgs.shape) # 打印输入图片的形状print(output.shape) # 打印输出图片的形状# 将输入图片和输出图片添加到SummaryWriter中writer.add_images('input', imgs, step)writer.add_images('output', output, step)step += 1 # 更新步数# 关闭SummaryWriter writer.close()数据流变化如下:
输入: [64, 3, 32, 32] (batch, channel, height, width) ↓ 卷积(3→9通道) 输出: [64, 9, 30, 30] ↓ reshape 显示: [192, 3, 30, 30] (将9通道分为3组3通道图像)
可视化后的输入与输出结果如下,原始的输入图片被拆分为 3 张输出图片:

3 池化层
3.1 池化操作
池化是一种**降采样(downsampling)**操作,它通过滑动窗口在输入特征图上提取局部区域的特征值,然后根据池化类型(最大池化、平均池化等)输出该区域的代表值。
主要作用
- 降维:减少特征图的空间尺寸,降低后续层的计算负担。
- 特征不变性:增强模型对位置变化的鲁棒性(平移、旋转等)。
- 防止过拟合:通过减少参数数量,抑制模型对训练数据的过度拟合。
- 扩大感受野:使后续层能看到更广的输入区域。
常见类型
-
最大池化(Max Pooling)
最大池化选取窗口区域内的最大值作为输出,能够保留最显著的特征。

-
平均池化(Average Pooling)
计算窗口区域内的平均值,能保留整体特征但可能丢失显著特征。
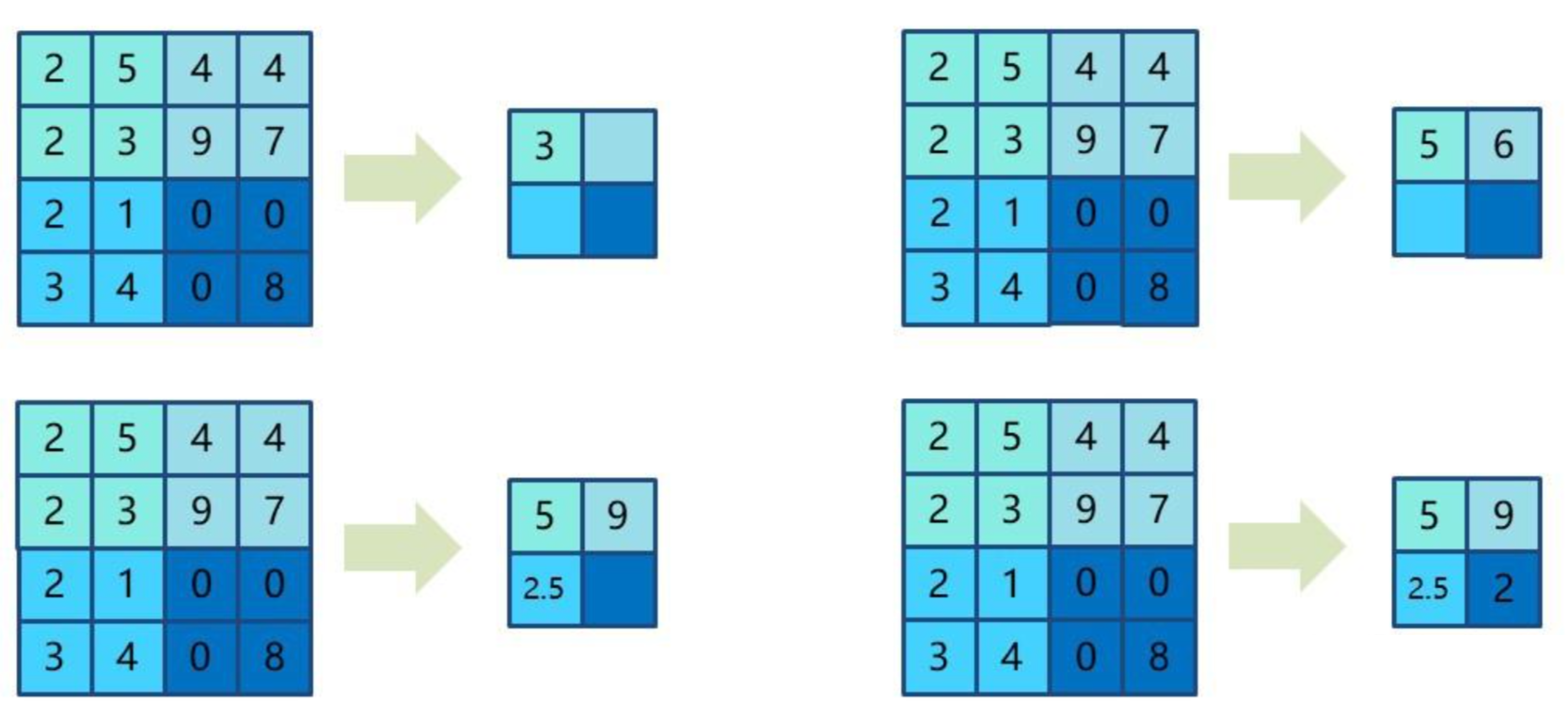
以 MaxPool2d 为例:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
-
kernel_size:池化窗口大小,可以是整数(如 3 表示 3×3 窗口)或元组(如 (3, 2) 表示 3×2 窗口)。 -
stride:窗口移动步长,默认等于 kernel_size。若为元组(如 (2, 1)),则分别指定高度和宽度方向的步长。 -
padding:输入边缘的填充量(默认为 0),填充值为负无穷。可以是整数或元组。 -
dilation:控制窗口内元素的间距(默认为 1),用于扩大感受野。 -
return_indices:若为 True,返回最大值索引,用于后续反池化(如 MaxUnpool2d)。 -
ceil_mode:若为 True,输出尺寸向上取整;默认为 False(向下取整)。 -
输入尺寸: ( N , C , H i n , W i n ) (N,C,H_{\mathrm{in}},W_{\mathrm{in}}) (N,C,Hin,Win) 或 ( C , H i n , W i n ) (C,H_{\mathrm{in}},W_{\mathrm{in}}) (C,Hin,Win)。
-
输出尺寸: ( N , C , H o u t , W o u t ) (N,C,H_{\mathrm{out}},W_{\mathrm{out}}) (N,C,Hout,Wout) 或 ( C , H o u t , W o u t ) (C,H_{\mathrm{out}},W_{\mathrm{out}}) (C,Hout,Wout)。
3.2 代码示例
-
对张量池化。
import torch import torchvision from torch import nn# 创建一个5x5的二维张量 input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]]) # 将张量reshape为1x5x5的形状 input = input.reshape((1, 5, 5)) # 打印张量的形状 print(input)# 定义一个自定义的模型类 class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()# 定义一个最大池化层,池化核大小为3,ceil_mode=True表示向上取整self.maxpool1 = nn.MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, x):# 对输入张量进行最大池化操作y = self.maxpool1(x)return y# 创建模型实例 model = MyModel() # 对输入张量进行前向传播 output = model(input) # 打印输出张量 print(output)工作原理:
-
输入 5×5 矩阵,池化核大小 3×3,步幅默认为 kernel_size (即 3)。
-
由于
ceil_mode=True,输出尺寸向上取整为 2×2。 -
计算过程:在 3×3 窗口内取最大值,然后滑动窗口。

-
-
可视化池化操作。
import torch import torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from torchvision import transforms# 加载CIFAR10数据集 dataset = torchvision.datasets.CIFAR10(root='./dataset', # 数据集的根目录train=False, # 是否为训练集download=True, # 是否下载数据集transform=transforms.ToTensor() # 数据集的转换 )# 创建数据加载器 dataloader = DataLoader(dataset, batch_size=64)# 定义一个自定义的模型类 class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()# 定义一个最大池化层,池化核大小为3,ceil_mode=True表示向上取整self.maxpool1 = nn.MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, x):# 对输入张量进行最大池化操作y = self.maxpool1(x)return y# 创建模型实例 model = MyModel()# 创建一个SummaryWriter对象,用于记录训练过程中的数据 writer = SummaryWriter('logs') # 初始化step为0 step = 0 # 遍历dataloader中的数据 for data in dataloader:# 获取输入图片和目标标签imgs, targets = data# 将输入图片添加到SummaryWriter中writer.add_images('input', imgs, step)# 使用模型对输入图片进行预测output = model(imgs)# 将预测结果添加到SummaryWriter中writer.add_images('output', output, step)# step加1step += 1# 关闭SummaryWriter writer.close()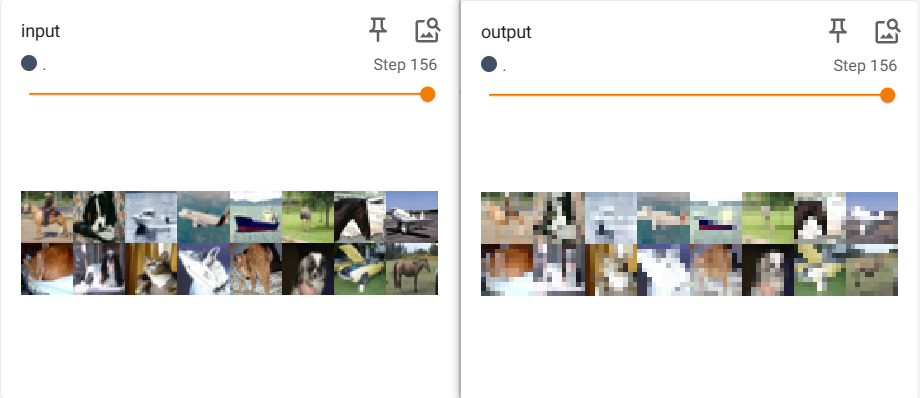
4 非线性激活
非线性激活函数是神经网络中引入非线性特性的核心组件,决定神经元是否被激活以及如何传递信息。
为什么需要非线性激活?
- 打破线性限制:没有激活函数时,多层网络等价于单层线性变换。
- 增强表达能力:可以逼近任意复杂函数(万能逼近定理)。
- 实现特征分层提取:从低级特征(边缘)到高级特征(物体)的逐步抽象。
4.1 ReLU
数学表达式:
R e L U ( x ) = ( x ) + = max ( 0 , x ) \mathrm{ReLU}(x)=(x)^+=\max(0,x) ReLU(x)=(x)+=max(0,x)

- 计算高效(无指数运算)。
- 缓解梯度消失(正区间梯度恒为 1)。
- 可能导致"神经元死亡"(负输入梯度为 0)。
4.2 Sigmoid
数学表达式:
S i g m o i d ( x ) = σ ( x ) = 1 1 + exp ( − x ) \mathrm{Sigmoid}(x)=\sigma(x)=\frac1{1+\exp(-x)} Sigmoid(x)=σ(x)=1+exp(−x)1
- 输出范围 (0, 1),适合概率输出。
- 存在梯度消失问题(当 |x| 较大时梯度接近 0)。
- 输出非零中心,可能影响梯度下降效率。

4.3 代码实现
以 Sigmoid 为例:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms# 加载CIFAR10数据集
dataset = torchvision.datasets.CIFAR10(root='./dataset', # 数据集的根目录train=False, # 是否为训练集download=True, # 是否下载数据集transform=transforms.ToTensor() # 数据集的转换
)# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=64)# 定义一个自定义的模型类
class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.sigmoid1 = nn.Sigmoid()def forward(self, x):y = self.sigmoid1(x) # 将输入x通过Sigmoid激活函数得到输出yreturn y# 创建模型实例
model = MyModel()# 创建一个SummaryWriter对象,用于记录训练过程中的数据
writer = SummaryWriter('logs')
# 初始化step为0
step = 0
# 遍历dataloader中的数据
for data in dataloader:# 获取输入图片和目标标签imgs, targets = data# 将输入图片添加到SummaryWriter中writer.add_images('input', imgs, step)# 使用模型对输入图片进行预测output = model(imgs)# 将预测结果添加到SummaryWriter中writer.add_images('output', output, step)# step加1step += 1# 关闭SummaryWriter
writer.close()

5 线性层
线性层(又称全连接层,Fully Connected Layer)是神经网络中最基础的组件之一,其核心功能是通过线性变换将输入数据映射到输出空间。数学表达式为:
y = W x + b y=Wx+b y=Wx+b
其中:
- x x x:输入向量,形状为
(batch_size, in_features) - W W W:权重矩阵,形状为
(out_features, in_features) - b b b:偏置向量,形状为
(out_features,) - y y y:输出向量,形状为
(batch_size, out_features)

作用
- 特征变换:将高维输入(如图像展平后的像素值)映射到低维输出(如类别概率),实现特征降维或升维。
- 线性组合:通过权重矩阵 W W W 学习输入特征之间的线性关系,偏置 b b b 提供平移灵活性。
- 与其他层配合:通常与非线性激活函数(如 ReLU)结合,增强模型的表达能力。
| 特性 | 说明 |
|---|---|
| 权重共享 | 同一批次的所有样本共享相同的 W W W 和 b b b。 |
| 自动求导 | PyTorch 自动计算梯度,支持反向传播优化 W W W 和 b b b。 |
| 多维输入支持 | 输入可以是任意维度,线性层仅对最后一维变换(如 (N,C,H,W) → (N,C,H,out_features)) |
代码示例
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms# 加载CIFAR10数据集
dataset = torchvision.datasets.CIFAR10(root='./dataset', # 数据集的根目录train=False, # 是否为训练集download=True, # 是否下载数据集transform=transforms.ToTensor() # 数据集的转换
)# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=64, drop_last=True)# 定义一个自定义的模型类
class MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.linear1 = nn.Linear(196608 // 64, 10)def forward(self, x):y = self.linear1(x)return y# 创建模型实例
model = MyModel()# 创建一个SummaryWriter对象,用于记录训练过程中的数据
writer = SummaryWriter('logs')
# 初始化step为0
step = 0
# 遍历dataloader中的数据
for data in dataloader:# 获取输入图片和目标标签imgs, targets = data# 将输入图片添加到SummaryWriter中writer.add_images('input', imgs, step)# 使用模型对输入图片进行预测output = model(imgs.reshape(64, 1, 1, -1))# 将预测结果添加到SummaryWriter中writer.add_images('output', output, step)# step加1step += 1# 关闭SummaryWriter
writer.close()

6 使用 Sequential
nn.Sequential 是 PyTorch 中的一个容器模块,用于按顺序组织多个子模块(如神经网络层)。它简化了模型的构建过程,适用于线性堆叠的网络结构。
- 顺序执行:
nn.Sequential中的模块按定义的顺序依次执行,前一层的输出自动作为下一层的输入。 - 简化代码:无需在
forward方法中显式调用每一层,只需调用Sequential实例即可。
6.1 直接传入模块列表
直接按顺序传入神经网络层,输入数据会依次通过这些层。
模块按顺序编号(如 model1[0] 表示第一层)。
self.model1 = nn.Sequential(nn.Conv2d(3, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, padding=2),# ... 其他层
)print(model[0]) # 通过索引访问
6.2 使用 OrderedDict 命名层
可通过名字访问特定层(如 model1.conv1)。
from collections import OrderedDictself.model1 = nn.Sequential(OrderedDict([('conv1', nn.Conv2d(3, 32, 5, padding=2)),('pool1', nn.MaxPool2d(2)),# ... 其他层
]))print(model.conv1) # 通过名称访问
6.3 代码示例
以 CIFAR10 模型为例:

(1)输入 input 是 3 个通道的 32×32 大小的数据,该模型输入为 CIFAR10。
(2)经过一个 5×5 的 kernelsize 的卷积,变成 32 通道的 32×32 的大小。通道变成 32 是因为用了 32 个 3@5×5 的卷积核,每一个卷积核生成一个输出通道。输出通道数 32 表示卷积核的数量,每个卷积核会提取一种独特的特征(如边缘、纹理等)。32 个卷积核意味着生成 32 个不同的特征图,从而增强模型对输入特征的表达能力。
(3)经过一个最大池化,尺寸减半为 32 通道的 16×16 大小(最大池化不改变通道数)。
(4)经过一次卷积,通道数和尺寸不变,还是 32@16×16。
(5)经过一次最大池化,尺寸减半为 32 通道的 8×8 大小。
(6)经过一次卷积,通道数变为 64,尺寸不变。
(7)经过一次最大池化,尺寸减半为 64 通道的 4×4 大小。
(8)Flatten 展开为 64@4×4 大小的 64 通道的 1 行(4×4 方队变 1 行长队伍)。
(9)通过全连接层把输出变为 10(cifar10 有 10 个类)。
代码示例:
from collections import OrderedDictimport torch
from torch import nn
from torch.utils.tensorboard import SummaryWriterclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.model1 = nn.Sequential(OrderedDict([('conv1', nn.Conv2d(3, 32, 5, padding=2)),('maxpool1', nn.MaxPool2d(2)),('conv2', nn.Conv2d(32, 32, 5, padding=2)),('maxpool2', nn.MaxPool2d(2)),('conv3', nn.Conv2d(32, 64, 5, padding=2)),('maxpool3', nn.MaxPool2d(2)),('flatten', nn.Flatten()),('linear1', nn.Linear(64 * 4 * 4, 64)),('linear2', nn.Linear(64, 10))]))def forward(self, x):x = self.model1(x)return xmodel = MyModel()
print(model)input = torch.ones(64, 3, 32, 32)
output = model(input)
print(output.shape)

使用 tensorboard 可视化:
writer = SummaryWriter('logs')
writer.add_graph(model, input)
writer.close()
