大数据分析06 数据排序汇总
排序
- 数据源
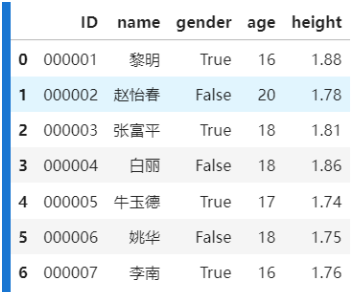
data = {'ID': ['000001', '000002', '000003', '000004', '000005', '000006', '000007'],'name':['黎明', '赵怡春', '张富平', '白丽', '牛玉德', '姚华', '李南'], 'gender':[True, False, True, False, True, False, True], 'age':[16, 20, 18, 18, 17, 18, 16], 'height':[1.88, 1.78, 1.81, 1.86, 1.74, 1.75, 1.76]}
frame = pd.DataFrame(data)
frame
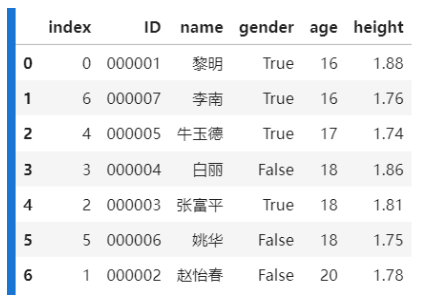
- 按顺序排序
frame = frame.reindex([6, 5, 4, 3, 2, 1, 0])
frame
- 按照列排序
默认升序
frame.sort_values(by=['height'])
- 排序方式
frame.sort_values(by=['height'], ascending=False)frame.sort_values(by=['height','age'], ascending=[True,False])
- 排序序号删除
frame = frame.reset_index(drop=False)
frame
- 纯数字按照某行或者列的值排序
frame1.sort_values(by=[3], axis=1)
分组聚合
- 聚合
groups = frame.groupby(frame['gender'])
- 汇总
groups.count()
- 简单value统计
frame['gender'].value_counts()
等同于
frame[['gender']].groupby(frame['gender']).count()
- 分组排序统计
frame[['ID']].groupby([frame['gender'], frame['age']]).count().sort_values(by=['gender', 'age'], ascending=[False, True])

- 展示平均值
frame['height'].groupby([frame['gender'], frame['age']]).mean()
- 按值的长度
frame['name'].groupby(frame['name'].apply(len)).count()
- 按随机数
apply执行任意函数,使用args=[] 传递参数。
frame['name'].groupby(frame['height'].apply(round, args=[2])).count()
- 自定义函数
男女生高差排序
def peak2peak(arr):return arr.max() - arr.min()frame['height'].groupby(frame['gender']).apply(peak2peak)
- 匿名函数lambda
frame['height'].groupby(frame['gender']).apply(lambda arr:arr.max()-arr.min())