KV Cache:大模型推理加速的核心机制
当 AI 模型生成文本时,它们经常会重复许多相同的计算,这会降低速度。KV Cache 是一种技术,它可以通过记住之前步骤中的重要信息来加快此过程。模型无需从头开始重新计算所有内容,而是重复使用已经计算过的内容,从而使文本生成更快、更高效。
从矩阵运算角度理解 KV Cache
让我们从最基础的注意力机制开始。标准的 self-attention 计算公式大家都很熟悉:
Attention(Q,K,V) = softmax(QK^T/√d_k)V
在实际应用中,随着上下文长度的增加,这个计算会变得非常昂贵。比如当我们有 10,000 个 token 时,QK^T 会产生一个 10,000×10,000 的巨大矩阵。在自回归生成过程中,每次预测新 token 都需要重新计算整个注意力矩阵。但仔细观察会发现,对于已经生成的 token,它们的 K 和 V 向量在每次计算中都是相同的。
以"我爱大模型"的生成过程为例:
- 第1步:输入"我",预测"爱"
- 第2步:输入"我爱",预测"大"
- 第3步:输入"我爱大",预测"模"
- 第4步:输入"我爱大模",预测"型"
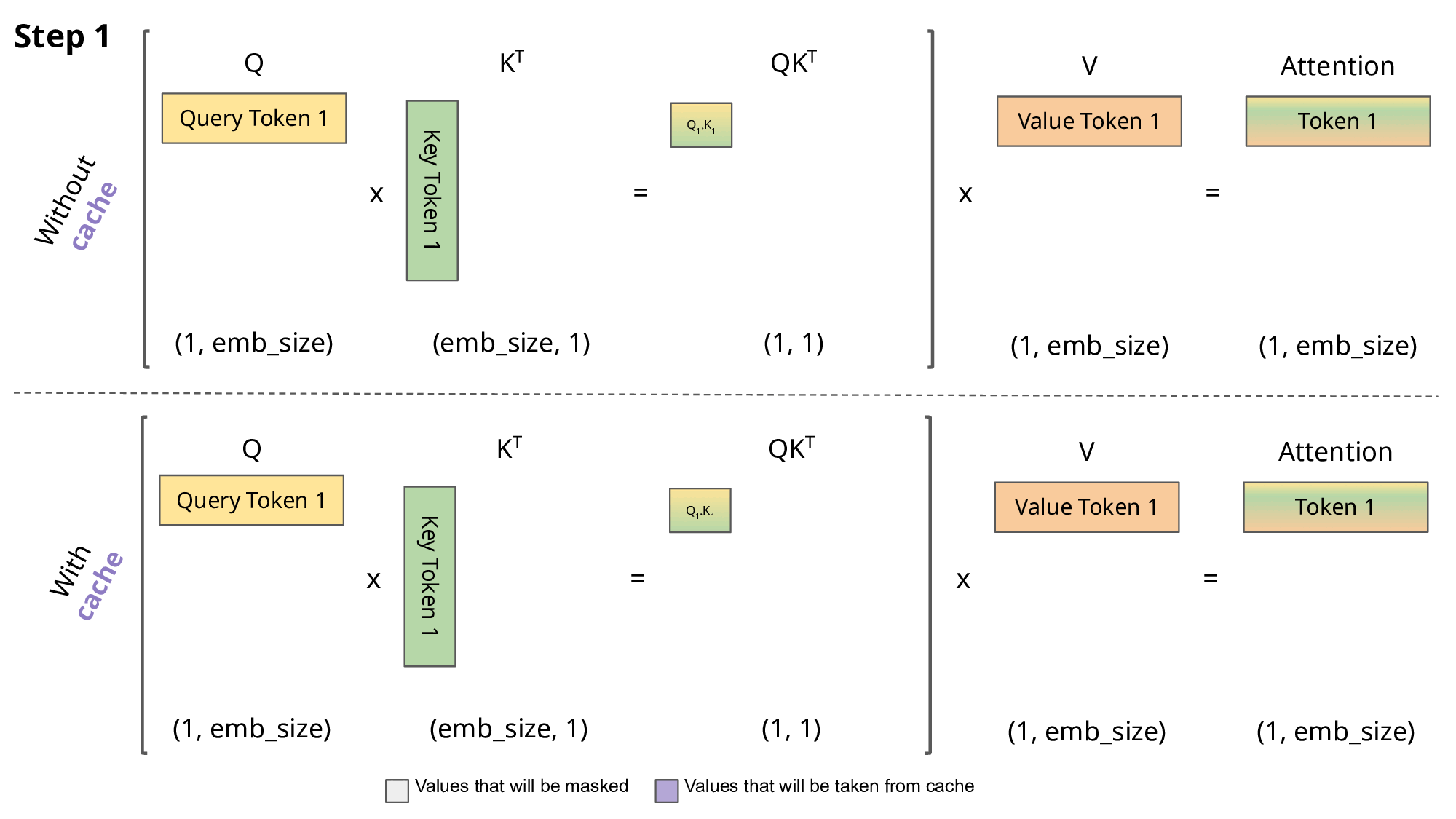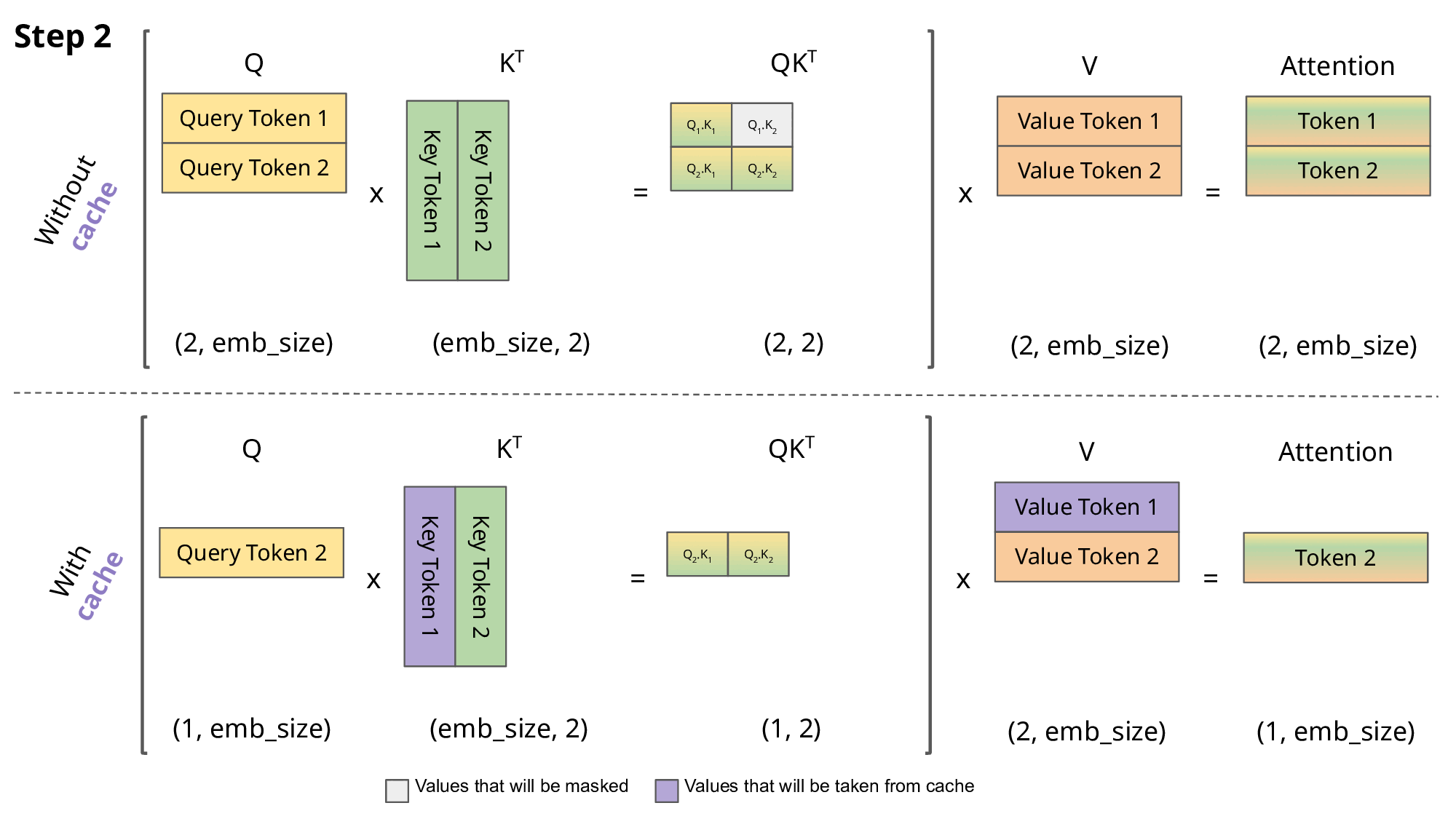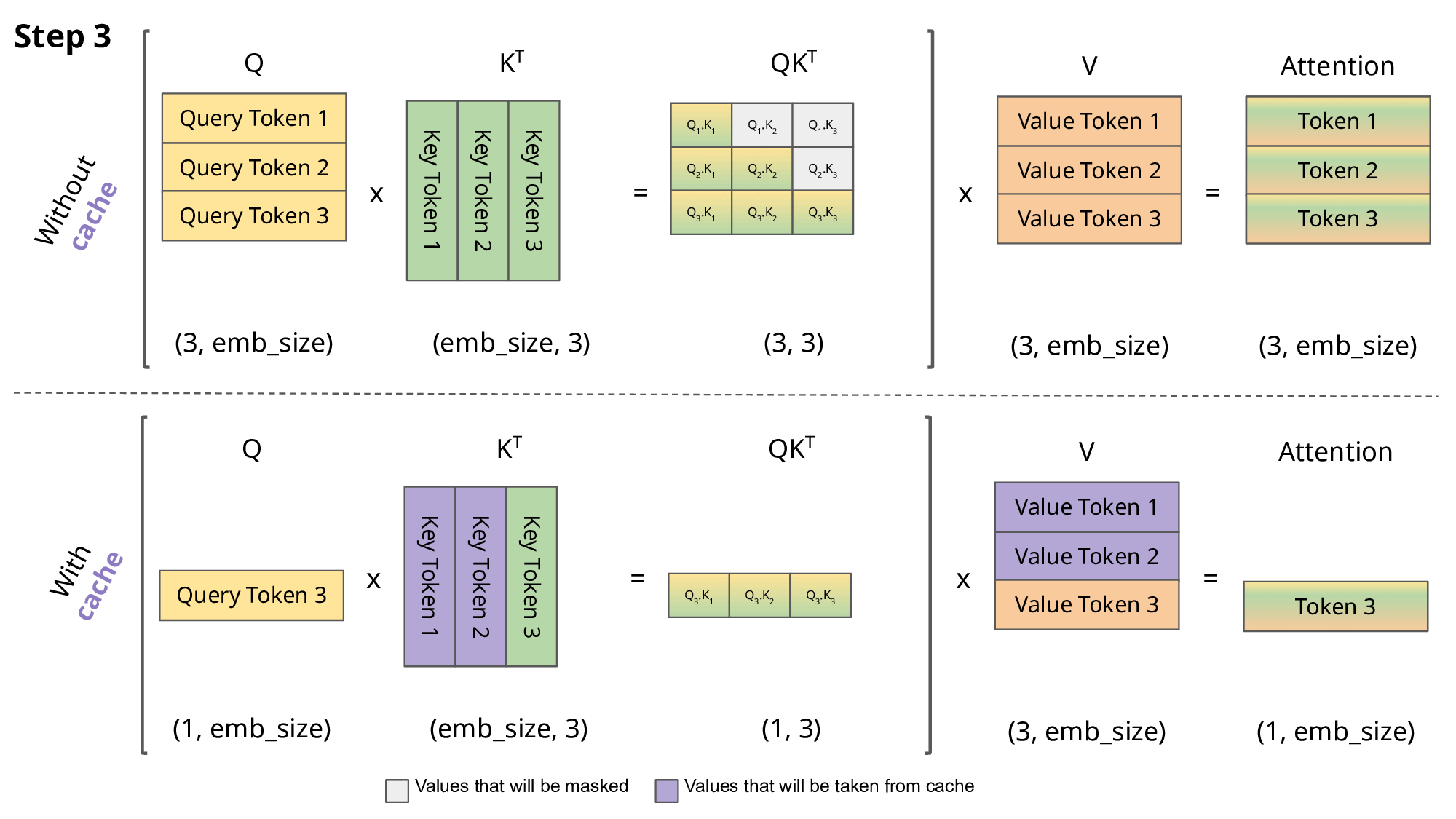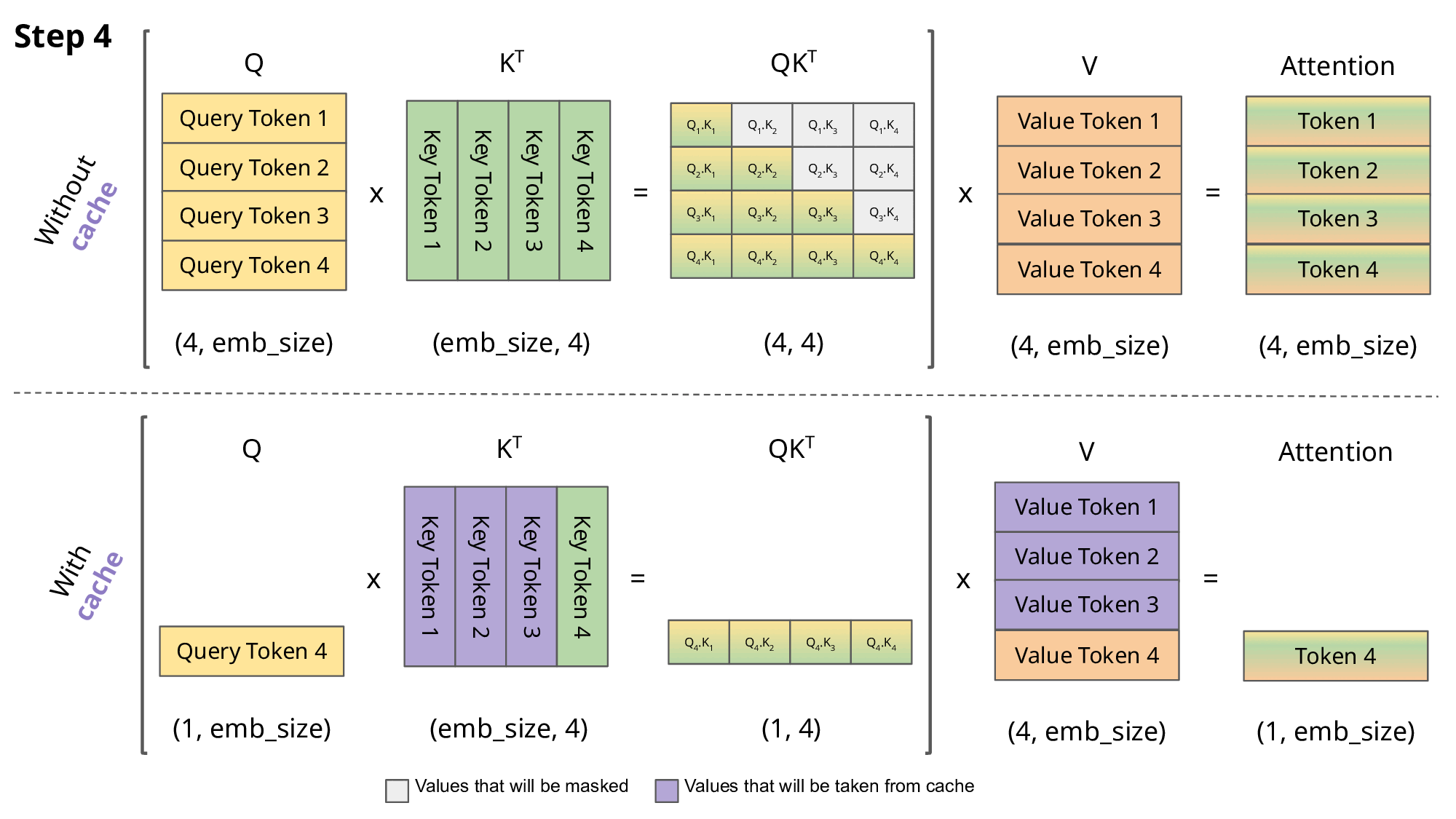
在第4步计算时,"我爱大模"这四个字的 K 和 V 值与前面步骤中计算的完全相同。如果每次都重新计算,就是巨大的浪费。
从矩阵维度来看,每一步的计算实际上是在上一步的基础上增加一行一列。masking 机制确保了只有下三角部分参与计算,这意味着上一步计算的结果可以完全复用。
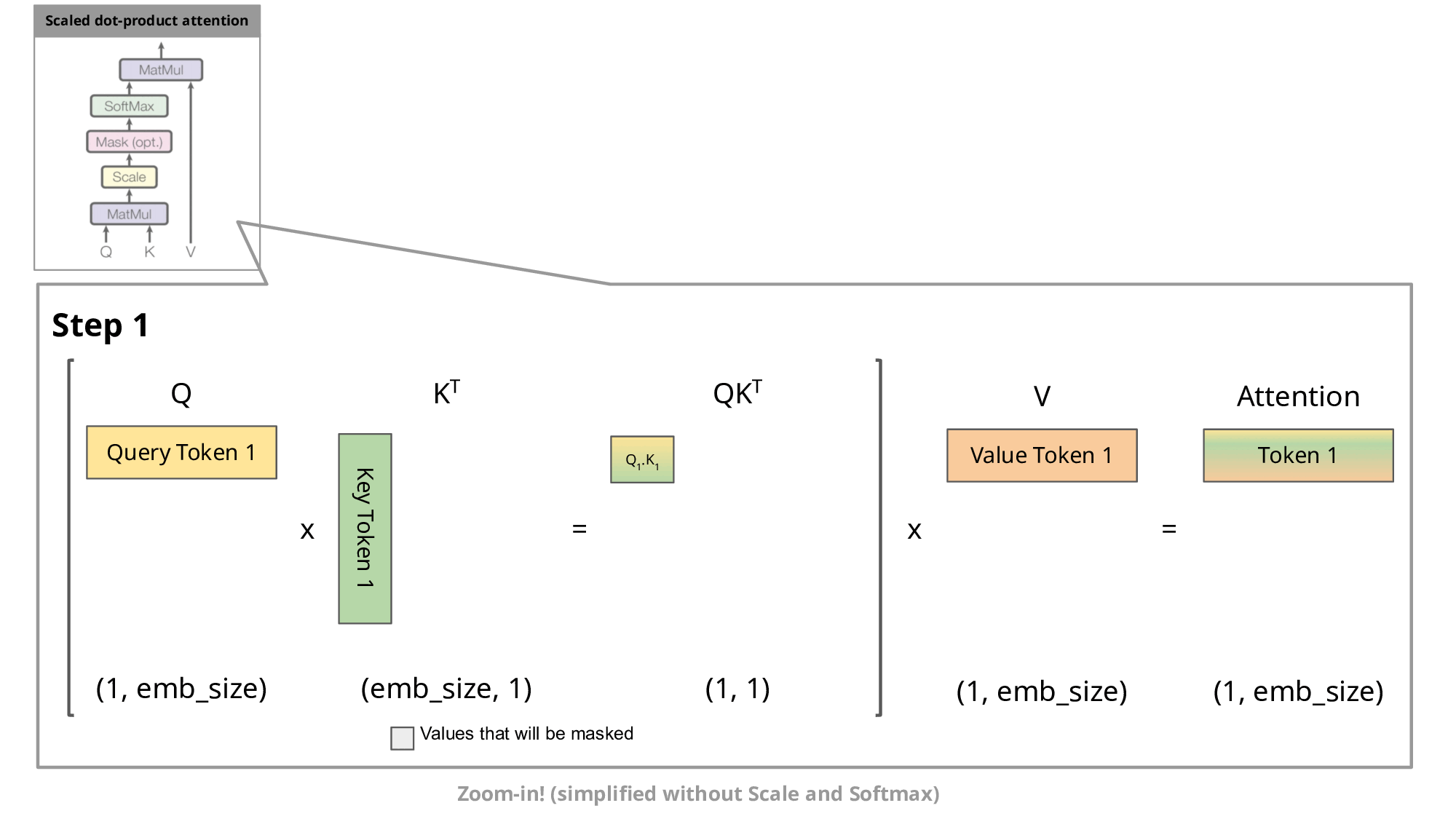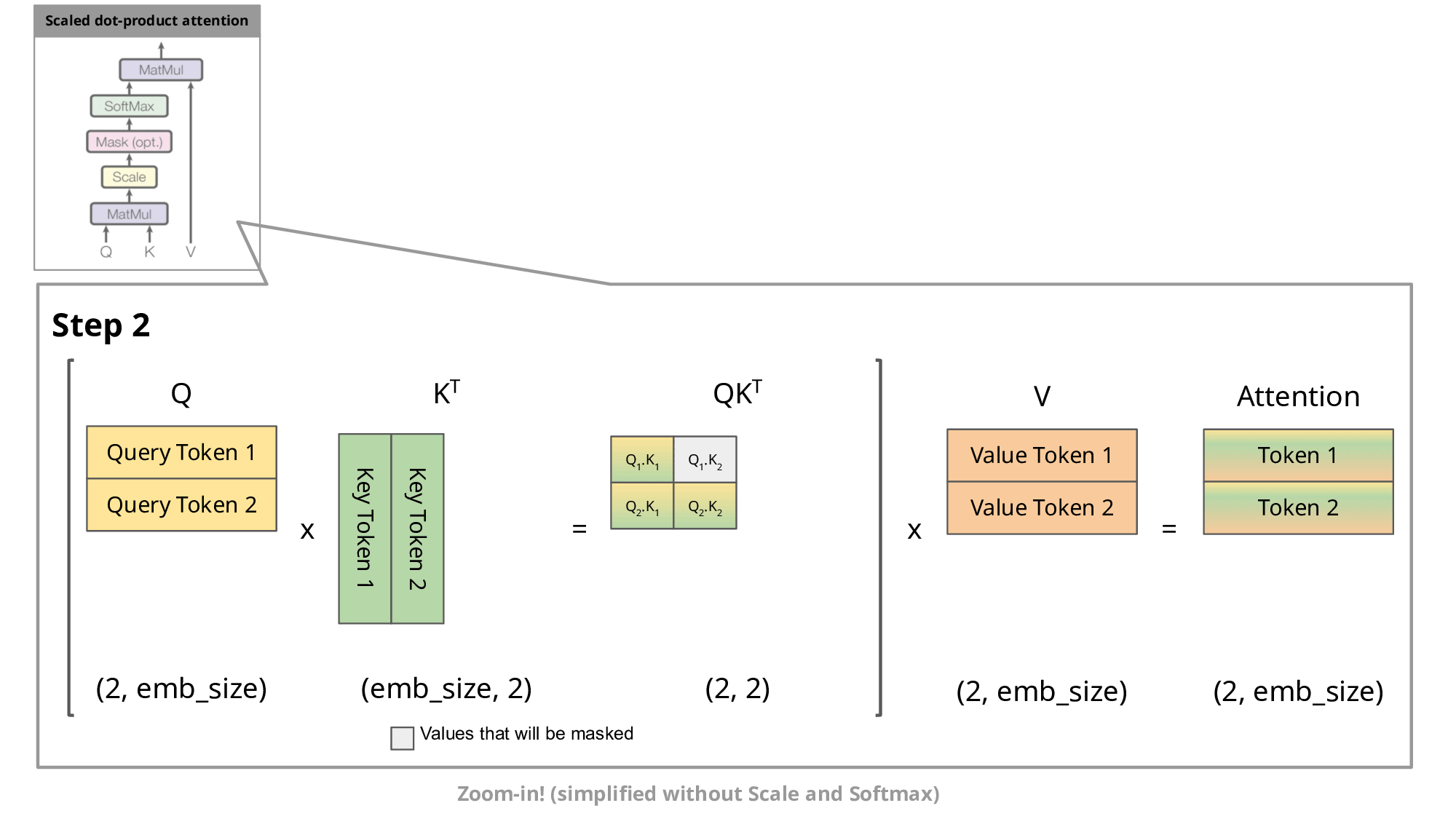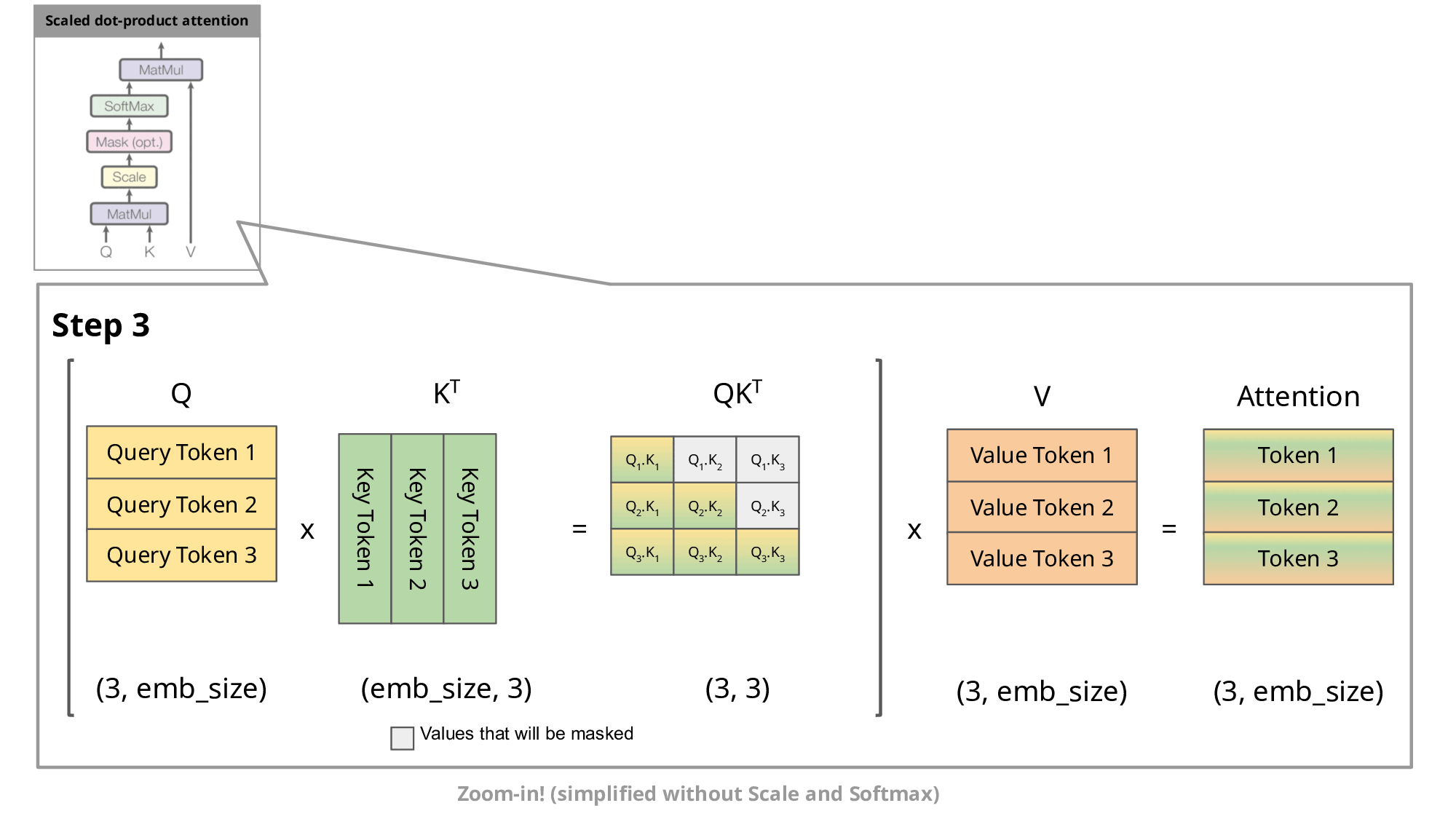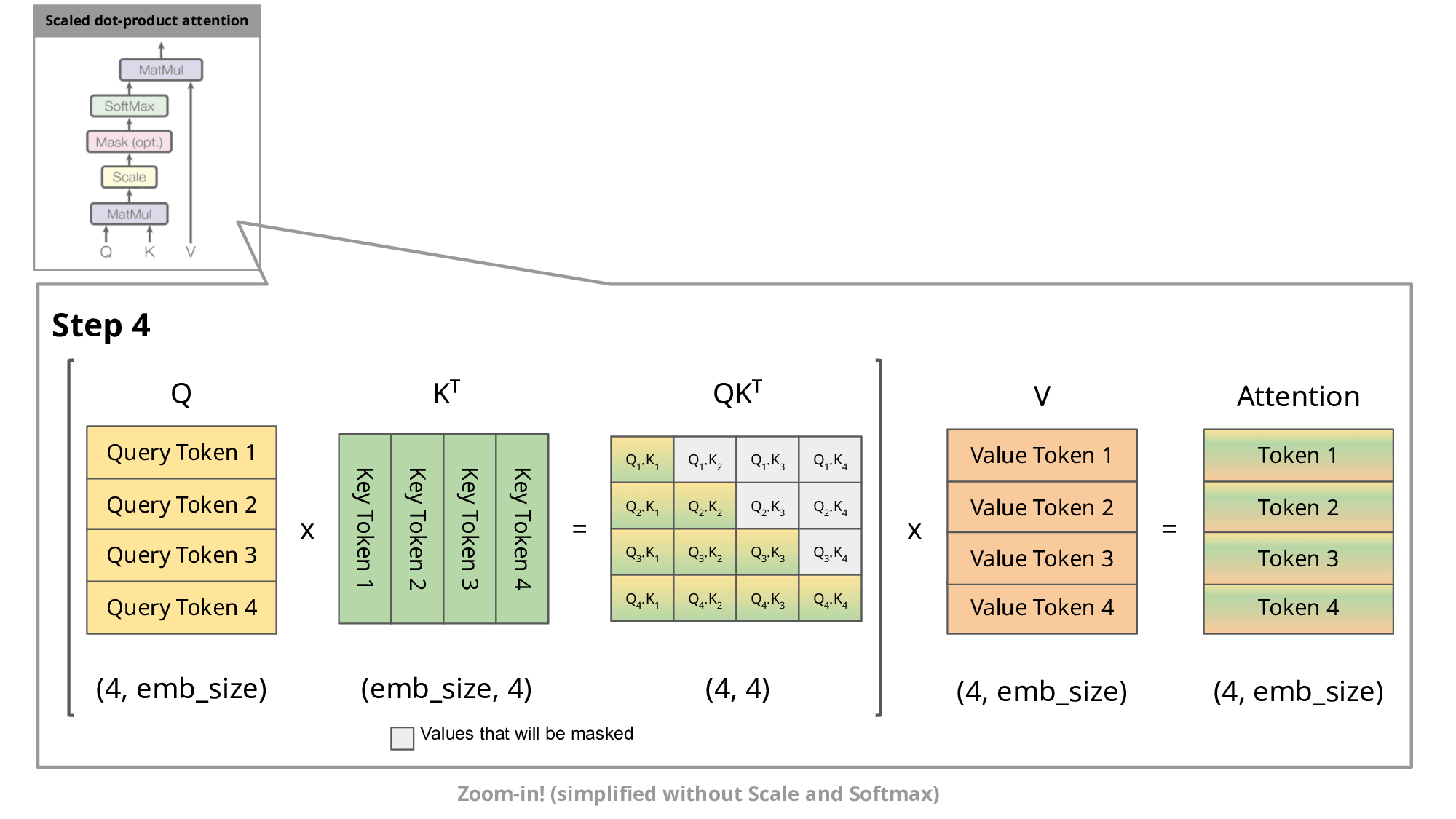
KV Cache 的核心思想是:缓存之前计算过的 K 和 V 向量,每次只计算新增 token 的部分。
为什么不缓存 Q? 因为 Q 向量始终是当前步骤新生成的 token,没有复用价值。每次生成新 token 时,Q 是查询的量,即该值是基于每次的新 token 计算的。
具体来说:
- 第1步:计算并缓存"我"的 K 和 V
- 第2步:只计算"爱"的 K 和 V,与缓存的"我"组合使用
- 第3步:只计算"大"的 K 和 V,与缓存的"我爱"组合使用
- 依此类推…
这样,每一步的计算量从 O(n²) 降低到 O(n),其中 n 是当前序列长度。
让我们更仔细地看看这个过程:
第2步详细分析:
当我们需要预测"大"时,传统方法会重新计算"我"和"爱"之间的所有注意力关系。但实际上:
- "我"的 K 和 V 向量在第1步已经计算过
- 我们只需要计算"爱"与"我"的关系,以及"爱"与自己的关系
- 缓存的"我"的向量直接复用,避免重复计算
第3步时:
- "我"和"爱"的 K、V 向量都已缓存
- 只需计算"大"与之前所有 token 的关系
- 上一步形成的注意力权重矩阵的上三角部分完全不变
KV Cache 关键点
首先需要明确 KV Cache 的几个核心特征:
只在推理阶段使用:训练时不需要 KV Cache,因为训练时所有 token 都是已知的。推理时由于是逐个生成 token,才需要这种缓存机制。
仅存在于 Decoder 中:如果你用的是 BERT 这种纯 Encoder 模型,是用不上 KV Cache 的。只有像 GPT 这样的自回归模型才需要。
KV Cache 内存计算
使用KV Cache即是使用空间换取时间,以下公式计算了当推理n个token(序列长度)所需占用的显存空间
KV Cache 内存 = 2 × 层数 × 注意力头数 × 头维度 × 序列长度 × 数据类型字节数
说明:
- 这里的 “2” 代表 K 和 V 两个缓存矩阵。
- 需要乘以层数是因为:每个 Transformer block 都有自己的 KV Cache,不同层的 K 和 V 值不同。
以 Llama 3 70B 为例的详细计算
模型参数:
- 层数:80 层
- 注意力头数:64 头
- 头维度:128 维
- 数据类型:FP16 (2字节)
单个 token 的 KV Cache:
2 × 80 × 64 × 128 × 1 × 2 = 2,621,440 字节 ≈ 2.5MB
单次请求假设是中等文本长度 1K tokens,推理一次需要占用的内存是:
2.5MB × 1,000 = 2,500MB ≈ 2.5GB
20个并发用户,每人 1K tokens,这时候我们需要*20,因为每个用户的 KV Cache 是独立的,无法共享:
2.5GB × 20 = 50GB
由此可以看出公司上线一个大模型,与序列长度和用户数量线性相关,这部分也是一个很大的资源消耗。因此当我们下载一个大模型时,最好别下满,需要预留好KV Cache的显存空间
从代码直观感受KV Cache性能
以GPT-2代码做示例:
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizerdevice = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)for use_cache in (True, False):times = []for _ in range(10): # 测试10次取平均start = time.time()model.generate(**tokenizer("什么是KV缓存?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)times.append(time.time() - start)print(f"{'使用' if use_cache else '不使用'} KV缓存: {round(np.mean(times), 3)} ± {round(np.std(times), 3)} 秒")
测试结果让我印象深刻:
- 使用 KV Cache: 11.885 ± 0.272 秒
- 不使用 KV Cache: 56.197 ± 1.855 秒