深度学习————注意力机制模块
关于注意力机制我自己的一点理解:建立各个维度数据之间的关系,就是对已经处理为特征图的数据,将其他影响因素去除(比如通道注意力,就将空间部分的影响因素消除或者减到极小)再对特征图进行以此特征提取 以此找到这个维度数据之间的联系。
SENet 注意力模块
场景出发:CNN 的缺点
传统 CNN 在处理一张图片(或特征图)时,默认每个通道都一样重要,全部都送到下一层。但事实是:
-
某些通道可能表示重要信息(比如边缘、血管、肿瘤区域)
-
某些通道是冗余的,或者是噪声
CNN 不会主动区分这些通道的“重要性”,这就是性能的瓶颈。
SENet模块的目标:让网络自己学会哪些通道重要,放大它们;不重要的通道就抑制。
模块结构总览
SENet 主要由三步组成(你可以记成 3 个“S”):
| 步骤 | 名称 | 直观解释 |
|---|---|---|
| ① Squeeze(压缩) | 把整张图“压成一个通道向量” | 得到每个通道的重要性“初始印象” |
| ② Excitation(激励) | 用两层小全连接网络分析通道之间的关系 | 学出权重向量 |
| ③ Scale(重标定) | 把每个通道乘上权重 | 强化重要通道,抑制次要通道 |
✅ 第一步:Squeeze(压缩)
输入:一张特征图,大小是 [B, C, H, W]
意思是:batch大小为B,有C个通道,每张图的高为H,宽为W
操作:对每个通道做平均池化,把每张通道图变成1个值:
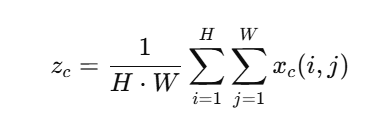
也就是说:
每个通道 → 取平均 → 得到该通道的“整体响应程度”
目的:
-
把一个
[C, H, W]的特征图压成[C, 1, 1] -
每个通道只用一个数字表示,用于描述“它在整个图中有多强”
举个例子
比如你有一个特征图 [3, 4, 4](3个通道,4×4大小),假设:
-
第1通道值都很大(比如检测到边缘)
-
第2通道值都一般
-
第3通道值都很小(基本没信息)
做完池化后得到 [0.9, 0.5, 0.1],这就是对通道重要性的“初印象”。
第二步:Excitation(激励)
上一步你得到了一个大小为 [C] 的通道向量,表示每个通道的“存在感”。
现在要做的事:用两层全连接网络 去学习通道间的依赖关系,并产生新的权重向量 s,表示“真正重要的通道”。
为什么要用两层 FC(全连接)?
-
第一层:降低维度,学出非线性组合(像压缩感知)
-
第二层:恢复维度,输出最终的通道权重
-
使用 ReLU + Sigmoid:
-
ReLU:引入非线性,模拟复杂关系
-
Sigmoid:将权重限制在 [0,1][0, 1][0,1] 区间,便于加权
-
数学形式:
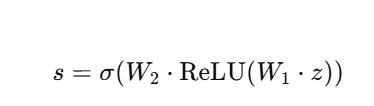
-
W1:将通道数降为 C(比如16分之一)
-
W2:再升回原始通道数 C
-
σ 激活,输出范围在 [0,1]
第三步:Scale(加权重标定)
你现在得到了每个通道的重要性权重 s∈RC,比如:s=[0.95,0.21,0.76,… ]
就把原特征图中每个通道乘上对应的权重:
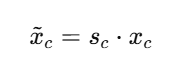
通俗地说:
-
sc 越接近 1 → 通道保持不变或增强
-
sc 越接近 0 → 通道抑制或屏蔽
这样,模型就能自动忽略冗余特征,专注有用特征。
这样做到底有什么用?
-
动态调节特征通道
-
不再“一刀切”地对待每个通道,而是自适应处理
-
-
增强网络的判别能力
-
在分类、检测、分割任务中,能让模型更关注重要区域和通道
-
-
几乎不增加计算量
-
两个小FC层,几乎不影响速度
-
举个真实应用的例子:
以医学图像分割为例(比如CT脑出血):
-
UNet 的解码部分可能生成多个通道
-
有的通道强调脑出血的边缘,有的通道是背景,有的通道是噪声
-
使用 SE 模块后,模型学会:
-
放大表示“出血边缘”的通道
-
减弱“背景”或“无效特征”的通道
-
-
最终输出的掩膜更精准、更聚焦于病灶
第二部分:CBAM 模块(通道注意力 + 空间注意力)
CBAM = 通道注意力(Channel Attention) + 空间注意力(Spatial Attention)
相当于在“看什么通道”的基础上,加了“看图中哪里”的能力。
✅ 一句话总结:
SENet 只关注“哪个通道重要”,CBAM 则进一步判断:
-
哪些通道重要(Channel Attention)
-
哪些空间位置重要(Spatial Attention)
类比人类视觉:不仅知道“哪些颜色”重要(通道),还要知道“看哪里”最重要(空间)
CBAM的结构图:
一个标准的 CBAM 模块如下:
输入特征图 [B, C, H, W]↓
[1] 通道注意力模块(Channel Attention)↓
输出 [B, C, H, W],但每个通道已加权调整↓
[2] 空间注意力模块(Spatial Attention)↓
最终输出 [B, C, H, W],空间区域也被加权强化
模块一:通道注意力(Channel Attention)
这一步其实类似 SENet,但做了些优化。
原理:
通道注意力模块的目标是:学习每个通道的重要程度
CBAM的设计里,它使用了**两个不同的池化方式(MaxPool + AvgPool)**来获取通道描述。
步骤:
-
输入特征图
[B, C, H, W] -
分别做平均池化和最大池化 → 得到两个通道描述向量
[B, C, 1, 1] -
把这两个通道向量送入共享的MLP(两层全连接) → 得到两个权重
-
加和后做 sigmoid 激活 → 得到通道注意力权重向量
[B, C, 1, 1] -
与原始特征图相乘,输出加权通道图
数学表达:
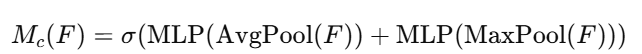
-
输出是大小为
[B, C, 1, 1]的通道注意力图 -
与输入特征图逐通道相乘
模块二:空间注意力(Spatial Attention)
这一步是 CBAM 的关键创新。
原理:
通道注意力告诉我们“要看哪个通道”,但我们还需要知道“在图像的哪个位置重要”。
空间注意力模块学习的是一个二维图,表示每个像素点的重要性。
步骤:
-
输入来自上一步的特征图
[B, C, H, W] -
在通道维上做 max-pooling 和 avg-pooling → 得到两个
[B, 1, H, W]的图 -
将两个图拼接 concat →
[B, 2, H, W] -
用一个 7×7卷积核 处理 → 得到一个
[B, 1, H, W]的空间注意力图 -
与输入图做逐像素点相乘(广播) → 输出最终注意力加权图
数学表达:
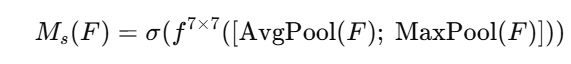
-
输出是大小为
[B, 1, H, W]的空间注意力图 -
与输入图逐元素相乘,实现“看哪里”的目的
第三部分:BAM 模块(瓶颈注意力模块)
全称:Bottleneck Attention Module,发表于 ECCV 2018
BAM 也是“通道注意力 + 空间注意力”的组合,但与 CBAM 串联结构不同,BAM 使用并联结构,即同时计算通道和空间注意力,最后相乘后用于加权特征图。
BAM 的整体结构:
输入特征图 X↓
分支1:通道注意力模块(MLP)↓
分支2:空间注意力模块(空洞卷积)↓
通道注意力 × 空间注意力 → 融合注意力权重↓
加权输入特征:F_out = X × (1 + Attention)
注意:
-
与 CBAM 不同,BAM 是“并行计算注意力”,结果合并
-
输出特征图是
X × (1 + Attention),即保留了原始特征 + 注意力增强项
模块一:通道注意力(Channel Attention)
原理:
与 SENet 类似,使用全局平均池化 + MLP 学习每个通道的重要性。
数学表达:
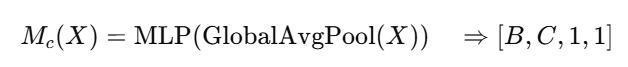
-
通道注意力输出为
[B, C, 1, 1] -
广播乘回输入图
模块二:空间注意力(Spatial Attention)
原理:
使用多个**空洞卷积(dilated conv)**进行多尺度空间建模,增强对空间结构的理解能力。
操作:
-
用多个空洞卷积提取不同尺度的空间结构信息
-
用 ReLU 和 BatchNorm 激活
-
最后输出一个
[B, 1, H, W]的空间注意力图
数学表达:

整体融合方式
注意力融合方式是:

然后再与输入特征图相乘:
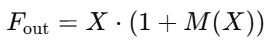
这里的 1 + M(X) 是为了保留部分原始信息,防止模型过度依赖注意力。
第四部分:Non-local Attention(非局部注意力)
全称:Non-local Neural Networks,发表于 CVPR 2018,提出者来自 Facebook AI
Non-local Attention 是一种 全局建模方法,它通过计算任意两个位置之间的关系(非局部),实现信息的长距离传递,弥补了卷积/池化等本地操作的缺陷。
为什么叫“非局部”?
传统 CNN(如卷积、池化)每次只能处理局部邻域,想要获取长距离信息必须多层堆叠。而 Non-local 可以一步捕捉图像中任意两个像素之间的关系,这种跨越距离的机制就叫做“非局部操作”。
数学表达(核心公式)
给定输入特征图 X∈RC×H×WX ,Non-local 输出如下:
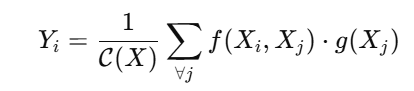
-
Yi:位置 i的输出特征
-
f(Xi,Xj):位置 i 与 j的相似度函数
-
g(Xj):从位置 j 抽取的信息
-
C(X):归一化因子
组成模块详解
Non-local 模块包含以下子模块:
查询-键-值(Q-K-V)机制
与 Transformer 中的 self-attention 思想一致:
-
Query Q=WqXQ
-
Key K=WkXK
-
Value V=WvXV
都是使用 1×1 卷积进行变换,降维。
相似度计算函数 f
常用的是嵌入高斯核(Embedded Gaussian):
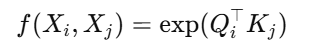
再通过 softmax 归一化:
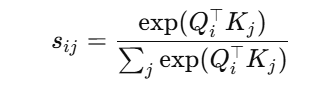
表示位置 i 与所有位置 jj的关系。
输出加权求和:
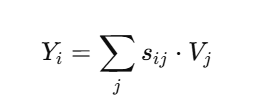
就是所有位置的 Value 乘以其与位置 iii 的相似度,再求和。
残差连接(Residual)
最终输出为:
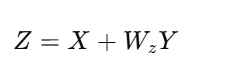
其中 Wz 是一个 1×1 卷积,用于调整通道。
结构图
Input X↓┌─────────────┐│ Query (Wq) │└─────────────┘↓┌─────────────┐│ Key (Wk) │└─────────────┘↓相似度计算(Softmax)↓┌─────────────┐│ Value (Wv) │└─────────────┘↓加权求和输出 → Wz → + Input → 输出 Z
第五部分:Transformer 风格注意力模块在 CNN 中的嵌入
CoT Attention(Contextual Transformer)
来源:论文《Contextual Transformer Networks for Visual Recognition》(ICCV 2021)
CoT Attention 将 局部卷积 和 全局注意力 相结合,兼顾局部细节提取和上下文建模,是将 Transformer 精髓嵌入到 CNN 模块中的一个代表作,既能卷积、又能“看远”。
背景问题
普通自注意力模块存在两个问题:
-
不善于捕捉局部空间关系(不像卷积)
-
计算复杂度高(空间维度平方级)
CoT 的目标是构造一个低成本、高表达力、可嵌入 CNN 的注意力模块,适合视觉场景。
CoT Attention 的核心结构
输入特征图 X∈RB×C×H×WX,CoT Attention 包括三步:
步骤 1:提取上下文上下文信息(K)
使用 3×3 卷积获取每个位置的上下文表示:
K=Conv3x3(X)
这一步像是加强局部语义建模能力,不像传统 attention 那样直接线性变换。
步骤 2:提取 Query,并与 Key 融合形成 Attention Map
先计算 Query:
Q=1x1Conv(X)
然后将 Q 与每个位置对应的上下文 Key 拼接,再经过非线性映射得到每个位置的注意力权重(权重是一个 卷积核 的形式):
A=MLP([Qi,Ki])
-
[Qi,Ki]:表示 Q 和其上下文信息拼接
-
MLP 通常是 1x1 卷积 + BN + ReLU + 1x1 卷积
步骤 3:加权 Value 特征生成输出
用上一步得到的注意力作为动态卷积核,对输入 X 做卷积:
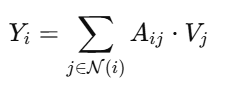
其中:
-
N(i):位置 i 的邻域(比如 3×3 范围)
-
Aij:是对邻域位置的注意力
-
Vj:是邻域内的特征
最终结果是Query 中的每个位置都用一套 attention 卷积核动态聚合周围信息,结合上下文生成新特征。
结构图
Input Feature X↓┌──────────────┐│ 3x3 Conv │ → K (上下文)└──────────────┘↓┌──────────────┐│ 1x1 Conv │ → Q└──────────────┘↓[Q || K] 拼接↓┌──────────────┐│ MLP │ → Attention Weights (动态核)└──────────────┘↓动态卷积 → 输出 Y
第六部分:Efficient Channel Attention(ECA)
来源:论文《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》(CVPR 2020)
ECA 是对 SENet 的改进,不使用全连接层、参数更少、计算更快、效果不差甚至更好。它用一个小的 1D 卷积代替 FC 层,自适应建模通道间依赖关系。
背景:SENet 的局限
-
对特征做全局平均池化 → 得到每个通道的统计值
-
用 2 层 FC 层建模通道关系 → 得到权重
-
对输入每个通道乘以对应权重
-
两个 FC 层引入了不少参数(尤其是通道数大时)
-
存在“信息瓶颈”问题(中间维度压缩可能丢失信息)
ECA 的创新点
ECA 用一维卷积(1D卷积)替换 FC 层:
-
不使用维度压缩
-
使用局部通道间交互
-
极大减少参数和计算量
简洁结构,性能却优于SENet!
ECA Attention 的结构
输入特征图 X∈RB×C×H×W
步骤 1:全局平均池化(GAP)
得到通道级描述向量 z∈RB×C
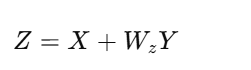
每个通道一个数
步骤 :1D 卷积建模通道关系
将 z∈RB×C 看作一个 1D 向量序列:
s=Conv1D(z)
这一步相当于用滑动窗口对每个通道与其周围通道建模依赖(比如和前后3个通道的关系)
卷积核大小 k 的选择:动态计算,如:
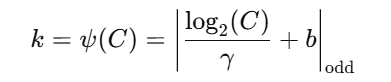
论文中使用 γ=2, b=1(保证输出为奇数)
步骤 :Sigmoid 激活 + 通道加权
得到每个通道的 attention 权重后:
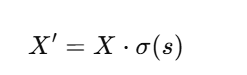
这里 σ\sigmaσ 是 Sigmoid,进行通道维度的加权增强。
ECA 的结构图
Input Feature X↓┌────────────────────┐│ Global Avg Pooling │ → z ∈ ℝ^C└────────────────────┘↓┌────────────────┐│ 1D Conv(k) │ ← 不用FC└────────────────┘↓Sigmoid↓通道加权输出 X'
第七部分:Coordinate Attention(坐标注意力,CA)
来源:论文《Coordinate Attention for Efficient Mobile Network Design》(CVPR 2021)
Coordinate Attention(坐标注意力)是一种结合了通道注意力和位置信息的机制,既保留了通道间的依赖,又引入了精确的空间位置信息编码,适合移动设备和轻量网络,也很适合图像分割等视觉任务。
背景问题
传统的通道注意力(比如SE、ECA)忽略了空间信息,只对通道进行加权,但空间位置信息对于视觉任务尤为关键;而纯空间注意力计算复杂,难以部署。
坐标注意力创新地将空间位置的两条坐标轴信息分开编码,做到:
-
低计算量
-
高效捕捉长距离空间依赖
-
兼顾空间和通道信息
Coordinate Attention 的核心结构
输入特征图 X∈RB×C×H×W
步骤 1:对空间两个坐标轴分别做全局池化
-
沿着 宽度方向做全局平均池化,得到 gh∈RB×C×H×1
-
沿着 高度方向做全局平均池化,得到 gw∈RB×C×1×W
这一步分别捕获了每行和每列的空间特征。
步骤 2:连接两个池化结果并通过共享卷积
将 gh 和 gw 在空间维度上拼接成 RB×C×(H+W)×1,然后通过一个 1×11 \times 11×1 卷积降维(通常降为 C/r,r为缩减率),再经过非线性激活(ReLU)。
步骤 3:分离特征并分别投影
把降维后的特征分为两部分,分别对应 H 和 W 方向,然后各自通过一个 1×1 卷积恢复通道维度,得到两个注意力权重映射:
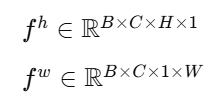
步骤 4:利用广播机制,将两个权重乘到输入特征 X上
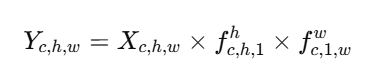
这样既考虑了通道的注意力,也引入了空间的位置信息。
结构图示意
Input X (B, C, H, W)│┌────────────────────┐│ Pool H-axis (Avg) │ → g^h (B, C, H, 1)└────────────────────┘│┌────────────────────┐│ Pool W-axis (Avg) │ → g^w (B, C, 1, W)└────────────────────┘│拼接 (H+W)│┌─────────────────┐│ 1x1 Conv + ReLU │└─────────────────┘│┌────────────────────┐│ Split → 1x1 Conv │└────────────────────┘↓ ↓f^h (B,C,H,1) f^w (B,C,1,W)↓ ↓\ /\ /Element-wise multiplication│Output Feature Y