基于多流特征融合与领域知识整合的CNN-xLSTM-xAtt网络用于光电容积脉搏波信号的无创血压估计【代码已复现】
摘要
由于信号可变性和噪声,以及 PPG 和 BP 之间的复杂关系,根据光电容积脉搏波 (PPG) 信号估计血压 (BP) 具有挑战性,这需要复杂的算法和个性化才能实现高精度。本文介绍了一种基于深度学习 (DL) 的新型框架,其中包括一个基于 CNN-xLSTM-xAtt 的深度神经网络,用于提取多域特征,以及一个带有信号增强器的多流特征融合网络 (MSFN),用于从 PPG 信号估计 BP。通过基于 ML 的损失函数将领域知识整合到 DL 网络中,该框架的性能得到了进一步增强。数据预处理步骤包含一个新颖的信号选择器,该选择器接受在指定范围内具有峰高和距离方差的信号。为了确保从峰值中进行稳健的特征学习,这项工作采用了一种基于卷积的峰值增强 (CPE) 方法。对于特征提取,使用两个并行网络处理精细信号,从而能够从一维信号域和图像域进行互补特征学习。所提出的框架的一维路径,包含两个并行网络——ConvLSTM 和 xLSTM——促进了短期和长期的时间依赖性。同时,基于图像的网络利用预训练网络的优势,从三种不同的图像模态中提取形态学和光谱特征。为了确保框架专注于这个多流网络中最重要的来源,提出了一种新颖的多流空间和交叉注意力网络 (M-SCAN)。最后,通过基于 CNN-xLSTM 的多流融合网络 (MSFN) 将这两种类型的特征结合起来,可以得到 BP 的估计。在深度学习网络的训练过程中,还提出了一种领域知识集成的动态定量嵌入基于监督的调整 (D-QuEST) 作为模型的监督损失。所提出的框架的性能已在两个公开可用的数据集上进行了测试,表明小数据集为 0.05 % MSE、1.40 % MAE 和 99.36 % PCC,大型数据集为 0.06 % MSE、1.58 % MAE 和 99.09 % PCC。拟议的框架性能明显优于现有的最先进的方法,即使主题多样性很高。这证明了它仅根据具有不同变化的 PPG 信号进行准确 BP 估计的潜力。
1. 引言
血压 (BP) 是指示心血管健康的关键生命体征。显着升高和异常低的血压水平都会对患者的生命构成严重风险,可能导致危及生命的情况(Marczak、Williams、Loeffler 等人,2018 年)。在传统系统中,将袖带充气在上臂周围以暂时限制血液流动,然后释放压力以测量收缩压和舒张压,即收缩压和舒张压(Lewis,英国&社会,2019年)。这个过程虽然准确,但由于袖带需要放气和重置,因此通常每隔至少两分钟进行一次。这种间歇性使设备不适合连续监测,并且会引起不适,尤其是在频繁使用时。此外,使用袖带在锻炼、睡觉时或在患者处于麻醉状态的医疗程序或手术期间测量血压变得非常不切实际。因此,许多用户发现这些传统方法不方便,导致人们对无袖带解决方案越来越感兴趣,这些解决方案可以提供更无缝、连续的血压监测,而无需定期给袖带充气(Muntner等人,2019 年)。光电容积脉搏波 (PPG) 有可能远程估计血压,而无需任何袖带。
PPG 传感器通过用 LED 或红外灯照亮皮肤并检测光电二极管的反射或透射光来测量身体区域的血容量变化,从而评估真皮和皮下组织中的血液灌注(Allen,2007 年,Elgendi,2012 年)。使用数码相机进行远程 PPG 波测量也是可行的(Niu, Han, Shan, Chen, 2017, Xiao, Liu, Sun, Li, Zhao, Avolio, 2024)。PPG 波形通常具有突出的收缩压 (SBP) 收缩压峰值和较小的舒张压 (DBP) 舒张压峰值 (Elsamnah, Bilgaiyan, Affiq, Shim, Ishidai, Hattori, 2019, Hernando, Peláez-Coca, Gil, 2024)。较高的峰值反映了微血管组织中血液密度的增加,使 PPG 波与血压测量值相关以进行连续监测(Bagha、Shaw,2011 年、Le、Ellington、Lee、Vo、Khine、Krishnan、Dutt、Cao,2020 年、Tazarv、Levorato,2021 年)。
由于受到接触压力(May等人,2021)、温度(Khan等人,2015)、运动伪影(Desquins, Bousefsaf, Pruski, & Maaoui, 2022)和设备噪音(Nowara, McDuff, & Veeraraghavan, 2020)以及生理因素(如肤色(Fine等人,2021 年)。较小的舒张期峰值也使血压估计复杂化(Desquins等人,2022 年)。随着数据多样性的增加,这些挑战会加剧,从而更难从 PPG 信号中捕获准确的特征。
为了实现稳健和准确的 BP 估计,必须对 PPG 信号进行预处理,以便更好地提取特征。预处理通常涉及信号质量检查和信号过滤。严重嘈杂或受伪影影响的信号会阻碍估计,因此信号质量评估对于确保有效输入至关重要。偏度、峰度、熵和过零等统计方法通常用于测量信号质量指数 (SQI)(Elgendi,2016 年,Elgendi,Martinelli,Menon,2024b)。Chen et al. (2024) 介绍了一种基于 SNR 的方法,该方法从 PPG 信号中选择最佳信号段。吸引子重建也显示出评估信号质量的有效性(Schmith et al., 2023)。有效信号通常包含使 PPG 形状失真的高频噪声。为了恢复正确的信号形状,带通滤波器 (BPF)、Savitzky-Golay 滤波器或基于小波的重建等滤波方法被广泛应用于最先进的研究中。
关于 BP 的估计,文献中提供了三类方法:1) 基于信号处理的方法,2) 基于机器学习 (ML) 的手动特征提取方法,以及 3) 基于深度学习 (DL) 的自动特征提取方法。基于信号处理的方法,通常与 ML 模型相结合,需要大量的手动计算并产生次优结果(Chen, Yang, Chen, Han, Gong, Wang, Zhang, 2024, Haddad, Boukhayma, Caizzone, 2021),这使得 ML 和 DL 方法越来越受欢迎。基于 ML 和 DL 的方法的性能在很大程度上取决于从 PPG 信号中提取的特征质量。
从 PPG 信号中手动提取特征包括时间、统计和基于频率的特征 (Maqsood, Xu, Springer, Mohawesh, 2021, Riaz, Azad, Arshad, Imran, Hassan, Rehman, 2019)。为了正确估计血压,必须仔细选择特征。SVM、决策树和 AdaBoost 等传统 ML 模型已广泛应用于多项研究(El-Hajj、Kyriacou、2020、Haddad、Boukhayma、Caizzone、2021、Hasanzadeh、Ahmadi、Mohammadzade,2019、张、曾、胡、周,2017)。虽然 AdaBoost 在连续血压估计方面表现出色,但它在训练速度方面面临挑战(Chao et al., 2021)。另一方面,随机森林 (RF) 在不减慢训练过程的情况下提供了更好的效率(Chen et al., 2024)。
DL 模型通过自动从 PPG 信号中提取复杂特征,优于基于 ML 的方法。基于卷积神经网络 (CNN) 的 DL 方法可以有效地从信号中捕获短期特征。Kyung 等人(2023 年)利用一种基于 CNN 的方法,具有时间注意力机制,使用 PPG 信号、它们的导数和相应的包络(包括手指压力)来估计血压,以帮助表现。然而,手指压力的要求为远程血压测量造成了障碍。PPG 信号的复杂性也导致在几项研究中除了 PPG 之外,还使用了心电图 (ECG)(Jeong、Lim,2021 年、Miao、温、胡、Fortino、王、刘、唐、李,2020 年、Tanveer、Hasan,2019 年)。这些基于 CNN 的方法有效地从一维信号中捕获短期时间特征,但忽略了长期依赖性,而多样化的数据加剧了这一限制。
基于长短期记忆 (LSTM) 的模型通常更适合从 PPG 信号中提取长程时间特征。El-Hajj, Kyriacou, 2021a, El-Hajj, Kyriacou, 2021b 比较了 LSTM、门控循环单元 (GRU)、双向 LSTM (Bi-LSTM) 和基于双向 GRU (Bi-GRU) 的模型,用于从 PPG 信号估计 BP,发现 Bi-LSTM/Bi-GRU 的性能更好,因为它们能够捕获过去和未来的依赖关系。此外,Panwar, Gautam, Biswas, & Acharyya (2020) 和 Tazarv & Levorato (2021) 发现,将CNN与LSTM结合提供了提取短距离和长距离特征的能力,显著提高了性能。尽管 CNN-LSTM 组合可以捕获短期和长期特征,但它仅限于一维特征域,导致在不同数据集上的性能欠佳。
几项研究已将 PPG 信号转换为 2-D 特征空间以增强特征提取(Aldrich,2023 年)。Liu, Yu, & Mou (2023) 将PPG信号转换为五个图像:grammian角度求和/差分场(GASF, GADF),自然/水平能见度图(NVG,HVG,和原始PPG图像,并使用基于ResNet18的架构训练它们以估计BP。同样,Rong & Li (2021) 同时使用了一维信号和二维图像,将PPG和尺度图图像与CNN-BiLSTM网络相结合。然而,他们的方法依赖于一个简单的基于密集层的融合网络,限制了他们充分利用来自多个来源的互补信息的能力。此外,他们只专注于提取长期的时间特征,没有加入注意力模块来突出相关来源,这因未能集成更多样化和动态的特征提取技术而限制了模型的整体性能。尽管最先进的方法在小型数据集上表现令人满意,但由于这些限制,它们无法从不同的数据集中捕获 PPG 波形中的复杂模式,从而导致性能不佳。
1.1. 研究贡献
- i) 本文提出了一种新的预处理方法,称为基于方差的信号选择器 (VSS),旨在识别有效的 PPG 信号。基于 Chen 等人(2024 年)利用峰值距离方差评估信号质量的见解,VSS 方法通过结合峰高和峰差方差的评估来增强这一概念。此外,它还应用最小峰高标准,以确保准确的信号选择。这种先进的技术可以有效地区分极小的收缩期峰和过大的舒张期峰值,从而确保所选信号的可靠性。
- 二) 这项工作开发了一种旨在放大 PPG 信号中收缩期和舒张期峰值的新型基于卷积的峰值增强 (CPE) 方法。这种增强功能已被证明可以有效减少运动伪影对波形的影响,从而提高信号质量和可靠性。
- 三) 这项工作提出了一种新的基于图像的多域网络 (MDI-Net) 和基于多路径的一维信号网络 (MUS-Net),用于在并行结构中提取时间、形态和光谱特征。在并行网络中,MUS-Net 专为分析一维 ABP 信号的短期和长期特征而量身定制。相比之下,MDI-Net 利用预先训练的 Inception 网络来处理转换后的 PPG 图像,从而能够提取丰富的形态和光谱特征。为了弥合每个网络中互补模式之间的差距,该研究引入了多流空间和交叉注意力网络 (M-SCAN)。这种新颖的注意力机制在提炼和整合各种特征方面发挥着关键作用,确保了协同特征学习,从而显着增强了网络捕获复杂关系的能力。
- 四) 这项工作提出了一种基于 CNN 和 xLSTM (Bi-LSTM 和 LSTM) 的新型多流融合网络 (MSFN),它有效地整合了 MUS-Net 和 MDI-Net 提取的各种特征。通过利用 CNN 的短期处理和 xLSTM 的长期处理优势,MSFN 确保了无缝和强大的特征融合。
- v) 已经开发了一种新型的基于 ML 的领域知识集成动态定量嵌入基于监督的调整 (D-QuEST) 网络,该网络利用了 DL 模型中的手动特征提取能力。在 DL 中包含 ML 模型通过提供特定于领域的监督来提高性能,该监督在训练期间使用手工制作的功能指导 DL 模型。这种集成提高了泛化性并减少了过拟合,同时允许使用可学习耦合因子 (LCF) 动态调整 DL 模型的参数,从而优化了框架根据 PPG 估计 BP 的能力。
2. 材料和方法
2.1. 数据集
2.1.1. MIMIC 数据集
2.1.2. VitalDB 数据集
2.2. 数据预处理
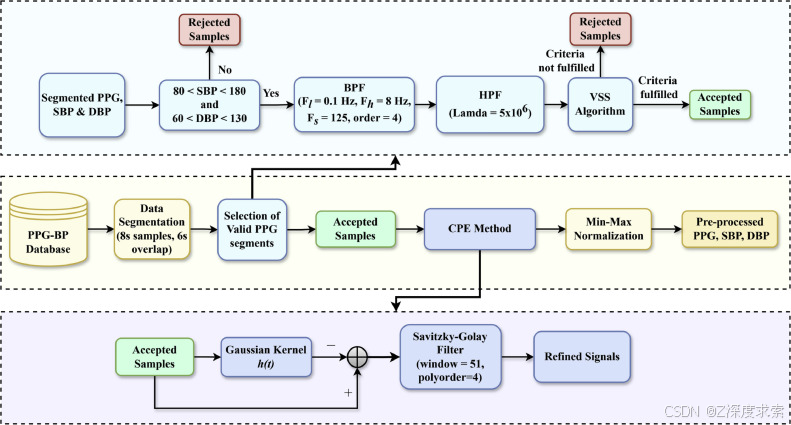
图 1.整体预处理框架,包括所提出的信号选择和峰增强方法。
2.2.1. 选择有效的 PPG 段


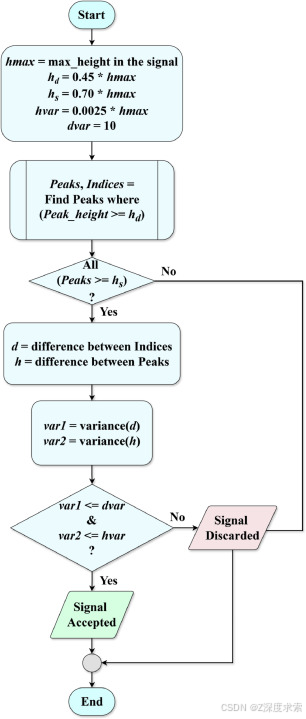
图 2.VSS 算法的流程图。
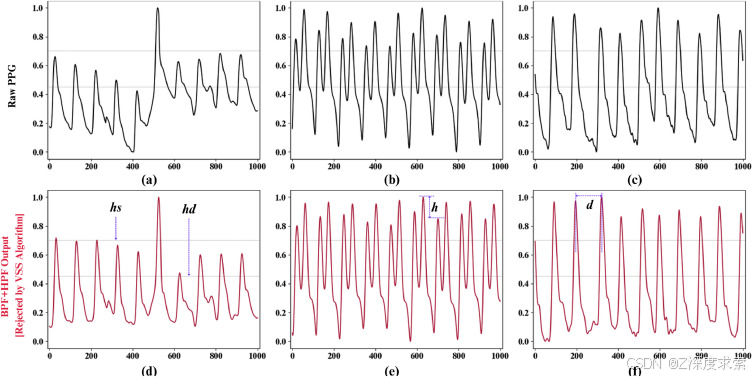
图 3.通过提出的 VSS 算法任意拒绝的原始 PPG 片段,包括 BPF+HPF 的相应输出,带有拒绝子句:(a, d) 收缩压高度低于阈值上限,(b, e) 身高方差超过阈值,以及 (c, f) 距离方差超过阈值。
2.2.2. 收缩压和舒张压峰值增强的 CPE 方法
准确识别收缩期和舒张期峰值对于评估心血管功能至关重要。然而,某些 PPG 信号表现出不规则性,例如过于尖锐的收缩期峰值或较小的舒张期峰值,这可能会妨碍峰值检测算法的精度。为了缓解这些问题,这项工作引入了一种基于卷积的峰值增强技术。

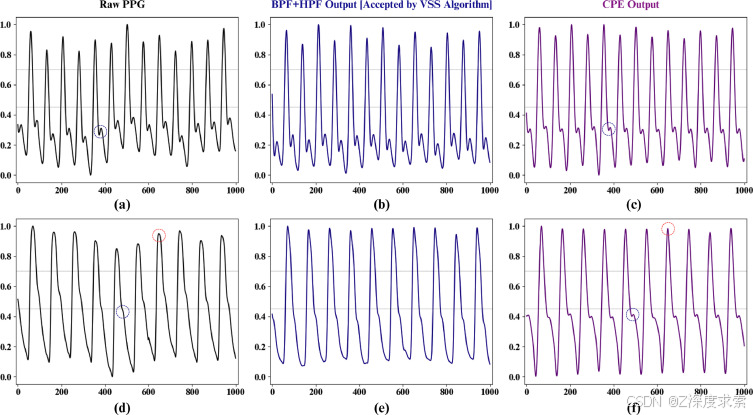
图 4.所提出的 VSS 算法任意接受的原始 PPG 片段,包括 BPF+HPF 的相应输出,以及所提出的 CPE 方法的效果,带有标记物,用于显示原始信号中 (a-c) 突出峰和 (d-f) 抑制峰的峰增强。
2.2.3. 归一化

2.3. 建议的网络架构
本研究的整体网络架构如图 5 所示。PPG 信号通过两个并行网络进行处理:1) MUS-Net,一种基于 CNN 和 xLSTM 的网络,旨在从转换后的 ABP 信号中提取一维特征,以及 2) MDI-Net,一种基于 InceptionV3 的网络,用于从转换后的二维图像中提取特征。
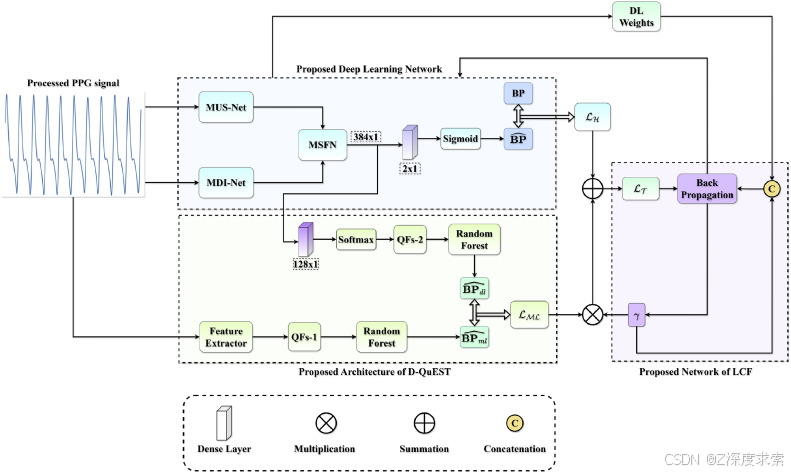
图 5.所提出的深度学习网络的总体框架和所提出的 D-QuEST 与 LCF 的传播。
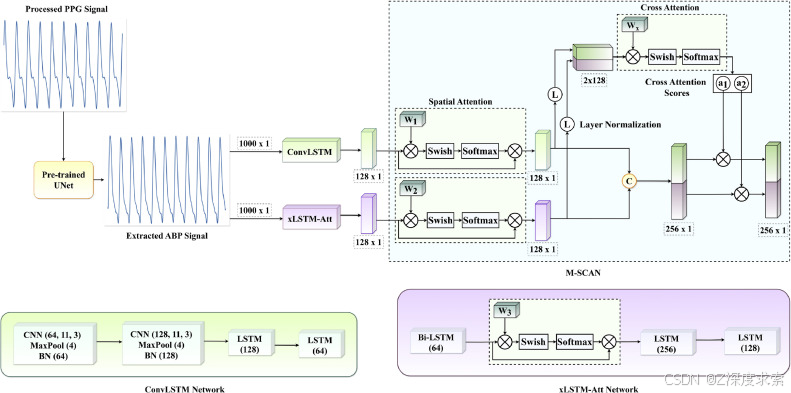
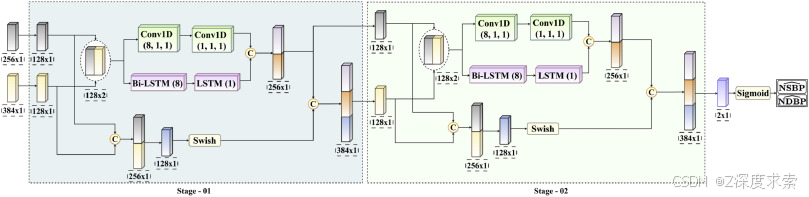
MUS-Net 由两个并行组件组成:xLSTM-Att 和 convLSTM,前者专注于长程依赖性,后者捕获一维信号中的短程和长程依赖性。为了优先考虑 MUS-Net 中最相关的特征,提出的 M-SCAN 机制分配了注意力权重以突出重要特征。此外,MDI-Net 处理三个不同转换图像域的 PPG 信号,使用预先训练的 InceptionV3 网络从 2-D 信号中提取空间和光谱特征。为了强调最重要的图像域,MDI-Net 中也采用了 M-SCAN。这些并行网络的输出使用基于 CNN-xLSTM 的双级 MSFN 进行集成,该 MSFN 估计 NSBP 和 NDBP。这种融合网络结合了长期和短期特征,确保了稳健的互补特征学习。
以下小节提供了并行网络和融合网络的详细说明。
2.3.1. 基于 CNN 和 xLSTM 的 MUS-Net



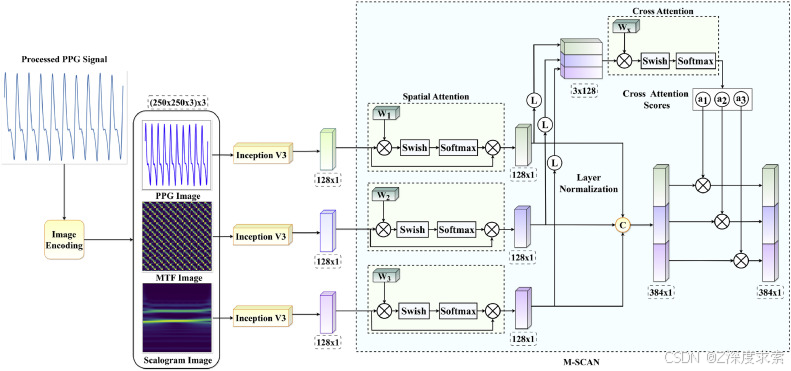
2.3.2. 基于 InceptionV3 的 MDI-Net
所提出的 MDI-Net 的整个工作流程如图 7 所示。为了使用所提出的 MDI-Net 进行训练,PPG 信号被转换为两个不同的域:1) 马尔可夫跃场 (MTF) 和 2) 基于小波的标量图,以从时域和频域中提取特征。此外,原始 PPG 图像还用于利用信号的形态特征。首先讨论图像编码模块的详细信息。


2.3.3. 多流融合网络


2.4. 损失函数
2.4.1. Huber 损失

2.4.2. 领域知识集成 D-QuEST
为了使用从精炼的 PPG 信号派生的基于 ML 的特征来增强深度学习模型,我们实现了一个特征提取器模块。该模块负责从处理后的 PPG 信号中提取 5 个高度相关的特征。选定的特征如下:(1) 心率 (HR),(2) 平均收缩期间 (MSI),(3) 平均舒张期 (MDI),(4) 升支时间 (ABT) 和 (5) 下降支时间 (DBT)。这些定量特征集 (QFs-1) 在预测血压和其他心血管指标方面起着关键作用。随机森林模型使用 QFs-1 估计 BP。

2.4.3. 全损

2.5. 实现细节
2.5.1. 训练详情
2.5.2. 测试细节
2.6. 性能评估指标

3. 实验结果和讨论
3.1. 性能指标
表 2 描述了最先进的方法和我们提出的方法之间的比较。尽管现有文献 (Kyung, Yang, Choi, Chang, Bae, Choi, Kim, 2023, Liu, Yu, Mou, 2023, Rong, Li, 2021, Tanveer, Hasan, 2019) 对于小数据表现足够,但它们对于大数据却非常困难。与其他现有方法相比,Rong & Li (2021) 提出的方法在较小的数据集上提供了更可靠的性能,但随着数据集多样性的增加,结果开始迅速下降。这种基于 CNN 的多类型方法在小数据上提供 0.24% MSE、3.36% MAE 和 98.91% PCC。增加数据变异会使结果降级为 1.27 % MSE、7.96 % MAE 和 92.21 % PCC。Panwar 等人(2020 年)提出的框架在大型数据集中最先进的方法中提供了更好的性能,实现了 0.74% 的 MSE、5.91% 的 MAE 和 95.58% 的 PCC。Kyung等人(2023年),Liu等人(2023年)和Tanveer & Hasan(2019年)的工作中描述的方法对于小数据表现良好,但在大数据集中未能提供良好的性能。所提出的方法在两种类型的数据中都大大优于所有现有的最先进方法,在小数据上实现了 0.05 % MSE、1.40 % MAE、99.36 % PCC,在大数据上实现了 0.06 % MSE、1.58 % MAE、99.09 % PCC。
Table 1. Computing system specifications.
| CPU | Intel(R) Core(TM) i7-8700K CPU @ 3.70GHz |
|---|---|
| GPU | 11GB NVIDIA GeForce GTX 1080Ti |
| RAM | 32GB DDR4 @ 3200 MHz |
Table 2. Performance metrics comparison of different methods using the small and the large datasets.
| Model | Small Data | Large Data | ||||
|---|---|---|---|---|---|---|
| Empty Cell | MSE(%) | MAE(%) | PCC(%) | MSE(%) | MAE(%) | PCC(%) |
| Panwar et al. (2020) | 0.32 % | 3.74 % | 98.15 % | 0.74 % | 5.91 % | 95.58 % |
| a Liu et al. (2023) | 0.30 % | 3.88 % | 98.30 % | 1.11 % | 6.95 % | 93.03 % |
| Kyung et al. (2023) | 0.81 % | 6.39 % | 95.11 % | 1.38 % | 8.83 % | 91.01 % |
| Rong & Li (2021) | 0.24 % | 3.36 % | 98.91 % | 1.27 % | 7.96 % | 92.21 % |
| a Tanveer & Hasan (2019) | 0.38 % | 4.23 % | 97.63 % | 1.23 % | 8.11 % | 92.00 % |
| Proposed | 0.05 % | 1.40 % | 99.36 % | 0.06 % | 1.58 % | 99.09 % |
Evaluated on only PPG signals as input.
3.2. BHS 标准
表 3 显示了现有方法在英国高血压协会 (BHS) 标准下的性能比较 (O'Brien et al., 1993)。BHS 标准根据误差小于 5 mmHg 、 10 mm 和 15 mmHg 的累积误差百分比来评估性能。如果最低 60 %、85 % 和 95 % 的估计值分别小于 5 mmHg、10 mmHg 和 15 mmHg,则性能被视为 A 级。根据错误百分比的等级在表格顶部提到。表 3 的底部存储了用于 SBP 和 DBP 估算的最新方法的 BHS 标准结果。Liu et al. . (2023), Panwar et al. . (2020)和 Rong & Li (2021) 的作品中提出的方法达到了“A”级的表现,而Kyung等人(2023)和Tanveer & Hasan (2019)的作品在小数据中达到了“B”级的表现。Rong & Li (2021)的方法在其他最先进的方法中取得了最好的结果,其中61.8%的SBP预测和82.9%的DBP预测保持在5 mmHg的累积误差范围内。Kyung等人(2023年),Rong & Li(2021年)和Tanveer & Hasan(2019年)的框架在大数据的SBP估计中取得了“D”级的表现和在DBP估计中的“C”级表现。Liu 等人(2023 年)在 SBP 估计中也取得了 “D”级,但在 DBP 估计中取得了 “B” 级。Panwar 等人(2020 年)的工作在最先进的方法中取得了最佳性能,40.8% SBP 和 63.6% DBP 估计保持在 5 mmHg 以下。拟议的框架为每项估计都获得了 A 级,无论数据大小。对于小数据,92.1% 的估计 SBP 和 96.8% 的估计 DBP 误差在 5 mmHg 以内。此外,对于大数据,90.7% 的估计 SBP 和 96.0% 的估计 DBP 误差在 5 mmHg 以内。
Table 3. BHS standard results of different methods using the small and the large datasets.
| Grade | Cumulative error (%) | ||
|---|---|---|---|
| Empty Cell | ≤ 5 mmHg | ≤ 10 mmHg | ≤ 15 mmHg |
| A | 60 | 85 | 95 |
| B | 50 | 75 | 90 |
| C | 40 | 65 | 85 |
| D | Worse than C grade | ||
| Model | BP type | Small data | Large data | ||||
|---|---|---|---|---|---|---|---|
| Empty Cell | Empty Cell | ≤ 5 mmHg | ≤ 10 mmHg | ≤ 15 mmHg | ≤ 5 mmHg | ≤ 10 mmHg | ≤ 15 mmHg |
| Panwar et al. (2020) | SBP | 62.6 % | 86.1 % | 93.6 % | 40.8 % | 66.3 % | 80.2 % |
| DBP | 79.5 % | 94.3 % | 97.5 % | 63.6 % | 89.5 % | 96.4 % | |
| Liu et al. (2023) | SBP | 59.1 % | 85.0 % | 94.7 % | 38.5 % | 55.4 % | 67.2 % |
| DBP | 81.3 % | 96.2 % | 98.8 % | 56.6 % | 86.1 % | 94.5 % | |
| a Kyung et al. (2023) | SBP | 36.8 % | 63.1 % | 78.3 % | 23.0 % | 43.6 % | 60.5 % |
| DBP | 55.1 % | 89.5 % | 96.8 % | 40.9 % | 76.4 % | 93.3 % | |
| Rong & Li (2021) | SBP | 61.8 % | 90.6 % | 97.0 % | 27.6 % | 49.7 % | 66.6 % |
| DBP | 82.9 % | 97.0 % | 98.6 % | 49.6 % | 82.7 % | 93.6 % | |
| a Tanveer & Hasan (2019) | SBP | 56.4 % | 82.2 % | 92.0 % | 26.9 % | 49.3 % | 65.3 % |
| DBP | 72.6 % | 92.2 % | 97.2 % | 46.7 % | 81.0 % | 93.4 % | |
| Proposed | SBP | 93.4 % | 98.7 % | 99.5 % | 90.7 % | 97.1 % | 99.1 % |
| DBP | 97.0 % | 99.4 % | 99.8 % | 96.0 % | 99.2 % | 99.7 % | |
Evaluated on only PPG signals as input.
3.3. AAMI 标准
医疗器械进步 (AAMI) 标准结果(Stergiou et al., 2018)考虑了真实血压和估计血压之间的 ME 和标准差 (SD)。根据 AAMI 标准,如果 ME 和 SD 分别小于 5 mmHg 和 8 mmHg,则性能是“可接受的”。现有模型与拟议模型之间的 AAMI 标准结果比较如表 4 所示。除了 Kyung 等人 (2023) 的工作外,根据小数据中的 AAMI 标准,其他最先进的方法可以被认为是“可接受的”。然而,这些框架在大数据中表现出低于标准的性能,具有更高的 SD。所提出的方法在 SBP 和 DBP 估计中都成功地实现了 “可接受 ”的性能,无论数据是小数据还是大数据,SD 和 ME 都非常低。
Table 4. AAMI standard results of different methods using the small and the large datasets.
| Grade | Metrics | |
|---|---|---|
| Empty Cell | ME (mmHg) | SD (mmHg) |
| Acceptable | ≤ 5 | ≤ 8 |
| Not Acceptable | Otherwise | |
| Model | BP Type | Small Data | Large Data | ||
|---|---|---|---|---|---|
| Empty Cell | Empty Cell | ME (mmHg) | SD (mmHg) | ME (mmHg) | SD (mmHg) |
| Panwar et al. (2020) | SBP | 0.07 | 7.67 | – 0.61 | 9.97 |
| DBP | 0.23 | 5.47 | – 0.19 | 6.83 | |
| Liu et al. (2023) | SBP | 3.92 | 7.01 | 8.42 | 10.13 |
| DBP | 3.25 | 3.65 | 5.87 | 7.49 | |
| a Kyung et al. (2023) | SBP | 6.97 | 8.17 | 10.19 | 11.86 |
| DBP | 5.35 | 8.53 | 7.01 | 8.95 | |
| Rong & Li (2021) | SBP | –3.08 | 6.27 | 9.66 | 10.59 |
| DBP | –1.36 | 4.22 | 6.45 | 7.15 | |
| a Tanveer & Hasan (2019) | SBP | –0.38 | 7.30 | –0.67 | 10.55 |
| DBP | 0.15 | 6.25 | –0.35 | 7.91 | |
| Proposed | SBP | –0.13 | 2.91 | –0.09 | 4.09 |
| DBP | –0.12 | 2.04 | –0.01 | 2.62 | |
Evaluated on only PPG signals as input.
3.4. 统计分析
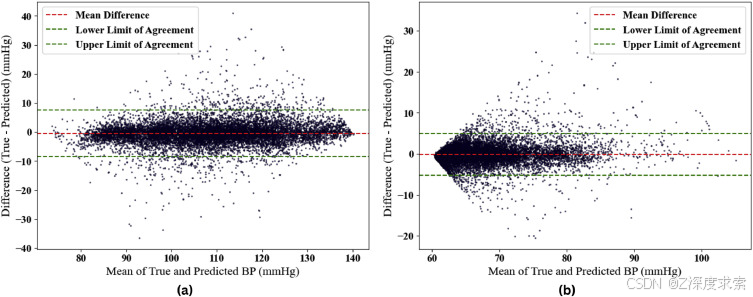
图 9.Bland-Altman 图,用于估计 (a) SBP 和 (b) DBP,使用在大型数据集上训练的拟议方法。
图 10 显示了真实血压和估计血压之间的相关性。绿线表示完美估计,红线表示拟议模型的预测。该图暗示绿线和红线彼此非常接近。红线和绿线越近,估计值越好。SBP 和 DBP 的回归图描述了真实血压和估计血压之间的极高相关性。
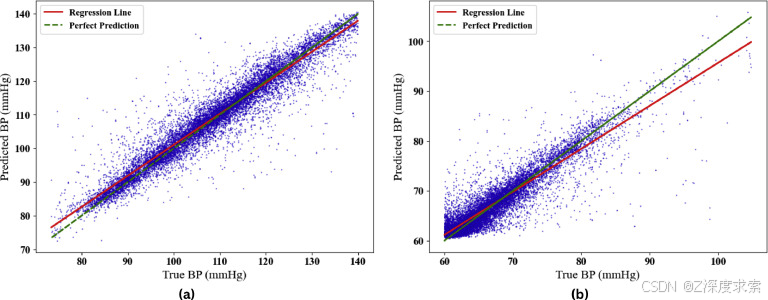
图 10.使用在大型数据集上训练的建议方法估计 (a) SBP 和 (b) DBP 的回归图。
在图 11 中,残差图和相应的直方图提供了对位于“零残差线”周围的估计分布的更多见解。残差图的关联直方图表明零残差线中有超过 6500 个估计值。此外,相当大的估计值位于 10 mmHg 误差范围内。
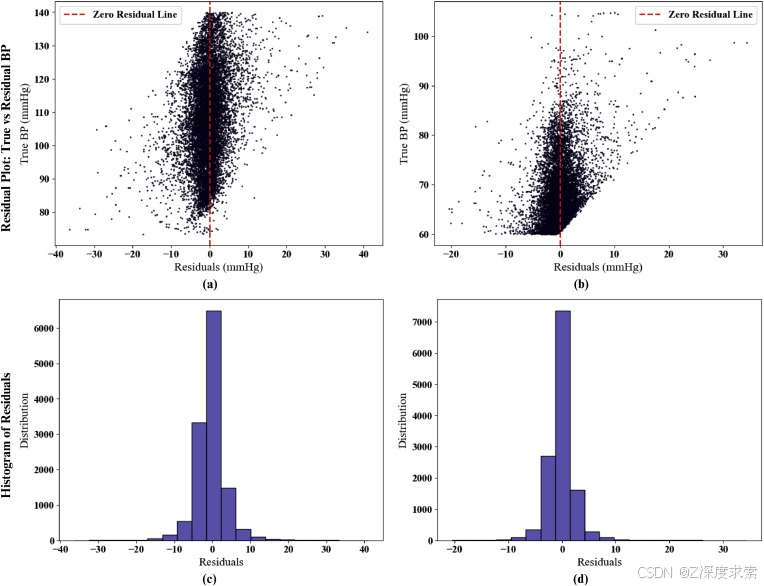
图 11.残差图和相应的直方图,用于估计 (a, c) SBP 和 (b, d) DBP,使用在大型数据集上训练的建议方法。
3.5. 讨论
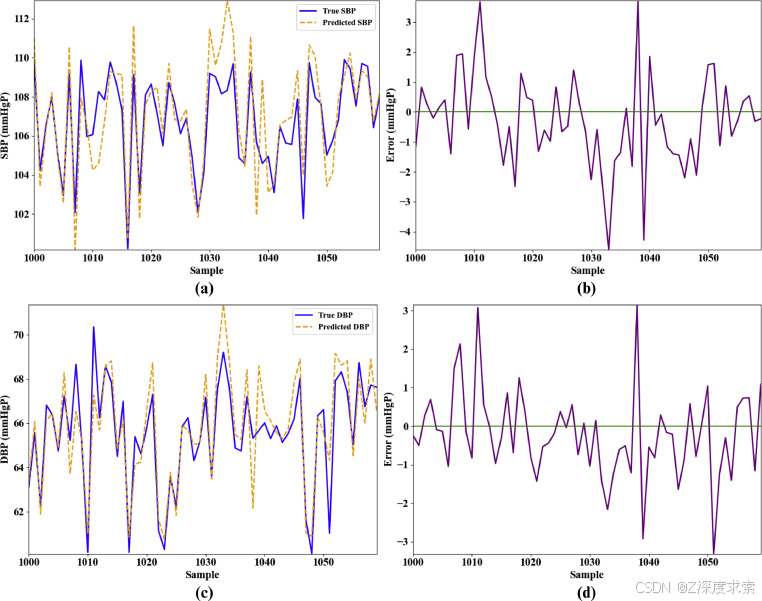
图 12.在任意主题的大数据上训练的所提框架的连续 BP 估计性能。(a) SBP 估计,(b) 详细的 SBP 误差分析,(c) DBP 估计,以及 (d) 详细的 DBP 误差分析。
基于 PPG 的 BP 估计模型的泛化性受到训练数据集的多样性和代表性的显著影响。在同质数据集上训练的模型在不同人群中的准确性可能会降低,从而引入潜在的偏差。通过整合年龄、性别、种族和肤色等人口统计属性来提高数据集的多样性,对于提高稳健性和可靠性至关重要。解决生理变化并确保不同人群的公平代表对于开发普遍适用的血压估计模型至关重要(Aguet、Van Zaen、Proença、Bonnier、Frossard、Lemay,2022 年、Elgendi、Haugg、Fletcher、Allen、Shin、Alian、Menon,2024a、Mehta、Kwatra、Jain、McDuff,2024 年,Weber-Boisvert、Gosselin、Sandberg,2023 年)。
与小数据集相比,这项工作中使用的大型数据集在年龄和性别方面表现出更大的受试者多样性。此外,与小型数据集相比,大型数据集中的年龄组在男性和女性之间的分布更均匀。一般来说,增加数据集多样性有助于减少模型对任何特定组的偏差。这个小型数据集在性别上分布不均匀(女性受试者多于男性),显示男性的误差大于女性。相比之下,较大的数据集具有更均衡的分布,为男性和女性提供更一致的结果。为了支持这一观察结果,图 13(a) 和 (b) 说明了小型和大型数据集中受试者和性别的多样性,其中大型数据集显示出更多的多样性。此外,图 13(c) 显示了两个数据集中性别分布的平均血压误差,突出了跨性别组的大型数据集中更一致的血压估计性能。
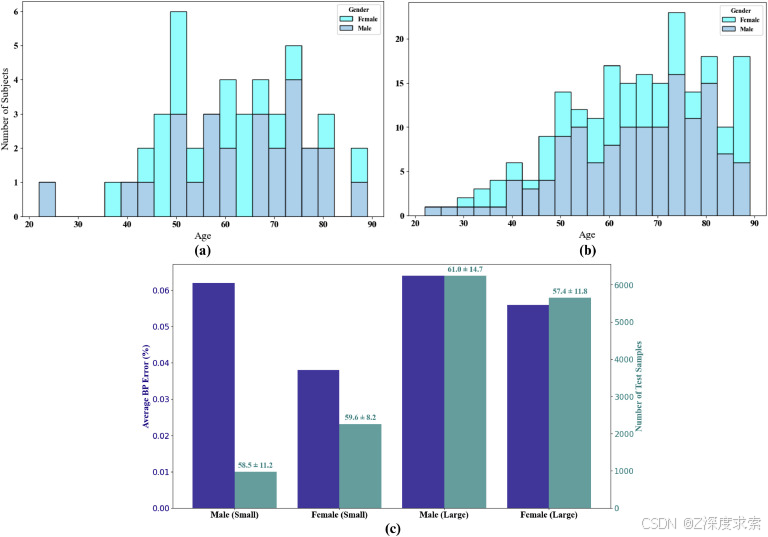
图 13.在 (a) 小型和 (b) 大型数据集中按年龄和性别划分的受试者分布,以及 (c) 两个数据集按性别划分的预测误差分析以及相应的样本编号。
此外,与小数据集相比,大型数据集在 BP 范围内表现出更大的多样性。然而,大型数据集不包括极其多样化的血压范围,这意味着结果中仍然存在一些偏差。然而,与小数据集相比,大数据集对任何特定血压组的偏倚较小。为了说明这一点,分析了四个血压类别的血压估计误差——低(SBP<90 mmHgP 或 DBP<60 mmHgP)、最佳(SBP<120 mmHgP 和 DBP<80 mmHgP)、前高(SBP<140 mmHgP 或 DBP<90 mmHgP)和高血压(SBP>140 mmHgP 或 DBP>90 mmHgP)(Mitchell, Mulholland, & Khuman, 2022)。如图 14 所示,前两个 BP 类别的 BP 估计误差低于后两个 BP 类别,这可能是由于后一类的样本量相对较小。这种有限的样本量阻碍了模型在 PPG 信号中捕获复杂模式以实现准确 BP 估计的能力。增加样本数量可能会提高后一类的性能。但是,两种模型的估计误差都保持在可接受的范围内。此外,与小数据集相比,大型数据集中不同 BP 组之间的误差标准差较小,表明性能更可靠。
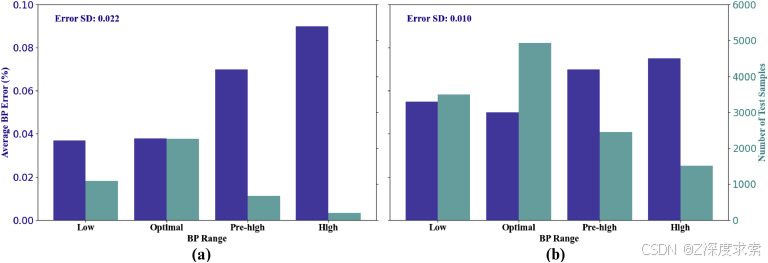
图 14.根据 Mitchell 等人 (2022) 提到的 BP 图表,(a) 小数据集和 (b) 大数据集,包括相应数量的测试样本,不同 BP 水平的血压估计误差。
所提出的框架在小型和大型数据集上都取得了强大的性能,证明了它在捕获 PPG 波形中的复杂模式并将其与 BP 相关联方面的效率,从而强调了其通用性。将训练数据集的多样性扩展到更广泛的年龄、身体条件或 BP 可以进一步提高所提出的框架的通用性,这是一个值得在未来工作中探索的方向。
同样重要的是要强调,该实验是使用混合类型的训练测试数据集进行的,其中训练和测试数据集包括重叠或相似的受试者。虽然这种方法提供了对模型性能的初步评估,但它并不能充分评估模型泛化到完全看不见的主体的能力。在实际应用中,BP 估计模型通常需要与新的、看不见的个体一起运行,这些个体的生理特征可能与训练数据中存在的个体有很大不同。使用非混合数据集评估模型,其中训练集和测试集包含不同的、不重叠的主题,将提供更严格的通用性和稳健性衡量标准。解决这一限制对于确保模型在实际场景中的可靠性至关重要,例如临床部署或可穿戴设备应用。在未来的工作中探索这一方向可能会带来有价值的见解,并进一步加强所提出的系统在各种和动态的现实世界环境中的适用性。
对于实际临床应用,所提出的方法可以在捕获 PPG 样本并使用预先训练的网络权重来估计 BP 的设备中实现。这些权重可以存储在服务器上以进行定期更新,从而实现持续改进。此外,可以集成一个轻量级的、可本地训练的校准网络,以微调模型以进行个性化 BP 估计,从而有效解决非混合数据集带来的挑战(Elgendi et al., 2024a)。
4. 消融研究
在本节中,通过展示预处理步骤的好处、所提出模型模块的效果以及领域知识集成的 D-QuEST 来验证不同组件的影响。为了评估消融研究,选择了小数据。
4.1. 预处理的影响
预处理步骤包括四个步骤:1) BPF、2) HPF、3) VSS 和 4) CPE。最近对基于深度学习的 PPG BP 估计的研究利用 BPF 去除高频噪声分量。表 5 显示,去除噪声分量明显提高了性能。此外,为了消除 PPG 信号中的趋势效应,在 BPF 之后实施了 HPF。表 5 显示,在 BPF 后使用 HPF 可降低 0.03 % 的 MSE 和 0.11 % 的 MAE,并使 PCC 增加 0.17 %。这种改进是意料之中的,因为去除趋势分量,消除了信号的直流偏移,丰富了信号质量。直流分量通常对 BP 值没有影响,而是表示由于测量设备振动引起的信号漂移。此外,可以使用建议的 VSS 算法将损坏的 PPG 样本排除在训练和测试程序之外。这些损坏的 PPG 样本不能保留 PPG 信号的正确形状,导致与 BP 估计的相关性较低。加入 VSS 可分别使 MSE 和 MAE 降低 0.06 % 和 0.13 %,并使 PCC 增加 0.18 %。血压的测量主要取决于收缩压和舒张压峰值,使这些峰值成为 PPG 信号中最重要的部分之一。CPE 模块使用基于卷积的滤波器增强峰,使模型能够有效地学习收缩期和舒张期峰的位置。从表 5 中可以明显看出,包含 CPE 模块可将 MSE、MAE 和 PCC 分别提高 0.05 %、0.39 % 和 0.04 %。
Table 5. Performance evaluation of the proposed model using different preprocessing schemes on the small dataset.
| Preprocessing Method | MSE (%) | MAE (%) | PCC (%) |
|---|---|---|---|
| (a) Raw | 0.23 % | 2.27 % | 98.41 % |
| (b) BPF | 0.19 % | 2.15 % | 98.90 % |
| (c) b + HPF | 0.16 % | 2.04 % | 99.07 % |
| (d) c + VSS | 0.10 % | 1.91 % | 99.25 % |
| (e) d + CPE (Proposed) | 0.05 % | 1.40 % | 99.36 % |
4.2. 建议模块的影响
所提出的深度学习网络由两个并行网络组成: MUS-Net 和 MDI-Net,旨在分别处理 1-D 和 2-D 特征空间中的 PPG 信号。对于 MDI-Net,Inception-V3 已被选为基础网络,因为它具有有效的性能和高效处理和提取 2-D 数据特征的能力。对于 MUS-Net,LSTM 和 GRU 都可以被视为从 1-D 信号中提取有效特征的基础网络。为了确定一维信号处理的最佳模型,我们将基于 LSTM 的网络(xLSTM 和 convLSTM)与基于 GRU 的网络(xGRU 和 convGRU)进行了比较。如表6所示,xLSTM的性能优于xGRU,这可能是由于LSTM中的额外门(输入、忘记和输出),这提供了对信息流的更大控制,使它们能够更长时间地保留信息并更有效地捕获长期依赖性(Pudikov & Brovko,2020)。因此,已选择 xLSTM-Att 作为基础网络来评估所提出模型的有效性。
Table 6. Performance comparison between xLSTM and convLSTM models versus xGRU and convGRU models for small and large datasets.
| Data | Performance Metrics | Model | |
|---|---|---|---|
| Empty Cell | Empty Cell | xLSTM and ConvLSTM | xGRU and ConvGRU |
| Small | MSE (%) | 0.05 % | 0.05 % |
| MAE (%) | 1.40 % | 1.46 % | |
| PCC (%) | 99.36 % | 99.27 % | |
| Large | MSE (%) | 0.06 % | 0.09 % |
| MAE (%) | 1.58 % | 1.96 % | |
| PCC (%) | 99.09 % | 98.77 % | |
表 7 显示,xLSTM-Att 提供的 MSE、MAE 和 PCC 的中等性能分别为 1.44 %、8.46 % 和 91.72 %。尽管 xLSTM-Att 从正向和反向提取序列数据中的时间特征,但添加 ConvLSTM 作为并行网络 – MUS-Net 有助于从一维信号中提取短期和长期时间特征。利用这两种特性可提供卓越的性能,使 MSE 和 MAE 分别降低 1.15% 和 5.13%,PCC 增加 6.62%。
Table 7. Ablation experiment showing the results of multiple parallel modules of the proposed framework using the small dataset.
| Model | Loss | Performance metrics | |||
|---|---|---|---|---|---|
| Empty Cell | Huber | D-QuEST | MSE (%) | MAE (%) | PCC (%) |
| (a) xLSTM-Att | ✔ | – | 1.44 % | 8.46 % | 91.72 % |
| (b) a + ConvLSTM | ✔ | – | 0.29 % | 3.33 % | 98.34 % |
| (c) b + MDI-Net | ✔ | – | 0.26 % | 3.16 % | 98.54 % |
| (d) c + MSFN | ✔ | – | 0.18 % | 2.41 % | 98.92 % |
| (e) d + UABP | ✔ | – | 0.13 % | 2.12 % | 99.21 % |
| (f) e + UABP | ✔ | ✔ | 0.06 % | 1.52 % | 99.29 % |
| (g) f + M-SCAN | ✔ | ✔ | 0.05 % | 1.40 % | 99.36 % |
此外,实施 MDI-Net 并与 (b) 连接,将性能提高到 0.26% MSE、3.16% MAE 和 98.54% PCC。这种性能改进是意料之中的,因为图像域包含了 1-D 数据中通常不可用的隐藏特征。此外,将信号转换为图像域可以释放利用在大型数据集 (ImageNet) 上预先训练的基于卷积的架构 (InceptionV3) 的好处。包含预训练架构为从 PPG 信号的大小变化中提取极其复杂的模式铺平了道路。然而,MSFN 的集成允许从 1-D 和 2-D 信号域提取的特征之间进行适当融合,从而实现极其高效的互补学习。MSFN 使 MSE 降低 0.08 %,MAE 降低 0.75 %,PCC 进一步增加 0.38 %。
从两个维度利用 PPG 信号中的特征,提供了非常好的性能。然而,从 ABP 信号而不是 PPG 信号中提取一维特征,可以显著提高所提模型的性能。表 7 显示 MSE 下降了 0.05%,MAE 下降了 0.29%,PCC 增加了 0.29%。这种性能的提升是 ABP 信号随 BP 值变化而明显变化的结果。为了保留 PPG 信号的结构特征信息,只有 MUS-Net 提供 ABP 信号,使 MDI-Net 完全依赖于 PPG。这种架构使模型能够从 ABP 中学习互补特征,而这些特征通常仅在 PPG 中是不存在的。最后,为了进一步提高性能,采用所提出的 M-SCAN,而不是直接串联 MUS-Net 和 MDI-Net 的并行通道。M-SCAN 有效地专注于更重要的功能,从而进一步提高性能。表 7 显示,纳入 M-SCAN 导致 0.05% MSE、1.40% MAE 和 99.36% PCC。
4.3. 领域知识集成 D-QuEST 的影响
通过结合基于 ML 的领域知识集成 D-QuEST 架构,所提出的网络的性能是动态调整的。尽管单独的 ML 无法捕获数据中的关键模式,但将 ML 与 DL 相结合可以使 DL 模型学习可能被忽视的特征。但是,将 ML 特征直接包含在 DL 中会导致不明确的特征融合,因为这些特征属于完全不同的类别。此外,在 DL 模型的训练和测试阶段,在特征空间中包含 ML 特征将需要这些特征。测试周期中对 ML 功能的需求会减慢评估过程,因为提取 ML 功能很麻烦并且需要手动管理。这可以防止 DL 模型完全自动化。因此,在这项研究中,ML被提出的D-QuEST架构用作监督机制。ML 模型的专业知识源自手工制作的特征,通过评估第 2.4.2 节中描述的损失来指导 DL 模型。将 ML 作为专家监督的损失函数不仅可以提高性能,还可以在测试数据评估期间省略 ML 指导,使 DL 模型能够作为一个强大的全自动网络运行。表 7 显示,D-QuEST 将所提议网络的整体性能提高了 0.08 % 和 0.6 % 的 MSE 和 MAE,以及 PCC 增加了 0.08 %。
5. 总结
本文引入了一种新的深度学习框架,该框架由 ML 引导的损失函数增强,仅根据增强的 PPG 信号估计 BP。通过整合创新的预处理步骤,例如峰高方差检查和信号优化,该框架有效地解决了与噪声灵敏度和受试者多样化特征相关的挑战。通过 MUS-Net 集成长期和短期时间特征,包括通过 MDI-Net 的结构和光谱特征已被证明可以显着提高 BP 估计的准确性。虽然一些现有方法在小型数据集上提供了足够的性能,但随着数据集多样性的增加,它们难以保持这种有效性水平,这凸显了它们在处理更复杂的多样化数据方面的局限性。该模型的卓越性能在公开可用的数据集上进行了测试,表明与最先进的方法相比,它有显著的改进。它实现了高性能指标,包括在数据多样性较小的数据集上达到 0.05% MSE、1.40% MAE 和 99.36% PCC,在数据多样性较大的数据集上实现 0.06% MSE、1.58% MAE 和 99.09% PCC。该解决方案为远程和连续血压监测提供了一种强大的方法,为不同人群的实际应用提供了广阔的潜力。然而,该实验依赖于混合类型的训练测试数据集,限制了其评估看不见的受试者性能的能力。使用非混合数据集评估模型(其中训练和测试涉及不同的主题)仍未探索。解决这一限制对于将系统集成到实际场景中至关重要,并且可以在未来的工作中进行探索。
数据可用性(代码已复现)
本研究中使用的数据集 MIMIC-III 和 VitalDB 是公开可用的。MIMIC-III 可以通过 PhysioNet (MIMIC-III Clinical Database v1.4) 访问,VitalDB 可在 (VitalDB) 访问。
引用
- D. Acharya, A. Rani, S. Agarwal, V. SinghApplication of adaptive Savitzky–Golay filter for EEG signal processingPerspectives in Science, 8 (2016), pp. 677-679View PDF View article Google Scholar
- Aguet, Van Zaen, Proença, Bonnier, Frossard, Lemay, 2022 C. Aguet, J. Van Zaen, M. Proença, G. Bonnier, P. Frossard, M. LemayGeneralization capability of a neural network for blood pressure estimation from photoplethysmography2022 Computing in Cardiology (cinc), vol. 498, IEEE (2022), pp. 1-4Google Scholar
- Aldrich, 2023 C. AldrichA comparative analysis of image encoding of time series for anomaly detectionTime series analysis - Recent advances, new perspectives and applications, IntechOpen (2023)Google Scholar
- Allen, 2007 J. AllenPhotoplethysmography and its application in clinical physiological measurementPhysiological Measurement, 28 (3) (2007), Article R1Google Scholar
- Bagha, Shaw, 2011 S. Bagha, L. ShawA real time analysis of PPG signal for measurement of SpO2 and pulse rateInternational Journal of Computer Applications, 36 (11) (2011), pp. 45-50Google Scholar
- Chao, Wu, Nguyen, Nguyen, Huang, Le, 2021 P.C.-P. Chao, C.-C. Wu, D.H. Nguyen, B.-S. Nguyen, P.-C. Huang, V.-H. LeThe machine learnings leading the cuffless PPG blood pressure sensors into the next stageIEEE Sensors Journal, 21 (11) (2021), pp. 12498-12510Crossref View in Scopus Google Scholar
- Chen, Yang, Chen, Han, Gong, Wang, Zhang, 2024 Q. Chen, X. Yang, Y. Chen, X. Han, Z. Gong, D. Wang, J. ZhangA blood pressure estimation approach based on single-channel photoplethysmography differential featuresBiomedical Signal Processing and Control, 97 (2024), Article 106662View PDF View article View in Scopus Google Scholar
- Chung Chung, M. K. (2020). Gaussian kernel smoothing. arXiv preprint arXiv: 2007.09539.Google Scholar
- Cogley, Nason, 1995 Real bus cyclesT. Cogley, J.M. NasonEffects of the Hodrick-Prescott filter on trend and difference stationary time series implications for business cycle research:pp. 626–651Journal of Economic Dynamics and Control, 19 (1–2) (1995), pp. 253-278(2013)View PDF View article View in Scopus Google Scholar
- Desquins, Bousefsaf, Pruski, Maaoui, 2022 T. Desquins, F. Bousefsaf, A. Pruski, C. MaaouiA survey of photoplethysmography and imaging photoplethysmography quality assessment methodsApplied Sciences, 12 (19) (2022), p. 9582Crossref View in Scopus Google Scholar
- El-Hajj, Kyriacou, 2020 C. El-Hajj, P.A. KyriacouA review of machine learning techniques in photoplethysmography for the non-invasive cuff-less measurement of blood pressureBiomedical Signal Processing and Control, 58 (2020), Article 101870View PDF View article View in Scopus Google Scholar
- El-Hajj, Kyriacou, 2021a C. El-Hajj, P.A. KyriacouCuffless blood pressure estimation from PPG signals and its derivatives using deep learning modelsBiomedical Signal Processing and Control, 70 (2021), Article 102984View PDF View article View in Scopus Google Scholar
- El-Hajj, Kyriacou, 2021b C. El-Hajj, P.A. KyriacouDeep learning models for cuffless blood pressure monitoring from PPG signals using attention mechanismBiomedical Signal Processing and Control, 65 (2021), Article 102301View PDF View article View in Scopus Google Scholar
- Elgendi, 2012 M. ElgendiOn the analysis of fingertip photoplethysmogram signalsCurrent Cardiology Reviews, 8 (1) (2012), pp. 14-25View at publisher Crossref View in Scopus Google Scholar
- Elgendi, 2016 M. ElgendiOptimal signal quality index for photoplethysmogram signalsBioengineering, 3 (4) (2016), p. 21View at publisher Crossref View in Scopus Google Scholar
- Elgendi, Haugg, Fletcher, Allen, Shin, Alian, Menon, 2024a M. Elgendi, F. Haugg, R.R. Fletcher, J. Allen, H. Shin, A. Alian, C. MenonRecommendations for evaluating photoplethysmography-based algorithms for blood pressure assessmentCommunication & Medicine, 4 (1) (2024), p. 140View in Scopus Google Scholar
- Elgendi, Martinelli, Menon, 2024b M. Elgendi, I. Martinelli, C. MenonOptimal signal quality index for remote photoplethysmogram sensingnpj Biosensing, 1 (1) (2024), p. 5Google Scholar
- Elsamnah, Bilgaiyan, Affiq, Shim, Ishidai, Hattori, 2019 F. Elsamnah, A. Bilgaiyan, M. Affiq, C.-H. Shim, H. Ishidai, R. HattoriReflectance-based organic pulse meter sensor for wireless monitoring of photoplethysmogram signalBiosensors, 9 (3) (2019), p. 87View at publisher Crossref View in Scopus Google Scholar
- Farjana, Singha, Al Farabi, 2021 F. Farjana, S.K. Singha, A. Al FarabiCuffless blood pressure determination using photoplethysmogram (PPG) signal based on multiple linear regression analysis2021 International Conference on Science and Contemporary Technology (ICSCT), IEEE (2021), pp. 1-5View at publisher Crossref Google Scholar
- Fine, Branan, Rodriguez, Boonya-Ananta, Ajmal, Ramella-Roman, McShane, Cote, 2021 J. Fine, K.L. Branan, A.J. Rodriguez, T. Boonya-Ananta, Ajmal, J.C. Ramella-Roman, …, G.L. CoteSources of inaccuracy in photoplethysmography for continuous cardiovascular monitoringBiosensors, 11 (4) (2021), p. 126View at publisher Crossref View in Scopus Google Scholar
- Goda, Charlton, Behar, 2023 M.Á. Goda, P.H. Charlton, J.A. BeharRobust peak detection for photoplethysmography signal snalysis2023 Computing in Cardiology (cinc), vol. 50, IEEE (2023), pp. 1-4View at publisher Crossref Google Scholar
- Haddad, Boukhayma, Caizzone, 2021 S. Haddad, A. Boukhayma, A. CaizzoneContinuous PPG-based blood pressure monitoring using multi-linear regressionIEEE Journal of Biomedical and Health Informatics, 26 (5) (2021), pp. 2096-2105Google Scholar
- Hasanzadeh, Ahmadi, Mohammadzade, 2019 N. Hasanzadeh, M.M. Ahmadi, H. MohammadzadeBlood pressure estimation using photoplethysmogram signal and its morphological featuresIEEE Sensors Journal, 20 (8) (2019), pp. 4300-4310Google Scholar
- Hernando, Peláez-Coca, Gil, 2024 A. Hernando, M.D. Peláez-Coca, E. GilDecomposing photoplethysmogram waveforms into systolic and diastolic waves, with application to hyperbaric environmentsBiomedical Signal Processing and Control, 88 (2024), Article 104814View PDF View article View in Scopus Google Scholar
- Ibtehaz, Mahmud, Chowdhury, Khandakar, Ayari, Tahir, & Rahman Ibtehaz, N., Mahmud, S., Chowdhury, M. E. H., Khandakar, A., Ayari, M. A., Tahir, A., & Rahman, M. S. (2020). PPG2ABP: Translating Photoplethysmogram (PPG) Signals to Arterial Blood Pressure (ABP) Waveforms using Fully Convolutional Neural Networks. arXiv preprint arXiv: 2005.01669.Google Scholar
- Jeong, Lim, 2021 D.U. Jeong, K.M. LimCombined deep CNN–LSTM network-based multitasking learning architecture for noninvasive continuous blood pressure estimation using difference in ECG-PPG featuresScientific Reports, 11 (1) (2021), Article 13539View in Scopus Google Scholar
- Johnson, Pollard, Shen, Lehman, Feng, Ghassemi, Moody, Szolovits, Anthony Celi, Mark, 2016 A.E.W. Johnson, T.J. Pollard, L. Shen, L.-w.H. Lehman, M. Feng, M. Ghassemi, …, R.G. MarkMIMIC-III, A freely accessible critical care databaseScientific Data, 3 (1) (2016), pp. 1-9Crossref Google Scholar
- Khan, Pretty, Amies, Elliott, Shaw, Chase, 2015 M. Khan, C.G. Pretty, A.C. Amies, R. Elliott, G.M. Shaw, J.G. ChaseInvestigating the effects of temperature on photoplethysmographyIFAC-PapersOnLine, 48 (20) (2015), pp. 360-365View PDF View article View in Scopus Google Scholar
- Kyung, Yang, Choi, Chang, Bae, Choi, Kim, 2023 J. Kyung, J.-Y. Yang, J.-H. Choi, J.-H. Chang, S. Bae, J. Choi, Y. KimDeep-learning-based blood pressure estimation using multi channel photoplethysmogram and finger pressure with attention mechanismScientific Reports, 13 (1) (2023), p. 9311View in Scopus Google Scholar
- Le, Ellington, Lee, Vo, Khine, Krishnan, Dutt, Cao, 2020 T. Le, F. Ellington, T.-Y. Lee, K. Vo, M. Khine, S.K. Krishnan, …, H. CaoContinuous non-invasive blood pressure monitoring: A methodological review on measurement techniquesIEEE Access, 8 (2020), pp. 212478-212498Crossref View in Scopus Google ScholarView at publisher
- Lee, Park, Yoon, Yang, Park, Jung, 2022 H.-C. Lee, Y. Park, S.B. Yoon, S.M. Yang, D. Park, C.-W. JungVitalDB, a high-fidelity multi-parameter vital signs database in surgical patientsScientific Data, 9 (1) (2022), p. 279Google Scholar
- Lewis, British, Society, 2019 P.S. Lewis, British, I.H. SocietyOscillometric measurement of blood pressure: A simplified explanation. a technical note on behalf of the british and irish hypertension societyJournal of Human Hypertension, 33 (5) (2019), pp. 349-351Crossref View in Scopus Google ScholarView at publisher
- Liu, Yu, Mou, 2023 Y. Liu, J. Yu, H. MouPhotoplethysmography-based cuffless blood pressure estimation: An image encoding and fusion approachPhysiological Measurement, 44 (12) (2023), Article 125004Google Scholar
- Maqsood, Xu, Springer, Mohawesh, 2021 S. Maqsood, S. Xu, M. Springer, R. MohaweshA benchmark study of machine learning for analysis of signal feature extraction techniques for blood pressure estimation using photoplethysmography (PPG)IEEE Access, 9 (2021), pp. 138817-138833Crossref View in Scopus Google Scholar
- Marczak, Williams, Loeffler, et al., 2018 L. Marczak, J. Williams, M. Loeffler, et al.Global deaths attributable to high systolic blood pressure, 1990–2016JAMA, 319 (21) (2018), p. 2163View in Scopus Google Scholar
- May, Mejía-Mejía, Nomoni, Budidha, Choi, Kyriacou, 2021 J.M. May, E. Mejía-Mejía, M. Nomoni, K. Budidha, C. Choi, P.A. KyriacouEffects of contact pressure in reflectance photoplethysmography in an in vitro tissue-vessel phantomSensors, 21 (24) (2021), p. 8421Crossref View in Scopus Google Scholar
- Mehta, Kwatra, Jain, McDuff, 2024 S. Mehta, N. Kwatra, M. Jain, D. McDuffExamining the challenges of blood pressure estimation via photoplethysmogramScientific Reports, 14 (1) (2024), Article 18318View in Scopus Google Scholar
- Miao, Wen, Hu, Fortino, Wang, Liu, Tang, Li, 2020 F. Miao, B. Wen, Z. Hu, G. Fortino, X.-P. Wang, Z.-D. Liu, …, Y. LiContinuous blood pressure measurement from one-channel electrocardiogram signal using deep-learning techniquesArtificial Intelligence in Medicine, 108 (2020), Article 101919View PDF View article View in Scopus Google Scholar
- Mitchell, Mulholland, Khuman, 2022 N. Mitchell, T. Mulholland, A.S. KhumanUsing fuzzy logic to diagnose blood pressureArtificial intelligence in healthcare: Recent applications and developments, Springer (2022), pp. 231-247Crossref Google Scholar
- Muntner, Shimbo, Carey, Charleston, Gaillard, Misra, Myers, Ogedegbe, Schwartz, Townsend, et al., 2019 P. Muntner, D. Shimbo, R.M. Carey, J.B. Charleston, T. Gaillard, S. Misra, …, R.R. Townsend, et al.Measurement of blood pressure in humans: A scientific statement from the American Heart AssociationHypertension, 73 (5) (2019), pp. e35-e66Google Scholar
- Niu, Han, Shan, Chen, 2017 X. Niu, H. Han, S. Shan, X. ChenContinuous heart rate measurement from face: A robust rppg approach with distribution learning2017 IEEE International Joint Conference on Biometrics(IJCB), IEEE (2017), pp. 642-650Google Scholar
- Nowara, McDuff, Veeraraghavan, 2020 E.M. Nowara, D. McDuff, A. VeeraraghavanA meta-analysis of the impact of skin tone and gender on non-contact photoplethysmography measurementsProc IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020), pp. 284-285Google Scholar
- O’Brien, Petrie, Littler, De Swiet, Padfield, Altman, Bland, Coats, Atkins, et al., 1993 E. O’Brien, J. Petrie, W. Littler, M. De Swiet, P.L. Padfield, D. Altman, …, N. Atkins, et al.The British Hypertension Society protocol for the evaluation of blood pressure measuring devicesJournal of Hypertension, 11 (Suppl 2) (1993), pp. S43-S62Google Scholar
- Panwar, Gautam, Biswas, Acharyya, 2020 M. Panwar, A. Gautam, D. Biswas, A. AcharyyaPP-Net: A deep learning framework for PPG-based blood pressure and heart rate estimationIEEE Sensors Journal, 20 (17) (2020), pp. 10000-10011Crossref View in Scopus Google Scholar
- Park, Seok, Kim, Shin, 2022 J. Park, H.S. Seok, S.-S. Kim, H. ShinPhotoplethysmogram analysis and applications: An integrative reviewFrontiers in Physiology, 12 (2022), Article 808451View in Scopus Google Scholar
- Pudikov, Brovko, 2020 A. Pudikov, A. BrovkoComparison of LSTM and GRU recurrent neural network architecturesInternational Scientific and Practical Conference in Control Engineering and Decision Making, Springer (2020), pp. 114-124Google Scholar
- Qiu, Ma, Li, Fan, Deng, Huang, 2024 Y. Qiu, X. Ma, X. Li, S. Fan, Z. Deng, X. HuangNon-Contact blood pressure estimation from radar signals by a stacked deformable convolution networkIEEE Journal of Biomedical and Health Informatics (2024)Google Scholar
- Ramachandran, Zoph, & Le Ramachandran, P., Zoph, B., & Le, Q. V. (2017). Searching for activation functions. arXiv preprint arXiv: 1710.05941.Google Scholar
- Riaz, Azad, Arshad, Imran, Hassan, Rehman, 2019 F. Riaz, M.A. Azad, J. Arshad, M. Imran, A. Hassan, S. RehmanPervasive blood pressure monitoring using photoplethysmogram (PPG) sensorFuture Generation Computer Systems, 98 (2019), pp. 120-130View PDF View article View in Scopus Google Scholar
- Rinkevičius, Kontaxis, Gil, Bailón, Lázaro, Laguna, Marozas, 2019 M. Rinkevičius, S. Kontaxis, E. Gil, R. Bailón, J. Lázaro, P. Laguna, V. MarozasPhotoplethysmogram signal morphology-based stress assessment2019 Computing in Cardiology (cinc), IEEE (2019), pp. Page-1Google Scholar
- Rong, Li, 2021 M. Rong, K. LiA multi-type features fusion neural network for blood pressure prediction based on photoplethysmographyBiomedical Signal Processing and Control, 68 (2021), Article 102772View PDF View article View in Scopus Google Scholar
- Schmith, Kelsch, Cunha, Prade, Martins, Keller, de Figueiredo, 2023 J. Schmith, C. Kelsch, B.C. Cunha, L.R. Prade, E.A. Martins, A.L. Keller, R.M. de FigueiredoPhotoplethysmography signal quality assessment using attractor reconstruction analysisBiomedical Signal Processing and Control, 86 (2023), Article 105142View PDF View article View in Scopus Google Scholar
- Stergiou, Alpert, Mieke, Asmar, Atkins, Eckert, Frick, Friedman, Graßl, Ichikawa, et al., 2018 G.S. Stergiou, B. Alpert, S. Mieke, R. Asmar, N. Atkins, S. Eckert, …, T. Ichikawa, et al.A universal standard for the validation of blood pressure measuring devices: Association for the Advancement of Medical Instrumentation/European Society of Hypertension/International Organization for Standardization (AAMI/ESH/ISO) collaboration statementHypertension, 71 (3) (2018), pp. 368-374View at publisher Crossref View in Scopus Google Scholar
- Tanveer, Hasan, 2019 M.S. Tanveer, M.K. HasanCuffless blood pressure estimation from electrocardiogram and photoplethysmogram using waveform based ANN-LSTM networkBiomedical Signal Processing and Control, 51 (2019), pp. 382-392View PDF View article View in Scopus Google Scholar
- Tazarv, Levorato, 2021 A. Tazarv, M. LevoratoA deep learning approach to predict blood pressure from ppg signals2021 43rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE (2021), pp. 5658-5662Crossref View in Scopus Google ScholarView at publisher
- Weber-Boisvert, Gosselin, Sandberg, 2023 G. Weber-Boisvert, B. Gosselin, F. SandbergIntensive care photoplethysmogram datasets and machine-learning for blood pressure estimation: Generalization not guarantiedFrontiers in Physiology, 14 (2023), Article 1126957View in Scopus Google Scholar
- Xiao, Liu, Sun, Li, Zhao, Avolio, 2024 H. Xiao, T. Liu, Y. Sun, Y. Li, S. Zhao, A. AvolioRemote photoplethysmography for heart rate measurement: A reviewBiomedical Signal Processing and Control, 88 (2024), Article 105608View PDF View article View in Scopus Google Scholar