Deep Evidential Regression

摘要
翻译:
确定性神经网络(NNs)正日益部署在安全关键领域,其中校准良好、鲁棒且高效的不确定性度量至关重要。本文提出一种新颖方法,用于训练非贝叶斯神经网络以同时估计连续目标值及其关联证据,从而学习偶然和认知不确定性。我们通过在原高斯似然函数上放置证据先验,并训练神经网络推断证据分布的参数来实现这一目标。此外,我们在训练中施加先验约束,当预测证据与正确输出未对齐时对模型进行正则化。该方法不依赖推理期间的采样,也无需使用分布外(OOD)样本进行训练,从而实现高效且可扩展的不确定性学习。我们在多个基准测试中展示了良好校准的不确定性度量,可扩展至复杂计算机视觉任务,并对抗性样本和OOD测试样本具有鲁棒性。
| 研究背景 | 安全关键领域需要确定性神经网络的可靠不确定性度量 |
|---|---|
| 创新方法 | 1. 使用证据先验替代传统高斯似然、2. 网络直接输出证据分布超参数 |
| 技术突破 | 同时建模: 偶然不确定性(数据噪声) 认知不确定性(模型置信度) |
| 训练机制 | 引入证据对齐的正则化项,惩罚预测证据与真实输出的偏差 |
| 效率优势 | 无需: 推理时采样、 OOD训练数据 |
| 验证效果在以下场景有效 | 标准基准测试、 复杂CV任务、 对抗/OOD样本 |
传统模式

class GaussianNN(nn.Module):def __init__(self, input_dim):super().__init__()self.fc = nn.Linear(input_dim, 2) # 输出mu和log_sigmadef forward(self, x):output = self.fc(x)mu = output[:, 0] # 均值预测log_sigma = output[:, 1] # 对数方差(数值稳定)sigma = torch.exp(log_sigma)return mu, sigmadef train_step(x, y_true):mu, sigma = model(x)loss = 0.5 * (torch.log(sigma**2) + (y_true - mu)**2 / sigma**2)loss.mean().backward()
案例


1.引言
翻译
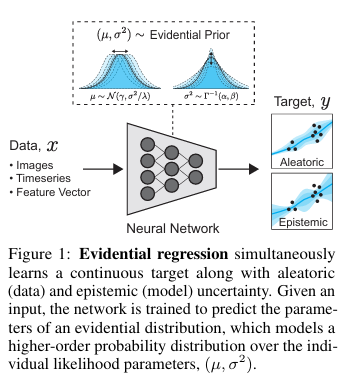
基于回归的神经网络(NNs)正被应用于计算机视觉[15]、机器人与控制[1,6]等安全关键领域,在这些领域中,推断模型不确定性的能力对于最终的大规模应用至关重要。此外,精确且校准良好的不确定性估计有助于解释置信度、捕捉分布外(OOD)测试样本的领域偏移,并识别模型可能失败的情况。
神经网络的不确定性可以分为两个方面进行建模:(1) 数据中的不确定性,称为偶然不确定性(aleatoric uncertainty);(2) 预测中的不确定性,称为认知不确定性(epistemic uncertainty)。虽然偶然不确定性可以通过数据直接学习,但认知不确定性的估计方法也有多种,例如贝叶斯神经网络(Bayesian NNs),它在网络权重上设置概率先验,并通过采样来近似输出方差[25]。然而,贝叶斯神经网络面临一些限制,包括在给定数据的情况下难以直接推断权重的后验分布、推理过程中需要采样带来的计算开销,以及如何选择权重先验的问题。
相比之下,证据深度学习(Evidential Deep Learning)将学习过程形式化为一个证据获取过程[42,32]。每个训练样本都为一个学习到的高阶证据分布提供支持。从该分布中采样可得到低阶似然函数的实例,而数据正是从中生成的。不同于贝叶斯神经网络在网络权重上设置先验,证据方法直接对似然函数设置先验。通过训练神经网络输出高阶证据分布的超参数,可以在无需采样的情况下,学习到有依据的认知和偶然不确定性的表示。
迄今为止,证据深度学习主要面向离散分类问题[42,32,22],并且通常需要定义明确的距离度量以连接最大不确定性的先验[42],或依赖于使用OOD数据进行训练以提升模型不确定性[32,31]。相比之下,连续回归问题缺乏明确定义的距离度量来正则化所推断的证据分布。此外,在大多数应用场景中预先定义合理的OOD数据集并不容易;因此,亟需仅从分布内训练集中获得对OOD数据具有校准良好不确定性的方法。
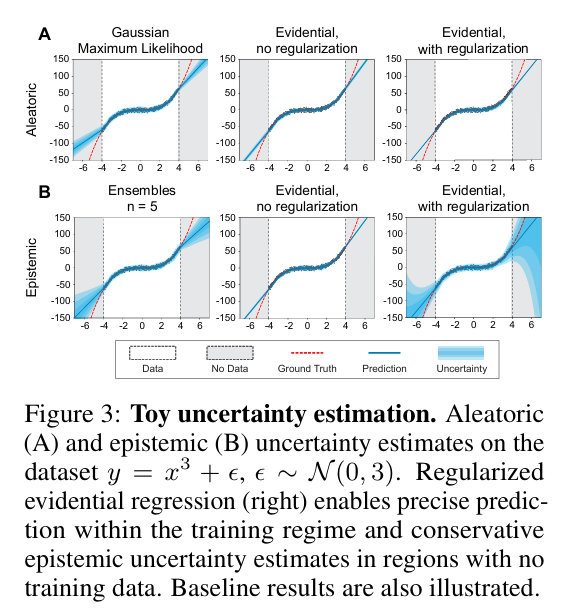
我们提出了一种新的方法,通过学习证据分布来建模回归网络的不确定性(如图1所示)。具体而言,本文做出了以下贡献:
- 提出了一种新颖且可扩展的方法,用于在回归问题中学习认知和偶然不确定性,无需在推理或训练过程中进行采样;
- 提出了适用于连续回归问题的证据正则化方法,用于惩罚误差和OOD示例上的错误证据;
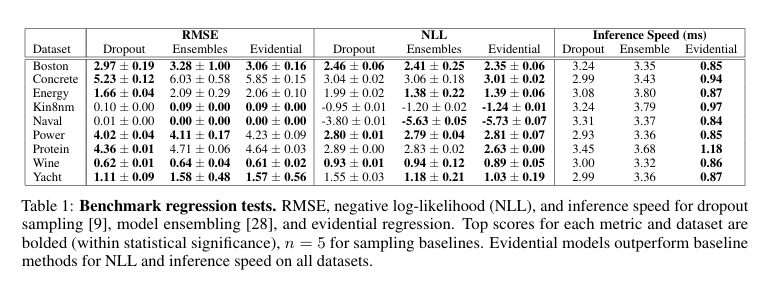
- 在基准和复杂的视觉回归任务上评估了认知不确定性,并与当前最先进的神经网络不确定性估计技术进行了比较;
- 在OOD和对抗性扰动的测试输入数据上评估了鲁棒性和校准性能。
传统神经网络vs贝叶斯神经网络
贝叶斯神经网络就像个"会承认自己会犯错"的学霸
| 传统神经网络(普通学霸) | 贝叶斯神经网络(谦虚学霸) |
|---|---|
| 特点:每次考试都斩钉截铁给答案 | 特点:会给答案范围 |
| “这道题答案绝对是3.14!” | “答案可能是3.1到3.2之间,我有80%把握” |
| 实际可能是3.12,但从不告诉你它有多确定 | 同时告诉你答案和可信度 |
工作原理类比
步骤1:考前划重点(先验)
老师说:“考试重点在1-3章”(这就是先验知识)
普通学霸:只背这3章,其他完全不看
贝叶斯学霸:重点看1-3章,但也会瞄一眼其他章节
步骤2:考试答题(训练)
发现第4章也考了
贝叶斯学霸:
“看来不能全信老师,要调整复习策略”
→ 更新知识分布(计算后验)
步骤3:回答不确定的题(预测)
遇到超纲题时:
普通学霸:硬着头皮蒙一个答案
贝叶斯学霸:
“这题我没把握,答案可能在A到D之间”
→ 通过多次思考(采样)给出概率范围
4. 为什么需要多次"思考"?
贝叶斯学霸会这样做:
第一次想:可能是B
第二次想:也可能是C
…
综合100次思考结果:
60%概率是B
30%概率是C
10%概率是其他
最终答案:最可能是B,但有不确定性(方差)
贝叶斯实际应用例子
医疗诊断场景:
普通AI:
“患者有80%概率患癌”(医生可能过度治疗)
贝叶斯AI:
“患癌概率60%-85%,因为模型没见过类似病例”
→ 提醒医生需要进一步检查
贝叶斯关键优势
知道什么时候不确定:遇到没见过的题型会明说
能利用经验:把老师划重点的知识融入判断
避免过度自信:不会对蒙的答案打包票
本文



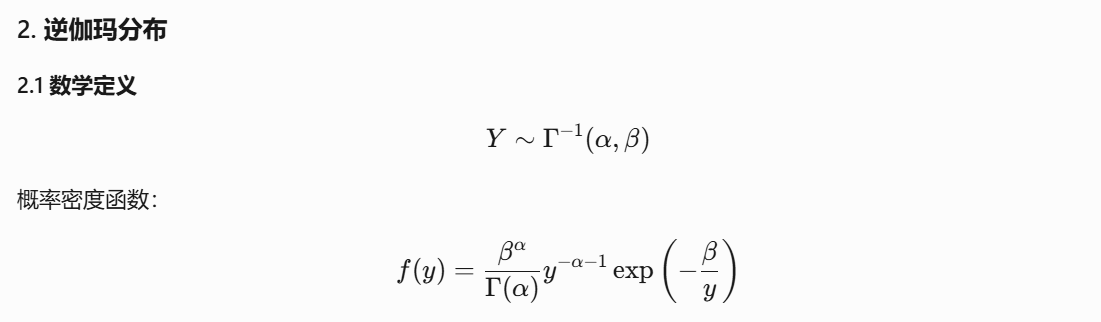

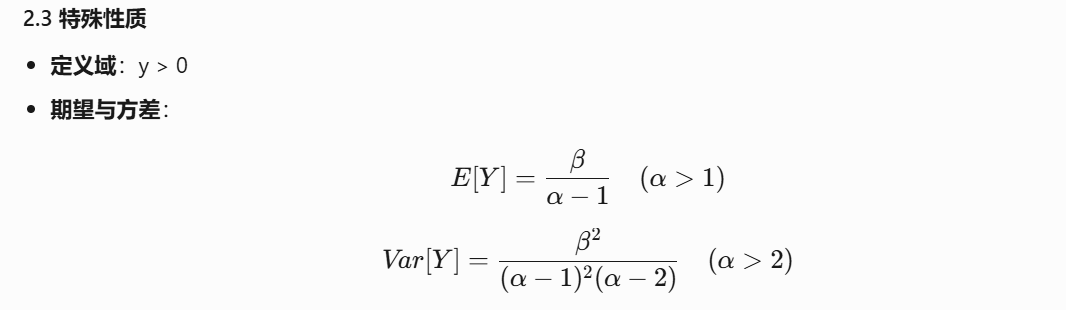
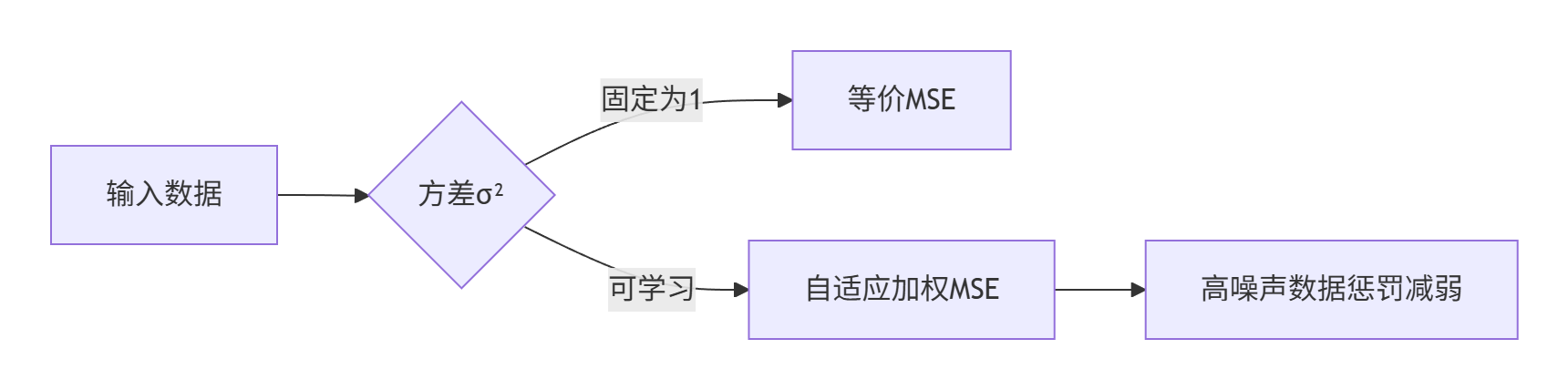
2. 从数据中建模不确定性


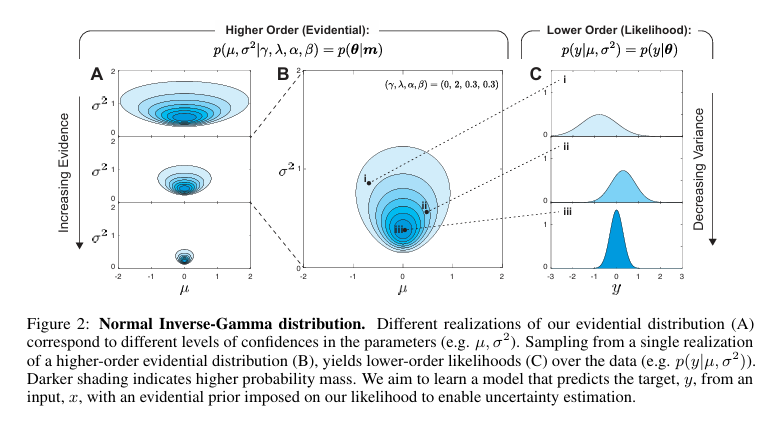



3. 回归中的证据不确定性

NIG分布是高斯分布与逆伽玛分布的联合分布


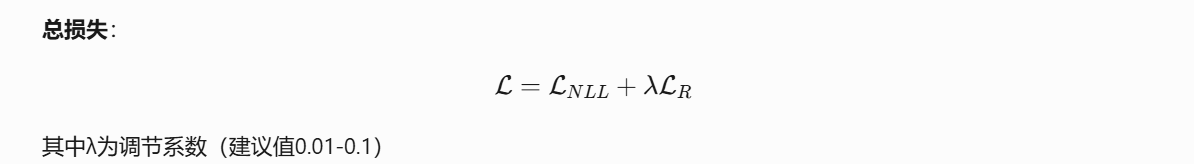
在这里插入代码片
4.实验