记录:训练过程中可训练参数出现nan和inf造成loss为nan
文章目录
- 第1步检查loss出现nan的源头(排除输入数据问题)
- 第2步 降低学习率查看能否解决(排除是学习率设置不当的问题)
- 第3步 查看是不是数据溢出造成的(混精度运算->统一精度)
- 第四步 确定gpu计算方式
- 第五步 回到第3步骤,直接全部启用fp32精度参数训练
- 教训:训练绝对别用fp16,不溢出算我的@@@
第1步检查loss出现nan的源头(排除输入数据问题)
遇到这个问题首先追踪打印loss看看究竟是啥导致了loss出现nan,结果发数据输入没啥问题,就是在训练过程中可训练参数出现inf和nan等:
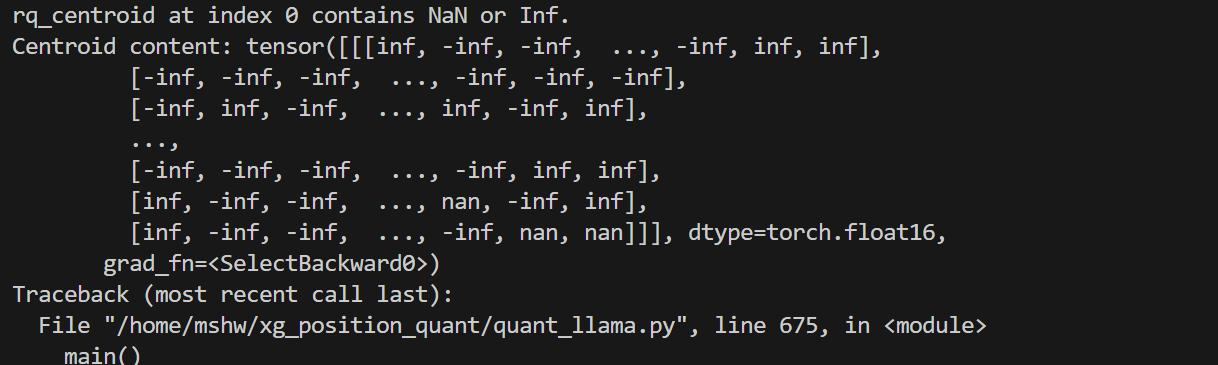
第2步 降低学习率查看能否解决(排除是学习率设置不当的问题)
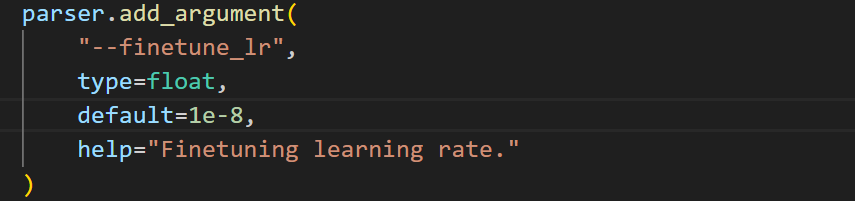
我将学习率从10-5降低十倍,一点点作用都没有
第3步 查看是不是数据溢出造成的(混精度运算->统一精度)
因为我这个情况比较特殊,我的输入数据是32位的,但是我的模型训练参数是16位的,loss计算是32位的,因为上面也发现我的问题是训练参数inf和nan了,所以我想会不会是精度不一样导致参数计算的时候溢出了。由于我的baseline是16位的,我计划将所有的转换成16位来训练。
结果还是一样,在训练的第一次更新完参数就inf和nan了。

第四步 确定gpu计算方式
可能你的gpu是半精度(fp16)训练,启用了tf32训练
加上:
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
with autocast(dtype=torch.float16):
还是报错:
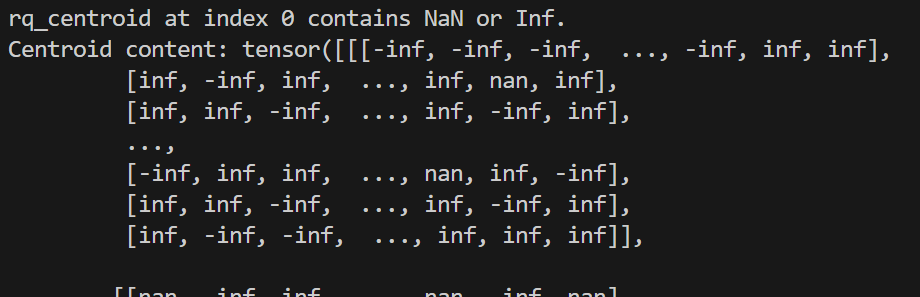
第五步 回到第3步骤,直接全部启用fp32精度参数训练
这里其实有一个问题:我最终需要的是fp16 的精度(因为怕溢出),但是参与训练是32。
解决:我将参数初始化为32,但是前向计算时候转换成16

解决了