Mac 部署Ollama + OpenWebUI完全指南
文章目录
- 💻 环境说明
- 🛠️ Ollama安装配置
- 1. 安装[Ollama](https://github.com/ollama/ollama)
- 2. 启动Ollama
- 3. 模型存储位置
- 4. 配置 Ollama 环境变量
- 5. Ollama 常用命令
- 6. Ollama 终端指令
- 🌐 OpenWebUI部署
- 1. 安装Docker
- 2. 部署[OpenWebUI](https://www.openwebui.com/)(可视化大模型对话界面)
- 🔒 离线部署方案
- 1. 准备工作
- 下载必要的 Docker 镜像
- 下载所需的模型文件
- 2. 离线环境部署
- 加载 Docker 镜像
- 创建 Docker 网络
- 启动 Ollama 容器
- 启动 OpenWebUI 容器
- 3. 验证部署
- 检查容器状态
- 访问 WebUI
- 4. 故障排除
- 5. 注意事项
- ⚡ 性能优化建议
- ❓ 常见问题
- 🎉 结语
想拥有一个完全属于自己的AI助手,还不依赖互联网?本教程带你从零开始搭建本地AI环境!(Apple Silicon架构)
💻 环境说明
| 配置项 | Mac | Windows |
|---|---|---|
| 操作系统 | macOS Sonoma | Windows 10/11 |
| CPU | M4 | 12核或以上 |
| 内存 | 16GB | 32GB或以上 |
| 硬盘空间 | 20GB | 20GB或以上 |
🛠️ Ollama安装配置
官网:https://ollama.com/
模型:https://ollama.com/library
Github:https://github.com/ollama/ollama
Docker:https://hub.docker.com/r/ollama/ollama/tags
1. 安装Ollama
# 使用Homebrew安装
brew install ollama
# 或直接下载安装包
curl https://ollama.ai/download/Ollama-darwin.zip -o Ollama.zip
unzip Ollama.zip
# 输入`ollama`或 `ollama -v`验证安装
ollama
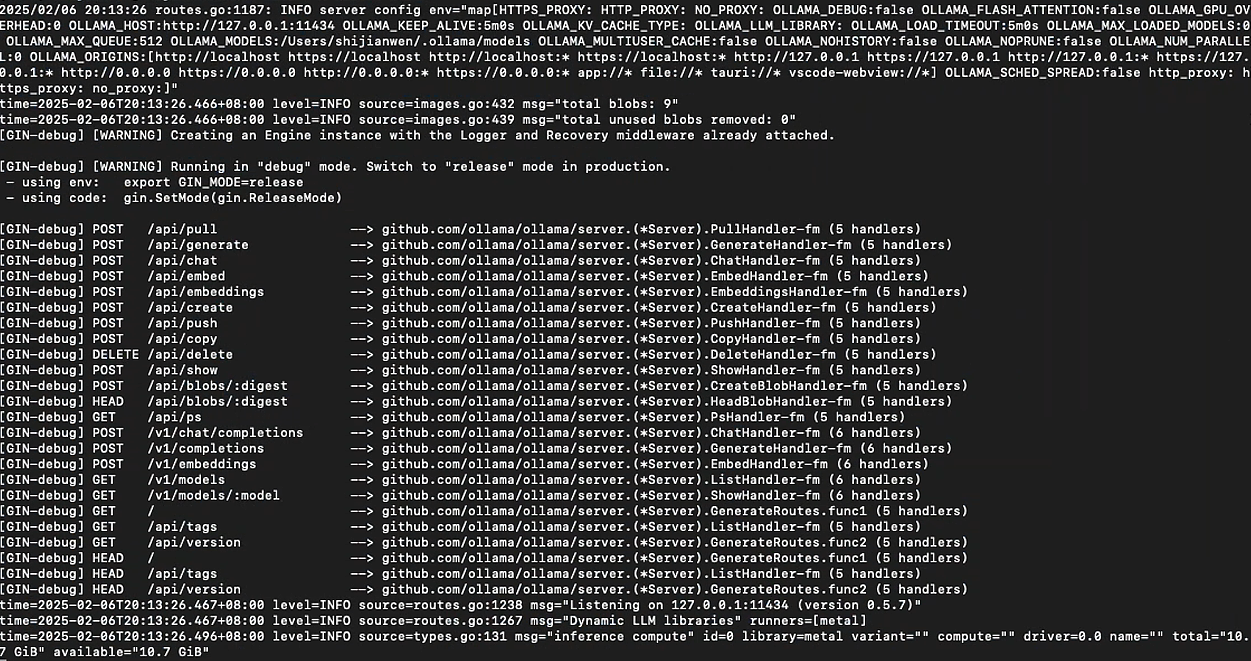
2. 启动Ollama
# 启动Ollama服务
ollama serve
# 或点击浏览器访问:http://localhost:11434
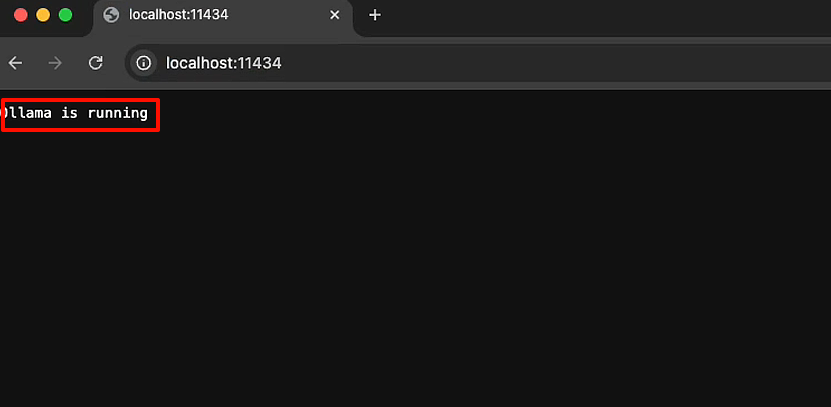
显示Ollama is running代表已经运行起来了!
# 下载Llama3 8B模型
ollama run llama3:8b # 建议先尝试小模型

💡 小贴士:你应该至少有 8 GB 的 RAM 来运行 7B 模型,16 GB 的 RAM 来运行 13B 模型,以及 32 GB 的 RAM 来运行 33B 模型。
3. 模型存储位置
Mac下,Ollama的默认存储位置:
- 模型文件:
~/.ollama/models - 配置文件:
~/Library/Application Support/Ollama
Windows下,Ollama的默认存储位置:
- 程序目录:
C:\Users\<用户名>\AppData\Local\Programs\Ollama - 模型目录:
C:\Users\<用户名>\.ollamamodels - 配置文件:
C:\Users\<用户名>\AppData\Local\Ollama
💡 小贴士:建议通过环境变量OLLAMA_MODELS自定义模型存储路径,避免占用系统盘空间。
4. 配置 Ollama 环境变量
Ollama 提供了多种环境变量以供配置:
- OLLAMA_DEBUG:是否开启调试模式,默认为 false。
- OLLAMA_FLASH_ATTENTION:是否闪烁注意力,默认为 true。
- OLLAMA_HOST:Ollama 服务器的主机地址,默认为空。
- OLLAMA_KEEP_ALIVE:保持连接的时间,默认为 5m。
- OLLAMA_LLM_LIBRARY:LLM 库,默认为空。
- OLLAMA_MAX_LOADED_MODELS:最大加载模型数,默认为 1。
- OLLAMA_MAX_QUEUE:最大队列数,默认为空。
- OLLAMA_MAX_VRAM:最大虚拟内存,默认为空。
- OLLAMA_MODELS:模型目录,默认为空。
- OLLAMA_NOHISTORY:是否保存历史记录,默认为 false。
- OLLAMA_NOPRUNE:是否启用剪枝,默认为 false。
- OLLAMA_NUM_PARALLEL:并行数,默认为 1。
- OLLAMA_ORIGINS:允许的来源,默认为空。
- OLLAMA_RUNNERS_DIR:运行器目录,默认为空。
- OLLAMA_SCHED_SPREAD:调度分布,默认为空。
- OLLAMA_TMPDIR:临时文件目录,默认为空。
- OLLAMA_DEBUG:是否开启调试模式,默认为 false。
- OLLAMA_FLASH_ATTENTION:是否闪烁注意力,默认为 true。
- OLLAMA_HOST:Ollama 服务器的主机地址,默认为空。
- OLLAMA_KEEP_ALIVE:保持连接的时间,默认为 5m。
- OLLAMA_LLM_LIBRARY:LLM 库,默认为空。
- OLLAMA_MAX_LOADED_MODELS:最大加载模型数,默认为 1。
- OLLAMA_MAX_QUEUE:最大队列数,默认为空。
- OLLAMA_MAX_VRAM:最大虚拟内存,默认为空。
- OLLAMA_MODELS:模型目录,默认为空。
- OLLAMA_NOHISTORY:是否保存历史记录,默认为 false。
- OLLAMA_NOPRUNE:是否启用剪枝,默认为 false。
- OLLAMA_NUM_PARALLEL:并行数,默认为 1。
- OLLAMA_ORIGINS:允许的来源,默认为空。
- OLLAMA_RUNNERS_DIR:运行器目录,默认为空。
- OLLAMA_SCHED_SPREAD:调度分布,默认为空。
- OLLAMA_TMPDIR:临时文件目录,默认为空。
5. Ollama 常用命令
- 启动Ollama服务: ollama serve
- 从模型文件创建模型: ollama create
- 显示模型信息: ollama show
- 运行模型: ollama run 模型名称
- 从注册表中拉去模型: ollama pull 模型名称
- 将模型推送到注册表: ollama push
- 列出模型: ollama list
- 复制模型: ollama cp
- 删除模型: ollama rm 模型名称
- 获取有关Ollama任何命令的帮助信息: ollama help
6. Ollama 终端指令
- 查看支持的指令:使用命令 /?
- 退出对话模型:使用命令 /bye
- 显示模型信息:使用命令 /show
- 设置对话参数:使用命令 /set 参数名 参数值,例如设置温度(temperature)或top_k值
- 清理上下文:使用命令 /clear
- 动态切换模型:使用命令 /load 模型名称
- 存储模型:使用命令 /save 模型名称
- 查看快捷键:使用命令 /?shortcuts
🌐 OpenWebUI部署
Github:https://github.com/open-webui/open-webui
文档:https://docs.openwebui.com/
1. 安装Docker
- 访问 Docker官网 下载Mac版本(Apple Silicon)
- 安装并启动Docker Desktop
- 配置国内镜像源加速下载(我这里
科学上网不需要)

💡 小贴士:Windows 安装 Docker 需要开启 Hyper-V(Windows专业版必需)
2. 部署OpenWebUI(可视化大模型对话界面)
# 拉取镜像 (直接run默认会拉取 latest 标签的镜像)
docker pull ghcr.io/open-webui/open-webui:main
#(官方文档)以上是从 GitHub Container Registry (GHCR) 上拉取镜像,而不是从 Docker Hub。
# 也可以docker hub 拉取 open-webui镜像
docker pull dyrnq/open-webui:main
# 启动容器
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
访问 http://localhost:3000 即可使用Web界面。
 创建账号,这个是本地账号,随便添加账号信息即可
创建账号,这个是本地账号,随便添加账号信息即可

选择ollama中的模型,聊天测试

也可以在这里直接拉取模型

与下载的新模型进行对话

💡 小贴士:
- 注册时邮箱可以随便填写,设置密码后注意保存!
- ollama后台一定要运行着模型,如:ollama run phi-4
🔒 离线部署方案
1. 准备工作
下载必要的 Docker 镜像
在有网络的环境中,需要下载以下镜像:
# 下载 Ollama 镜像
docker pull ollama/ollama:latest
# 下载 OpenWebUI 镜像
docker pull ghcr.io/open-webui/open-webui:main
# 保存镜像到文件
docker save ollama/ollama:latest -o ollama.tar
docker save ghcr.io/open-webui/open-webui:main -o openwebui.tar
下载所需的模型文件
在有网络的环境中下载模型文件:
# 使用 Ollama 下载模型
ollama pull llama3
# 模型文件位于 ~/.ollama/models 目录
2. 离线环境部署
加载 Docker 镜像
# 加载保存的镜像文件
docker load -i ollama.tar
docker load -i openwebui.tar
创建 Docker 网络
docker network create ollama-network
启动 Ollama 容器
docker run -d \
--name ollama \
--network ollama-network \
-v ~/.ollama:/root/.ollama \
-p 11434:11434 \
ollama/ollama
启动 OpenWebUI 容器
docker run -d \
--name open-webui \
--network ollama-network \
-p 3000:8080 \
-e OLLAMA_API_BASE_URL=http://ollama:11434/api \
ghcr.io/open-webui/open-webui:main
3. 验证部署
检查容器状态
docker ps
docker logs ollama
docker logs open-webui
访问 WebUI
在浏览器中访问 http://localhost:3000
4. 故障排除
- 如果容器无法启动,检查日志:
docker logs ollama
docker logs open-webui
- 检查网络连接:
# 确保容器间可以通信
docker network inspect ollama-network
- 检查模型文件:
# 进入 Ollama 容器检查模型文件
docker exec -it ollama ls /root/.ollama/models
5. 注意事项
- 确保模型文件已正确复制到 Ollama 容器的对应目录
- 检查磁盘空间是否充足,容器间的网络通信是关键,需要确保正确配置
- 确保端口 3000 和 11434 未被占用
- 容器的启动顺序很重要,必须先启动 Ollama 再启动 OpenWebUI
- 目前也有捆绑安装的方式,将 Open WebUI 和 Ollama 打包在一个 Docker 容器中,通过一条命令就能同时安装和启动两者。
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
⚡ 性能优化建议
-
内存管理
- 关闭不必要的后台应用
- 使用Activity Monitor监控内存使用
-
模型选择
- 建议从小模型开始测试
- 推荐模型大小顺序:
- qwen2:0.5b (最轻量)
- llama2:7b (平衡型)
- codellama:7b (代码专用)
-
温度控制
- 保持Mac Mini通风良好
- 可使用监控工具观察CPU温度
❓ 常见问题
-
Q: M4芯片能跑多大的模型?
A: 16GB内存的M4可以流畅运行8B参数的模型,更大的模型可能会影响性能。 -
Q: Llama中文支持不好怎么办?
A: 可以使用Llama-Chinese等经过中文优化的模型。 -
Q: OpenWebUI打不开怎么办?
A: 检查Docker状态:docker ps # 查看容器状态 docker logs open-webui # 查看日志
🎉 结语
通过本教程的配置,你已经拥有了一个完全本地化的AI助手!有任何问题欢迎在评论区讨论,让我们一起探索AI的无限可能!
如果觉得这篇文章对你有帮助,别忘了点赞转发哦~ 👍
你用Mac Mini跑过哪些AI模型?欢迎分享你的使用体验!💭