【01】大模型原理与API使用
本篇目标
·AIGC发展:从GPT1到GPT4
·AIGC的表现与优势
·AIGC的通用能力应用
·大模型API使用
CASE-情感分析-Qwen
CASE-天气Function-Qwen
CASE-表格提取-Qwen
CASE-运维事件处置-Qwen
AI 的分类
- 分析式AI : 也称为判别式AI,其核心任务是对已有数据进行分类、预测或决策。
优势在于其高精度和高效性,但其局限性在于仅能处理已有数据的模式,无法创造新内容. - 生成式AI:专注于创造新内容,例如文本、图像、音等。突破在于其创迪性和灵活性,但也面临败据隐私、版权保护等挑战
chatgpt 的发展历史
| 版本 | 时间 | 特点 |
|---|---|---|
| GPT | 2018 | 最初版本,提出基于 Transformer 的语言建模思路 |
| GPT-2 | 2019 | 增大模型规模(15亿参数),展示出惊人的文本生成能力(但初期未公开) |
| GPT-3 | 2020 | 参数规模达 1750 亿,成为主流应用和研究的标志性模型 |
| ChatGPT(基于 GPT-3.5) | 2022 | 引入对话调优,使其更适应交互场景 |
| GPT-4 / GPT-4.5 / GPT-4-turbo | 2023–2024 | 多模态能力(图文)、更强逻辑与对话性、上下文扩展到数十万 token |
| GPT-5(传闻中) | 2025 | 可能进一步强化多模态、智能体、自主学习能力 |
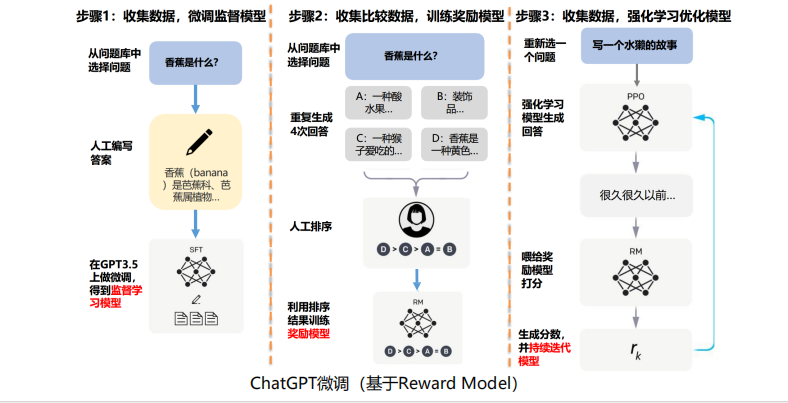
chatgpt 是如何训练出来的? (基于奖励模型)
包含3个步骤:
CASE1 : 车险反欺诈预测
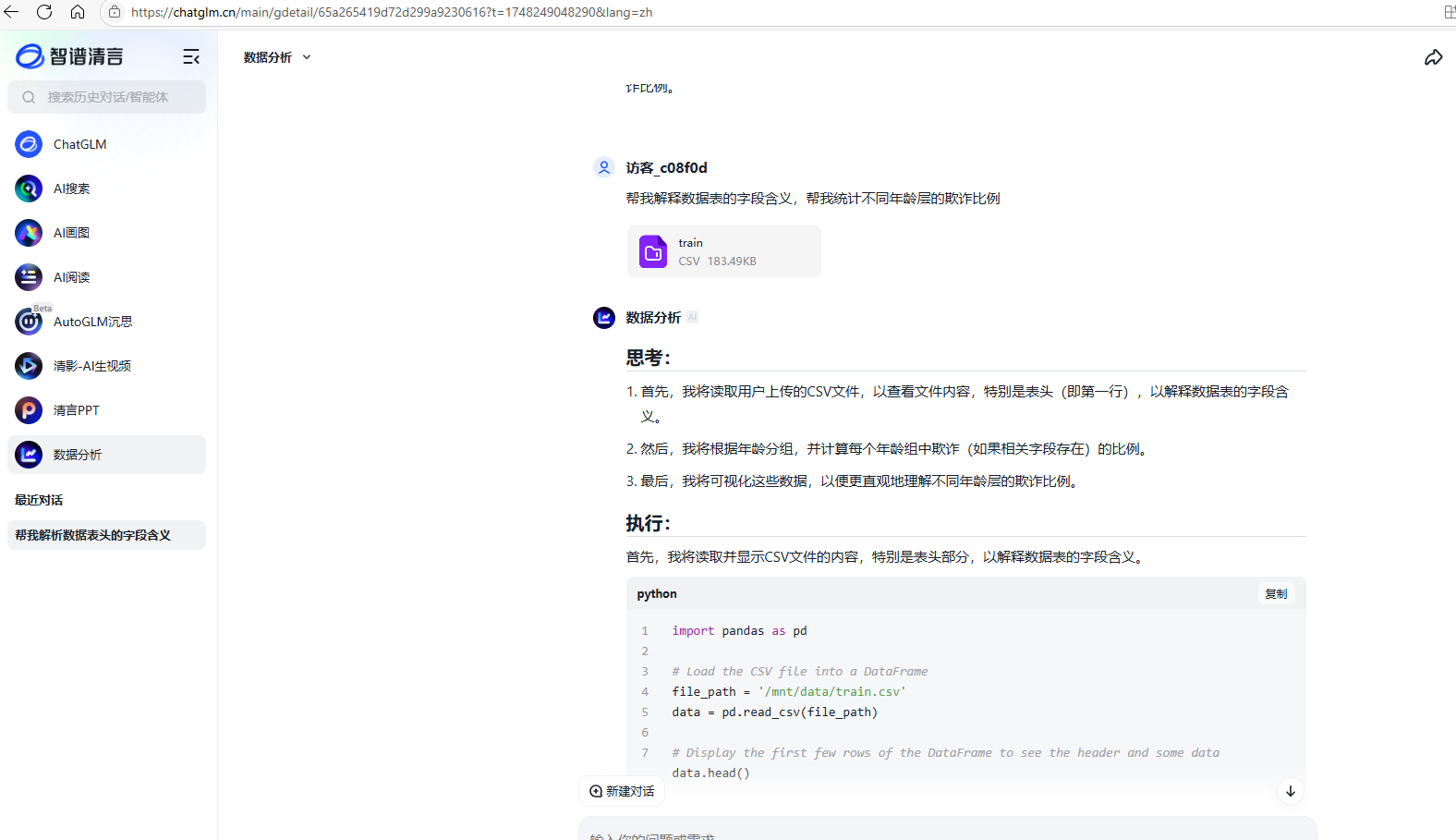
- 使用智谱清言 ChatGLM
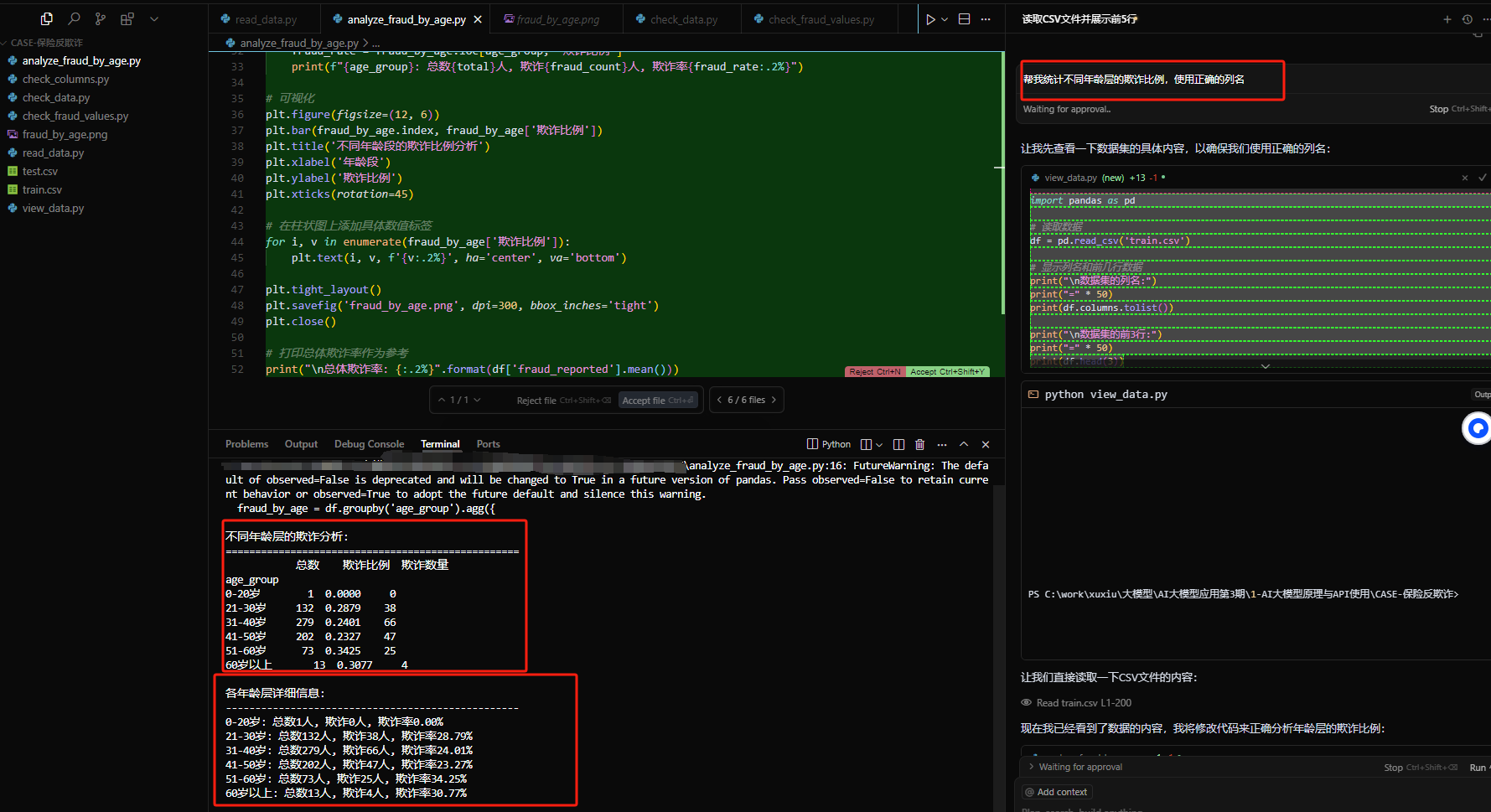
- 使用cursor (网上自行搜cursor 安装教程)
优点:生成好后,能运行
如:帮我编写python 读取 train.csv,并展示前5行

帮我统计不同年龄层的欺诈比例,使用正确的列名
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# 读取数据
df = pd.read_csv('train.csv')# 创建年龄段
df['age_group'] = pd.cut(df['age'], bins=[0, 20, 30, 40, 50, 60, 100],labels=['0-20岁', '21-30岁', '31-40岁', '41-50岁', '51-60岁', '60岁以上'])# 计算每个年龄段的欺诈比例
fraud_by_age = df.groupby('age_group').agg({'fraud_reported': ['count', 'mean']
}).round(4)fraud_by_age.columns = ['总数', '欺诈比例']
fraud_by_age['欺诈数量'] = (fraud_by_age['总数'] * fraud_by_age['欺诈比例']).astype(int)# 打印结果
print("\n不同年龄层的欺诈分析:")
print("=" * 50)
print(fraud_by_age)
print("\n各年龄层详细信息:")
print("-" * 50)
for age_group in fraud_by_age.index:total = fraud_by_age.loc[age_group, '总数']fraud_count = fraud_by_age.loc[age_group, '欺诈数量']fraud_rate = fraud_by_age.loc[age_group, '欺诈比例']print(f"{age_group}: 总数{total}人, 欺诈{fraud_count}人, 欺诈率{fraud_rate:.2%}")# 可视化
plt.figure(figsize=(12, 6))
plt.bar(fraud_by_age.index, fraud_by_age['欺诈比例'])
plt.title('不同年龄段的欺诈比例分析')
plt.xlabel('年龄段')
plt.ylabel('欺诈比例')
plt.xticks(rotation=45)# 在柱状图上添加具体数值标签
for i, v in enumerate(fraud_by_age['欺诈比例']):plt.text(i, v, f'{v:.2%}', ha='center', va='bottom')plt.tight_layout()
plt.savefig('fraud_by_age.png', dpi=300, bbox_inches='tight')
plt.close()# 打印总体欺诈率作为参考
print("\n总体欺诈率: {:.2%}".format(df['fraud_reported'].mean()))
CASE - API 使用
获取key:通过 https://bailian.console.aliyun.com/ 完成注册,得到 dashscope的API Key,方便后续使用大模型,比如使用 Qwen-Turbo
https://bailian.console.aliyun.com/?tab=model#/api-key
安装dashscope库时,需要关闭梯子,否则报错
情感分析
import json
import os
import dashscope
from dashscope.api_entities.dashscope_response import Role
dashscope.api_key = "sk-your key"# 封装模型响应函数
def get_response(messages):response = dashscope.Generation.call(model='qwen-turbo',messages=messages,result_format='message' # 将输出设置为message形式)return responsereview = '这款音效特别好 给你意想不到的音质。'
messages=[{"role": "system", "content": "你是一名舆情分析师,帮我判断产品口碑的正负向,回复请用一个词语:正向 或者 负向"},{"role": "user", "content": review}]response = get_response(messages)
response.output.choices[0].message.content