python每日剂量(2)探讨Python中不同解析库的提取速度对比
今天闲着没事,突发异想,相对比不同解析库的解析速度,本文中对比五种解析库
一.概述
1.scrapy自带Css选择
2.scrapy自带xpath
3.lxml自带xpath from lxml import etree
4.bs4自带美味的汤 from bs4 import BeautifulSoup
5.re 正则表达式
以这个文本为例,在循环解析链接标题时间情况,再循环499次并打印输出,约循环7500次,为了避免误差,考虑到CPU资源波动,那么Python程序能够得到的CPU时间就会或多或少,从而导致运行时间变长或变短,所以每种方式运行三次。
当CPU爆满时
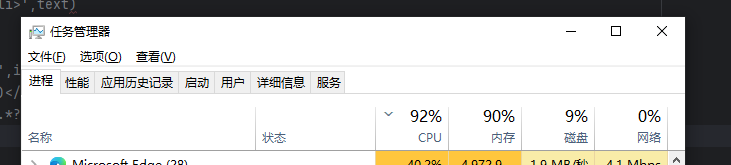
运行时间非常慢
![]()
当CPU充足时,同样是程序就会非常快

本程序都在CPU充足情况下运行
text ='''<div class="news_list zy_listbox"><!-- 展示15条数据后出现分页 --><ul><li><b>·</b><a href="/index/Article/detail.html?id=2565">青海省生态环境监测中心自行采购2024-010号</a><span>2024-07-18</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2564">单一来源采购公示</a><span>2024-07-15</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2563">青海省生态环境监测中心自行采购2024-009号(第二次)</a><span>2024-07-10</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2562">青海省生态环境监测中心自行采购2024-009号</a><span>2024-07-05</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2561">等保测评询价函</a><span>2024-05-28</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2560">单一来源采购公示</a><span>2024-05-24</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2559">青海省生态环境监测中心自行采购2024-007号(第二次)</a><span>2024-05-20</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2558">单一来源采购公示</a><span>2024-05-16</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2557">青海省生态环境监测中心自行采购2024-008号</a><span>2024-05-06</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2556">询价函</a><span>2024-04-30</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2555">青海省生态环境监测中心自行采购2024-007号</a><span>2024-04-22</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2554">青海省生态环境监测中心自行采购2023-004号(第二次)</a><span>2024-04-12</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2553">青海省生态环境监测中心自行采购2024-006号</a><span>2024-03-29</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2552">青海省生态环境监测中心自行采购2024-005号</a><span>2024-03-20</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2551">青海省生态环境监测中心自行采购2024-004号</a><span>2024-03-16</span></li></ul></div>'''二.探讨CSS选择器解析速度
t= time.time()
selector = Selector(text=text)
for i in range(1,500):for l in selector.css('div.news_list>ul>li'):print(l.css('a::text').get())print(l.css('span::text').get())print(l.css('a::attr(href)').get())
css_parse = time.time()-t
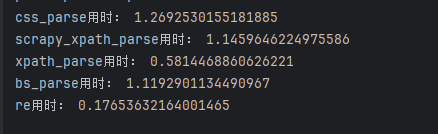
print('css_parse用时:',css_parse)第一次

第二次
![]()
第三次

三.探讨scrapy里的xpath解析速度
t= time.time()
selector = Selector(text=text)
for i in range(1,500):for l in selector.xpath('//div[@class = "news_list zy_listbox"]/ul/li'):print(l.xpath('.//a/text()').get())print(l.xpath('.//span/text()').get())print(l.xpath('.//a/@href').get())
scrapy_xpath_parse = time.time()-t
print('scrapy_xpath_parse用时:',scrapy_xpath_parse)第一次
![]()
第二次
![]()
第三次

四.探讨lxml里的xpath解析速度
t= time.time()
selector = etree.HTML(text)
for i in range(1,500):for l in selector.xpath('//div[@class = "news_list zy_listbox"]/ul/li'):print(l.xpath('.//a/text()')[0])print(l.xpath('.//span/text()')[0])print(l.xpath('.//a/@href')[0])
xpath_parse = time.time()-t
print('xpath_parse用时:',xpath_parse)第一次
![]()
第二次
![]()
第三次

五.探讨bs4自带BeautifulSoup解析速度
t = time.time()
soup = BeautifulSoup(text, 'html.parser')
news_list = soup.select('div.news_list.zy_listbox ul li')
for i in range(1,500):for l in news_list:print( l.select_one('a').get_text(strip=True))print(l.select_one('span').get_text(strip=True))print(l.select_one('a')['href'])
bs_parse = time.time() - t
print('bs_parse用时:',bs_parse )第一次
![]()
第二次
![]()
第三次

六.探讨re正则解析速度
t = time.time()
li = re.findall(' <li><b>·</b>.*?</li>',text)
for l in range(1,500):for i in li:print(re.search('>(.*?)</a>',i).group(1))print(re.search('<span>(.*?)</span>',i).group(1))print(re.search('<a href="(.*?)">',i).group(1))
re_time = time.time()-t
print('re:',re_time )第一次
![]()
第二次
![]()
第三次
![]()
七.总结
经上述程序实验证明,速度排序:
re正则 > lxml xpath > bs4 BeautifulSoup > Scrapy css ≈ Scrapy xpath
在本实验中,并不严谨,除CPU波动外,只选取了一种特定的HTML网页进行速度对比,没有考虑到不同类型和结构的网页对解析速度的影响。例如,网页中若包含大量嵌套的表单、复杂的JavaScript生成的动态内容等,甚至有个html藏在动态接口的json里面,不同解析工具的表现可能会大不相同,这使得实验结果存在一定的局限性。实际应用中还需要根据具体的HTML网页结构、解析需求以及性能指标等多方面因素综合考量,选择最合适的解析工具。
总程序
from lxml import etree
from scrapy import Selector
from bs4 import BeautifulSoup
import re
import requests
import time
text ='''<div class="news_list zy_listbox"><!-- 展示15条数据后出现分页 --><ul><li><b>·</b><a href="/index/Article/detail.html?id=2565">青海省生态环境监测中心自行采购2024-010号</a><span>2024-07-18</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2564">单一来源采购公示</a><span>2024-07-15</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2563">青海省生态环境监测中心自行采购2024-009号(第二次)</a><span>2024-07-10</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2562">青海省生态环境监测中心自行采购2024-009号</a><span>2024-07-05</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2561">等保测评询价函</a><span>2024-05-28</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2560">单一来源采购公示</a><span>2024-05-24</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2559">青海省生态环境监测中心自行采购2024-007号(第二次)</a><span>2024-05-20</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2558">单一来源采购公示</a><span>2024-05-16</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2557">青海省生态环境监测中心自行采购2024-008号</a><span>2024-05-06</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2556">询价函</a><span>2024-04-30</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2555">青海省生态环境监测中心自行采购2024-007号</a><span>2024-04-22</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2554">青海省生态环境监测中心自行采购2023-004号(第二次)</a><span>2024-04-12</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2553">青海省生态环境监测中心自行采购2024-006号</a><span>2024-03-29</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2552">青海省生态环境监测中心自行采购2024-005号</a><span>2024-03-20</span></li><li><b>·</b><a href="/index/Article/detail.html?id=2551">青海省生态环境监测中心自行采购2024-004号</a><span>2024-03-16</span></li></ul></div>'''
t= time.time()
selector = Selector(text=text)
for i in range(1,500):for l in selector.css('div.news_list>ul>li'):print(l.css('a::text').get())print(l.css('span::text').get())print(l.css('a::attr(href)').get())
css_parse = time.time()-t
t= time.time()
selector = Selector(text=text)
for i in range(1,500):for l in selector.xpath('//div[@class = "news_list zy_listbox"]/ul/li'):print(l.xpath('.//a/text()').get())print(l.xpath('.//span/text()').get())print(l.xpath('.//a/@href').get())
scrapy_xpath_parse = time.time()-t
t= time.time()
selector = etree.HTML(text)
for i in range(1,500):for l in selector.xpath('//div[@class = "news_list zy_listbox"]/ul/li'):print(l.xpath('.//a/text()')[0])print(l.xpath('.//span/text()')[0])print(l.xpath('.//a/@href')[0])
xpath_parse = time.time()-t
t = time.time()
soup = BeautifulSoup(text, 'html.parser')
news_list = soup.select('div.news_list.zy_listbox ul li')
for i in range(1,500):for l in news_list:print( l.select_one('a').get_text(strip=True))print(l.select_one('span').get_text(strip=True))print(l.select_one('a')['href'])
bs_parse = time.time() - t
t = time.time()
li = re.findall(' <li><b>·</b>.*?</li>',text)
for l in range(1,500):for i in li:print(re.search('>(.*?)</a>',i).group(1))print(re.search('<span>(.*?)</span>',i).group(1))print(re.search('<a href="(.*?)">',i).group(1))
re_time = time.time()-t
print('css_parse用时:',css_parse)
print('scrapy_xpath_parse用时:',scrapy_xpath_parse)
print('xpath_parse用时:',xpath_parse)
print('bs_parse用时:',bs_parse )
print('re用时:',re_time )
各时间对比