强化学习(十一)探索与利用
本篇系统的介绍在强化学习领域如何有效的进行探索,给出了几类探索算法,通过引入后悔值,借助多臂赌博机这一与状态无关的示例从理论上论述了相关算法的有效性,随后很简单地介绍了将其扩展至与状态相关学习问题和这些算法如何具体应用于解决MDP问题。
1. 简介 Introduction
探索和利用的困局:
- 利用是做出当前信息下的最佳决定,
- 探索则是尝试不同的行为继而收集更多的信息。最好的长期战略通常包含一些牺牲短期利益举措。通过搜集更多或者说足够多的信息使得个体能够达到宏观上的最佳策略。
因此探索和利用是一对矛盾。
几个基本的探索方法:
朴素探索(Naive Exploration): 在贪婪搜索的基础上增加一个Ɛ以实现朴素探索;
几个基本的探索方法:
朴素探索(Naive Exploration): 在贪婪搜索的基础上增加一个Ɛ以实现朴素探索;
乐观初始估计(Optimistic Initialization): 优先选择当前被认为是最高价值的行为,除非新信息的获取推翻了该行为具有最高价值这一认知;
概率匹配(Probability Matching): 根据当前估计的概率分布采样行为;
信息状态搜索(Information State Search): 将已探索的信息作为状态的一部分联合个体的状态组成新的状态,以新状态为基础进行前向探索。
根据搜索过程中使用的数据结构,可以将搜索分为:
- 依据状态行为空间的探索(State-Action Exploration)
- 参数化搜索(Parameter Exploration)
前者指针对每一个当前的状态,以一定的算法尝试之前该状态下没有尝试过的行为。
后者则直接针对策略的函数近似,此时策略用各种形式的参数表达,探索即表现为尝试不同的参数设置。
- 后者的优点是:得到基于某一策略的一段持续性的行为;
- 其缺点是对个体曾经到过的状态空间毫无记忆,也就是个体也许会进入一个之前曾经进入过的状态而并不知道其曾到过该状态,不能利用已经到过这个状态这个信息。
2. 与状态无关的多臂赌博机 Multi-Armed Bandits
多臂赌博机(下图)是由多个独立的单臂赌博机构成,赌博机相当于环境,个体拉下某一单臂赌博机的拉杆表示选择该赌博机,随后该赌博机会给出一个即时奖励 R R R。各个单臂赌博机之间是独立无关的,这等于说各单臂赌博机所给出的即时奖励值无关且各自的奖励分布也不同。此外,同一时刻只能拉下其中一个赌博机的拉杆,在某一个赌博机上先前拉杆得到的奖励与随后拉杆所能得到的奖励无关。另外,多臂赌博机每给出一个即时奖励,该Episode随即结束,因此一个Episode就是由一个动作和一个即时奖励构成,与状态无关。
由上文的描述可以得出,多臂赌博机可以看成是由行为空间和奖励组成的元组 ⟨ A , R ⟩ \langle A,R \rangle ⟨A,R⟩ ,假如一个多臂赌博机由 m 个单臂赌博机组成,那么动作空间将由 m 个具体动作组成,每一个动作对应拉下某一个单臂赌博机的拉杆。在 t t t 时刻,个体从动作空间 A A A 中选择一个动作 a t a_t at,随后环境产生一个即时奖励 r t r_t rt。采取动作 a a a 得到的即时奖励 r r r 服从一个个体未知的概率分布: R a ( r ) = P [ r ∣ a ] R^a(r)=P[r|a] Ra(r)=P[r∣a] 中采样得到。个体可以持续的与多臂赌博机进行交互。
问题:利用得到的即时奖励值,个体使用什么样的搜索策略可以最大化其累积即时奖励: ∑ τ = 1 t r τ \sum_{\tau=1}^t r_{\tau} ∑τ=1trτ
为了方便描述问题,我们先给出几个定义:
这个问题不涉及状态本身,我们仿照状态价值(或状态动作价值)的定义来定义一个仅针对某一动作的价值 Q ( a ) Q(a) Q(a):
Q ( s ) = E [ r ∣ a ] Q(s)=\mathbb{E}[r|a] Q(s)=E[r∣a]
它的意思是一个动作的价值等于该动作能得到的即时奖励期望,即该动作得到的所有即时奖励的平均值。
假如我们能够事先知道哪一个单臂赌博机能够给出最大即时奖励,那我们可以每次只选择对应的那个拉杆。如果用 V ∗ V^* V∗ 表示这个最优价值, a ∗ a^* a∗ 表示能够带来最优价值的动作,那么:
V ∗ = Q ( a ∗ ) = max a ∈ A Q ( a ) V^* = Q(a^*) = \max_{a \in \mathcal{A}} Q(a) V∗=Q(a∗)=a∈AmaxQ(a)
事实上我们不可能事先知道拉下哪个拉杆能带来最高奖励,因此每一次拉杆获得的即时奖励可能都与最优价值 V ∗ V* V∗ 存在一定的差距,我们定义这个差距为后悔值(regret):
l t = E [ V ∗ − Q ( a t ) ] l_t = \mathbb{E} \left[ V^* - Q(a_t) \right] lt=E[V∗−Q(at)]
每做出一个动作,都会产生一个后悔值 l t l_t lt ,因此随着持续的拉杆动作,将所有的后悔值加起来,形成总后悔值:
L t = E [ ∑ τ = 1 t V ∗ − Q ( a τ ) ] L_t = \mathbb{E} \left[ \sum_{\tau=1}^{t} V^* - Q(a_\tau) \right] Lt=E[τ=1∑tV∗−Q(aτ)]
这样,最大化累计奖励的问题就可以转化为最小化总后悔值了。
注:之所以这样转换,是为了描述问题的方便,在随后的讲解中可以看到,较好的算法可以控制后悔值的增加速度。而用最大化累计奖励描述问题不够方便直观。
现在我们从另一个角度重写总后悔值。定义计数 N t ( a ) N_t(a) Nt(a) 为到 t t t 时刻时已执行动作 a a a 的次数。定义差距 Δ a \Delta a Δa 为最优价值 a ∗ a^* a∗ 与动作 a a a 的价值之间的差。那么总后悔值可以推导成:
L t = E [ ∑ τ = 1 t V ∗ − Q ( a τ ) ] = ∑ a ∈ A E [ N t ( a ) ] ( V ∗ − Q ( a ) ) = ∑ a ∈ A E [ N t ( a ) ] Δ a \begin{align*} L_t &= \mathbb{E} \left[ \sum_{\tau=1}^{t} V^* - Q(a_\tau) \right] \\ &= \sum_{a \in \mathcal{A}} \mathbb{E} [N_t(a)] \left( V^* - Q(a) \right) \\ &= \sum_{a \in \mathcal{A}} \mathbb{E} [N_t(a)] \Delta_a \end{align*} Lt=E[τ=1∑tV∗−Q(aτ)]=a∈A∑E[Nt(a)](V∗−Q(a))=a∈A∑E[Nt(a)]Δa
这相当于把各动作的差距与该动作发生的次数乘起来,随后把动作空间的所有动作的这个乘积再相加得到,只不过这里是期望。
把总后悔值用计数和差距描述可以使我们理解到一个好的算法应该尽量减少那些差距较大的动作的次数。不过我们并不知道这个差距具体是多少,因为根据定义虽然最优价值 V ∗ V^* V∗ 和每个动作的差距 Δ a \Delta a Δa 都是静态的,但我们并不清楚这两者的具体数值,我们所能使用的信息就是每次动作带来的即时奖励 r r r 。那么我们如何利用每次动作的即时奖励呢?
我们使用每次的即时奖励来计算得到 t t t 时刻止某一动作的平均价值:
Q ^ t ( a ) = 1 N t ( a ) ∑ t = 1 T r t 1 ( a t = a ) \hat{Q}_t(a) = \frac{1}{N_t(a)} \sum_{t=1}^{T} r_t \mathbf{1}(a_t = a) Q^t(a)=Nt(a)1t=1∑Trt1(at=a)
这个方法也叫蒙特卡罗评估,以此来近似该动作的实际价值 Q ( a ) Q(a) Q(a)
我们先直观了解下不同形式的随机策略其总后悔值随着时间的变化曲线:
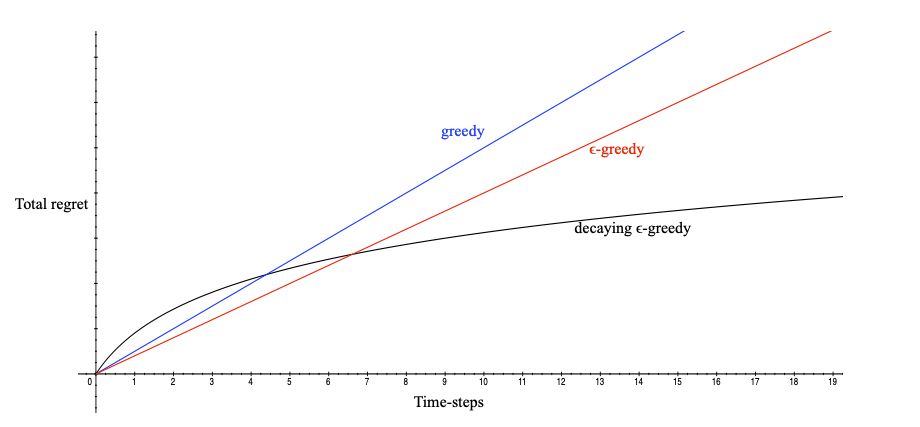
对于 ϵ − g r e e d y \epsilon-greedy ϵ−greedy 探索方法,总后悔值会呈线性增长,这是一个好的算法所不能接受的。这是因为每一个时间步,该探索方法有一定的几率选择最优动作,但同样也有一个固定小的几率采取完全随机的动作,如采取随机动作,那将一直会带来一定后悔值,如果持续以虽小但却固定的几率采取随机动作,那么总的后悔值会一直递增,导致呈现与时间之间的线性关系。类似的softmax探索方法与此类似。
对于greedy探索方法,其总后悔值也是线性的,这是因为该探索方法的行为选择可能会锁死在一个不是最佳的行为上。
现在问题是,能否找到一种探索方法,使用该探索方法时随着时间的推移其总后悔值增加得越来越少呢?答案是肯定的。下文将依次介绍几种较好的探索方法。
2. 估计方法
(1) 乐观初始估计(Optimistic Initialization)
理论上,这仍是总后悔值线性增加的探索方法,但是实际应用效果却非常好,因此放在这里介绍。其主要思想是在初始时给动作 A A A 一个较高的价值,随后使用递增蒙特卡罗评估来更新该动作的价值:
Q ^ t ( a t ) = Q ^ t − 1 + 1 N t ( a t ) ( r t − Q ^ t − 1 ) \hat Q_t(a_t)=\hat Q_{t-1}+\frac{1}{N_t(a_t)}(r_t-\hat Q_{t-1}) Q^t(at)=Q^t−1+Nt(at)1(rt−Q^t−1)
可以看出,某动作的价值会随着实际获得的即时奖励在初始设置的较高价值基础上不断得到更新,这在一定程度上达到了尽可能尝试所有可能的动作。但是该方法仍然可能锁死在次优动作上。理论上,该方法与greedy或 ϵ − g r e e d y \epsilon-greedy ϵ−greedy 结合带来的结果同样是线性增加的总后悔值。
(2) 衰减Ɛ-greedy(Decaying Ɛ-greedy)
这是在 ϵ − g r e e d y \epsilon-greedy ϵ−greedy 的基础上做细小的修改,这个在之前讲解过:即随着时间的延长, ϵ \epsilon ϵ 值越来越小。我们来从理论上考虑如下这个安排:
假设我们现在知道每一个动作的最优价值 V ∗ V^* V∗,那么我们可以根据动作的价值计算出所有动作的差距 Δ a \Delta a Δa。可设置为:如果一个动作的差距越小,则尝试该动作的机会越多;如果一个动作的差距越大,则尝试该动作的几率越小。数学表达如下:
- c > 0 c > 0 c>0:常数(可以调整,通常是超参数)。
- d = min a ∣ Δ a > 0 Δ i d = \min_{a \mid \Delta_a > 0} \Delta_i d=mina∣Δa>0Δi:所有次优臂到最优臂的期望奖励差的最小值(gap)。
- ϵ t = min { 1 , c ∣ A ∣ d 2 t } \epsilon_t = \min \left\{ 1, \frac{c |\mathcal{A}|}{d^2 t} \right\} ϵt=min{1,d2tc∣A∣}: ϵ t \epsilon_t ϵt 随 t t t 递减, ∣ A ∣ |A| ∣A∣ 是臂的数量。
按照上述公式设定的 e p s i l o n − g r e e d y epsilon-greedy epsilon−greedy 方法是一种衰减 ϵ − g r e e d y \epsilon-greedy ϵ−greedy 方法,惊奇的是它能够使得总的后悔值呈现出与时间步长的次线性(sublinear)关系:对数关系。不巧的是,该方法需要事先知道每个动作的差距 Δ a \Delta a Δa ,实际上式不可行的。后续的任务就是要找一个实践可行的总后悔值与时间步长呈对数关系的探索方法。
(3) 不确定动作优先探索(optimism in the face of uncertainty)
在展开该方法之前,先思考一个问题:试想一下怎样的多臂赌博机问题容易选择最好动作?
如果一个多臂赌博机其中某个单臂一直给以较高的奖励,而另一个(或其它)单臂则一直给出相对较低的奖励,那么选择起来就容易得多了。相反,如果多个单臂给出的奖励方差较大,忽高忽低,而且多个单臂给出的奖励值有很多时候非常接近,那么选择一个价值高的动作可能就要花费很长时间了,也就是说这些单臂给出的奖励虽然类似,但其均值却差距较大。
因此,可以通过比较候选单臂的价值(均值)与最优价值的差距 Δ a \Delta a Δa 以及描述其奖励分布的相似程度的KL散度 K L ( R a ∣ ∣ R a ∗ ) KL(R_a||R_{a^{*}}) KL(Ra∣∣Ra∗) 来判断总的后悔值下限:差距越大,后悔值越大;奖励分布的相似程度越高,后悔值越低。
针对多臂赌博机,有一个定理是这样说的,渐进意义下的总遗憾至少与步数的对数成正比:
lim t → ∞ L t ≥ log t ∑ a ∣ Δ a > 0 Δ a K L ( R a ∥ R a ∗ ) \lim_{t \to \infty} L_t \geq \log t \sum_{a\,|\,\Delta_a > 0} \frac{\Delta_a}{KL(\mathcal{R}^a \| \mathcal{R}^{a^*})} t→∞limLt≥logta∣Δa>0∑KL(Ra∥Ra∗)Δa
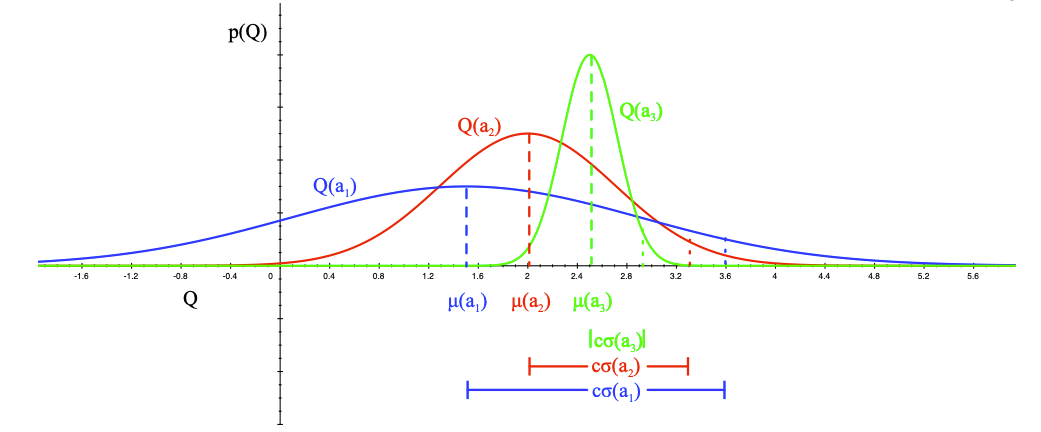
现在我们来看看不确定动作优先搜索具体是怎么回事。想象一下现在由3个不同的单臂组成的多臂赌博机,现根据历史行为和奖励信息,绘制它们当前的奖励分布图。
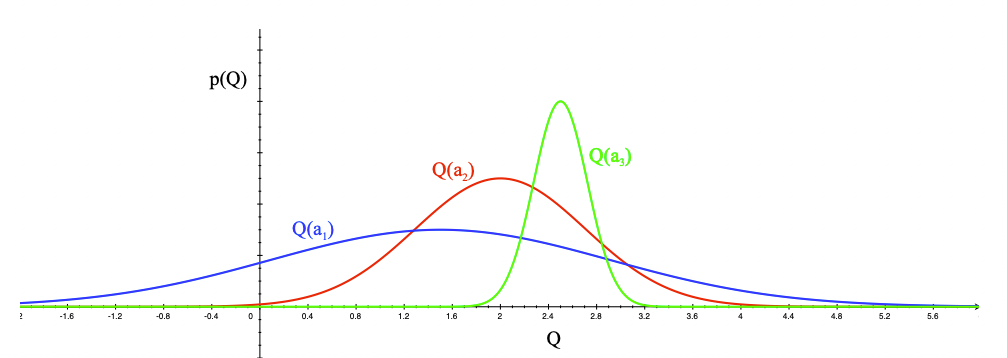
特别注意这并不一定是它们真正服从的奖励分布,而是个体根据历史信息构建的一个经验分布。现在问题是,接下来该如何选择哪一个动作?正确的动作是采取蓝色的单臂,而不是绿色的单臂。理由是,蓝色的分布虽然其奖励均值比绿色的低(图中相应曲线最大P值对应的Q值),但其实际奖励分布范围较广,由于探索次数的限制,蓝色单臂对应的动作价值有不少的几率要比分布较窄的绿色单臂要高,也就是说蓝色单臂的动作价值具有较高的不确定性。因此我们需要优先尝试更多的蓝色单臂,以更准确地估计其动作价值,即尽可能缩小其奖励分布的方差。
从上面的分析可以看出,单纯用动作的奖励均值作为动作价值的估计进而知道后续动作的选择因为采样数量的原因可能会不够准确,更加准确的办法是:
- 对每个动作值估计一个上置信界 U ^ t ( a ) \hat U_t(a) U^t(a)
- 满足 Q ( a ) ≤ Q ^ t ( a ) + U ^ t ( a ) Q(a)\leq \hat Q_t(a)+\hat U_t(a) Q(a)≤Q^t(a)+U^t(a)(高概率下成立)
- 这取决于动作 a a a 被选择的次数 N ( a ) N(a) N(a)
- 当 N t ( a ) N_t(a) Nt(a) 较小时, U ^ t ( a ) \hat U_t(a) U^t(a) 较大(估计值不确定)
- 当 N t ( a ) N_t(a) Nt(a) 较大时, U ^ t ( a ) \hat U_t(a) U^t(a) 较小(估计值准确)
- 选择使上置信界(UCB)最大的动作:
a t = a r g max a ∈ A Q ^ t ( a ) + U ^ t ( a ) a_t=arg\ \max_{a\in A} \hat Q_t(a)+\hat U_t(a) at=arg a∈AmaxQ^t(a)+U^t(a)
如果即时奖励分布是明确可知的,那么置信区间上界将比较容易根据均值进行求解。例如对于高斯分布95%的置信区间上界是均值与两倍标准差的和。而一般的对于分布未知的执行区间上界如何得到呢?这就要用到Hoeffding 不等式了。
定理(Hoeffding 不等式):
设 X 1 , X 2 , ⋯ , X t X_1,X_2,\cdots,X_t X1,X2,⋯,Xt 是取值在 [ 0 , 1 ] [0,1] [0,1] 区间上的独立同分布随机变量, X ˉ t = 1 τ ∑ τ = 1 t X τ \bar{X}_t=\frac{1}{\tau}\sum_{\tau=1}^t X_{\tau} Xˉt=τ1∑τ=1tXτ 是样本均值,则有:
P [ E [ X ] > X ˉ t + u ] ≤ e − 2 t u 2 \mathbb{P}[\mathbb{E}[X]>\bar{X}_t+u] \leq e^{-2tu^2} P[E[X]>Xˉt+u]≤e−2tu2
我们将把 Hoeffding 不等式应用于 bandit 的奖励,在选择动作
a a a 的条件下,有:
P [ Q ( a ) > Q ^ t ( a ) + U t ( a ) ] ≤ e − 2 N t ( a ) U t ( a ) 2 \mathbb{P}[Q(a)>\hat Q_t(a)+U_t(a)]\leq e^{-2N_t(a)U_t(a)^2} P[Q(a)>Q^t(a)+Ut(a)]≤e−2Nt(a)Ut(a)2
该不等式描述的置信区间上限较之前描述的置信区间上限较弱,但也是实际可用的不等式。利用该不等式得到一个特定可信度的置信区间上限就比较容易了。
UCB算法(Calculating Upper Confidence Bounds)
假定我们设定动作的价值有 p p p 的概率超过我们设置的可信区间上界,即令:
e − 2 N t ( a ) U t ( a ) 2 = p e^{-2N_t(a)U_t(a)^2} = p e−2Nt(a)Ut(a)2=p
那么可以得到:
U t ( a ) = − l o g p 2 N t ( a ) U_t(a)=\sqrt {\frac{-log\ p}{2N_t(a)}} Ut(a)=2Nt(a)−log p
随着时间步长的增加,我们逐渐减少 p p p 值,比如 p = t − 4 p=t^{-4} p=t−4,那么随着时间步长趋向无穷大,我们据此可以得到最佳动作。
给出实际应用时 U t ( a ) U_t(a) Ut(a) 和 a t a_t at 的公式:
U t ( a ) = 2 l o g t N t ( a ) U_t(a)=\sqrt {\frac{2log\ t}{N_t(a)}} Ut(a)=Nt(a)2log t
a t = a r g max a ∈ A Q ( a ) + 2 l o g t N t ( a ) a_t=arg\max_{a\in A}\ Q(a)+\sqrt {\frac{2log\ t}{N_t(a)}} at=arga∈Amax Q(a)+Nt(a)2log t
注:上式中,argmax是针对后两项整体的,式中 N t ( a ) N_t(a) Nt(a) 是动作 a a a 的计数、 Q ( a ) Q(a) Q(a) 是根据历史数据获得的奖励的平均值。
结论:由UCB算法设计的探索方法可以使得总后悔值满足对数渐进关系。
lim t → ∞ L t ≤ 8 log t ∑ a : Δ a > 0 Δ a \lim_{t \to \infty} L_t \leq 8 \log t \sum_{a\,:\,\Delta_a > 0} \Delta_a t→∞limLt≤8logta:Δa>0∑Δa
下图展示了不同设置的UCB算法和不同设置的 ϵ − g r e e d y \epsilon-greedy ϵ−greedy 算法在10臂赌博机上的表现情况。该图由四个分图组成,上方与下方的不同在于10-臂赌博机各臂参数设置不同,相当于描述了各个单臂的即时奖励的分布。左侧图描述的是各个算法随时间表现,右侧图描述的是总后悔值随时间的变化。
事实表明, ϵ − g r e e d y \epsilon-greedy ϵ−greedy 算法如果参数调整得当,可以表现的很好,反之则可能是灾难。UCB在没有掌握任何信息的前提下也能做得很好。
这两组图展示了**多臂赌博机问题(Multi-Armed Bandit)**下,不同算法(UCB2、UCB-tuned、ε-Greedy)在两种不同奖励分布下的表现对比。
每组(上方和下方)都有两个子图:
- 左边:x轴是拉杆次数(plays,log尺度),y轴是“玩到最佳机器的百分比”(% best machine played),即算法选择最优臂的频率。
- 右边:x轴是拉杆次数,y轴是累积懊悔值(regret),即由于没有每次都选最优臂而产生的损失。
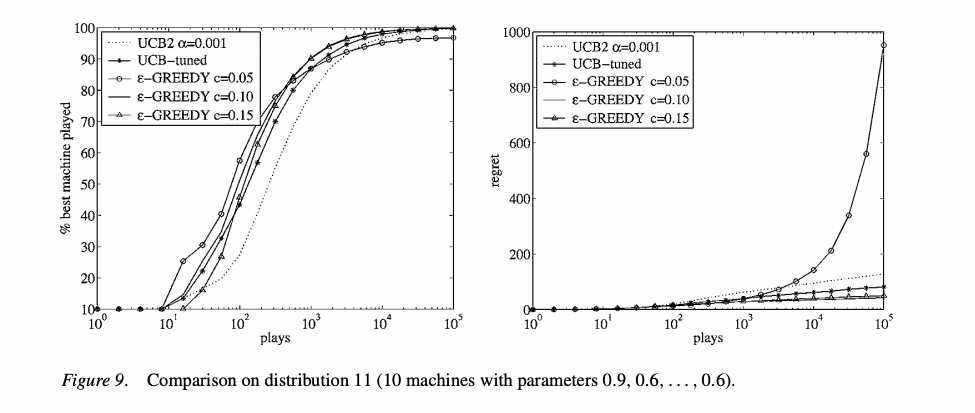
Figure 9 讲解:
- 分布描述:10台老虎机,参数分别为0.9, 0.6, …, 0.6(1台好机器,9台差机器)。
- 左图分析(% best machine played):
- 随着拉杆次数增加,各算法最终都能越来越频繁地选择最优臂(接近100%)。
- UCB2、UCB-tuned、ε-Greedy表现都不错,但UCB-tuned收敛稍快。
- 不同ε值的ε-Greedy策略,ε越小(更贪婪)收敛越快。
- 右图分析(regret):
- UCB系列算法随着时间推移,懊悔值增长较慢。
- ε-Greedy策略,ε越大(探索性强),懊悔值更高,尤其在回合数很大时(10⁴以上),懊悔值急剧上升。
- UCB2的懊悔值始终控制得较低。
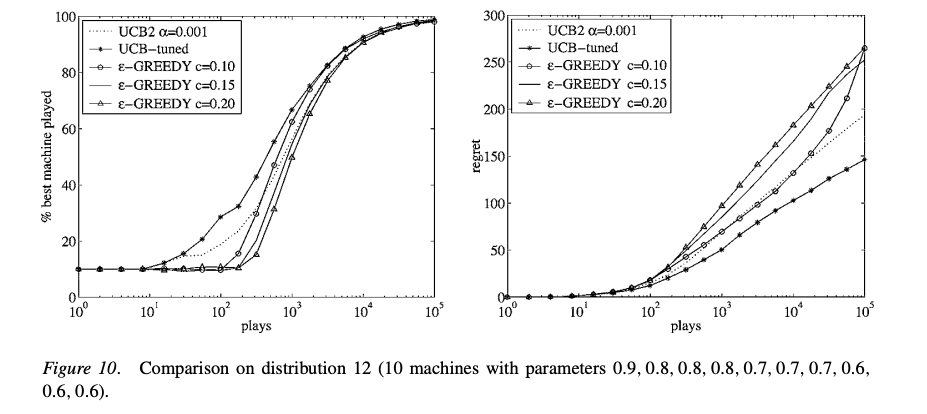
Figure 10 讲解
- 分布描述:10台老虎机,参数为0.9, 0.8, 0.8, 0.8, 0.7, 0.7, 0.7, 0.7, 0.6, 0.6(机器间差距更小)。
- 左图分析(% best machine played):
- 各算法收敛速度比Figure 9慢,因为最优臂与其他臂的差距变小,更难区分最优臂。
- UCB2和UCB-tuned表现稍优于ε-Greedy。
- 右图分析(regret):
- 所有算法的懊悔值都比Figure 9高,因为误选次优臂的概率变大。
- UCB-tuned和UCB2比ε-Greedy策略懊悔值低,尤其是回合数大时。
总结
- UCB算法(UCB2, UCB-tuned)在探索-利用权衡上表现更优,尤其在臂数多/差距小的情况下,懊悔值更低。
- ε-Greedy算法的ε参数影响显著,ε大时探索过多导致懊悔值增加,ε小则更容易收敛到最优臂。
- 随着回合数增加,所有算法最终都能较多地选择最优臂,但UCB类算法收敛更快且懊悔值更低。
前文讲到了UCB算法可以得到很好的效果,UCB算法仅仅依靠统计各个动作的奖励均值和出现的次数,并在此基础上设定一定的置信区间上限,指导动作选择。如果我们利用历史信息构建即时奖励针对每个动作的分布情况,在此基础上决定后续动作的选择也是一条可行的办法。
假设各单臂赌博机服从相互独立的高斯分布,可以用每一个单臂赌博机的均值和标准差参数化整体奖励分布,$ \mathcal{R}_a® = \mathcal{N}(r; \mu_a, \sigma_a^2) $:
对每个动作 a a a 的均值 μ a \mu_a μa 和方差 σ a 2 \sigma_a^2 σa2,在已观测历史 h t h_t ht 下,利用贝叶斯定理计算后验分布:
p [ μ a , σ a 2 ∣ h t ] ∝ p [ μ a , σ a 2 ] ∏ t ∣ a t = a N ( r t ; μ a , σ a 2 ) p[\mu_a, \sigma_a^2 \mid h_t] \propto p[\mu_a, \sigma_a^2] \prod_{t \mid a_t = a} \mathcal{N}(r_t; \mu_a, \sigma_a^2) p[μa,σa2∣ht]∝p[μa,σa2]t∣at=a∏N(rt;μa,σa2)
- p [ μ a , σ a 2 ∣ h t ] p[\mu_a,\sigma_a^2|h_t] p[μa,σa2∣ht]:给定历史数据后, μ a \mu_a μa 和 σ a 2 \sigma_a^2 σa2 的后验概率分布。
- p [ μ a , σ a 2 ] p[\mu_a,\sigma_a^2] p[μa,σa2]:先验分布(对均值和方差的先验假设)。
- ∏ t ∣ a t = a N ( r t ; μ a , σ a 2 ) \prod_{t \mid a_t = a} \mathcal{N}(r_t; \mu_a, \sigma_a^2) ∏t∣at=aN(rt;μa,σa2):所有历史中选择了动作 a a a 时观测到的奖励 r t r_t rt 的似然,假设奖励服从高斯分布。
- 这个公式就是贝叶斯公式在高斯分布下的具体应用。
选择一个动作,让它的期望奖励和不确定性(标准差)加权后的值最大,从而实现探索与利用的平衡。
公式:
a t = a r g max a ( μ a + c σ a / N ( a ) ) a_t=arg\ \max_a(\mu_a+c\sigma_a/\sqrt{N(a)}) at=arg amax(μa+cσa/N(a))
(3) 概率匹配 Probability Matching
Probability Matching 的定义
概率匹配的想法先估计每一个动作可能是最佳动作的概率,然后依据这个概率来选择后续动作。
π ( a ∣ h t ) = P [ Q ( a ) > Q ( a ′ ) , ∀ a ′ ≠ a ∣ h t ] \pi(a|h_t)=\mathbb{P}[Q(a)>Q(a'),\forall a'\ne a|h_t] π(a∣ht)=P[Q(a)>Q(a′),∀a′=a∣ht]
- π ( a ∣ h t ) \pi(a|h_t) π(a∣ht):在历史 h t h_t ht 下,选择动作 a a a 的概率。
- Q ( a ) Q(a) Q(a):动作 a a a 的价值(reward 期望)。
- 意思是:选 a a a 的概率等于 a a a 的 Q Q Q 值超过其他所有动作的概率。
Probability Matching 的特性
- 面临不确定性时具有乐观性(optimistic in the face of uncertainty):
- 那些还不确定(不常被尝试)的动作,虽然均值可能不高,但由于不确定性大,“成为最优”的概率也许较高,因此更容易被探索。
- 这让算法在初期会多探索那些还没有被充分了解的选项。
- 这是一种探索和利用之间的自动平衡。
计算难点
- 难以从后验分布中解析计算:
- 对于很多分布,精确计算“某个动作成为最优的概率”是很难的。
- 实际上通常会用采样方法(如Thompson Sampling)来近似计算:从后验分布中采样每个动作的 Q ( a ) Q(a) Q(a) 选择最大者。
Thompson sampling算法是基于该思想的一种实际可行的算法,该算法实现起来非常简单,同时也是一个非常接近总后悔值对数关系的一个算法。该算法的步骤如下:
- 利用历史信息构建各单臂的奖励分布估计
- 依次从每一个分布中采样得到所有动作对应即时奖励的采样值
- 选取最大采样值对应的动作。
π ( a ∣ h t ) = P [ Q ( a ) > Q ( a ′ ) , ∀ a ′ ≠ a ∣ h t ] = E R ∣ h t [ 1 ( a = arg max a ∈ A Q ( a ) ) ] \begin{align*} \pi(a \mid h_t) &= \mathbb{P} \left[ Q(a) > Q(a'), \, \forall a' \ne a \mid h_t \right] \\ &= \mathbb{E}_{\mathcal{R} \mid h_t} \left[ \mathbf{1}\left( a = \arg\max_{a \in \mathcal{A}} Q(a) \right) \right] \end{align*} π(a∣ht)=P[Q(a)>Q(a′),∀a′=a∣ht]=ER∣ht[1(a=arga∈AmaxQ(a))]
该算法的采样过程中利用到了历史信息得到的分布,同时动作得到的真实奖励值将更新该动作的分布估计。
(4) 信息价值 Value of Information
本小节尝试从信息的角度来讲解另外一种探索方法。探索之所以有价值是因为它会带来更多的信息,那么能否量化被探索信息的价值和探索本身的开销,以此来决定是否有探索该信息的必要呢?这就涉及到信息本身的价值。
先打个比方,对于一个2臂赌博机。假如个体当前对动作 a 1 a1 a1 的价值有一个较为准确的估计,比如是100镑,这意味着执行动作 a 1 a1 a1 可以得到的即时奖励的期望,个体虽然对于动作 a 2 a2 a2 的价值也有一个估计,假如说是70镑,但这个数字非常不准确,因为个体仅执行了非常少次的动作 a 2 a2 a2。那么获取“较为准确的动作 a 2 a2 a2 的价值”这条信息的价值有多少呢?
这取决于很多因素,其中之一就是个体有没有足够多的动作次数来获取累计奖励,假如个体只有非常有限的动作次数,那么个体可能会倾向于保守的选择 a 1 a1 a1 而不去通过探索动作 a 2 a2 a2 而得到较为准确的动作 a 2 a2 a2 的价值。因为探索本身会带来一定几率的后悔。相反如果个体有数千次的动作次数,那么得到一个更准确的动作 a 2 a2 a2 的价值就显得非常必要了,因为即使通过一定次数的探索 a 2 a2 a2,后悔值也是可控的。而一旦得到的动作 a 2 a2 a2 的价值超过 a 1 a1 a1,则将影响后续数千次的动作的选择。
为了能够确定信息本身的价值,可以设计一个MDP,将信息作为MDP的状态构建对其价值的估计:
M ~ = ⟨ S ~ , A , P ~ , R , γ ⟩ \tilde{\mathcal{M}} = \langle \tilde{\mathcal{S}}, \mathcal{A}, \tilde{\mathcal{P}}, \mathcal{R}, \gamma \rangle M~=⟨S~,A,P~,R,γ⟩
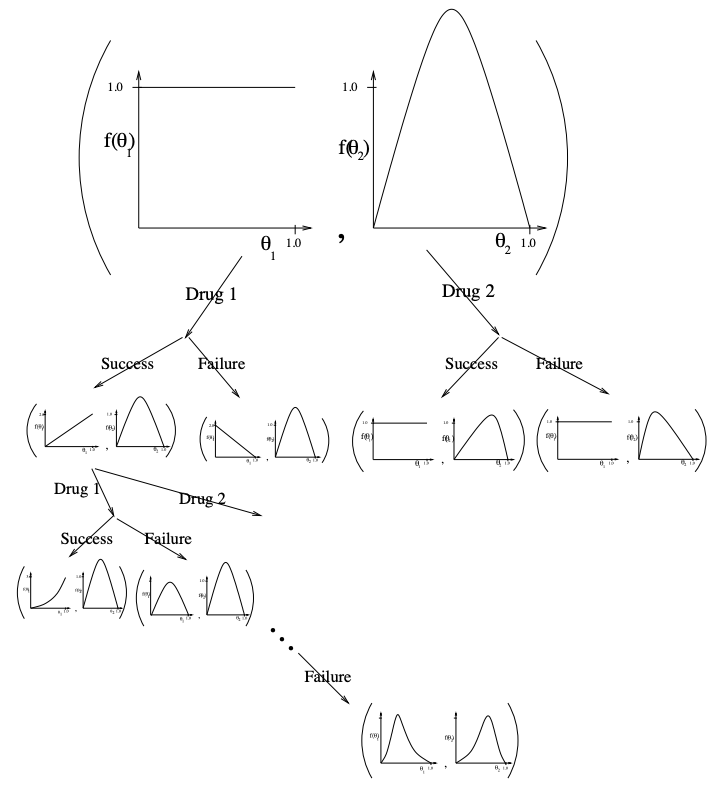
继续使用2臂赌博机的例子来解释信息状态的内容。在这个例子中,一个信息状态对应于分别采取了行为 a 1 a1 a1 和 a 2 a2 a2 的次数,例如S0<5,3>可以表示一个信息状态,它意味着个体在这个状态时已经对动作 a 1 a1 a1 执行了5次, a 2 a2 a2 执行了3次。随后个体又执行了一个动作 a 1 a1 a1,那么状态转移至S1<6,3>。事实上这样的信息状态构建得到的MDP是一个规模非常庞大的MDP,解决它需要使用之前将结果的函数近似。
我们再举一个例子来更加清楚的解释信息状态是如何转换以及转换概率是如何计算的。
现在考虑一个即时奖励服从伯努利分布的赌博机,或者一个服从伯努利分布的药物实验:
R a = B ( μ a ) \mathcal {R}^a=\mathcal {B}(\mu_a) Ra=B(μa)
上式中 μ a \mu_a μa 是拉下一个拉杆能够获得奖励1的概率,或者是选择一个药物其疗效超过一定预期的概率。对于由服从该分布的单臂赌博机构成的2臂赌博机,我们的目标就是找到哪一个赌博机有较高的 μ a \mu_a μa,这样就能每次选择那个较高 μ a \mu_a μa 的赌博机,以此来最小化总后悔值。如果是药物实验,则可以想象成是比较两种药物的疗效优劣,已决定后续选择的药物。
对于这样由2个动作组成的动作空间,可以将信息状态描述为 s ⟨ α , β ⟩ s\langle \alpha, \beta \rangle s⟨α,β⟩,其中 α a \alpha_a αa 为执行动作 A A A 得到奖励为0的次数, β a \beta_a βa 表示执行动作 A A A 得到奖励为1的次数。该信息状态的内容记载了所有历史信息。
下图是较为直观的信息状态转移图。我们从药物实验的角度来解释,动作 a 1 a1 a1 表示个体对某一患者使用药物 a 1 a1 a1,假设疗效服从伯努利分布,它与一个金标准比较可能性只有2个:优于金标准和不优于金标准。
最初个体对于药物 a 1 a1 a1 的疗效一无所知,即它并不清楚药物 a 1 a1 a1 优于金标准疗效的概率分布,也就是说从0-1之间任意一个概率都是均一的(图中上方括号左侧的水平线图);而对于药物 a 2 a2 a2 ,个体通过实验了解到其平均有50%的概率优于金标准疗效(图中上方括号右侧的曲线图)。
每一个信息状态对应的两个曲线图都是对当前状态所有历史信息的描述,也就是各药物疗效优于或不优于金标准的计数。现在前向观察这个搜索树,比如现在选择了动作 a 1 a1 a1,发现动作 a 1 a1 a1 的疗效要优于金标准,那么我们修改对动作 a 1 a1 a1 疗效的计数,同时反映在对应的图上。如果随后继续使用 a 1 a1 a1 但发现疗效不好,则目前对于 a 1 a1 a1 来说一次疗效好,一次不好。则总体呈现出50%类似于药物 a 2 a2 a2 的疗效。
3. 小结
至此通过与状态无关的例子讲解了几大类探索方法。其中特别要指出的是对不确定优先探索这类方法应用在工业上有一定的危险性。因为这类算法优先尝试那些不确定的行为,而一些不确定的行为在工业应用上可能并不安全。例如控制一个机器人行走,你可能并不想让其一直探索未知的行为,这可能导致其摔倒或者其它不可预知的不好后果。