Speech Synthesis/Text to Speech(TTS)
TTS before end-to-end
Traditional deep learning
Input samples——Feature extraction——Feature Selection——Classifier——Output samples
End to end
Concatenative Approach拼接法
speech from a large database由于是直接分割,发音割裂,效果不好
Parametric Approach参数合成法
基于隐马尔科夫模型
Deep Voice
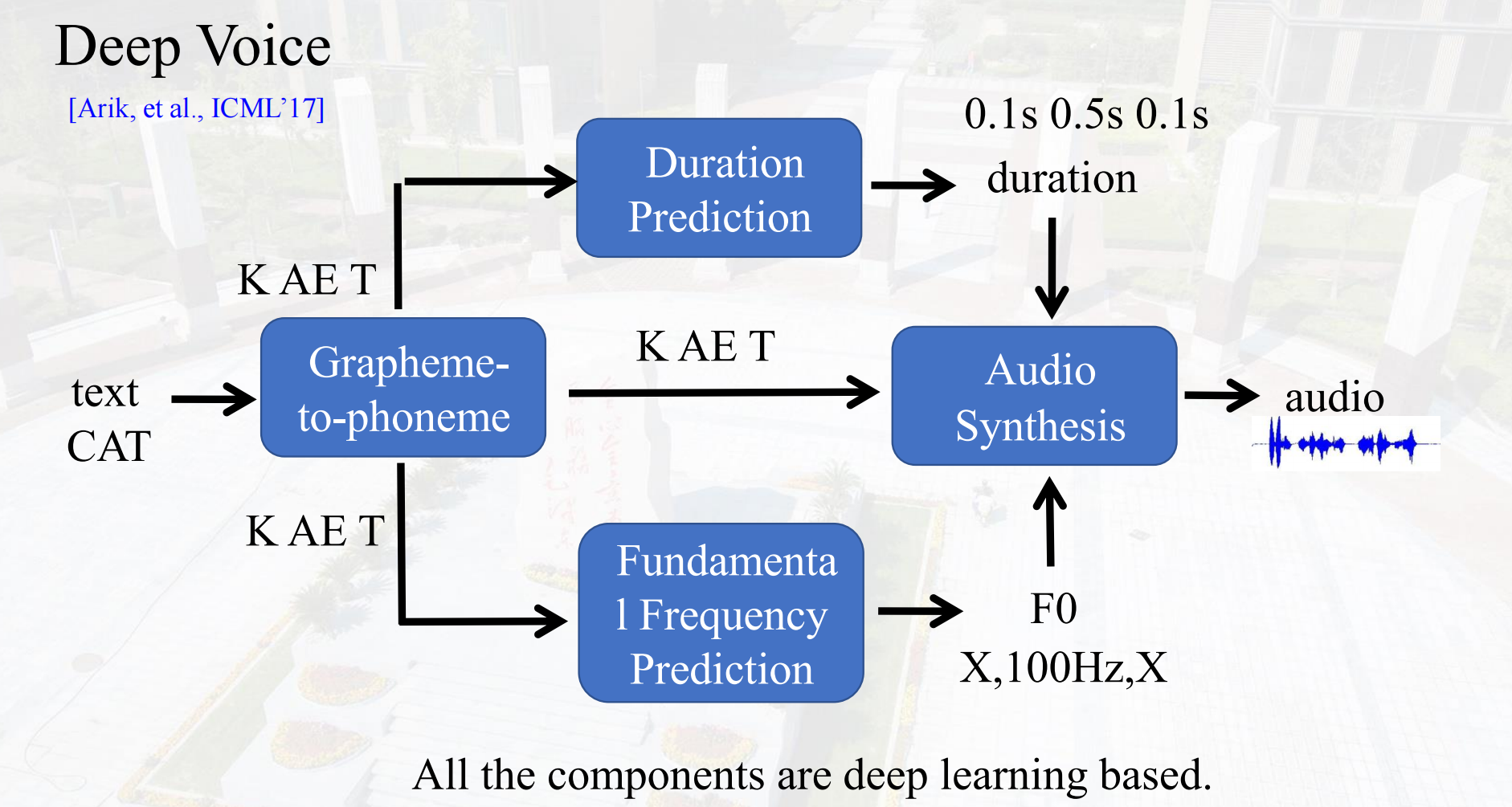
三个关键组件,Grapheme to phoneme根据字母猜测发音,Duration Prediction时长预测,Fundamental Frequency Prediction基频预测,将这三个部分结合,合成语音。
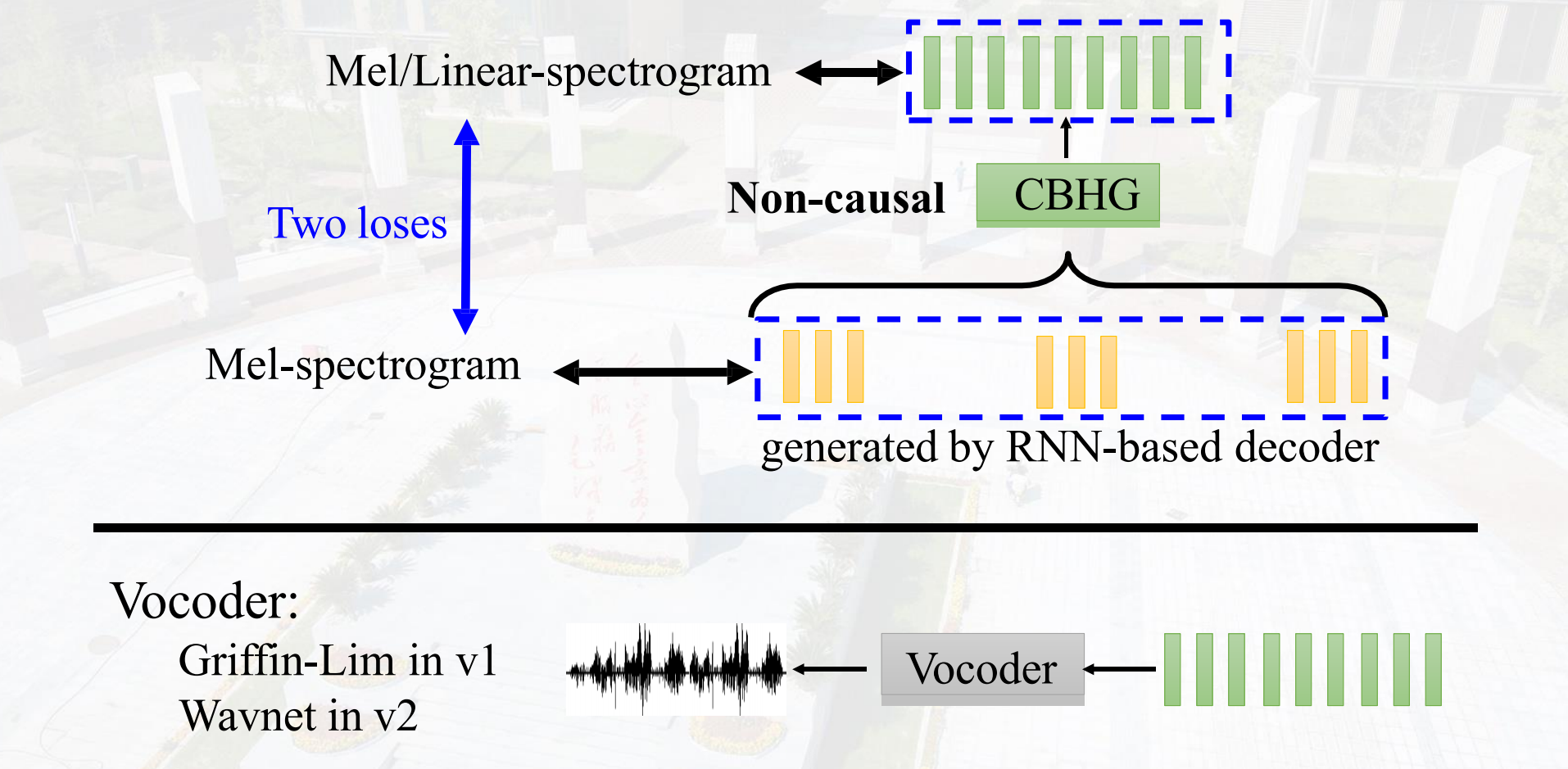
Tacotron:end to end TTS
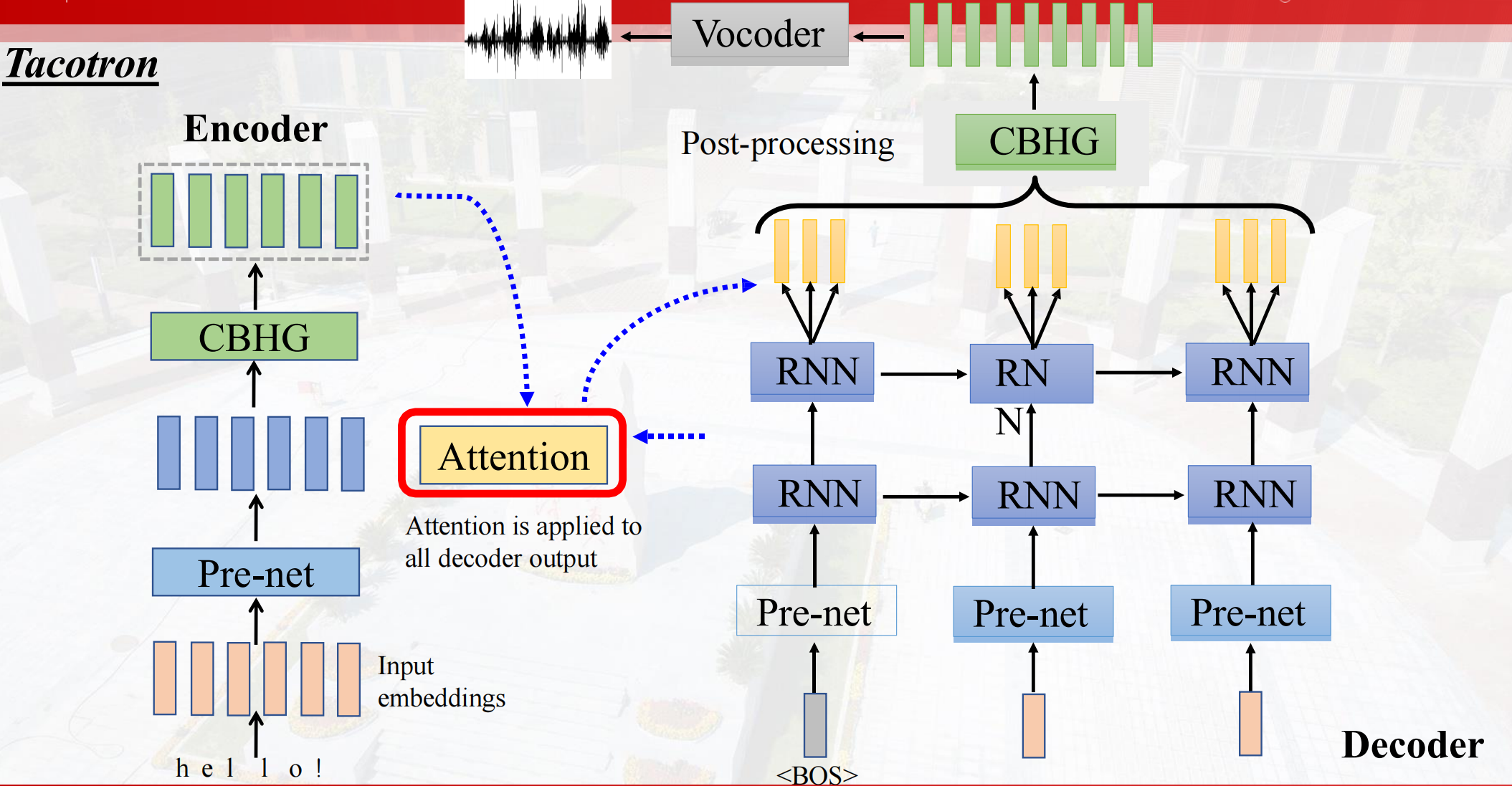
Encoder部分
通过input embedding,对于transformer是需要position encodering的,但是这里不需要。
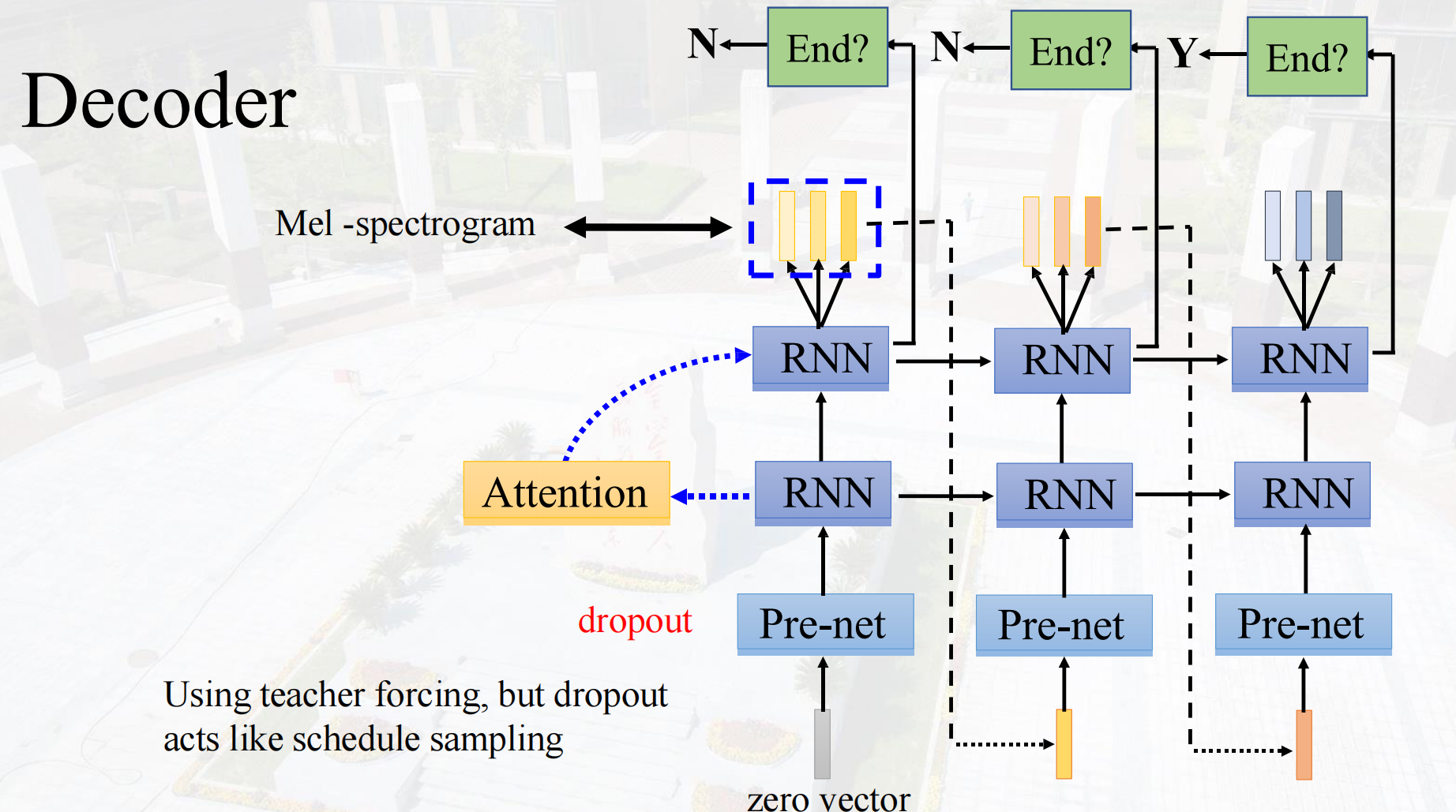
Pre-net通常是预训练好的MLP,一般有三种作用a.全连接,特征融合;b.非线性变换;c.dropout(防止过拟合),在这里是dropout的作用。
CBHG架构包含的内容如下:
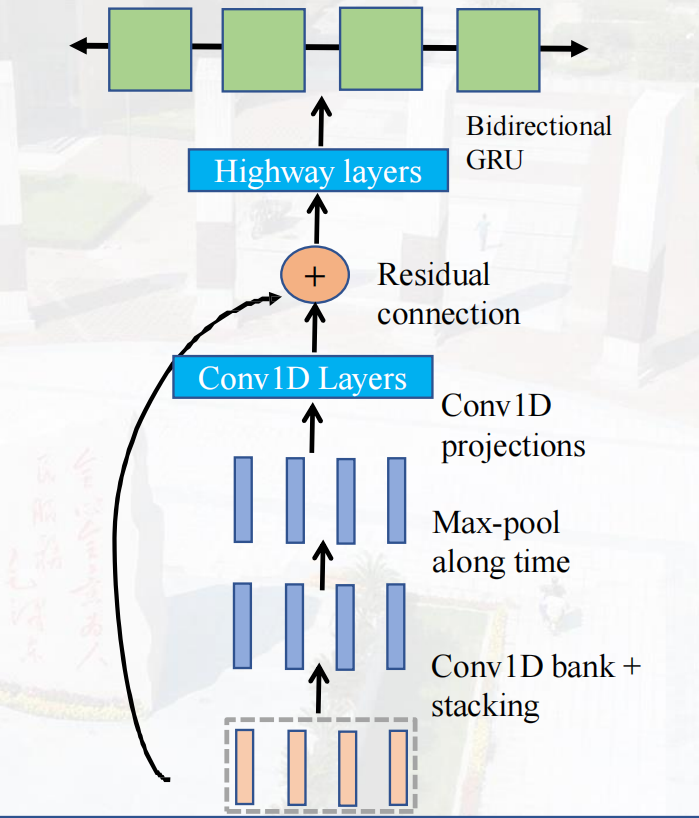
因为是序列数据,采用一维卷积,Max pooling在保留重要信息的情况下减少计算量。
Residual connection防止退化问题。
Attention:Modeling Duration建模持续时间
将文本与语音对齐的作用,输出的音频和输入的文本必须单调对齐。
Decoder