vae 视频截图 复习 gans和vae的原理区别
【双语】Variational Autoencoders_哔哩哔哩_bilibili

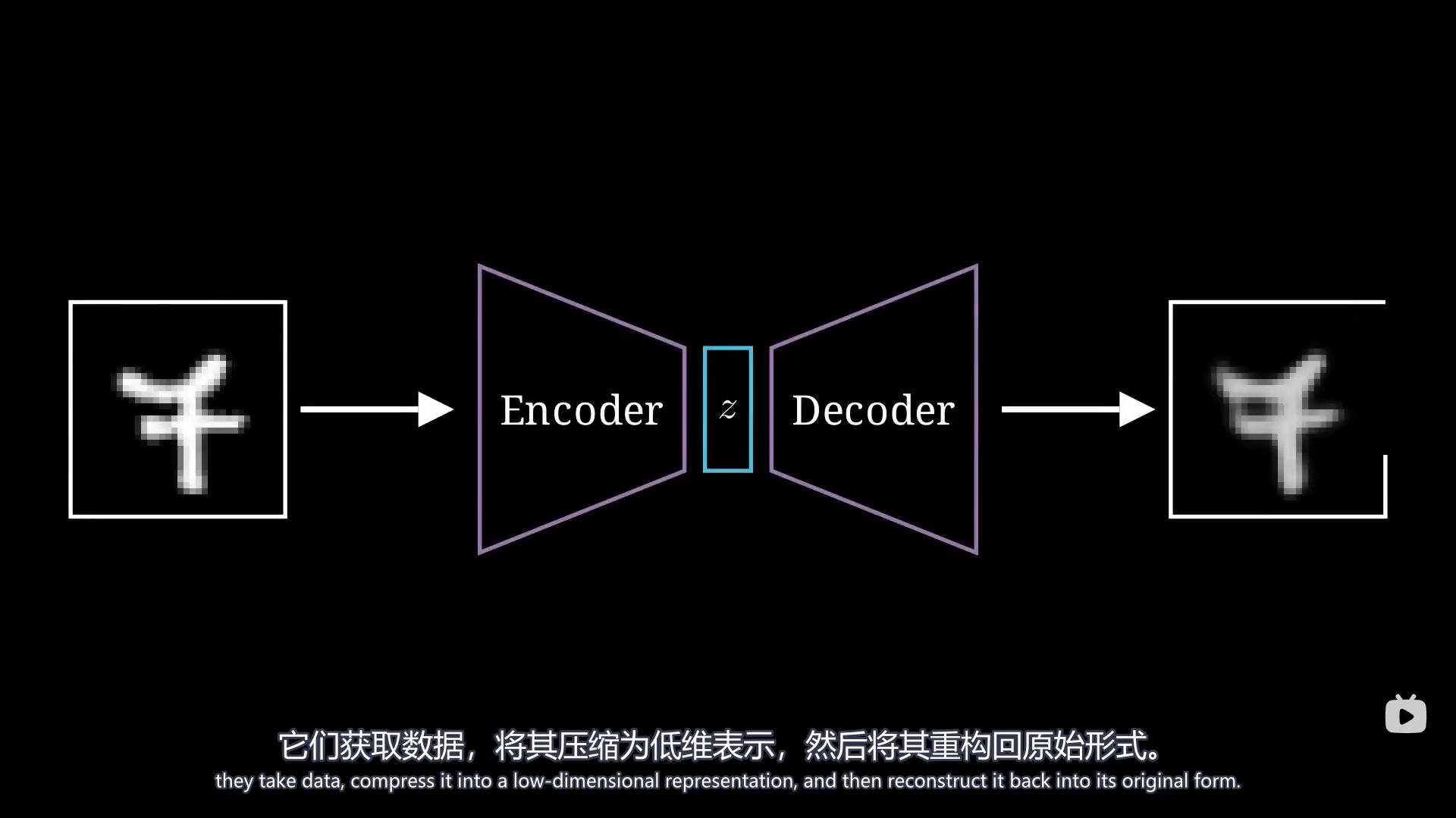
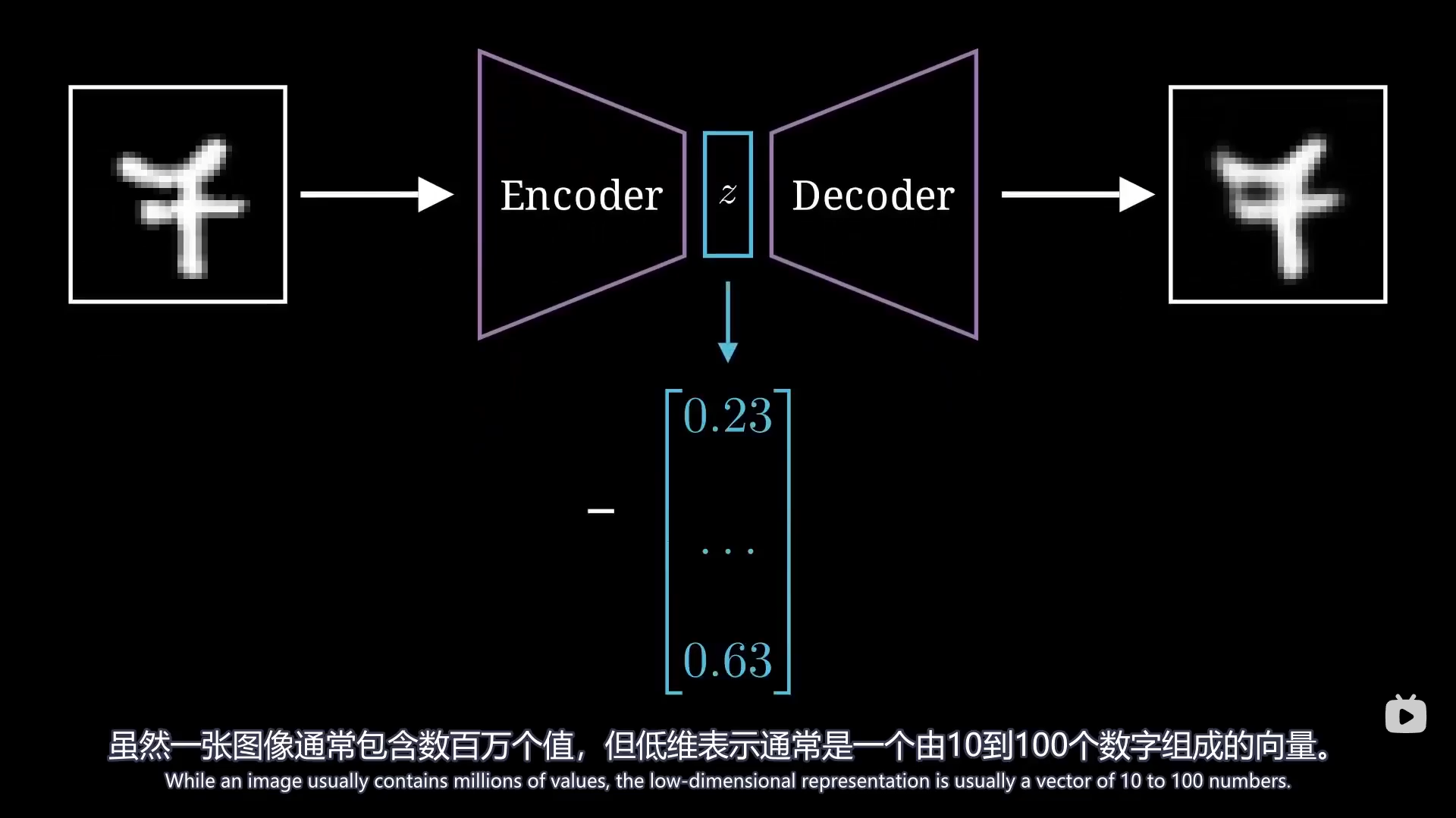
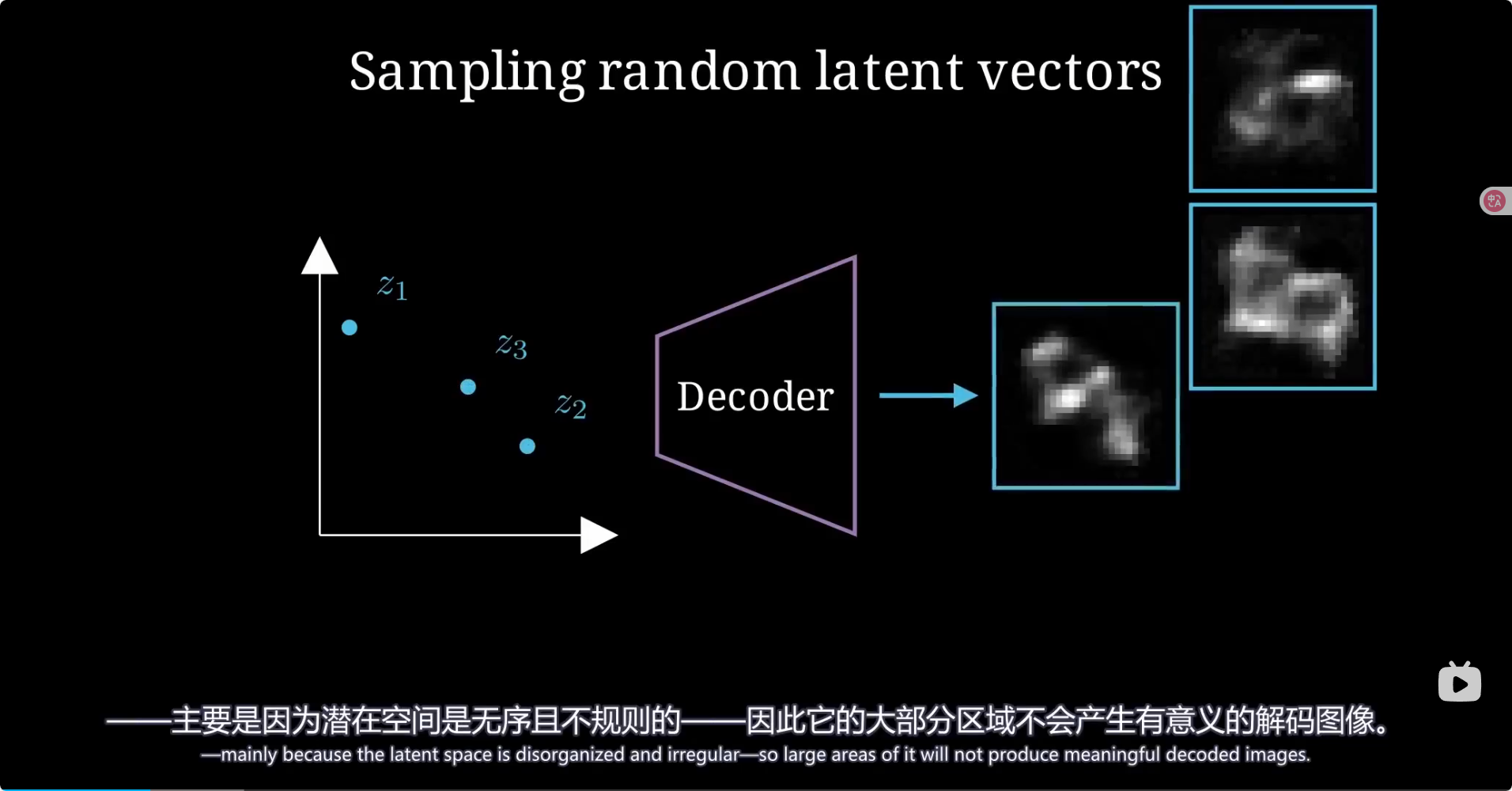
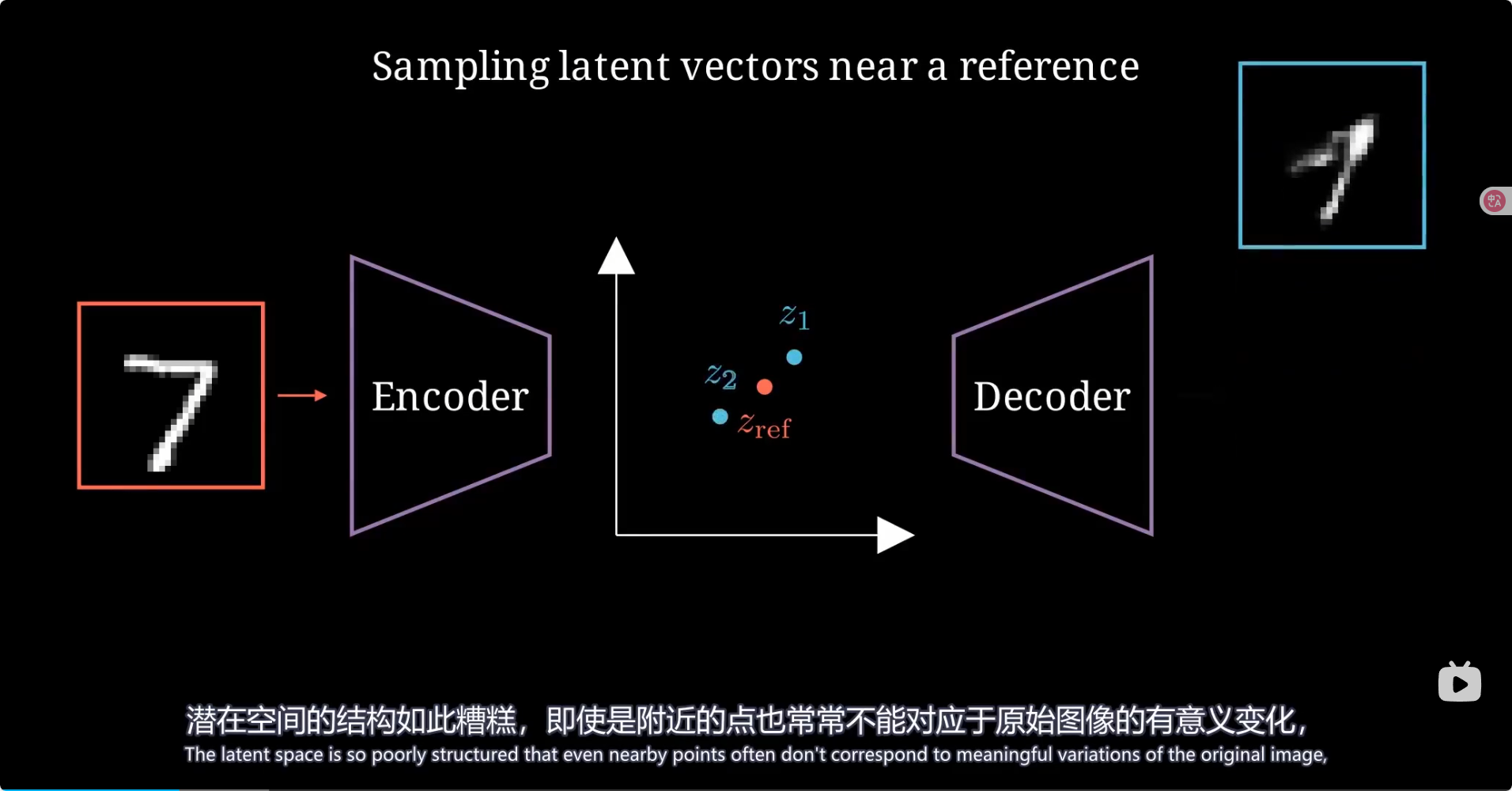


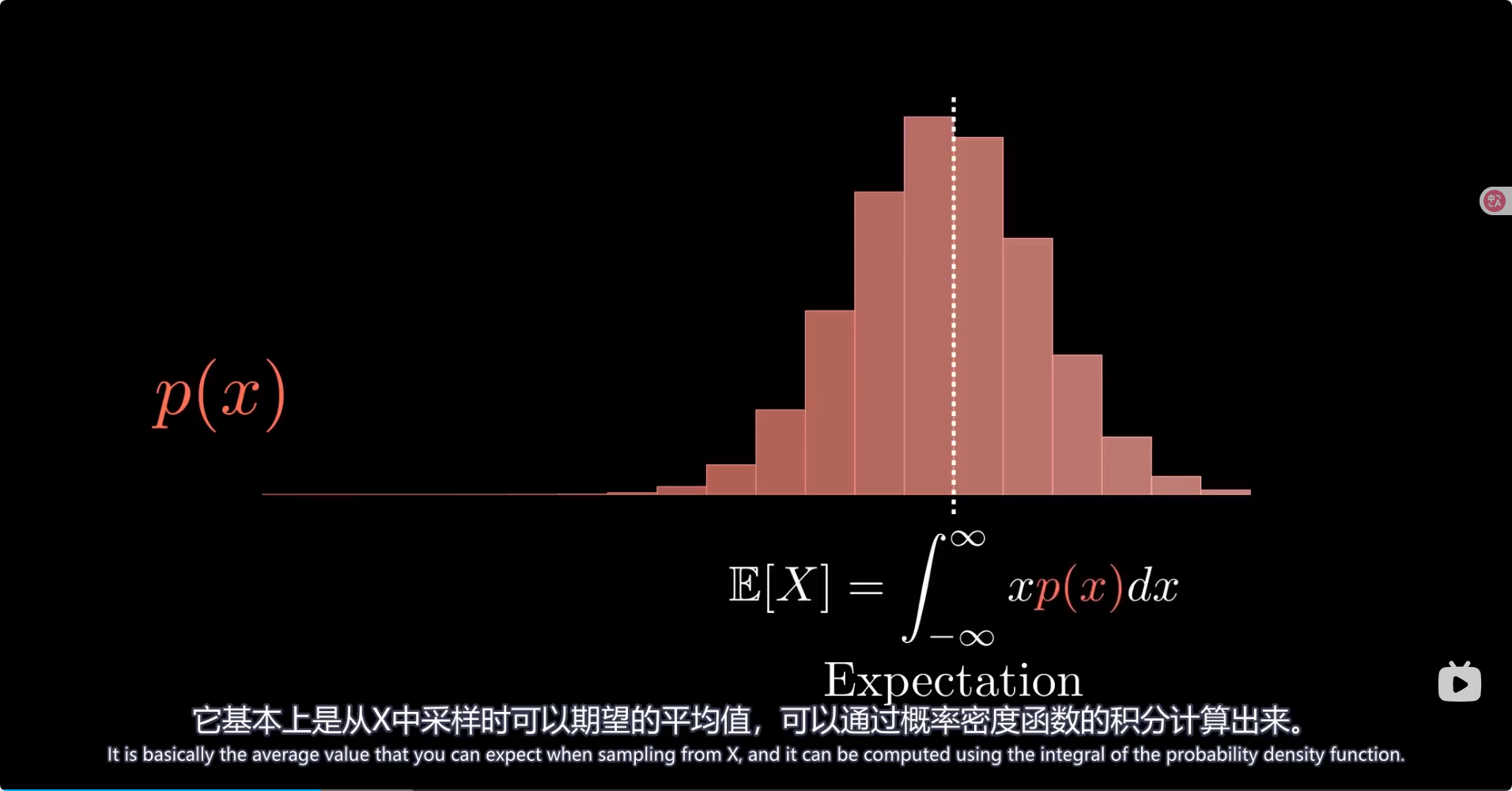
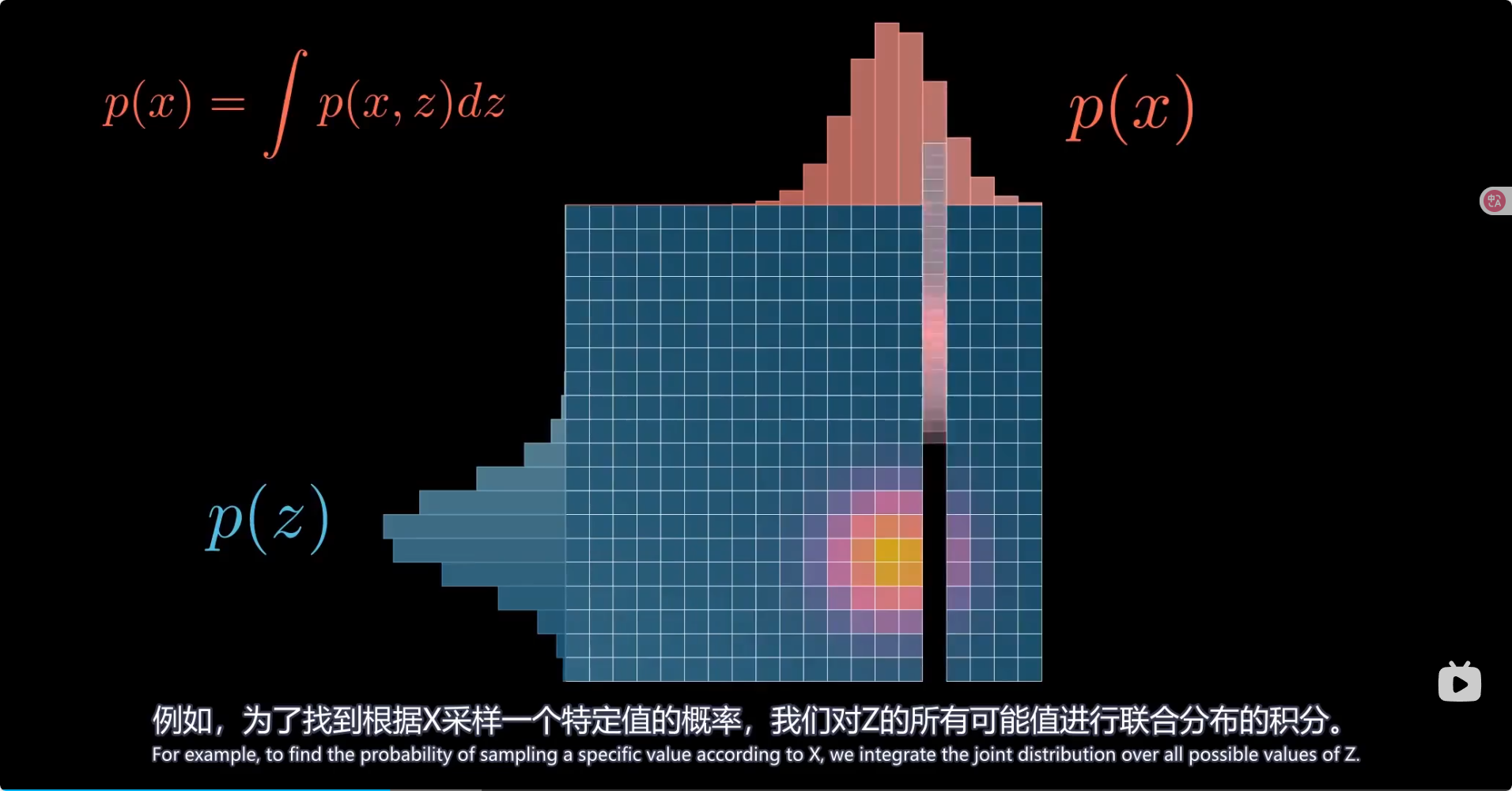
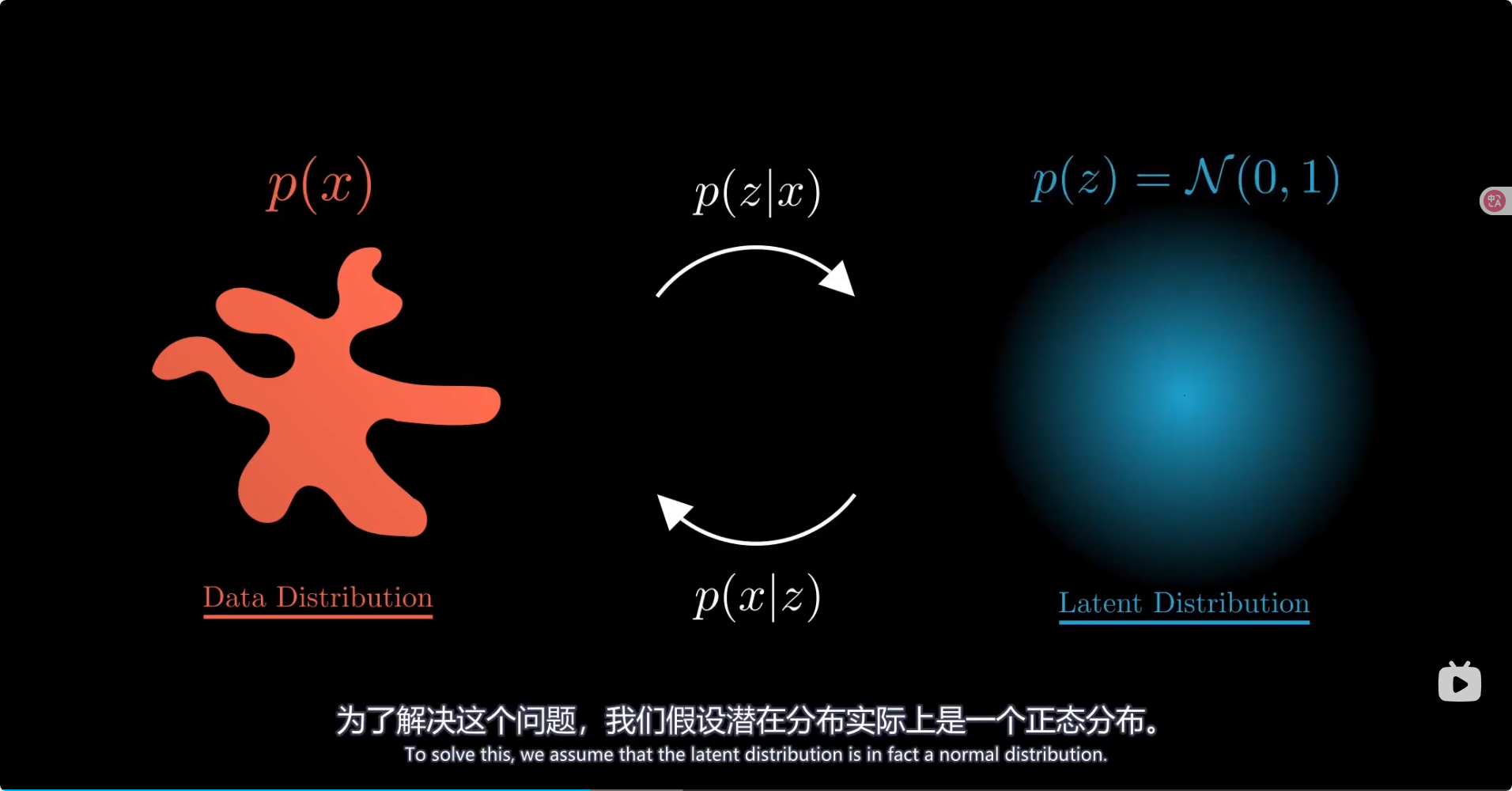
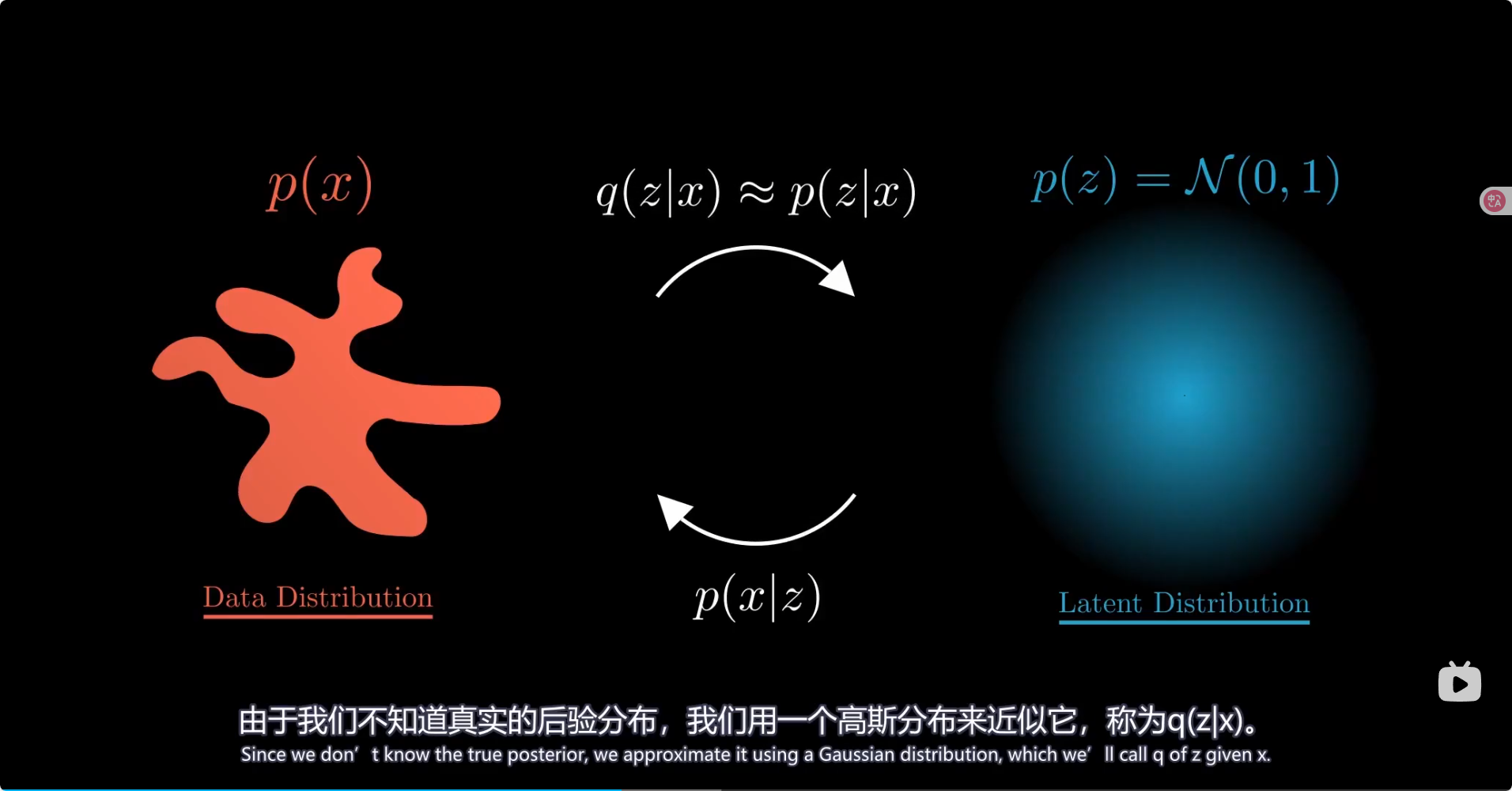
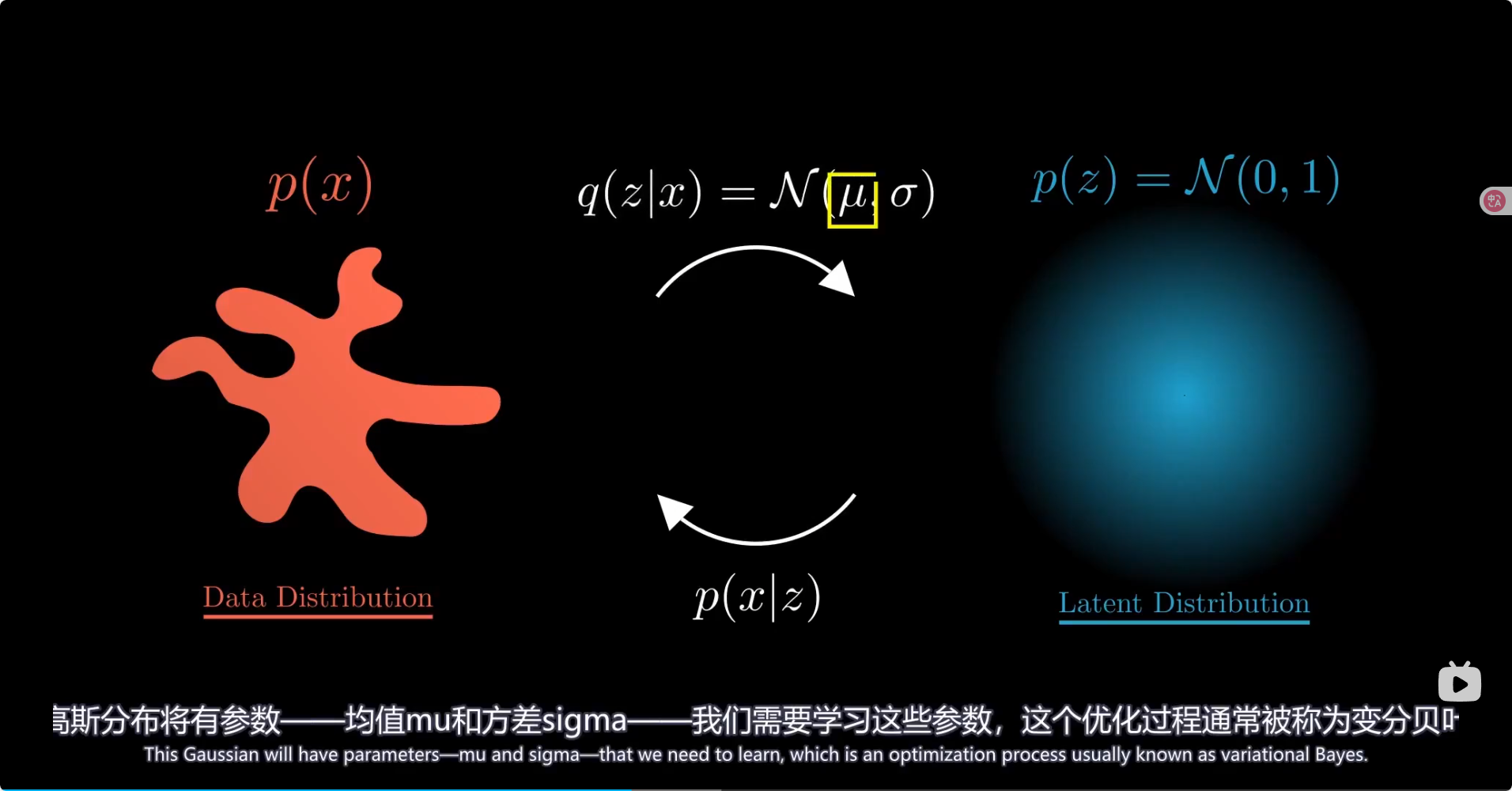

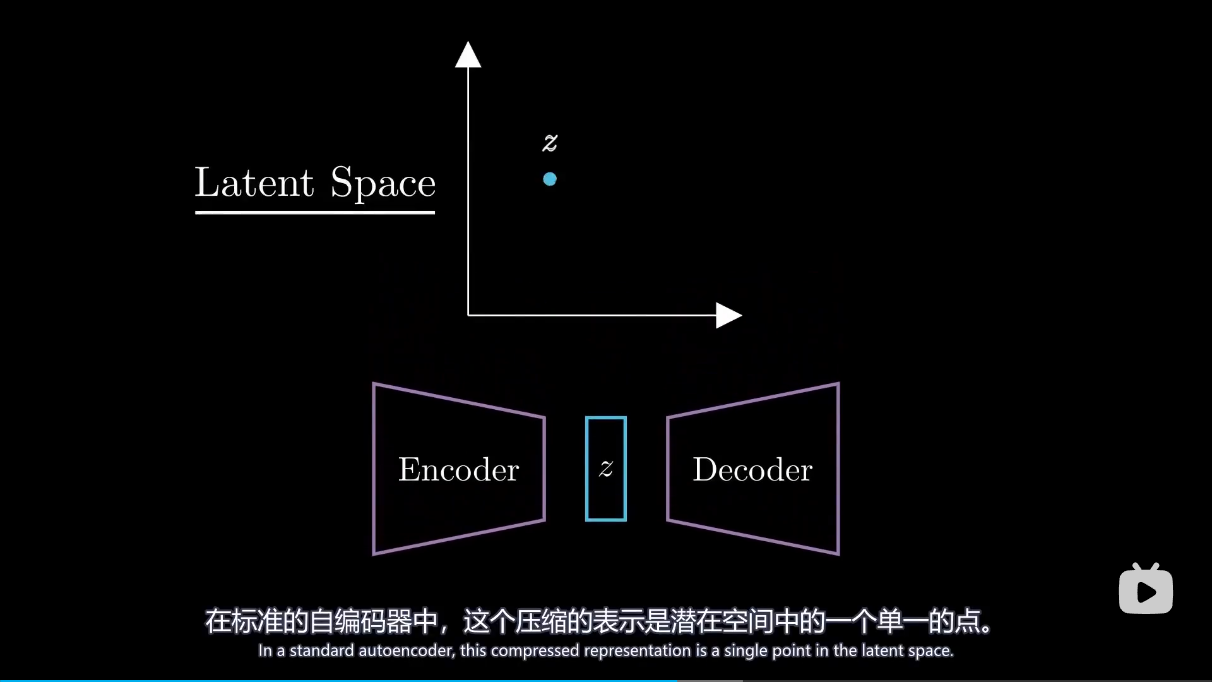
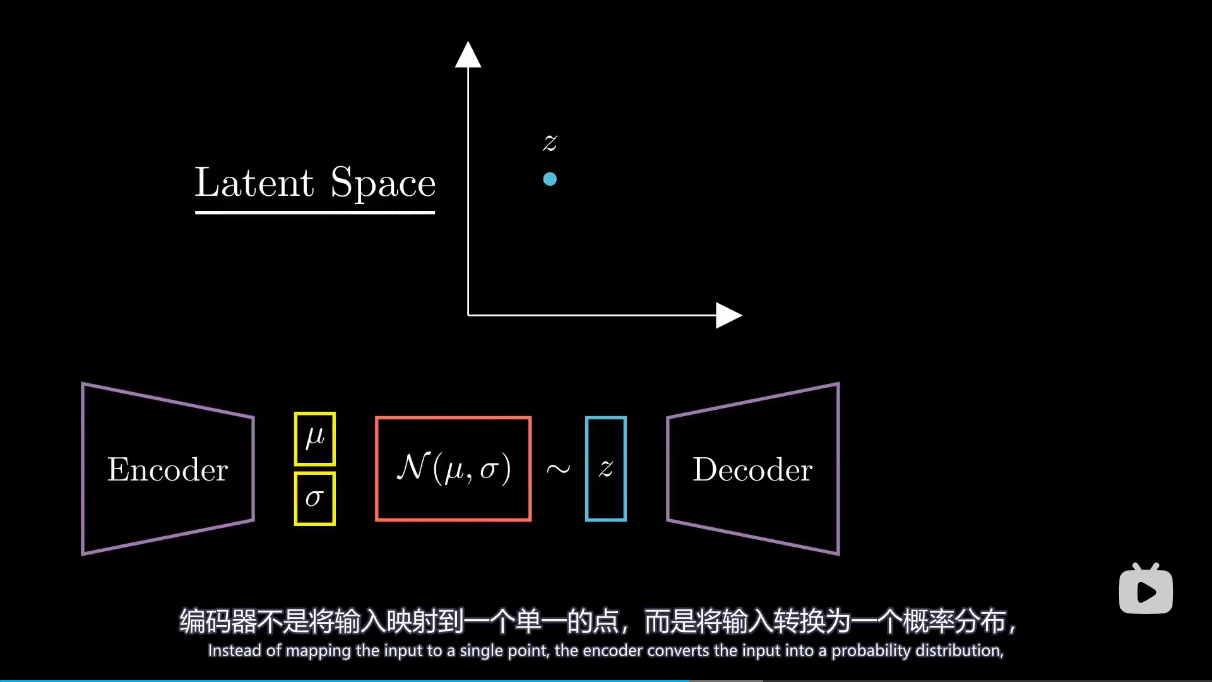
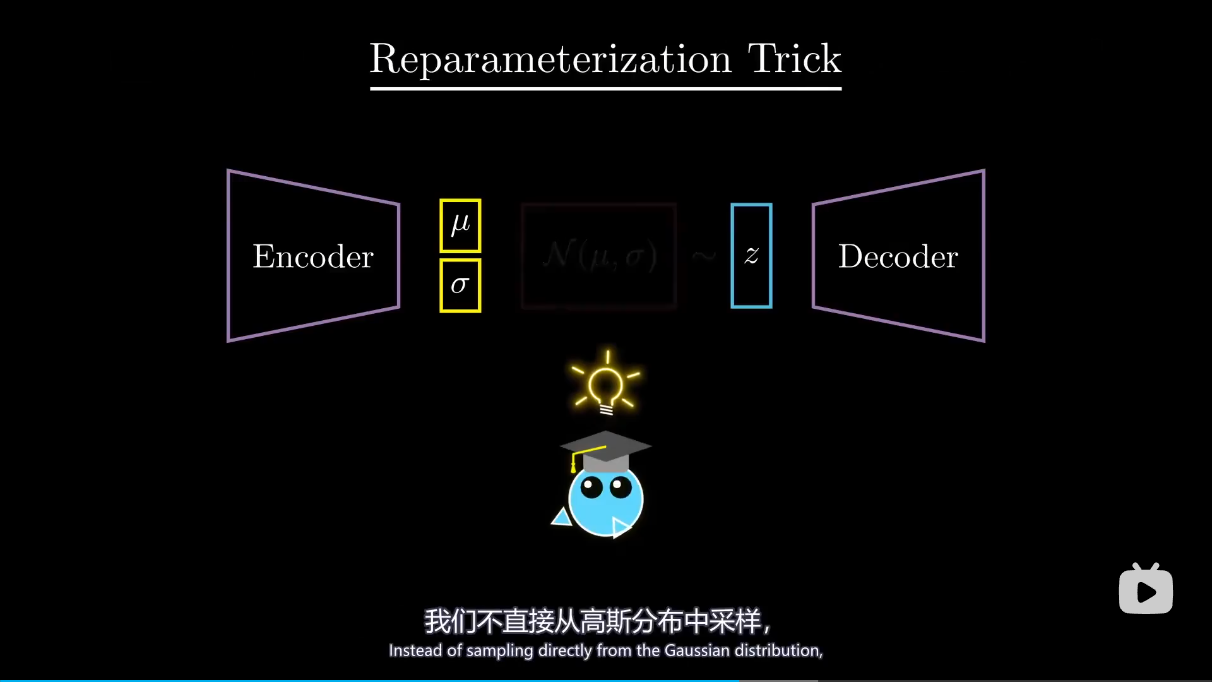
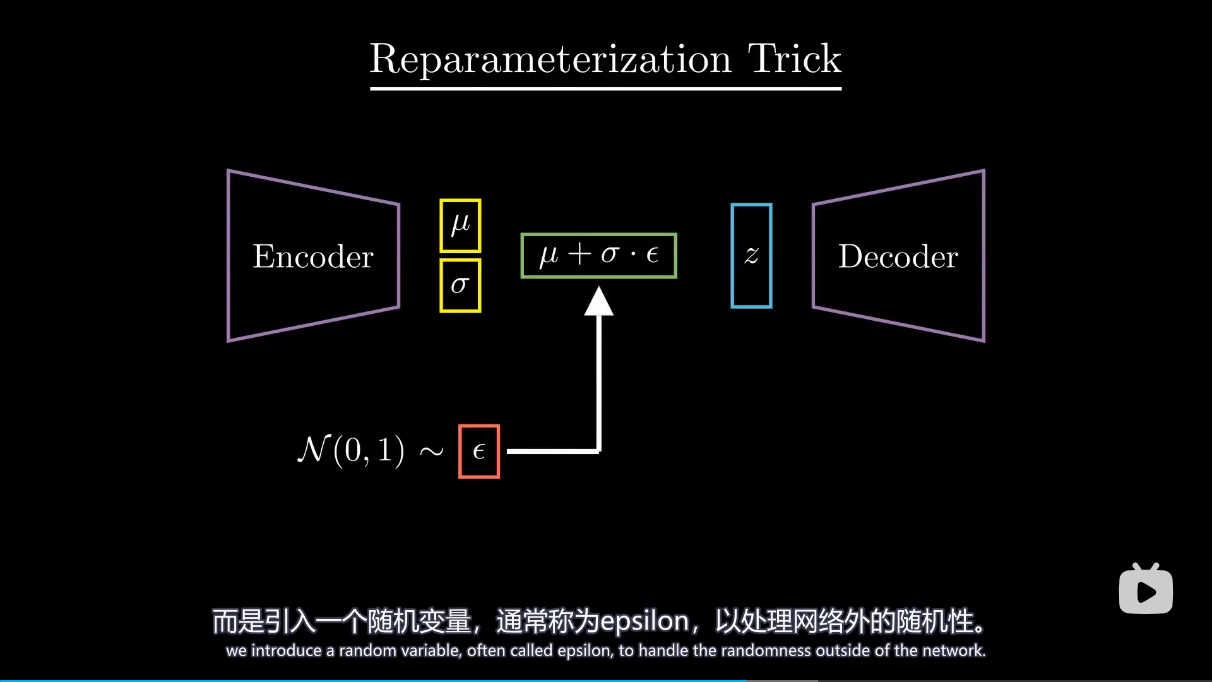


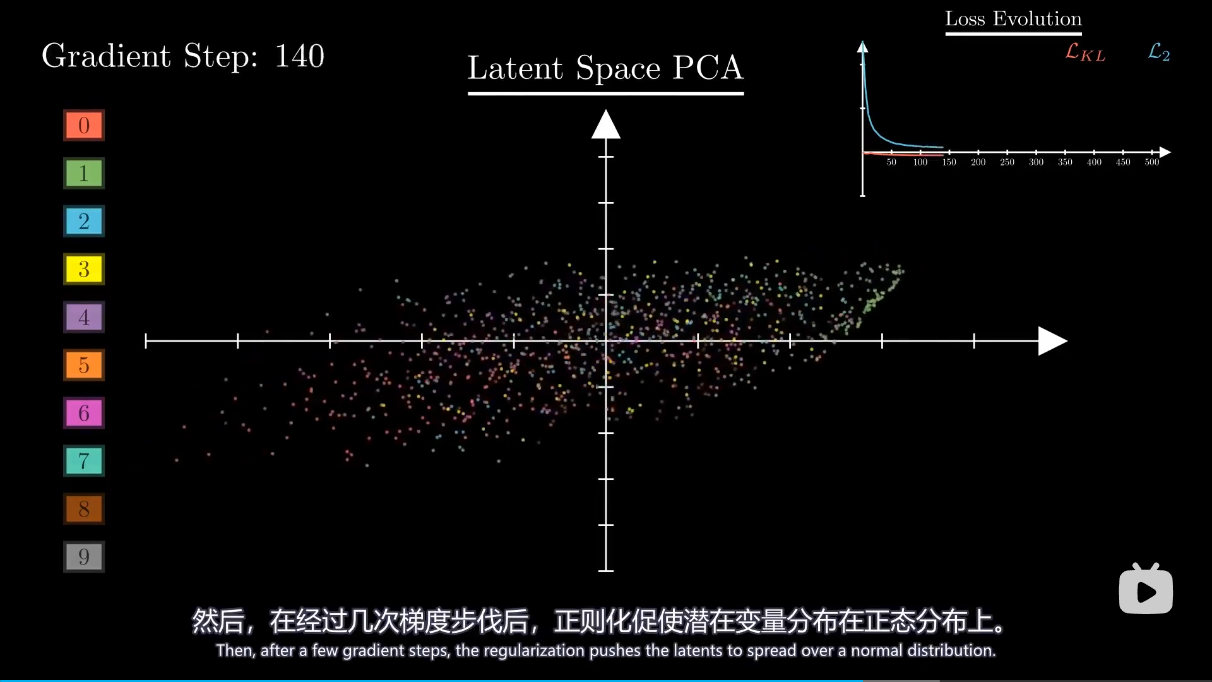
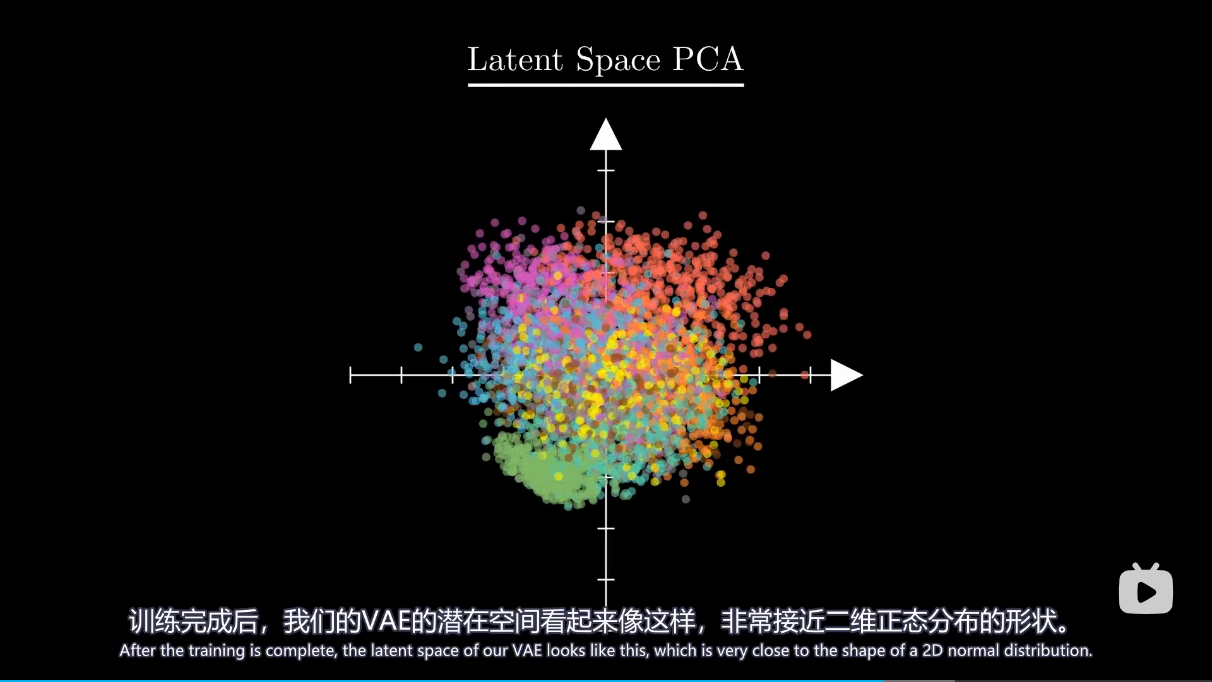
 总结 模型里引入了高斯分布参数从而可以让潜在空间规则地生成图像
总结 模型里引入了高斯分布参数从而可以让潜在空间规则地生成图像






使用均方误差(MSE)作为变分自编码器(VAE)的重构损失函数是完全可行的,但这样做可能会导致一些与使用交叉熵不同的效果和挑战。让我们具体看看如果在VAE中使用MSE会发生什么:
使用MSE的影响
-
适用于连续值数据:MSE通常用于处理连续值的数据,比如图像像素值。如果你处理的是这种类型的数据,使用MSE是可以接受的,并且可以得到合理的重构结果。
-
潜在空间的平滑性:VAE的一个重要特性是它能够学习到一个平滑且结构良好的潜在空间,这使得你可以在潜在空间中进行插值等操作,并生成新的样本。虽然MSE也可以帮助学到有用的潜在表示,但它可能不如交叉熵那样自然地鼓励潜在变量分布接近先验分布(通常是标准正态分布),因此潜在空间的质量可能有所下降。
-
梯度行为:MSE和交叉熵在优化过程中提供不同的梯度行为。对于某些任务,特别是当输出接近0或1时,MSE可能导致梯度消失的问题,因为在这种情况下,预测值的小变化会导致非常小的梯度,从而减慢训练过程。相比之下,交叉熵损失在这种情况下提供了更稳定的梯度。
-
重建质量和多样性:使用MSE可能会导致VAE在重建质量方面表现得不错,但在生成新样本的多样性和质量上可能不如使用交叉熵。这是因为MSE主要关注于最小化输入和输出之间的差异,而没有直接考虑概率分布匹配,这在生成模型中是很重要的。
-
数据假设:交叉熵损失假定每个像素都是从伯努利分布中抽取的,这在二值图像或近似二值的情况下是一个合理的选择。然而,当你使用MSE时,这个假设不再适用,这可能会影响模型对数据的理解和处理方式。
总结
- 可以使用MSE:对于连续值数据,使用MSE作为VAE的重构损失是可行的,并且可以获得不错的重构效果。
- 潜在影响:不过,使用MSE而非交叉熵可能会导致潜在空间不够平滑、优化过程中的梯度问题以及生成样本的多样性和质量上的挑战。
- 选择依据:选择哪种损失函数应基于你的具体应用需求。如果你更关心连续值数据的精确重建,MSE可能是个好选择;但如果你希望获得更好的生成性能和潜在空间的可操作性,那么交叉熵可能是更好的选项。
总之,在决定是否在VAE中使用MSE时,需要权衡这些因素并根据实际应用场景做出最佳选择。


自动编码器(AE)通常使用均方误差(MSE)作为损失函数而不是交叉熵,主要是因为它们的应用场景和目标不同。以下是为什么AE更倾向于使用MSE而非交叉熵的一些关键原因:
1. 数据类型与假设
- 连续值数据:AE主要用于处理连续值的数据,如图像像素值。这些值通常是0到255之间的整数或归一化后的浮点数(例如0到1之间)。对于这种类型的输入数据,MSE是一个自然的选择,因为它直接衡量了两个连续数值之间的差异。
- 交叉熵的适用性:交叉熵损失更适合用于分类任务或当输出可以被视为从概率分布中抽取的情况(比如二值图像或分类标签)。它衡量的是两个概率分布之间的距离,因此在处理非概率性质的连续值数据时不是最佳选择。
2. 损失函数的特性
- MSE的直观性:MSE简单直观,计算的是原始输入 xx 和重构输入 x^x^ 之间的平方差的平均值。这使得它非常适合用来比较重建结果和原始输入之间的相似度,尤其是在希望重建输出尽可能接近真实值的情况下。
- 梯度行为:对于连续值数据,MSE提供了稳定的梯度,这对于训练深度神经网络至关重要。MSE的梯度随预测值和实际值之间的差距线性变化,这有助于优化过程。
3. 目标的不同
- AE的目标:自动编码器的主要目标是学习一个有效的压缩表示(即编码),并能够从这个表示中尽可能准确地重建原始输入。因此,其关注点在于最小化输入和输出之间的误差。
- VAE的目标:相比之下,变分自编码器不仅关注于重建质量,还强调学习潜在变量的分布,使其接近某个先验分布(通常是标准正态分布)。这就是为什么VAE需要采用交叉熵来更好地匹配这种概率模型,并确保潜在空间的平滑性和结构良好性。
总结
- AE用MSE是因为它的主要任务是高效地重建连续值数据,MSE提供了一个简单、直接且有效的手段来测量和最小化输入与输出间的差异。
- 不常用交叉熵是因为交叉熵更适合处理概率性输出或分类问题,在这些情况下,输出被视为属于某个类别或遵循特定的概率分布。对于AE处理的大多数连续值数据集,这不是必要的。
因此,根据AE的设计目的及其所处理的数据类型,MSE被广泛认为是比交叉熵更为合适的选择。然而,这也并非绝对规则,具体选择应基于应用场景和数据特性进行调整。