为什么hash函数能减少哈希冲突
快速回答:哈希表的索引是通过h&(n-1)计算的。n是底层数据的容量;n-1和某个哈希值做&运算,相当于截取了最低的四位,如果数组的容量很小,只取h的低位很容易导致哈希冲突。
通过异或操作将h 的低位引入高位可以增加哈希值的随机性,从而减少哈希冲突。
解释:
以初始⻓度 16 为例,16-1=15。2 进制表示是 0000 0000 0000 0000 0000 0000 0000 1111 。只取最后 4 位相等于哈希值的⾼位都丢弃了。

⽐如说 1111 1111 1111 1111 1111 1111 1111 1111,取最后 4 位,也就是 1111。1110 1111 1111 1111 1111 1111 1111 1111,取最后 4 位,也是 1111。
不就发⽣哈希冲突了吗?
这时候 hash 函数 (h = key.hashCode()) ^ (h >>> 16) 就派上⽤场了。
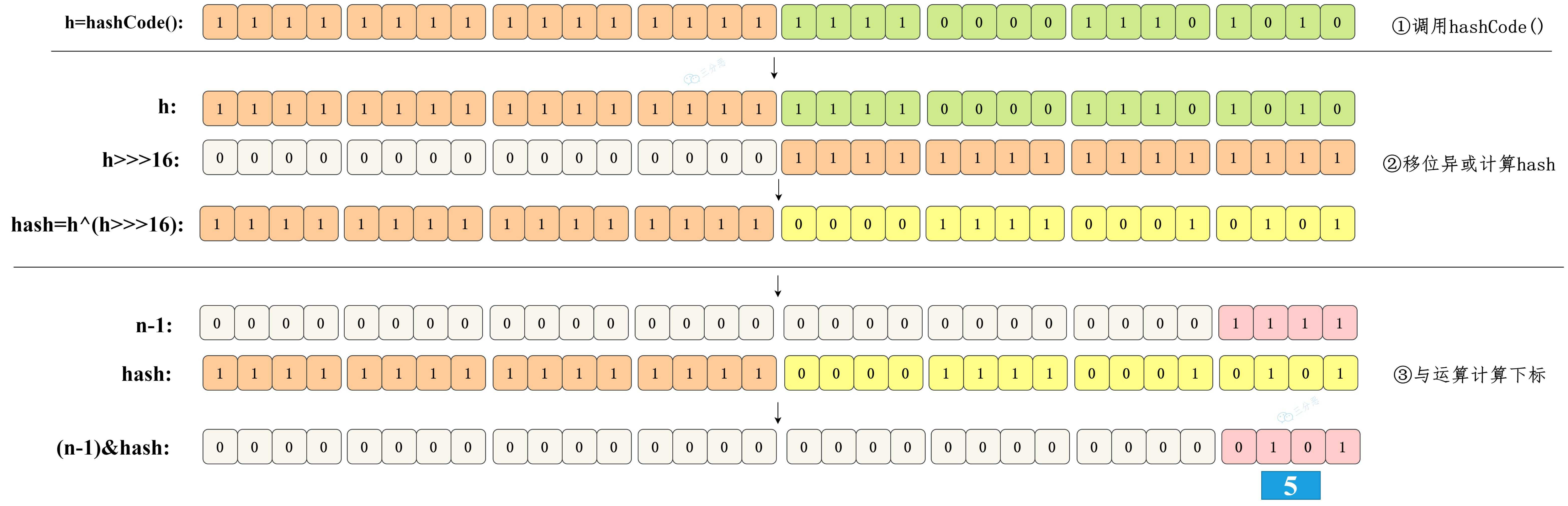
将哈希值⽆符号右移 16 位,意味着原哈希值的⾼ 16 位被移到了低 16 位的位置。这样,原始哈希值的⾼ 16 位和低 16 位就可以参与到最终⽤于索引计算的低位中。
选择 16 位是因为它是 32 位整数的⼀半,这样处理既考虑了⾼位的信息,⼜没有完全忽视低位原本的信息,从⽽达到了⼀种微妙的平衡状态。
举个例⼦(数组⻓度为 16)。
- 第⼀个键值对的键:h1 = 0001 0010 0011 0100 0101 0110 0111 1000
- 第⼆个键值对的键:h2 = 0001 0010 0011 0101 0101 0110 0111 1000
如果没有 hash 函数,直接取低 4 位,那么 h1 和 h2 的低 4 位都是 1000,也就是说两个键值对都会放在数组的第8 个位置。
来看⼀下 hash 函数的处理过程。
①、对于第⼀个键 h1 的计算:
原始: 0001 0010 0011 0100 0101 0110 0111 1000
右移: 0000 0000 0000 0000 0001 0010 0011 0100
异或: -------------------------------------------------
结果: 0001 0010 0011 0100 0100 0100 0100 1100
②、对于第⼆个键 h2 的计算:
原始: 0001 0010 0011 0101 0101 0110 0111 1000
右移: 0000 0000 0000 0000 0001 0010 0011 0101
异或: -------------------------------------------------
结果: 0001 0010 0011 0101 0100 0100 0100 1101
通过上述计算,我们可以看到 h1 和 h2 经过 h ^ (h >>> 16) 操作后得到了不同的结果。现在,考虑数组⻓度为 16 时(需要最低 4 位来确定索引):
对于 h1 的最低 4 位是 1100 (⼗进制中为 12)
对于 h2 的最低 4 位是 1101 (⼗进制中为 13)
这样, h1 和 h2 就会被分别放在数组的第 12 个位置和第 13 个位置上,从⽽避免了哈希冲突。