数量优势:使用Bagging和Boosting的集成模型

文章目录
- 装袋法(Bagging)和提升法(Boosting)
- 利用集成学习创建强大的模型
- 装袋法(Bagging):为机器学习模型增加稳定性
- 装袋法示例
- 提升法(Boosting):减少弱学习器的偏差
- 预测先前的残差
- 树的数量
- 树的深度
- 学习率
- 装袋法 vs. 提升法——核心差异解析
- 总结
装袋法(Bagging)和提升法(Boosting)
装袋法(Bagging)和提升法(Boosting)是机器学习中两种强大的集成技术——它们是数据科学家必须掌握的知识!读完本文后,你将深入理解装袋法和提升法的工作原理以及何时使用它们。我们将涵盖以下主题,并大量使用示例来直观展示关键概念:
- 集成学习(Ensembling):如何助力创建强大的模型
- 装袋法(Bagging):为机器学习模型增添稳定性
- 提升法(Boosting):减少弱学习器的偏差
- 装袋法(Bagging)与提升法(Boosting)——何时使用以及原因
利用集成学习创建强大的模型
在机器学习(Machine Learning领域,集成学习(Ensembling) 是一个宽泛的术语,指的是任何通过组合多个模型的预测结果来进行预测的技术。如果在进行预测时涉及多个模型,那么这种技术就属于集成学习!
集成学习方法通常可以提升单个模型的性能。集成学习有助于减少:
- 方差(Variance):通过对多个模型进行平均。
- 偏差(Bias):通过迭代改进误差。
- 过拟合(Overfitting):因为使用多个模型可以增强对虚假关系的鲁棒性。
装袋法(Bagging)和提升法(Boosting)都是集成方法,它们的表现通常比单个模型要好得多。现在让我们深入了解它们的细节!
装袋法(Bagging):为机器学习模型增加稳定性
装袋法(Bagging)是一种特定的集成学习技术,用于降低预测模型的方差。这里所说的方差是机器学习意义上的,即模型随训练数据集变化的程度,而不是统计学意义上衡量分布离散程度的方差。由于装袋法有助于降低机器学习模型的方差,因此它通常可以改进高方差(High Variance)模型(如决策树(Decision Trees)和K近邻算法(KNN)),但对低方差(Low Variance)模型(如线性回归(Linear Regression))的作用不大。
既然我们已经了解了装袋法在何时起作用(高方差模型),让我们深入了解其内部工作原理,看看它是如何发挥作用的!装袋算法本质上是迭代的,它通过重复以下三个步骤来构建多个模型:
- 从原始训练数据中进行自助采样(Bootstrap),生成新的数据集。
- 在自助采样得到的数据集上训练一个模型。
- 保存训练好的模型。
这个过程中创建的模型集合称为集成(Ensemble)。当需要进行预测时,集成中的每个模型都会做出自己的预测,最终的装袋预测结果是所有模型预测结果的平均值(用于回归问题)或多数投票结果(用于分类问题)。
现在我们了解了装袋法的工作原理,让我们花几分钟时间来直观理解它为什么有效。我们可以借鉴传统统计学中的一个熟悉概念:抽样估计总体均值。
在统计学中,从分布中抽取的每个样本都是一个随机变量。小样本量往往具有高方差,可能无法很好地估计真实均值。但随着我们收集的样本增多,这些样本的平均值就会更接近总体均值。
同样,我们可以将每个单独的决策树视为一个随机变量,毕竟每棵树都是在不同的随机样本数据上训练的!通过对多棵树的预测结果进行平均,装袋法降低了方差,并产生了一个能够更好捕捉数据中真实关系的集成模型。
装袋法示例
我们将使用Scikit-learn Python包中的load_diabetes数据集来说明一个简单的装袋法示例。该数据集有10个输入变量——年龄(Age)、性别(Sex)、身体质量指数(BMI)、血压(Blood Pressure)以及6种血清水平指标(S1 - S6),还有一个表示疾病进展程度的输出变量。下面的代码导入数据并进行了简单的清理。数据集准备好后,我们就可以开始建模了!
# 导入并格式化数据
from sklearn.datasets import load_diabetesdiabetes = load_diabetes(as_frame=True)
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df.loc[:, 'target'] = diabetes.target
df = df.dropna()
在我们的示例中,我们将使用基本的决策树作为装袋法的基础模型。首先,让我们验证一下我们的决策树确实是高方差模型。我们将通过在不同的自助采样数据集上训练三棵决策树,并观察测试数据集预测结果的方差来进行验证。下面的图表展示了三棵不同的决策树在同一测试数据集上的预测结果。每条垂直虚线代表测试数据集中的一个单独观测值。每条线上的三个点分别是三棵不同决策树的预测结果。
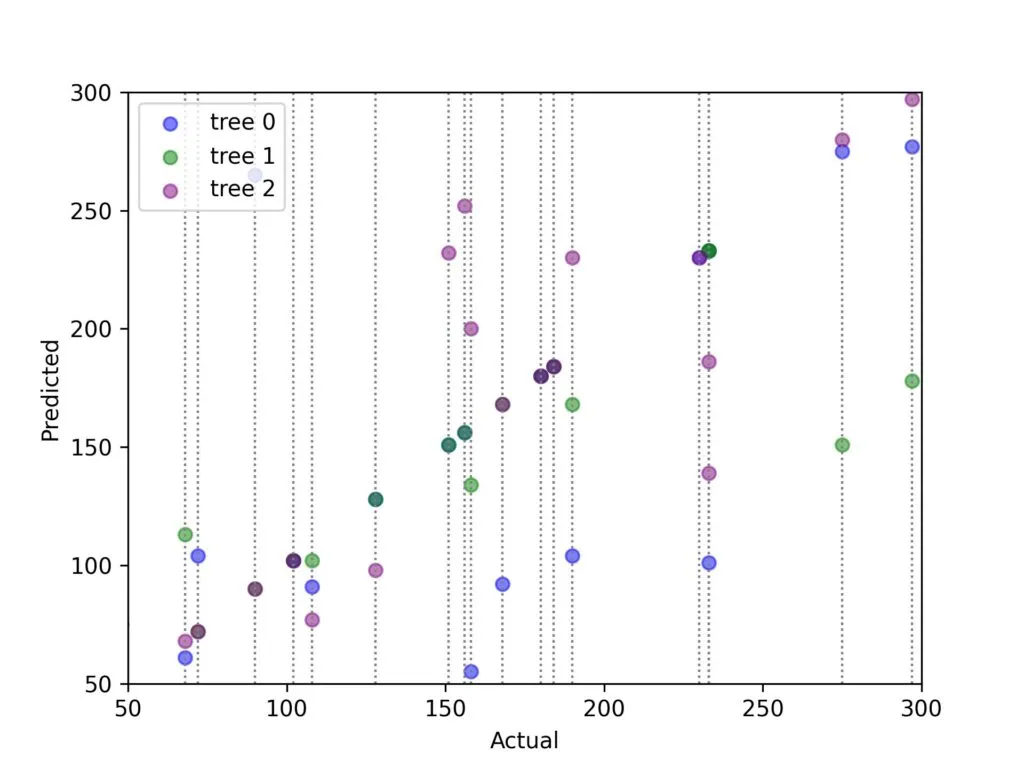
在上面的图表中,我们可以看到,当在自助采样数据集上进行训练时,单个决策树可能会给出非常不同的预测结果(每条垂直线上三个点的分布情况)。这就是我们一直在讨论的方差!
既然我们已经看到我们的决策树对训练样本的鲁棒性不强,让我们对预测结果进行平均,看看装袋法能起到什么作用!下面的图表展示了三棵树预测结果的平均值。对角线代表完美的预测结果。正如你所见,使用装袋法后,我们的数据点更加紧密地围绕在对角线周围。
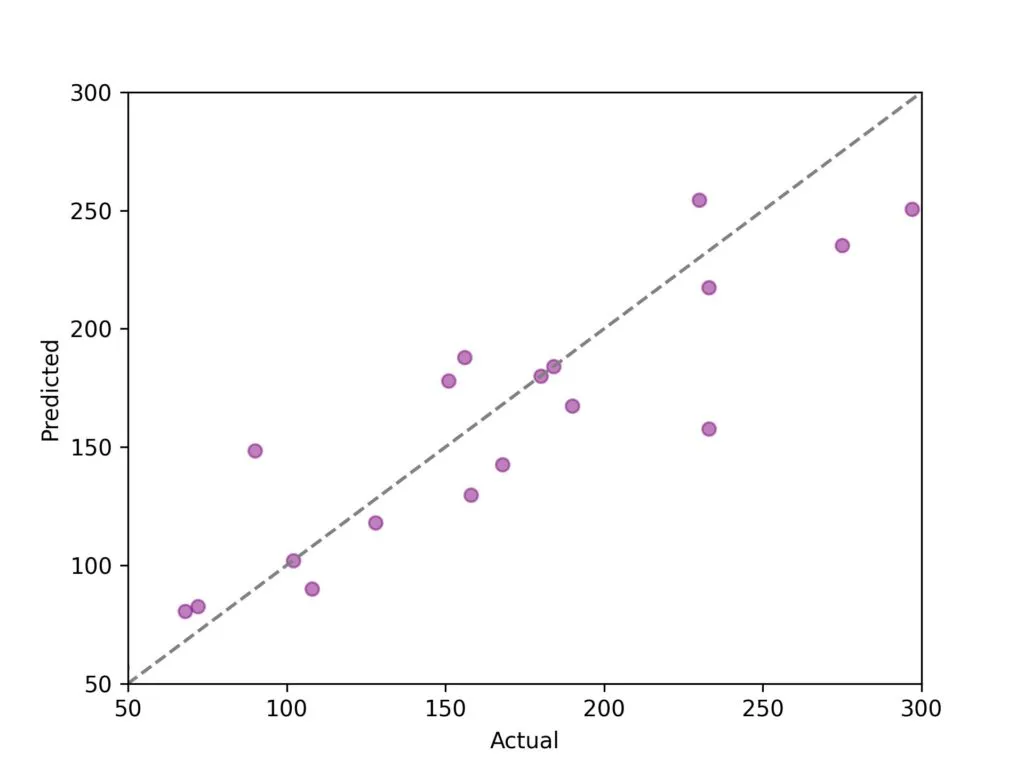
仅仅对三棵树的预测结果进行平均,我们就已经看到了模型性能的显著提升。让我们增加更多的树来强化我们的装袋算法!
以下是一个可以根据我们的需求训练任意数量决策树的代码:
def train_bagging_trees(df, target_col, pred_cols, n_trees):'''通过在自助采样数据上训练多个决策树来创建一个装袋决策树模型。输入:df (pandas DataFrame) : 包含目标列和输入列的训练数据target_col (str) : 目标列的名称pred_cols (list) : 预测列名称的列表n_trees (int) : 集成中要训练的树的数量输出:train_trees (list) : 训练好的树的列表'''train_trees = []for i in range(n_trees):# 自助采样训练数据temp_boot = bootstrap(train_df)# 训练树temp_tree = plain_vanilla_tree(temp_boot, target_col, pred_cols)# 将训练好的树保存到列表中train_trees.append(temp_tree)return train_treesdef bagging_trees_pred(df, train_trees, target_col, pred_cols):'''接受一个装袋树的列表,并通过对每棵单独树的预测结果进行平均来创建预测。输入:df (pandas DataFrame) : 包含目标列和输入列的训练数据train_trees (list) : 集成模型 - 即训练好的决策树列表target_col (str) : 目标列的名称pred_cols (list) : 预测列名称的列表输出:avg_preds (list) : 集成树的预测结果列表'''x = df[pred_cols]y = df[target_col]preds = []# 使用每棵决策树对数据进行预测for tree in train_trees:temp_pred = tree.predict(x)preds.append(temp_pred)# 获取树的预测结果的平均值sum_preds = [sum(x) for x in zip(*preds)]avg_preds = [x / len(train_trees) for x in sum_preds]return avg_preds
上面的函数非常简单,第一个函数用于训练装袋集成模型,第二个函数接受集成模型(简单来说就是一个训练好的树的列表),并根据给定的数据集进行预测。
代码准备好后,让我们运行多个集成模型,看看随着树的数量增加,我们的袋外预测(Out-of-bag Predictions)会发生怎样的变化。
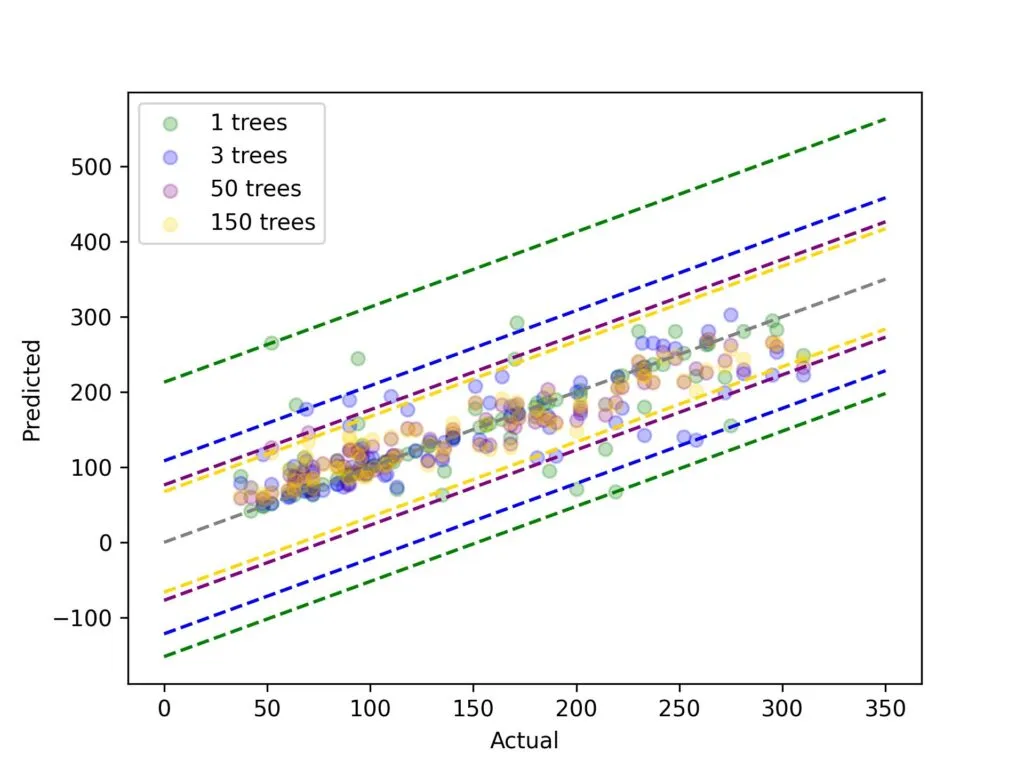
不得不承认,这个图表看起来有点复杂。不要过于纠结于每个单独的数据点,虚线才是关键!这里我们有一个基本的决策树模型和三个装袋决策树模型——分别包含3棵、50棵和150棵树。颜色编码的虚线标记了每个模型残差(Residuals)的上下范围。这里有两个主要的结论:(1) 随着树的数量增加,残差的范围会缩小;(2) 增加更多的树带来的收益会逐渐减少——当我们从1棵树增加到3棵树时,范围缩小了很多,但当我们从50棵树增加到150棵树时,范围只缩小了一点。
现在我们已经成功完成了一个完整的装袋法示例,接下来我们准备开始学习提升法(Boosting)!让我们快速回顾一下本节所涵盖的内容:
- 装袋法通过对多个单独模型的预测结果进行平均,降低了机器学习模型的方差。
- 装袋法对高方差模型最为有效。
- 装袋的模型越多,集成模型的方差就越低,但方差降低的收益会逐渐减少。
好了,让我们开始学习提升法吧!
提升法(Boosting):减少弱学习器的偏差
在装袋法中,我们创建多个独立的模型——模型的独立性有助于平均掉单个模型的噪声。提升法(Boosting)也是一种集成学习技术;与装袋法类似,我们也会训练多个模型……但与装袋法非常不同的是,我们训练的模型将是相互依赖的。提升法是一种建模技术,它首先训练一个初始模型,然后依次训练额外的模型,以改进先前模型的预测结果。提升法的主要目标是减少偏差——尽管它也可以帮助减少方差。
我们已经知道提升法可以迭代地改进预测结果,现在让我们深入了解它是如何做到的。提升算法可以通过两种方式迭代地改进模型的预测结果:
- 直接预测上一个模型的残差,并将其添加到先前的预测结果中——可以将其视为残差校正。
- 对上一个模型预测效果较差的观测值赋予更多的权重。
由于提升法的主要目标是减少偏差,因此它适用于通常具有较大偏差的基础模型(如浅决策树(Shallow Decision Trees))。在我们的示例中,我们将使用浅决策树作为基础模型——为了简洁起见,本文仅介绍残差预测方法。让我们开始提升法的示例吧!
预测先前的残差
残差预测方法从一个初始模型开始(有些算法提供一个常数,有些则使用基础模型的一次迭代结果),然后我们计算该初始预测的残差。集成中的第二个模型预测第一个模型的残差。有了残差预测后,我们将残差预测添加到初始预测中(这就得到了经过残差校正的预测结果),并重新计算更新后的残差……我们继续这个过程,直到创建出指定数量的基础模型。这个过程相当简单,但仅用文字解释有点困难——下面的流程图展示了一个简单的包含4个模型的提升算法。
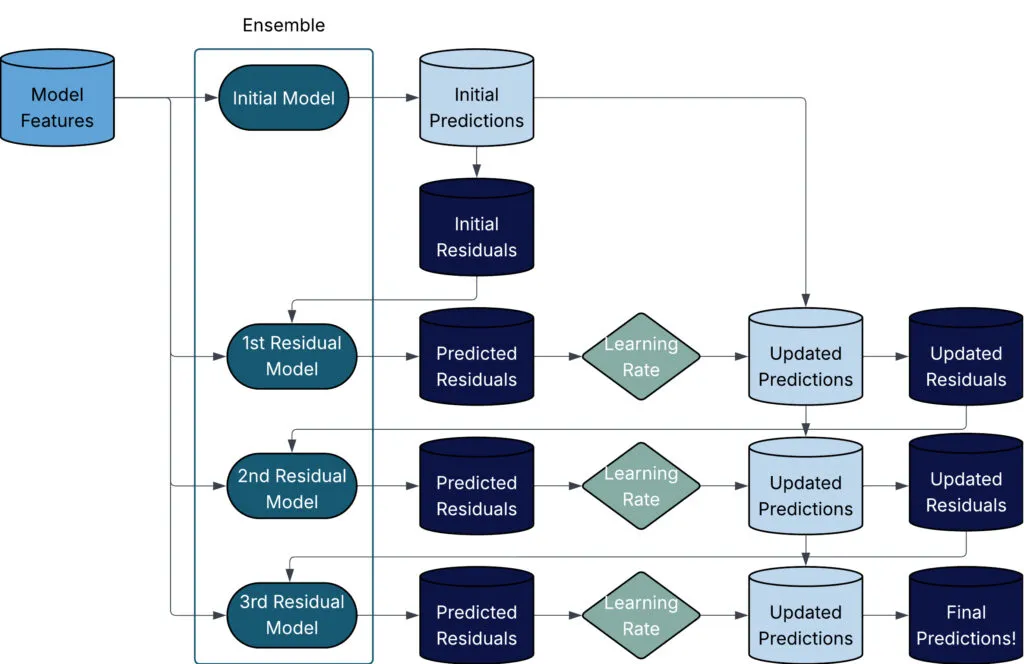
在进行提升法时,我们需要设置三个主要参数:(1) 树的数量,(2) 树的深度,(3) 学习率(Learning Rate)。现在让我们花点时间来讨论一下这些参数。
树的数量
对于提升法来说,树的数量与装袋法中的含义相同——即集成中要训练的树的总数。但与装袋法不同的是,我们不应该一味地增加树的数量!下面的图表展示了糖尿病数据集的测试均方根误差(RMSE)与树的数量之间的关系。

这表明,在大约200棵树之前,测试均方根误差随着树的数量增加而迅速下降,然后开始逐渐上升。这看起来像是一个典型的“过拟合”图表——我们达到了一个点,超过这个点后,增加更多的树对模型反而不利。这是装袋法和提升法之间的一个关键区别——在装袋法中,增加更多的树最终会不再有帮助,而在提升法中,增加更多的树最终会开始产生负面影响!
在装袋法中,增加更多的树最终会不再有帮助,而在提升法中,增加更多的树最终会开始产生负面影响!
我们现在知道,树的数量过多不好,过少也不好。我们将使用超参数调优(Hyperparameter Tuning)来选择树的数量。需要注意的是,超参数调优是一个非常大的主题,远远超出了本文的范围。稍后我将通过一个包含训练集和测试集的简单网格搜索(Grid Search)示例来进行演示。
树的深度
这是集成中每棵树的最大深度。在装袋法中,树通常可以长得尽可能深,因为我们需要的是低偏差、高方差的模型。然而,在提升法中,我们使用顺序模型来解决基础学习器的偏差问题,因此我们不太关心生成低偏差的树。那么我们如何确定最大深度呢?我们将使用与选择树的数量相同的技术——超参数调优。
学习率
树的数量和树的深度是我们在装袋法中熟悉的参数(尽管在装袋法中我们通常不会对树的深度进行限制)——但这个“学习率”是一个新面孔!让我们花点时间来了解一下。学习率是一个介于0和1之间的数字,在将当前模型的残差预测添加到总体预测之前,会将其乘以这个学习率。
下面是一个学习率为0.5时预测计算的简单示例。在理解了学习率的工作原理后,我们将讨论为什么学习率很重要。
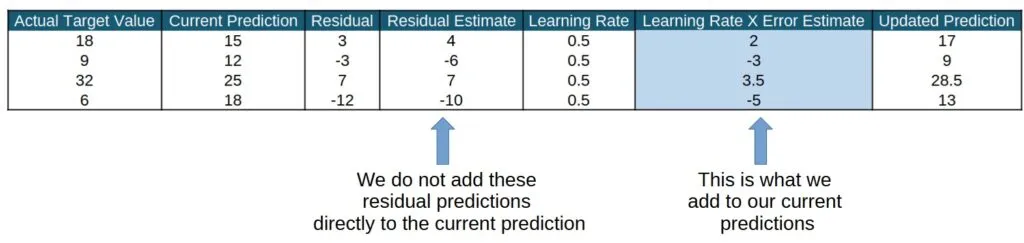
那么,为什么我们要对残差预测进行“折扣”处理呢?这样做不会使我们的预测结果变差吗?嗯,答案是有好有坏。对于单次迭代来说,这可能会使我们的预测结果变差——但我们进行的是多次迭代。在多次迭代中,学习率可以防止模型对单棵树的预测结果反应过度。它可能会使我们当前的预测结果变差,但不用担心,我们会多次进行这个过程!最终,学习率通过降低集成中任何单棵树的影响,有助于减轻提升模型的过拟合问题。你可以将其想象成慢慢转动方向盘来纠正驾驶方向,而不是猛地转动。实际上,树的数量和学习率之间存在相反的关系,即学习率降低时,树的数量需要增加。这是很直观的,因为如果我们只允许每棵树的残差预测的一小部分添加到总体预测中,那么在总体预测看起来良好之前,我们就需要更多的树。
最终,学习率通过降低集成中任何单棵树的影响,有助于减轻提升模型的过拟合问题。
好了,现在我们已经介绍了提升法中的主要参数,让我们开始编写Python代码吧!我们需要几个函数来实现提升算法:
- 基础决策树函数——一个简单的函数,用于创建和训练单棵决策树。我们将使用上一节中名为
plain_vanilla_tree的函数。 - 提升训练函数——这个函数会按照用户指定的数量依次训练决策树并更新残差。在我们的代码中,这个函数名为
boost_resid_correction。 - 提升预测函数——这个函数接受一系列提升模型,并进行最终的集成预测。我们将这个函数称为
boost_resid_correction_pred。
以下是用Python编写的函数:
# 与上一节相同的基础树函数
def plain_vanilla_tree(df_train,target_col,pred_cols,max_depth = 3,weights=[]):X_train = df_train[pred_cols]y_train = df_train[target_col]tree = DecisionTreeRegressor(max_depth = max_depth, random_state=42)if weights:tree.fit(X_train, y_train, sample_weights=weights)else:tree.fit(X_train, y_train)return tree# 残差预测
def boost_resid_correction(df_train,target_col,pred_cols,num_models,learning_rate=1,max_depth=3):'''创建提升决策树集成模型。输入:df_train (pd.DataFrame) : 包含训练数据target_col (str) : 目标列名称pred_cols (list) : 预测列名称列表num_models (int) : 提升过程中使用的模型数量learning_rate (float, 默认为1) : 对残差预测的折扣系数(取值范围:(0, 1])max_depth (int, 默认为3) : 每棵树模型的最大深度输出:boosting_model (dict) : 包含模型预测所需的所有信息(包括集成中的树列表)'''# 创建初始预测model1 = plain_vanilla_tree(df_train, target_col, pred_cols, max_depth = max_depth)initial_preds = model1.predict(df_train[pred_cols])df_train['resids'] = df_train[target_col] - initial_preds # 计算初始残差# 创建多个模型,每个模型预测更新后的残差models = []for i in range(num_models):temp_model = plain_vanilla_tree(df_train, 'resids', pred_cols) # 训练残差预测树models.append(temp_model)temp_pred_resids = temp_model.predict(df_train[pred_cols]) # 预测当前残差# 更新残差(学习率控制当前残差预测的贡献度)df_train['resids'] = df_train['resids'] - (learning_rate * temp_pred_resids)boosting_model = {'initial_model': model1, # 初始模型'models': models, # 残差预测模型列表'learning_rate': learning_rate, # 学习率'pred_cols': pred_cols # 预测列名称}return boosting_model# 该函数使用残差提升模型对数据进行评分
def boost_resid_correction_predict(df,boosting_models,chart = False):'''根据提升模型对数据集进行预测。输入:df (pd.DataFrame) : 待预测的数据boosting_models (dict) : 包含提升模型参数的字典chart (bool, 默认为False) : 是否生成性能图表输出:pred (np.array) : 提升模型的预测结果rmse (float) : 预测的均方根误差'''# 获取初始预测initial_model = boosting_models['initial_model']pred_cols = boosting_models['pred_cols']pred = initial_model.predict(df[pred_cols]) # 初始预测值# 计算每个模型的残差预测并累加(乘以学习率)models = boosting_models['models']learning_rate = boosting_models['learning_rate']for model in models:temp_resid_preds = model.predict(df[pred_cols])pred += learning_rate * temp_resid_preds # 残差校正if chart:plt.scatter(df['target'], pred) # 绘制实际值与预测值散点图plt.show()rmse = np.sqrt(mean_squared_error(df['target'], pred)) # 计算均方根误差return pred, rmse太棒了,我们在装袋法部分使用的糖尿病数据集上训练一个模型。我们将进行快速网格搜索(同样,这里不进行复杂的调优)来调整三个参数,然后使用boost_resid_correction函数训练最终模型。
# 网格搜索调参
n_trees = [5, 10, 30, 50, 100, 125, 150, 200, 250, 300]
learning_rates = [0.001, 0.01, 0.1, 0.25, 0.50, 0.75, 0.95, 1]
max_depths = list(range(1, 16)) # 生成1到15的深度列表# 创建字典保存每个网格点的测试RMSE
perf_dict = {}
for tree in n_trees:for learning_rate in learning_rates:for max_depth in max_depths:# 训练提升模型temp_boosted_model = boost_resid_correction(train_df,'target',pred_cols,tree,learning_rate=learning_rate,max_depth=max_depth)temp_boosted_model['target_col'] = 'target'# 在测试集上预测并计算RMSEpreds, rmse = boost_resid_correction_predict(test_df, temp_boosted_model)# 生成字典键(参数组合字符串)dict_key = '_'.join(str(x) for x in [tree, learning_rate, max_depth])perf_dict[dict_key] = rmse# 找到RMSE最小的参数组合
min_key = min(perf_dict, key=perf_dict.get)
print(perf_dict[min_key]) # 输出最小RMSE值
我们的获胜者是 🥁 ——50棵树、学习率0.1和最大深度1!让我们看看预测效果如何。
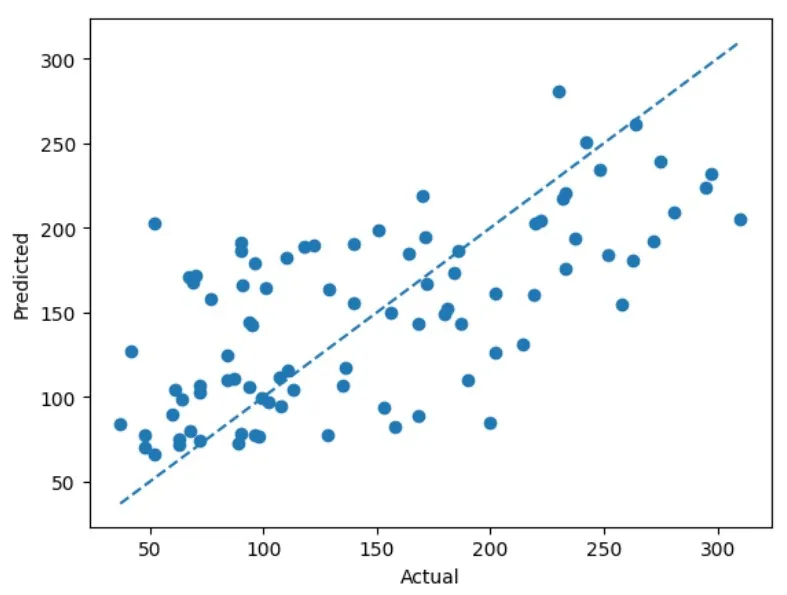
虽然我们的提升集成模型似乎合理捕捉了趋势,但直观来看其预测效果不如装袋模型。我们可能需要更多时间调优——但也有可能是装袋法更适合该特定数据集。至此,我们已理解装袋法和提升法的核心原理,接下来进行对比总结:
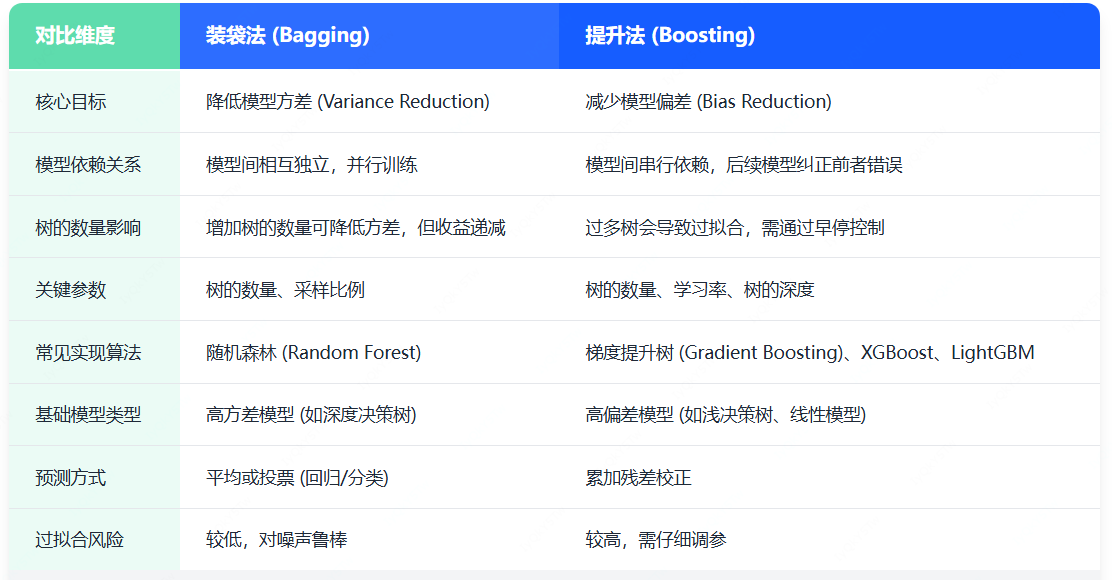
装袋法 vs. 提升法——核心差异解析
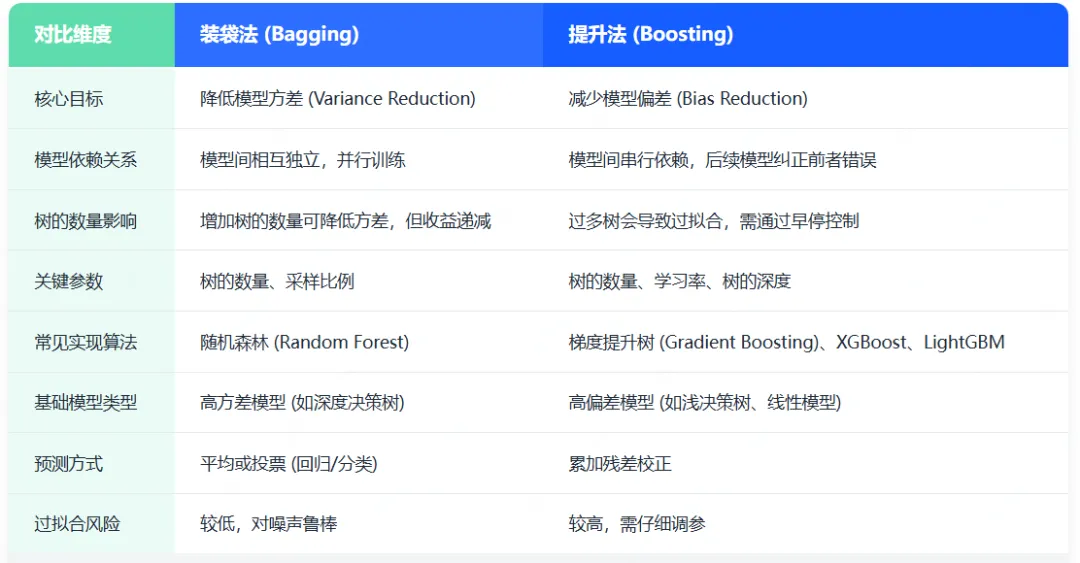
我们已分别介绍了装袋法和提升法,下表总结了两者的关键区别:
注意:本文为教学目的编写了自定义装袋和提升代码,实际应用中应直接使用Python库(如scikit-learn)中的成熟实现。此外,纯装袋法或提升法很少单独使用,更常见的是采用改进后的高级算法(如随机森林、XGBoost)来优化性能。
总结
装袋法和提升法是改进弱学习器(如灵活的决策树)的强大实用技术。两者均通过集成学习解决不同问题——装袋法降低方差,提升法减少偏差。实际中,几乎总是使用预封装代码来训练结合装袋/提升思想并经过多重优化的高级机器学习模型。