阿里千问系列:Qwen3技术报告解读(下)

技术报告下载链接:Qwen3 Technical Report
Github链接:https://github.com/QwenLM/Qwen3
书接上文:阿里千问系列:Qwen3技术报告解读(上),本文主要来细挖Qwen3最核心的预训练和后训练方法,同时来看看Qwen3不同模型的实验表现。
预训练 (Pre-training)
(1)预训练数据
Qwen3 的预训练数据在规模、多样性和质量上实现了显著突破,为模型的多语言能力和复杂任务处理奠定了基础。具体表现为:
-
规模与覆盖范围:
- 预训练数据总量达36 万亿 token,较 Qwen2.5 翻倍,覆盖119 种语言和方言(Qwen2.5 仅 29 种),涵盖编码、STEM、推理、多语言文本等多领域,显著提升跨语言泛化能力。
- 通过多模态方法扩展数据:利用 Qwen2.5-VL 从 PDF 文档提取文本,结合 Qwen2.5 系列模型(如 Math、Coder)生成合成数据(如教科书、代码片段),补充数万亿高质量 token。
-
数据质量优化:
- 采用两阶段过滤流程:首先通过 Qwen2.5-72B-Instruct 过滤掉不可验证或无需推理的查询,确保数据复杂度;然后人工评估候选响应,移除错误、重复或低质量内容,保留高质量推理样本。
- 开发多语言数据标注系统:对 30 万亿 token 进行教育价值、领域、安全性等多维度标注,支持实例级数据混合优化,通过消融实验在小模型上验证数据组合有效性,避免传统领域级混合的局限性。
-
多语言增强:
- 新增语言覆盖包括阿拉伯语、印地语、斯瓦希里语等稀有语种,提升模型在低资源语言中的表现。
- 通过翻译任务和区域知识数据集(如 INCLUDE)强化跨语言理解,为后续多语言基准测试(如 MT-AIME24、PolyMath)的优异表现提供支撑。
关键意义:数据规模的扩大与精细标注确保模型能捕捉更广泛的语言模式和领域知识,多模态数据生成与实例级优化则提升了数据的针对性和有效性,为模型在推理、编码、多语言任务中的领先性能提供了底层支撑。
(2)预训练阶段
Qwen3 的预训练采用三阶段渐进式策略,逐步强化通用能力、推理能力和长上下文处理,结合架构优化实现效率与性能的平衡。具体阶段如下:
-
通用阶段(S1):
-
目标:构建语言理解能力与通用世界知识。
-
数据与配置:使用 30 万亿 token 训练,覆盖 119 种语言,序列长度 4096 token。
-
效果:模型掌握基础语言能力和世界知识,为后续阶段提供泛化能力底座。
-
-
推理阶段(S2):
- 目标:提升 STEM、编码和推理能力。
- 数据与配置:引入 5 万亿高质量知识密集型数据(如科学论文、代码库),加速学习率衰减以聚焦专业领域优化。
- 技术要点:通过增加 STEM 和编码数据比例(如数学问题、算法示例),强化模型逻辑推理和结构化思维,为数学基准(如 MATH、GSM8K)和编码任务(如 HumanEval)的高表现埋下伏笔。
-
长上下文阶段:
- 目标:扩展上下文长度至 32768 token,支持长文本理解与生成。
- 数据与配置:使用数百亿长文本 token(75% 长度 16K-32K,25% 长度 4K-16K),结合技术优化提升序列处理能力。
- 技术要点:
- 采用ABF 技术将 RoPE 基础频率从 10,000 提升至 1,000,000,增强位置编码对长序列的适应性。
- 引入YARN 和双块注意力(DCA),在推理时将序列长度容量提升四倍,确保长上下文下的稳定性和效率。
关键意义:三阶段训练逐层递进,从通用能力到专业推理再到长上下文,系统性提升模型的综合性能。长上下文技术的引入使 Qwen3 能处理复杂文档(如学术论文、代码库),而推理阶段的专项优化则使其在数学和编码任务中超越同类开源模型,体现了预训练策略的针对性和有效性。
(3)预训练评估
Qwen3 基础模型在多领域基准测试中表现优异,尤其在推理、编码和多语言任务中展现出开源领先性,且模型效率显著优于前代和同类产品。
-
评估基准与对比设置:
- 任务覆盖:涵盖通用知识(MMLU)、数学推理(MATH、AIME)、编码(EvalPlus、MultiPL-E)、多语言(MGSM、MMMLU)等 15 个基准,覆盖 5 大类任务。
- 基线模型:包括 Qwen2.5 系列、DeepSeek-V3 Base、Llama-4、Gemma-3 等开源模型,部分任务对比闭源模型(如 GPT-4o)。
-
关键结论:
-
旗舰模型 Qwen3-235B-A22B-Base:
- 作为 MoE 模型(235B 总参数,22B 激活参数),在多数基准中超越 DeepSeek-V3 Base、Llama-4-Maverick 等开源模型,甚至以更少参数接近闭源模型(如 GPT-4o)。
- MoE 架构效率显著:仅用 Qwen2.5-72B-Base(密集型)1/3 的激活参数,性能全面超越,且推理成本更低。
-
密集型模型 Qwen3-32B-Base:
- 参数 32B,性能接近 Qwen2.5-72B-Base(72B 参数),在编码任务(EvalPlus 72.05 vs. Qwen2.5-72B 的 65.93)和推理任务(MMLU-Pro 65.54 vs. 58.07)中显著领先,体现 “小参数大能力” 的优化效果。
-
轻量级模型(14B 及以下):
- Qwen3-14B/8B/4B 等模型在多数基准中超越同参数规模的 Qwen2.5 模型,甚至优于更大规模旧模型。例如,Qwen3-1.7B 在 MGSM 多语言任务中得分 50.71,远超 Qwen2.5-1.5B 的 32.82。
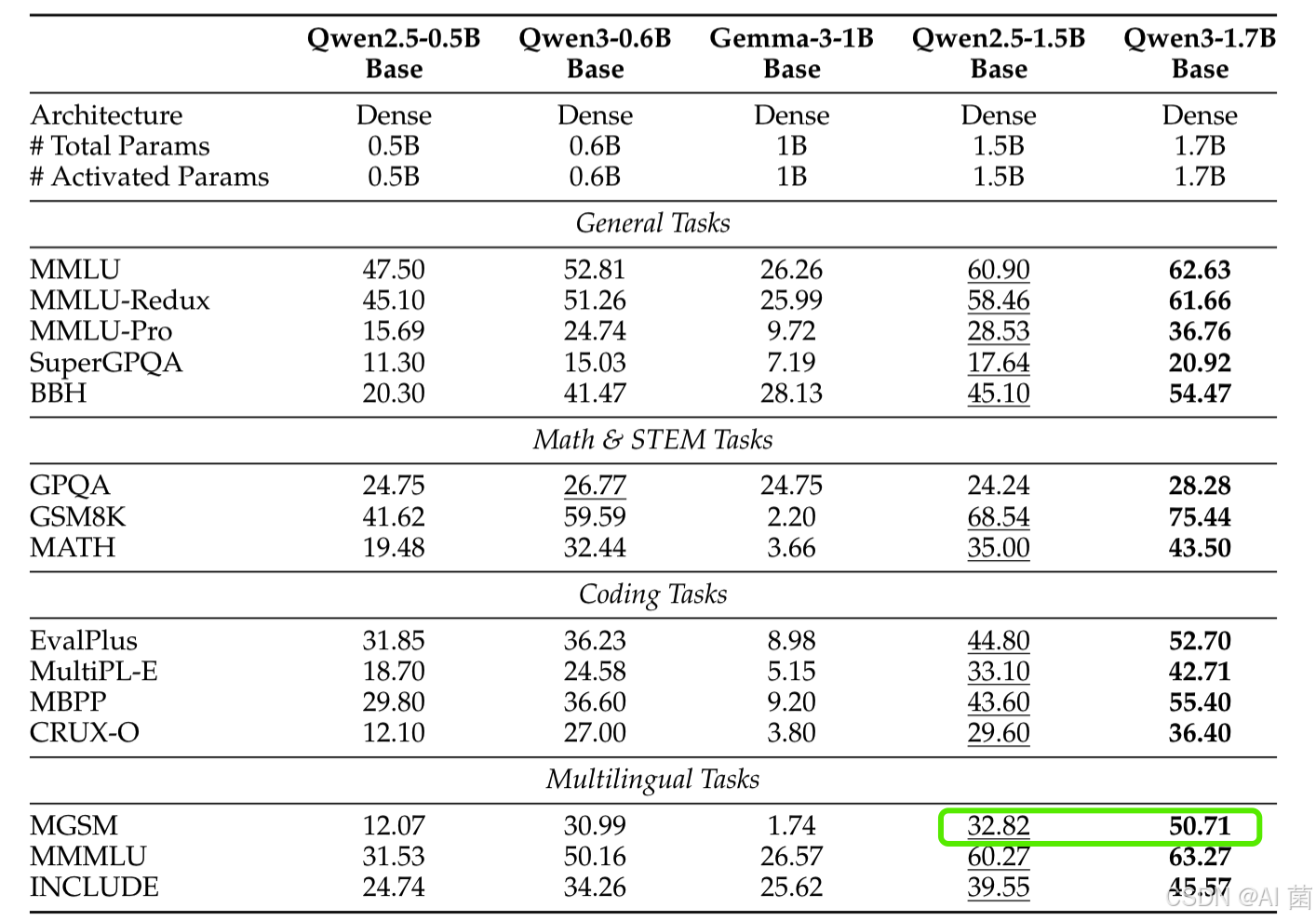
- Qwen3-14B/8B/4B 等模型在多数基准中超越同参数规模的 Qwen2.5 模型,甚至优于更大规模旧模型。例如,Qwen3-1.7B 在 MGSM 多语言任务中得分 50.71,远超 Qwen2.5-1.5B 的 32.82。
-
关键意义:预训练评估验证了 Qwen3 在模型效率(MoE 激活参数更少)、任务覆盖(通用 + 专业领域)和多语言支持上的全面提升,为后训练阶段(如推理 RL、模式融合)的进一步优化提供了坚实基础,也证明其作为开源 SOTA 模型的竞争力。
后训练 (Post-training)
Qwen3 的后训练流程围绕两个核心目标进行战略性设计:
(1)推理控制:整合 “非思考” 和 “思考” 两种模式,使用户能够灵活选择模型是否进行推理,并通过为思考过程指定 token 预算来控制思考深度。
(2)强弱蒸馏:旨在精简和优化轻量级模型的后训练流程。通过利用大规模模型的知识,大幅降低构建小规模模型所需的计算成本和开发工作量。这种方法无需为每个小规模模型单独执行详尽的四阶段训练流程,将教师模型的输出对数概率直接蒸馏到轻量级学生模型中,所需训练耗时仅为四阶段训练方法第1/10。
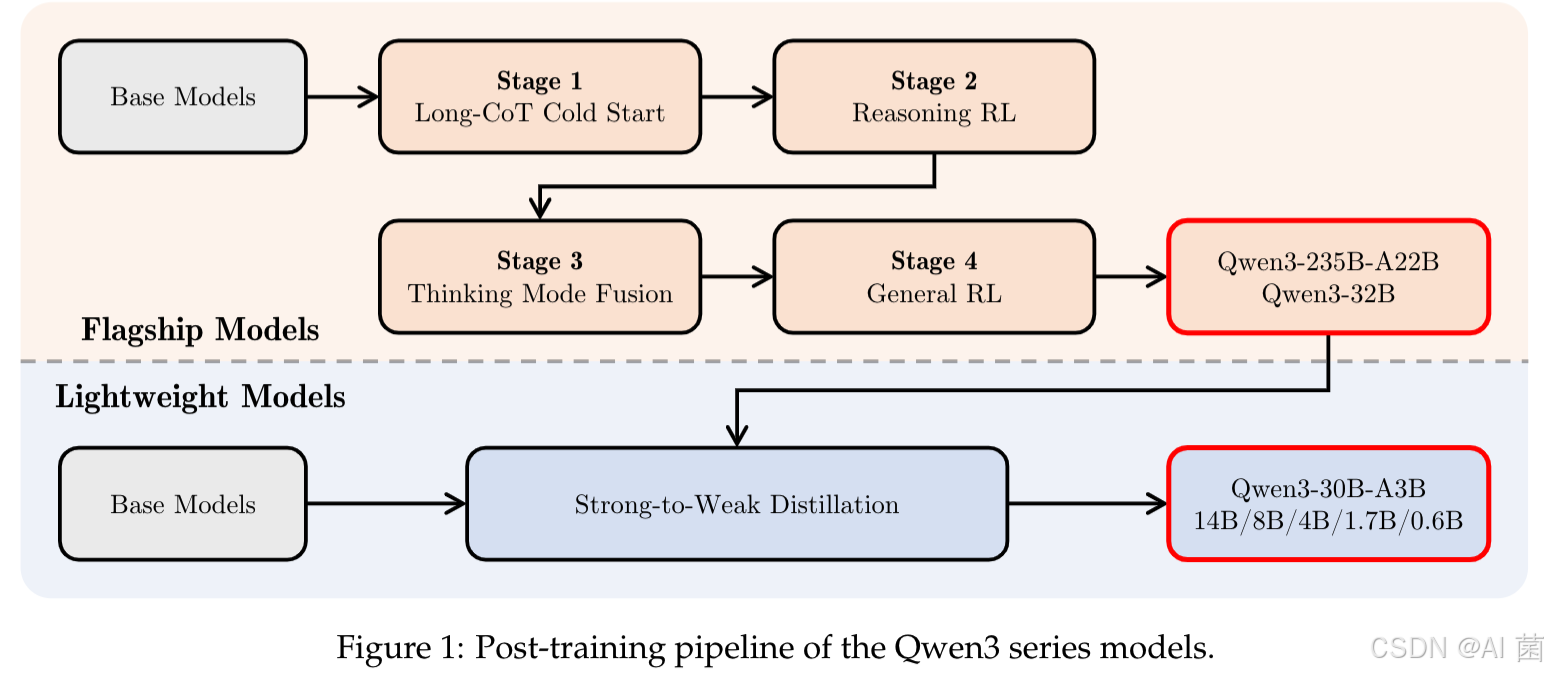
(1)长思维链冷启动
长思维链冷启动是 Qwen3 后训练的初始阶段,旨在为模型注入基础推理能力,建立复杂问题分解的思维模式。具体实施包括:
-
数据集构建:
- 收集数学、代码、逻辑推理等领域的复杂问题,每个问题附带验证答案或代码测试用例,形成初始训练集。
- 通过两阶段过滤确保数据质量:
- 查询过滤:使用 Qwen2.5-72B-Instruct 排除简单问题(如无需推理的通用文本生成),保留需多步思考的复杂查询(如数学竞赛题、逻辑谜题)。
- 响应过滤:通过 QwQ-32B 生成候选答案,人工剔除错误答案、重复内容或猜测性推理,确保留存高质量思维链。
-
训练目标与策略:
- 核心目标:使模型掌握基础推理流程,而非追求即时性能峰值,为后续强化学习阶段预留优化空间。
- 轻量化训练:采用最小化训练样本和步骤,避免过拟合,重点培养模型 “先分解问题、再逐步推理” 的思维习惯。例如,通过少量典型案例引导模型生成结构化思考路径(如数学题的分步解析)。
-
领域平衡与标注:
- 使用 Qwen2.5-72B-Instruct 对查询进行领域标注(如代数、算法、逻辑),确保训练数据在各领域均衡分布,避免模型偏向单一任务类型。
关键意义:为模型奠定了推理的 “思维框架”,避免直接进入强化学习时因缺乏基础推理模式而导致的优化低效。此阶段生成的高质量思维链数据,为后续推理 RL 提供了可靠的初始训练信号,是 Qwen3 实现复杂推理能力的基石。
(2)推理强化学习
推理强化学习(RL)阶段通过挑战性数据和动态奖励机制,系统性提升模型的推理精度和深度,是 Qwen3 从 “基础推理” 迈向 “高效推理” 的关键环节。
-
数据与标准:
- 数据筛选:使用冷启动阶段未涉及的、难度更高的查询 - 验证对(共 3,995 对),覆盖数学、编码、逻辑等领域,确保模型面对未知复杂任务时的泛化能力。
- 四大标准:数据需满足 “未冷启动使用、可学习性、高挑战性、领域多样性”,避免模型重复学习已知模式。
-
训练技术与优化:
- 算法选择:采用 GRPO(广义策略优化)算法更新模型参数,结合大批次和高滚动次数(rollouts)提升样本效率,减少训练方差。
- 探索与利用平衡:通过控制模型输出的熵值(entropy),确保训练初期充分探索多种推理路径,后期稳定收敛至高效策略,避免陷入局部最优。
-
性能提升案例:
- 在 AIME’24 数学竞赛基准中,Qwen3-235B-A22B 模型通过 170 步 RL 训练,分数从 70.1 提升至 85.1,体现推理能力的显著提升。
- 训练过程中奖励信号与验证性能同步增长,无需人工调整超参数,证明了 RL 策略的自适应性和稳定性。
关键意义:推理 RL 阶段通过 “难数据 + 强优化” 的组合,迫使模型突破冷启动阶段的基础能力,学会在高复杂度任务中动态调整推理深度。此阶段引入的挑战型数据和熵控制策略,不仅提升了模型的推理准确率,还增强了其在开放场景下的探索能力,为后续模式融合和通用 RL 提供了强大的推理内核。
(3)思考模式融合
思考模式融合阶段致力于将 “思考模式” 与 “非思考模式” 整合至单一模型,实现动态任务适配,同时降低多模型部署成本。核心进展包括:
-
双模式整合技术:
- 聊天模板设计:通过在用户查询中引入
/think(思考模式)和/no_think(非思考模式)标记,指示模型切换行为。例如,用户输入 “请用 /think 详细推导数学公式” 时,模型生成分步推理;输入 “/no_think 推荐一本书” 时,直接返回结果。 - 内部格式统一:非思考模式响应中保留空思考块(如
<|FunctionCallBegin|>...<|FunctionCallEnd|>),确保模型输出结构一致,便于开发者通过模板控制推理行为(如强制插入空块禁用思考)。
- 聊天模板设计:通过在用户查询中引入
-
数据与训练策略:
- 混合数据集:结合 “思考数据”(带思维链的复杂问题)和 “非思考数据”(指令遵循、闲聊等),通过拒绝采样确保思考数据质量不受非思考数据稀释。
- 多语言增强:增加翻译任务比例,提升低资源语言下的模式切换稳定性,例如在印尼语、斯瓦希里语中正确识别
/think标记并触发推理。
-
思考预算机制:
- 动态停止推理:当思考长度达到用户设定的 token 阈值(如 8192 token),模型自动插入停止指令 “基于现有思考给出答案”,平衡推理深度与响应延迟。
- 能力涌现:预算控制能力无需显式训练,而是模式融合的副产品,体现模型对 “思考进度” 的自我监控能力。
关键意义:模式融合使 Qwen3 摆脱了 “专用推理模型与对话模型分离” 的传统架构,实现 “一个模型应对多元场景”。思考预算机制则赋予用户细粒度控制能力,例如在实时对话中使用非思考模式快速响应,在学术研究中使用长预算深度推理,提升了模型的实用性和灵活性。
(4)通用强化学习
通用强化学习(RL)阶段聚焦模型在多场景下的综合能力提升,通过多元化奖励信号优化指令遵循、格式对齐、代理工具调用等通用技能,确保模型在真实世界中的可靠性。
-
奖励系统设计:
- 规则奖励:针对指令遵循(如格式要求)和安全合规性,通过预定义规则直接评估输出正确性,防止 “奖励欺骗”(如生成看似合理但实际错误的内容)。
- 模型奖励(带参考):使用 Qwen2.5-72B-Instruct 对开放式问题(如创意写作)的响应打分,基于参考答案提升内容相关性。
- 模型奖励(无参考):通过人类偏好数据训练奖励模型,评估响应的吸引力和帮助性,优化闲聊、角色扮演等主观任务。
-
能力扩展:
- 代理工具调用:训练模型通过指定接口调用外部工具(如计算器、知识库),在 RL 滚动中结合环境反馈优化多轮交互策略,例如在代码调试任务中自动调用编译器验证结果。
- 长周期任务:在 RAG(检索增强生成)场景中,通过奖励信号引导模型优先使用检索信息而非虚构内容,降低幻觉风险。
-
多任务平衡:
- 在提升通用能力的同时,通过保留部分思考模式数据,避免模型在数学、编码等专业任务上的性能退化。例如,在训练中混合 20% 的推理任务数据,维持推理能力基线。
关键意义:通用 RL 阶段使 Qwen3 从 “专项推理模型” 升级为 “全场景智能助手”,其多元化奖励系统确保模型在指令严格性(如 JSON 格式生成)和用户体验(如自然语言流畅度)之间取得平衡。代理能力的强化则为构建复杂 AI 应用(如编程辅助、多语言客服)提供了底层支持,拓展了模型的实际应用边界。
(5)强弱蒸馏
强弱蒸馏是 Qwen3 轻量级模型(如 0.6B-14B)的核心优化技术,通过迁移旗舰模型的知识,在大幅降低计算成本的同时保留高性能,实现 “小模型,大能力”。
-
两阶段蒸馏流程:
- 离线策略蒸馏(Off-policy Distillation):
- 使用 Qwen3-235B-A22B 或 Qwen3-32B 作为教师模型,生成带
/think和/no_think标记的响应数据。 - 学生模型(如 Qwen3-8B)直接学习教师模型的输出分布(logits),快速获取推理模式切换能力和基础响应质量。
- 使用 Qwen3-235B-A22B 或 Qwen3-32B 作为教师模型,生成带
- 在线策略蒸馏(On-policy Distillation):
- 学生模型自主生成响应,通过 KL 散度损失与教师模型对齐,优化实时推理时的策略选择(如判断何时触发思考模式)。
- 离线策略蒸馏(Off-policy Distillation):
-
效率与性能平衡:
- 计算成本优势:相较于传统 RL 训练,蒸馏仅需 1/10 的 GPU 小时。例如,Qwen3-8B 通过蒸馏在 AIME’24 中达到 76.0 分,而 RL 需 17,920 小时 GPU 训练,蒸馏仅需 1,800 小时。
- 性能保持:蒸馏后的轻量级模型在多数基准中接近教师模型表现。例如,Qwen3-14B 在 MMLU-Redux 中得分 83.41,与 Qwen3-32B 的 87.40 差距较小,但参数仅为 1/2。
-
模式切换能力传承:
- 教师模型的动态模式切换能力通过蒸馏传递给学生模型。例如,Qwen3-4B 在 Multi-IF 多语言指令任务中,能根据语言类型自动选择思考深度(如阿拉伯语数学题触发长思考,英语闲聊使用非思考模式)。
关键意义:强弱蒸馏解决了轻量级模型 “性能与成本不可兼得” 的难题,使 Qwen3 系列小模型既能在边缘设备高效运行,又能保持接近大模型的推理能力。此技术尤其适用于资源受限场景(如移动端、嵌入式系统),推动了高性能 LLM 的普及和落地。
(6)后训练评估
后训练评估全面验证了 Qwen3 在思考 / 非思考模式下的任务表现,覆盖通用知识、推理、编码、多语言等维度,证明其作为开源 SOTA 模型的综合实力。
-
评估维度与方法:
- 任务覆盖:
- 通用任务:MMLU-Redux、C-Eval;
- 推理任务:AIME’24/’25、AutoLogi;
- 编码任务:BFCL v3、LiveCodeBench v5;
- 多语言任务:MT-AIME24(55 语言)、PolyMath(18 语言)。
- 模式区分:分别测试思考模式(高推理需求)和非思考模式(快速响应),参数设置差异(如温度、top-p)模拟真实使用场景。
- 任务覆盖:
-
关键性能亮点:
- 旗舰模型 Qwen3-235B-A22B:
- 思考模式下,AIME’24 得分 85.7,超越 DeepSeek-R1(79.8),接近 Grok-3-Beta (Think)(92.0);
- 非思考模式下,CodeForces 评级 2056(98.2% percentile),超越 GPT-4o(864)和 Qwen2.5-72B,证明其无需深度推理即可处理复杂编码任务。
- 轻量级模型 Qwen3-32B:
- 思考模式下,MMLU-Pro 得分 65.54,超越 Qwen2.5-72B(58.07);
- 非思考模式下,Creative Writing v3 得分 78.3,优于 Qwen2.5-72B(61.8),体现均衡能力。
- 旗舰模型 Qwen3-235B-A22B:
-
多语言表现:
- 在 MT-AIME24(多语言数学)中,Qwen3-235B-A22B 得分 80.8,超越其他主流模型;在 INCLUDE(44 语言知识)中得分 78.7,展现区域知识的广泛覆盖。
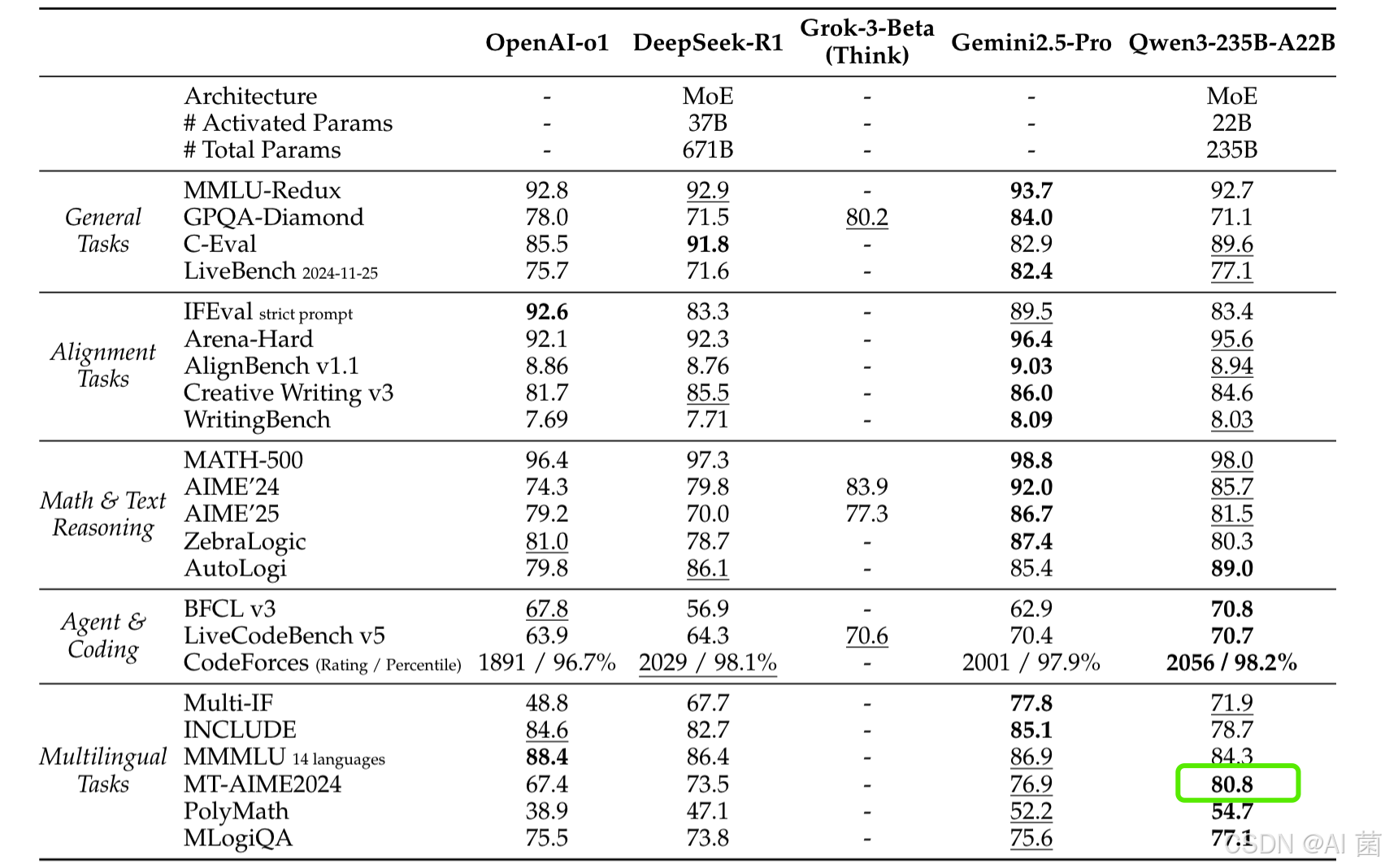
- 在 MT-AIME24(多语言数学)中,Qwen3-235B-A22B 得分 80.8,超越其他主流模型;在 INCLUDE(44 语言知识)中得分 78.7,展现区域知识的广泛覆盖。
关键意义:后训练评估不仅验证了 Qwen3 在推理和编码等 “硬任务” 上的领先性,还揭示其在多语言、创意写作等 “软任务” 中的进步。思考与非思考模式的差异化优化,使模型能根据任务特性动态调整策略,标志着 Qwen3 向 “通用型 AGI 基础模型” 迈出了重要一步。
总结
预训练的大规模数据与三阶段训练策略赋予 Qwen3 强大的基础能力,后训练的双模式整合和蒸馏技术则使其适用于多样化场景,成为高效通用的开源大模型。