Python-多线程编程(threading 模块)
目录
- 一、Linux 下查看线程
- 二、Ubuntu 修改内核数量
- 三、线程的生命周期和属性
- 四、创建和使用 Thread 类
- 1. 创建和使用 threading.Thread
- 2. 主线程结束时间晚于子线程
- 3. 重写 run 方法
- 4. 全局解释器锁 GIL
- 五、线程共享全局变量
- 1. 共享全局变量的示例代码
- 2. 共享全局变量可能出现的问题
- 六、线程同步(线程锁)
- 1. 使用互斥锁线程操作
- 2. 上锁 / 解锁过程
- 七、死锁
- 1. 死锁的概念
- 2. 避免死锁的方法
- 八、threading 模块的高级用法
- 九、多任务版 UDP 聊天器
参考文章:【Python 多线程 | 菜鸟教程】
threading 模块是 Python 中用于实现多线程编程的核心模块,它在低层级的 thread 模块之上构造了高层级的线程接口。在 Python 中,线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,一个进程可以有多个线程,即多线程。多线程编程允许程序同时执行多个任务,提高了程序的执行效率和响应速度。
一、Linux 下查看线程
/proc 文件系统是 Linux 中一个特殊的虚拟文件系统,它不存储在硬盘上,而是在内存中动态生成。它为用户空间提供了一个接口,通过这个接口可以访问内核空间的数据结构和信息,即 /proc 文件系统中的文件和目录提供了系统和进程的详细信息。
例如,每个进程都有一个以其 PID 命名的目录,其中包含了该进程的各种详细信息。除了进程信息,/proc 还包含了许多其他有用的文件,如:
-
cpuinfo :提供处理器的类型和速度信息。
-
modules :列出当前加载到内核中的模块。
-
meminfo :显示物理内存、交换空间等信息。
-
version :显示当前运行的内核版本。
这些文件通常是只读的,但有些文件也可以写入,从而改变内核的行为。例如,通过写入某些配置文件,可以动态地更改内核参数。
我们可以通过 cd /proc 和 ls 命令查看 /proc 文件下的以 PID 命名的目录和其他一些文件:
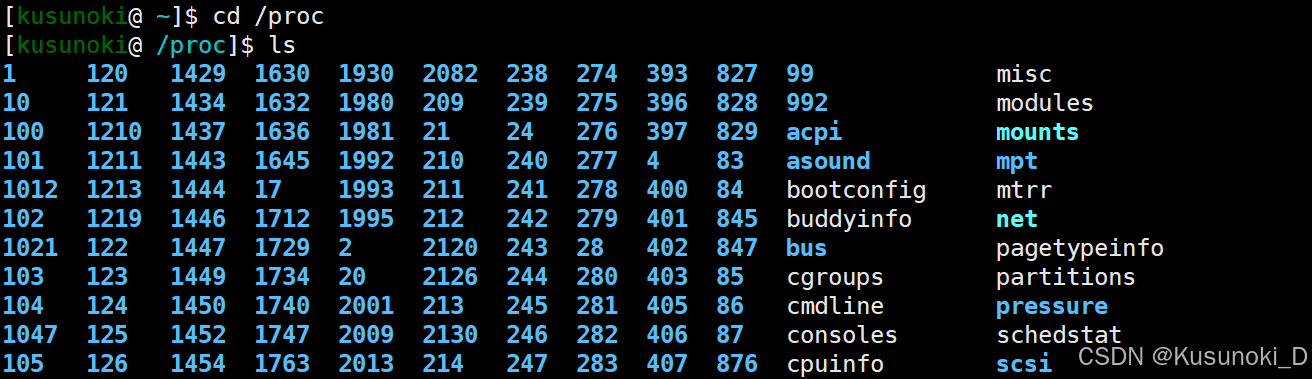
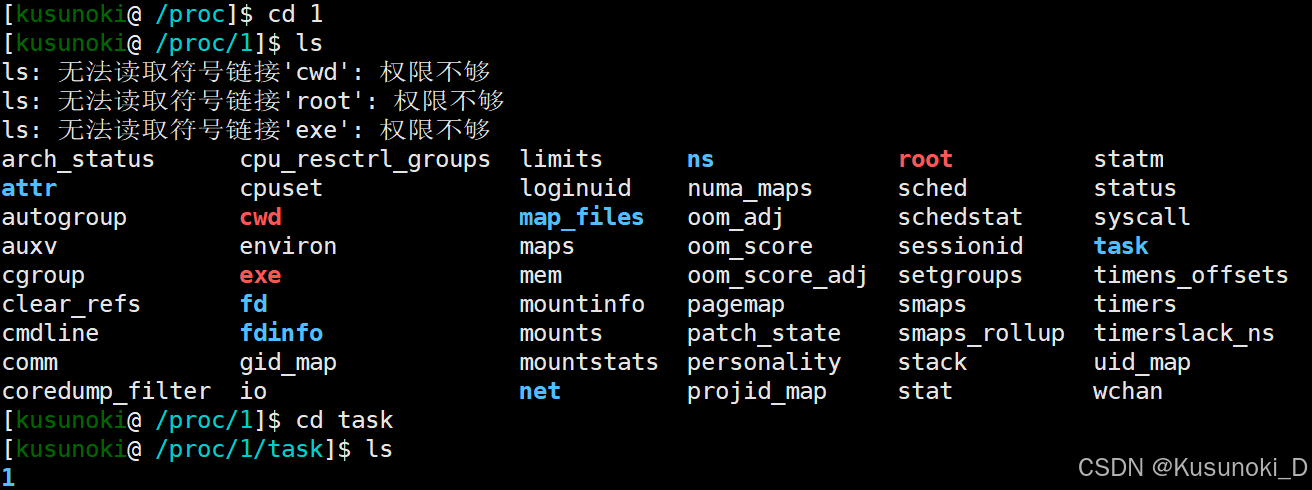
然后通过 cd [PID] 和 ls 命令查看指定 PID 的进程目录下的文件,再通过 cd task 和 ls 命令查看该进程中的每一个线程,每一个目录的名字是以线程 ID 命名的(TID)。
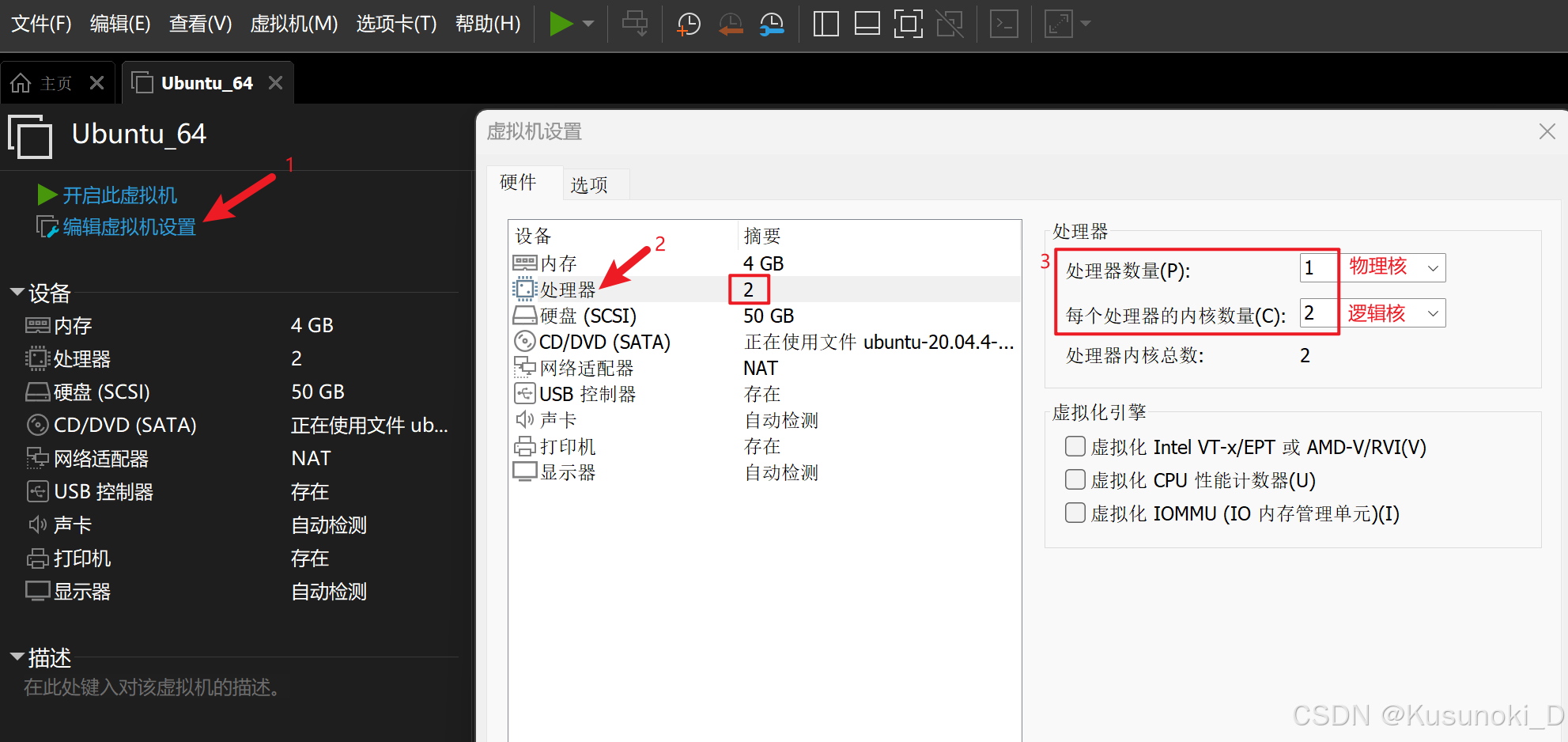
二、Ubuntu 修改内核数量
进入 VMware Workstation Pro ,打开 Ubuntu 虚拟机,点击 “编辑虚拟机设置” → “硬件” → “处理器” ,将处理器数量设置为 1 、每个处理器的内核数量设置为 2 ,最后点击 “确定” 即可。
三、线程的生命周期和属性
线程的生命周期包括创建、启动、运行、阻塞和死亡。线程 threading 模块提供了 Thread 类来处理线程,Thread 类提供了以下方法:
-
threading.Thread.run():用以表示线程活动的方法。 -
threading.Thread.start():启动线程活动。 -
threading.Thread.join([timeout]):timeout 参数可选,表示等待的时间(单位为秒)。- 如果设置了 timeout 参数,主线程最多等待子线程执行 timeout 秒,超时后无论子线程是否执行完都会继续执行主线程;
- 如果不设置 timeout 参数,则主线程会一直等待子线程执行完毕。
-
threading.Thread.is_alive():返回线程是否还在运行。
线程对象具有 name 属性,表示线程的名称,可以在构造方法中赋值。
-
threading.Thread.getName():返回线程名。 -
threading.Thread.setName():设置线程名。 -
线程的
threading.Thread.daemon属性决定了线程是否是守护线程,守护线程会在主线程结束时自动终止。
线程 threading 模块提供了以下方法:
-
threading.enumerate():返回一个包含正在运行的线程的 list ,正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 -
threading.active_count():返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。 -
threading.current_thread():返回当前的线程变量。 -
threading.get_ident():获取当前线程 ID 的方法,该方法返回当前线程的唯一标识符。
【拓展】:
1、Linux 下查看系统中所有 Python 进程及其线程的详细信息,使用命令:ps -elLf|grep python
2、Linux 下使用top命令显示系统性能信息和进程信息时,可以按 H 来查看线程
3、线程的优点:启动速度快,上下文切换的速度快
4、线程的缺点:线程任何一个挂掉,整个进程都会结束(Python 一个线程崩溃,其他的线程是正常的)
四、创建和使用 Thread 类
Python 的 thread 模块和 threading 模块都可以用来创建和管理线程,但 thread 模块只提供了基本的线程和锁支持,而 threading 模块提供了更加完全和高级的线程管理。
在 threading 模块中,最核心的类是 Thread ,创建一个 Thread 对象后,可以通过调用其 start() 方法来启动线程,使其执行目标函数。每个 Thread 对象代表一个线程,可以在每个线程中处理不同的任务。
1. 创建和使用 threading.Thread
Python 代码示例如下:
# !/usr/bin/python
# -*- coding:utf-8 -*-import time
import threadingdef say_morning():print("good morning!")time.sleep(1)if __name__ == "__main__":for i in range(5):# say_morning()t = threading.Thread(target=say_morning)t.start() # 启动线程,即让线程开始执行
-
在上述代码中,say_morning 函数被作为目标函数传递给 Thread 对象,然后通过 start() 方法启动线程,主线程和子线程将同时运行,互不干扰。
-
当调用 start() 函数时,才会真正的创建线程,并且开始执行。
-
可以明显看出使用了多线程并发(GIL 锁)的操作,花费时间要短很多。
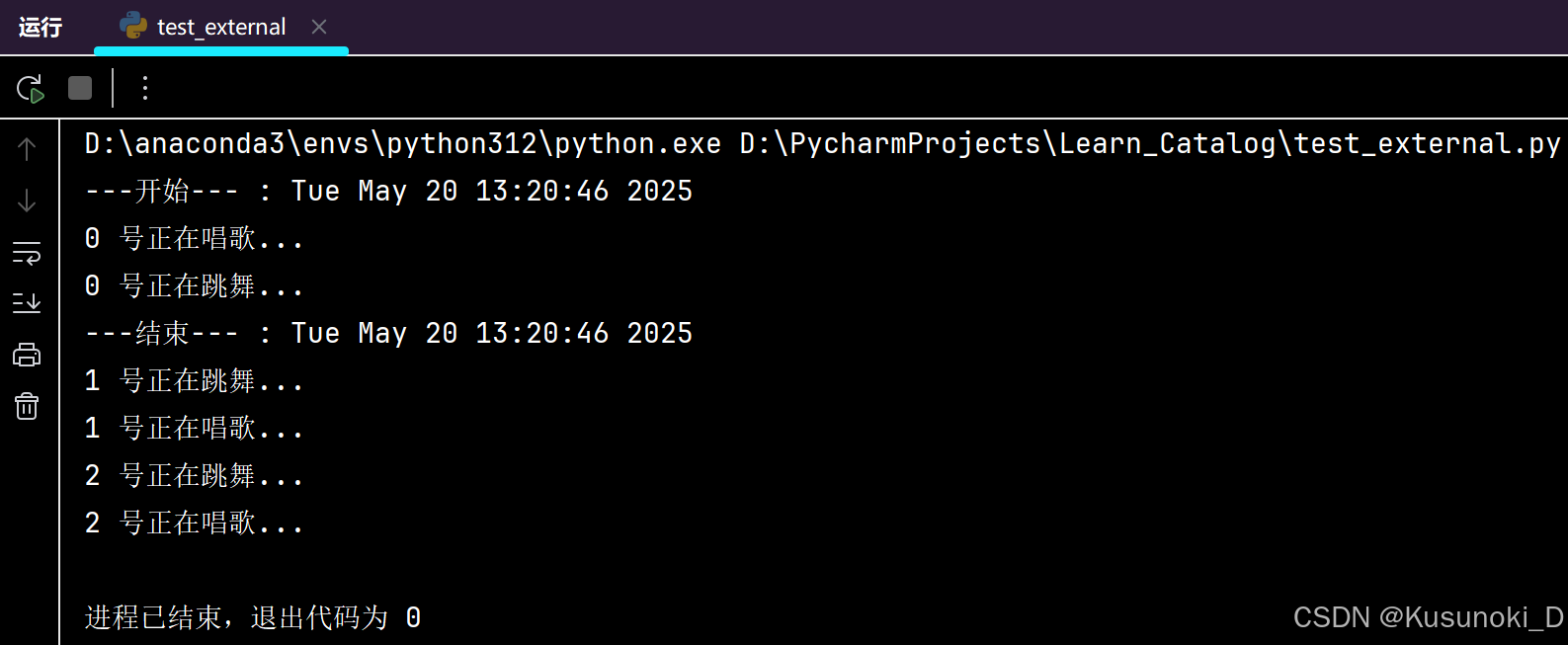
不使用线程时,每打印一次会停顿一秒;使用线程时,所有结果几乎同时打印。
2. 主线程结束时间晚于子线程
进程(主线程)会等待所有的子线程结束后才结束,Python 代码示例如下:
# !/usr/bin/python
# -*- coding:utf-8 -*-import threading
from time import sleep, ctimedef sing():for i in range(3):print("%d 号正在唱歌..." % i)sleep(1)def dance():for i in range(3):print("%d 号正在跳舞..." % i)sleep(1)if __name__ == '__main__':print('---开始--- : %s' % ctime())t1 = threading.Thread(target=sing)t2 = threading.Thread(target=dance)t1.start()t2.start()# t2.join()print('---结束--- : %s' % ctime())
3. 重写 run 方法
Python 的 threading.Thread 类有一个 run 方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法。
创建自己的线程实例后,通过 Thread 类的 start 方法,可以启动该线程,交给 python 虚拟机进行调度,当该线程获得执行的机会时,就会调用 run 方法执行线程。
Python 代码示例如下:
# !/usr/bin/python
# -*- coding:utf-8 -*-import threading
import timeclass MyThread(threading.Thread):def run(self):for i in range(3):time.sleep(1)msg = "I'm " + self.name + ' @ ' + str(i) # name 属性中保存的是当前线程的名字print(msg)def test():for i in range(3):t = MyThread()t.start()if __name__ == '__main__':test()
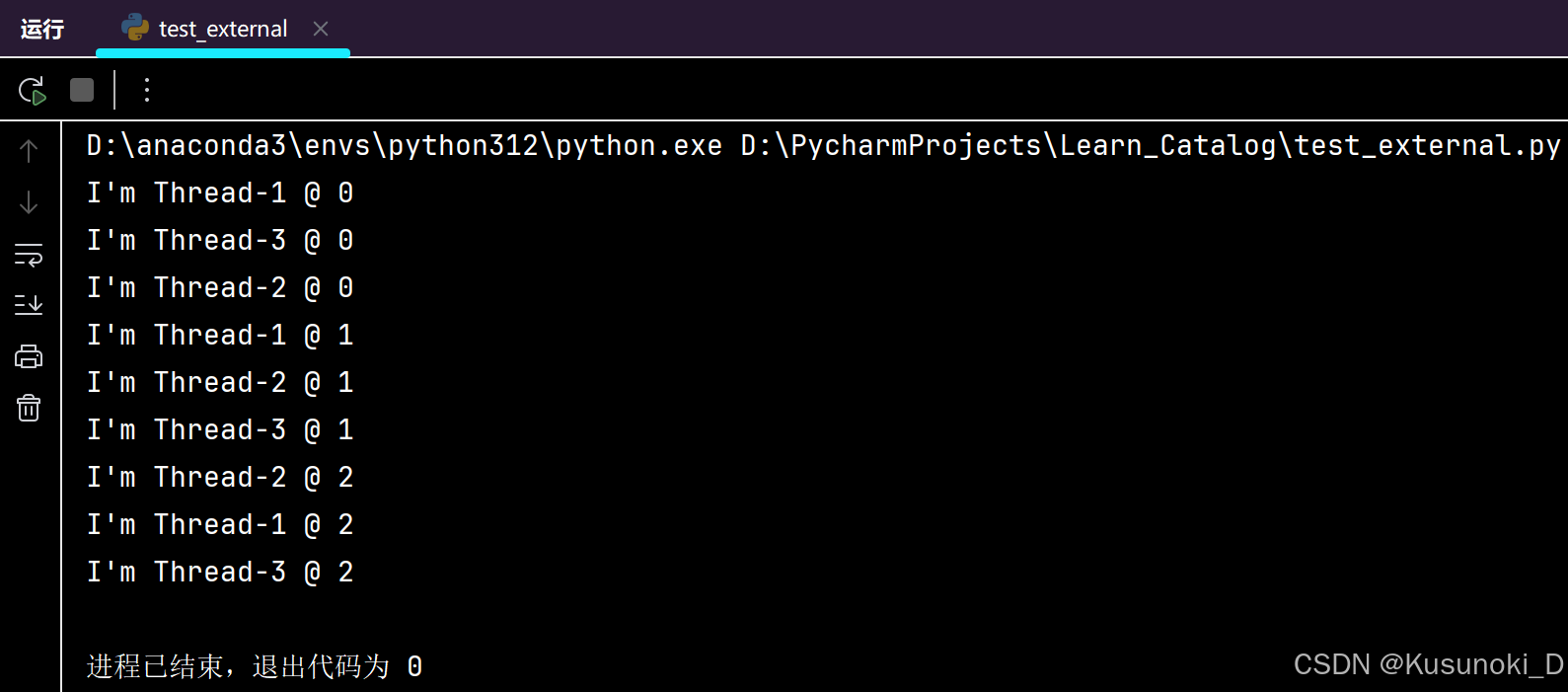
从代码和执行结果可以看出:多线程程序的执行顺序是不确定的。当执行到 sleep 语句时,线程将被阻塞(Blocked),到 sleep 结束后,线程进入就绪(Runnable)状态,等待调度。而线程调度将自行选择一个线程执行。上面的代码中只能保证每个线程都运行完整个 run 函数,但是线程的启动顺序、run 函数中每次循环的执行顺序都不能确定。
总结:
-
每个线程默认有一个名字,如果没有指定线程对象的 name ,那么 Python 会自动为线程指定一个名字。
-
当线程的 run() 方法结束时该线程完成。
-
虽然无法控制线程调度程序,但可以通过别的方式来影响线程调度的方式。
4. 全局解释器锁 GIL
GIL(Global Interpreter Lock,全局解释器锁)是 Python 解释器中的一个机制,用来保证在任意时刻,无论系统上存在多少个可用的 CPU 核心,只允许单个 Python 线程执行。这限制了 Python 程序只能在一个处理器上运行。
① GIL 的作用:
-
Python 的内存管理不是线程安全的,而 GIL 防止多个 Python 线程同时执行,避免了竞态条件和内存错误。
-
GIL 保证了解释器内部数据结构(比如引用计数)的安全。
② GIL 的影响:
-
对 CPU 密集型任务:多线程不能利用多核 CPU 的优势,因为同一时刻只有一个线程执行 Python 代码,导致性能瓶颈。
-
对 I/O 密集型任务:由于 I/O 操作会释放 GIL ,线程可以在等待 I/O 时切换,因此多线程仍然能带来性能提升。
五、线程共享全局变量
1. 共享全局变量的示例代码
# !/usr/bin/python
# -*- coding:utf-8 -*-import threadingg_num = 100def work1(p_list):thread_id = threading.get_ident() # 获取当前线程 IDglobal g_numfor i in range(3):g_num += 1p_list.append(4)print(f"----in {thread_id}, g_num is {g_num}, my_list is {p_list}----")def work2(p_list):thread_id = threading.get_ident() # 获取当前线程 IDglobal g_numprint(f"----in {thread_id}, g_num is {g_num}, my_list is {p_list}----")if __name__ == '__main__':my_list = [1, 2, 3]print(f"---Before the thread is created, g_num is {g_num}, my_list is {my_list}---")t1 = threading.Thread(target=work1, args=(my_list,))t1.start()t1.join()t2 = threading.Thread(target=work2, args=(my_list,))t2.start()t2.join()
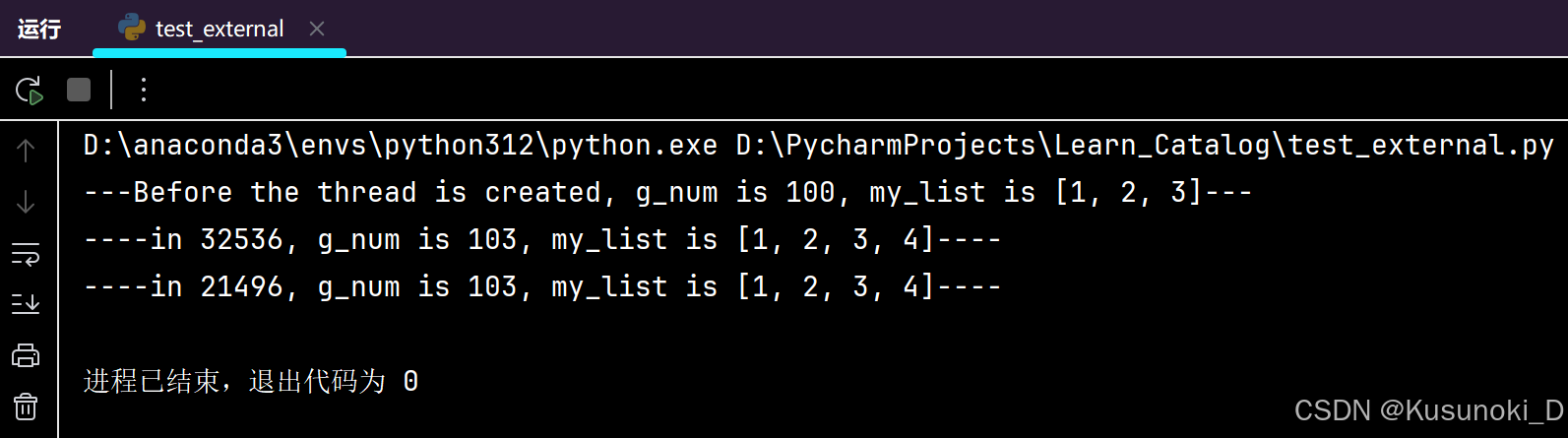
总结:
-
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据。
-
缺点:线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)。
2. 共享全局变量可能出现的问题
假设两个线程 t1 和 t2 都要对全局变量 g_num(默认是 0)进行加 1 运算,t1 和 t2 都各对 g_num 加 10 次,g_num 的最终的结果应该为 20。但是由于是多线程同时操作,有可能出现以下情况:
-
在 g_num = 0 时,t1 取得 g_num = 0 ,此时系统把 t1 调度为 “sleeping” 状态,把 t2 转换为 “running” 状态,t2 也获得 g_num = 0 ;
-
然后 t2 对得到的值进行加 1 并赋给 g_num ,使得 g_num = 1 ;
-
然后系统又把 t2 调度为 “sleeping” 状态,把 t1 转换为 “running” 状态,线程 t1 又把它之前得到的 0 加 1 后赋值给 g_num 。
-
这样导致虽然 t1 和 t2 都对 g_num 加 1 ,但结果仍然是 g_num = 1 。
Python 代码示例如下:(在 Linux 下运行)
# !/usr/bin/python
# -*- coding:utf-8 -*-import threading
import timeg_num = 0def work(num):thread_id = threading.get_ident()global g_numfor j in range(num):g_num += 1print(f"----in {thread_id}, g_num is {g_num}----")if __name__ == '__main__':print("---Before the thread is created, g_num is %d---" % g_num)# count = 10count = 1000000for i in range(2):t = threading.Thread(target=work, args=(count,))t.start()while threading.active_count() != 1:time.sleep(1)print("The end result after two threads working on the same global variable is : %d" % g_num)
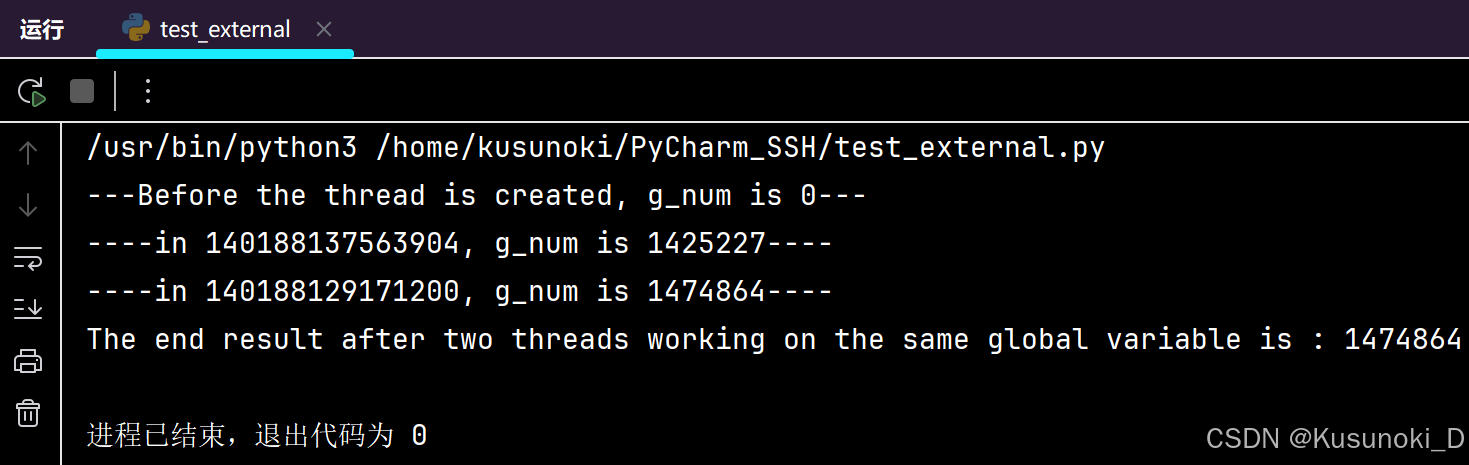
结论:如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确。
注:在 Python 3.12 版本下已经不会出现上述问题了。
该计算错误的问题可以通过线程同步来解决,思路如下:
-
系统调用 t1 ,然后获取到 g_num 的值为 0 ,此时上一把锁,即不允许其他线程操作 g_num 。
-
t1 对 g_num 的值进行 +1 操作。
-
t1 解锁后其他线程可以开始使用 g_num 了,且此时 g_num 的值不是 0 而是 1 。
-
同理,其他线程在对 g_num 进行修改时,都要先上锁,处理完后再解锁,在上锁的整个过程中不允许其他线程访问,就保证了数据的正确性。
六、线程同步(线程锁)
同步就是协同步调,按预定的先后次序进行运行。如:进程、线程同步,可理解为进程或线程 A 和 B 一块配合,A 执行到一定程度时要依靠 B 的某个结果,于是停下来,示意 B 运行,B 执行后将结果给 A,A 再继续操作。
在多线程环境中,为了防止多个线程同时修改同一数据导致数据不一致的问题,需要使用线程锁(Lock)。线程锁可以确保同一时刻只有一个线程可以访问特定的数据。
threading 模块中定义了 Lock 类,可以方便的处理锁定:
-
创建锁:
mutex = threading.Lock() -
锁定:
mutex.acquire() -
释放:
mutex.release()
如果锁未被上锁,那么 acquire 不会堵塞;如果在调用 acquire 对锁进行上锁之前,它已经被其他线程上了锁,那么此时 acquire 会堵塞,直到这个锁被解锁为止。
1. 使用互斥锁线程操作
Python 代码示例如下:
# !/usr/bin/python
# -*- coding:utf-8 -*-import threading
import timeg_num = 0def test(num, lock):thread_id = threading.get_ident()global g_numlock.acquire() # 上锁for j in range(num):g_num += 1lock.release() # 解锁print(f"----in {thread_id}, g_num is : {g_num}----")if __name__ == '__main__':print("Before the thread is created, g_num is %d" % g_num)count = 1000000# 创建一个互斥锁,默认是未上锁的状态mutex = threading.Lock()# 创建 2 个线程,让他们各自对 g_num 加 1000000 次for i in range(2):t = threading.Thread(target=test, args=(count, mutex))t.start()# 等待计算完成while threading.active_count() != 1:time.sleep(1)print("The end result after two threads working on the same global variable is : %d" % g_num)
2. 上锁 / 解锁过程
当一个线程调用锁的 acquire() 方法获得锁时,锁就进入 “locked” 状态。
每次只有一个线程可以获得锁,如果此时另一个线程试图获得这个锁,该线程就会变为 “blocked” 状态,称为 “阻塞” ,直到拥有锁的线程调用锁的 release() 方法释放锁之后,锁进入“unlocked” 状态。
线程调度程序从处于同步阻塞状态的线程中选择一个来获得锁,并使得该线程进入运行(running)状态。
总结:
-
锁的好处:确保了某段关键代码只能由一个线程从头到尾完整地执行。
-
锁的坏处:
- 阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。
- 由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁。
七、死锁
详细介绍见:【进程与线程 IV(死锁)】
1. 死锁的概念
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。尽管死锁很少发生,但一旦发生就会造成应用的停止响应。
以下代码是进入到死锁状态的示例:
# !/usr/bin/python
# -*- coding:utf-8 -*-import threading
import timemutexA = threading.Lock()
mutexB = threading.Lock()class MyThread1(threading.Thread):def run(self):# 对 mutexA 上锁mutexA.acquire()# mutexA 上锁后,延时 1 秒,等待另外那个线程 把 mutexB 上锁print(self.name + '----do1---up----')time.sleep(1)# 此时会堵塞,因为这个 mutexB 已经被另外的线程抢先上锁了mutexB.acquire()print(self.name + '----do1---down----')mutexB.release()# 对 mutexA 解锁mutexA.release()class MyThread2(threading.Thread):def run(self):# 对 mutexB 上锁mutexB.acquire()# mutexB 上锁后,延时 1 秒,等待另外那个线程 把 mutexA 上锁print(self.name + '----do2---up----')time.sleep(1)# 此时会堵塞,因为这个 mutexA 已经被另外的线程抢先上锁了mutexA.acquire()print(self.name + '----do2---down----')mutexA.release()# 对 mutexB 解锁mutexB.release()if __name__ == '__main__':t1 = MyThread1()t2 = MyThread2()t1.start()t2.start()
2. 避免死锁的方法
-
利用银行家算法
-
设置超时时间
八、threading 模块的高级用法
除了基本的线程创建和同步外,threading 模块还提供了其他高级功能,如条件变量(Condition)、信号量(Semaphore)、事件(Event)和栅栏(Barrier)等,这些都是用于不同线程间的协调和通信的同步原语。
threading 模块的使用可以根据具体的应用场景和需求进行选择,无论是 I/O 密集型任务还是 CPU 密集型任务,合理地使用多线程都能显著提高程序的性能和用户体验。
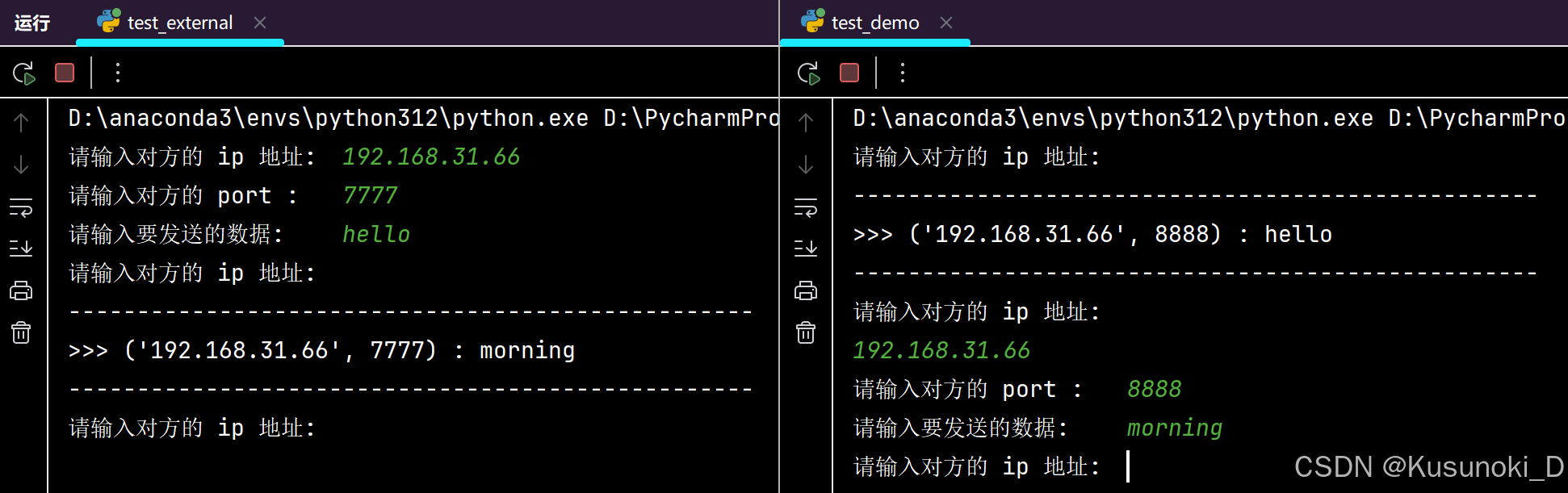
九、多任务版 UDP 聊天器
Python 代码:
# !/usr/bin/python
# -*- coding:utf-8 -*-import socket
import threadingdef send_msg(udp_socket):"""获取键盘数据,并将其发送给对方"""# 1. 输入对方的 ip 地址dest_ip = input("请输入对方的 ip 地址:\t")# 2. 输入对方的 portdest_port = int(input("请输入对方的 port :\t"))# 3. 从键盘输入数据send_to_msg = input("请输入要发送的数据:\t")# 4. 发送数据udp_socket.sendto(send_to_msg.encode("utf-8"), (dest_ip, dest_port))def recv_msg(udp_socket):"""接收数据并显示"""# 1. 接收数据msg = udp_socket.recvfrom(1024)# 2. 解码recv_from_msg = msg[0].decode("utf-8")recv_from_ip = msg[1]# 3. 显示接收到的数据print('\n' + '-' * 50)print(">>> %s : %s" % (str(recv_from_ip), recv_from_msg))print('-' * 50)print("请输入对方的 ip 地址:\t")def main():# 1. 创建套接字udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)# 2. 绑定本地信息udp_socket.bind(("192.168.31.66", 8888))# 3. 创建一个子线程用来接收数据t = threading.Thread(target=recv_msg, args=(udp_socket,))t.start()# 4. 让主线程用来检测键盘数据并且发送while True:send_msg(udp_socket)if __name__ == "__main__":main()
结果展示: