【概率论基本概念02】最大似然性
一、说明
最大似然性估计到底是啥?我们从总体随机抽样中如何得到总体分布的参数?有个“独立同分布”的意味着什么?本文将给出详细叙述。
二、对分布参数估计的目标
假设我们有一个随机样本 ( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn),其假设概率分布取决于某个未知参数 θ \theta θ。我们的主要目标是找到一个点估计量 u ( X 1 , X 2 , ⋯ , X n ) u(X_1, X_2, \cdots, X_n) u(X1,X2,⋯,Xn),使得 u ( x 1 , x 2 , ⋯ , x n ) u(x_1, x_2, \cdots, x_n) u(x1,x2,⋯,xn) 是 θ \theta θ 的一个“良好”点估计,其中 x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x1,x2,⋯,xn 是随机样本的观测值。例如,如果我们计划采取一个随机样本 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn,其中 X i X_i Xi假设为正态分布,平均值为 μ \mu μ且方差为 σ 2 \sigma^2 σ2,那么我们的目标就是找到 μ \mu μ的一个很好的估计值,比如,使用我们从特定随机样本中获得的数据 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn。
( X 1 , X 2 , ⋯ , X n ) (X_1, X_2, \cdots, X_n) (X1,X2,⋯,Xn)其假设概率分布取决于某些未知参数 θ \theta θ。我们的主要目标是找到一个点估计器 u ( X 1 , X 2 , ⋯ , X n ) u(X_1, X_2, \cdots, X_n) u(X1,X2,⋯,Xn),这样 u ( x 1 , x 2 , ⋯ , x n ) u(x_1, x_2, \cdots, x_n) u(x1,x2,⋯,xn)是一个“好的”点估计 θ \theta θ, 在这里 x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x1,x2,⋯,xn是随机样本的观测值。例如,如果我们计划随机抽取一个 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn
为此 X i X_i Xi假设呈正态分布,平均值 μ \mu μ和方差 σ 2 \sigma^2 σ2,那么我们的目标就是找到一个好的估计 μ \mu μ例如,使用数据 x 1 , x 2 , ⋯ , x n x_1, x_2, \cdots, x_n x1,x2,⋯,xn我们从特定的随机样本中获得。
三、基本实现思想
似乎合理的是,未知参数 θ \theta θ 的一个合理估计值应该是使概率(也就是似然值)最大化的 θ \theta θ值,从而得到我们观察到的数据。(那么,你知道“最大似然”这个名字是怎么来的吗?)简而言之,这就是最大似然估计方法背后的思想。但是,我们如何在实践中实现这个方法呢?假设我们有一个随机样本 X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn,其中每个 ( X i (X_i (Xi 的概率密度(或质量)函数为 f ( x i ; θ ) f(x_i;\theta) f(xi;θ)。那么, X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn 的联合概率质量(或密度)函数称之为 L ( θ ) L(\theta) L(θ),其含义如下:
L ( θ ) = P ( X 1 = x 1 , X 2 = x 2 , … , X n = x n ) = f ( x 1 ; θ ) ⋅ f ( x 2 ; θ ) ⋯ f ( x n ; θ ) = ∏ i = 1 n f ( x i ; θ ) L(\theta)=P(X_1=x_1,X_2=x_2,\ldots,X_n=x_n)=f(x_1;\theta)\cdot f(x_2;\theta)\cdots f(x_n;\theta)=\prod\limits_{i=1}^n f(x_i;\theta) L(θ)=P(X1=x1,X2=x2,…,Xn=xn)=f(x1;θ)⋅f(x2;θ)⋯f(xn;θ)=i=1∏nf(xi;θ)
第一个等式当然只是联合概率质量函数的定义。第二个等式源于我们有一个随机样本,这意味着根据定义, X i X_i Xi它们是独立的。最后一个等式只是使用了指标项乘积的简写数学符号。现在,根据最大似然估计的基本思想,一个合理的方法是将“似然函数 L ( θ ) L(\theta) L(θ)”视为 θ \theta θ的函数,并找到使 L ( θ ) L(\theta) L(θ)最大化 的 θ \theta θ值。这听起来还是太抽象了?让我们看一个例子,以便让它更具体一些。
四、示例 1-1
假设我们有一个随机样本 X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn 在这里:
- X i = 0 X_i=0 Xi=0如果随机选择的学生没有跑车,并且
- X i = 1 X_i=1 Xi=1如果随机选择的学生确实拥有一辆跑车。
假设 X i = 1 X_i=1 Xi=1是具有未知参数的独立伯努利随机变量 p p p,找到的最大似然估计 p p p,即拥有跑车的学生比例。
回答
如果 X i = 1 X_i=1 Xi=1是具有未知参数的独立伯努利随机变量 p p p,则每个概率密度函数是:
f ( x i ; p ) = p x i ( 1 − p ) 1 − x i f(x_i;p)=p^{x_i}(1-p)^{1-x_i} f(xi;p)=pxi(1−p)1−xi
为了 x i = 0 或 1 x_i=0或 1 xi=0或1和 0 < p < 1 0<p<1 0<p<1。因此,似然函数 L ( p ) L(p) L(p)根据定义:
L ( p ) = ∏ i = 1 n f ( x i ; p ) = p x 1 ( 1 − p ) 1 − x 1 × p x 2 ( 1 − p ) 1 − x 2 × ⋯ × p x n ( 1 − p ) 1 − x n L(p)=\prod\limits_{i=1}^nf(x_i;p)=p^{x_1}(1-p)^{1-x_1}\times p^{x_2}(1-p)^{1-x_2}\times \cdots \times p^{x_n}(1-p)^{1-x_n} L(p)=i=1∏nf(xi;p)=px1(1−p)1−x1×px2(1−p)1−x2×⋯×pxn(1−p)1−xn
为了 0 < p < 1 0<p<1 0<p<1。通过对指数求和,我们得到:
L ( p ) = p ∑ x i ( 1 − p ) n − ∑ x i L(p)=p^{\sum x_i}(1-p)^{n-\sum x_i} L(p)=p∑xi(1−p)n−∑xi
现在,为了实现最大似然法,我们需要找到 p p p最大化可能性 L ( p ) L(p) L(p)
我们现在需要运用微积分知识,因为为了最大化函数,我们需要对似然函数进行微分 p p p。为此,我们将使用一个“技巧”,这通常会使微分更容易一些。注意,利用自然对数函数ln(x)。
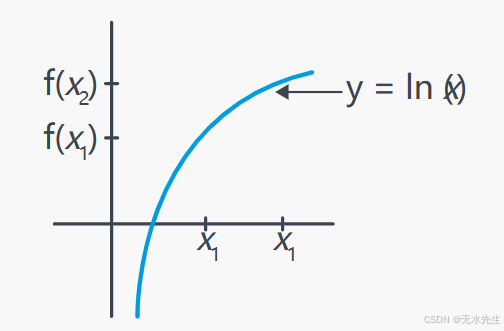
也就是说,如果 x 1 < x 2 x_1<x_2 x1<x2, 然后 f ( x 1 ) < f ( x 2 ) f(x_1)<f(x_2) f(x1)<f(x2)。这意味着 p p p
最大化似然函数的自然对数 ln L ( p ) \ln L(p) lnL(p)也是 p p p最大化似然函数 L ( p ) L(p) L(p)。所以,“诀窍”是取 ln L ( p ) \ln L(p) lnL(p)的导数(而不是取$ L§$的导数)。这样做会使问题更容易解决。
在这种情况下,似然函数的自然对数为:
log L ( p ) = ( ∑ x i ) log ( p ) + ( n − ∑ x i ) log ( 1 − p ) \text{log}L(p)=(\sum x_i)\text{log}(p)+(n-\sum x_i)\text{log}(1-p) logL(p)=(∑xi)log(p)+(n−∑xi)log(1−p)
现在,取对数似然的导数,并将其设置为 0,我们得到:
∂ log L ( p ) ∂ p = ∑ x i p − ( n − ∑ x i ) 1 − p ≡ S E T 0 \displaystyle{\frac{\partial \log L(p)}{\partial p}=\frac{\sum x_{i}}{p}-\frac{\left(n-\sum x_{i}\right)}{1-p} \stackrel{SET}{\equiv} 0} ∂p∂logL(p)=p∑xi−1−p(n−∑xi)≡SET0
经过简化得到:
∑ x i − n p = 0 \sum x_i-np=0 ∑xi−np=0
现在我们要做的就是求解p
p ^ = ∑ i = 1 n x i n \hat{p}=\dfrac{\sum\limits_{i=1}^n x_i}{n} p^=ni=1∑nxi
或者,估算器:
p ^ = ∑ i = 1 n X i n \hat{p}=\dfrac{\sum\limits_{i=1}^n X_i}{n} p^=ni=1∑nXi
技术上来说,我们应该验证一下我们确实得到了最大值。我们可以通过验证对数似然函数的二阶导数p是负面的。确实如此,但你可能需要做一些工作来说服自己!
五、正规定义
定义:给定 X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn 是来自依赖于一个或多个未知参数的分布的随机样本。 θ 1 , θ 2 , ⋯ , θ m \theta_1, \theta_2, \cdots, \theta_m θ1,θ2,⋯,θm 具有概率密度(或质量)函数 f ( x i ; θ 1 , θ 2 , ⋯ , θ m ) f(x_i;\theta_1,\theta_2,\cdots,\theta_m) f(xi;θ1,θ2,⋯,θm)
.假设 θ 1 , θ 2 , ⋯ , θ m \theta_1, \theta_2, \cdots, \theta_m θ1,θ2,⋯,θm限制在给定的参数空间 Ω \Omega Ω内。 然后:
1 对于随机样本 X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X1,X2,⋯,Xn 的密度函数 f f f的联合分布是
L ( θ 1 , θ 2 , … , θ m ) = ∏ i = 1 n f ( x i ; θ 1 , θ 2 , … , θ m ) L(\theta_1,\theta_2,\ldots,\theta_m)=\prod\limits_{i=1}^n f(x_i;\theta_1,\theta_2,\ldots,\theta_m) L(θ1,θ2,…,θm)=i=1∏nf(xi;θ1,θ2,…,θm)
被称为( θ 1 , θ 2 , ⋯ , θ m ∈ Ω \theta_1, \theta_2, \cdots, \theta_m\in \Omega θ1,θ2,⋯,θm∈Ω) 称为似然函数。
2 如果元组 [ u 1 ( x 1 , x 2 , … , x n ) , u 2 ( x 1 , x 2 , … , x n ) , … , u m ( x 1 , x 2 , … , x n ) ] [u_1(x_1,x_2,\ldots,x_n),u_2(x_1,x_2,\ldots,x_n),\ldots,u_m(x_1,x_2,\ldots,x_n)] [u1(x1,x2,…,xn),u2(x1,x2,…,xn),…,um(x1,x2,…,xn)]足以达到最大化似然化,那么 θ ^ i = u i ( X 1 , X 2 , … , X n ) \hat{\theta}_i=u_i(X_1,X_2,\ldots,X_n) θ^i=ui(X1,X2,…,Xn)就是 θ 1 , θ 2 , ⋯ , θ m \theta_1, \theta_2, \cdots, \theta_m θ1,θ2,⋯,θm的极大似然估计器。
3 相应的统计数据的观测值(2)即:
[ u 1 ( x 1 , x 2 , … , x n ) , u 2 ( x 1 , x 2 , … , x n ) , … , u m ( x 1 , x 2 , … , x n ) ] [u_1(x_1,x_2,\ldots,x_n),u_2(x_1,x_2,\ldots,x_n),\ldots,u_m(x_1,x_2,\ldots,x_n)] [u1(x1,x2,…,xn),u2(x1,x2,…,xn),…,um(x1,x2,…,xn)]
被称为最大似然估计 θ i \theta_i θi,此处 i = 1 , 2 , ⋯ , m i=1, 2, \cdots, m i=1,2,⋯,m。
六、一个示例
令 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn是来自均值未知的正态分布的随机样本 μ \mu μ和方差 σ 2 \sigma^2 σ2. 找到均值的最大似然估计和方差 μ \mu μ和方差 σ 2 \sigma^2 σ2。
回答
在寻找估计量时,我们要做的第一件事就是将概率参数写为
θ 1 = μ \theta_1=\mu θ1=μ和 θ 2 = σ 2 \theta_2=\sigma^2 θ2=σ2
于是密度函数:
f ( x i ; θ 1 , θ 2 ) = 1 θ 2 2 π exp [ − ( x i − θ 1 ) 2 2 θ 2 ] f(x_i;\theta_1,\theta_2)=\dfrac{1}{\sqrt{\theta_2}\sqrt{2\pi}}\text{exp}\left[-\dfrac{(x_i-\theta_1)^2}{2\theta_2}\right] f(xi;θ1,θ2)=θ22π1exp[−2θ2(xi−θ1)2]
参数空间: − ∞ < θ 1 < ∞ 和 0 < θ 2 < ∞ -\infty<\theta_1<\infty \text{ 和 }0<\theta_2<\infty −∞<θ1<∞ 和 0<θ2<∞
现在,这就得到了似然函数:
L ( θ 1 , θ 2 ) = ∏ i = 1 n f ( x i ; θ 1 , θ 2 ) = θ 2 − n / 2 ( 2 π ) − n / 2 exp [ − 1 2 θ 2 ∑ i = 1 n ( x i − θ 1 ) 2 ] L(\theta_1,\theta_2)=\prod\limits_{i=1}^nf(x_i;\theta_1,\theta_2)=\theta^{-n/2}_2(2\pi)^{-n/2}\text{exp}\left[-\dfrac{1}{2\theta_2}\sum\limits_{i=1}^n(x_i-\theta_1)^2\right] L(θ1,θ2)=i=1∏nf(xi;θ1,θ2)=θ2−n/2(2π)−n/2exp[−2θ21i=1∑n(xi−θ1)2]
因此似然函数的对数为:
log L ( θ 1 , θ 2 ) = − n 2 log θ 2 − n 2 log ( 2 π ) − ∑ ( x i − θ 1 ) 2 2 θ 2 \text{log} L(\theta_1,\theta_2)=-\dfrac{n}{2}\text{log}\theta_2-\dfrac{n}{2}\text{log}(2\pi)-\dfrac{\sum(x_i-\theta_1)^2}{2\theta_2} logL(θ1,θ2)=−2nlogθ2−2nlog(2π)−2θ2∑(xi−θ1)2
现在,对对数似然函数求偏导数 θ 1 \theta_1 θ1和 θ 2 \theta_2 θ2,并将其设置为 0,我们会看到一些事情相互抵消,剩下:
∂ log L ( θ 1 , θ 2 ) ∂ θ 1 = − 2 ∑ ( x i − θ 1 ) ( − 1 ) 2 θ 2 ≡ SET 0 \displaystyle{\frac{\partial \log L\left(\theta_{1}, \theta_{2}\right)}{\partial \theta_{1}}=\frac{-\color{red} \cancel {\color{black}2} \color{black}\sum\left(x_{i}-\theta_{1}\right)\color{red}\cancel{\color{black}(-1)}}{\color{red}\cancel{\color{black}2} \color{black} \theta_{2}} \stackrel{\text { SET }}{\equiv} 0} ∂θ1∂logL(θ1,θ2)=2 θ2−2 ∑(xi−θ1)(−1) ≡ SET 0
现在,乘以 θ 2 \theta_2 θ2,并分配总和,我们得到:
∑ x i − n θ 1 = 0 \sum x_i-n\theta_1=0 ∑xi−nθ1=0
现在,求解 θ 1 \theta_1 θ1,并戴上帽子,我们已经证明了 θ 1 \theta_1 θ1 是:
θ ^ 1 = μ ^ = ∑ x i n = x ˉ \hat{\theta}_1=\hat{\mu}=\dfrac{\sum x_i}{n}=\bar{x} θ^1=μ^=n∑xi=xˉ
现在求 θ 2 \theta_2 θ2. 对对数似然取偏导数 θ 2 \theta_2 θ2,并设置为 0,我们得到:
∂ log L ( θ 1 , θ 2 ) ∂ θ 2 = − n 2 θ 2 + ∑ ( x i − θ 1 ) 2 2 θ 2 2 ≡ SET 0 \displaystyle{\frac{\partial \log L\left(\theta_{1}, \theta_{2}\right)}{\partial \theta_{2}}=-\frac{n}{2 \theta_{2}}+\frac{\sum\left(x_{i}-\theta_{1}\right)^{2}}{2 \theta_{2}^{2}} \stackrel{\text { SET }}{\equiv} 0} ∂θ2∂logL(θ1,θ2)=−2θ2n+2θ22∑(xi−θ1)2≡ SET 0
乘以 2 θ 2 2 2\theta_2^2 2θ22:
∂ log L ( θ 1 , θ 2 ) ∂ θ 1 = [ − n 2 θ 2 + ∑ ( x i − θ 1 ) 2 2 θ 2 2 ≡ s ϵ ϵ 0 ] × 2 θ 2 2 \displaystyle{\frac{\partial \log L\left(\theta_{1}, \theta_{2}\right)}{\partial \theta_{1}}=\left[-\frac{n}{2 \theta_{2}}+\frac{\sum\left(x_{i}-\theta_{1}\right)^{2}}{2 \theta_{2}^{2}} \stackrel{s \epsilon \epsilon}{\equiv} 0\right] \times 2 \theta_{2}^{2}} ∂θ1∂logL(θ1,θ2)=[−2θ2n+2θ22∑(xi−θ1)2≡sϵϵ0]×2θ22
得到:
− n θ 2 + ∑ ( x i − θ 1 ) 2 = 0 -n\theta_2+\sum(x_i-\theta_1)^2=0 −nθ2+∑(xi−θ1)2=0
并且,求解 θ 2 \theta_2 θ2,并戴上帽子,我们已经证明了 θ 2 \theta_2 θ2 是:
θ ^ 2 = σ ^ 2 = ∑ ( x i − x ˉ ) 2 n \hat{\theta}_2=\hat{\sigma}^2=\dfrac{\sum(x_i-\bar{x})^2}{n} θ^2=σ^2=n∑(xi−xˉ)2
以上证明了:
μ ^ = ∑ X i n = X ˉ \hat{\mu}=\dfrac{\sum X_i}{n}=\bar{X} μ^=n∑Xi=Xˉ
σ ^ 2 = ∑ ( X i − X ˉ ) 2 n \hat{\sigma}^2=\dfrac{\sum(X_i-\bar{X})^2}{n} σ^2=n∑(Xi−Xˉ)2
七、后记
以上给出的密度函数总是有解析表达,对于有些分布无法写出解析表达,如何处理呢?请参看博文【经验分布】https://yamagota.blog.csdn.net/article/details/148089446?spm=1011.2415.3001.5331