计算机基础核心课程
系列文章目录
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 前言
- 1. 存储程序原理
- 冯诺依曼计算机
- 计算机中的数
- 内存系统
- Cache
- 指令系统
- 寻址方式
- x86常用汇编
- CPU
- 内部异常和外部中断
- 指令流水线
- 总线和外设
- 操作系统
- 用户态与内核态
- 中断与异常
- 分页
- 段式管理
- 段页式管理
- 请求分页式管理
- 页面置换算法
- 计算机网络
- 数据链路层
- 功能
- 流量控制, 可靠传输与滑动窗口
- 网络层
- 功能
- IPv4与NAT
- ARP
- DHCP
- ICMP
- IPv6
- RIP,IP组播
- 传输层
- UDP校验
- TCP流量控制、拥塞控制
- 应用层
- 客户-服务(C/S)模型
- 对等(P2P)模型
- DNS系统
- www
- 从输入网址到现实页面
- others
- C++统一执行器提案
- receiver, sender, scheduler
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
1. 存储程序原理
“存储程序”工作方式规定,程序执行前,需要将程序所含的指令和数据送入主存储器,一旦程序被启动执行,就无须操作人员的干预,自动逐条完成指的取出和执行任务。
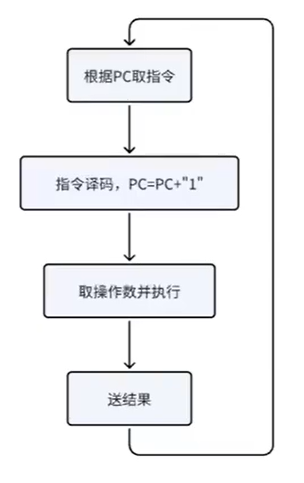
冯诺依曼计算机
- 采用“存储程序”的工作方式
- 计算机由运算器、控制器、存储器输入设备和输出设备5个基本部件组成
- 存储器不仅能存放数据,还能存放指令,在形式上指令和数据没有任何区别,但计算机能够区分开它们
- 计算机内部以二进制形式
计算机中的数
C语言数据转换
小字节向大字节扩展,大数截断为小数
补码加减运算器可用于有无符号数据加减运算。
IEEE754浮点数格式
内存系统
RAM: SRAM, DRAM
ROM: MROM, PROM, EPROM, flash, ssd
MAR发送地址,地址线、片选确定带访问数据的位置,MDR获得数据
位扩展,字扩展
Cache
缓存块大小
缓存命中率p
CPU访问数据的平均访问时间Ta = pTc + (1-p)(Tc+Tm) = Tc + (1-p)*Tm
指令系统
取数指令执行过程的描述
- (PC)->MAR->M->MDR->IR 取出指令
- OP(IR)->CU 分析指令
- AD(IR)->MAR->M->MDR->ACC
寻址方式
指令给出操作数或操作数地址的方式称为寻址方式。
+----------------------------------------+
| 操作码 | 寻址特征 | 形式地址 |
+----------------------------------------+
形式地址(A)和有效地址EA
- 隐含寻址:
- 立即寻址:立即数
- 直接寻址:EA=A
- 间接寻址:EA=(A)
- 寄存器寻址:EA=Ri
- 寄存器间接寻址:EA=(Ri)
- 相对寻址:EA=(PC)+A
- 基址寻址:EA=(BR)+A
- 变址寻址:EA=变址寄存器(IX)+A
x86常用汇编
mov eax, ebx # eax = ebx
mov byte ptr [var], 5 # 将5保存到内存地址未var的一字节中
# mov两个操作数不能都是内存,即mov指令不能直接从内存中复制到内存中push eax # 将esp的值-4,然后将eax的值复制到栈顶
push [var]pop eax # 将栈顶的值拷贝到eax,然后将esp+4
pop [ebx] # 将栈顶值弹出到ebx所指的内存地址中sub eax, ebx # eax -= ebx
add byte ptr [var], 10 # 将var指向的内存地址的一字节值与10相加,存入var指向的内存地址dec eax # eax--
inc dword ptr [var] # 将var指示的内存地址的4字节值自增1imul eax, [var] # eax = [var] * eax
imul esi, edi, 25 # esi = edi * 25
x86中IP为指令指针寄存器,指向下一条指令的地址(相当于ARM中的PC)
begin: xor ecx, ecx
jmp begin
cmp/test:相当于执行sub/and指令,但不保存计算结果,只修程序状态字(PSW)
cmp eax, ebx
jle donecmp dword ptr [var], 10
jne loopcall/ret
CPU
CPU每取出并执行一条指令所需的全部时间称为指令周期;一个指令周期有一个或多个机器周期组成,一个机器周期由多个时钟周期组成;一个完整的指令周期包括取指令、间址、执行和中断四个周期。
- 取指令并计算下一条指令地址
- 判断是否需要间接地址
- 根据EA取出操作数,数据操作,保存操作数
- 中断处理:如果CPU检测到中断请求,进入中断周期,此时需要关中断、保存断点、执行中断服务程序等
内部异常和外部中断
指令流水线
+------------------------------------------------------------+
输入 -> | S1取指令IF | S2 译码ID | S3 取操作数OF | S4 执行EX | S5 写回WB | -> 输出+------------------------------------------------------------+-----------+| S1 | S2 | S3 | S4 | S5 |+------------------------------------------------------------+-----------+| S1 | S2 | S3 | S4 | S5 |+------------------------------------------------------------+
数据冒险
性能指标
相比CISC指令集,RISC能更好的应用流水线
超标量流水线技术 之乱序执行
超长指令字技术
超流水线技术
总线和外设
三总线结构:主存总线(CPU和内存传递地址,数据和控制信息); I/O总线(CPU与各类外设通讯); DMA总线(内存和高速外设之间直接传递数据)
I/O编址分为独立编址和统一编址两种.统一编址是将主存地址空间分出一部分给I/O端口进行编址
I/O数据传送控制方式之程序中断:CPU启动外设后寻行其他程序,外设完成数据传送的准备工作后主动向CPU发出中断请求,CPU终止当前程序响应中断,执行中断处理服务,返回原来的程序
程序中断过程:
中断响应________________________________________中断处理
关中断 -> 保存断点和程序状态字 -> 终端服务程序寻址 -> 保存现场和屏蔽字 -> 开中断 -> 执行中断服务程序 -> 关中断 -> 恢复现场和屏蔽字 -> 开中断 -> 中断返回
DMA通讯
操作系统
用户态与内核态
在用户太将PSW的某位置位,进入内核态, 再置位返回用户态
中断与异常
内终端(异常): 故障fault,自陷trap,终止abort
外中断(中断): 可屏蔽中断,不可屏蔽中断
- fault: 是一种可能恢复的异常事件,若当前指令执行产生故障,CPU转到故障处理程序进行修复.若可以修复,则CPU转到引起故障的指令继续执行.若干不能修复,则终止当前进程.常见故障如缺页异常,若当前指令访问的页面不在内存中时,会发生缺页异常,由OS的缺页handler将页面调入,随后CPU返回到当前的指令继续执行
- trap: 一种有意安排的异常事件.最重要的用途是syscall. 调用trap后CPU转到对应的内核程序去执行
- abort: 一种无法恢复的异常
中断是一种由I/O外部设备触发的事件,他与CPU正在执行的指令无关,中断提供了外设与CPU交流的机制,CPU会在当前指令执行完毕后响应中断请求
分页
页面大小时40B,逻辑空间大小为280B,则逻辑地址117所对应的页号即偏移量?
分页=280/40=7个 0~6
页号=逻辑地址/页面大小=117/40=2
偏移量=逻辑地址%页面大小=117%40=37
逻辑地址
n-1 k,k-1 0
+-----------------+
| 页号P | 偏移量W |
+-----------------+
页表存储页号和物理地址页的映射关系
多级页表可以保证一个页表在一个页内
段式管理
和分页式管理非常接近,只不过每个段的大小是可变的
+-----------------+
| 段号P |段内地址 |
+-----------------+段表:
0 段长 基地址
1 段长 基地址ye
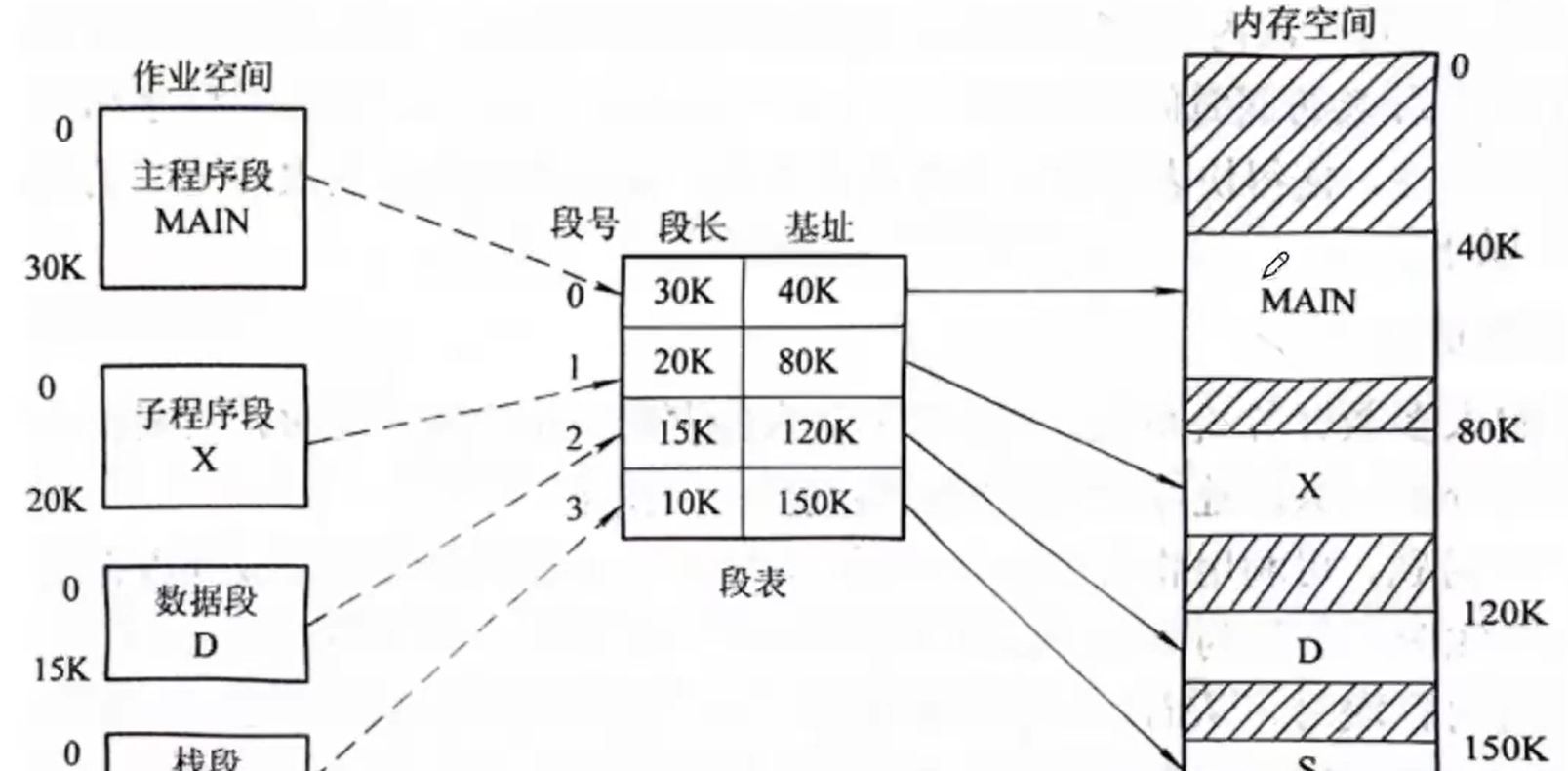
段页式管理
段页式存储管理方式是分页和分段管理的结合,他先将地址空间中的用户程序分成若干个段,再将每个段分成若干个页。而内存空间则被分成与页同样大小的块,并以块为单位来进行内存的分配。
为了实现地址变换,系统必须为每个进程建立一张段表,并为每个分段建立一张页表,段表项给出了每个分段所对应的页表的内存始址和长度,页表项则给出了页所对应的内存块号。
+----------------------------+
| 段号P | 段内页号 | 页内地址 |
+----------------------------+

请求分页式管理
页面置换算法
LRU最近最久未使用
计算机网络
网络协议是一组规则和标准,用于定义计算机在网络中如何进行通讯,是实现接口和服务的基础.
协议是水平的,是控制对等实体之间通许的规则.
通讯三要素:
- 语法: 语法规定传输数据的格式
- 语义: 语义指数据的含义和解释,包括各字段的功能,用途和意义,定义了通讯各方应如何处理和响应接收到的数据.
- 同步(时序): 事件发生的顺序和时间关系,包括消息发送和接收的时机,超时处理和同步机制等.
网络模型: 物 数 网 传 会 表 应
- 物理层: 传输比特流, RJ45 IEEE802.3协议等
- 数据链路层: 提供帧的传输和错误检测; 管理物理地址(MAC); 进行流量控制和帧同步; SDLC, HDLC, PPP, STP和帧中继等协议
- 网络层: 把网络层的协议数据单元从源端传到目的端; 路由选择,流量控制,拥塞控制,差错控制和网际互联; 传输单位为数据报; 协议IP,icmp, ipx, igmp, arp, rarp, ospf
- 传输层: 为用户提供端到端服务,提供流量控制,差错控制,数据传输管理,服务质量.同时复用和分用功能.TCP是流式协议,UDP是报文协议.
复用:传输层将来自多个应用程序的数据流合并成一个数据流,以便通过单个网络链接进行传输.传输层使用端口号来区分不同的应用程序.
分用:传输层从收到的单个数据流中提取不同应用程序的数据段,并将它们转发给相应的应用程序.通过端口号实现 - 会话层: 管理应用程序之间的会话,建立,维护,终止会话连接
- 表示层: 数据格式化,压缩,加解密等
- 应用层: 为用户和应用程序提供直接的网络服务接口,包括各种网络服务文件传输,电子邮件,远程登录等,是用户与网络的交互点.
http(s), ftp, 简单邮件传输协议smtp, 域名系统dns, 远程桌面协议rdp
数据链路层
功能
链路: 网络中两个结点之间的物理通道,传输介质主要有双绞线,光纤,电磁波等
数据链路: 网络中两个结点之间的逻辑通道,吧实现数据传输协议的硬件和软件(如网卡)加到链路上就变成了数据链路
数据链路层以帧为单位传输和处理数据
|帧开始 | 帧结束
发送 +-----------------------------+<-- | 帧首部 | 帧数据 | 帧尾部 |+-----------------------------+| |--最大数据长--| ||<-------数据链路层的帧长------->|
数据链路层是相邻节点之间的流量控制,传输层是端到端的流量控制
如何定位帧的首位? HDLC协议使用0比特填充首位标识法
01111111111101111110
-> 每连续的5个1填充0
01111110 011111[0]11111[0]1011111[0]10 01111110
流量控制, 可靠传输与滑动窗口
- 流量控制: 发送放与接受放协调速率传输机制,确保发送方不会以超过接收方处理能力的速度发送
- 可靠传输: 确认和超时重传, 自动重传请求
- 滑动窗口
网络层
功能
数据报
- 端系统:拆分报文并加上控制信息
- 中间节点:选择合适的路由转发
无连接传输,可能出现乱序、丢失和重复数据报,每个数据报在网络中独立传输,包含完整的源地址和目标地址,适用于突发性通讯、不适用于长报文、会话式通讯;
虚电路
- 结合数据报方式与电路交换方式
- 在分组发送前通讯双方建立一条逻辑上相连的虚电路(固定了虚电路对应的物理路径)
- 虚电路通讯过程分为 虚电路建立、数据传输、释放三个阶段
- 虚电路方式的分组首部控制信息还需要加上虚电路号,以区别本系统中的其他虚电路
- 虚电路网络中的每个节点上都维持一张虚电路表,表中的每项记录了一个打开的虚电路的信息。
路由与转发
- 路由是指选择路径的过程
- 路由器根据特定的路由选择协议构造出路由表,并经常和相邻路由表交换路由信息而不断更新和维护路由表。生成路由表后,从中得出转发表。路由器根据转发表将用户的IP数据报从合适的端口转发出去。
IPv4与NAT
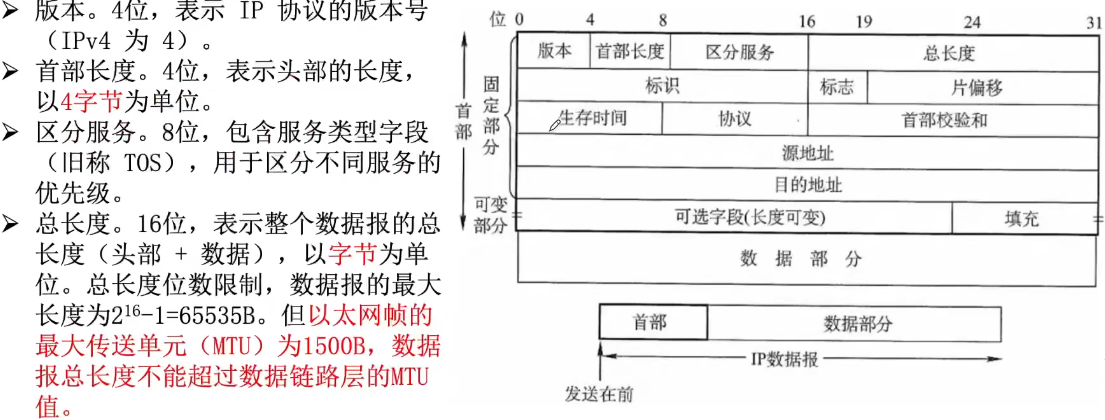
标识:16b,标识数据报的唯一ID,用于数据报分片和重组。
标志:3b, 控制数据报分片:[未使用|DF=1禁止分片|MF=1有后续分片]
片偏移:13b表示分片相对于原始数据报起始位置的偏移量,以8B为单位,出最后一个分片外每个分片一定是8字节的整数倍。
生存时间(TTL):标识数据报可以经过的最大路由器数量,路由器在转发分组前把TTL-1,若为0则必须丢弃。
协议:上层协议,TCP(6) UDP(17)
首部校验和:只校验分组的首部,而不校验数据部分
最大传送单元MTU:一个数据链路层数据报能承载的最大数量,以太网MTU为1500,许多广域网MTU不超过576B
分片:IP报封装成帧时若装不下则需要分片,重组只会在目的主机上发生
- 早期ip地址的分类
A(1~126) [0]
B(128~191) [10]
C(192~223) [110]
D(224~239) [1110]
E(240~255) [1111] - 特殊的IP地址:
网络地址:主机号全0用于标识整个网络;广播地址:主机号全为1;受限广播地址:32位全为1,表示整个TCP/IP网络的广播地址;回环地址:127.0.0.1; - 只有公有地址才能在互联网上直接通讯,私有地址必须通过公网IP才能上网,私有和公有IP通过NAT路由器(涉及到传输层)进行转换,它通过端口号将统一公网IP映射到不同的私有IP ;私有IP:A类1个网段(10.0.0.010.255.255.255),B类16个(172.16.0.0172.31.255.255),C类256(192.168.0.0~192.168.255.255)
ARP
将IP解析成MAC[IP | MAC | TTL];ARP请求帧目标MAC地址字段为FF-FF-FF-FF-FF-FF(ARP请求是一个广播帧,会被局域网上的所有主机和网络设备接收,目标主机接收后ip地址如果匹配则发送ARP响应)
DHCP
应用层协议,基于UDP,客户端使用68号端口,服务端使用67端口。网络上有多个HDCP服务器会选择最先到达的
ICMP
网络层协议,主要用来诊断网络故障
icmp_header.hpp
//
// icmp_header.hpp
// ~~~~~~~~~~~~~~~
//
// Copyright (c) 2003-2024 Christopher M. Kohlhoff (chris at kohlhoff dot com)
//
// Distributed under the Boost Software License, Version 1.0. (See accompanying
// file LICENSE_1_0.txt or copy at http://www.boost.org/LICENSE_1_0.txt)
//#ifndef ICMP_HEADER_HPP
#define ICMP_HEADER_HPP#include <istream>
#include <ostream>
#include <algorithm>// ICMP header for both IPv4 and IPv6.
//
// The wire format of an ICMP header is:
//
// 0 8 16 31
// +---------------+---------------+------------------------------+ ---
// | | | | ^
// | type | code | checksum | |
// | | | | |
// +---------------+---------------+------------------------------+ 8 bytes
// | | | |
// | identifier | sequence number | |
// | | | v
// +-------------------------------+------------------------------+ ---class icmp_header
{
public:enum { echo_reply = 0, destination_unreachable = 3, source_quench = 4,redirect = 5, echo_request = 8, time_exceeded = 11, parameter_problem = 12,timestamp_request = 13, timestamp_reply = 14, info_request = 15,info_reply = 16, address_request = 17, address_reply = 18 };icmp_header() { std::fill(rep_, rep_ + sizeof(rep_), 0); }unsigned char type() const { return rep_[0]; }unsigned char code() const { return rep_[1]; }unsigned short checksum() const { return decode(2, 3); }unsigned short identifier() const { return decode(4, 5); }unsigned short sequence_number() const { return decode(6, 7); }void type(unsigned char n) { rep_[0] = n; }void code(unsigned char n) { rep_[1] = n; }void checksum(unsigned short n) { encode(2, 3, n); }void identifier(unsigned short n) { encode(4, 5, n); }void sequence_number(unsigned short n) { encode(6, 7, n); }friend std::istream& operator>>(std::istream& is, icmp_header& header){ return is.read(reinterpret_cast<char*>(header.rep_), 8); }friend std::ostream& operator<<(std::ostream& os, const icmp_header& header){ return os.write(reinterpret_cast<const char*>(header.rep_), 8); }private:unsigned short decode(int a, int b) const{ return (rep_[a] << 8) + rep_[b]; }void encode(int a, int b, unsigned short n){rep_[a] = static_cast<unsigned char>(n >> 8);rep_[b] = static_cast<unsigned char>(n & 0xFF);}unsigned char rep_[8];
};template <typename Iterator>
void compute_checksum(icmp_header& header,Iterator body_begin, Iterator body_end)
{unsigned int sum = (header.type() << 8) + header.code()+ header.identifier() + header.sequence_number();Iterator body_iter = body_begin;while (body_iter != body_end){sum += (static_cast<unsigned char>(*body_iter++) << 8);if (body_iter != body_end)sum += static_cast<unsigned char>(*body_iter++);}sum = (sum >> 16) + (sum & 0xFFFF);sum += (sum >> 16);header.checksum(static_cast<unsigned short>(~sum));
}#endif // ICMP_HEADER_HPPipv4_header.hpp
//
// ipv4_header.hpp
// ~~~~~~~~~~~~~~~
//
// Copyright (c) 2003-2024 Christopher M. Kohlhoff (chris at kohlhoff dot com)
//
// Distributed under the Boost Software License, Version 1.0. (See accompanying
// file LICENSE_1_0.txt or copy at http://www.boost.org/LICENSE_1_0.txt)
//#ifndef IPV4_HEADER_HPP
#define IPV4_HEADER_HPP#include <algorithm>
#include <asio/ip/address_v4.hpp>// Packet header for IPv4.
//
// The wire format of an IPv4 header is:
//
// 0 8 16 31
// +-------+-------+---------------+------------------------------+ ---
// | | | | | ^
// |version|header | type of | total length in bytes | |
// | (4) | length| service | | |
// +-------+-------+---------------+-+-+-+------------------------+ |
// | | | | | | |
// | identification |0|D|M| fragment offset | |
// | | |F|F| | |
// +---------------+---------------+-+-+-+------------------------+ |
// | | | | |
// | time to live | protocol | header checksum | 20 bytes
// | | | | |
// +---------------+---------------+------------------------------+ |
// | | |
// | source IPv4 address | |
// | | |
// +--------------------------------------------------------------+ |
// | | |
// | destination IPv4 address | |
// | | v
// +--------------------------------------------------------------+ ---
// | | ^
// | | |
// / options (if any) / 0 - 40
// / / bytes
// | | |
// | | v
// +--------------------------------------------------------------+ ---class ipv4_header
{
public:ipv4_header() { std::fill(rep_, rep_ + sizeof(rep_), 0); }unsigned char version() const { return (rep_[0] >> 4) & 0xF; }unsigned short header_length() const { return (rep_[0] & 0xF) * 4; }unsigned char type_of_service() const { return rep_[1]; }unsigned short total_length() const { return decode(2, 3); }unsigned short identification() const { return decode(4, 5); }bool dont_fragment() const { return (rep_[6] & 0x40) != 0; }bool more_fragments() const { return (rep_[6] & 0x20) != 0; }unsigned short fragment_offset() const { return decode(6, 7) & 0x1FFF; }unsigned int time_to_live() const { return rep_[8]; }unsigned char protocol() const { return rep_[9]; }unsigned short header_checksum() const { return decode(10, 11); }asio::ip::address_v4 source_address() const{asio::ip::address_v4::bytes_type bytes= { { rep_[12], rep_[13], rep_[14], rep_[15] } };return asio::ip::address_v4(bytes);}asio::ip::address_v4 destination_address() const{asio::ip::address_v4::bytes_type bytes= { { rep_[16], rep_[17], rep_[18], rep_[19] } };return asio::ip::address_v4(bytes);}friend std::istream& operator>>(std::istream& is, ipv4_header& header){is.read(reinterpret_cast<char*>(header.rep_), 20);if (header.version() != 4)is.setstate(std::ios::failbit);std::streamsize options_length = header.header_length() - 20;if (options_length < 0 || options_length > 40)is.setstate(std::ios::failbit);elseis.read(reinterpret_cast<char*>(header.rep_) + 20, options_length);return is;}private:unsigned short decode(int a, int b) const{ return (rep_[a] << 8) + rep_[b]; }unsigned char rep_[60];
};#endif // IPV4_HEADER_HPPping.cpp
//
// ping.cpp
// ~~~~~~~~
//
// Copyright (c) 2003-2024 Christopher M. Kohlhoff (chris at kohlhoff dot com)
//
// Distributed under the Boost Software License, Version 1.0. (See accompanying
// file LICENSE_1_0.txt or copy at http://www.boost.org/LICENSE_1_0.txt)
//#include <asio.hpp>
#include <istream>
#include <iostream>
#include <ostream>#include "icmp_header.hpp"
#include "ipv4_header.hpp"using asio::ip::icmp;
using asio::steady_timer;
namespace chrono = asio::chrono;class pinger
{
public:pinger(asio::io_context& io_context, const char* destination): resolver_(io_context), socket_(io_context, icmp::v4()),timer_(io_context), sequence_number_(0), num_replies_(0){destination_ = *resolver_.resolve(icmp::v4(), destination, "").begin();start_send();start_receive();}private:void start_send(){std::string body("\"Hello!\" from Asio ping.");// Create an ICMP header for an echo request.icmp_header echo_request;echo_request.type(icmp_header::echo_request);echo_request.code(0);echo_request.identifier(get_identifier());echo_request.sequence_number(++sequence_number_);compute_checksum(echo_request, body.begin(), body.end());// Encode the request packet.asio::streambuf request_buffer;std::ostream os(&request_buffer);os << echo_request << body;// Send the request.time_sent_ = steady_timer::clock_type::now();socket_.send_to(request_buffer.data(), destination_);// Wait up to five seconds for a reply.num_replies_ = 0;timer_.expires_at(time_sent_ + chrono::seconds(5));timer_.async_wait(std::bind(&pinger::handle_timeout, this));}void handle_timeout(){if (num_replies_ == 0)std::cout << "Request timed out" << std::endl;// Requests must be sent no less than one second apart.timer_.expires_at(time_sent_ + chrono::seconds(1));timer_.async_wait(std::bind(&pinger::start_send, this));}void start_receive(){// Discard any data already in the buffer.reply_buffer_.consume(reply_buffer_.size());// Wait for a reply. We prepare the buffer to receive up to 64KB.socket_.async_receive(reply_buffer_.prepare(65536),std::bind(&pinger::handle_receive, this, std::placeholders::_2));}void handle_receive(std::size_t length){std::cout << "handler recv len: " << length << std::endl;// The actual number of bytes received is committed to the buffer so that we// can extract it using a std::istream object.reply_buffer_.commit(length);// Decode the reply packet.std::istream is(&reply_buffer_);ipv4_header ipv4_hdr;icmp_header icmp_hdr;is >> ipv4_hdr >> icmp_hdr;// We can receive all ICMP packets received by the host, so we need to// filter out only the echo replies that match the our identifier and// expected sequence number.if (is && icmp_hdr.type() == icmp_header::echo_reply&& icmp_hdr.identifier() == get_identifier()&& icmp_hdr.sequence_number() == sequence_number_){// If this is the first reply, interrupt the five second timeout.if (num_replies_++ == 0)timer_.cancel();// Print out some information about the reply packet.chrono::steady_clock::time_point now = chrono::steady_clock::now();chrono::steady_clock::duration elapsed = now - time_sent_;std::cout << length - ipv4_hdr.header_length()<< " bytes from " << ipv4_hdr.source_address()<< ": icmp_seq=" << icmp_hdr.sequence_number()<< ", ttl=" << ipv4_hdr.time_to_live()<< ", time="<< chrono::duration_cast<chrono::milliseconds>(elapsed).count()<< std::endl;}start_receive();}static unsigned short get_identifier(){
#if defined(ASIO_WINDOWS)return static_cast<unsigned short>(::GetCurrentProcessId());
#elsereturn static_cast<unsigned short>(::getpid());
#endif}icmp::resolver resolver_;icmp::endpoint destination_;icmp::socket socket_;steady_timer timer_;unsigned short sequence_number_;chrono::steady_clock::time_point time_sent_;asio::streambuf reply_buffer_;std::size_t num_replies_;
};int main(int argc, char* argv[])
{try{if (argc != 2){std::cerr << "Usage: ping <host>" << std::endl;
#if !defined(ASIO_WINDOWS)std::cerr << "(You may need to run this program as root.)" << std::endl;
#endifreturn 1;}asio::io_context io_context;pinger p(io_context, argv[1]);io_context.run();}catch (std::exception& e){std::cerr << "Exception: " << e.what() << std::endl;}
}IPv6
2110🔢1234
RIP,IP组播
一种分布式的、基于距离向量的路由选择协议。
IP组播是一种网络通讯方法,允许主机将数据报发送给多个接收者而不需要为每个接收者单独发送数据。与单播相比,在一对多的通讯中,组播可大大节约网络资源。源主机把单个分组发送给一个组播地址,该组播地址标识一组地址,网络把这个分组的副本投递给该组中的每台主机。因特网中的IP组播也使用组播组的概念,每个组都有一个特别分配的地址,使用这个地址作为分组的目标地址。主机使用IGMP协议加入组播组,使用该协议通知本地网络上的路由器要接收某个组播的分组的愿望。当分组到达目的局域网时,由于局域网具有硬件多播功能,因此不需要复制分组,在局域网上的多播组成员都能收到这个视频分组。
- 在互联网范围的组播要靠路由器来实现,这些路由器必须增加一些能够识别组播数据报的软件。能够运行多播协议的路由器称为组播路由器。组播路由器也可以转发普通的单播IP数据报。
- 组播只能使用UDP,是“尽最大努力的交付”,不保证能够交付组播内的所有成员。TCP是一个面向连接的协议,只能一对一发送数据。
- IP组播地址:
- 组播的标识符就是IP地址中的D类地址。D类地址的前四位是1110,范围是244.0.0.0到239.255.255.255
- 并非所有的D类地址都可以作为组播地址
- 多播数据报和一般的IP数据包的区别就是它使用D类IP地址作为目的地址,并且首部中的协议字段值是2,表明使用网际组管理协议IGMP
- 组播地址只能用于目的地址而不能用于源地址
- 对组播数据报不产生ICMP差错报文。若在ping命令后面键入组播地址,将永远不会收到响应
- IP组播分两种. 1.本地局域网 2.互联网
- 本局域网上进行硬件多播。以太网MAC地址中的第一字节的最低位为1时即为组播地址。IANA的以太网组播地址范围:01-00-5E-00-00-00到01-00-5E-7F-FF-FF可见只有23位可用作组播,和D类IP地址中的23位有一一对应关系。D类IP地址可供分配的有28位,在这28位中,前5位不能用来构成以太网的硬件地址。
- 互联网范围内进行多播。要使路由器直到组播成员的信息,就要使用因特网组管理协议Internet Group Management Protocol,IGMP。它让连接到本地局域网上的组播路由器直到本局域网上是否有主机参加或退出了某个组播组。要是连接到局域网上的组播路由器和因特网上的其他组播路由器协同工作,以便把组播数据包用最小代价传送给所有组成员,就要使用组播路由选择协议
传输层
- 硬件端口:是不同硬件设备进行交互的接口
- 软件端口:是应用层的各种协议进程与运输实体进行层间交互的地点
- 传输层使用的是软件端口
- 端口号是为了标志本计算机应用层中的各个进程在和运输层交互时的层间接口
UDP仅在IP的数据报服务之上增加了两个最基本的服务:复用分用,差错检测。UDP特点:
- 无连接
- 不保证可靠
- 面向报文的
- 没有拥塞控制
- 一对一、一对多、多对一和多对多的交互通信
- 首部开销小,只有8个字节
+-----------------------------+
| 16位源端口号 | 16位目的端口号 |
| 16位UPD长度 | 16位UDP校验和 |
+-----------------------------+
| data |端口1 端口2 端口3^ ^ ^| | |+-------+--------+|UDP分用^|IP层
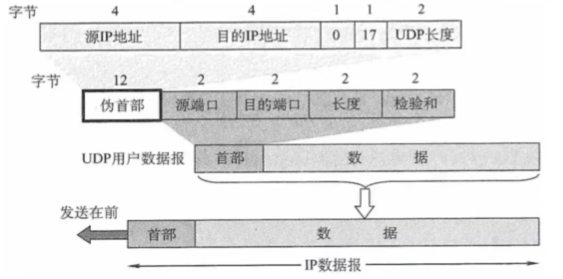
UDP校验
在计算校验和时,要在UDP数据报之前增加12B的伪首部:
- 伪首部只是在计算校验和时临时添加在UDP数据报的前面,得到一个临时的UDP数据报;
- 校验和就是按照这个临时的UDP数据报来计算的;
- 伪首部既不向下传送又不向上递交,而只是为了计算校验和;
UDP计算校验和的方法和计算IP数据报首部检验的方法相似。但不同的是:IP数据报的检验和只检验IP数据报的首部,但UDP的检验和是把首部和数据部分一起都检验。
TCP是面向连接,点对点,可靠交付,全双工,面向字节流的流式协议。
TCP首部 20B固定部分+可变部分,建立连接(通讯双方确认对方存在;协商参数;实体资源分配)、数据传送、连接释放
TCP可靠性(校验、序号、确认、重传)
TCP流量控制、拥塞控制
- 流量控制服务用于消除发送方发送数据太快,从而使接收方缓冲区溢出的可能性
- TCP提供一种基于滑动窗口协议的流量控制机制
- 发送窗口大小 = min[rwnd, cwnd]: 接收窗口rwnd,接收方根据目前接收缓存大小来确定的最新窗口值,反应接收方的容量;拥塞窗口cwnd,发送方根据自己估算的网络拥塞程度而设置的窗口值,反应网络的当前容量,只要网络未出现拥塞,拥塞窗口就再大些,以便把更多的分组发送出去;但只要网络出现拥塞,拥塞窗口就减小些,以减少注入网络的分组数。
- 拥塞控制算法:慢开始,拥塞避免,快重传,快恢复
应用层
客户-服务(C/S)模型
- 客户程序:被用户调用后运行,在通讯时主动向服务器发起通讯,客户程序必须知道服务器程序的地址
- 服务器程序:专门用来提供某种服务,持续运行,被动的等待并接受来自客户的通讯请求
- 常见的C/S模型的应用包括web、DHCP、FTP、远程登陆、电子邮件
- 网络中计算机地位不平等,服务器管理用户权限,使客户机不能随意存储/删除数据或进行其他受限的网络活动;整个网络的管理工作由少数服务器担当,集中和方便;客户机之间不直接通讯;可扩展性不佳,服务器硬件和网络带宽的限制,服务器支持的客户机数量有限
- B/S方式(Browser/Server方式),即浏览器-服务器方式,是C/S的一种特例
对等(P2P)模型
对等连接(peer-to-peer)指两个主机在通讯时不区分服务请求放和服务提供方。对等连接方式从本质上看仍然是使用CS方式,只是对等连接中的每一个主机即是客户又是服务器。
- 常见P2P模型应用:PPlive、Bittorrent、电驴
DNS系统
- 互联网的域名系统为联机分布式数据库系统,采用客户服务。
- DNS协议运行在UDP之上,使用53号端口
- 三级域名.二级域名.顶级域名
- 顶级域名分为国家顶级域名、通用顶级域名(com公司、 net网络服务机构、 org非盈利组织)
www
- 万维网www(world wide web)是一个大规模的、分布式的、联机式的信息储藏所.
- 一个有用的事务称为一个资源。这些资源由全域统一资源定位符URL标识,并通过HTTP协议发给使用者,使用者通过单击链接获取资源,www使用链接可以方便的从因特网上的一个站点访问另一个站点。HTML在此功不可没。
从输入网址到现实页面
- 浏览器解析URL
- 浏览器向DNS请求解析域名
- 域名系统解析出IP并发给浏览器
- 浏览器与服务器建立TCP连接
- 浏览器发出HTTP请求
- 服务器响应HTTP请求
- 释放TCP连接
- 浏览器解析响应并渲染web页面给用户
others
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2020/p0443r14.html
https://semver.org
C++统一执行器提案
two key components of execution: a work execution interface and a representation of work and their interrelationships. Respectively, these are executors and senders and receivers:
// make P0443 APIs in namespace std::execution available
using namespace std::execution;// get an executor from somewhere, e.g. a thread pool
std::static_thread_pool pool(16);
executor auto ex = pool.executor();// use the executor to describe where some high-level library should execute its work
perform_business_logic(ex);// alternatively, use primitive P0443 APIs directly// immediately submit work to the pool
execute(ex, []{ std::cout << "Hello world from the thread pool!"; });// immediately submit work to the pool and require this thread to block until completion
execute(std::require(ex, blocking.always), foo);// describe a chain of dependent work to submit later
sender auto begin = schedule(ex);
sender auto hi_again = then(begin, []{ std::cout << "Hi again! Have an int."; return 13; });
sender auto work = then(hi_again, [](int arg) { return arg + 42; });// prints the final result
receiver auto print_result = as_receiver([](int arg) { std::cout << "Received " << arg << std::endl; });// submit the work for execution on the pool by combining with the receiver
submit(work, print_result);// Blue: proposed by P0443. Teal: possible extensions.
clients execute work:
文件图片
88/1000实时翻译
客户执行工作:
划译
基本执行器接口是客户端执行工作的execute函数:
// obtain an executor
executor auto ex = ...// define our work as a nullary invocable
invocable auto work = []{ cout << "My work" << endl; };// execute our work via the execute customization point
execute(ex, work);
上述执行器执行完work后就结束了,用户无法和该wor交互
考虑一下如何扩展std::async以与执行器互操作,从而实现客户端对执行的控制:
template<class Executor, class F, class Args...>
future<invoke_result_t<F,Args...>> async(const Executor& ex, F&& f, Args&&... args) {// package up the workpackaged_task work(forward<F>(f), forward<Args>(args)...);// get the futureauto result = work.get_future();// execute work on the given executorexecution::execute(ex, move(work));return result;
}
这种扩展的好处是,客户端可以从多个线程池中进行选择,通过提供相应的执行器来精确控制std::async使用哪个线程池。工作包装和提交的不便成为库的责任。
考虑一个从不阻塞调用者版本的std::async
template<executor E, class F, class... Args>
auto really_async(const E& ex, F&& f, Args&&... args) {// package up the workstd::packaged_task work(std::forward<F>(f), std::forward<Args>(args)...);// get the futureauto result = work.get_future();// execute the nonblocking work on the given executorexecution::execute(std::require(ex, execution::blocking.never), std::move(work));return result;
}
receiver, sender, scheduler
一个receiver类似回调函数,它分别为valu,error,"done"分离三个频道。
https://godbolt.org/z/dafqM-
sender
// P0443R12
std::execution::submit(snd, rec);
// P0443R13
auto state = std::execution::connect(snd, rec);
// ... later
std::execution::start(state);sender auto s = std::execution::schedule(sched);
// OK, s is a single-shot sender of void that completes in sched's execution contexttemplate<receiver R, class F>
struct _then_receiver : R { // for exposition, inherit set_error and set_done from RF f_;// Customize set_value by invoking the callable and passing the result to the base classtemplate<class... As>requires receiver_of<R, invoke_result_t<F, As...>>void set_value(As&&... as) && noexcept(/*...*/) {std::execution::set_value((R&&) *this, invoke((F&&) f_, (As&&) as...));}// Not shown: handle the case when the callable returns void
};template<sender S, class F>
struct _then_sender : std::execution::sender_base {S s_;F f_;template<receiver R>requires sender_to<S, _then_receiver<R, F>>state_t<S, _then_receiver<R, F>> connect(R r) && {return std::execution::connect((S&&)s_, _then_receiver<R, F>{(R&&)r, (F&&)f_});}
};template<sender S, class F>
sender auto then(S s, F f) {return _then_sender{{}, (S&&)s, (F&&)f};
}