ArcGISpro中的空间统计分析(二)
“分析模式”工具集
“分析模式”工具可提供对宏观空间模式进行量化的统计数据。 这些工具可以解答“数据集中的要素或与数据集中要素关联的值是否发生空间聚类?”和“聚类程度是否会随时间变化?”之类的问题,主要包括以下几个常用工具:
| 工具 | 描述 |
|---|---|
| 平均最近邻 | 根据从每个要素到其最近相邻要素的平均距离计算最近邻指数。 |
| 高/低聚类 | 使用 Getis-Ord General G 统计可度量高值或低值的聚类程度。 |
| 增量空间自相关 | 测量一系列距离的空间自相关,并选择性创建这些距离及其相应 z 得分的折线图。 z 得分反映空间聚类的程度,具有统计显著性的峰值 z 得分表示促进空间过程聚类最明显的距离。 这些峰值距离值通常适用于具有距离范围或距离半径参数的工具。 |
| 多距离空间聚类分析(Ripley's K 函数) | 确定要素(或与要素相关联的值)是否显示某一距离范围内具有统计显著性的聚类或离散。 |
| 空间自相关 | 使用 Global Moran's I 统计数据,基于要素位置和属性值测量空间自相关。 |
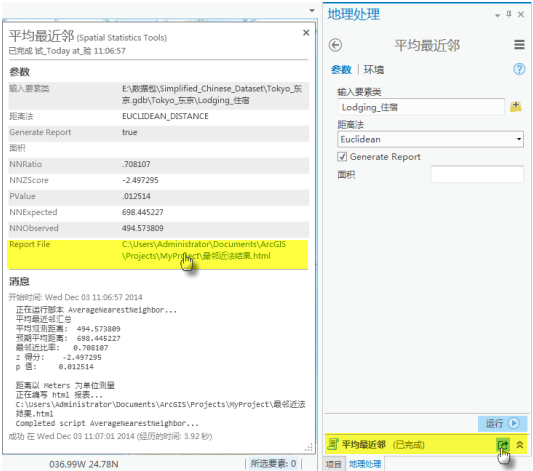
1.平均最近邻 (空间统计)
根据从每个要素到其最近相邻要素的平均距离计算最近邻指数。
如果指数(平均最近邻比率)小于 1,则表现的模式为聚类。如果指数大于 1,则表现的模式趋向于扩散。
注意:①进行平均最近邻计算之前要用投影坐标系,②对“面积”值非常敏感(面积参数值的细微变化会导致 z 得分和 p 值结果产生巨大变化)。 因此,平均最近邻工具最适用于对固定研究区域中不同的要素进行比较。
适用范围
-
评估竞争或领地:量化并比较固定研究区域中的多种植物种类或动物种类的空间分布;比较城市中不同类型的企业的平均最近邻距离。
-
监视随时间变化的更改:评估固定研究区域中一种类型的企业的空间聚类中随时间变化的更改。
-
将观测分布与控制分布进行比较:在木材分析中,如果给定全部可收获木材的分布,则您最好将已收获面积图案与可收获面积图案进行比较,以确定砍伐面积是否比期望面积更为聚类。
2.高/低聚类 (Getis-Ord General G) (空间统计)
使用 Getis-Ord General G 统计可度量高值或低值的聚类程度,简单来说就是返回一个数值反映高值或低值集聚程度。
空间权重矩阵的几种形式
全局高低聚类与全局空间自相关的区别,前者是反映高值或低值聚类程度,后者是反映整体的集聚或离散。
| 结果 | 高/低聚类 | 空间自相关 |
|---|---|---|
| p 值不具有统计学上的显著性。 | 不能拒绝零假设。要素属性值的空间分布可能是随机空间过程的结果。也就是说,所观测到的值的空间模式很可能是完全空间随机性的众多可能结果之一。 | |
| p 值具有统计学上的显著性,且 z 得分为正值。 | 可以拒绝零假设。如果基础空间过程是完全随机的,则数据集中高值的空间分布与预期的空间分布相比在空间上的聚类程度更高。 | 可以拒绝零假设。如果基础空间过程是完全随机的,则数据集中高值和/或低值的空间分布在空间上聚类的程度要高于预期。 |
| p 值具有统计学上的显著性,且 z 得分为负值。 | 可以拒绝零假设。如果基础空间过程是完全随机的,则数据集中低值的空间分布与预期的空间分布相比在空间上的聚类程度更高。 | 可以拒绝零假设。如果基础空间过程是完全随机的,则数据集中高值和低值的空间分布在空间上离散的程度要高于预期。离散空间模式通常会反映某种类型的竞争过程:具有高值的要素排斥具有高值的其他要素;类似地,具有低值的要素排斥具有低值的其他要素。 |
3.增量空间自相关 (空间统计)
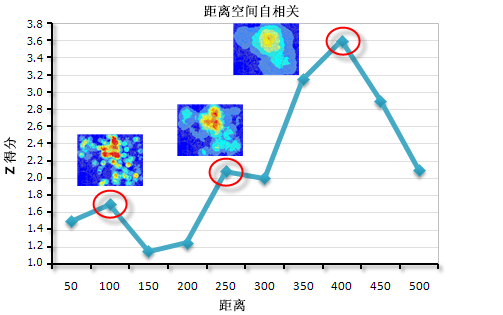
测量一系列距离的空间自相关,并选择性创建这些距离及其相应 z 得分的折线图。 z 得分反映空间聚类的程度,具有统计显著性的峰值 z 得分表示促进空间过程聚类最明显的距离。 这些峰值距离值通常适用于具有距离范围或距离半径参数的工具。
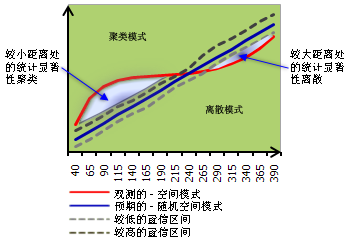
4.多距离空间聚类分析 (Ripley's K 函数) (空间统计)
确定要素(或与要素相关联的值)是否显示某一距离范围内具有统计显著性的聚类或离散。
5.空间自相关 (Global Moran's I) (空间统计)
在给定一组要素及相关属性的情况下,该工具评估所表达的模式是聚类模式、离散模式还是随机模式。 此工具将计算 Moran's I 指数值以及 z 得分和 p 值以评估该指数的显著性。 P 值是已知分布曲线下面积的数值近似值,受检验统计数据的限制。
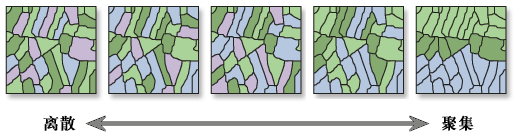
空间自相关的结果解读:
| p 值不具有统计学上的显著性。 | 无法拒绝零假设。 要素值的空间分布很可能是随机空间过程的结果。 所观测到的要素值的空间模式很可能是完全空间随机性 (CSR) 的众多可能结果之一。 |
| p 值具有统计学上的显著性,且 z 得分为正值。 | 可以拒绝零假设。 如果基础空间过程是随机的,则数据集中高值和/或低值的空间分布与预期的空间分布相比在空间上的聚类程度更高。 |
| p 值具有统计学上的显著性,且 z 得分为负值。 | 可以拒绝零假设。 如果基础空间过程是随机的,则数据集中高值和低值的空间分布在空间上离散的程度要高于预期。 离散空间模式通常会反映某种类型的竞争过程:具有高值的要素排斥具有高值的其他要素;类似地,具有低值的要素排斥具有低值的其他要素。 |
空间自相关需要注意的点:
