【漫话机器学习系列】277.梯度裁剪(Gradient Clipping)
【深度学习】什么是梯度裁剪(Gradient Clipping)?一张图彻底搞懂!
在训练深度神经网络,尤其是 RNN、LSTM、Transformer 这类深层结构时,你是否遇到过以下情况:
-
模型 loss 突然变成 NaN;
-
梯度爆炸导致训练中断;
-
训练刚开始几步模型就“失控”了。
这些问题,很多时候都是因为——梯度过大(梯度爆炸)。而应对这个问题的常见方案之一,就是本文要讲的主角:梯度裁剪(Gradient Clipping)。
一、梯度裁剪是什么?
我们先看一张图,一图胜千言:
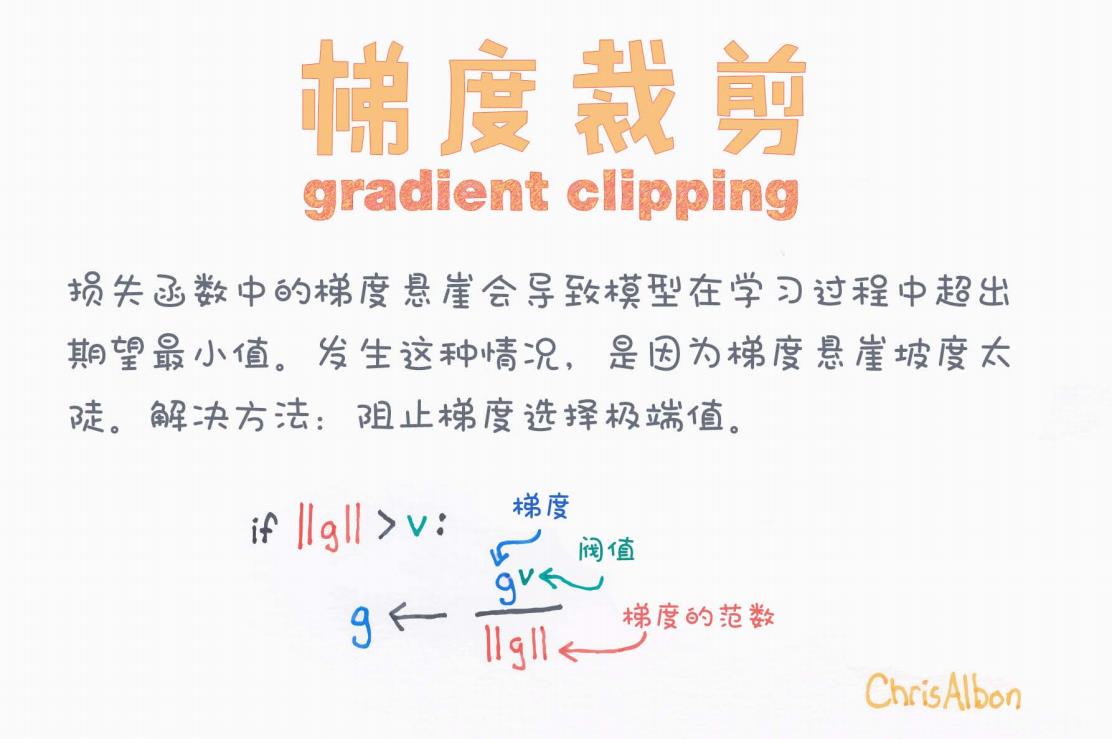
图中文字解读如下:
-
标题:梯度裁剪(Gradient Clipping)
-
说明文字:
损失函数中的梯度悬崖会导致模型在学习过程中超出期望最小值。发生这种情况,是因为梯度陡峭。解决方法:阻止梯度选择极端值。
-
图示公式:
if ‖g‖ > v:g ← (g / ‖g‖) * v意思是:
-
如果梯度的范数(即长度)大于某个阈值 v,就将梯度缩放为长度为 v 的向量。
-
这样可以防止某些参数更新过大。
-
二、为什么需要梯度裁剪?
1. 梯度爆炸的根源
在反向传播中,每一层的梯度是前面所有梯度的乘积。在深层网络中,如果这些乘积的值都 > 1,最终梯度将呈指数级增长,导致所谓的梯度爆炸(Gradient Explosion)。
表现形式:
-
loss一直上升,甚至变成NaN -
参数更新过大,模型发散
-
模型无法收敛
2. 梯度裁剪的作用
梯度裁剪并不会改变梯度的方向,它只是在梯度的模(大小)超过某个阈值时,进行缩放。这就像是给模型装了一个“刹车”系统,一旦速度过快就减速。
三、梯度裁剪的数学原理
设:
-
当前梯度为 g
-
范数为 ∥g∥
-
阈值为 v
裁剪操作如下:
也就是说:将梯度的模限制在最大值 vv 内,方向保持不变。
四、实战中如何实现梯度裁剪?
在 PyTorch 中非常简单:
import torch# 假设已经定义 optimizer 和 model
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
在 TensorFlow(Keras)中也可以:
optimizer = tf.keras.optimizers.Adam(clipnorm=1.0)
五、梯度裁剪 vs 梯度正则化
| 名称 | 作用 | 是否改变方向 |
|---|---|---|
| 梯度裁剪 | 控制梯度最大值,避免爆炸 | 否 |
| L2 正则化(权重衰减) | 防止模型过拟合,限制权重大小 | 是 |
注意:梯度裁剪是为了“救训练”,不是为了“提高精度”!
六、何时需要使用梯度裁剪?
-
训练深度模型如 RNN、LSTM、Transformer;
-
loss 出现爆炸性增长,模型训练不稳定;
-
使用高学习率训练时容易出问题;
-
模型结构复杂,层数深,非线性强。
七、调参建议
| 参数 | 建议取值 | 说明 |
|---|---|---|
| clip norm | 0.1 ~ 5 | 通常从 1.0 开始尝试,逐步调整 |
| 适用优化器 | Adam、SGD | 梯度裁剪不依赖特定优化器 |
| 使用频率 | 每次 step 前 | 每次梯度更新前裁剪 |
八、总结
梯度裁剪是深度学习中极其实用的一种 训练稳定性保障机制。它的作用不是提升模型能力,而是防止模型“发疯”。在某些模型结构中(如 LSTM、GAN),它几乎是标配操作。
一句话总结:梯度裁剪不是为了让模型跑得快,而是为了别让它翻车。
推荐阅读
-
《Deep Learning》by Ian Goodfellow(第 6 章)
-
PyTorch 官方文档:clip_grad_norm_
如果你觉得本文对你有帮助,欢迎点赞、收藏、评论~
也欢迎你分享你在训练中使用梯度裁剪的经验或踩过的坑!