c++学习之---stack,queue
目录
stack和queue的基本性质:
适配器的具象化:
1、粗略理解适配器模式:
2、适配器模式实现stack:
3、适配器模式实现queue:
deque:
作为stack和queue的底层容器 :
简要认识deque的实现原理:
1,deque的迭代器遍历:
2,deque的头插头删和尾插尾删(deque的存储结构,中控数组和缓冲区):
3,deque的随机访问:
4,deque的尴尬时刻(中间的操作)...:
编辑
priority_queue:
1,底层结构:数据结构里的堆 :
2,priorit_queue的模拟实现:
顺带对比vector和list的优劣:
继续认识STL里的三个容器,哦不,更准确的说是三个容器适配器——stack和queue以及de_queue
stack和queue的基本性质:
这俩货的性质不必多说 : stack的数据后进先出,queue的数据先进先出。但是这里的关键在于 :只要我们可以对外表现出这两种性质,那不管它底层的实现逻辑如何,也仍然可以被称为stack和queue 。
适配器的具象化:
1、粗略理解适配器模式:
拿手机充电器进行类比以便理解:
- 屏蔽底层实现细节:手机充电器如何对整流和降压、stack和queue底层使用的什么容器来实现“后进先出,先进先出”的性质我们不知道。
- 简化和同一了操作方式 :手机充电器只用插入和拔出、stack和queue只用调用符合自身性质的哪几个函数。
- 可扩展性强:手机充电器存在不同的接口协议、stack和queue底层也可以用不用的容器来实现。
- 属于外壳层:手机充电器本身不存储电,而是帮助发挥了电的功效、stack和queue本身也不存储数据,而是将底层容器的数据和操作结果体现了出来。
2、适配器模式实现stack:
stack的性质是“后进先出”,想要做到这点,只需要能够尾差尾删即可。因此底层使用vector是非常合适的。
下面的代码有两个关键点:
- 模版参数里的container默认是vector,然后在成员变量里使用了container。
- 在实现stack的相关接口时,也就是封装调用了成员变量本身的接口。比如:这里的push(),底层就是调用了contain成员变量(比如这里默认的vector)的push_back。
template<class T , class container = vector<T>>
class stack
{
public:void push(const T& val){st.push_back(val);}void pop(){st.pop_back();}T& top(){return st.back();}const T& top() const{return st.back();}void size() const{return st.size();}bool empty() const{return st.empty();}
private:container st;
};3、适配器模式实现queue:
queue的性质是“先进先出”,想要做到这一点,只要能够头删和尾插即可。这里仍然可以封装vector为底层容器,但是vector里删除头部元素会导致后面的元素向前挪动,降低效率,因此同样作为顺序容器的list成了这里的最优解。
代码如下,没有难度,重在体会适配器模式的设计思想
template<class T , class container = list<T>>class queue{public:void push(const T& val){qu.push_back(val);}void pop(){qu.pop_front();}T& front() {return qu.front();}const T& front() const{return qu.front();}bool empty() const{return qu.empty();}size_t size(){qu.size();}private:container qu;};deque:
在上面实现stack和queue时,我们还要纠结用什么底层容器实现,但其实库里已经设计好了一个兼顾vector和list的容器——deque。
作为stack和queue的底层容器 :
下面用deque作为stack的底层容器,代码没有什么改动(queue的实现也是同理),只是在模版参数里设置deque为默认的容器,同时注意使用deque本身有的接口名。
template<class T, class container = deque<T>> //使用deque作为默认的底层容器
class stack
{
public:void push(const T& val){st.push_back(val);}void pop(){st.pop_back();}T& top(){return st.back();}const T& top() const{return st.back();}void size() const{return st.size();}bool empty() const{return st.empty();}
private:container st;
};简要认识deque的实现原理:
deque的设计初衷是结合vector和list的优点,可既然同时存在了vector和list,且都是常用的容器,就说明——deque的理想破灭了.....但是,它的设计思想依然比较巧妙,且正好可以在保证效率的前提下实现同时同时满足stack和queue的需求。
1,deque的迭代器遍历:
首先,deque底层并非真的连续,而是有许多个小的连续空间组成了整体逻辑上整体连续,这样的话在插入和删除中间元素时就不用挪动所有其他数据。

其次,deque想要同时实现vector的高效访问和list的不挪数据可不容易,而他的关键法宝在于它的迭那特殊的迭代器,大致有四个成员变量:cur、first、last、node。
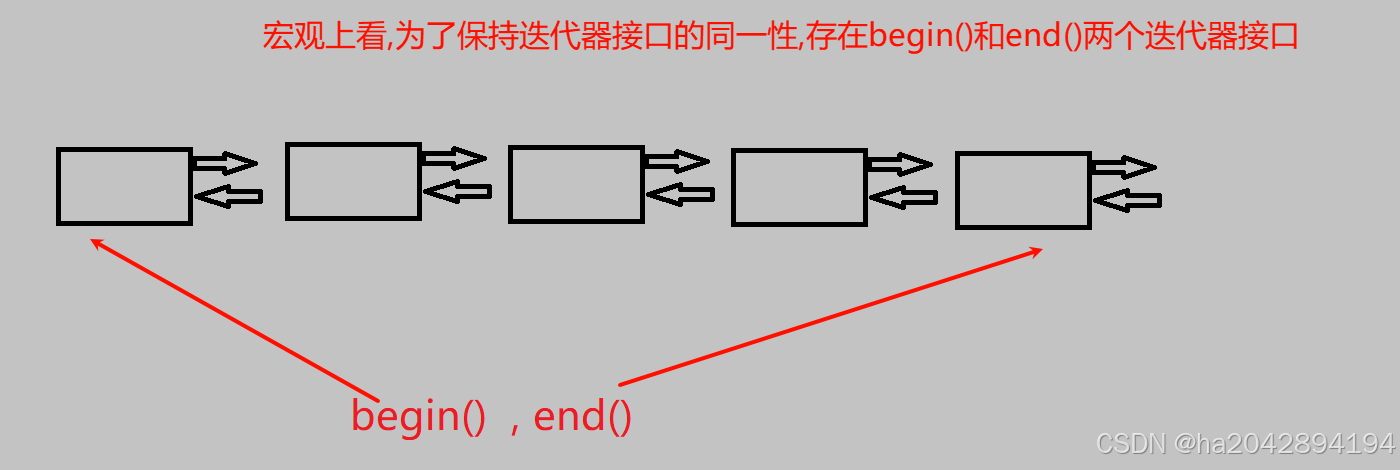
目前为止,我们大概可以知道deque的迭代器遍历遍历逻辑 : 从首迭代器begin()开始,遍历,但是每个迭代器变量内部又进行了遍历,当一个迭代器变量内的遍历逻辑结束后通过成员变量node到下一个迭代器遍历,直到最后一个迭代器。总之,和我们以往的迭代器相比,这里的迭代器变量就是各自又可以访问多个而非一个元素。
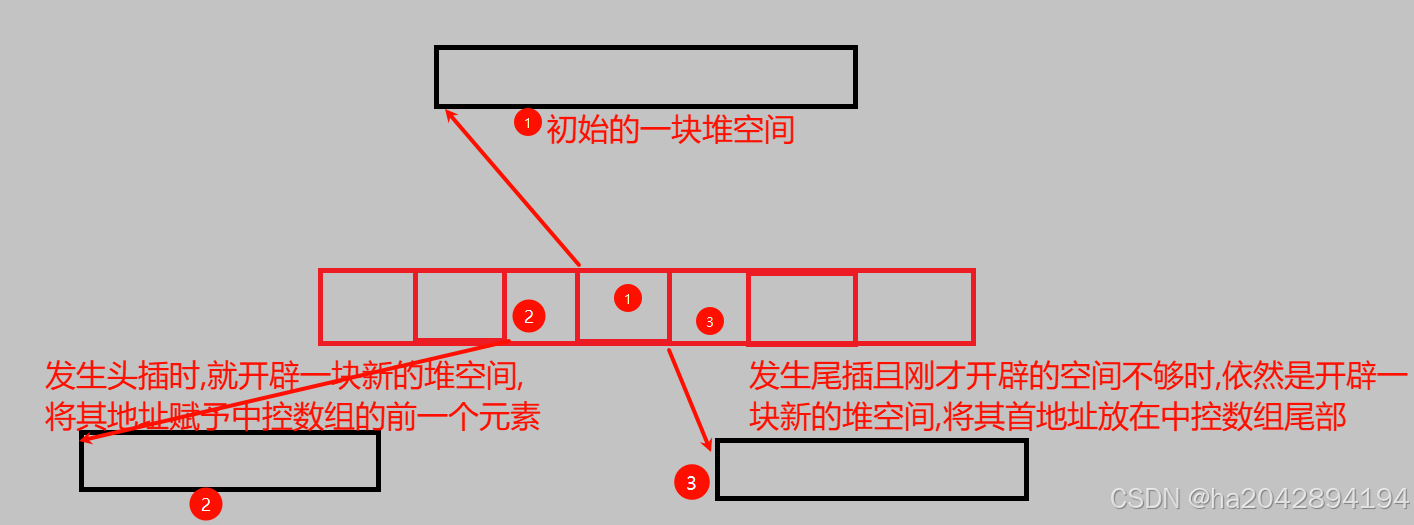
2,deque的头插头删和尾插尾删(deque的存储结构,中控数组和缓冲区):
要想了解deque头部和尾部的高效操作,首先来粗略认识其底层所用涉及的结构设计:一个用指针数组实现的中控数组,以及每个数组元素所指向的真正存放数据的缓冲区(buffer)。
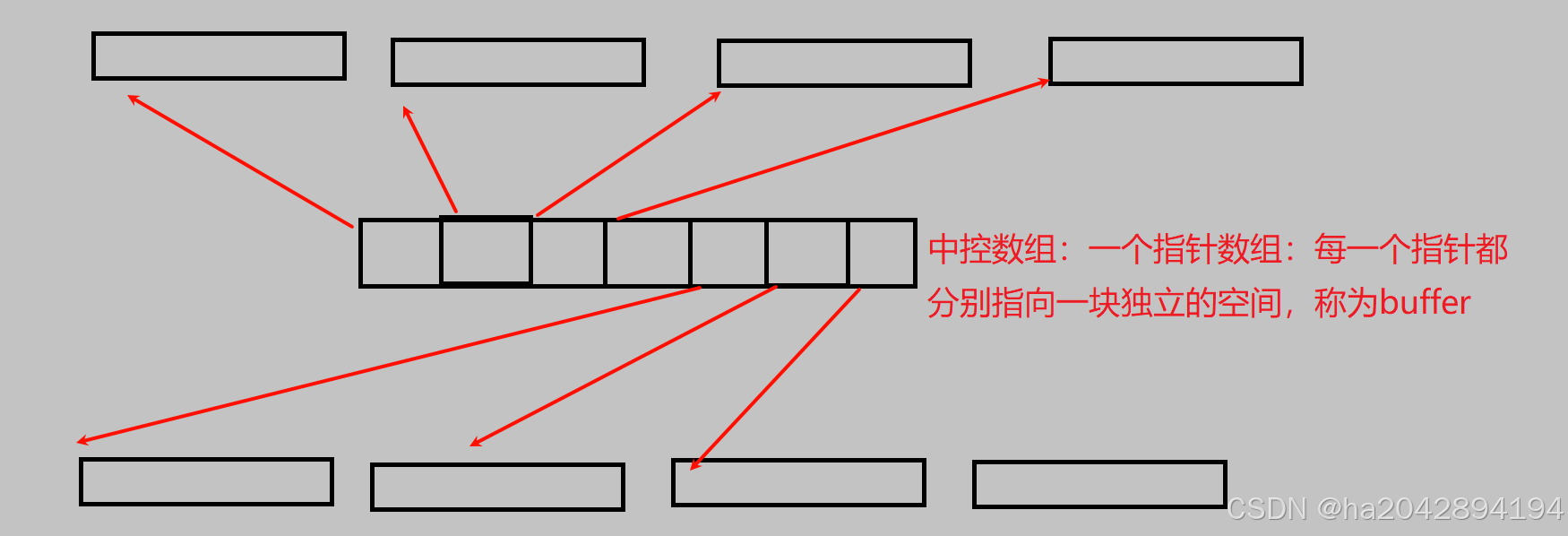
为了实现高效的头尾操作,中控数组里的指针变量的开辟往往是从中间开始,向两边扩展
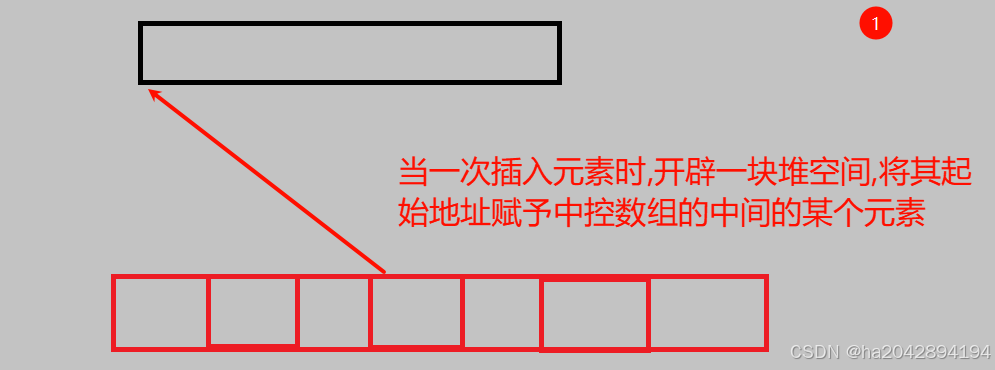
基本的存储结构我们知道了,接下来再看看如何进行头部和尾部的操作:
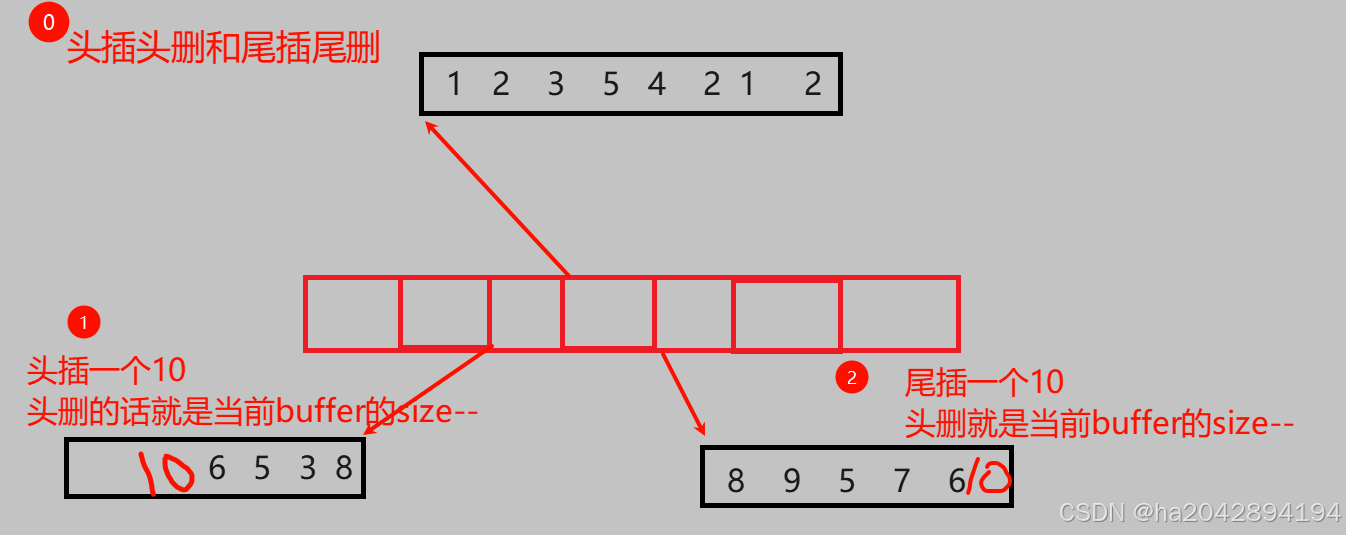
- 头插 : 每次插入时都从最左端的buffer的末尾依次往前插入,这样就避免了挪动数据.
- 头删 : 只用移除一块最左端的buffer的最左边的元素即可,由于头插的方式的特殊(从右往左),最左边也相当于这个buffer的尾部,因此同样不用挪动数据.
- 尾插和尾删 : 这俩就和vector很类似了, 就是对最左边(也就是末尾)的buffer进行插入和删除 。
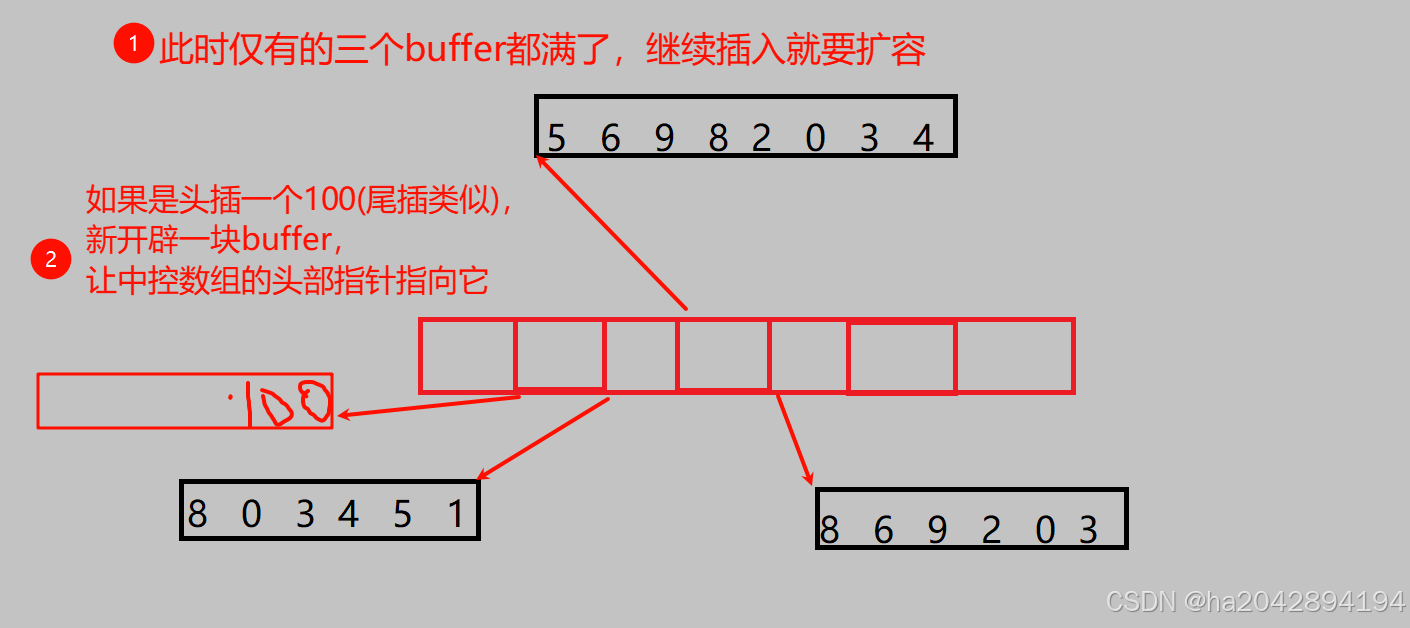
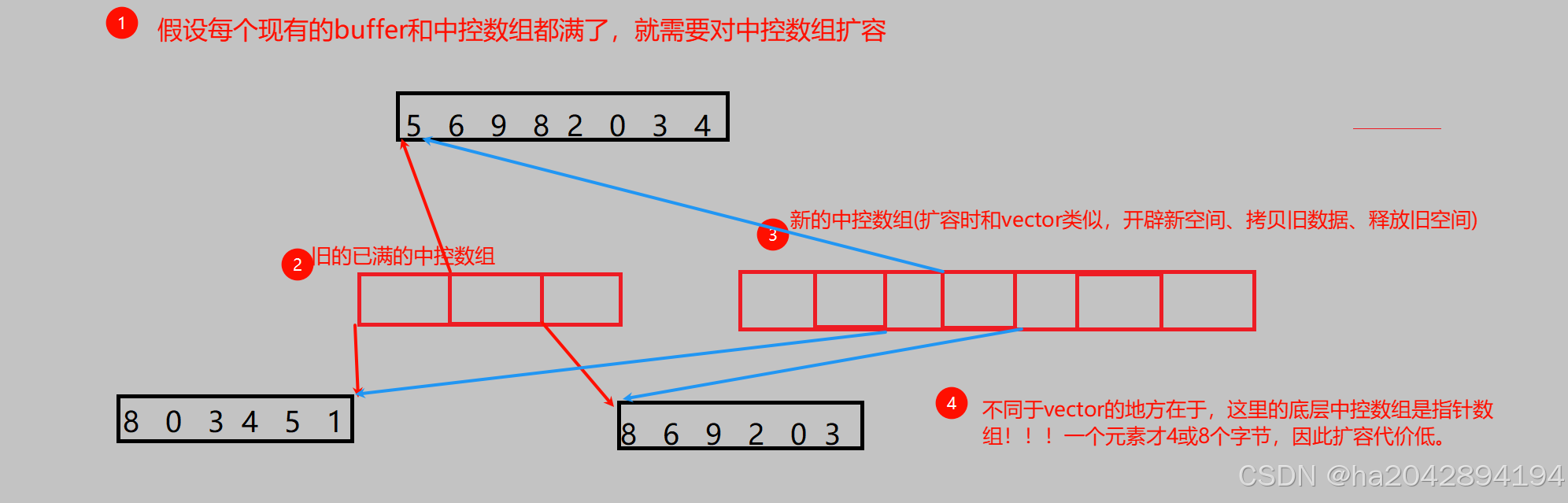
- 扩容 :这是deque优于vector的地方,对于vector,在空间不足时:开辟一整块新空间、将所有的原数据拷贝到这块新空间、销毁旧空间 , 这样会导致效率降低,甚至随着基础空间的增大,1.5倍或者2倍扩容会浪费不少空间;但是deque不同:开辟一小块新的buffer空间,让中控数组多一个元素(指针)执行此空间的起始地址。每一个buffer通过地址在逻辑上连续,但在物理空间上不一定连续,这就和list很像,因此免去了频繁扩容。当然,存放每个buffer的中控数组满了之后会扩容,但是没关系,指针数组的扩容代价极低(一个指针才4或8个字节)。
3,deque的随机访问:
上面所谈的是和容量相关的内容,这里谈一个访问操作——即deque如何实现高效的随机访问!!!答案是咱属性的 % 和 / 这俩运算符。
由于逻辑层面连续的deque底层是由许多不连续的buffer组成 , 因此每一个buffer的大小就很有讲究了——每一个都是一样的!!!
假设每一个buffer可以存放4个元素,总共有四个buffer ,那如果我要访问第13个元素:
首先,13 / 4 得到目标元素在第几个buffer;其次,13%4得到目标元素在这个buffer第几个位置 。13/4 = 3 , 因此是第三个buffer;13%4 = 1 , 因此是第三个buffer的第一个元素。
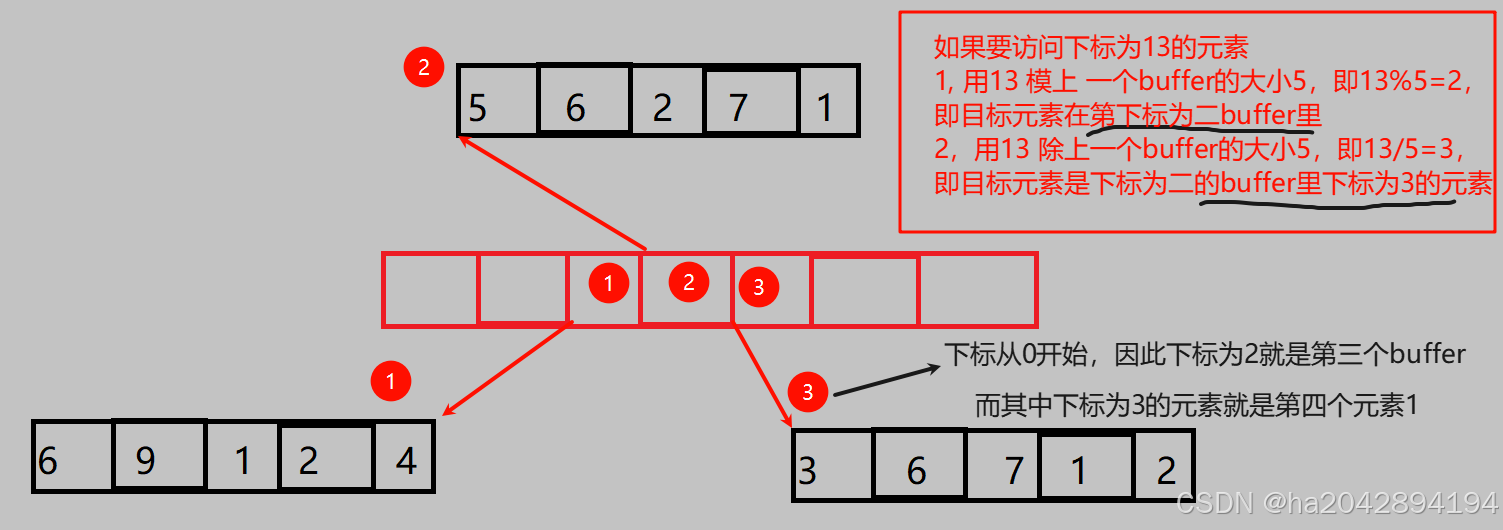
哈哈哈,是不是特别简单。但是别急着高兴,还记不记得我们说过:头插的元素是从右往左来填充第一个buffer的,而我们默认的下标计算逻辑是从左往右,这就很难搞,但是终归是用解决方案的——

4,deque的尴尬时刻(中间的操作)...:
通过上面的一系列认识,是不是感觉deque势如破竹,仿佛可以拳打vector、脚踢list了???哈哈哈哈哈,这里属于是先扬后抑,起始deque也有它的局限之处。
deque的头部和尾部的操作确实很棒:既有vector下标访问的高效和成块空间的较高缓存利用率,也有list中数据分块而避免的扩容和挪动数据的性能损耗。
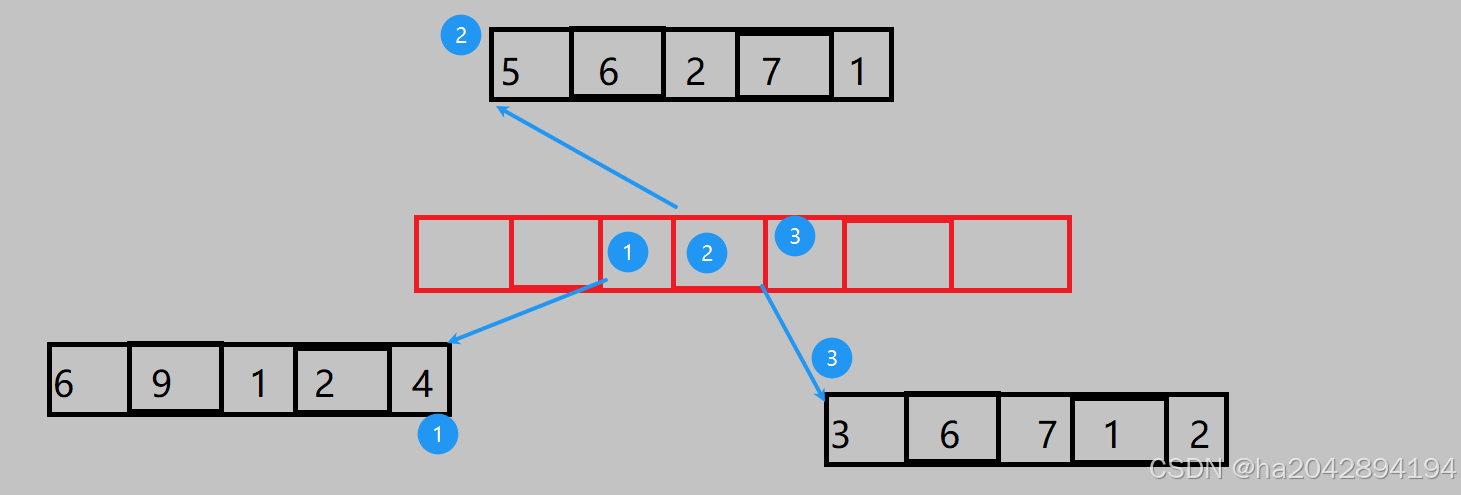
但是,但是,如果在中间进行操作会如何呢???
下图中用三个buffer,如果我要在第三个buffer里插入数据,会发生啥?当然是扩容,那么如何扩容就成了这里的痛点!!!
- 一种方法就是单独扩容第二个buffer,比如从空间为5扩容到10,只用为这单独的一个buffer来 新建空间、拷贝数据、释放空间。嗯,似乎依然比较高效,可是,deque的随机访问高度依赖固定的buffer大小。如果buffer大小不一致,随机访问的效率就崩了,所以不能因小失大,单独扩容buffer——行不通
- 第二种方法,也是STL官方库才用的办法,就是放到其他的buffer里。比如这里的第二个buffer满了,那就放到第三个buffer里,可是第单个buffer依然满了。因此,对于中间插入,就得另开一个buffer,并将他的首地址放到中控数组里,因此中控数组需要进行挪动数据甚至是开辟、拷贝、销毁三部曲(中控数组也满了的情况),好在中控数组的元素是指针,数据量不大,性能的损耗可以勉强可以接受。
- 当然了,这只是中间插入,中间删除的话也比较复杂。和中间插入一样,还得判断是对中间的buffer进行操作还是对头尾的buffer进行操作,以及一系列挪动数据和扩容带来的性能损耗,就不过多赘述了,总之,deque不适合在中间进行操作!!!
priority_queue:
1,底层结构:数据结构里的堆 :
浅浅的回顾一下堆的概念:
- 逻辑层面上来讲,堆是一个完全二叉树
- 物理层面上来讲,堆可以用数组来存储数据,通过下标操作来高效的访问数据
- 父节点下标*2+1 = 左孩子节点下标;父节点下标*2+2 = 右孩子节点 下标; (孩子节点下标-1)/ 2 = 父节点下标。
二priorit_queue同样是容器适配器,底层使用vector就很合适,毕竟涉及大量的下标随机访问.
2,priorit_queue的模拟实现:
priorit_queue作为容器适配器,只用对外提供相关的接口,底层用什么实现的就看我们自己啦.
- 底层容器肯定首选vector,为了支持大量的下标随机访问.
- 尾插就直接调用vector的尾插,然后调用咱自己写的向上调整算法.
- 头删需要交换vector首尾元素,然后调用vector的尾删,接着调用咱们自己写的向下调整算法,维持堆的性质.(直接头删会导致大量的数据挪动)
- 其他的函数接口,诸如size(),empty(),top()就很简单啦,直接调用底层vector相关的功能相同的接口即可
//实现小于比较的仿函数template<class T>struct less{bool operator()(const T& left, const T& right) const{return left < right;}};//实现大于比较的仿函数template<class T>struct more{bool operator()(const T& left, const T& right) const{return left > right;}};//堆template<class T , class compare = less<T>> //默认大堆class heap{public:void adjust_up(vector<T>& con){int size = con.size() ;int child = size - 1;int parent = (child - 1) / 2;while (parent >= 0){if (compare()(con[parent], con[child])) //默认大堆{std::swap(con[parent], con[child]);child = parent;parent = (child - 1) / 2;}else{break;}}}void adjust_down(vector<T>& con ,size_t parent,size_t size){//int size = con.size();while (parent*2+1 < size){//确定子节点int child = 2 * parent + 1;if (child + 1 < size && compare()(con[child], con[child + 1])){child += 1;}//比较父子if (compare()(con[parent], con[child])){std::swap(con[parent], con[child]);parent = child;}else{break;}}}void push(const T& val){self.push_back(val);adjust_up(self);}void pop(){std::swap(self.front(), self.back());self.pop_back();adjust_down(self,0);}T& top(){return self.front(); }const T& top() const{return self.front(); }size_t size() const{return self.size();}bool empty() const{return self.empty();}//自己给自己配一个打印void print(){for (auto au : self){cout << au << " ";}cout << endl;}////给自己配一个堆排序void HeapSort(vector<T>& con){//建堆for (int parent = (con.size() - 1 - 1) / 2; parent >= 0; parent--){adjust_down(con, parent,con.size());}//排序for (int end = con.size() - 1; end > 0; ){std::swap(con[0], con[end]);end -= 1;adjust_down(con, 0 , end);}}private:vector<T> self;};顺带对比vector和list的优劣:
deque的设计初衷是为了取代vector和list,也就是兼顾vector和list的优势 . 但从适配stack和queue的角度来说它成功了,但是在更加普遍和广泛的情况下还是vector和list这俩更专精的容器更具优势,更能在各自的领域发光发热(当然也少不了他俩合作的情况).
文章的最后 , 大致的梳理一下vector和list各自的优势和劣势,并将其以表格的形式来做对比...
| vector | list | |
| 随机访问的效率 | 连续内存,支持O(1)直接访问,奇快无比 | 需要遍历节点,O(N)的访问效率,稍稍逊色 |
| 缓存利用率 | CPU读取内存通常一块一块的,而底层的数组也是连续的,因此CPU一次可以访问到更多的内容,美其名曰:缓存利用率高 | 每一个元素的空间都是独立的,CPU一次只能访问一个,所以:缓存利用率低 |
| 中间操作(插入或删除)的效率 | 底层是数组,因此会涉及挪动数据,O(N)的时间复杂度效率较低 | 各个数据独立互不影响,仅仅更改前后节点的指针,O(1)的时间复杂度效率高 |
| 扩容与否 | 一段连续空间,存在容量的概念.空间满时 : 开辟、拷贝、销毁 三件套。拖累效率,且在基础容量较大时的1.5或两倍扩容会浪费空间 | 每个节点独立,无空间的概念,不存在扩容 |