CAU人工智能class6 ResNet
一朵乌云
现有的研究证明,加深神经网络深度可以得到更好的效果

但是随着网络层数的增加,即使解决或缓解了以上存在的问题,仍然有一朵乌云挥之不去。
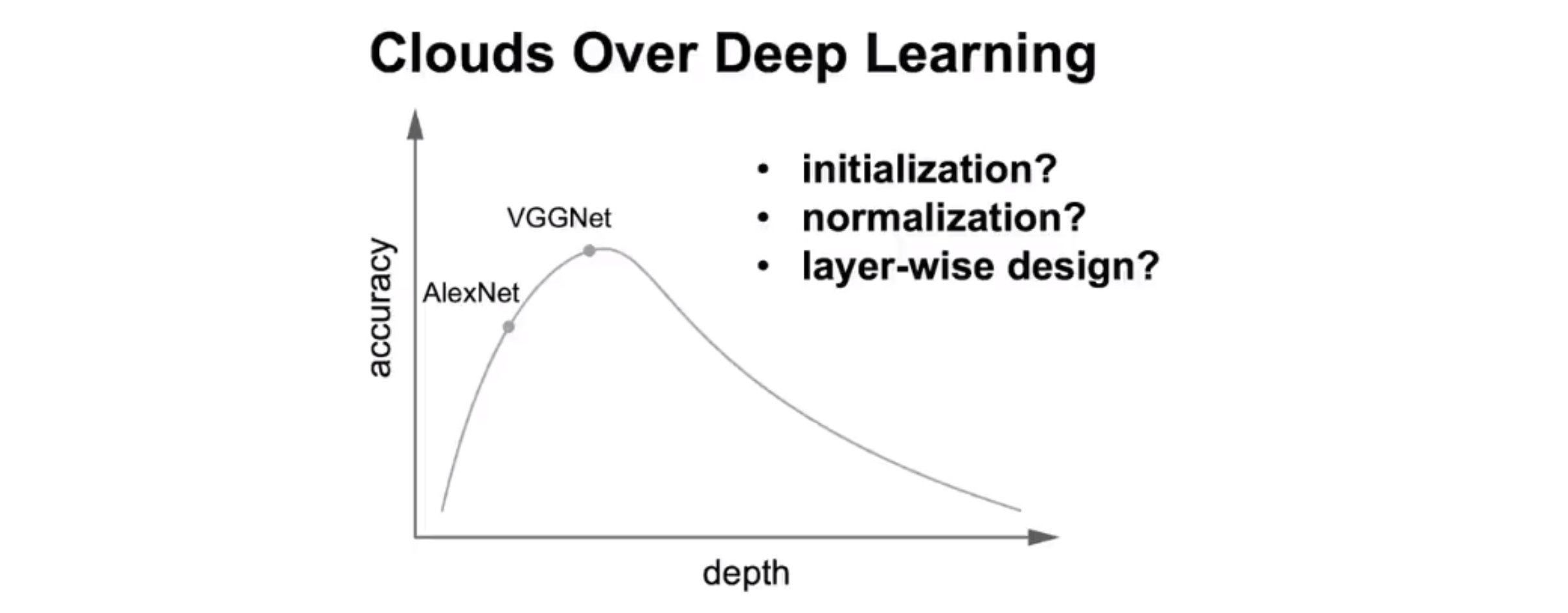
退化问题!
ResNet
ResNet最重要之处就是提出了残差学习。
退化问题
退化问题:随着网络深度的增加,准确率达到饱和(不足为奇),然后迅速退化。训练误差和测试误差都降低。
但是退化不是由过拟合导致的,
为什么?
因为在过拟合中,训练 𝐿𝑜𝑠𝑠 是一直减小的,但在测试数据或新数据上的误差很大
恒等映射
研究退化问题要先研究这样一个问题:
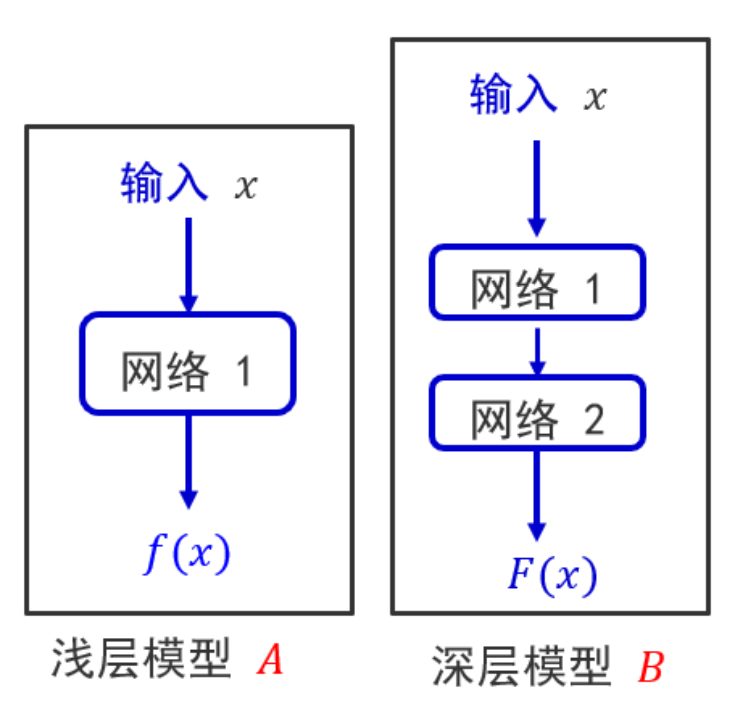
考虑一个浅网络架构和一个此基础上增加了更多层的深网络架构。
比如在A层上加上网络2,那么那么B产生的训练误差应不高于A,但在实践中并非如此。
在实际中训练出的效果更差,这是由于冗余的网络层学习了不是恒等映射的参数。
恒大映射就是:网络2 层什么也不学习,仅仅复制网络1 层的特征
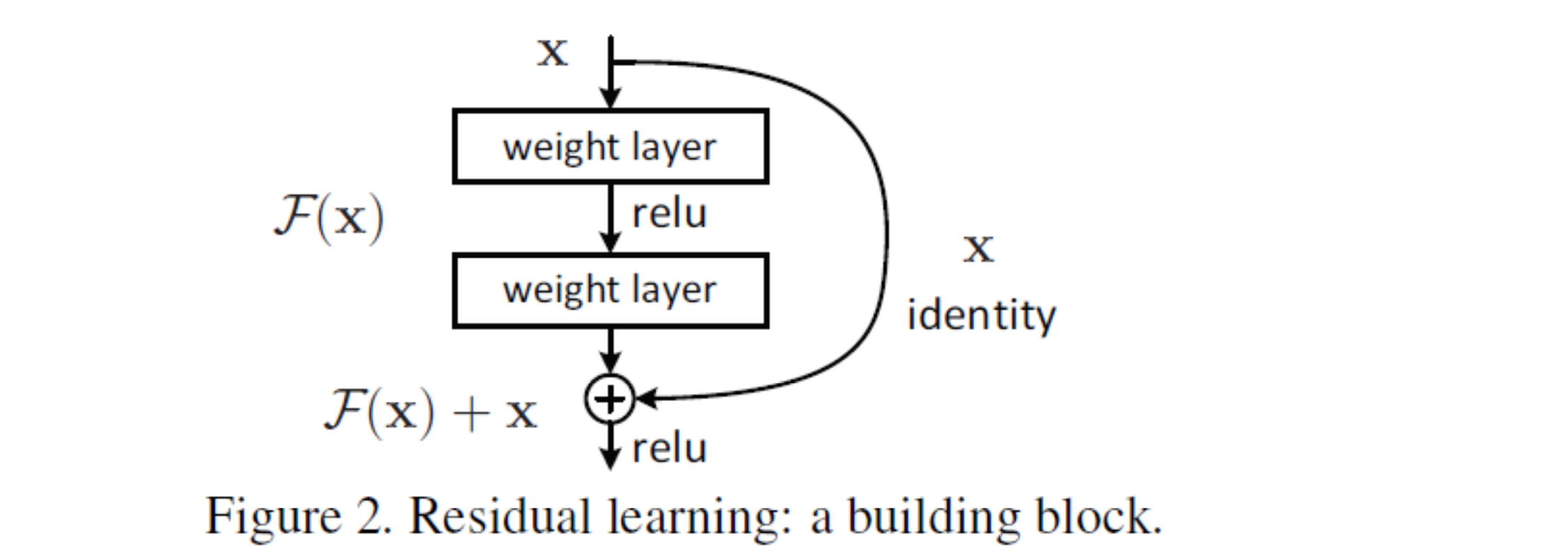
残差学习

残差学习:只训练上一层输入与真实值的差距,而不训练输出值整体。


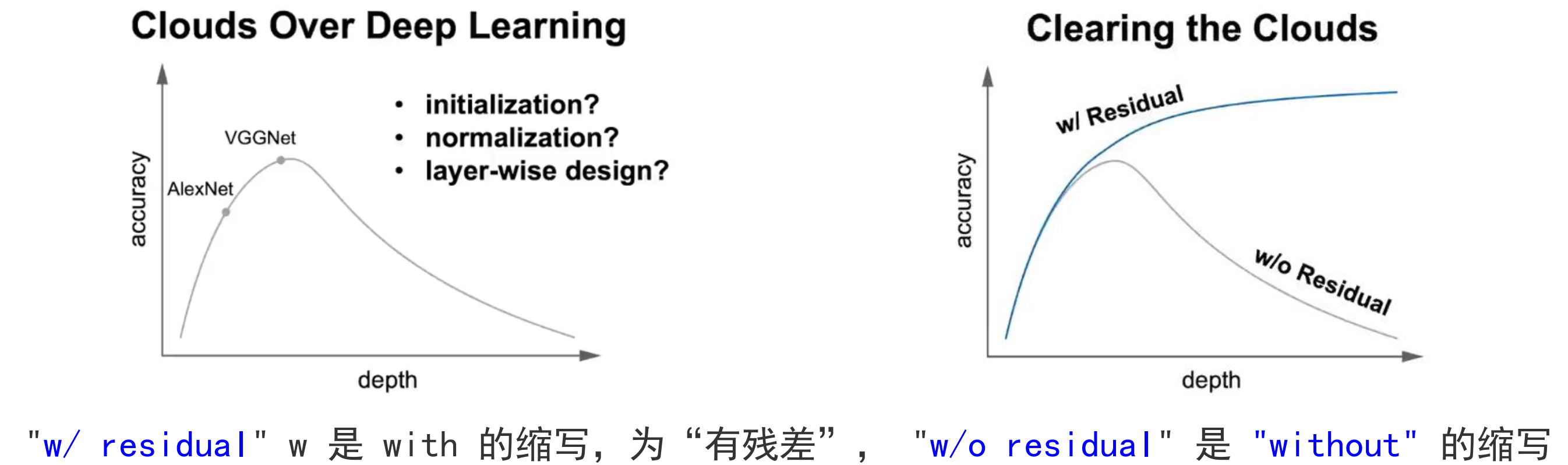
这样的情况下,就可以用𝐹 𝑥 = 0(容易训练)来代替𝐻(𝑥) = 𝑥 (恒等映射)(困难训练)

可以从上图看到,加入残差学习后深层网络(红线)的错误率开始低于浅层网络(蓝线),且右边相较于左边总体错误率更低。
问题解决:
优点:
- 更短的优化路径:
- 避免了梯度消失的问题:里层的参数计算梯度时是多次求偏导的结果,当偏导小于1时会越乘越小,最后趋近于0,为了避免这种情况采用f(x) + x的形式可以保证求偏导的结果至少大于1.
同纬度映射
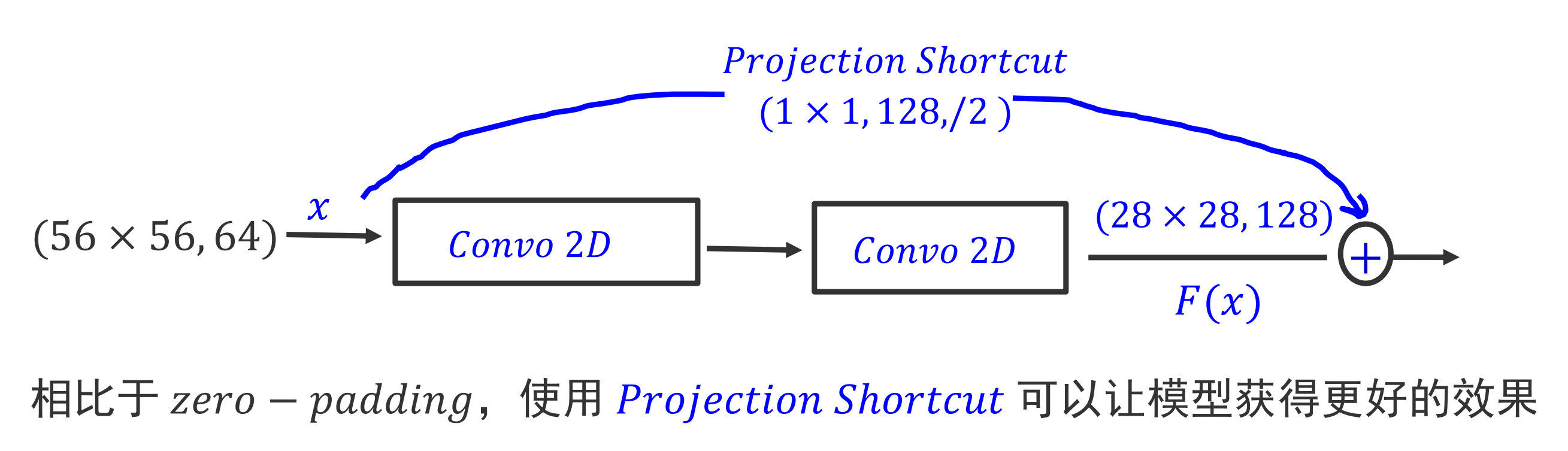
残差连接有个问题就是跨层连接时输入与输出的形状不一样怎么办?

解决方法:
- 边界填充(选择 𝑧𝑒𝑟𝑜 − 𝑝𝑎𝑑𝑑𝑖𝑛𝑔 ):一般输入特征图维度(尺寸)经过卷层以后会变小,希望卷积计算保持输入特征图尺寸不变,可以做边界填充(选择 𝑧𝑒𝑟𝑜 − 𝑝𝑎𝑑𝑑𝑖𝑛𝑔 )
- 投影快捷方式(𝑃𝑟𝑜𝑗𝑒𝑐𝑡𝑖𝑜𝑛 𝑆ℎ𝑜𝑟𝑡𝑐𝑢𝑡):具体做法用步长 2,大小为 1 × 1 的卷积来对残差块的输入信号进行特征提取,使得 𝑥 信号和 𝐹 信号的 𝑠ℎ𝑎𝑝𝑒 一致
(更常用)
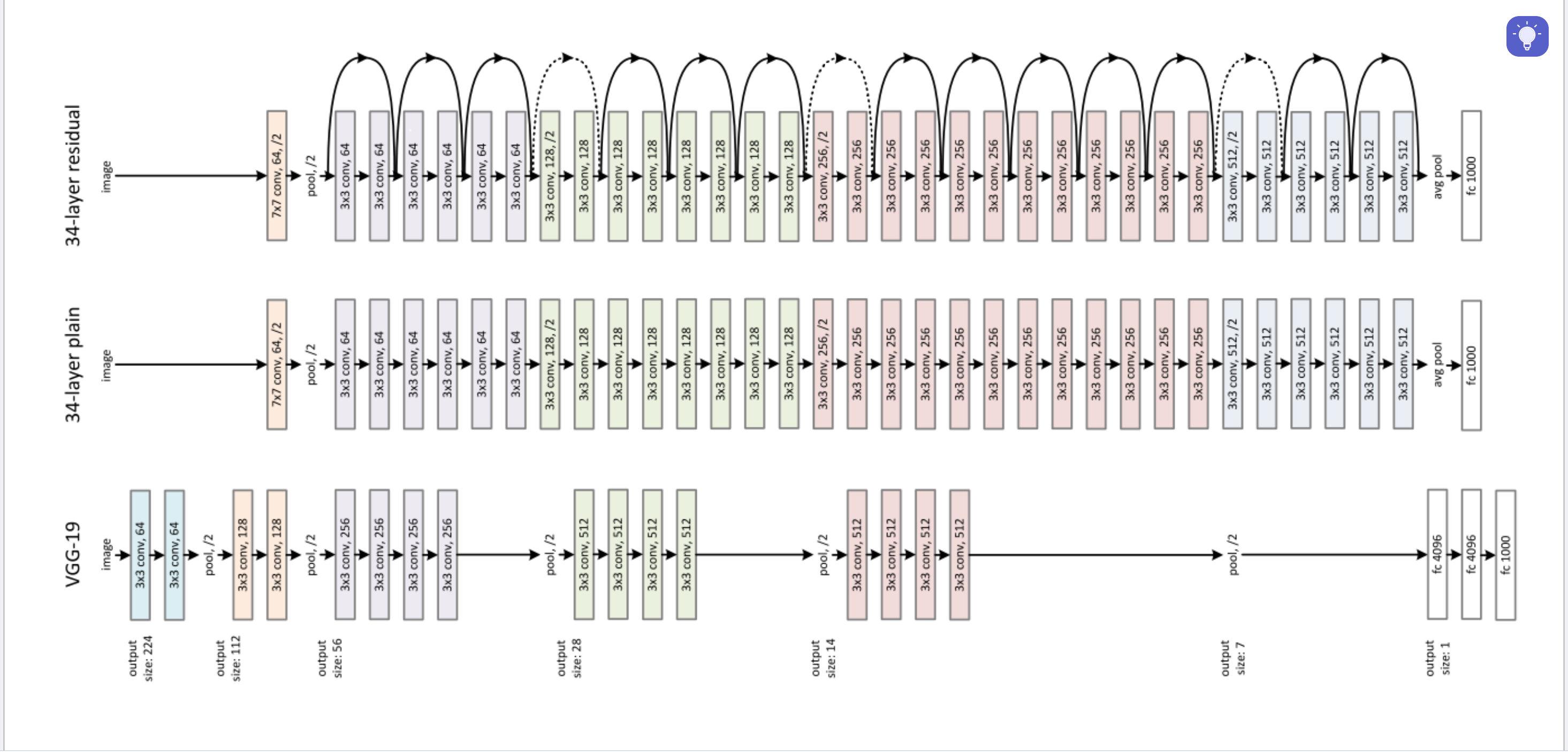
网络结构
ResNet在vgg19的基础上进行了修改。
理解网络前先引入两个概念
building Block 块(积木块)
浅层网络中(ResNet-18/34)使用
瓶颈设计(bottleneck design)
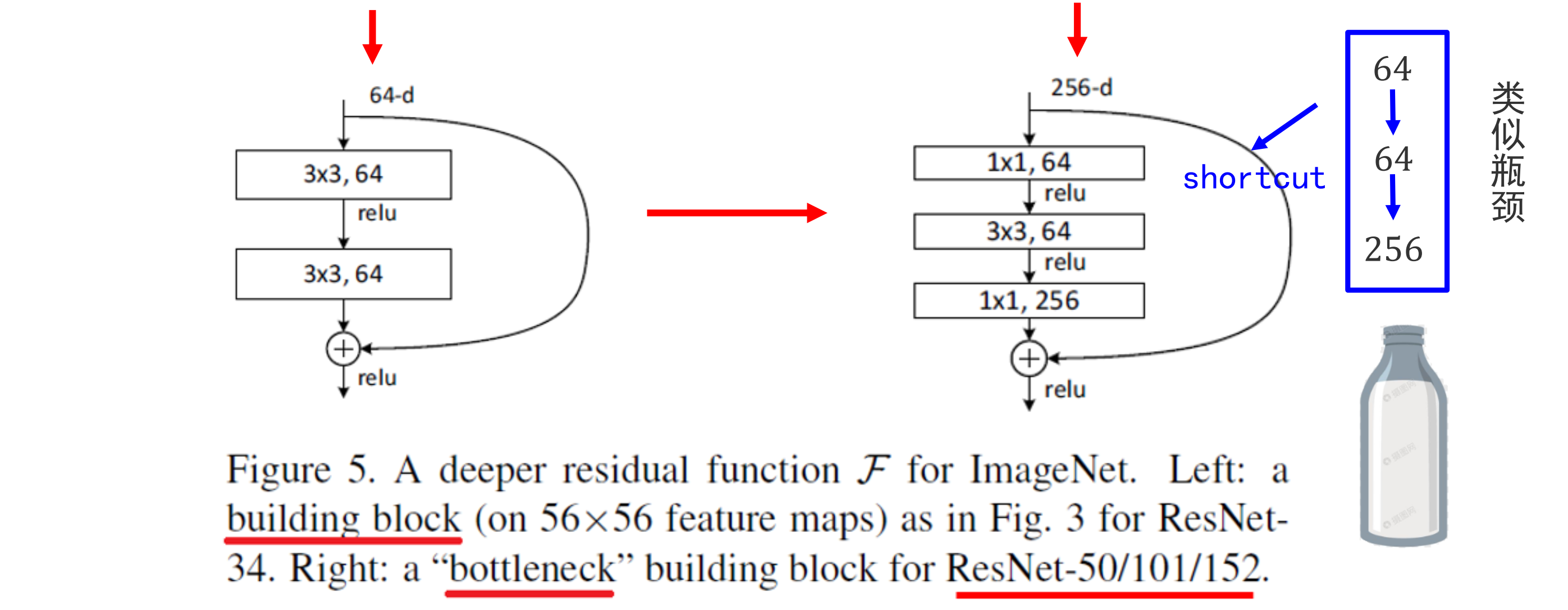
首端和末端的 1 × 1 卷积用来削减和恢复维度(通道数量),先消减通道再卷积比直接卷积参数更少,效果基本不变。
参数更少,因此适合深层模型的学习(ResNet-50, ResNet-101, ResNet-
152)。
具体实现

ResNet 变种 – DenseNet
CVPR 2017 最佳论文提出了 DenseNet(Dense Convolutional Network)。DenseNet 吸收了 ResNet 最精华的部分,并在此上做了更加创新的工作,使得网络性能进一步提升
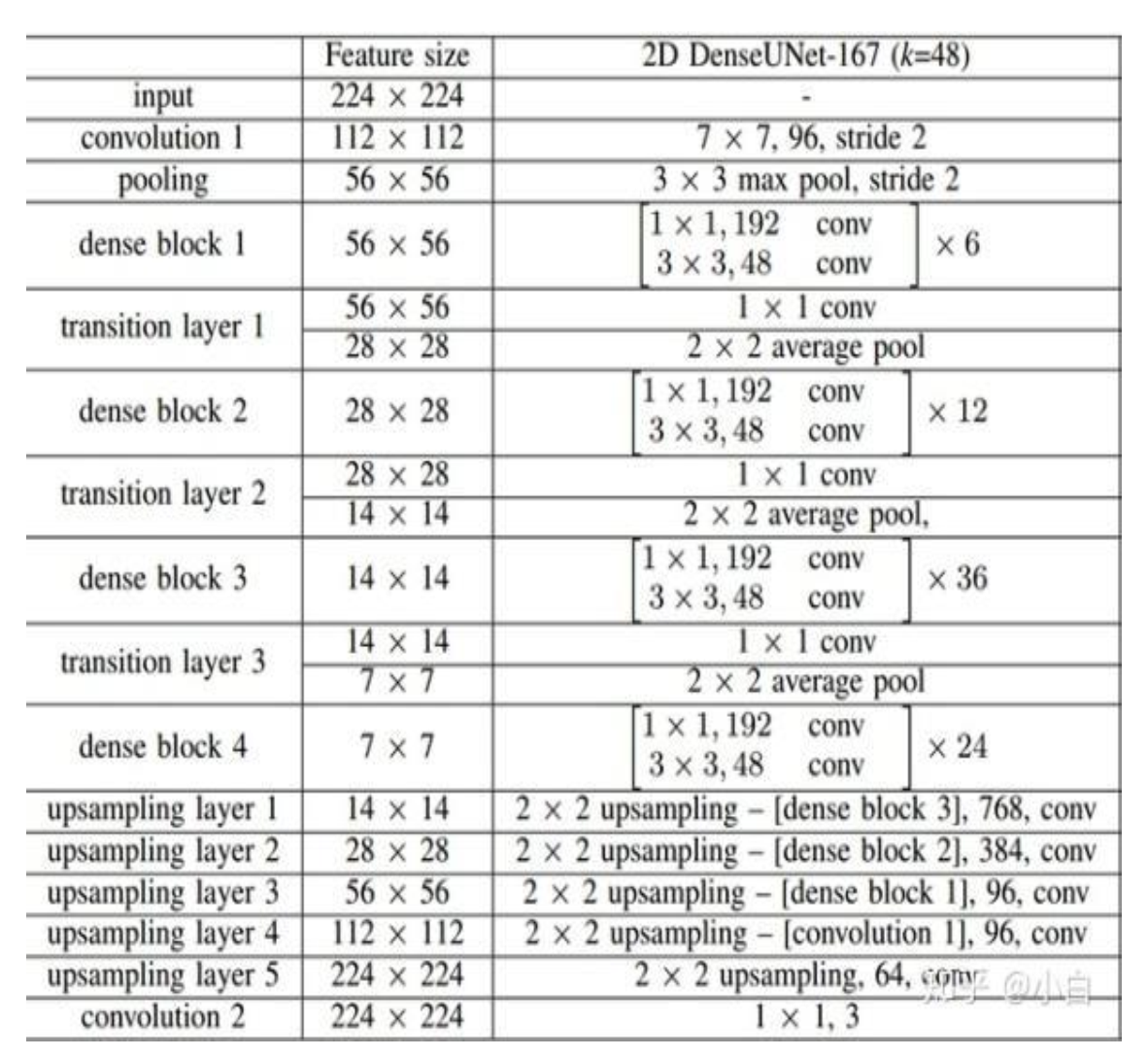
稠密块 (𝐷𝑒𝑛𝑠𝑒 𝐵𝑙𝑜𝑐𝑘)
𝐷𝑒𝑛𝑠𝑒 𝐵𝑙𝑜𝑐𝑘 中每一层的输入都是来自前面所有层的输出,也就是说每一层
输出的 𝐹𝑒𝑎𝑡𝑢𝑟𝑒 𝑀𝑎𝑝 都会作为后面的层的输入
过渡层 (𝑇𝑟𝑎𝑛𝑠𝑖𝑡𝑖𝑜𝑛 𝐿𝑎𝑦𝑒𝑟)
每个稠密块都会使得通道数增加, 过渡层则用于控制模型的复杂度
过渡层 (𝑇𝑟𝑎𝑛𝑠𝑖𝑡𝑖𝑜𝑛 𝐿𝑎𝑦𝑒𝑟)
过渡层使用 1 × 1 卷积层来减小通道数,并使用步幅为 2 的平均池化层减半高宽
利用ResNet改造VGG:RepVGG
只用 3x3 卷积和 ReLU激活函数的超级简单架构,通过结构重参数化 (structural reparameterization),就让这个7年前的老架构再次“容光焕发”!
结构
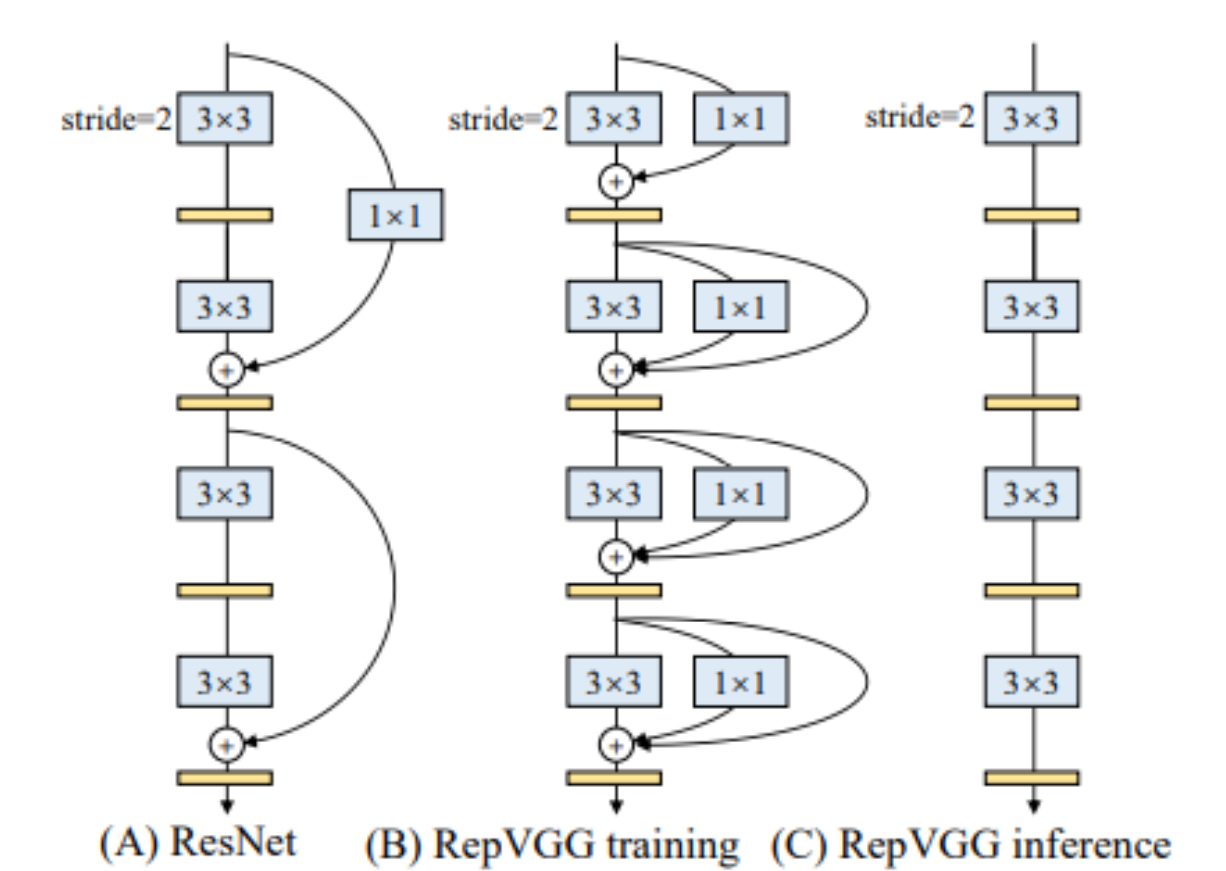

ShortCut只用于训练参数,再预测时用的是C结构(单模型)