高效大型语言模型推理优化综述
1. 研究背景
这篇论文全面综述了LLMs推理服务的方法,涵盖了从实例级别优化到集群规模策略,再到新兴场景和其他重要领域。通过系统的方法和细致的分类,本文为LLMs推理服务的优化提供了宝贵的见解和未来的研究方向。希望这些工作能为正在进行的相关研究提供有价值的参考。
研究问题:这篇文章要解决的问题是如何高效地服务大型语言模型(LLMs)推理,特别是如何在单个GPU内存不足的情况下实现低延迟和高吞吐量。
研究难点:该问题的研究难点包括:LLMs的参数数量庞大,导致显著的内存开销;注意力机制的高计算需求;以及如何在分布式环境中实现负载均衡和资源优化。
相关工作:该问题的研究相关工作有:Miao等人(2023)、Yuan等人(2024)、Zhou等人(2024)和Li等人(2024a)之前的研究,但这些工作在建深度、广度或及时性方面存在局限性。
这篇论文整体是一个综述,可以作为当前大模型推理优化进行阅读。
论文名称:Taming the Titans: A Survey of Efficient LLM Inference Serving
论文地址:
https://arxiv.org/pdf/2504.19720arxiv.org/pdf/2504.19720
2. 实例级别优化:
2.1 模型放置

由于LLMs的参数规模庞大,单个GPU的内存往往不足以容纳整个模型。因此,需要将模型分布到多个GPU或CPU上。常见的方法包括模型并行化(如管道并行和张量并行)、专家并行化以及模型卸载技术(如ZeRO-Offload和DeepSpeed-Inference)
模型并行性:将模型的不同层分配到多个设备上,如GPipe、PipeDream和Megatron-LM等,以实现并行处理。
张量并行性:将模型的个体操作或层分割成更小的子张量,并在不同设备上并行计算,如Megatron-LM中的实现。关于数据并行和张量并行我之前写过两篇文章,具体可以参考:
Trancy Wang:大模型训练工程(一)-数据并行2 赞同 · 0 评论文章
Trancy Wang:大模型训练工程(二)- tensor(张量)并行5 赞同 · 0 评论文章
再说一下补充技术:
顺序并行性:如Kortikanti等人(2022)提出的,沿序列维度划分LayerNorm和Dropout激活。
上下文并行性:如NVIDIA(2024)提出的,沿序列维度划分所有层。
专家并行性:如Fedus等人(2022)提出的,优化稀疏MoE组件的内存使用。
卸载技术:如ZeRO-Offload、DeepSpeed-Inference和FlexGen等,将大部分模型权重存储在内存或存储设备中,只在需要时加载到GPU内存中。
2.2 请求调度
请求调度直接影响推理延迟的优化。包括跨请求调度(如FCFS、SJF、SRTF等)和请求内调度(如迭代级调度、动态分割融合等)。通过优化调度策略,可以提高系统的吞吐量和响应速度重点说一下跨请求调度包含的几个策略,在大型语言模型(LLMs)推理服务中,请求调度策略直接影响系统的延迟和吞吐量。文档中提到的几种主要请求调度策略包括:
(1) First-Come-First-Served (FCFS):这是最简单的调度策略,按照请求到达的顺序进行处理。然而,这种策略可能会导致长请求阻塞短请求,增加整体延迟。
(2) Shortest Job First (SJF):优先处理预测解码时间较短的请求,以减少平均等待时间。这种方法需要准确预测每个请求的解码长度。
(3) Preemptive Scheduling:允许中断当前正在处理的请求,优先处理更高优先级的请求。例如,FastServe引入了Skip-Join Multi-Level Feedback Queue (MLFQ) 调度器,通过抢占长时间运行的任务来加速短请求的处理。
2.3 解码长度预测
生成长度的不确定性使得请求调度变得具有挑战性。本文将预测方法分为三类:
(1)精确长度预测
其实就是直接预测每个请求的精确解码长度(如token数),有两种方式,一种是基于历史数据训练回归模型(如线性回归、神经网络)。另一种是利用输入序列特征(如上下文长度、提示词复杂度)预测输出长度。
(2)范围分类
将解码长度划分为离散区间(如短/中/长),预测所属类别而非具体值。使用分类模型(如Softmax分类器)划分长度范围(例如:<10、10-50、>50 tokens)。结合启发式规则(如提示词类型)辅助分类。
(3)相对排名预测
不直接预测绝对长度,而是比较请求间的相对解码时间或长度。训练模型输出请求间的优先级分数(如通过对比学习)。调度器根据分数动态调整优先级(如FastServe的Skip-Join MLFQ)。
(4)基于模式的启发式规则
利用输入模式的统计规律预测解码长度。譬如:提示词包含“翻译” → 预测中等长度输出。提示词为“生成故事” → 预测较长输出。实现方式一般是规则引擎或简单决策树。
(5)动态自适应预测
结合在线学习和反馈机制动态调整预测模型。初始阶段使用预训练模型,后续根据实际解码结果微调。例如,记录历史请求的实际解码长度,通过滑动窗口更新预测参数
(6) 混合策略
先用分类模型粗粒度划分范围,再在范围内用回归模型细化。对高置信度预测直接调度,低置信度请求进入备用队列。
2.4 KV缓存优化(KV Cache Optimization):
KV缓存用于存储中间结果,减少重复计算,但其管理、压缩和重用策略对性能有显著影响。优化方法包括无损存储技术、语义感知重用和压缩技术(如量化和紧凑编码架构)。
KV缓存优化是提升大型语言模型(LLMs)推理效率的核心技术,其核心目标是在保证模型精度的同时,显著降低KV缓存(Key-Value Cache)的内存占用和计算开销。KV缓存用于存储注意力机制中的历史键值对,避免重复计算,但会随序列长度增长呈线性扩张,导致内存瓶颈。优化方法涵盖无损压缩(如量化、熵编码)、有损压缩(如低秩近似、稀疏化)、动态管理(如滑动窗口、Recompute)及分布式存储(如分页、模型并行)等策略。
例如,量化技术可将FP16缓存压缩至INT4,节省75%内存;稀疏化则通过保留高重要性Token的KV缓存减少冗余存储;分页机制动态加载缓存块,避免GPU内存溢出。这些方法协同作用,使长序列推理(如文档处理、代码生成)在资源受限环境下仍能高效运行,同时为超大规模模型(如GPT-3、PaLM)提供可扩展的推理方案。
2.5 预测差异分解
通过将预填充和解码分离到不同的环境中,可以针对性地优化每一阶段。
预测差异分解(Prediction Discrepancy Decomposition)是一种分析模型预测误差来源的关键技术,其核心是通过数学建模将模型的预测误差拆解为多个可解释的组成成分,如数据偏差(模型未能捕捉真实数据分布)、方差(模型对训练数据的过拟合程度)、噪声(数据固有的不可预测性)以及模型结构局限性等,从而帮助定位误差根源。
例如,在回归任务中,经典的偏差-方差分解可将总误差量化为偏差平方、方差和噪声之和;在因果推断中,则可分解为直接效应、间接效应和残差;在深度学习中,还可结合注意力机制分析特征贡献差异。
该技术广泛应用于模型诊断、错误溯源、公平性检测和可解释性分析等领域,通过揭示误差构成,指导模型优化(如调整复杂度、增强数据或改进架构),最终提升预测性能和系统可靠性。
3 集群级别优化:
3.1 集群优化:
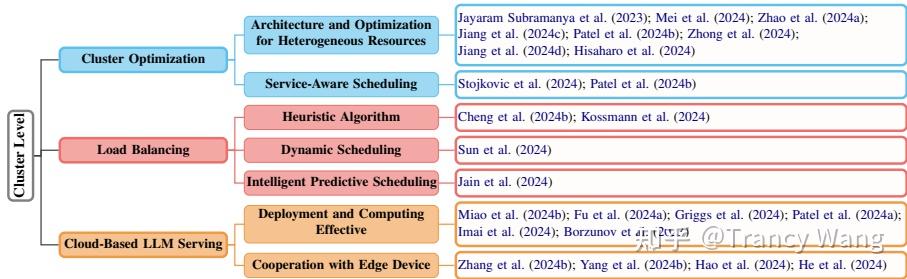
内部优化需要更多的机器随着参数规模的增加,而外部优化如面向服务的集群调度则进一步增强了内部优化。
3.2 负载均衡:
集群级别的负载均衡优化请求分布,以防止节点过载或欠载,提高吞吐量和服务质量。
3.3 基于云的LLMs服务
当本地LLMs部署缺乏资源时,云服务提供了一个更经济的替代方案。集群优化通过自适应任务和批量大小的联合优化框架,显著提高了吞吐量。负载均衡算法如SCLS和SAL通过动态调整请求分配,避免了节点过载或欠载。基于云的LLMs服务通过动态并行化和参数重用,降低了部署成本。
4. 新兴场景:
4.1 长上下文处理:
随着LLMs的发展,上下文长度显著扩展,这对分布式部署、计算和存储提出了新的挑战。
(1) 弹性序列并行性:如Loongserve(Wu等人,2024a)提出的,通过弹性序列并行性高效处理长上下文LLMs服务。
(2) 分布式注意力机制:如RingAttention(Liu等人,2023)和StripedAttention(Brandon等人,2023)提出的,通过块自注意力和前馈网络计算分布长序列,减少KV通信开销。DistAttention(Lin等人,2024a)提出的,将注意力分布在GPU上,避免缓存传输,支持任意序列长度的分区,最小化数据传输。
(3)KV缓存管理:如Infinite-LLM(Lin等人,2024a)和InfiniGen(Lee等人,2024)提出的,通过集群级别调度平衡资源,最大化吞吐量。
4.2 检索增强生成(RAG):
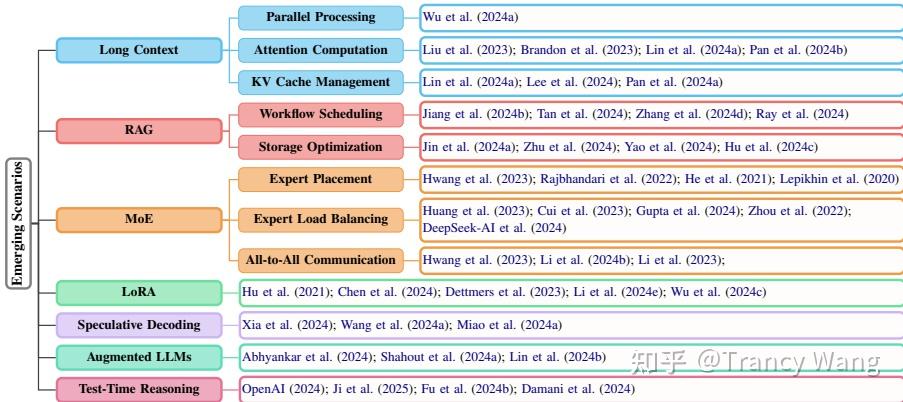
RAG使LLMs能够检索外部知识以响应,但处理大规模检索上下文的多样性和复杂性带来了优化延迟和KV缓存存储的挑战。
(1) 工作流程调度:如PipeRAG(Jiang等人,2024b)提出的,通过管道并行性、灵活的检索间隔和性能驱动的质量调整提高效率。
(2) 存储优化:如RAGCache(Jin等人,2024a)和SparseRAG(Zhu等人,2024)提出的,通过知识树和动态投机流水线减少冗余,高效管理大规模KV缓存。
(3) 缓存混合:如CacheBlend(Yao等人,2024)和EPIC(Hu等人,2024c)提出的,通过缓存选择和令牌重用增强效率,减少延迟。
关于RAG可以参考我之前的几篇文章:
Trancy Wang:RAG年终总结之12篇综述:从2022到2024看架构、策略、评测及演化60 赞同 · 1 评论文章
Trancy Wang:大模型RAG系列汇总52 赞同 · 0 评论文章
4.3 专家混合(MoE):
MoE模型在LLMs中表现出色,但其关键推理延迟挑战包括专家并行性、负载均衡和全量通信。其实MoE现在已经很多变种了。 MoE策略主要围绕动态路由、负载均衡、稀疏计算和硬件适配展开,核心目标是通过稀疏激活和资源优化,在保持模型性能的同时显著降低计算成本。实际应用中需根据任务需求(如吞吐量优先 vs. 延迟敏感)选择合适的策略组合。本文就简单写一个常用的动态专家选择策略,其中一个是top-k稀疏激活,另一个是门控网络优化。
(1)Top-k稀疏激活
核心思想:仅激活Top-k个最相关的专家(如k=1~2),而非全部专家,大幅减少计算量。代表方法:Switch Transformer:硬性选择单一专家(k=1),计算效率极高但可能损失表达能力。软性Top-k选择,平衡效率与性能。
(2)门控网络优化
改进门控网络(Gating Network)的精度(如FP16→INT8量化)或结构(如浅层MLP),加速专家选择过程。TUTEL 使用轻量级门控机制减少路由开销。
关于MoE的具体细节可以参考我之前的一篇文章
Trancy Wang:DeepSeekV3前置技术之MOE9 赞同 · 5 评论文章
4.4 低秩适应(LoRA):
LoRA通过小型可训练适配器适应LLMs的各种任务。其实LoRA也有很多变种, 具体可以参考
Trancy Wang:大模型微调之LoRA 及其变种1 赞同 · 0 评论文章
4.5 推测解码:
推测解码通过生成草稿令牌并用较小的LLMs验证它们来加速推理。通过使用较小的LLM生成草稿令牌,并与目标LLM并行验证它们来加速推理,减少延迟和成本而不损失质量。
4.6 增强LLMs:
LLMs越来越多地与外部工具(如API和代理)集成。
4.7 测试时推理:
推理时算法增强了LLMs的推理能力,但生成大量令牌会消耗计算资源。