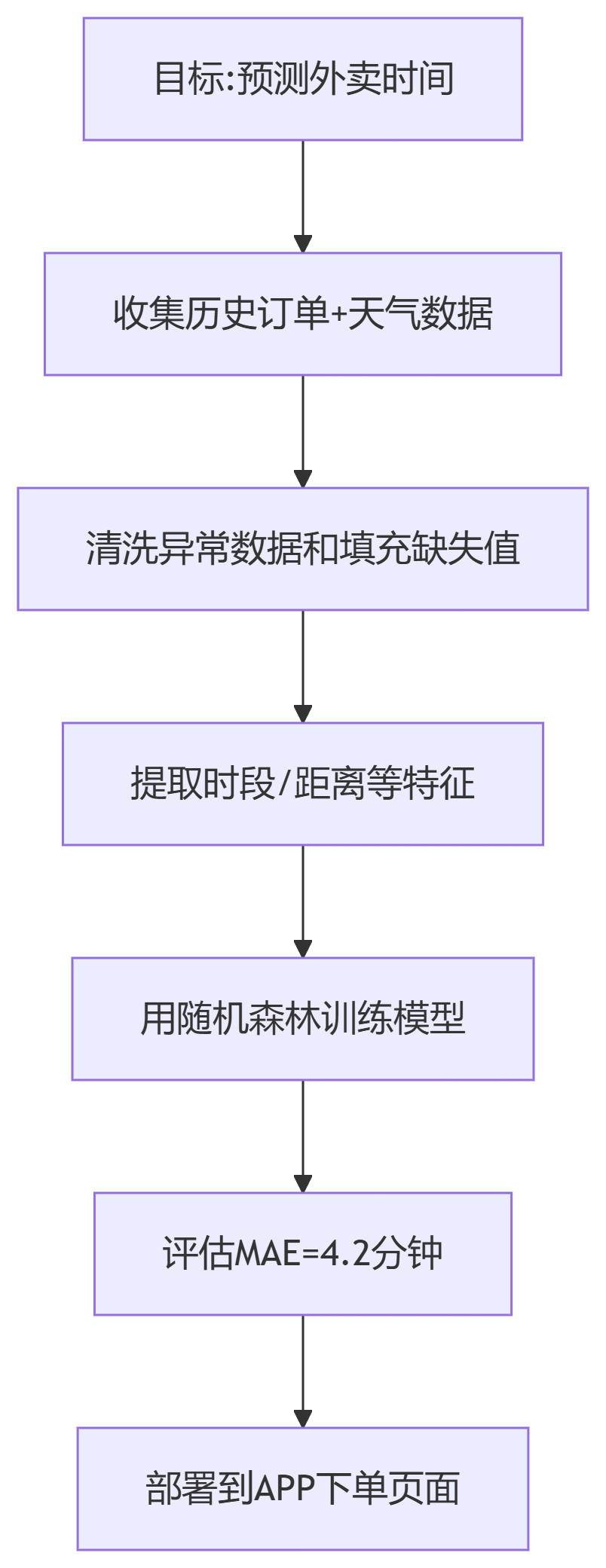
机器学习开发全流程
一、机器学习开发全流程图示
图表

二、分步详解(附外卖案例)
1. 明确问题(Problem Definition)
核心问题:你要用机器学习解决什么?
-
案例目标:预测用户下单后外卖的送达时间(回归问题)
-
关键指标:平均误差不超过5分钟(MAE < 5min)
2. 数据收集(Data Collection)
需要哪些数据?
-
特征值(X):
餐厅距离、天气状况、历史配送时间、时段(午/晚高峰) -
目标值(y):
实际送达时间
数据来源:
✔ 数据库订单记录
✔ 气象局API
✔ 地图导航距离数据
3. 数据预处理(Data Preprocessing)
处理脏数据就像洗菜:
-
缺失值处理:
→ 天气数据缺失?用当天平均天气填充 -
异常值处理:
→ 配送时间=300分钟?可能是记录错误,删除或修正 -
格式统一化:
→ 将“暴雨/大雨/小雨”映射为数字1,2,3
工具代码示例:
import pandas as pd
# 填充缺失值
df['weather'].fillna(df['weather'].mean(), inplace=True)4. 特征工程(Feature Engineering)
特征=模型的营养,需要精心搭配:
-
特征提取:
→ 从下单时间中提取是否周末、时间段 -
特征缩放:
→ 把距离(km)和配送费(元)缩放到同一量纲(如0~1) -
特征选择:
→ 发现餐厅评分与送达时间无关?删除!
关键技巧:
✔ 用热力图观察特征相关性
✔ 树模型不需要缩放,但神经网络必须做
5. 模型训练(Model Training)
选算法就像选厨具:
-
初步尝试:
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor() model.fit(X_train, y_train)
-
调参优化:
→ 用GridSearchCV调整n_estimators和max_depth
6. 模型评估(Evaluation)
不仅要好吃,还要健康达标:
-
回归任务指标:
✔ MAE(平均绝对误差)
✔ RMSE(对大误差更敏感) -
交叉验证:
→ 用5折交叉验证防止过拟合
结果示例:
测试集MAE = 4.2分钟 (达标!)
7. 部署上线(Deployment)
把菜端上桌:
-
保存模型:
import joblib joblib.dump(model, 'delivery_time_model.pkl')
-
API接口:
# Flask示例 @app.route('/predict', methods=['POST']) def predict():data = request.jsonreturn jsonify({"pred_time": model.predict(data)})
三、避坑指南
-
❌ 不要跳过数据探索:
→ 曾有人因未发现“夜间配送员少”导致白天模型夜间失效 -
✅ 持续监控模型:
→ 上线后每周检查指标(如疫情后配送模式变化) -
🔧 工具链推荐:
-
数据预处理:Pandas + Scikit-learn
-
可视化:Matplotlib/Seaborn
-
部署:Flask/FastAPI
-
四、完整案例流程图