CMSIS-NN:2.神经网络到CMSIS-NN的转换
更多内容:XiaoJ的知识星球
目录
- 二、神经网络到CMSIS-NN的转换
- 1.检查支持层:
- 2.比较ML框架和CMSIS-NN数据布局。
- (1)具有全连接层的示例
- (2)卷积层示例
- 3.量化:
- (1)量化
- (2)计算激活统计信息。
- (3)选择量化方案。
- 4.数据计算:
- (1)计算层Q格式。
- (2)计算shift
- 5.生成CMSIS-NN实现:
- 6.优化:
- 三、应用示例
- 1.使用CMSIS-NN在Cortex-M上部署卷积神经网络
- (1)量化
- (2)应用
二、神经网络到CMSIS-NN的转换
要将任何网络转换为CMSIS-NN,遵循以步骤:
.
1.检查支持层:
CMSIS-NN只支持几个层,不支持的层,应尝试CMSIS-NN和CMSIS-DSP功能的等效组合。
例如,CMSIS-NN中没有 LSTM(长短期记忆网络) 层的实现,但是可以用CMSIS-NN和CMSIS-DSP表示如下:
全连接层(CMSIS-NN)
s型和双曲正切激活(CMSIS-NN)
元素向量积(CMSIS-DSP)
.
2.比较ML框架和CMSIS-NN数据布局。
使用的术语:
-
一维张量称为向量
-
二维张量称为矩阵
-
大于2D张量称为张量
与CMSIS-NN相比,ML框架中张量的布局可能遵循不同的约定。
例如,矩阵中的元素可以在内存中按行或列顺序排列。对于一般张量,有更多的排序选择来对应维度的排列。
如果出现以下情况,则必须对层的权重进行重新排序,以便与CMSIS-NN一起使用:
-
ML框架和CMSIS-NN排序不同
-
该层是卷积层或全连接层
-
层的输入是矩阵或张量
.
(1)具有全连接层的示例
例如,我们看一下全连接层跟随卷积层的常见情况。这种情况,输入是一个张量。
a.对于 ML 框架:
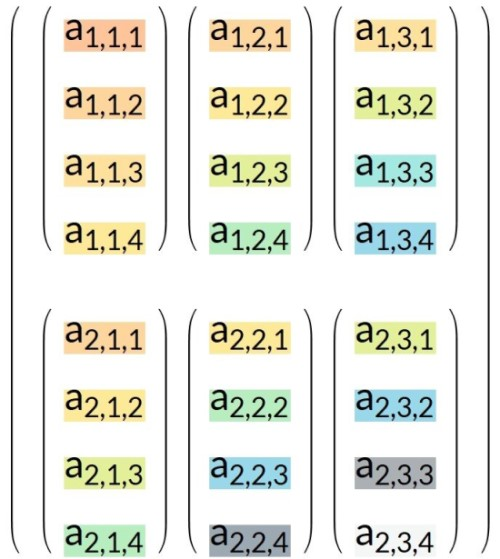
假设,输入是一个维度是 {2,3,4} 的张量 T_org:
图a1. 输入张量T_org
全连接层使用向量 FT_org 作为输入。它是张量 T_org 的扁平化版本:
图a2. 输入向量 FT_org

假设全连接层的输出有两个元素,则权重矩阵 W_org 的维度为 {2,24}:
图a3. 权重矩阵 W_org

全连接层的目的是计算矩阵乘积: W_org. FT_org
图a4. 全连接层输出

b.对于CMSIS-NN:
CMSIS-NN 对数据的排序方式与 ML 框架的不同。
输入张量T_new 是 T_org 的转置张量 ,维度为 {4,3,2} :
图b1. 输入张量T_new / T_org 的转置张量
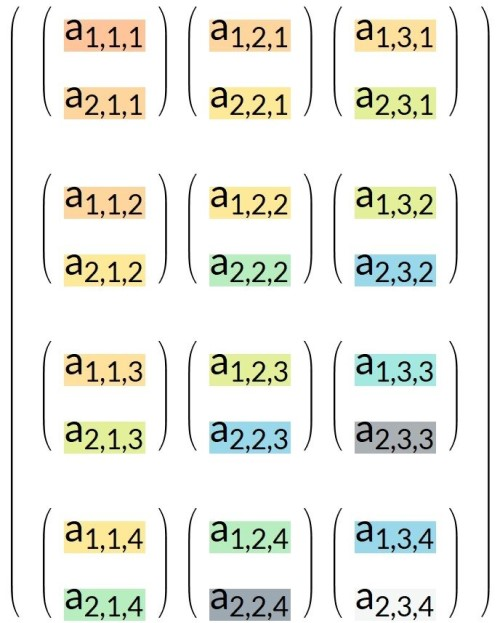
T_new 对应的扁平化向量 FT_new :
图b2. 扁平化向量 FT_new

要保持全连接层的输出不变,将权重矩阵 W_org 重新排序为 W_new:
图b3. 重新排序的权重矩阵W_new

最终输出 W_new . FT_new = W_org . FT_org
.
(2)卷积层示例
CMSIS-NN中:
-
卷积层的输入和输出的维度:{in通道,x 维度,y 维度}
-
卷积层权重张量的维度:{in通道、x 维度、Y 维度、out通道}
现在,假设您的 ML 框架正在处理维度:
-
输入:{y 维度,x 维度,in通道}
-
权重张量维度:{y 维度、x 维度、in通道、out通道}
必须对 ML 框架维度进行重新排序,以便新的权重张量具有 CMSIS-NN 预期顺序的维度:
- {in通道、x 内核、y 内核、out通道}
在 NumPy 中,可以通过以下方式完成:T_new = T_org.transpose(2,1,0,3)
.
3.量化:
(1)量化
网络量化是个难题。因为从浮点运算切换到定点运算时,会引入截断噪声和饱和效应。
截断噪声:数值被截断而产生的误差。
饱和效应:网络中的激活函数,当输入值过大或过小,它们的输出值会趋于饱和,即输出值接近于最大或最小值。
有两种方法可以解决量化网络的问题:
-
使用量化网络进行训练:在网络训练过程中,使用低精度的数据(如8位或16位定点数)来进行训练。
-
量化现有网络:将已经训练好的浮点网络转化为定点网络。
.
(2)计算激活统计信息。
要确定网络层的输入/输出,必须知道值的范围。意味着要在多个模式上评估网络,并记录每个层的输入和输出值。通常记录统计数据方式:
保留最小值和最大值。
为每个输入和输出计算直方图
.
(3)选择量化方案。
从上面的直方图中,可以看到值往往是集中的。这意味着可以测试几种策略:
-
使用全范围的值,基于最小值和最大值进行量化
-
只关注最可能的值,使用直方图的xx%值范围进行量化
-
更复杂的方案,以检测和删除这个值分布中的异常值
选择一个方案进行量化。
.
4.数据计算:
(1)计算层Q格式。
有了每层的统计数据和量化方案的选择,就可以推导出层的输入和输出的Q格式。
某些层会对输出格式施加约束,例如:
最大池的输出的Q格式与其输入格式相同,因为该算法在CMSIS-NN中是如此实现的。因此,您不能自由选择最大池层的输出格式。
对于全连接层和卷积层,可通过偏移偏置和输出值来独立于输入格式选择输出格式。
在这一步,你需要为每个输入和输出选择一个Q格式。您需要考虑:
-
各层如何连接
-
哪些图层允许自定义输出格式
从基于训练模式统计的网络输入Q格式开始。如果输入层是全连接或卷积层,则基于输出统计定义输出Q格式。否则,根据输入格式和层的性质计算输出Q格式。
过程如下:
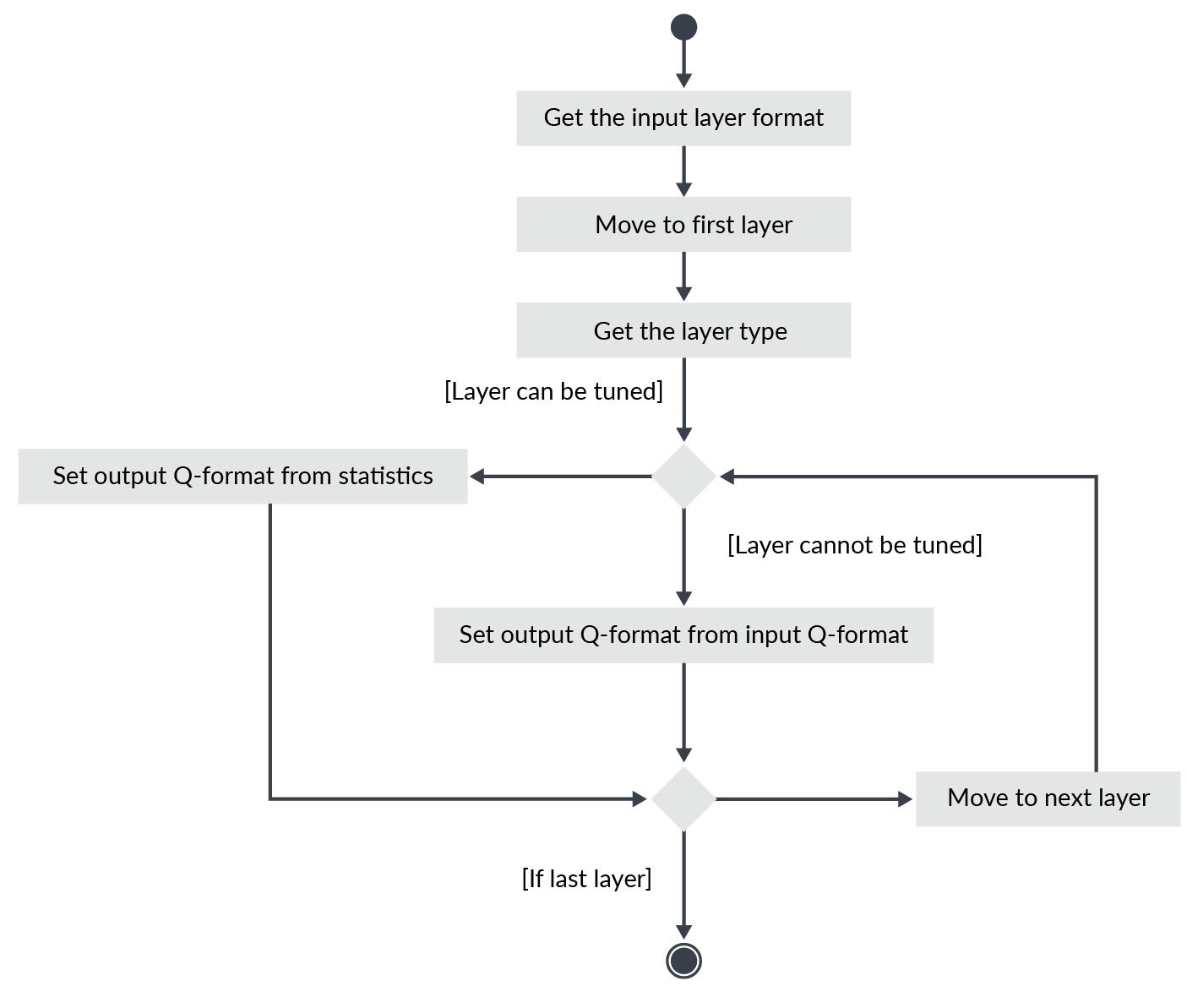
tuned:调整。
.
(2)计算shift
shift操作:
是指将数据样本沿着某个方向平移一定的像素。这可以生成更多的训练样本,增加模型的泛化能力。
知道输入和输出的Q格式,你就可以计算偏置移位和输出移位。
如果 fi 是输入的小数位数,fo是输出,fw是权重,fb是偏置,则:
bias shift : (fi + fw) - fb
out shift : (fi + fw) - fo
.
5.生成CMSIS-NN实现:
知道了Q格式以及偏置和输出shift,就可以生成量化系数和代码,以供CMSIS-NN使用。
-
将量化数据和权重数据,转存储到C数组中。第一层CMSIS-NN函数调用。
-
将计算的bias shift、out shift、层API参数转储到buf。其他层调用CMSIS-NN函数。
- 参数包括:步幅、填充、内核大小、输入维度和输出维度等等。
-
CMSIS-NN函数调用,得到输出。
图1. 第一层过程
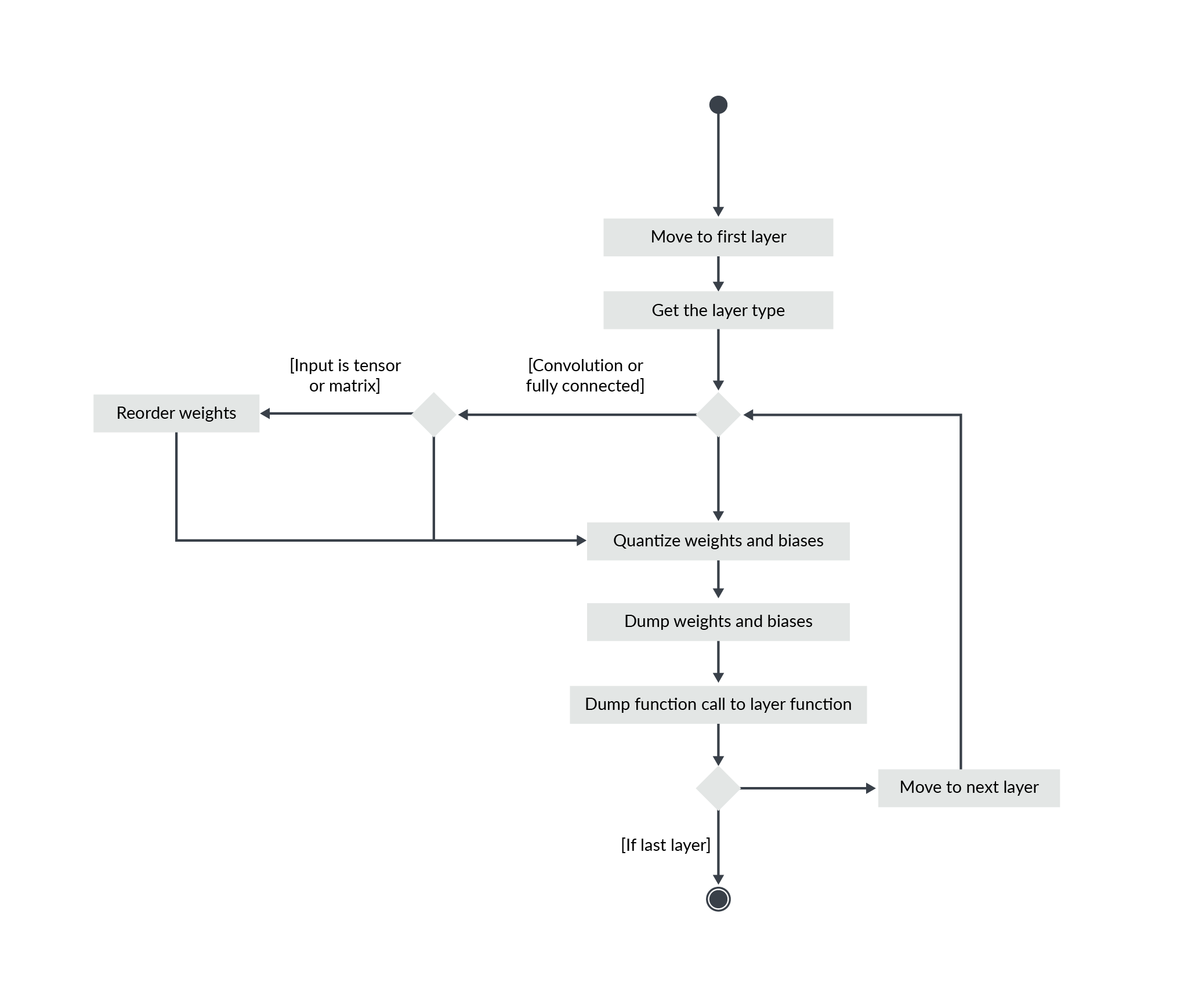
Reorder:重新调整。
.
6.优化:
-
测试最终的定点版本。
- 如果定点版本不够好,可更改量化方法或更改网络。最终得到个好的表现。
-
优化最终的CMSIS-NN代码。
-
使用每个层函数的最有效版本。
-
通过尽可能多地重用缓冲区来最小化内存使用。
-
.
三、应用示例
1.使用CMSIS-NN在Cortex-M上部署卷积神经网络
本示例,演示如何把以下神经网络部署到Cortex-M上:
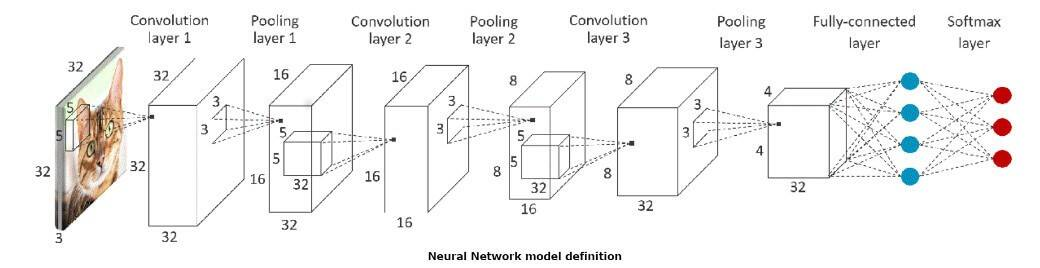
采用CIFAR-10数据集,遵循本教程,能轻松在PC上训练数据集。
上面神经网络由三个卷积层组成,中间穿插着ReLU激活层和最大池化层,最后是一个完全连接的层。该网络的输入是一个32x32像素的彩色图像,它将被分类到10个输出类之一。
可以将每层想象为一个软件框架API。选择适当的CMSIS-NN API 即可实现此网络,如图:
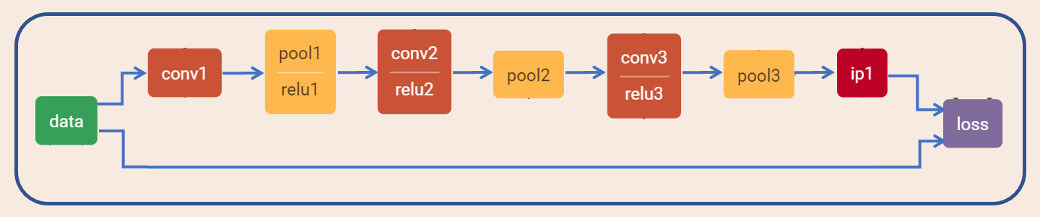
.
(1)量化
将浮点权重/激活数据转换为Qm.n格式,Python转示例如下,主要分三步:
-
查找最小/最大重量
-
找到Qx.y
-
量化权重数据
min_wt = weight.min()
max_wt = weight.max()# 需要几位二进制位数表示整数、小数。 # np.ceil() 向上取整。
int_bits = int(np.ceil(np.log2(max(abs(min_wt),abs(max_wt)))))
frac_bits = 7-int_bits # 缩放到[-128,127]范围。 # np.round() 四舍五入。
quant_weight = np.round(weight*(2**frac_bits))
# 将quant_weight映射到原始权重的范围。
weight = quant_weight/(2**frac_bits)
按相同流程将激活数据转换为Qm.n格式,然后总的计算流程将是:
Weight Qx.y * Activation Qx.y + Bias Qx.y -> Output Qx.y
量化权重/激活数据后,将数据导出到头文件中,用于编译嵌入式代码。
#define CONV1_WT {-9,-1,2,6,-4,6,4,-11,8, ...}
#define CONV1_BIAS {-49,-18,-7,-20,-12,-15, ...}
#define CONV2_WT {-3,-9,-16,-14,8,-17, ...}
#define CONV2_BIAS {55,50,34,43,-37,35, ...}
#define CONV3_WT {15,10,3,1,-20,-11,5, ...}
#define CONV3_BIAS {18,36,-46,-45,64,8, ...}
#define IP1_WT {38,-13,5,-20,15,-4,-3, ...}
#define IP1_BIAS {30,-121,-51,77,40,20, ...}
.
(2)应用
训练了网络层并量化了权重/激活数据,可以开始部署我们的网络了。
我们基于Cortex-M微控制器,选择合适开发环境和代码库,并确保在项目中添加CMSIS-NN头文件。
下面,使用CMSIS-NN API 映射网络层:
Layer1:

arm_convolve_HWC_q7_RGB()四组参数是:输入、卷积核、偏置和输出。
请确保设置了正确的内核大小/填充/步幅,与训练模型相同。
Layer2:

该层包括两个API,arm_maxpool_q7_HWC()和arm_relu_q7()。
与第1层一样,请参考网络模型参数,检查池化内核设置。
Layer3:

当输入张量维度是4的倍数时,使用arm_convolve_HWC_q7_fast(),因为这可以很好地利用8位操作上的SIMD 32读取和交换行为。
Layer4:

对于bufferA大小非零的情况,使用arm_avepool_q7_HWC()。
Layer5:

再次使用卷积API arm_convolve_HWC_q7_fast()。
Layer 6:

再次使用arm_avepool_q7_HWC()。
Layer7:

使用arm_fully_connected_q7_opt(),此优化函数旨在使用交错权重矩阵。
最终的代码应该如下:
void run_nn() {q7_t* buffer1 = scratch_buffer;q7_t* buffer2 = buffer1 + 32768;arm_convolve_HWC_q7_RGB(input_data, CONV1_IN_DIM, CONV1_IN_CH, conv1_wt, CONV1_OUT_CH, CONV1_KER_DIM, CONV1_PAD, CONV1_STRIDE, conv1_bias, CONV1_BIAS_LSHIFT, CONV1_OUT_RSHIFT, buffer1, CONV1_OUT_DIM, (q15_t*)col_buffer, NULL);arm_maxpool_q7_HWC(buffer1, POOL1_IN_DIM, POOL1_IN_CH, POOL1_KER_DIM, POOL1_PAD, POOL1_STRIDE, POOL1_OUT_DIM, col_buffer, buffer2);arm_relu_q7(buffer2, RELU1_OUT_DIM*RELU1_OUT_DIM*RELU1_OUT_CH);arm_convolve_HWC_q7_fast(buffer2, CONV2_IN_DIM, CONV2_IN_CH, conv2_wt, CONV2_OUT_CH, CONV2_KER_DIM, CONV2_PAD, CONV2_STRIDE, conv2_bias, CONV2_BIAS_LSHIFT, CONV2_OUT_RSHIFT, buffer1, CONV2_OUT_DIM, (q15_t*)col_buffer, NULL);arm_relu_q7(buffer1, RELU2_OUT_DIM*RELU2_OUT_DIM*RELU2_OUT_CH);arm_avepool_q7_HWC(buffer1, POOL2_IN_DIM, POOL2_IN_CH, POOL2_KER_DIM, POOL2_PAD, POOL2_STRIDE, POOL2_OUT_DIM, col_buffer, buffer2);arm_convolve_HWC_q7_fast(buffer2, CONV3_IN_DIM, CONV3_IN_CH, conv3_wt, CONV3_OUT_CH, CONV3_KER_DIM, CONV3_PAD, CONV3_STRIDE, conv3_bias, CONV3_BIAS_LSHIFT, CONV3_OUT_RSHIFT, buffer1, CONV3_OUT_DIM, (q15_t*)col_buffer, NULL);arm_relu_q7(buffer1, RELU3_OUT_DIM*RELU3_OUT_DIM*RELU3_OUT_CH);arm_avepool_q7_HWC(buffer1, POOL3_IN_DIM, POOL3_IN_CH, POOL3_KER_DIM, POOL3_PAD, POOL3_STRIDE, POOL3_OUT_DIM, col_buffer, buffer2);arm_fully_connected_q7_opt(buffer2, ip1_wt, IP1_IN_DIM, IP1_OUT_DIM, IP1_BIAS_LSHIFT, IP1_OUT_RSHIFT, ip1_bias, output_data, (q15_t*)col_buffer);
}
现在,将相机硬件或其他图像驱动程序添加到代码中,即可使用这个网络啦。
.
声明:资源可能存在第三方来源,若有侵权请联系删除!