BLIP3-o:一系列完全开源的统一多模态模型——架构、训练与数据集
摘要
在近期关于多模态模型的研究中,将图像理解与生成统一起来受到了越来越多的关注。尽管图像理解的设计选择已经得到了广泛研究,但对于具有图像生成功能的统一框架而言,其最优模型架构和训练方案仍有待进一步探索。鉴于自回归和扩散模型在高质量生成和可扩展性方面具有强大潜力,我们对它们在统一多模态环境中的使用进行了全面研究,重点关注图像表示、建模目标和训练策略。基于这些研究,我们提出了一种新方法,该方法采用扩散Transformer生成语义丰富的CLIP图像特征,这与传统的基于VAE的表示方法不同。这种设计既提高了训练效率,又提升了生成质量。此外,我们证明了统一模型的顺序预训练策略——先进行图像理解训练,再进行图像生成训练——具有实际优势,能够在发展强大的图像生成能力的同时,保持图像理解能力。最后,我们通过使用涵盖各种场景、物体、人体姿态等的多样化字幕提示GPT-4o,精心策划了一个高质量的指令调优数据集BLIP3o-60k,用于图像生成。基于我们创新的模型设计、训练方案和数据集,我们开发了BLIP3-o,这是一套最先进的统一多模态模型。BLIP3-o在大多数涵盖图像理解和生成任务的流行基准测试中均取得了优异表现。为促进未来的研究,我们完全开源了我们的模型,包括代码、模型权重、训练脚本以及预训练和指令调优数据集。
代码:https://github.com/JiuhaiChen/BLIP3o
模型:https://huggingface.co/BLIP3o/BLIP3o-Model
预训练数据:https://huggingface.co/datasets/BLIP3o/BLIP3o-Pretrain
指令调优数据:https://huggingface.co/datasets/BLIP3o/BLIP3o-60k
1 引言
近期的研究进展表明,支持图像理解和图像生成的统一多模态表示学习在单个模型中具有潜力[7, 31, 38, 35, 4, [33, 23]]。尽管在图像理解方面已经进行了大量研究,但图像生成的最优架构和训练策略仍有待探索。以往的争论主要集中在两种方法上:第一种方法将连续的视觉特征量化为离散标记,并将其建模为分类分布[32, 34, 21];第二种方法通过自回归模型生成中间视觉特征或潜在表示,然后基于这些视觉特征通过扩散模型生成图像[33, 23]。近期发布的GPT-4o图像生成功能[1]据称采用了混合架构,结合了自回归和扩散模型,遵循第二种方法[1, 40]。因此,我们受到启发,以类似的方式对设计选择进行系统研究。具体而言,我们的研究聚焦于三个关键设计维度:(1)图像表示——是将图像编码为低层像素特征(例如,来自基于VAE的编码器)还是高层语义特征(例如,来自CLIP图像编码器);(2)训练目标——均方误差(MSE)与流匹配[17, 19],以及它们对训练效率和生成质量的影响;(3)训练策略——像Metamorph [33]那样对图像理解和生成进行联合多任务训练,还是像LMFusion [28]和MetaQuery [23]那样进行顺序训练,即先对模型进行理解训练,然后扩展用于生成。
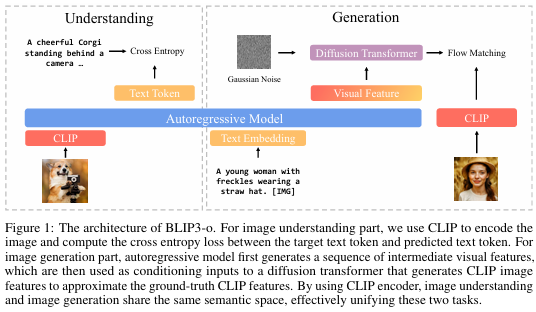
我们的研究发现,CLIP图像特征比VAE特征提供了更紧凑、信息量更大的表示,从而加快了训练速度并提高了图像生成质量。流匹配损失被证明比均方误差(MSE)损失更有效,能够实现更多样化的图像采样并产生更好的图像质量。此外,我们发现顺序训练策略——先在图像理解任务上训练自回归模型,然后在图像生成训练期间将其冻结——能取得最佳的整体性能。基于这些发现,我们开发了BLIP3-o,这是一系列最先进的统一多模态模型。BLIP3-o在CLIP特征上利用扩散Transformer和流匹配(如图1所示),并按照顺序在图像理解和图像生成任务上进行训练。为了进一步提高视觉美感和指令跟随能力,我们通过用涵盖各种场景、物体、人类手势等的多样化提示词提示GPT-4o,精心策划了一个包含60k高质量指令调优数据集BLIP3o-60k用于图像生成。我们观察到,在BLIP3o-60k上进行监督指令调优显著增强了BLIP3-o与人类偏好的对齐程度,并提高了美学质量。

在我们的实验中,BLIP3-o在大多数流行的图像理解和生成基准测试中均取得了优异表现,其中8B模型在MME-P上得分为1682.6,在MMMU上得分为50.6,在GenEval上得分为0.84。为了支持进一步的研究并秉承像BLIP-3 [39]这样的开源基础模型研究的使命,我们完全开源了我们的模型,包括模型权重、代码、预训练和指令调优数据集以及评估流程。我们希望我们的工作能够支持研究社区,并推动统一多模态领域的持续进步。
2 图像生成与理解的统一多模态模型
2.1 动机
近期研究表明,开发能够同时支持图像理解和生成的统一多模态架构是一个有前景的研究方向。Janus [4]、Show-o [38]、MetaMorph [33]、Janus-Pro [4]和LMFusion [28]等模型是早期在单一框架内实现图像理解和生成融合的尝试。近期OpenAI的GPT-4o [1]进一步展示了这种架构在高质量图像生成和多模态理解方面的强大能力。然而,实现这种统一能力的底层设计原则和训练策略仍有待深入研究。本研究旨在系统探讨并推动统一模型的发展,并明确了构建统一多模态模型的关键动机。
推理与指令遵循 将图像生成能力集成到自回归模型(如多模态大语言模型(MLLMs))中,有望继承这些模型的预训练知识、推理能力和指令遵循能力。例如,我们的模型能够直接解读诸如“一种长鼻子的动物”这样的提示,而无需对提示进行重写。这展示了传统图像生成模型难以企及的推理能力和世界知识水平。除了推理能力之外,当MLLMs的指令遵循能力被整合到统一架构中时,预计这种能力也会延续到图像生成过程中。
上下文学习 同时支持图像理解和生成的统一模型自然促进了上下文学习能力。在这样的模型中,之前生成的多模态输出可以作为后续生成的上下文,从而为迭代图像编辑、视觉对话以及逐步视觉推理提供无缝支持。这消除了模式切换或依赖外部处理流程的需要,使模型能够保持一致性和任务连续性。
迈向多模态通用人工智能 随着人工智能向通用人工智能(AGI)迈进,未来的系统需要超越基于文本的能力,以无缝地感知、解释和生成多模态内容。实现这一目标需要从仅支持文本的架构转向能够跨不同模态进行推理和生成的统一多模态架构。这样的模型对于构建能够以全面、类人的方式与世界交互的通用智能至关重要。
在这些动机的驱动下,我们在接下来的章节中探索开发一种统一模型,该模型能够同时支持图像理解和生成任务。
2.2 结合自回归与扩散模型
近期,OpenAI的GPT-4o [1] 在图像理解、生成和编辑任务中展现了最先进的性能。关于其架构的新兴假设 [40] 提出了一种混合流程,结构如下:
标记(Tokens) ⟶ \longrightarrow ⟶ [自回归模型(Autoregressive Model)] ⟶ \longrightarrow ⟶ [扩散模型(Diffusion Model)] ⟶ \longrightarrow ⟶ 图像像素(Image Pixels)
这表明,自回归模型和扩散模型可以联合使用,以结合这两个模块的优势。受这种混合设计的启发,我们在研究中采用了自回归 + 扩散的框架。然而,该框架下的最优架构仍不明确。自回归模型生成连续的中间视觉特征,旨在近似真实图像表示,这引发了两个关键问题。首先,什么应作为真实嵌入(ground-truth embeddings):我们应该使用变分自编码器(VAE)还是对比语言-图像预训练模型(CLIP)将图像编码为连续特征?其次,一旦自回归模型生成了视觉特征,我们如何最优地将它们与真实图像特征对齐,或者更一般地,我们应该如何建模这些连续视觉特征的分布:是通过简单的均方误差(MSE)损失,还是采用基于扩散的方法?因此,我们在下一节中对各种设计选择进行了全面探索。
3 统一多模态框架中的图像生成
在本节中,我们将讨论在统一多模态框架内构建图像生成模型时所涉及的设计选择。我们首先探讨如何通过编码器 - 解码器架构将图像表示为连续嵌入,这种架构在学习效率和生成质量方面发挥着基础性作用。
3.1 图像编码与重建
图像生成通常始于使用编码器将图像编码为连续的潜在嵌入,随后由解码器从该潜在嵌入重建图像。这种编码 - 解码流程可以有效降低图像生成中输入空间的维度,从而促进高效训练。接下来,我们将讨论两种广泛使用的编码器 - 解码器范式。
变分自编码器 变分自编码器(Variational Autoencoders,VAEs)[12, 27] 是一类生成模型,它们学习将图像编码到一个结构化的连续潜在空间中。编码器在给定输入图像的情况下近似潜在变量的后验分布,而解码器则从该潜在分布中抽取的样本重建图像。潜在扩散模型在此框架的基础上进行构建,通过学习对压缩后的潜在表示的分布进行建模,而非直接对原始图像像素进行建模。这些模型通过在 VAE 的潜在空间中运行,显著降低了输出空间的维度,从而降低了计算成本,并实现了更高效的训练。在去噪步骤之后,VAE 解码器将生成的潜在嵌入映射到原始图像像素。
带扩散解码器的 CLIP 编码器 由于 CLIP [26] 模型通过在大规模图像 - 文本对上进行对比训练,具备从图像中提取丰富高层语义特征的强大能力,因此已成为图像理解任务 [18] 的基础编码器。然而,将这些特征用于图像生成仍然是一个非平凡的挑战,因为 CLIP 最初并非为重建任务而设计。Emu2 [31] 提出了一种实用的解决方案,即将基于 CLIP 的编码器与基于扩散的解码器配对使用。具体而言,它使用 EVA-CLIP 将图像编码为连续的视觉嵌入,并通过从 SDXL-base [24] 初始化的扩散模型重建图像。在训练过程中,扩散解码器经过微调,以使用来自 EVA-CLIP 的视觉嵌入作为条件,从高斯噪声中恢复原始图像,而 EVA-CLIP 保持冻结状态。这一过程有效地将 CLIP 和扩散模型结合为一个图像自编码器:CLIP 编码器将图像压缩为语义丰富的潜在嵌入,而基于扩散的解码器则从这些嵌入重建图像。值得注意的是,尽管解码器基于扩散架构,但它是使用重建损失而非概率采样目标进行训练的。因此,在推理过程中,该模型执行确定性重建。
讨论 这两种编码器 - 解码器架构,即变分自编码器(VAEs)和 CLIP-扩散(CLIP-Diffusion),代表了图像编码与重建的不同范式,各自具有特定的优势和权衡。VAEs 将图像编码为低层级的像素特征,并提供更好的重建质量。此外,VAEs 作为现成模型广泛可用,可直接集成到图像生成训练流程中。相比之下,CLIP-扩散需要额外的训练来使扩散模型适应各种 CLIP 编码器。然而,CLIP-扩散架构在图像压缩比方面提供了显著优势。例如,在 Emu2 [31] 和我们的实验中,无论图像分辨率如何,每张图像都可以编码为固定长度为 64 的连续向量,从而提供紧凑且语义丰富的潜在嵌入。相比之下,基于 VAE 的编码器往往对更高分辨率的输入产生更长的潜在嵌入序列,这增加了训练过程中的计算负担。
3.2 潜在图像表示建模
在获得连续图像嵌入后,我们继续使用自回归架构对它们进行建模。给定一个用户提示(例如,“一位戴着草帽、有雀斑的年轻女子”),我们首先使用自回归模型的输入嵌入层将提示编码为一组嵌入向量 C \mathbf{C} C,并向 C \mathbf{C} C 追加一个可学习的查询向量 Q \mathbf{Q} Q,其中 Q \mathbf{Q} Q 随机初始化并在训练过程中进行优化。当组合序列 [ C ; Q ] [\mathbf{C} ; \mathbf{Q}] [C;Q] 通过自回归变换器处理时, Q \mathbf{Q} Q 学会关注并从提示 C \mathbf{C} C 中提取相关语义信息。由此得到的 Q \mathbf{Q} Q 被解释为自回归模型生成的中间视觉特征或潜在表示,并被训练以逼近真实图像特征 X \mathbf{X} X(从 VAE 或 CLIP 获得)。接下来,我们介绍两种训练目标:均方误差(Mean Squared Error,MSE)和流匹配(Flow Matching),用于学习使 Q \mathbf{Q} Q 与真实图像嵌入 X \mathbf{X} X 对齐。
MSE 损失 均方误差(MSE)损失是一种简单且广泛用于学习连续图像嵌入的目标函数 [7, 31]。给定自回归模型预测的视觉特征 Q \mathbf{Q} Q 和真实图像特征 X \mathbf{X} X,我们首先应用一个可学习的线性投影来对齐 Q \mathbf{Q} Q 和 X \mathbf{X} X 的维度。然后,MSE 损失表示为:
L M S E = ∥ X − W Q ∥ 2 2 \mathcal{L}_{\mathrm{MSE}}=\|\mathbf{X}-\mathbf{W Q}\|_{2}^{2} LMSE=∥X−WQ∥22
其中, W \mathbf{W} W 表示可学习的投影矩阵。
流匹配 需要注意的是,仅使用 MSE 损失只能使预测的图像特征 Q \mathbf{Q} Q 与目标分布的均值对齐。理想的训练目标应该对连续图像表示的概率分布进行建模。我们提出使用流匹配(Flow Matching)[16],这是一种扩散框架,可以通过从先验分布(例如,高斯分布)迭代传输样本来从目标连续分布中采样。给定一个真实图像特征 X 1 \mathbf{X}_{1} X1 和由自回归模型编码的条件 Q \mathbf{Q} Q,在每个训练步骤中,我们采样一个时间步 t ∼ U ( 0 , 1 ) t \sim \mathcal{U}(0,1) t∼U(0,1) 和噪声 X 0 ∼ N ( 0 , 1 ) \mathbf{X}_{0} \sim \mathcal{N}(0,1) X0∼N(0,1)。然后,扩散变换器学会在 Q \mathbf{Q} Q 的条件下,预测在时间步 t t t 沿着 X 1 \mathbf{X}_{1} X1 方向的“速度” V t = d X t d t \mathbf{V}_{t}=\frac{d \mathbf{X}_{t}}{d t} Vt=dtdXt。根据之前的工作 [19],我们通过 X 0 \mathbf{X}_{0} X0 和 X 1 \mathbf{X}_{1} X1 之间的简单线性插值来计算 X t \mathbf{X}_{t} Xt:
X t = t X 1 + ( 1 − t ) X 0 \mathbf{X}_{t}=t \mathbf{X}_{1}+(1-t) \mathbf{X}_{0} Xt=tX1+(1−t)X0
而 V t \mathbf{V}_{t} Vt 的解析解可表示为:
V t = d X t d t = X 1 − X 0 \mathbf{V}_{t}=\frac{d \mathbf{X}_{t}}{d t}=\mathbf{X}_{1}-\mathbf{X}_{0} Vt=dtdXt=X1−X0
最后,训练目标定义为:
L Flow ( θ ) = E ( X 1 , Q ) ∼ D , t ∼ U ( 0 , 1 ) , X 0 ∼ N ( 0 , 1 ) [ ∥ V θ ( X t , Q , t ) − V t ∥ 2 ] \mathcal{L}_{\text {Flow }}(\theta)=\mathbb{E}_{\left(\mathbf{X}_{1}, \mathbf{Q}\right) \sim \mathcal{D}, t \sim \mathcal{U}(0,1), \mathbf{X}_{0} \sim \mathcal{N}(0,1)}\left[\left\|\mathbf{V}_{\theta}\left(\mathbf{X}_{t}, \mathbf{Q}, t\right)-\mathbf{V}_{t}\right\|^{2}\right] LFlow (θ)=E(X1,Q)∼D,t∼U(0,1),X0∼N(0,1)[∥Vθ(Xt,Q,t)−Vt∥2]
其中, θ \theta θ 是扩散变换器的参数, V θ ( X t , Q , t ) \mathbf{V}_{\theta}\left(\mathbf{X}_{t}, \mathbf{Q}, t\right) Vθ(Xt,Q,t) 表示基于实例( X 1 , Q \mathbf{X}_{1}, \mathbf{Q} X1,Q)、时间步 t t t 和噪声 X 0 \mathbf{X}_{0} X0 预测的速度。
讨论 与离散标记(token)不同,离散标记本质上支持基于采样的策略来探索多样化的生成路径,而连续表示则不具备这一特性。具体而言,在基于均方误差(MSE)的训练目标下,对于给定的提示(prompt),预测的视觉特征 Q \mathbf{Q} Q 几乎变为确定性的。因此,无论视觉解码器是基于变分自编码器(VAEs)还是 CLIP + 扩散(CLIP + Diffusion)架构,在多次推理运行中,输出的图像几乎完全相同。这种确定性凸显了 MSE 目标的一个关键局限性:它限制了模型为每个提示生成单一、固定的输出,从而限制了生成的多样性。
相比之下,流匹配(Flow Matching)框架使模型能够继承扩散过程的随机性。这使得模型能够在相同提示的条件下生成多样化的图像样本,从而促进对输出空间的更广泛探索。然而,这种灵活性是以增加模型复杂度为代价的。与 MSE 相比,流匹配引入了额外的可学习参数。在我们的实现中,我们使用了扩散变换器(Diffusion Transformer,DiT),并从经验上发现,扩大其容量能够带来显著的性能提升。
3.3 设计选择
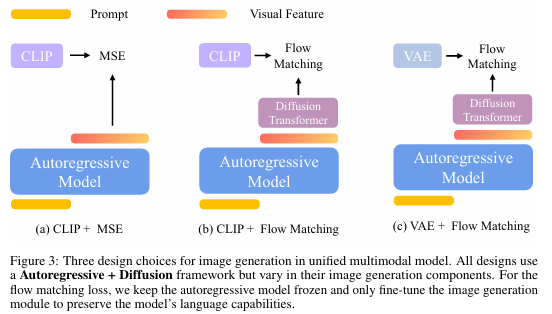
不同图像编码器 - 解码器架构与训练目标的组合为图像生成模型带来了一系列设计选择。这些设计选择如图3所示,对生成图像的质量和可控性有着显著影响。在本节中,我们将总结并分析不同编码器类型(例如,变分自编码器(VAEs)与CLIP编码器)和损失函数(例如,均方误差(MSE)与流匹配(Flow Matching))所带来的权衡。
CLIP + MSE 遵循Emu2 [31]、Seed-X [7]和Metamorph [33]的方法,我们使用CLIP将图像编码为64个固定长度且语义丰富的视觉嵌入。自回归模型被训练以最小化预测视觉特征 Q \mathbf{Q} Q与真实CLIP嵌入 X X X之间的均方误差(MSE)损失,如图3(a)所示。在推理过程中,给定文本提示 C \mathbf{C} C,自回归模型预测潜在视觉特征 Q \mathbf{Q} Q,随后将其传递给基于扩散的视觉解码器以重建真实图像。
CLIP + Flow Matching 作为MSE损失的替代方案,我们采用流匹配损失来训练模型以预测真实CLIP嵌入,如图3(b)所示。给定提示 C C C,自回归模型生成一系列视觉特征 Q Q Q。这些特征用作条件来引导扩散过程,从而产生预测的CLIP嵌入以逼近真实CLIP特征。本质上,推理流程包含两个扩散阶段:第一阶段使用条件视觉特征 Q \mathbf{Q} Q迭代去噪为CLIP嵌入;第二阶段则通过基于扩散的视觉解码器将这些CLIP嵌入转换为真实图像。这种方法在第一阶段实现了随机采样,从而允许图像生成具有更大的多样性。
VAE + Flow Matching 我们还可以使用流匹配损失来预测图3©中所示的真实VAE特征,这与MetaQuery [23]类似。在推理时,给定提示 C C C,自回归模型生成视觉特征 Q \mathbf{Q} Q。然后,在 Q \mathbf{Q} Q的条件下,并在每一步迭代去噪,真实图像由VAE解码器生成。
VAE + MSE 由于我们的重点是自回归 + 扩散框架,因此我们排除了VAE + MSE方法,因为它们没有包含任何扩散模块。
实现细节 为了比较各种设计选择,我们使用Llama-3.2-1B-Instruct作为自回归模型。我们的训练数据包括CC12M [3]、SA-1B [13]和JourneyDB [30],总计约2500万个样本。对于CC12M和SA-1B,我们利用LLaVA生成的详细标题;而对于JourneyDB,我们使用原始标题。使用流匹配损失的图像生成架构的详细描述在5.1节中给出。
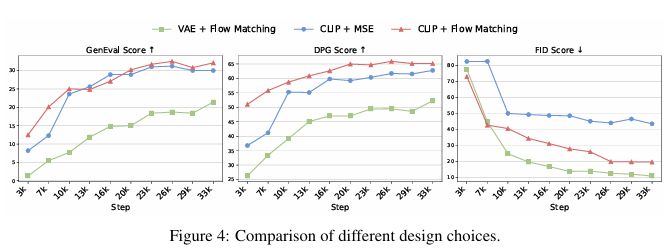
结果 我们在MJHQ-30k [15]数据集上报告了用于评估视觉美学质量的FID分数[10],以及用于评估提示对齐度的GenEval [8]和DPG-Bench [11]指标。我们大约每3200个训练步骤绘制一次每种设计选择的结果。图4显示,CLIP + Flow Matching在GenEval和DPG-Bench上均取得了最佳的提示对齐度分数,而VAE + Flow Matching则产生了最低(最佳)的FID分数,表明其美学质量更高。然而,FID存在固有局限性:它量化了与目标图像分布的风格偏差,并常常忽视真实的生成质量和提示对齐度。事实上,我们在MJHQ-30k数据集上对GPT-4o的FID评估产生了约30.0的分数,这凸显了FID在图像生成评估中可能具有误导性。总体而言,我们的实验表明CLIP + Flow Matching是最有效的设计选择。
讨论 在本节中,我们对统一多模态框架内图像生成的各种设计选择进行了全面评估。我们的结果清楚地表明,与VAE特征相比,CLIP的特征产生了更紧凑且语义更丰富的表示,从而提高了训练效率。与像素级特征相比,自回归模型能更有效地学习这些语义级特征。此外,流匹配被证明是建模图像分布的更有效训练目标,从而产生了更大的样本多样性和更高的视觉质量。

4 统一多模态模型的训练策略
基于我们的图像生成研究,下一步是开发一个能够同时执行图像理解和图像生成的统一模型。对于图像生成模块,我们采用CLIP + 流匹配(Flow Matching)方法。由于图像理解也在CLIP的嵌入空间中运作,我们将这两个任务对齐到同一个语义空间中,从而实现它们的统一。在此背景下,我们讨论两种实现这种集成的训练策略。
4.1 联合训练与顺序训练
联合训练 图像理解和图像生成的联合训练在最近的一些工作中已成为常见做法,例如Metamorph [33]、Janus-Pro [4]和Show-o [38]。尽管这些方法在图像生成方面采用了不同的架构,但它们都通过混合图像生成和理解的数据来进行多任务学习。
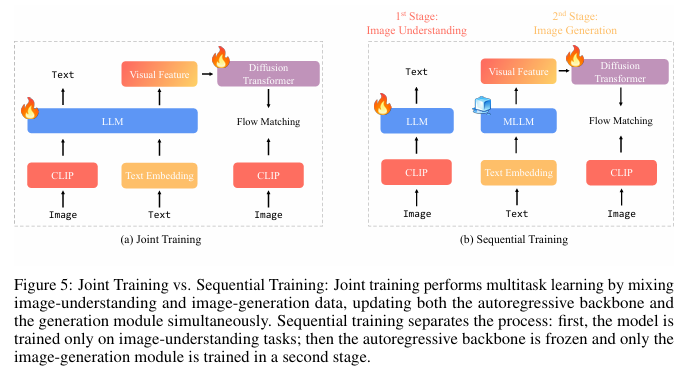
顺序训练 与同时训练图像理解和生成不同,我们采用两阶段的方法。在第一阶段,我们仅训练图像理解模块。在第二阶段,我们冻结多模态大型语言模型(MLLM)的主干网络,并仅训练图像生成模块,类似于LMFusion [28]和MetaQuery [23]的做法。
4.2 讨论
在联合训练设置中,尽管如Metamorph [33]所示,图像理解和生成任务可能相互受益,但有两个关键因素会影响它们的协同效应:(i)总数据量,以及(ii)图像理解数据与生成数据之间的数据比例。相比之下,顺序训练提供了更大的灵活性:它允许我们冻结自回归主干网络,并保持图像理解能力。我们可以将所有训练能力专门用于图像生成,避免联合训练中可能存在的任务间影响。此外,受LMFusion [28]和MetaQuery [23]的启发,我们将选择顺序训练来构建我们的统一多模态模型,并将联合训练留待未来工作。
5 BLIP3-o:我们最先进的统一多模态模型
基于我们的研究发现,我们采用CLIP + 流匹配(Flow Matching)和顺序训练策略,开发了我们自己最先进的统一多模态模型BLIP3-o。
5.1 模型架构
我们开发了两种不同规模的模型:一种是在专有数据上训练的80亿参数模型,另一种是仅使用开源数据训练的40亿参数模型。考虑到存在强大的开源图像理解模型,如Qwen 2.5 VL [2],我们跳过了图像理解训练阶段,并直接在Qwen 2.5 VL上构建了我们的图像生成模块。在80亿参数模型中,我们冻结了Qwen2.5-VL-7B-Instruct主干网络,并训练了扩散变换器(Diffusion Transformers,DiT),总共有14亿可训练参数。40亿参数模型采用了相同的图像生成架构,但使用Qwen2.5-VL-3B-Instruct作为主干网络。
扩散变换器(Diffusion Transformer, DiT)架构 我们采用了Lumina-Next模型[44]的架构作为我们的DiT。Lumina-Next模型基于改进的Next-DiT架构构建,这是一种可扩展且高效的扩散变换器,专为文本到图像和通用多模态生成而设计。它引入了三维旋转位置嵌入(3D Rotary Position Embedding),以在不依赖可学习位置标记的情况下,对时间、高度和宽度上的时空结构进行编码。每个变换器块都采用了夹层归一化(注意力/多层感知机前后均使用RMSNorm)和分组查询注意力(Grouped-Query Attention)来增强稳定性和减少计算量。基于经验结果,这种架构能够实现快速、高质量的生成。
5.2 训练方案
阶段1:图像生成的预训练 对于80亿参数模型,我们将约2500万开源数据(CC12M [3]、SA-1B [13]和JourneyDB [30])与额外的3000万张专有图像相结合。所有图像标题均由Qwen2.5-VL-7B-Instruct生成,提供详细的描述,平均长度为120个标记。为了提高对不同提示长度的泛化能力,我们还从CC12M [3]中包含了约10%(600万)的较短标题(约20个标记)。对于完全开源的40亿参数模型,我们使用了来自CC12M [3]、SA-1B [13]和JourneyDB [30]的2500万公开图像,每张图像都配有相同的详细标题。我们还混合了来自CC12M [3]的约10%(300万)的短标题。为了支持研究社区,我们发布了2500万条详细标题和300万条短标题。
阶段2:图像生成的指令微调 在图像生成预训练阶段之后,我们观察到模型存在以下一些弱点:
- 生成复杂的人类手势,例如“一个人正在拉弓射箭”。
- 生成常见物体,如各种水果和蔬菜。
- 生成地标,例如“金门大桥”。
- 生成简单文本,例如“在街道表面上写有‘Salesforce’这个词”。
尽管这些类别本应在预训练期间被涵盖,但由于我们预训练语料库的规模有限,它们并未得到充分处理。为了解决这一问题,我们针对这些特定领域进行了指令微调。对于每个类别,我们提示GPT-4o生成大约10,000个提示-图像对,从而创建一个有针对性的数据集,以提高模型处理这些情况的能力。为了提高视觉美学质量,我们还从JourneyDB [30]和DALL-E 3中提取提示来扩展数据。这一过程产生了大约60,000个高质量提示-图像对的精选集合。我们还发布了这60,000个指令微调数据集。
5.3 结果
为了进行基线比较,我们包括了以下统一模型:EMU2 Chat [31]、Chameleon [32]、Seed-X [7]、VILA-U [36]、LMfusion [28]、Show-o [38]、EMU3 [34]、MetaMorph [33]、TokenFlow [25]、Janus [35]和Janus-Pro [4]。
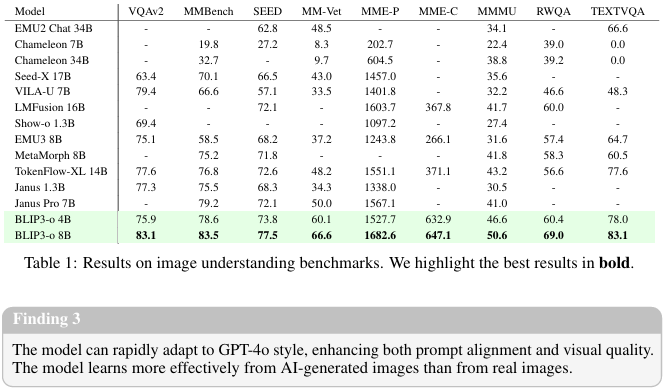
图像理解 :在图像理解任务中,我们在VQAv2 [9]、MMBench [20]、SeedBench [14]、MM-Vet [41]、MME-Perception和MME-Cognition [6]、MMMU [42]、TextVQA [29]和RealWorldQA [37]等基准上评估了模型性能。如表1所示,我们的BLIP3-o 8B在大多数基准测试中取得了最佳性能。
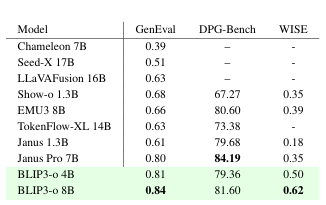
图像生成 :在图像生成基准测试中,我们报告了GenEval [8]和DPG-Bench [11]来衡量提示对齐度,以及WISE [22]来评估世界知识推理能力。如表2所示,BLIP3-o 8B在GenEval上取得了0.84的分数,在WISE上取得了0.62的分数,但在DPG-Bench上的分数较低。由于基于模型的DPG-Bench评估可能不可靠,我们在下一节中通过人工研究补充了所有DPG-Bench提示的结果。此外,我们还发现指令微调数据集BLIP3o-60k能立即带来提升:仅使用60k提示-图像对,提示对齐度和视觉美学均显著提高,许多生成瑕疵也迅速减少。尽管该指令微调数据集无法完全解决一些复杂情况(如复杂人类手势生成),但它显著提升了整体图像质量。
5.4 人工研究
在本节中,我们进行了一项人工评估,比较了BLIP3-o 8B和Janus Pro 7B在约1000个来自DPG-Bench的提示上的表现。对于每个提示,标注员根据两个指标对图像对进行并排比较:
- 视觉质量 :指示为“所有图像均使用不同方法从同一文本输入生成。请根据视觉吸引力(如布局、清晰度、物体形状和整体整洁度)选择您最喜欢的图像。”
- 提示对齐度 :指示为“所有图像均使用不同方法从同一文本输入生成。请选择图像与文本内容对齐度最高的图像。”
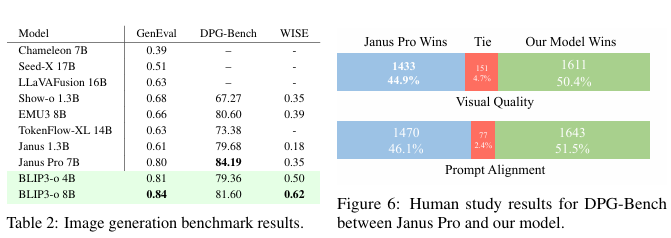
每个指标分别在两轮中进行评估,每个标准产生约3000个判断。如图6所示,尽管Janus Pro在表2中取得了更高的DPG分数,但BLIP3-o在视觉质量和提示对齐度方面均优于Janus Pro。视觉质量和提示对齐度的p值分别为5.05e-06和1.16e-05,表明我们的模型在统计上显著优于Janus Pro。
6 未来工作
目前,我们正在将我们的统一多模态模型扩展到下游任务,如图像编辑、多轮视觉对话以及交错生成等。作为第一步,我们将重点关注图像重建:
将图像输入到图像理解视觉编码器中,然后通过图像生成模型进行重建,以无缝衔接图像理解和生成。基于这一能力,我们将收集指令微调数据集,以使模型适应各种下游应用。
7 相关工作
近期的研究强调了统一多模态模型(既能进行图像理解又能进行图像生成)作为一种有前景的研究方向。例如,SEED-X [7]、Emu-2 [31]和MetaMorph [33]通过回归损失来训练图像特征,而Chameleon [32]、Show-o [38]、EMU3 [34]和Janus [35, 4]则采用了自回归离散标记预测范式。与此同时,DreamLLM [5]和Transfusion [43]利用扩散目标进行视觉生成。据我们所知,我们对自回归和扩散框架中的设计选择进行了首次系统性研究。
关于统一模型训练策略,LMFusion [28]基于冻结的多模态大语言模型(MLLM)主干网络,同时结合了使用Transfusion [43]进行图像生成的变换器模块。我们的方法与LMFusion的一个关键相似之处在于,两种方法都冻结了MLLM主干网络,并仅训练图像特定的组件。然而,LMFusion结合了并行的变换器模块用于图像扩散,显著扩大了模型规模。相比之下,我们的方法引入了一个相对轻量级的扩散头以实现图像生成,从而保持了更易于管理的整体模型规模。同时期的工作MetaQuery [23]也使用可学习的查询来桥接冻结的预训练MLLM和预训练的扩散模型,但扩散模型采用的是变分自编码器(VAE)+流匹配(Flow Matching)策略,而不是我们BLIP3-o中更高效的CLIP+流匹配策略。
8 结论
总之,我们对混合自回归和扩散架构在统一多模态建模中的设计选择进行了首次系统性探索,评估了三个关键方面:图像表示(CLIP特征与VAE特征)、训练目标(流匹配与均方误差)以及训练策略(联合训练与顺序训练)。我们的实验表明,CLIP嵌入与流匹配损失的结合既提高了训练效率,又提升了输出质量。基于这些见解,我们引入了BLIP3-o,这是一系列最先进的统一模型,并辅以一个包含60k指令微调数据集BLIP3o-60k,显著提高了提示对齐度和视觉美学效果。我们正在积极研究统一模型在迭代图像编辑、视觉对话以及逐步视觉推理等应用中的潜力。
附录A 图2中使用的提示词
- 一辆蓝色宝马汽车停在一堵黄色砖墙前。
- 一名女子在阳光明媚的小巷中旋转,小巷两旁是色彩斑斓的墙壁,她的夏日连衣裙在旋转中闪耀着光芒。
- 一群朋友正在野餐。
- 一片茂密的热带瀑布,在反光的金属路标上写着“深度学习”。
- 一只蓝松鸦站在一大篮彩虹色马卡龙上。
- 一只海龟在珊瑚礁上方游动。
- 一名年轻的红发女子戴着草帽,站在金色的麦田里。
- 三个人。
- 一名男子在电话中兴奋地交谈,嘴巴快速动着。
- 日出时的野花草地,“BLIP3o”投影在雾蒙蒙的表面上。
- 一个彩虹色的冰洞,在潮湿的沙滩上画着“Salesforce”。
- 一个巨大的玻璃瓶,里面装着一片微型的夏日森林。
- 漫步在纽约市曼哈顿冰冻的街道上——冰冻的树木和冰冻的帝国大厦。
- 一座灯塔孤独地矗立在暴风雨的海面上。
- 一只孤独的狼在闪烁的北极光下。
- 一只发光的鹿在霓虹灯照亮的未来丛林中行走。
- 一对情侣手牵手漫步在充满活力的秋日公园中,落叶轻轻地在他们周围飘落。
- 一艘好奇的船,形状像一只巨大的绿色西兰花,在明亮的阳光下漂浮在波光粼粼的海面上。
- 路上写着“Transformer”。
- 蓝色T恤上写着“Diffusion”。
- 一只金毛寻回犬平静地躺在木制门廊上,周围散落着秋天的落叶。
- 一只浣熊戴着侦探帽,用放大镜解谜。
- 一位赛博朋克风格的女子,身上散发着发光的纹身,机械手臂在全息天空下。
- 雪山山顶在清澈的高山湖泊中的倒影,形成了一个完美的镜像。
- 一名男子在阳光明媚的阳台上喝咖啡,阳台上摆满了盆栽植物,他穿着亚麻衣服和太阳镜,沐浴在晨光中。