Python打卡第35天
@浙大疏锦行
作业:调整模型定义时的超参数,对比下效果。
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import time
import matplotlib.pyplot as plt
from tqdm import tqdm# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 加载数据
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 转换为PyTorch张量
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test).to(device)# 定义模型
class MLP(nn.Module):def __init__(self, input_size=4, hidden_size=10, output_size=3):super(MLP, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, output_size)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 定义超参数组合
hyperparams = [{"lr": 0.01, "hidden_size": 10, "optimizer": "SGD"},{"lr": 0.001, "hidden_size": 20, "optimizer": "Adam"},{"lr": 0.1, "hidden_size": 5, "optimizer": "SGD"}
]results = []
num_epochs = 2000 # 减少训练轮数以加快实验速度for config in hyperparams:print(f"\n当前配置: {config}")# 初始化模型和优化器model = MLP(hidden_size=config["hidden_size"]).to(device)criterion = nn.CrossEntropyLoss()if config["optimizer"] == "SGD":optimizer = optim.SGD(model.parameters(), lr=config["lr"])elif config["optimizer"] == "Adam":optimizer = optim.Adam(model.parameters(), lr=config["lr"])losses = [] # 用于保存每个epoch的lossstart_time = time.time()with tqdm(total=num_epochs, desc="训练进度", unit="epoch") as pbar:for epoch in range(num_epochs):# 训练步骤model.train()outputs = model(X_train)loss = criterion(outputs, y_train)optimizer.zero_grad()loss.backward()optimizer.step()# 每200个epoch记录一次lossif (epoch + 1) % 200 == 0:losses.append(loss.item())pbar.set_postfix({'Loss': f'{loss.item():.4f}'})# 更新进度条if (epoch + 1) % 1000 == 0 or (epoch + 1) == num_epochs:pbar.update(1000 if (epoch + 1) % 1000 == 0 else num_epochs % 1000)# 测试准确率model.eval()with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)accuracy = (predicted == y_test).sum().item() / y_test.size(0)# 保存结果(确保包含losses)results.append({"config": config,"time": time.time() - start_time,"accuracy": accuracy,"final_loss": losses[-1] if losses else float('inf'),"losses": losses.copy() # 明确保存losses的副本})# 结果对比
print("\n===== 超参数对比结果 =====")
for i, res in enumerate(results):print(f"配置{i+1}: {res['config']}")print(f"训练时间: {res['time']:.2f}s | 测试准确率: {res['accuracy']*100:.2f}% | 最终Loss: {res['final_loss']:.4f}\n")# 可视化损失曲线
plt.figure(figsize=(12, 6))
for i, res in enumerate(results):if 'losses' in res and len(res['losses']) > 0: # 安全检查epochs_to_plot = range(0, len(res['losses']) * 200, 200)plt.plot(epochs_to_plot, res['losses'], label=f"配置{i+1}: {res['config']}")
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Comparison')
plt.legend()
plt.grid(True)
plt.show()使用设备: cuda:0当前配置: {'lr': 0.01, 'hidden_size': 10, 'optimizer': 'SGD'}
训练进度: 100%|██████████| 2000/2000 [00:02<00:00, 998.75epoch/s, Loss=0.3370] 当前配置: {'lr': 0.001, 'hidden_size': 20, 'optimizer': 'Adam'}
训练进度: 100%|██████████| 2000/2000 [00:02<00:00, 676.49epoch/s, Loss=0.0634]当前配置: {'lr': 0.1, 'hidden_size': 5, 'optimizer': 'SGD'}
训练进度: 100%|██████████| 2000/2000 [00:01<00:00, 1056.42epoch/s, Loss=0.0948]
c:\Users\lenovo\.conda\envs\DL\lib\site-packages\IPython\core\pylabtools.py:152: UserWarning: Glyph 37197 (\N{CJK UNIFIED IDEOGRAPH-914D}) missing from current font.fig.canvas.print_figure(bytes_io, **kw)
c:\Users\lenovo\.conda\envs\DL\lib\site-packages\IPython\core\pylabtools.py:152: UserWarning: Glyph 32622 (\N{CJK UNIFIED IDEOGRAPH-7F6E}) missing from current font.fig.canvas.print_figure(bytes_io, **kw)===== 超参数对比结果 =====
配置1: {'lr': 0.01, 'hidden_size': 10, 'optimizer': 'SGD'}
训练时间: 2.01s | 测试准确率: 93.33% | 最终Loss: 0.3370配置2: {'lr': 0.001, 'hidden_size': 20, 'optimizer': 'Adam'}
训练时间: 2.96s | 测试准确率: 96.67% | 最终Loss: 0.0634配置3: {'lr': 0.1, 'hidden_size': 5, 'optimizer': 'SGD'}
训练时间: 1.90s | 测试准确率: 96.67% | 最终Loss: 0.0948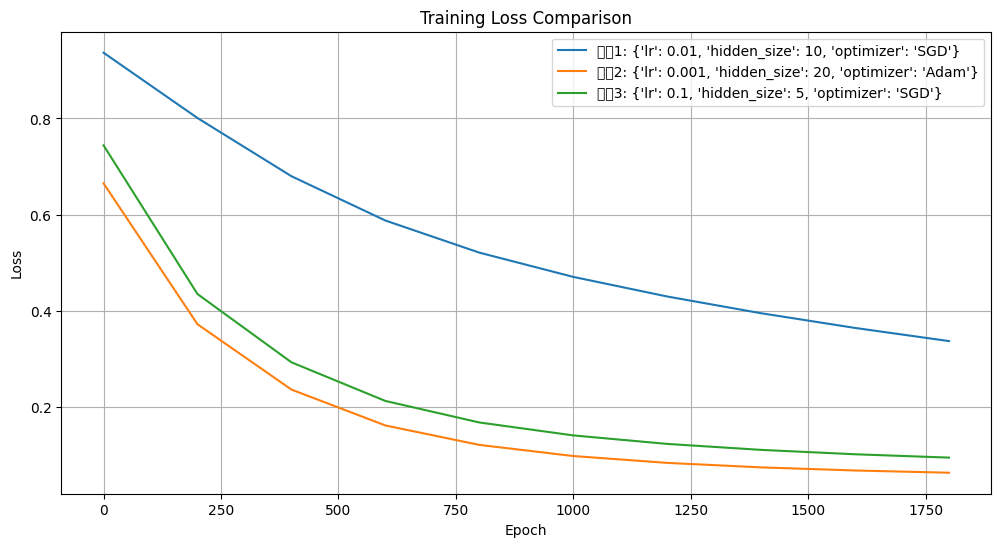
超参数对比实验结论
1. 最佳性能配置
配置2(lr=0.001, hidden_size=20, optimizer=Adam)综合表现最佳:
-
测试准确率最高(96.67%),与配置3相同,但Loss更低(0.0634 vs 0.0948),说明训练更稳定。
-
优化器选择影响大:Adam 在较低学习率(0.001)下表现优于 SGD,适合精细调整。
-
隐藏层大小(20)提供更强的表达能力,但训练时间稍长(2.96s)。
配置3(lr=0.1, hidden_size=5, optimizer=SGD)
-
训练最快(1.90s),且准确率与配置2相当(96.67%)。
-
高学习率(0.1)+ 小模型(hidden_size=5) 的组合可能适用于简单任务,但可能不稳定(Loss=0.0948 比 Adam 高)。
-
适用场景:如果训练速度优先,且任务较简单,可考虑此配置。
配置1(lr=0.01, hidden_size=10, optimizer=SGD)
-
表现最差(准确率93.33%),Loss较高(0.3370),说明学习率或模型容量不足。
-
改进方向:可以尝试增大
hidden_size或改用 Adam 优化器。
关键发现
-
Adam 优化器在低学习率下更稳定(配置2 Loss 最低)。
-
高学习率 + SGD 可能加速训练,但可能牺牲稳定性(配置3 快但 Loss 较高)。
-
隐藏层大小并非越大越好,配置2(20)和配置3(5)表现相当,但训练时间不同。
最终建议
-
追求高准确率 & 稳定训练 → 选择配置2(
lr=0.001, hidden_size=20, Adam) -
追求训练速度 & 可接受略高 Loss → 选择配置3(
lr=0.1, hidden_size=5, SGD) -
避免使用配置1(表现最差),或调整其超参数(如改用 Adam)。
如果需要进一步优化,可以尝试:
-
学习率调度(如 CosineAnnealingLR) 以平衡速度与稳定性
-
调整 batch size 观察训练效率变化
-
测试更大的
hidden_size(如30或50) 观察是否过拟合