java 代码查重(五)比较余弦算法、Jaccard相似度、欧式距离、编辑距离等在计算相似度的差异
目录
一、引言
二、针对Java 代码(.java文件), 比较余弦算法、Jaccard相似度、欧式距离、编辑距离等在计算相似度的差异
三、针对文本文件(.txt文件,里面是Java代码), 比较余弦算法、Jaccard相似度、欧式距离、编辑距离等在计算相似度的差异
四、初步结论
一、引言
对于文本相似度的问题,常见算法包括:
✔️数据量不是海量的场景下常用算法: 欧式距离、编辑距离、最长公共子串、余弦算法、Jaccard相似度等方法
✔️海量的场景下常用算法:
- SimHash计算得到的Hash串会非常的相近,从而可以判断两个文本的相似程度
-
海明距离应用最多的是在海量短文、文本去重上,以其性能优的特点。海明距离主要就是对文本进行向量化,或者说是把文本的特征抽取出来映射成编码(比如使用SimHash映射成编码),然后再对编码进行异或计算出海明距离。
二、针对Java 代码(.java文件), 比较余弦算法、Jaccard相似度、欧式距离、编辑距离等在计算相似度的差异
要求:比较源文件和目标文件(均为.java代码)的相似程度。比较时忽略注释、Java保留关键词、无意义中文等对代码比较的影响。
比较源文件和目标文件都是标准的Java代码(.java代码),唯一区别在于目标文件含有注释,源文件没有注释。
源文件内容如下(不含代码注释):
package com.homework.utils.hanlp;
import java.io.*;
public class FileIO {public static String readTxt(String txtPath) {String str = "";String strLine="";File storefile = new File(txtPath);FileInputStream fileInputStream = null;try {fileInputStream = new FileInputStream(storefile);InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "UTF-8");BufferedReader bufferedReader = new BufferedReader(inputStreamReader);while ((strLine = bufferedReader.readLine()) != null) {str += strLine;}inputStreamReader.close();bufferedReader.close();fileInputStream.close();} catch (IOException e) {e.printStackTrace();System.out.println("读文件异常,exception = " + e.getLocalizedMessage());}return str;}public static void writeTxt(double txtElem,String txtPath){String str = Double.toString(txtElem);File file = new File(txtPath);FileWriter fileWriter = null;try {fileWriter = new FileWriter(file, true);fileWriter.write(str, 0, (str.length() > 3 ? 4 : str.length()));fileWriter.write("\r\n");fileWriter.close();} catch (IOException e) {e.printStackTrace();}}
}
目标文件内容如下(含代码注释):
package com.homework.utils.hanlp;
import java.io.*;public class FileIO {/*** 读出txt文件* 传入文件绝对路径,将文件内容转化为 String字符串输出* txtPath 文件路径* 返回 文件内容*/public static String readTxt(String txtPath) {String str = "";String strLine="";// 将 txt文件按行读入 str中File storefile = new File(txtPath);FileInputStream fileInputStream = null;try {//将文件信息读入内存并利用InputStreamReader将字节信息转为字符流fileInputStream = new FileInputStream(storefile);InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "UTF-8");BufferedReader bufferedReader = new BufferedReader(inputStreamReader);// 利用BufferedReader创建对象,用readLine方法按行拼接字符串while ((strLine = bufferedReader.readLine()) != null) {
// // 过滤特殊字符
// String[] strings = {" ", "\n", "\r", "\t", "\\r", "\\n", "\\t", " ", "&", "<", ">", """, "&qpos;"};
// for (String string : strings) {
// strLine = strLine.replaceAll(string, "");
// }str += strLine;}// 关闭资源inputStreamReader.close();bufferedReader.close();fileInputStream.close();} catch (IOException e) {e.printStackTrace();System.out.println("读文件异常,exception = " + e.getLocalizedMessage());}return str;}/*** 写入txt文件* 传入内容、文件全路径名,将内容写入文件并换行* txtElem 传入的内容* txtPath 写入的文件路径*/public static void writeTxt(double txtElem,String txtPath){String str = Double.toString(txtElem);File file = new File(txtPath);FileWriter fileWriter = null;try {fileWriter = new FileWriter(file, true);fileWriter.write(str, 0, (str.length() > 3 ? 4 : str.length()));fileWriter.write("\r\n");// 关闭资源fileWriter.close();} catch (IOException e) {e.printStackTrace();}}
}
不同算法对源Java文件、目标Java文件相似度统计结果:
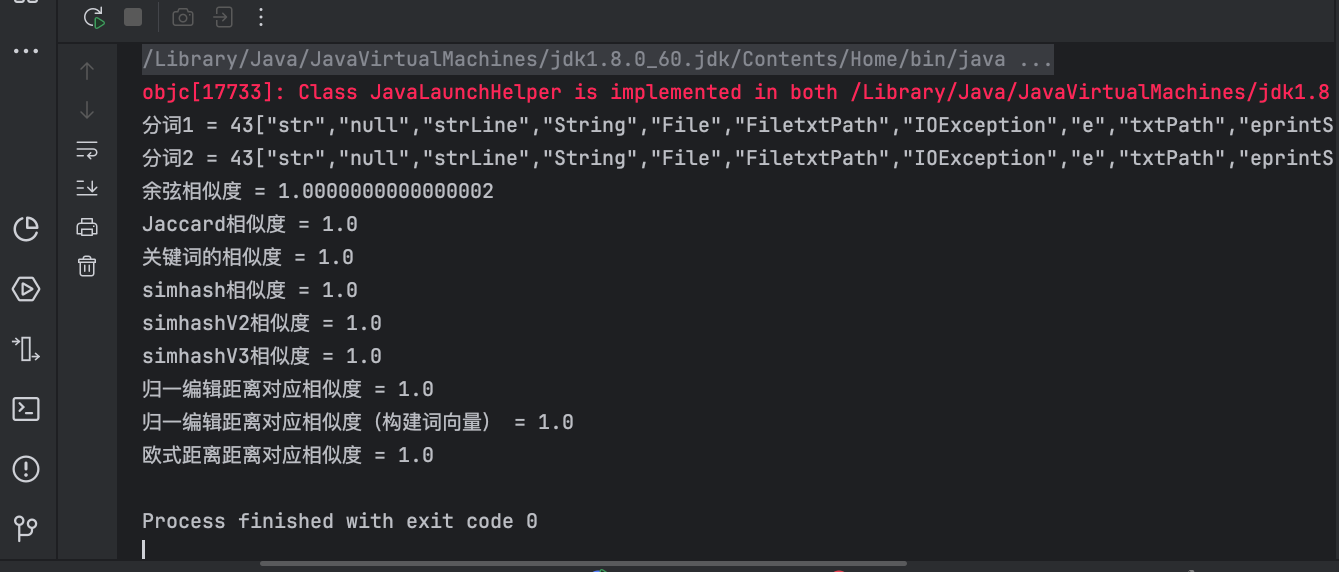
初步结论: 不同相似度方法 没有表现出明显的算法优劣差异
三、针对文本文件(.txt文件,里面是Java代码), 比较余弦算法、Jaccard相似度、欧式距离、编辑距离等在计算相似度的差异
要求:比较源文件和目标文件(均为.txt,里面内容为Java代码)的相似程度。比较时忽略注释、Java保留关键词、无意义中文等对代码比较的影响。
比较源文件和目标文件都是标准的Java代码,唯一区别在于目标文件含有注释,源文件没有注释。
源文件和目标文件内容 同上面的源文件和目标文件内容:
源文件:
package com.homework.utils.hanlp;
import java.io.*;
public class FileIO {
public static String readTxt(String txtPath) {
String str = "";
String strLine="";
File storefile = new File(txtPath);
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream(storefile);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
while ((strLine = bufferedReader.readLine()) != null) {str += strLine;
}
inputStreamReader.close();
bufferedReader.close();
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
System.out.println("读文件异常,exception = " + e.getLocalizedMessage());
}
return str;
}public static void writeTxt(double txtElem,String txtPath){
String str = Double.toString(txtElem);
File file = new File(txtPath);
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter(file, true);
fileWriter.write(str, 0, (str.length() > 3 ? 4 : str.length()));
fileWriter.write("\r\n");
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
目标文件:
package com.homework.utils.hanlp;
import java.io.*;public class FileIO {
/**
* 读出txt文件
* 传入文件绝对路径,将文件内容转化为 String字符串输出
* txtPath 文件路径
* 返回 文件内容
*/
public static String readTxt(String txtPath) {
String str = "";
String strLine="";
// 将 txt文件按行读入 str中
File storefile = new File(txtPath);
FileInputStream fileInputStream = null;
try {
//将文件信息读入内存并利用InputStreamReader将字节信息转为字符流
fileInputStream = new FileInputStream(storefile);
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "UTF-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
// 利用BufferedReader创建对象,用readLine方法按行拼接字符串
while ((strLine = bufferedReader.readLine()) != null) {
// // 过滤特殊字符
// String[] strings = {" ", "\n", "\r", "\t", "\\r", "\\n", "\\t", " ", "&", "<", ">", """, "&qpos;"};
// for (String string : strings) {
// strLine = strLine.replaceAll(string, "");
// }str += strLine;
}
// 关闭资源
inputStreamReader.close();
bufferedReader.close();
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
System.out.println("读文件异常,exception = " + e.getLocalizedMessage());
}
return str;
}/**
* 写入txt文件
* 传入内容、文件全路径名,将内容写入文件并换行
* txtElem 传入的内容
* txtPath 写入的文件路径
*/
public static void writeTxt(double txtElem,String txtPath){
String str = Double.toString(txtElem);
File file = new File(txtPath);
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter(file, true);
fileWriter.write(str, 0, (str.length() > 3 ? 4 : str.length()));
fileWriter.write("\r\n");
// 关闭资源
fileWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
不同算法对源文件、目标文件相似度统计结果:
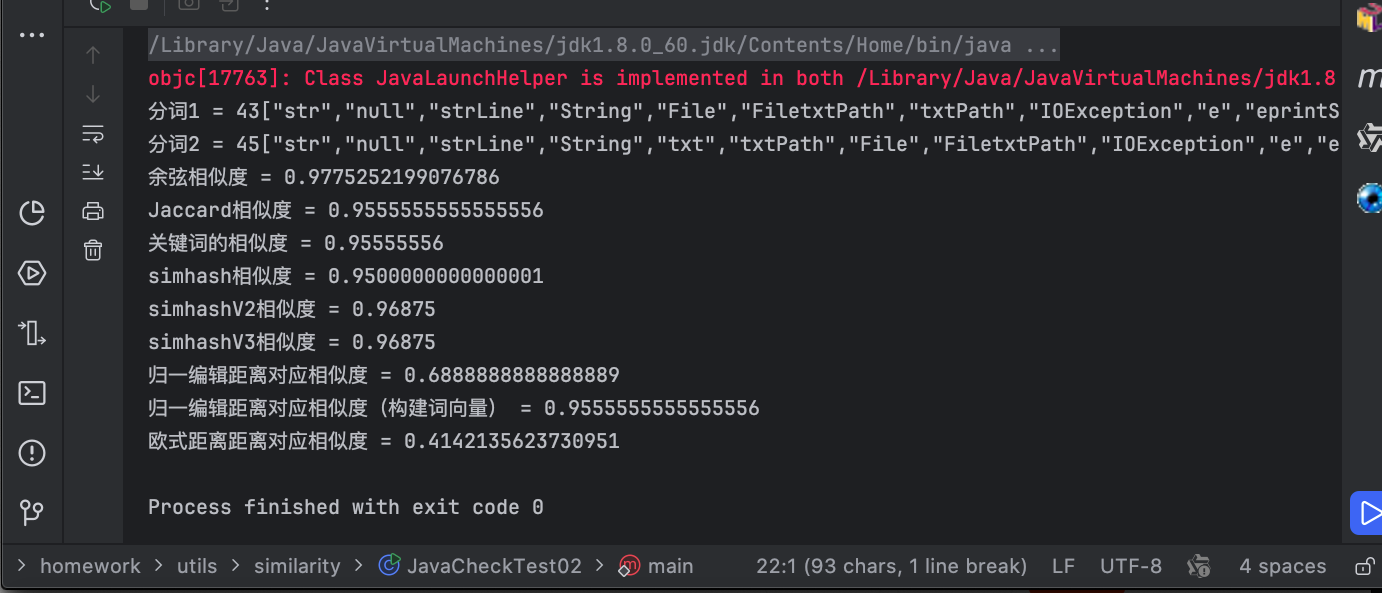
初步结论: 相同的Java代码复制到文本文件中(.txt文件),不同算法检查的相似度差异较大。
四、初步结论
为了实现更准确对比2个Java代码的相似度(用于Java课程作业查重场景), 可以将Java源码原封不动保存到.java文件中,可以得到更准确结果,且不同相似度算法下计算的相似度差异一致。