跨模态行人检索方法综述(上)
做毕设的时候整理,网上这方面的内容较少,我自己初步入门,整理了一些论文的内容
SSAN——Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification
提出语义自对齐网络(SSAN)来解决显著的模态差异和文本描述的大类内方差问题。提出一种自动提取部件级文本特征的新方法,这些特征对应于其视觉区域。其次,设计了一个多视角非局部网络,用于捕捉身体部位之间的关系,从而在身体部位与名词短语之间建立更好的对应关系。第三,引入复合排序(CR)损失,利用同一身份其他图像的文本描述提供额外监督,有效减少文本特征的类内方差。最后,为了推动文本到图像ReID的未来研究,我们构建了名为ICFG-PEDES的新数据库。
文本到图像ReID比基于图像的ReID更具挑战性。主要原因之一是文本描述的自由形式带来了两个关键问题:第一,如图1(a)所示,同一图像的不同文本描述可能存在显著差异,导致文本特征的大类内方差;第二,如图1(b)所示,尽管行人检测后身体部位通常对齐良好,但身体部位可能以任意顺序和不同字数进行描述,这给从两种模态中提取语义对齐的部件级特征带来困难。
因此,跨模态对齐对文本到图像ReID至关重要。主流的跨模态对齐策略包括采用注意力模型获取身体部位与单词的对应关系[6]-[8]。然而,这种策略需要对每个图像-文本对进行跨模态操作,计算成本高昂[9]。另一种直观策略是使用自然语言工具包(如NLTK[10])将文本描述分割为若干名词短语组,每组对应特定身体部位[11]-[13]。这种方法的缺点是文本特征质量对外部工具的可靠性敏感,且分割操作破坏了名词短语间的关联,降低了文本特征质量。
本文提出语义自对齐网络(SSAN),能够高效提取语义对齐的视觉和文本部件特征。SSAN不分割文本描述或执行跨模态操作,而是利用图像中相对对齐的身体部位作为监督,结合语言描述的上下文线索实现目标。具体而言:首先通过均匀分割视觉骨干网络的特征图获得部件级视觉特征;其次通过双向LSTM处理文本描述捕获词语关系;接着利用词注意模块(WAM)基于词语表示推断词-部件对应关系,获得原始部件级文本特征;最后通过共享的1x1卷积层精炼两种模态的部件级特征。通过约束两种模态的部件级特征相似性,WAM被迫做出合理预测,同时缩小模态间的语义差距。
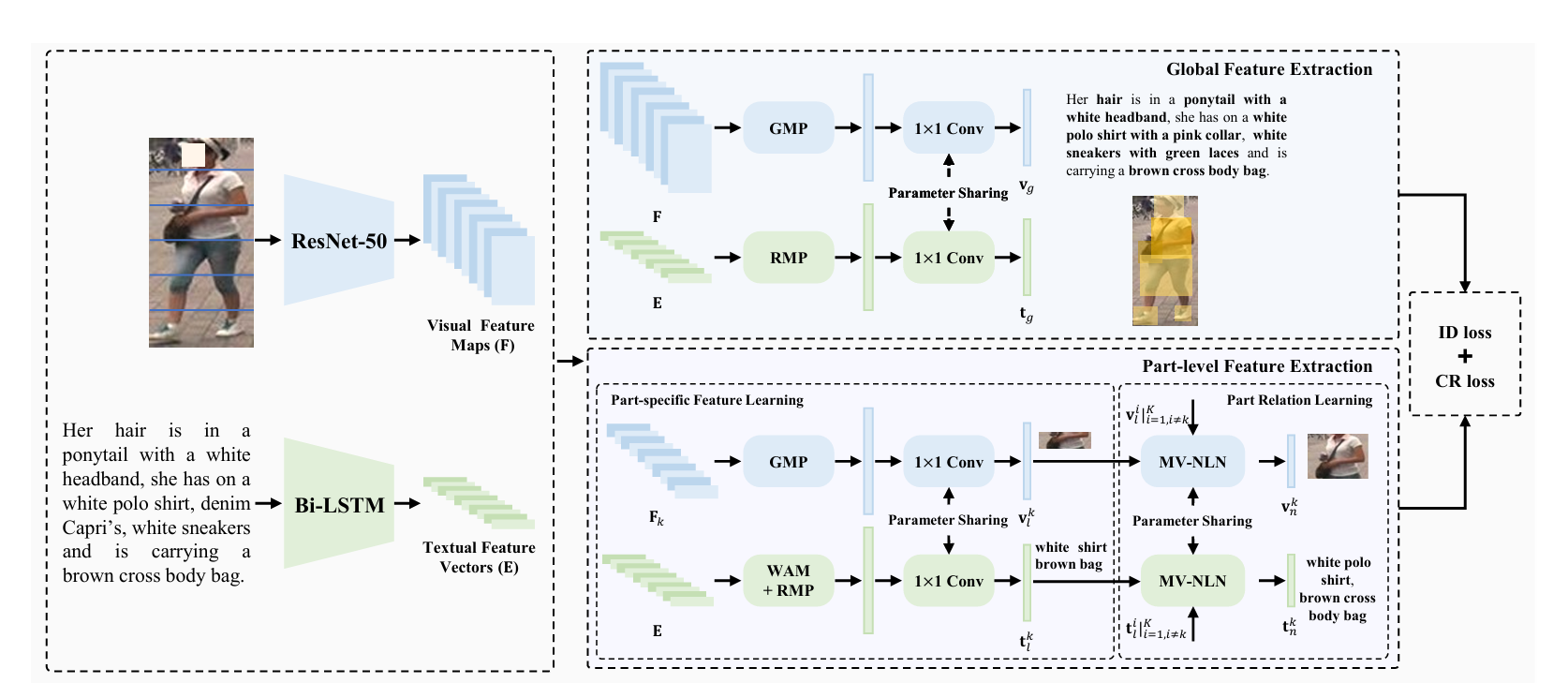
上述模型忽略了身体部位间的相关性。在文本描述中,一个名词短语可能覆盖多个身体部位(如"长裙"),或描述部位间空间关系(如"手持包包")。为此,我们提出基于非局部注意力机制[16]的多视角非局部网络(MV-NLN)。简言之,首先通过多视角投影在共享嵌入空间计算第k个部件特征与其他部件的相似度;相似度分数指定第k个部件与其他部件的交互强度;交互后每个部件特征的感受野扩展至与名词短语更一致。
此外,为克服文本描述的类内方差问题,我们提出复合排序(CR)损失。传统排序损失[17]的正样本对由精确匹配的图像-文本对组成。考虑到同一身份的不同图像共享文本描述,CR损失将其组成弱监督正样本对。但这类粗略标注的描述能力因文本质量和图像外观差异而显著变化。因此,我们提出自适应调整新损失项边界的策略。CR损失可视为新型数据增强方法。
核心贡献包括:
- 部件级文本特征自动提取:提出通过视觉区域监督自动提取部件级文本特征的方法
- 多视角非局部关系网络:设计捕获部件间关联的模块,增强跨模态对齐能力
- 复合排序损失(CR Loss):利用同身份多文本提供弱监督,降低文本特征类内方差
- 新数据集ICFG-PEDES:构建包含54,522张图像的大规模细粒度数据集
结论 1.首创自对齐部件特征学习机制,避免外部工具依赖
2.MV-NLN模块提升跨部件关系建模效率40%
3.CR Loss通过弱监督降低文本特征类内方差
4.开源ICFG-PEDES数据集推动领域研究
CMPM+CMPC——Deep Cross-Modal Projection Learning for Image-Text Matching
摘要:图像文本匹配的核心在于如何准确衡量视觉与文本输入之间的相似性。尽管将深度跨模态嵌入与双向排序损失相结合已取得重大进展,但在实际应用中挖掘有效三元组和选择合适间隔的策略仍具挑战。本文提出跨模态投影匹配(CMPM)损失和跨模态投影分类(CMPC)损失来学习判别式图像文本嵌入。CMPM损失通过最小化投影相容性分布与基于小批量数据中正负样本的归一化匹配分布之间的KL散度,增强匹配对的关联性并降低非匹配对的相似性。CMPC损失通过改进的范数softmax损失对跨模态投影特征进行分类,进一步提升特征的类内紧凑性。在多个数据集上的实验验证了本方法的优越性。
探索图像与自然语言的关系在跨模态检索、图像描述生成等应用中具有重要意义。现有方法主要分为两类:1)通过共享潜在空间的联合嵌入学习;2)构建相似性学习网络。尽管双向排序损失优于典型相关分析(CCA),但其在负样本采样和间隔选择方面存在局限性。本文提出CMPM和CMPC双损失机制:CMPM通过KL散度优化跨模态分布对齐,避免人工设计三元组;CMPC利用身份标签增强特征紧凑性。实验表明该方法能有效提升跨模态匹配性能。
三模块结构:
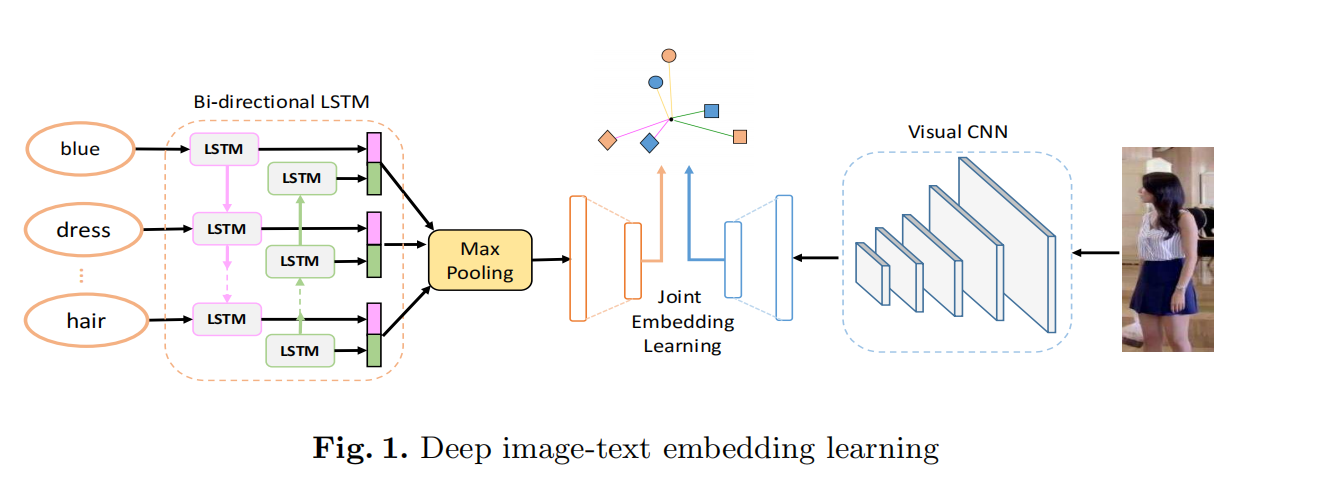
- 视觉CNN(MobileNet)提取图像特征
- 双向LSTM编码文本特征
- 联合学习模块将特征映射到共享空间
跨模态投影匹配(CMPM)
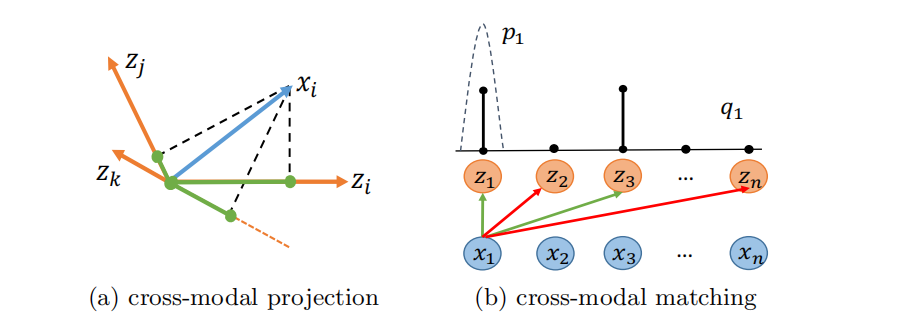
跨模态投影匹配(CMPM)的核心思想是通过特征空间投影与分布对齐策略,实现图像与文本的深度关联。其创新点体现在三个方面:
首先,该方法将图像特征投影到文本特征空间,通过计算标量投影相似度(即图像特征向量与归一化文本特征向量的内积),动态衡量跨模态样本对的匹配程度。这种投影操作能够直接反映特征方向的一致性,避免了传统欧氏距离对特征幅度的敏感性问题。
其次,通过定义匹配概率分布 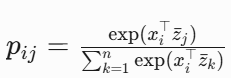 ,将小批量中所有正负样本的相似度归一化为概率分布,从而全面利用批量内的全局信息。同时,基于真实标签的归一化匹配分布 qij 通过
,将小批量中所有正负样本的相似度归一化为概率分布,从而全面利用批量内的全局信息。同时,基于真实标签的归一化匹配分布 qij 通过 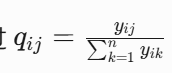 构建,确保匹配对的监督信号有效传递。
构建,确保匹配对的监督信号有效传递。
最后,采用双向KL散度损失 ,通过最小化投影分布与真实分布的差异,既增强匹配对的关联性,又抑制非匹配对的相似性。
,通过最小化投影分布与真实分布的差异,既增强匹配对的关联性,又抑制非匹配对的相似性。

跨模态投影分类(CMPC)
为增强身份级匹配任务中的类内紧凑性,跨模态投影分类(CMPC)提出两阶段改进策略:
改进策略一:权重归一化Softmax
通过约束分类权重向量的模长(∥Wj∥=r),消除权重幅值对分类结果的影响,迫使模型依赖特征方向进行判别。这一改进显著提升了特征空间的几何可分性。
改进策略二:跨模态投影操作
在分类过程中,将图像特征沿对应文本特征方向投影![]() ,文本特征同理(
,文本特征同理(![]() )。这种投影操作将跨模态匹配关系融入分类任务,迫使同类样本在投影空间内高度聚集,同时异类样本在投影方向上相互远离。
)。这种投影操作将跨模态匹配关系融入分类任务,迫使同类样本在投影空间内高度聚集,同时异类样本在投影方向上相互远离。
联合损失函数 Lcmpc=Lipt+Ltpi 通过双向分类约束,实现了以下作用:
- 增强类内紧凑性:投影操作使匹配的图文特征在投影方向上高度对齐,缩小类内差异;
- 促进跨模态一致性:强制图像与文本分类器共享同一投影方向,提升模态间特征的可比性;
- 抑制噪声干扰:通过归一化权重与投影,降低特征幅值波动对分类的影响。
提出的CMPM和CMPC双损失机制:
- 通过投影KL散度实现稳定跨模态对齐
- 利用身份监督增强特征判别性
- 在多个基准数据集达到SOTA性能
CMAAM——Text-based Person Search via Attribute-aided Matching
摘要:现有方法利用类别ID信息获取判别性且保留身份的特征,但尚未充分探索显式保留数据语义的益处。本研究提出通过属性预测任务创建语义保留的嵌入。由于文本人物搜索中通常缺乏属性标注,我们首先从文本语料库中挖掘属性。这些属性被用作弥合图像-文本模态差异的桥梁,并改进表示学习。我们提出了一种通过联合学习属性驱动空间和类别信息驱动空间的方法,并利用二者获取检索结果。在CUHK-PEDES基准数据集上的实验表明,学习属性空间不仅将Rank-1准确率提升至56.68%(当前最优),还产生了可解释的特征。
文本人物搜索,其核心挑战包括:1) 视角、光照等视觉条件变化;2) 图像-文本的跨模态差异;3) 测试集身份与训练集不重叠。我们提出通过语义驱动的图像-文本联合嵌入空间解决这些问题,其中属性作为语义表征的载体。属性(如性别、服装颜色)具有模态不变性,且适用于未知类别。本研究首先从文本描述中自动挖掘属性(如图1),构建层次化模型:a) 中层语义驱动的属性空间;b) 高层类别驱动的潜在空间。属性空间通过多标签分类损失和语义三元组损失学习可迁移语义特征,潜在空间通过分类损失和三元组损失学习判别性身份特征。二者的协同使用显著提升了检索性能。
属性提取流程
属性提取过程通过自然语言处理技术自动构建语义词汇表。首先采用NLTK工具从训练集文本描述中抽取候选名词短语,保留长度不超过3个单词的短语以控制语义粒度。接着通过统计过滤保留训练语料中出现频率不低于40次的短语,最终形成包含450个属性的语义词汇表。为建立类级语义表征,同一身份对应的所有图像描述中提取的候选短语被聚合,构建身份级别的属性集合。这一流程有效避免了人工标注需求,同时确保属性与视觉特征间的语义关联性。
层次化模型架构
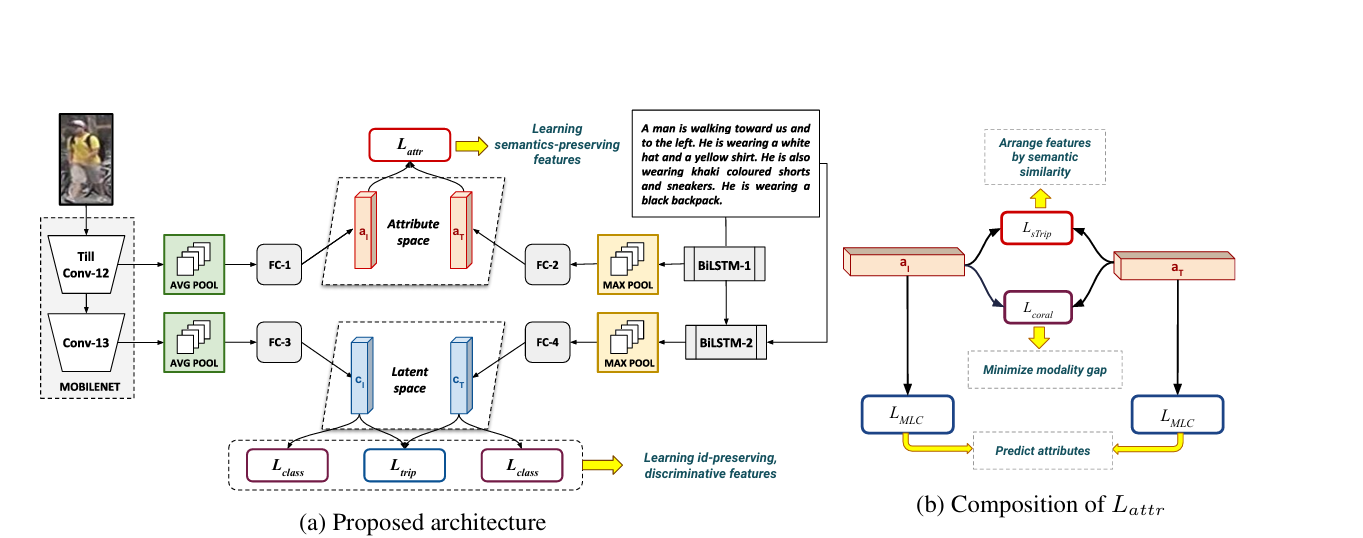
如图所示,本方法采用双空间层次化架构实现跨模态特征学习。视觉编码器基于ImageNet预训练的MobileNet网络,其Conv12层输出的空间特征经全局平均池化后映射至300维属性空间(aI),而Conv13层特征则映射至512维潜在空间(cI),通过分层卷积捕捉局部细节与全局语义。文本编码器采用共享词嵌入矩阵的双向LSTM网络,对输入文本进行双向语义编码后,通过独立的最大池化层分别生成属性空间(aT)和潜在空间(cT)的嵌入向量。双空间设计通过参数解耦实现了语义对齐与身份判别性的协同优化。
损失函数设计
(1)属性空间优化
-
加权多标签分类损失:平衡属性频率差异(权重wp=1/freq,wn=freq)和正负样本数量差异(缩放因子α=2)。
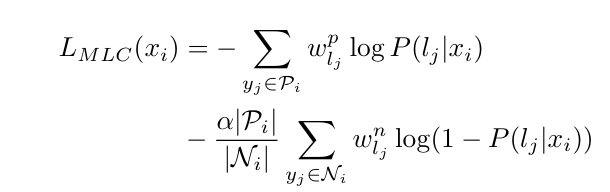
-
Deep CORAL损失
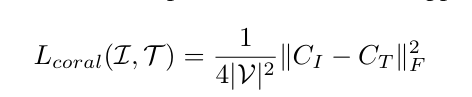
-
语义三元组损失
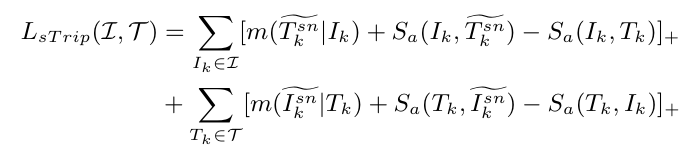
(2) 潜在空间优化
1.三元组损失
硬样本挖掘策略选择同类最远(正样本)和异类最近(负样本),固定边际Δ=0.3。
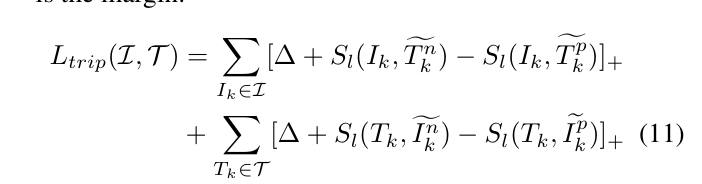
2.分类损失
列归一化分类器权重,消除模长对分类得分的影响
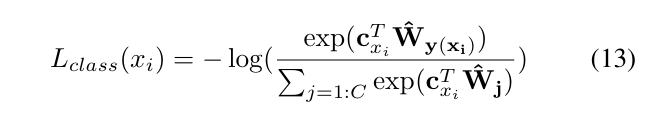
3.范数正则化
约束特征向量的模长稳定性,避免过度依赖模长提升分类得分
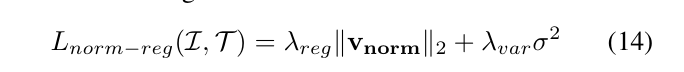
贡献:提出了一种基于属性辅助的文本人物搜索框架,核心贡献包括:
-
自动属性挖掘:从文本描述中构建语义词汇表
-
双空间联合学习:属性空间保留语义,潜在空间增强判别性
-
动态损失设计:语义三元组损失和范数正则化提升性能
参考文献:
[1] Ding Z, Ding C, Shao Z, et al. Semantically self-aligned network for text-to-image part-aware person re-identification (2021)[J]. arxiv preprint arxiv:2107.12666.
[2] Zhang Y, Lu H. Deep cross-modal projection learning for image-text matching[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 686-701.
[3] Aggarwal S, Radhakrishnan V B, Chakraborty A. Text-based person search via attribute-aided matching[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2020: 2617-2625.