【Linux】进程基本概念与基本操作
6.进程基本概念与基本操作
文章目录
- 6.进程基本概念与基本操作
- 一、进程概念
- 二、查看进程
- 查看详细信息
- 用代码查看进程中的信息
- 结束进程
- 对进程查看命令的补充
- 三、进程属性
- PPID
- gitppid()
- -bash
- 四、通过系统调⽤创建进程-fork初识
- fork()函数
- fork()创建进程的特点
- 对fork()返回值的理解
- 创建多进程
一、进程概念
操作系统中有一个模块叫做进程管理。在我们之前,一直在讲两个大话题,一个是冯诺伊曼纯硬件,另一个是操作系统。在操作系统部分,我们得到了管理先描述、再组织以及系统调用这样的概念。我们也理解操作系统不会把自己 彻底暴露给上层。当我们体会到这点时,我们再来谈操作系统内局部的一个功能模块,即进程管理。
在课本上一般会给出的概念:
-
课本概念:程序的⼀个执⾏实例,正在执⾏的程序等
-
内核观点:担当分配系统资源(CPU时间,内存)的实体。
对于我们当前程序来说,仅仅是可执行程序所对应的代码和数据。当它被加载到内存后,变成进程,它仅仅包含代码和数据。但现在有个问题,我们需要管理这个进程,需要在操作系统内部找到这个进程的代码和数据,需要知道它的优先级和状态。
操作系统通过进程的属性数据管理进程,类似于校长通过学生的数据进行管理,无需与学生见面,只需获取学生的姓名、成绩等属性数据即可进行管理。
对于操作系统而言,为管理进程,需有对应的属性数据。在操作系统中,加载进程时,不仅将程序加载到内存,还为进程创建内核级的数据结构,通常称为PCB。在Linux中,PCB具体称为task,即任务结构体。
- 在Linux中描述进程的结构体叫做task_struct
- task_struct是Linux内核的⼀种数据结构,它会被装载到RAM(内存)⾥并且包含着进程的信息。
- 将程序加载内存时,操作系统为管理该进程会创建对应的管理数据结构,称为taskstruct。taskstruct包含进程相关的所有属性,操作系统内部维护此结构后,该进程才被操作系统认可。
- 进程是被调度的。
- 通过系统调⽤获取进程标⽰符:进程id(PID),⽗进程id(PPID)
现在可以简单看一下task_struct中的一些成员变量:
标⽰符: 描述本进程的唯⼀标⽰符,⽤来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执⾏的下⼀条指令的地址。
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下⽂数据: 进程执⾏时处理器的寄存器中的数据[休学例⼦,要加图CPU,寄存器]。
I∕O状态信息: 包括显⽰的I/O请求,分配给进程的I∕O设备和被进程使⽤的⽂件列表。
记账信息: 可能包括处理器时间总和,使⽤的时钟数总和,时间限制,记账号等。
其他信息• 具体详细信息后续会介绍
二、查看进程
我们先写一段代码编译成可执行程序:
[user@hcss-ecs-b735 lession10]$ cat code.c
#include <stdio.h>
#include <unistd.h>int main()
{printf("code ready!\n");int i = 0;while(i <= 1000){i++;printf("hello linux\n");sleep(1);}return 0;
}
[user@hcss-ecs-b735 lession10]$ make
gcc -o code code.c
[user@hcss-ecs-b735 lession10]$ ls
code code.c makefile
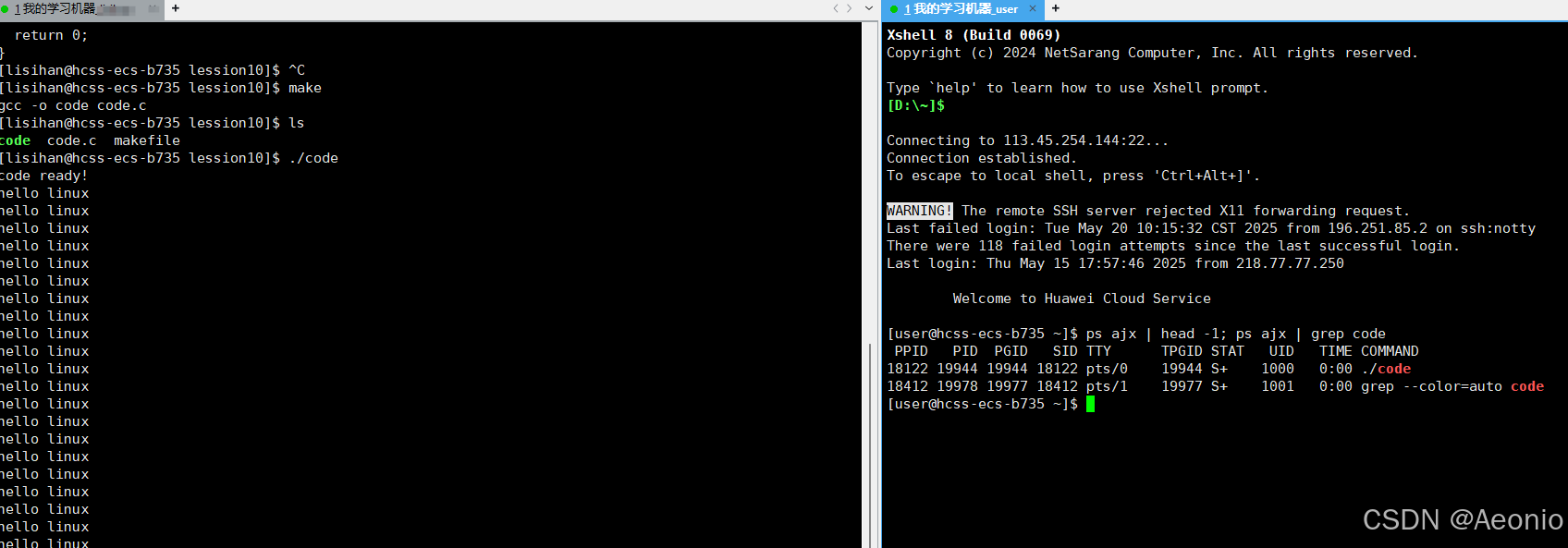
将他执行起来之后我们打开另一个用户,使用指令ps ajx可以查看当前服务器上所有的进程,
但如果我们呢想要查看指定程序的进程我们可以输入ps ajx | head -1; ps ajx | grep code
或者:ps ajx | head -1 && ps ajx | grep code
这里有几个小的知识点:
- 在一次指令输入的时候可以用
;或者&&将不同指令分隔开,实现一次输入多条指令 ps ajx | head -1表示显示进程的第一行,就是列表的各项信息,ps ajx | grep code表示显示指定程序的进程
查看详细信息
如果要查看进程更加详细的信息,由于在Linux系统中一切皆文件,所以进程也可以以文件的形式反应。进程的信息可以通过==/proc== 系统⽂件夹查看
如:要获取PID为1的进程信息,你需要查看 /proc/1 这个⽂件夹
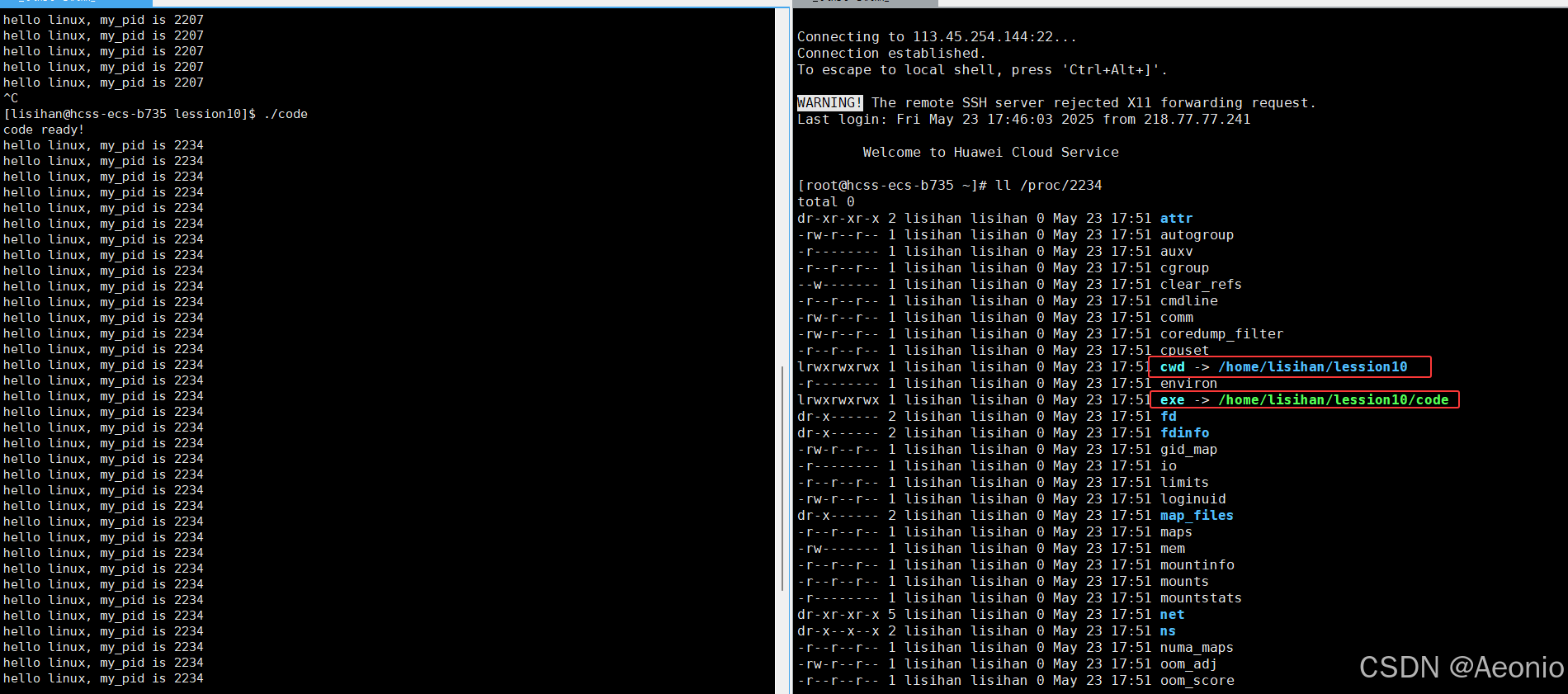
在这些详细信息中,有两个比较特殊的属性:
- exe是说明这个进程是由哪一个位置的哪一个文件执行得到的,当我们将这个可执行文件删除之后,可以发现这个进程仍然在运行,因为这个可执行程序已经加载到内存中去了,我们删除的是磁盘中的可执行程序文件

-
cwd是当前工作目录
之前C语言文件操作中,当我们创建一个不存在的文件时,会默认在当前目录下创建该文件,这个当前路径是指:在一个进程启动的时候,会记录当前启动的路径到cwd,即为进程启动的路径,在代码中,最终新建文件时,其路径是一个全路径,即按照这种方式拼接路径,然后再拼上你指定的文件名。此时系统会以默认路径的形式来新建文件,而当前路径前缀就是进程默认所处的路径,所以新建文件默认就在当前路径下。
因此我们可以用一个系统调用函数来重新指定我们执行该程序的路径
chdir(),chdir()函数将生成由路径所指向的路径名命名的目录参数成为当前工作目录,(这个与getpid()差不多,都是写在程序代码中的系统调用函数)但我们在使用这个函数的时候要注意我们重新修改的路径对于我们的权限限制。
用代码查看进程中的信息
从上面的图中我们可以看到./code的进程信息,其中它的进程id(PID)为19944,我们也可以在程序内部获取它运行时候的PID,我们使用getpid这个函数就行了如果不知道这个函数需要包含那些头文件和怎么使用用man指令去搜索就行
//code.c
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>int main()
{pid_t my_pid = getpid();printf("code ready!\n");int i = 0;while(i <= 1000){i++;printf("hello linux, my_pid is %d\n", my_pid);sleep(1);}return 0;
}
执行结果:
[user@hcss-ecs-b735 lession10]$ ./code
code ready!
hello linux, my_pid is 21255
hello linux, my_pid is 21255
hello linux, my_pid is 21255
hello linux, my_pid is 21255
hello linux, my_pid is 21255
hello linux, my_pid is 21255
hello linux, my_pid is 21255
hello linux, my_pid is 21255
结束进程
- 使用
ctrl + c直接删除,这个只能在启动进程的机器中删除 - 使用
kill -9 [PID],具体有关信号的内容暂时不讨论
对进程查看命令的补充
-
常用的进程查看命令其实是ps命令。实际上,在系统层面上,查看进程的接口是
/proc目录,该目录包含所有进程的详细信息。ps命令的底层实现就是打开这个目录,对目录内容进行文本分析,以形成ps命令的输出。也就是说,/proc目录包含了我们需要的进程信息。 -
/proc目录中有许多数字和子目录,系统提供了很多接口可以直接遍历查找目录,提取文件属性和内容,从而构建出ps命令。因此,ps命令的底层实现是对proc目录进行文本分析。当然,不排除有些查看进程属性的命令本质可能使用了一些系统调用,但操作系统提供的系统调用个数有限。如果想获取更详细的信息,我们需要通过proc目录来查询。因此,ps命令的实现与proc目录有关,系统中很多查看进程属性的命令也都与它相关。 -
proc目录。它不是磁盘级的文件。
它不是磁盘级的文件,这意味着如果我今天关闭电脑,proc目录及其内容将被全部释放,不会在磁盘上保存任何信息。当操作系统启动时,它会创建很多进程,可以理解为操作系统在启动时,会遍历所有进程的pcb。
在遍历的过程中,操作系统会构建出一套内存级的文件系统,将进程相关的属性以文件的形式展现出来。但实际上,这些文件并没有在磁盘上保存任何信息,所以不用担心数据频繁更新、创建和删除会影响系统效率。
现在能理解为什么新建文件立马出现,删除进程文件自动消失,因为它是实时更新的,因为它本来就是内存中的数据。
三、进程属性
PPID
在我们系统中启动任何进程时,除了有自己的进程PID之外,还有一个东西叫做PPID,即父进程ID。在Linux系统中启动后,新创建的进程是如何被创建的呢?如果你以某种方式启动了一个进程,是父进程帮你创建的,虽然常说进程是操作系统建的,但这里是父进程让操作系统这么建的。
gitppid()
一个进程要获取自己的PID,叫做getpid();如果要获取自己所对应的父进程ID,我们叫做getppid。它的返回值是pid_t类型的整数。
//我们在命令行中运行下面的代码,多运行几次
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{printf("code ready!\n");int i = 0;while(i <= 1000){i++;printf("hello linux, my_pid is %d, my ppid is %d\n", getpid(), getppid());sleep(1);}return 0;
}
结果:
[user@hcss-ecs-b735 lession10]$ ./code
code ready!
hello linux, my_pid is 3006, my ppid is 2319
hello linux, my_pid is 3006, my ppid is 2319
^C
[user@hcss-ecs-b735 lession10]$ ./code
code ready!
hello linux, my_pid is 3007, my ppid is 2319
hello linux, my_pid is 3007, my ppid is 2319
^C
[user@hcss-ecs-b735 lession10]$ ./code
code ready!
hello linux, my_pid is 3008, my ppid is 2319
hello linux, my_pid is 3008, my ppid is 2319
^C
[user@hcss-ecs-b735 lession10]$ ./code
code ready!
hello linux, my_pid is 3009, my ppid is 2319
hello linux, my_pid is 3009, my ppid is 2319
^C
我们会发现,这几次运行的结果中pid都不一样,但是ppid是一样的。我们可以简单看一下ppid这个进程的详细内容
-bash
[root@hcss-ecs-b735 ~]# ps ajx | head -1 && ps ajx | grep 2319 PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND2318 2319 2319 2319 pts/4 3013 Ss 1000 0:00 -bash2319 3013 3013 2319 pts/4 3013 S+ 1000 0:00 ./code2359 3020 3019 2359 pts/5 3019 S+ 0 0:00 grep --color=auto 2319
-
本质上,我们可以设想其执行过程:一个名为bash的进程创建子进程来执行我们的代码。换言之,实际上我们在命令行上启动的程序,最终是由bash进程执行的。bash是什么?bash它被称为命令行解释器。当时我们讲过,shell是所有命令行解释器外壳程序的统称,而在linux系统中,我们通常使用的是bash。换句话说,我们在命令行上启动的所有进程,其父进程其实都是bash。
-
每一次登录,我们的系统都会为我们当前的登录用户创建一个bash程序,前面带了一个短杠,代表的是我们当前用户是使用我们的命令行终端进行登录的,所以呢。我们如果同时登录了很多次,你如果想查的话,你可以看到很多我们对应的这样的bash程序
[root@hcss-ecs-b735 ~]# ps ajx | head -1 && ps ajx | grep "\-bash" #目前有四个用户登录了云服务器PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND2318 2319 2319 2319 pts/4 2319 Ss+ 1000 0:00 -bash2357 2359 2359 2359 pts/5 3804 Ss 0 0:00 -bash3552 3553 3553 3553 pts/0 3553 Ss+ 1000 0:00 -bash3584 3587 3587 3587 pts/1 3587 Ss+ 1000 0:00 -bash2359 3805 3804 2359 pts/5 3804 S+ 0 0:00 grep --color=auto \-bash
四、通过系统调⽤创建进程-fork初识
fork()函数
一个系统调用函数;它的作用是创建一个子进程;返回值有一点特殊:一旦我们创建成功了,那么它就会返回子进程的pid给父进程,返回0给子进程,说失败了的话,-1就被返回给父进程,没有子进程会被创建。
以下面的代码作为例子:
[user@hcss-ecs-b735 lession10]$ cat code2.c
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{printf("I am a process, pid %d, ppid %d\n", getpid(), getppid());pid_t id = fork();(void)id; //防止程序报警告,这里相当于用一下这个变量printf("I am a branch, pid %d, ppid %d\n", getpid(), getppid());return 0;
}
[user@hcss-ecs-b735 lession10]$ ./code2
I am a process, pid 7269, ppid 2319
I am a branch, pid 7269, ppid 2319
I am a branch, pid 7270, ppid 7269
运行结果:
-
因为经过fork,我们整个程序,它的执行分支就不再是一条执行分支了,而从fork之后,它会有两条执行分支,既然是两条执行分支。那么我们往后的代码,这两个执行分支都要跑,所以一个进程调printf,另一个也要调,那么很明显,这两个执行分支,一个pad 7269,一个pid 7270, 很明显是连续的,这证明他俩的pid进程很明显是连续创建的。显然7269是7270的父进程,也就是最开始运行的哪一个进程。
-
也就是说fork之后两条分支,一条一个分支,一个进程叫做父进程,一个进程叫做子进程。而父进程就是你这个进程自己,而你经过fork系统调用,创建出来的新的执行流叫做子进程。
-
一个进程可以创建多个子进程,但是任何一个子进程只有一个父进程。所以其实linux系统当中所有的进程也是树形结构
fork()创建进程的特点
我们下面再来看一个代码:
[user@hcss-ecs-b735 lession10]$ cat code3.c
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>int gn = 0;int main()
{printf("I am a process, pid %d, ppid %d\n", getpid(), getppid());pid_t id = fork();if(id == 0) //说明他是子进程{while(1){printf("父进程, pid %d, ppid %d, gn = %d\n", getpid(), getppid(), gn);gn += 2;sleep(1);}}else{while(1){printf("子进程, pid %d, ppid %d, gn = %d\n", getpid(), getppid(), gn);gn++;sleep(1);}}return 0;
}
[user@hcss-ecs-b735 lession10]$ ./code3
I am a process, pid 8060, ppid 2319
子进程, pid 8060, ppid 2319, gn = 0
父进程, pid 8061, ppid 8060, gn = 0
子进程, pid 8060, ppid 2319, gn = 1
父进程, pid 8061, ppid 8060, gn = 2
子进程, pid 8060, ppid 2319, gn = 2
父进程, pid 8061, ppid 8060, gn = 4
子进程, pid 8060, ppid 2319, gn = 3
父进程, pid 8061, ppid 8060, gn = 6
子进程, pid 8060, ppid 2319, gn = 4
父进程, pid 8061, ppid 8060, gn = 8
子进程, pid 8060, ppid 2319, gn = 5
父进程, pid 8061, ppid 8060, gn = 10
子进程, pid 8060, ppid 2319, gn = 6
父进程, pid 8061, ppid 8060, gn = 12
父进程, pid 8061, ppid 8060, gn = 14
子进程, pid 8060, ppid 2319, gn = 7
^C
-
现象:fork这个函数一旦调用,从fork往后就会有两个进程了,这两个进程呢,他们会各自执行,各自代码,其实这两个代码他们都会执行。而且,尽管在代码中是同一个全局变量,但是这两个进程执行的时候互相独立,互不干扰
-
理解性解释:在我们的linux系统里,包括所有的系统里fork之后俩进程,其中新创建的这两个进程是父子关系,一般而言,它们两个代码是会共享的,但是数据是各自私有一份的,进程它是具有很强的独立性的,多个进程之间运行时互不影响。即便是父子两个进程之间,也必须得有很强的独立性。
对fork()返回值的理解
-
在前面提到了fork()的返回值是一旦我们创建成功了,那么它就会返回子进程的pid给父进程,返回0给子进程,说失败了的话,-1就被返回给父进程,没有子进程会被创建。本质原因是因为父子之间的对应关系是其实是一比n的,所以父进程需要拿到多个子进程的pid对子进程进行管理。
-
听起来好像fork函数有两个返回值,一个返回给父进程,一个返回给子进程。如何理解一个函数有两个返回值?现在暂时解释不清,按照理解,应该是在fork函数返回之前,已经完成了父子进程的创建,之后的两个进程具有独立性,互不干扰。暂时只能怎么理解。
-
简单了解一下:fork之后,在父子进程中谁先运行?答案是不确定,因为fork之后谁先运行完全由操作系统自主决定,由操作系统里面有一个模块叫做调度器自主决定。
创建多进程
穿插一个小知识点:
我们平时写代码的时候,为什么那个代码,它有时候它能够检测出语法错误,实际上是因为你的编译器在你写代码的时候,它不断在调用你的编辑器,比如vim, 或者你的vs.或者是你的任何一款IDE,他会不断在后台去调用你的gcc,或者是g++有两种调用模式,一种是我们的命令行的,另一种是在后端运行的,相当于它在系统当中帮我们去跑,跑完之后把语法报错,然后就给我们呈现出来。
所以它为什么在我们写代码时就能检测出代码的错误呢?因为你的编译器,你的IDE环境在后台自动的不断的再去调你的编译器。所以有时候你写代码时会发现你的电脑有可能会突然会卡一点点,如果尤其是负载大的时候,为什么?因为你的代码不断的在被做,这叫做语法扫描。扫描不是IDE 做的,是IDE在调你的gcc或者g++调你的编译器。
创建多进程的代码如下:
#include <iostream>
#include <vector>
#include <sys/types.h>
#include <unistd.h>
using namespace std;const int num = 10;void SubProcessRun()
{while(true){cout << "I am sub process, pid: " <<getpid() <<" ,ppid: " << getppid() << std::endl;sleep(5);}
}int main()
{vector<pid_t> allchild;for(int i = 0; i<num; i++){pid_t id = fork();if(id == 0){// 子进程SubProcessRun();}// 这里谁执行?父进程一个人allchild.push_back(id);}// 父进程cout << "我的所有的孩子是:";for(auto child: allchild){cout << child << " ";}cout << endl;sleep(10);while(true){cout << "我是父进程,pid: " <<getpid() << endl;sleep(1);}return 0;
}
代码不做解释,应该能看懂。
运行结果:
[user@hcss-ecs-b735 lession10]$ ./myprocess
I am sub process, pid: 2784 ,ppid: 2783
I am sub process, pid: 2785 ,ppid: 2783
我的所有的孩子是:2784 2785 2786 2787 2788 2789 2790 2791 2792 2793
I am sub process, pid: 2787 ,ppid: 2783
I am sub process, pid: 2789 ,ppid: 2783
I am sub process, pid: 2788 ,ppid: 2783
I am sub process, pid: 2790 ,ppid: 2783
I am sub process, pid: 2791 ,ppid: 2783
I am sub process, pid: 2792 ,ppid: 2783
I am sub process, pid: 2786 ,ppid: 2783
I am sub process, pid: 2793 ,ppid: 2783
I am sub process, pid: 2784 ,ppid: 2783
I am sub process, pid: 2785 ,ppid: 2783
I am sub process, pid: 2787 ,ppid: 2783
I am sub process, pid: 2789 ,ppid: 2783
I am sub process, pid: 2788 ,ppid: 2783
I am sub process, pid: 2790 ,ppid: 2783
I am sub process, pid: 2791 ,ppid: 2783
I am sub process, pid: 2792 ,ppid: 2783
I am sub process, pid: 2786 ,ppid: 2783
I am sub process, pid: 2793 ,ppid: 2783
可是如果父进程或者子进程,他就想把数据交给对方,就涉及到我要把我的数据交给另一个进厂,就必定要打破独立性,要让多个竞争之间互相通信起来。这种技术是属于单独需要我们去设计的,因为天然的技术是具有独立性的,我们要打破独立性,打破独立性,让不同的竞争能够把消息数据互相传递起来,这种技术叫做通信技术。这个后面会学习。