【昇腾开发者训练营:Dify大模型部署实战】MindIE + Dify + DeepSeek + Embedding模型 + Rerank模型
文章目录
- 部署 Dify
- 1. Dify 适配 ARM
- 2. 安装 docker
- 3. 启动 Dify
- MindIE+Dify 实操手册
- 1. 基础环境搭建
- 1.1 环境检查
- 1.2 下载模型权重
- 1.3 获取MindIE镜像
- 2. 启动容器
- 3. 纯模型推理测试
- 3.1 纯模型对话测试
- 3.2 性能测试
- 4. 服务化部署
- 4.1 MindIE 配置
- 4.2 MindIE 服务化
- 4.3 发起测试请求
- 5. 接入 Dify
- 5.1 访问 Dify
- 5.2 配置大模型
- 5.3 创建聊天助手
- 进阶实操
- 1. 环境部署
- 1.1 下载模型权重
- 1.2 获取镜像
- 2. 启动容器
- 3. 推理测试
- 4. 接入 Dify
- 4.1 配置模型
- 4.2 创建知识库
- 5. 创建聊天助手
本次我负责【昇腾开发者训练营】的【DeepSeek+Dify大模型推理部署实践】部分的讲解,需要完成PPT、实操手册、8台服务器的环境部署~
机器:Atlas800 9000 即昇腾上一代芯片 910A,8卡32G,裸金属。
可能的卡点:ARM架构上部署Dify、910A上跑MindIE、910A上跑BGE向量模型和重排序模型。
注:本文档同样适用于 Atlas800T A2(910B)、Duo卡等设备。
更好的阅读体验:点击传送门


部署 Dify
1. Dify 适配 ARM
git clone https://github.com/langgenius/dify.git
cd dify
git checkout 0.15.3
cd docker/
cp .env.example .env
1. 修改配置文件
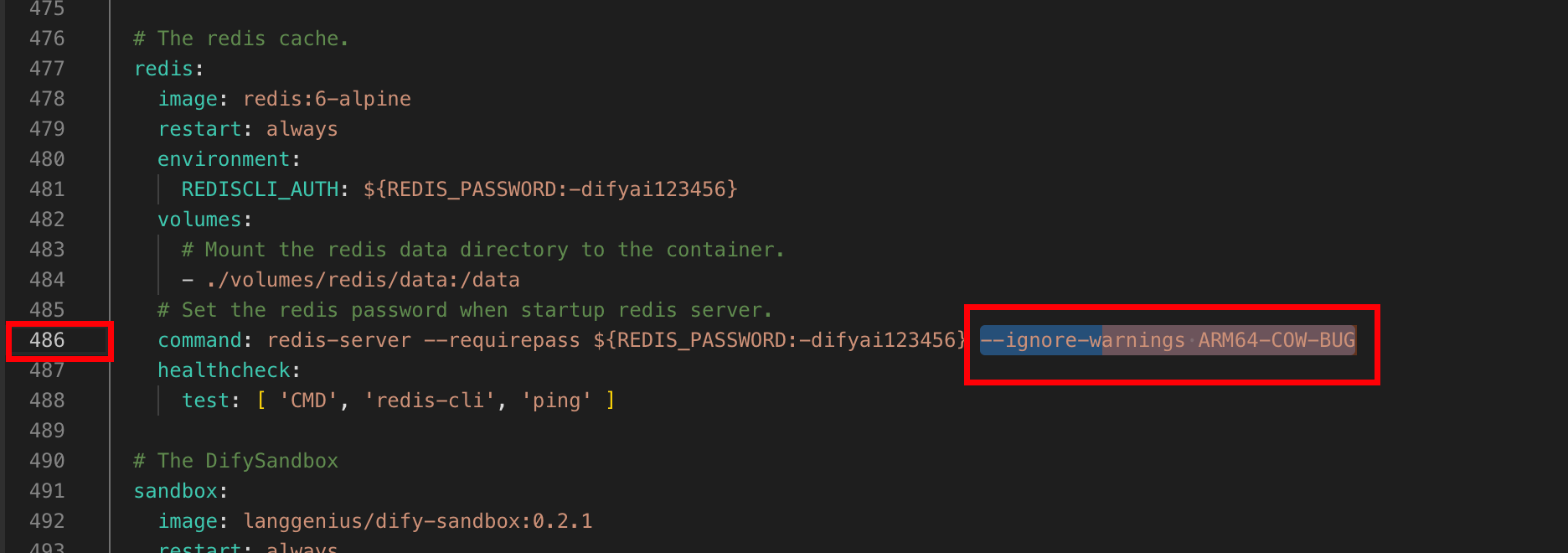
vim docker-compose.yaml
# 在redis的command后添加:
--ignore-warnings ARM64-COW-BUG
2. 修改sandbox版本
将sandbox版本从0.2.10修改为0.2.1。0.2.10版本会出现新增模型失败的情况,修改后不使用插件式的方式,可以正常添加。
2. 安装 docker
# 使用下面命令一键安装 docker 和 docker-composesudo yum install -y docker-engine docker-engine-selinux && sudo bash -c 'cat > /etc/docker/daemon.json <<EOF
{"registry-mirrors": ["https://docker.1ms.run","https://docker.xuanyuan.me"]
}
EOF' && sudo systemctl restart docker && sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose && sudo chmod +x /usr/local/bin/docker-compose
3. 启动 Dify
cd dify/docker
docker-compose up -d# 停止服务并删除容器
cd dify/docker
docker-compose down
MindIE+Dify 实操手册
本文档以 Atlas 800-9000 服务器和 DeepSeek-R1-Distill-Qwen-32B-W8A8 模型为例,让开发者快速开始使用MindIE进行大模型推理流程。
MindIE(Mind Inference Engine,昇腾推理引擎)是基于昇腾硬件的运行加速、调试调优、快速迁移部署的高性能AI推理引擎。
1. 基础环境搭建
注:本次昇腾开发者训练营提供的服务器基础环境已配置完毕,本章节可忽略。
1.1 环境检查
物理机部署场景,需要在物理机安装NPU驱动固件以及部署Docker,执行如下步骤判断是否已安装NPU驱动固件和部署Docker。
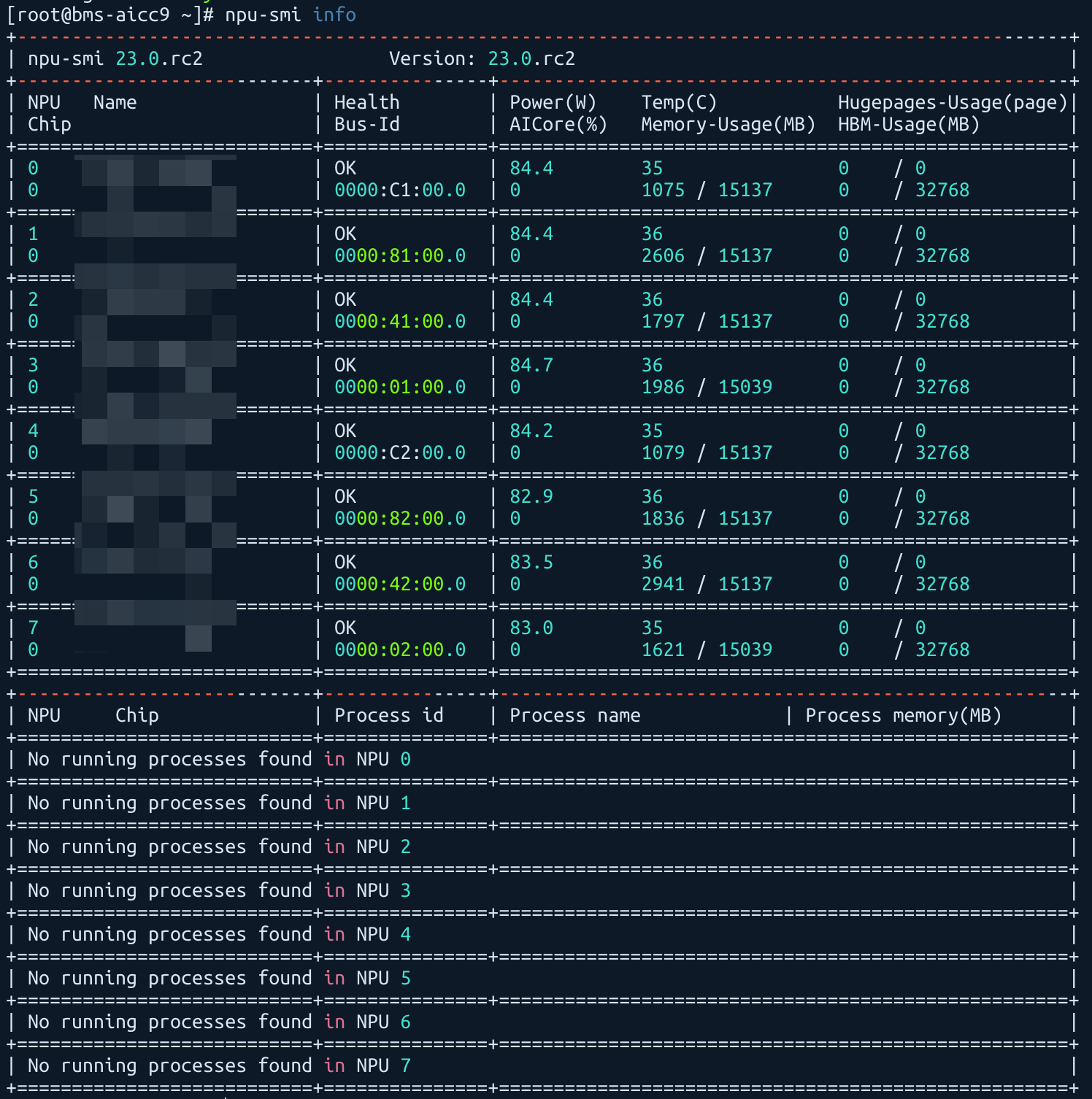
执行以下命令查看NPU驱动固件是否安装。
npu-smi info
1.2 下载模型权重
权重已下载,路径:/home/aicc/models/DeepSeek-R1-Distill-Qwen-32B-W8A8
1.3 获取MindIE镜像
昇腾镜像仓库地址:https://www.hiascend.com/developer/ascendhub/detail/af85b724a7e5469ebd7ea13c3439d48f
进入昇腾官方镜像仓库,根据设备型号选择下载对应的MindIE镜像。该镜像已具备模型运行所需的基础环境,包括:CANN、FrameworkPTAdapter、MindIE与ATB Models,可实现模型快速上手推理。
容器内各组件安装路径:
| 组件 | 安装路径 |
|---|---|
| CANN | /usr/local/Ascend/ascend-toolkit |
| CANN-NNAL-ATB | /usr/local/Ascend/nnal/atb |
| MindIE | /usr/local/Ascend/mindie |
| ATB Models | /usr/local/Ascend/atb-models |
2. 启动容器
镜像已下载,执行以下命令启动容器。
本次课程已提供8卡服务器,建议每台服务器启动4个容器,小组内自由分配,每个容器可以使用双卡进行模型推理。
# 注:命令执行前请修改 [容器名称]
# 启动容器
docker run -itd --privileged --name=m2 --net=host \--shm-size 500g \--device=/dev/davinci0 \--device=/dev/davinci1 \--device=/dev/davinci2 \--device=/dev/davinci3 \--device=/dev/davinci4 \--device=/dev/davinci5 \--device=/dev/davinci6 \--device=/dev/davinci7 \--device=/dev/davinci_manager \--device=/dev/hisi_hdc \--device /dev/devmm_svm \-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \-v /usr/local/sbin:/usr/local/sbin \-v /etc/hccn.conf:/etc/hccn.conf \-v /home/aicc:/home/aicc \swr.cn-central-221.ovaijisuan.com/wh-aicc-fae/mindie:910A-ascend_24.1.rc3-cann_8.0.t63-py_3.10-ubuntu_20.04-aarch64-mindie_1.0.T71.05 \bash# 进入容器
docker exec -it [容器名称] /bin/bash
参数说明:
| 参数 | 参数说明 |
|---|---|
| –privileged | 特权容器,允许容器访问宿主机的所有设备。 |
| –name | 设置容器名称。 |
| –device | 表示映射的设备,可以挂载一个或者多个设备。需要挂载的设备如下:/dev/davinciX:NPU设备,X是ID号,如:davinci0。 /dev/davinci_manager:davinci相关的管理设备。 /dev/hisi_hdc:hdc相关管理设备。 /dev/devmm_svm:内存管理相关设备。 |
| -v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro | 将宿主机目录“/usr/local/Ascend/driver”挂载到容器,请根据驱动所在实际路径修改。 |
| -v /usr/local/sbin:/usr/local/sbin:ro | 将宿主机工具“/usr/local/sbin/”以只读模式挂载到容器中,请根据实际情况修改。 |
| -v /path-to-weights:/path-to-weights:ro | 设定权重挂载的路径,需要根据用户的情况修改。说明请将权重文件和数据集文件同时放置于该路径下。 |
环境检查:
进入容器后,使用 npu-smi info 检查NPU驱动固件是否正常挂载。
3. 纯模型推理测试
参考文档
ATB Models的run_pa.py脚本用于纯模型快速测试,脚本中未增加强校验,出现异常情况时,会直接抛出异常信息,常用于快速验证模型的可用性。
3.1 纯模型对话测试
例如:使用/home/aicc/models/DeepSeek-R1-Distill-Qwen-32B-W8A8路径下的权重,使用2卡推理"What's deep learning?"和"Hello World.",推理时batch size为2。
pip install pandas # 测试前安装依赖
export ASCEND_RT_VISIBLE_DEVICES=1,2 # 设置使用的卡编号
cd ${ATB_SPEED_HOME_PATH}
torchrun --nproc_per_node 2 \--master_port 20030 \-m examples.run_pa \--model_path /home/aicc/models/DeepSeek-R1-Distill-Qwen-32B-W8A8 \--input_texts "What's deep learning?" "Hello World." \--max_batch_size 2# 参数说明
--nproc_per_node 使用的卡数
--input_texts 推理文本或推理文本路径,多条推理文本间使用空格分割。省略则使用默认值:"What's deep learning?"
--max_batch_size 模型推理最大batch size。
启动测试
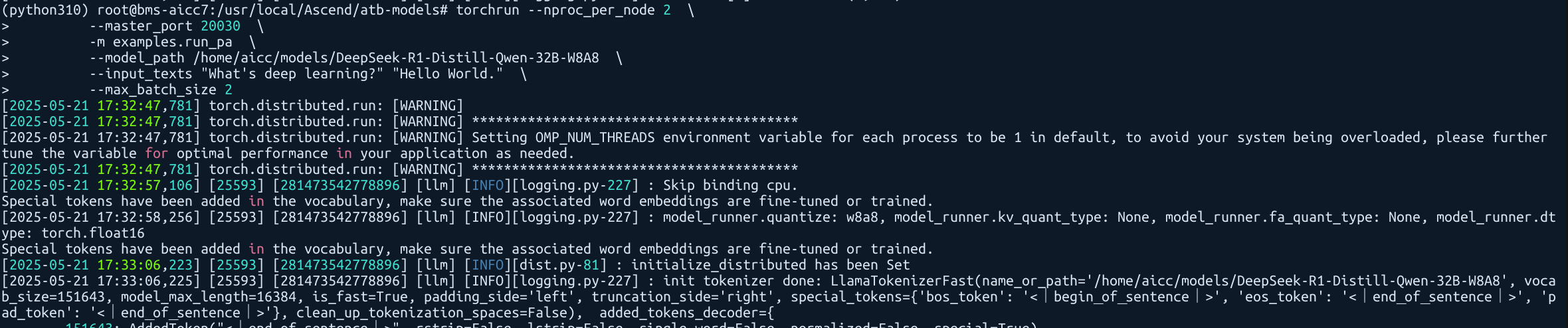
测试成功
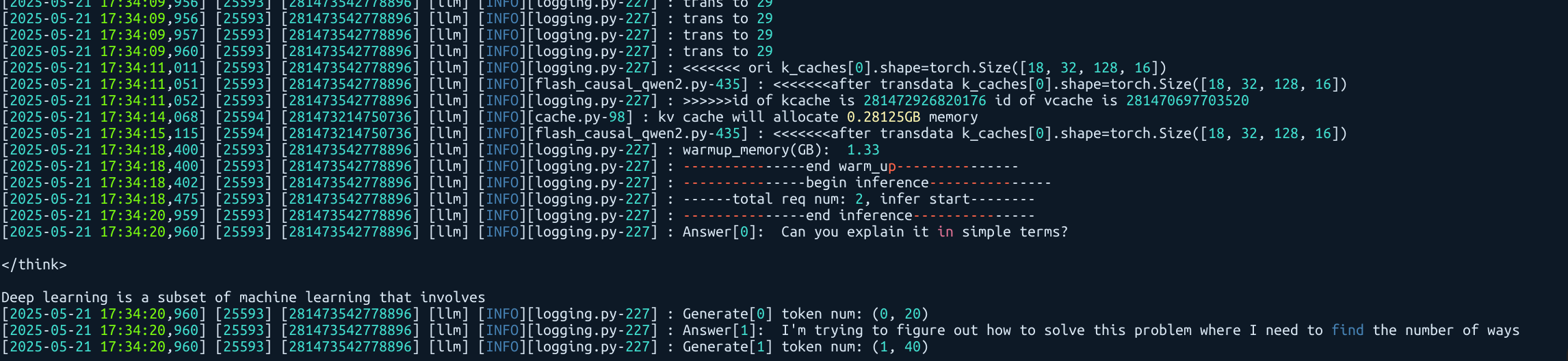
3.2 性能测试
安装依赖
pip install tiktoken fuzzywuzzy jieba rouge # 测试前安装依赖
测试脚本
batch=1, 输入长度256, 输出长度256用例的2卡并行性能测试命令为:
export ASCEND_RT_VISIBLE_DEVICES=1,2 # 设置使用的卡编号
cd $ATB_SPEED_HOME_PATH/tests/modeltest/
bash run.sh pa_fp16 performance [[256,256]] 1 \
qwen /home/aicc/models/DeepSeek-R1-Distill-Qwen-32B-W8A8 2
耗时结果会显示在Console中,并保存在./benchmark_result/benchmark.csv文件里。
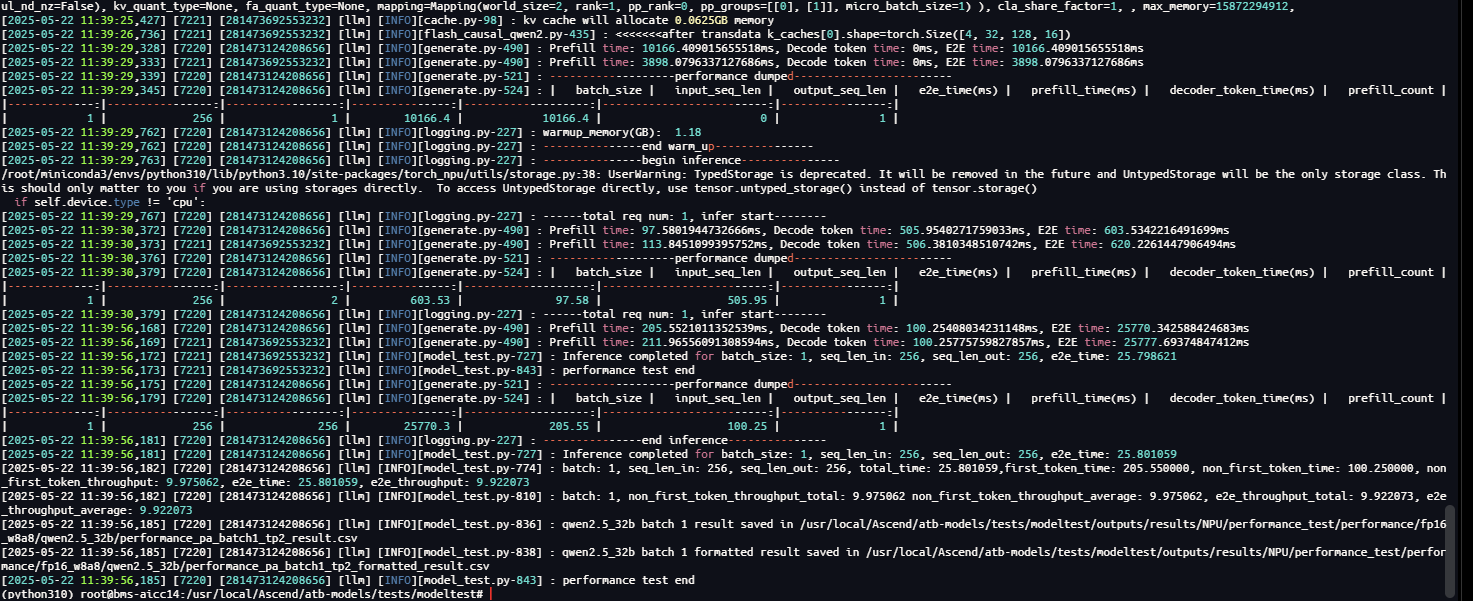

4. 服务化部署
4.1 MindIE 配置
参考文档
修改MindIE配置:
vim /usr/local/Ascend/mindie/latest/mindie-service/conf/config.json
主要参数:
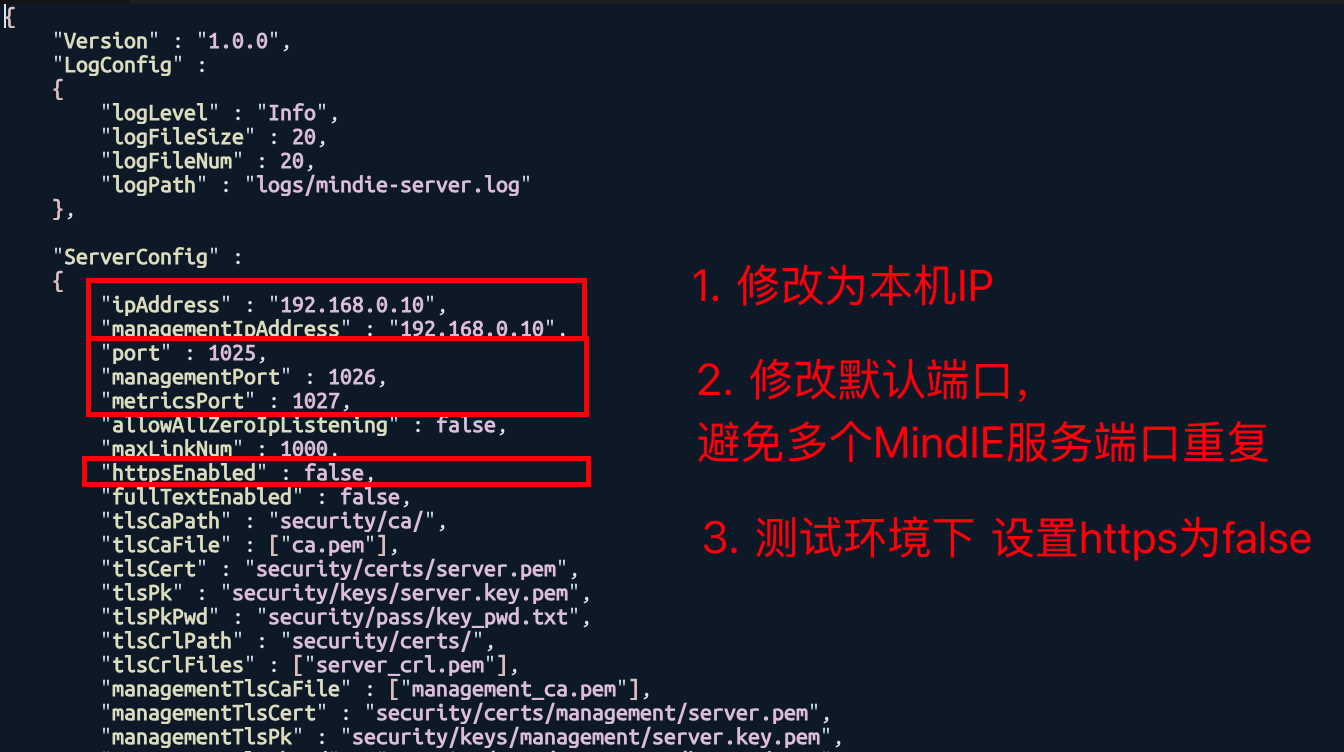
"ipAddress" : "192.168.0.10", 改为本机内网地址
"managementIpAddress" : "192.168.0.10", 改为本机内网地址()
"port" : 1025, 推理端口,请保证端口号无冲突
"managementPort" : 1026, 管理面端口,请保证端口号无冲突
"metricsPort" : 1027, 服务监控指标接口,请保证端口号无冲突
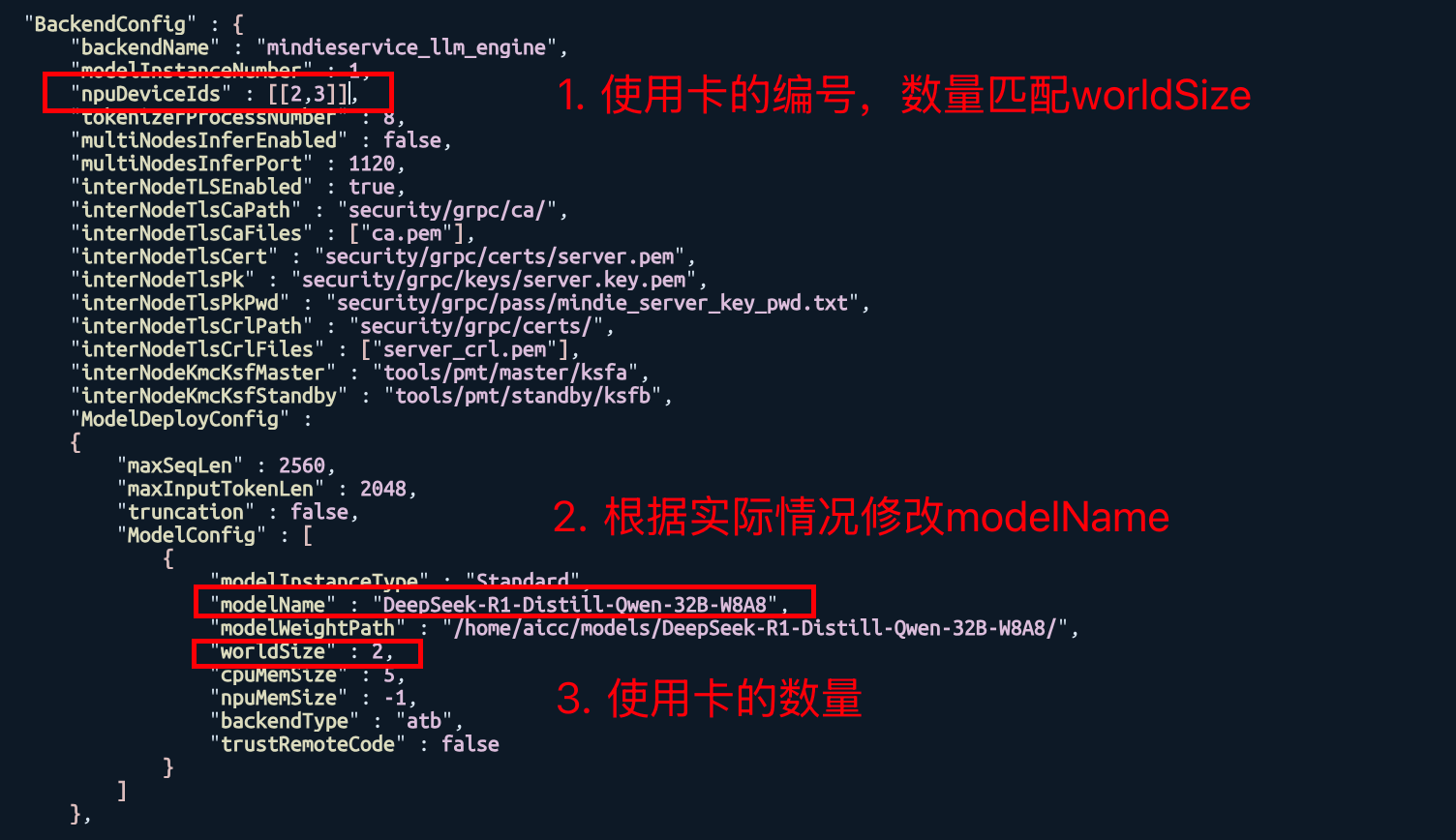
"npuDeviceIds" : [[0,1]], 表示启用哪几张卡。对于每个模型实例分配的npuIds
"modelName" : "DeepSeek-R1-Distill-Qwen-32B-W8A8", 模型名称
"modelWeightPath" : "/home/aicc/models/DeepSeek-R1-Distill-Qwen-32B-W8A8/", 模型权重路径
"worldSize" : 2, 启用几张卡推理。本模型启用两卡推理即可
注:小组内多个MindIE服务请保证 port 不同、modelName不同
4.2 MindIE 服务化
首先进入mindie-service目录:
cd /usr/local/Ascend/mindie/latest/mindie-service
-
方式一(推荐):使用后台进程方式启动服务。后台进程方式启动服务后,关闭窗口后进程也会保留。
nohup ./bin/mindieservice_daemon > output.log 2>&1 &使用 tail 实时跟踪日志
tail -f output.log打印如下信息说明启动成功。
Daemon start success! -
方式二:直接启动服务。
./bin/mindieservice_daemon回显如下则说明启动成功。
Daemon start success!
4.3 发起测试请求
参考文档

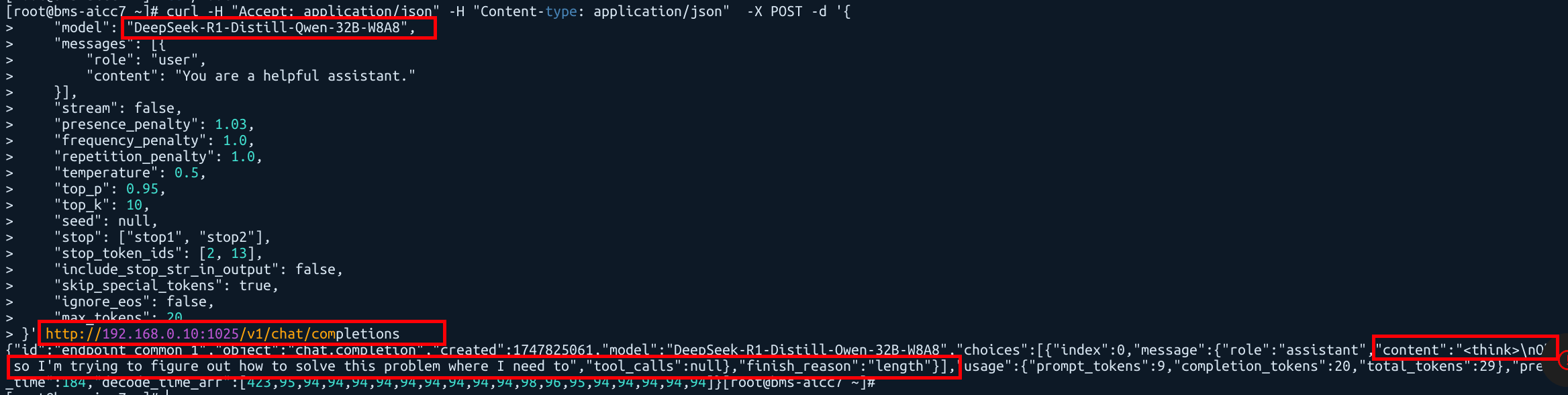
重开一个窗口,使用以下命令发送请求:
# OpenAI 接口
curl -H "Accept: application/json" -H "Content-type: application/json" \
-X POST -d '{"model": "DeepSeek-R1-Distill-Qwen-32B-W8A8","messages": [{"role": "user","content": "You are a helpful assistant."}],"stream": false,"presence_penalty": 1.03,"frequency_penalty": 1.0,"repetition_penalty": 1.0,"temperature": 0.5,"top_p": 0.95,"top_k": 10,"seed": null,"stop": ["stop1", "stop2"],"stop_token_ids": [2, 13],"include_stop_str_in_output": false,"skip_special_tokens": true,"ignore_eos": false,"max_tokens": 20
}' http://192.168.0.10:1025/v1/chat/completions
5. 接入 Dify
5.1 访问 Dify
根据 弹性公网IP:Dify端口 访问本机的Dify前端页面
用户名/密码:atlas@hw.com / 0atlas@hw.com
5.2 配置大模型
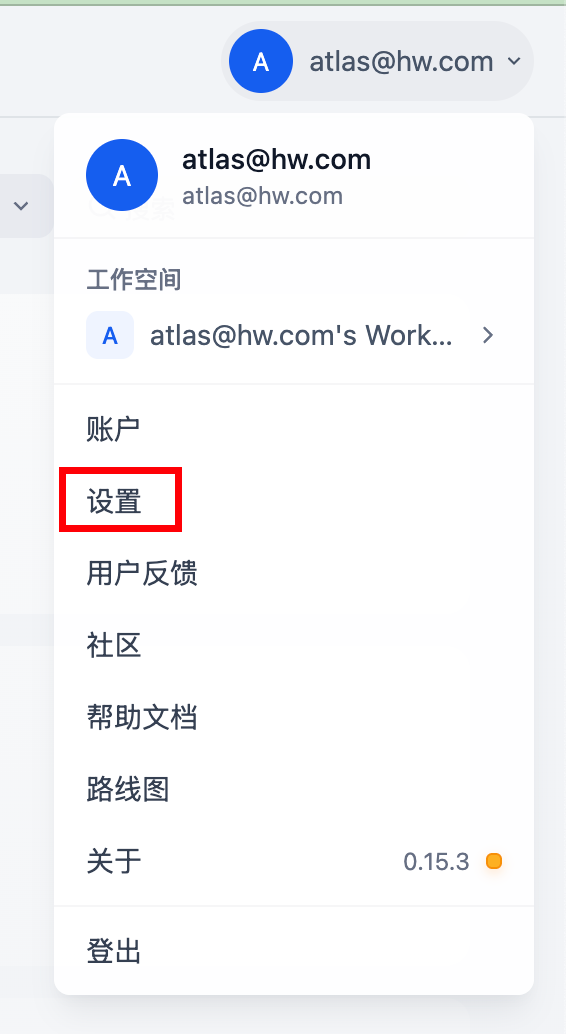
- 点击右上角用户头像,点击“设置”
- 点击“模型提供商”,搜索
OpenAI-API-compatible,点击“添加模型”
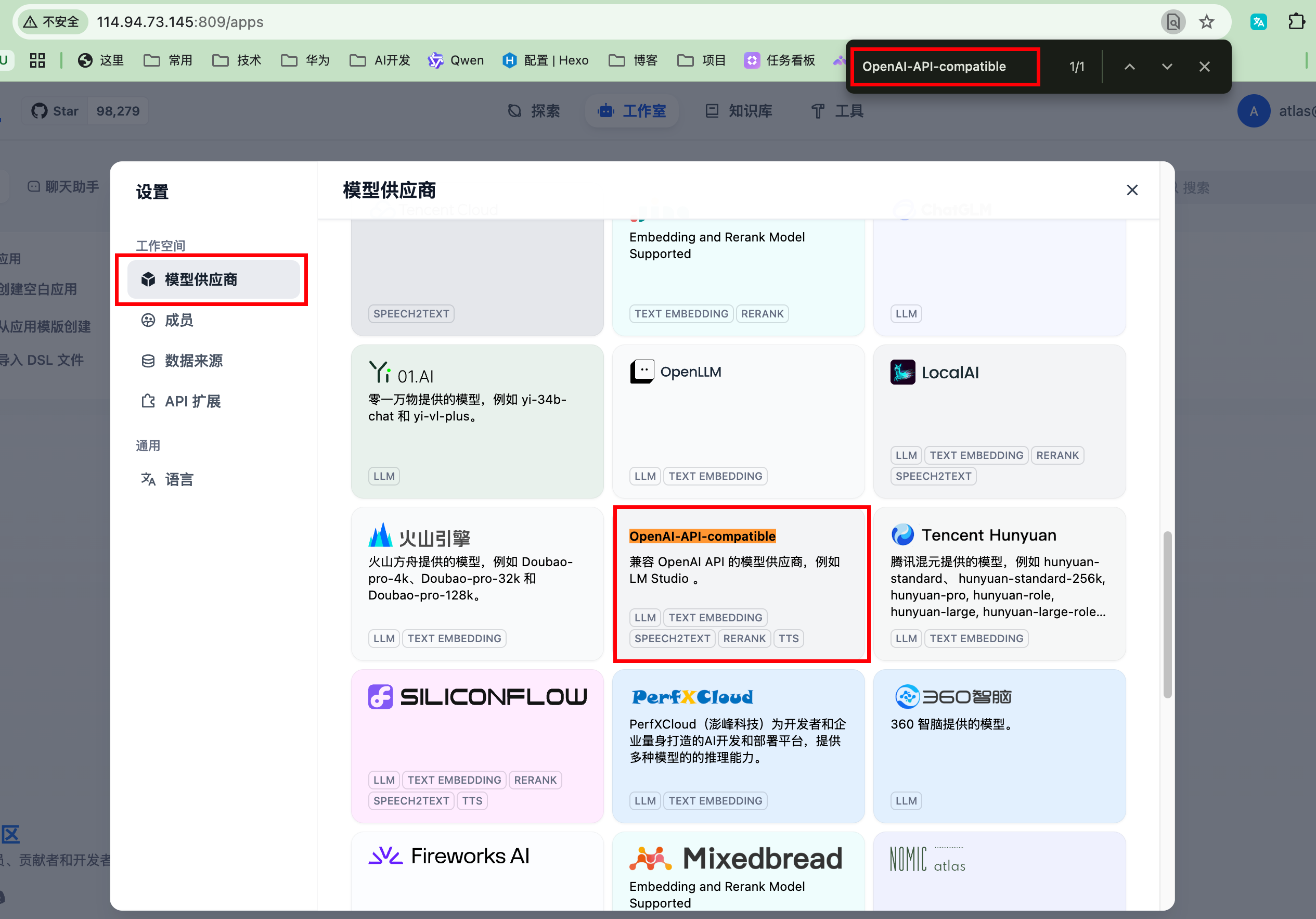
-
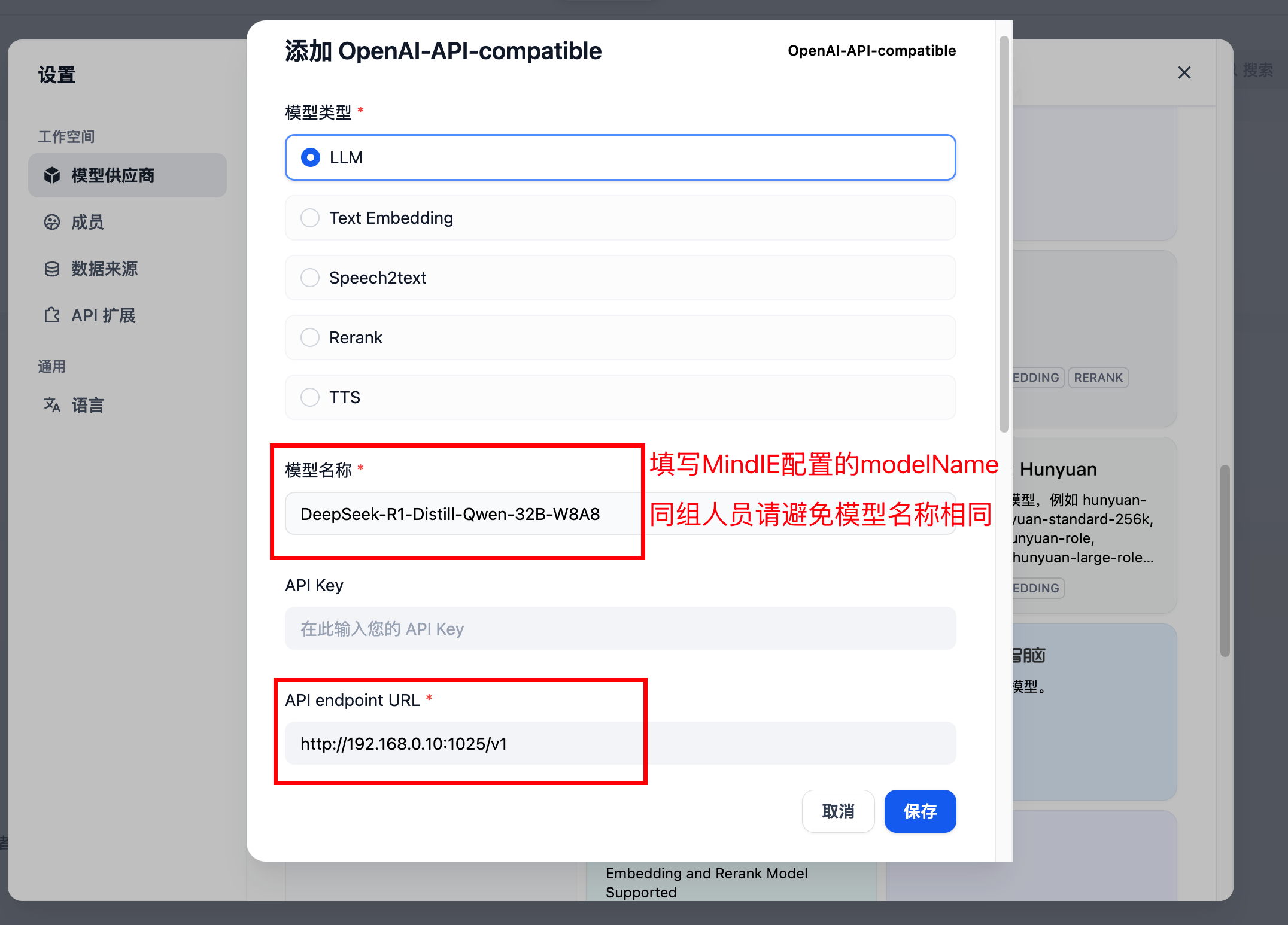
添加MindIE模型。
模型名称:填写MindIE配置的modelName
API endpoint URL:填写
本机内网IP:MindIE配置的port/v1
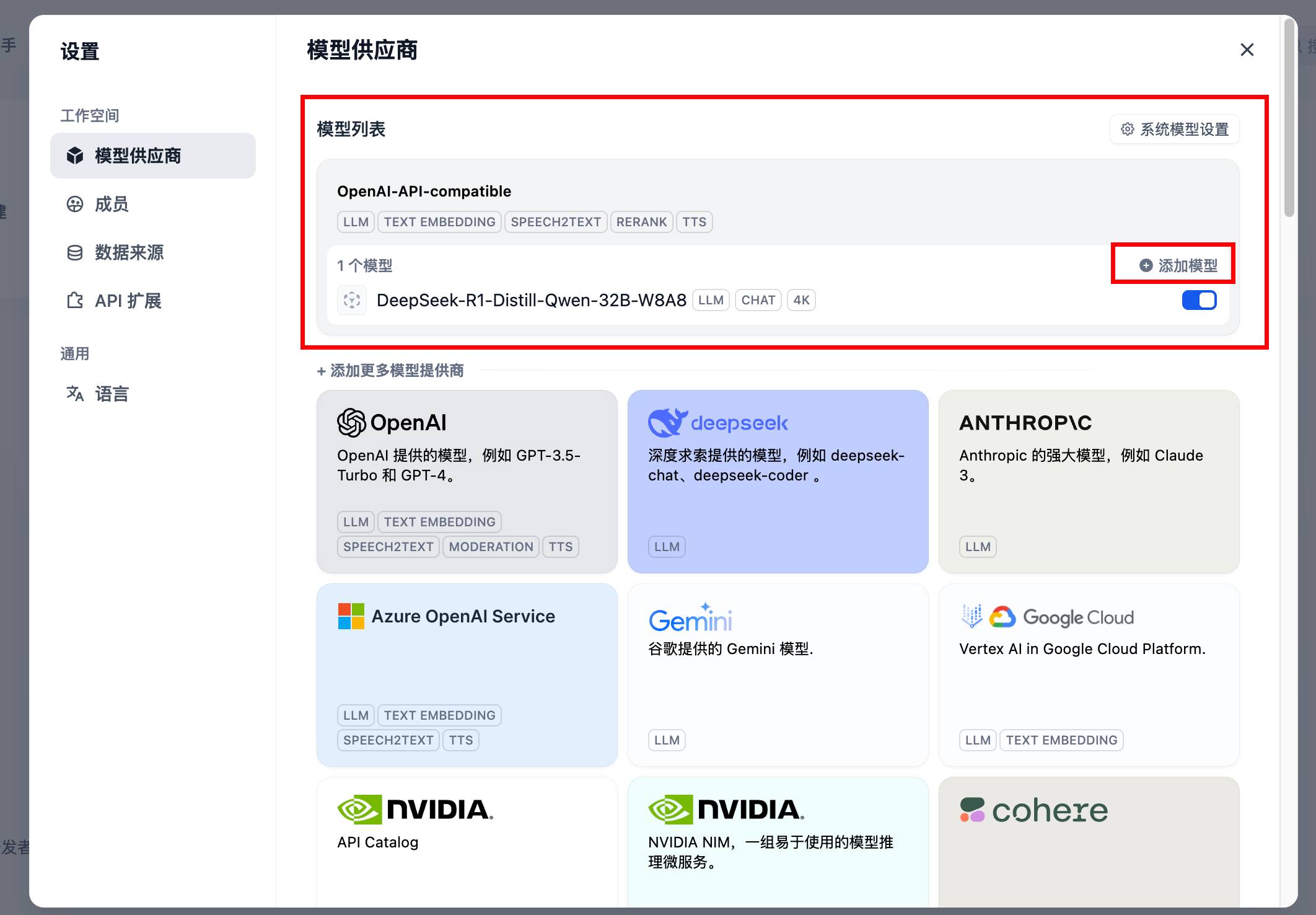
- 新增
OpenAI-API-compatible模型
添加过OpenAI-API-compatible模型后,可在弹窗上方看到已添加的模型列,可以点击“添加模型”继续添加。添加时请避免模型名称相同。
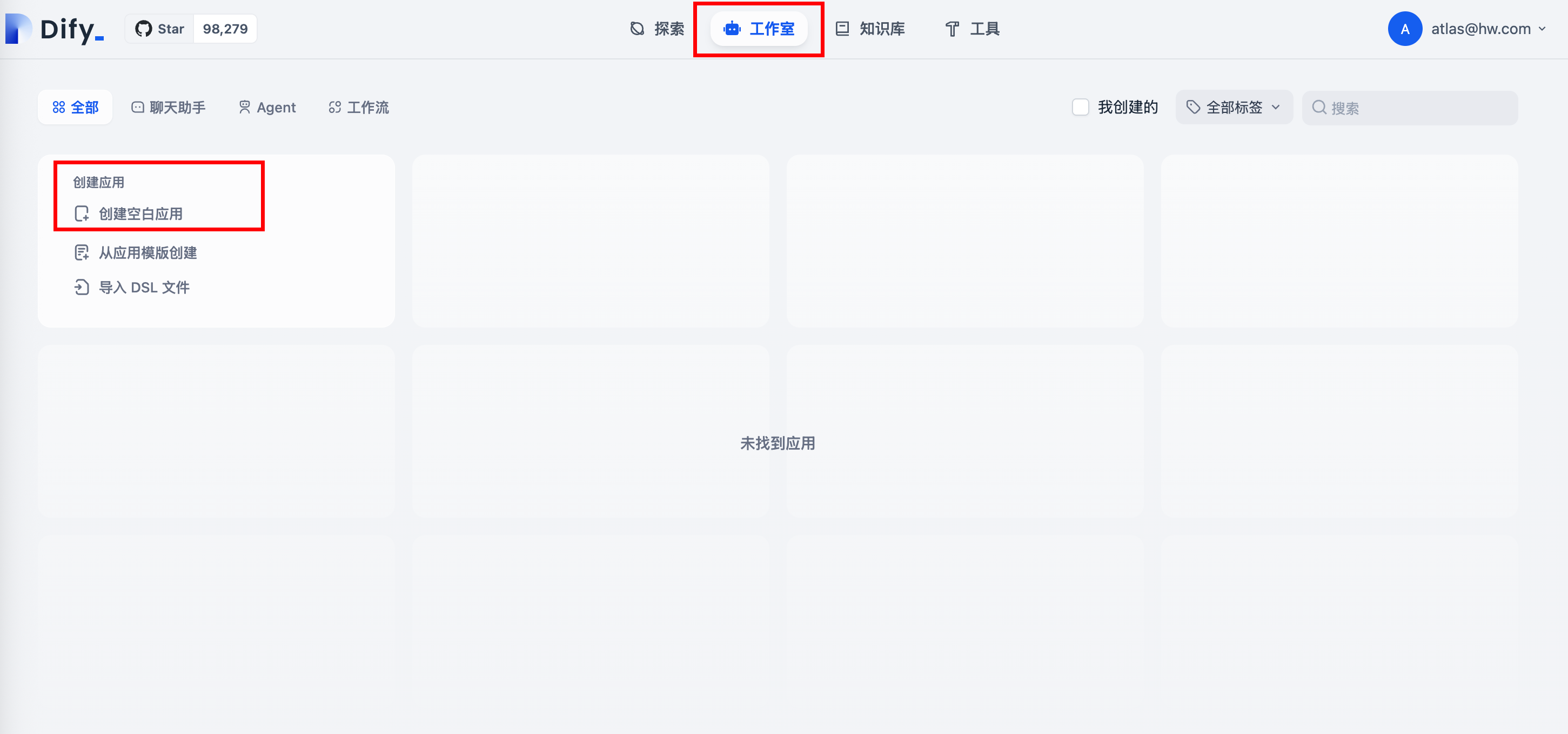
5.3 创建聊天助手
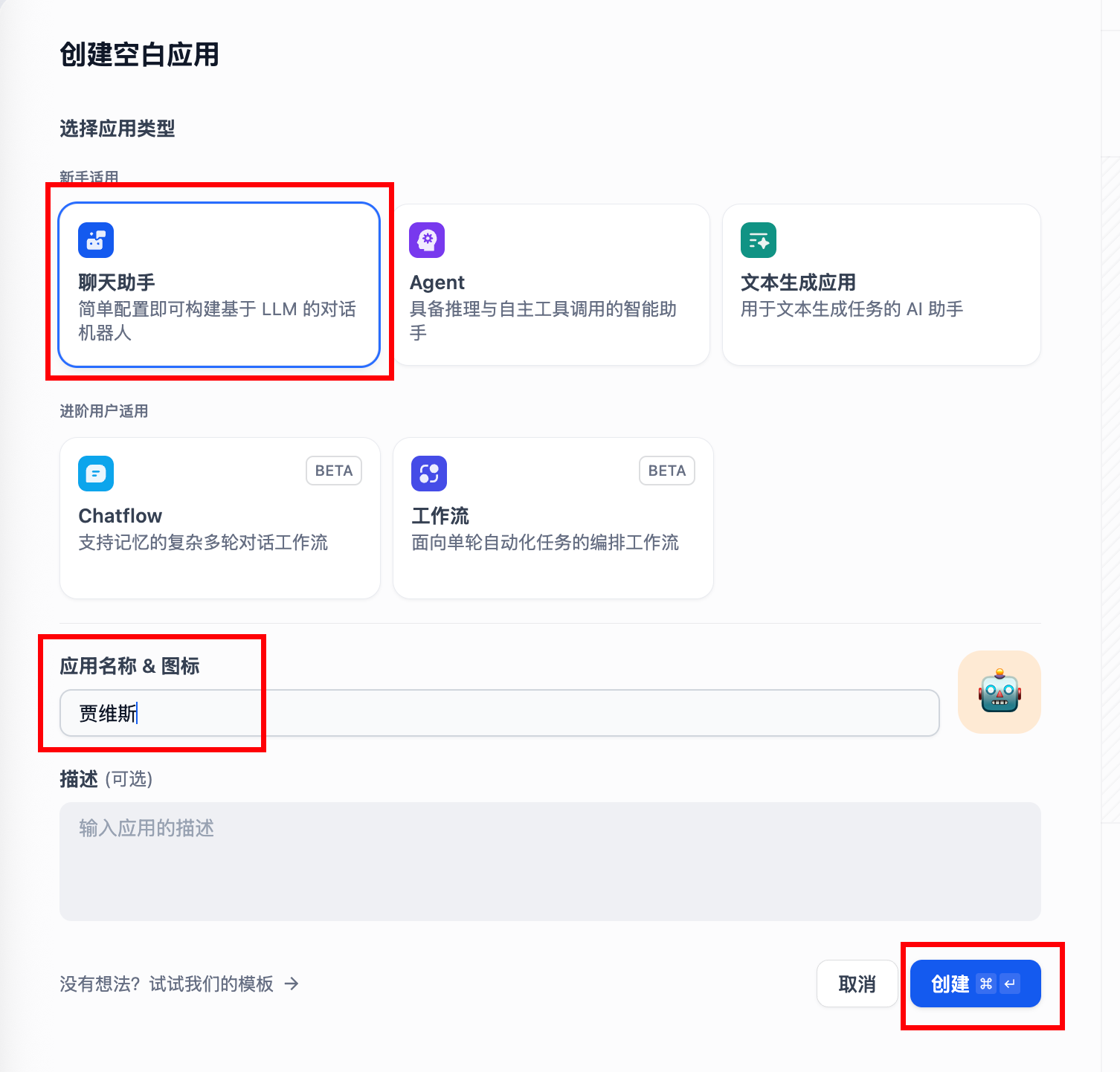
- 点击“工作室”、“创建空白应用”
- 选择 “聊天助手”,输入名称,点击 “创建”
- 选择模型

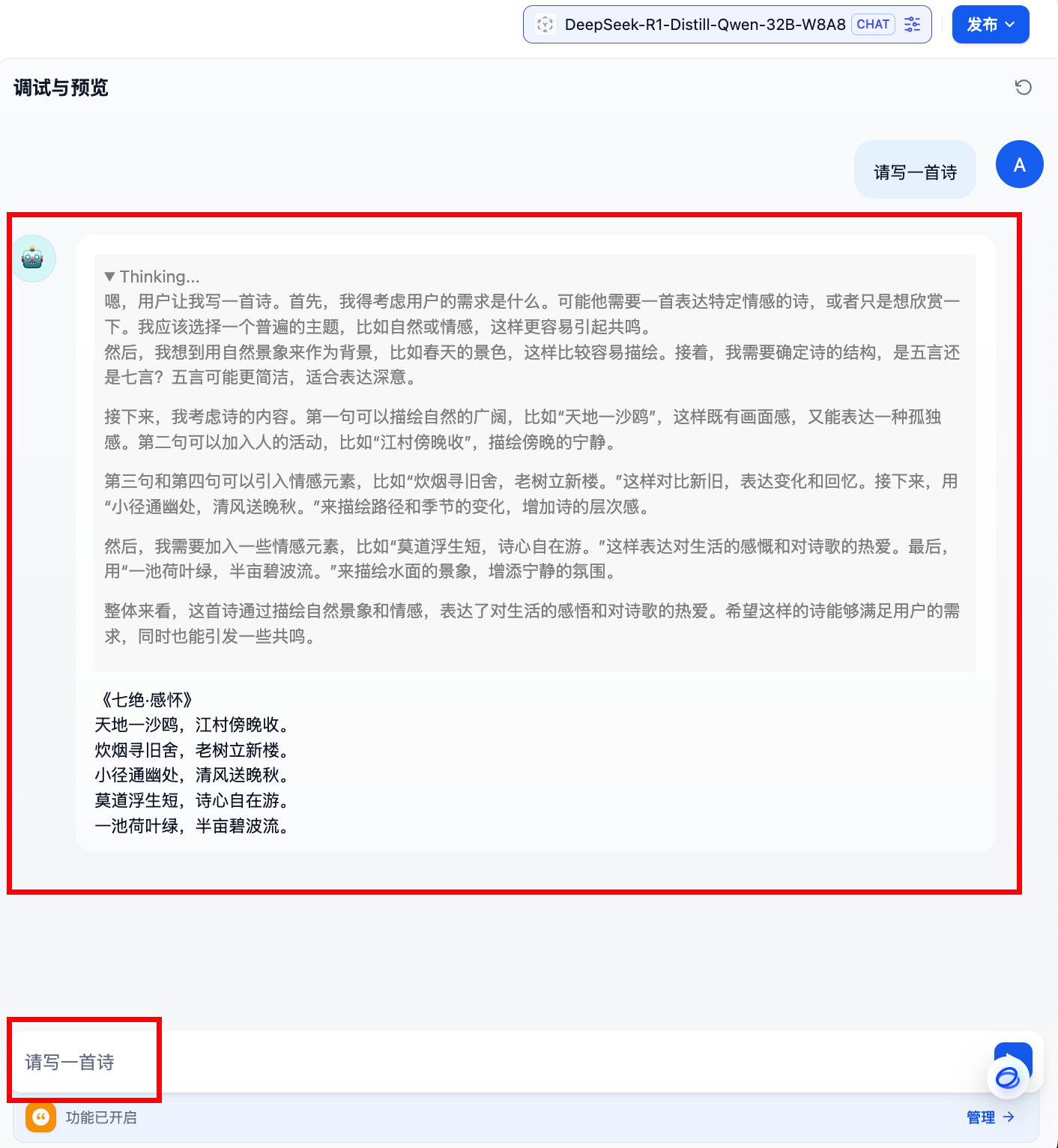
- 对话测试
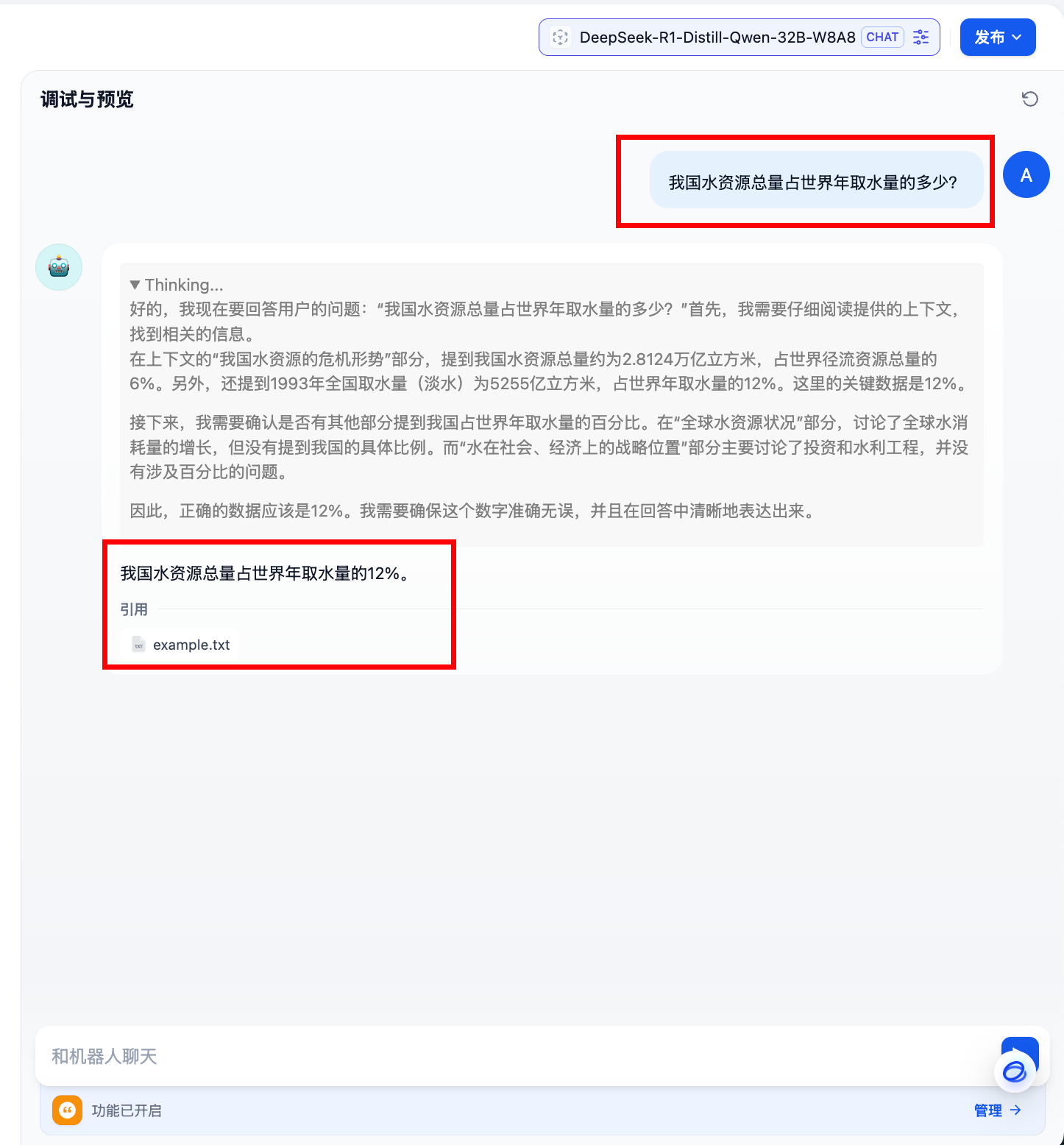
输入内容进行对话测试,接收到响应即为正确。
进阶实操
本文档以 Atlas 800-9000 服务器为例,让开发者快速开始使用TEI进行文本嵌入(Embedding)和重排序(Reranker)模型推理流程。
TEI(全称:Text Embeddings Inference)是由Huggingface推出的高性能推理框架,旨在简化和加速文本嵌入(Embedding)和重排序(Reranker)模型在生产环境中的部署。
TEI支持基于HTTP和gRPC协议的服务接口,能够高效处理文本嵌入的生成和基于文本相关性的重排序等任务;TEI框架同时也支持多种嵌入模型和重排序模型,并提供了灵活的请求批处理、模型管理和动态调度功能。通过TEI,开发者可以轻松地扩展和优化文本嵌入和重排序服务,以满足实时应用和批量处理的需求,特别适用于自然语言处理相关的在线推理任务,能够满足RAG(全称:Retrieval-Augmented Generation)、信息检索 (IR)、自然语言理解 (NLU)、文本分类以及个性化推荐系统等下游应用场景。
原生TEI仅支持GPU硬件环境,且Python后端接口仅支持Embedding模型的embed服务。昇腾实现了基于MindIE Torch与ATB的组图优化,拓展其Python后端功能、将其适配到昇腾环境。
本次使用以下模型:
| 模型名 | 说明 |
|---|---|
| BAAI/bge-large-zh-v1.5 | 稠密向量模型 |
| BAAI/bge-m3 | 稠密和稀疏向量模型 |
| BAAI/bge-reranker-large | 排序模型 |
1. 环境部署
注:本次昇腾开发者训练营提供的服务器基础环境已配置完毕,本章节可忽略。
1.1 下载模型权重
权重已下载,路径:/home/aicc/bge_model
mkdir /home/aicc/bge_model
pip install modelscopemodelscope download --model BAAI/bge-large-zh-v1.5 --local_dir /home/aicc/bge_model/bge-large-zh-v1.5
modelscope download --model BAAI/bge-reranker-large --local_dir /home/aicc/bge_model/bge-reranker-large
modelscope download --model BAAI/bge-m3 --local_dir /home/aicc/bge_model/bge-m3
修改模型数据类型
修改每一个模型内部的配置项torch_dtype为float16, Atlas800 9000/300I Duo/300V Pro设备需修改。Atlas 800T A2等设备不用修改。
cd /home/aicc/bge_model
vim bge-reranker-large/config.json
vim bge-large-zh-v1.5/config.json
vim bge-m3/config.json# 修改为:
torch_dtype": "float16",
1.2 获取镜像
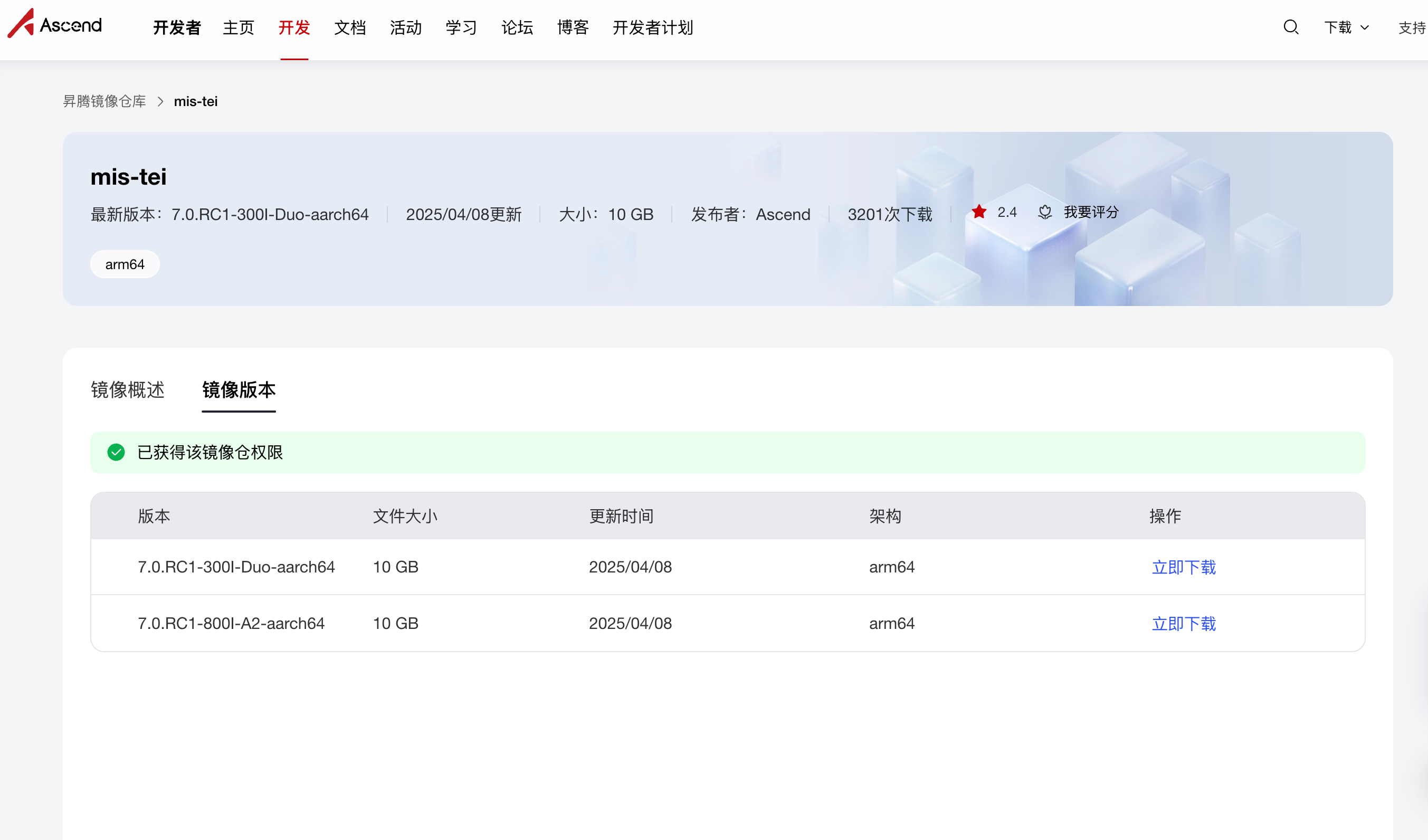
昇腾镜像仓库:https://www.hiascend.com/developer/ascendhub/detail/07a016975cc341f3a5ae131f2b52399d
进入昇腾官方镜像仓库,根据设备型号选择下载对应的TEI镜像,该镜像已具备模型运行所需的基础环境。
因为本次实验的机器为910A,所以需要根据官方镜像手动修改或重新构建。本次采用的是华为山东AICC的一位老哥的镜像,下载方式:
docker pull crpi-8ew3ouqcvy9yujug.cn-hangzhou.personal.cr.aliyuncs.com/sxj731533730/mis-tei_atlas_800_9000:v0
2. 启动容器
注意:
- 请修改本机 IP 和 端口,以下命令采用IP为192.168.0.10,端口为9000、9001、9002
- 修改推理卡编号:
TEI_NPU_DEVICE=0表示使用0卡推理,请修改为合适的卡号
# 启动 BAAI/bge-m3 推理容器
docker run -itd -u root -e ENABLE_BOOST=True --privileged=true \
-e TEI_NPU_DEVICE=0 --name=bge-m3 --net=host \
-v /home/aicc/bge_model:/home/HwHiAiUser/model \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
mis-tei_atlas_800_9000:v0
# 启动服务
docker exec -it bge-m3 bash
export HOME=/home/HwHiAiUser
bash start.sh BAAI/bge-m3 192.168.0.10 9000# 启动 BAAI/bge-large-zh-v1.5 推理容器
docker run -itd -u root -e ENABLE_BOOST=True --privileged=true \
-e TEI_NPU_DEVICE=0 --name=bge-large-zh-v1.5 --net=host \
-v /home/aicc/bge_model:/home/HwHiAiUser/model \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
mis-tei_atlas_800_9000:v0
# 启动服务
docker exec -it bge-large-zh-v1.5 bash
export HOME=/home/HwHiAiUser
bash start.sh BAAI/bge-large-zh-v1.5 192.168.0.10 9001# 启动 BAAI/bge-reranker-large 推理容器
docker run -itd -u root -e ENABLE_BOOST=True --privileged=true \
-e TEI_NPU_DEVICE=0 --name=bge-reranker-large --net=host \
-v /home/aicc/bge_model:/home/HwHiAiUser/model \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
mis-tei_atlas_800_9000:v0
# 启动服务
docker exec -it bge-reranker-large bash
export HOME=/home/HwHiAiUser
bash start.sh BAAI/bge-reranker-large 192.168.0.10 9002# 对于800TA2、300I Duo设备无需进入容器手动启动服务。将模型名称、IP、端口作为容器启动参数,例如:
docker run -itd -u root -e ENABLE_BOOST=True --privileged=true \
-e TEI_NPU_DEVICE=0 --name=bge-m3 --net=host \
-v /home/aicc/bge_model:/home/HwHiAiUser/model \-e POOLING=splade \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mis-tei:7.0.RC1-800I-A2-aarch64 BAAI/bge-m3 127.0.0.1 9000关键参数解释:
user: 容器运行用户,可配置为root或HwHiAiUser,如果不配置默认使用HwHiAiUser,建议以普通用户HwHiAiUser运行降低容器运行相关安全风险-e ASCEND_VISIBLE_DEVICES: 挂载指定的npu卡到容器中,只有宿主机安装了Ascend Docker Runtime,此环境变量才会生效,如果未安装Ascend Docker Runtime,可参考配置如下参数挂载指定的卡到容器
--device=/dev/davinci_manager \--device=/dev/hisi_hdc \--device=/dev/devmm_svm \--device=/dev/davinci0 \--device=/dev/davinci1 \-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \-v /usr/local/sbin:/usr/local/sbin:ro \
-e ENABLE_BOOST: 使能bert、roberta、xml-roberta类模型推理加速model dir: 模型存放的上级目录,如/home/data,不能配置为/home和/home/HwHiAiUser容器内的挂载目录/home/HwHiAiUser/model不可更改image id:从ascendhub网上拉取镜像后的镜像IDmodel id:从modelscope上获取的模型ID:例如:BAAI/bge-base-zh-v1.5, BAAI/bge-reranker-large等,如需运行时下载模型,请确保网络可访问modelscope网站listen ip:TEI服务的监听IP,例如:127.0.0.1listen port:TEI服务的监听端口,例如:8080- 稀疏向量模型添加(本次实践无需添加):
-e POOLING=splade,请求接口采用embed_sparse
3. 推理测试
使用以下命令进行推理测试:
curl 192.168.0.10:9000/embed \-X POST \-d '{"inputs":"What is Deep Learning?"}' \-H 'Content-Type: application/json'curl 192.168.0.10:9001/embed \-X POST \-d '{"inputs":"I like you."}' \-H 'Content-Type: application/json'curl 192.168.0.10:9002/rerank \-X POST \-d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]}' \-H 'Content-Type: application/json'
本镜像接口规范(符合TEI):

4. 接入 Dify
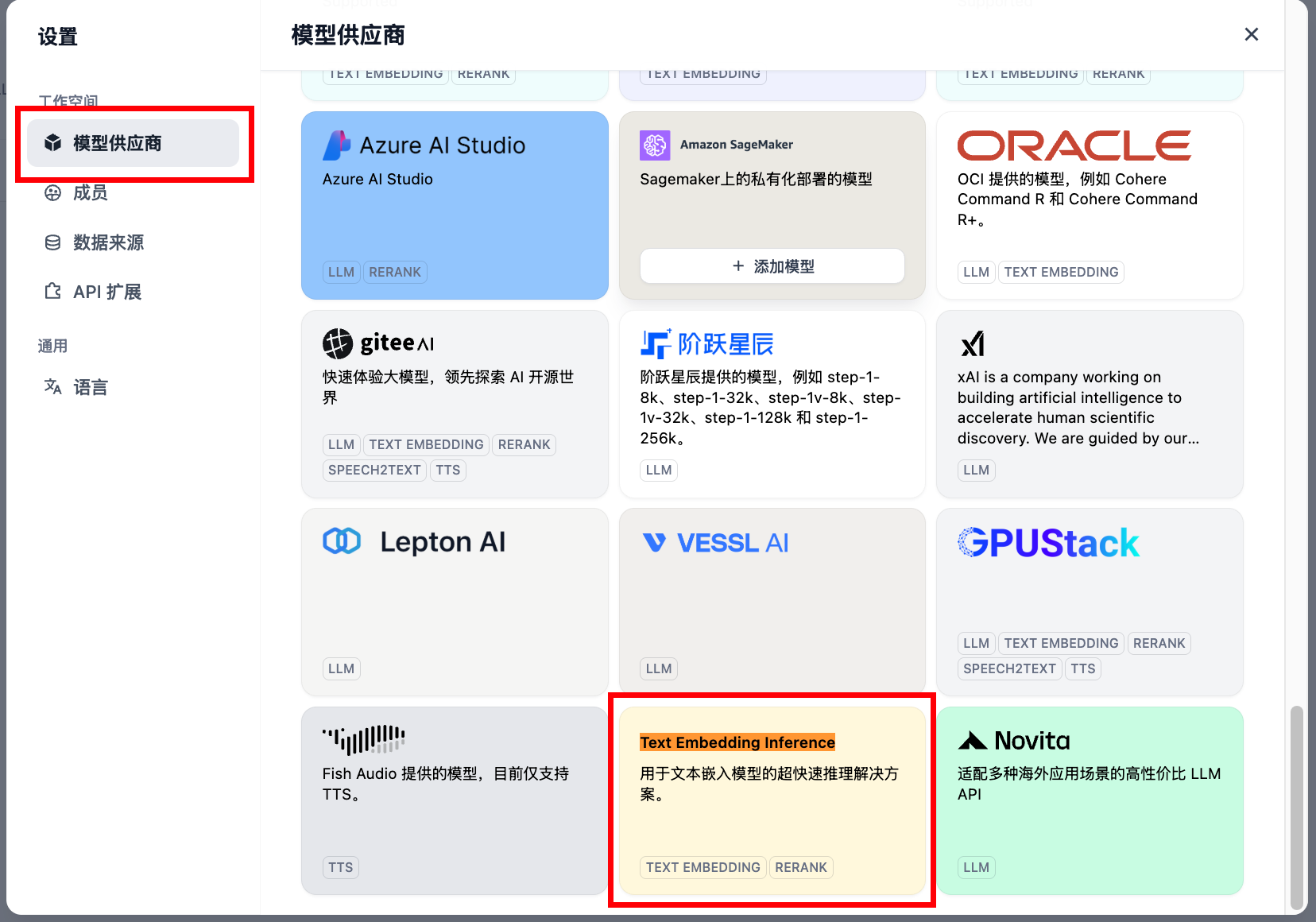
4.1 配置模型
在“模型供应商”中查询Text Embedding Inference,依次添加以下参数:
API Key 需要填写,随意填写即可。
| 模型名称 | 服务器URL | API Key |
|---|---|---|
| bge-m3 | http://192.168.0.10:9000 | 1 |
| bge-large-zh-v1.5 | http://192.168.0.10:9001 | 1 |
| bge-reranker-large | http://192.168.0.10:9002 | 1 |
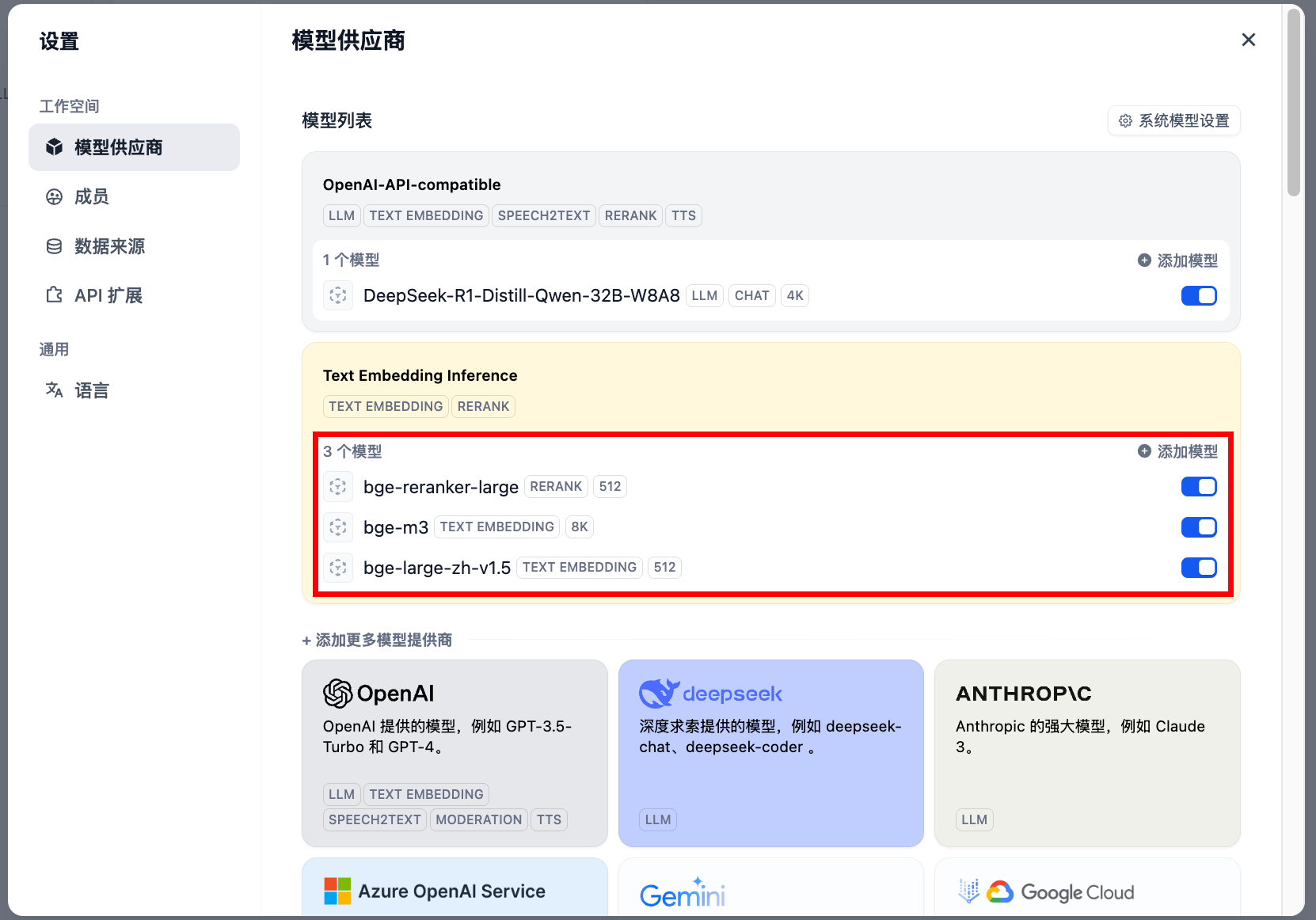
4.2 创建知识库
- 点击“知识库”,点击“创建知识库”
- 从本地选择一个文件导入:
选择文件后,点击“下一步”
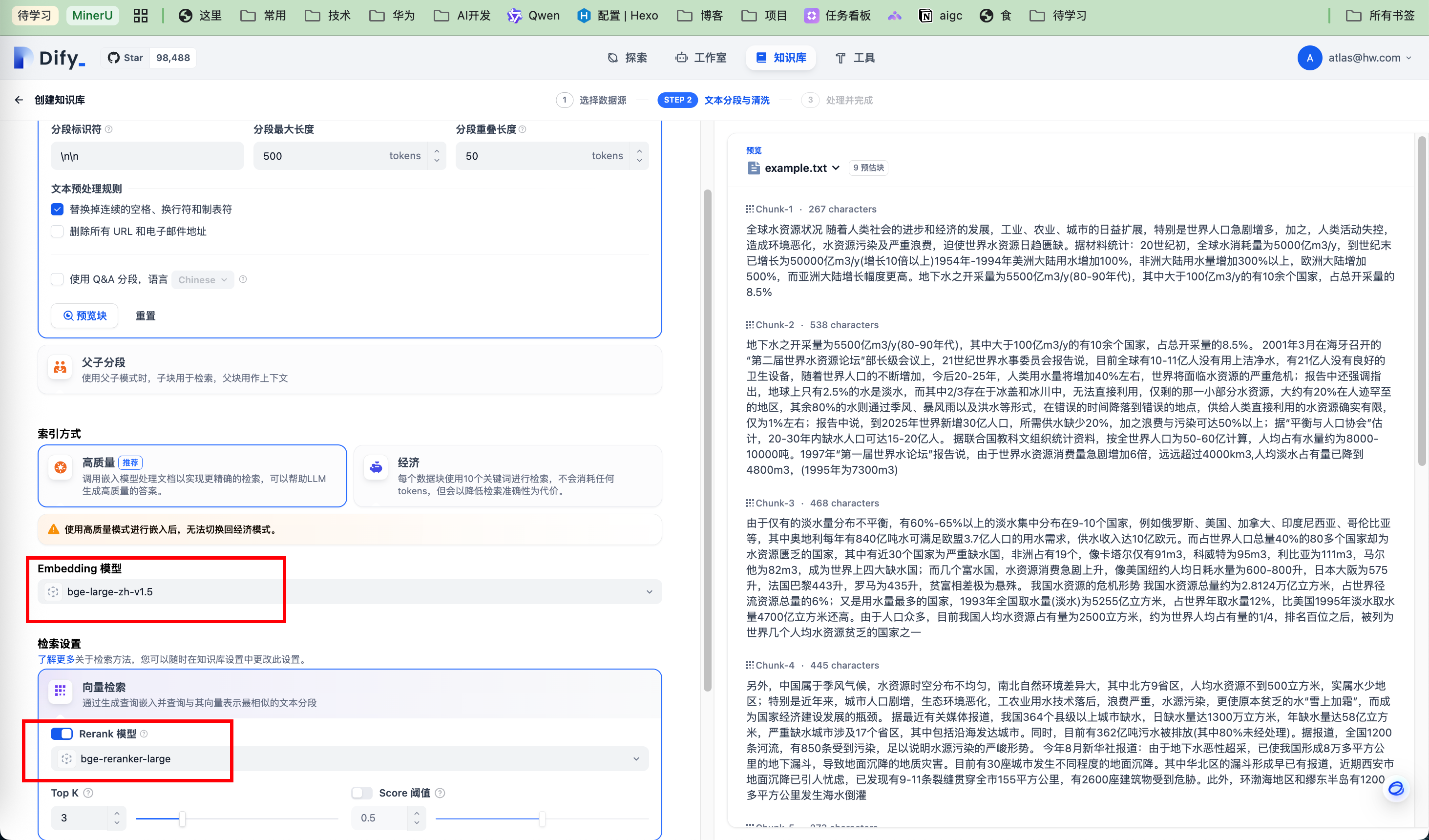
- 配置分段:使用默认配置无需修改
保证Embedding模型和Rerank模型设置正确,下滑到底部点击“保存并处理”
点击“前往文档”
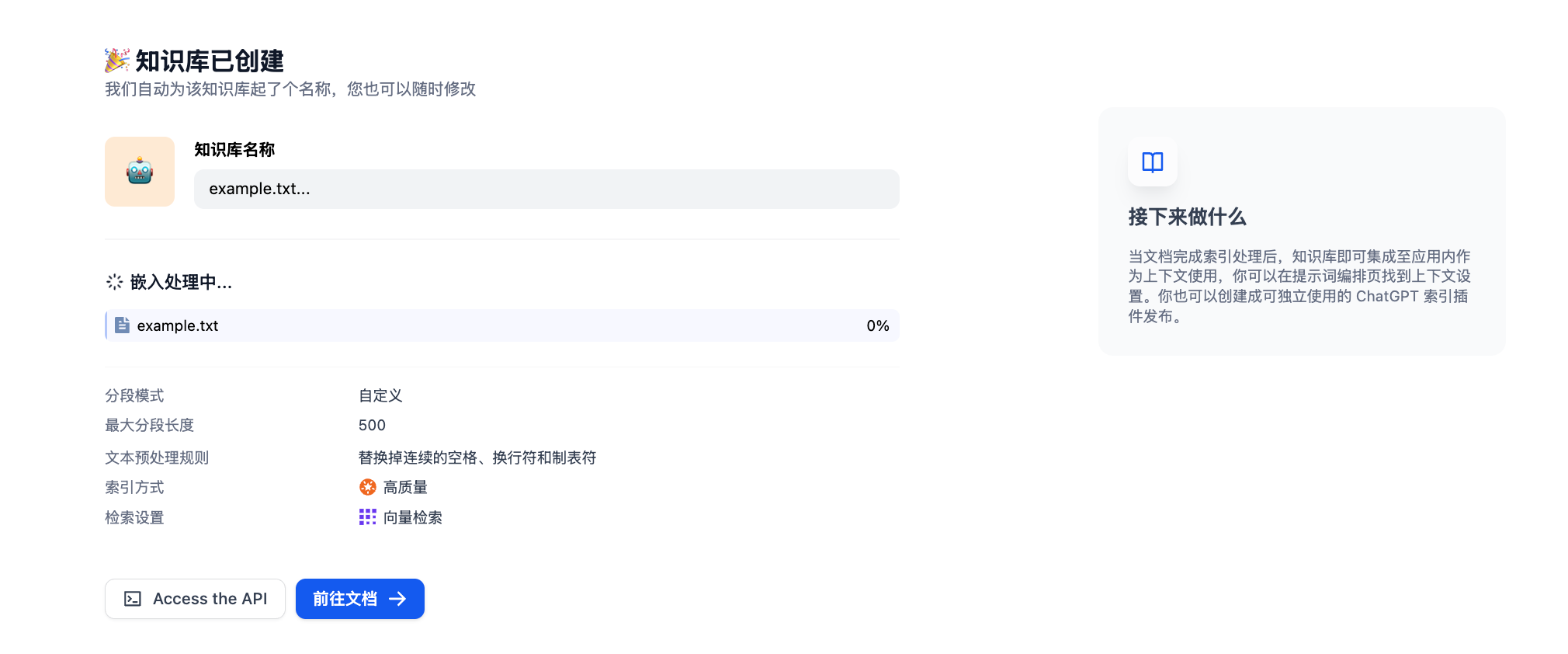
- 可查看处理后的文件状态
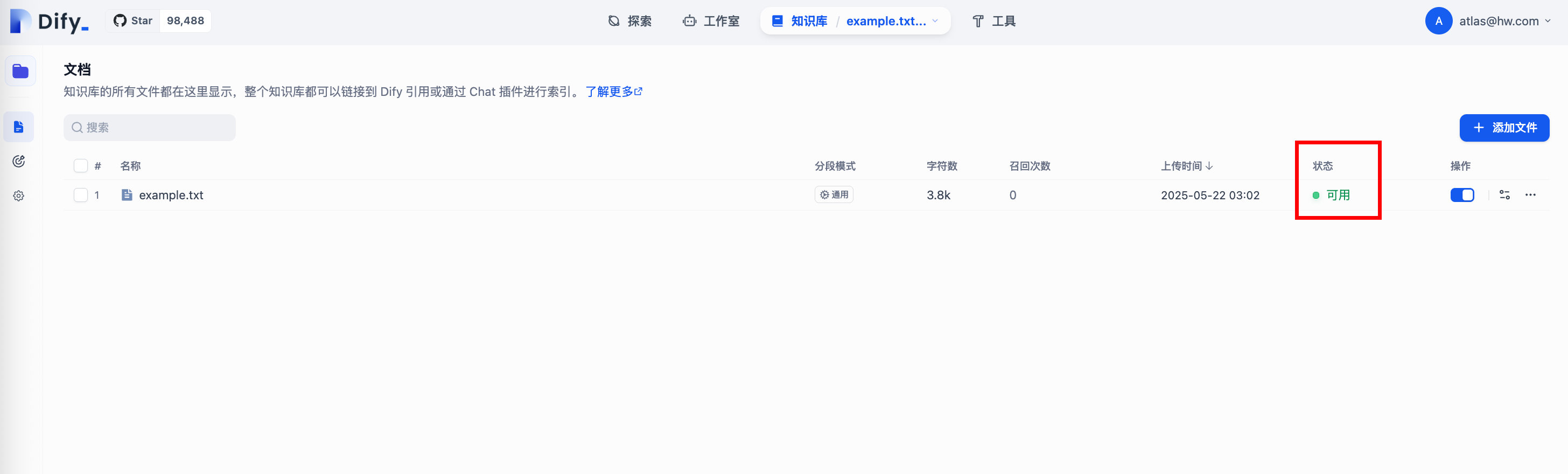
5. 创建聊天助手
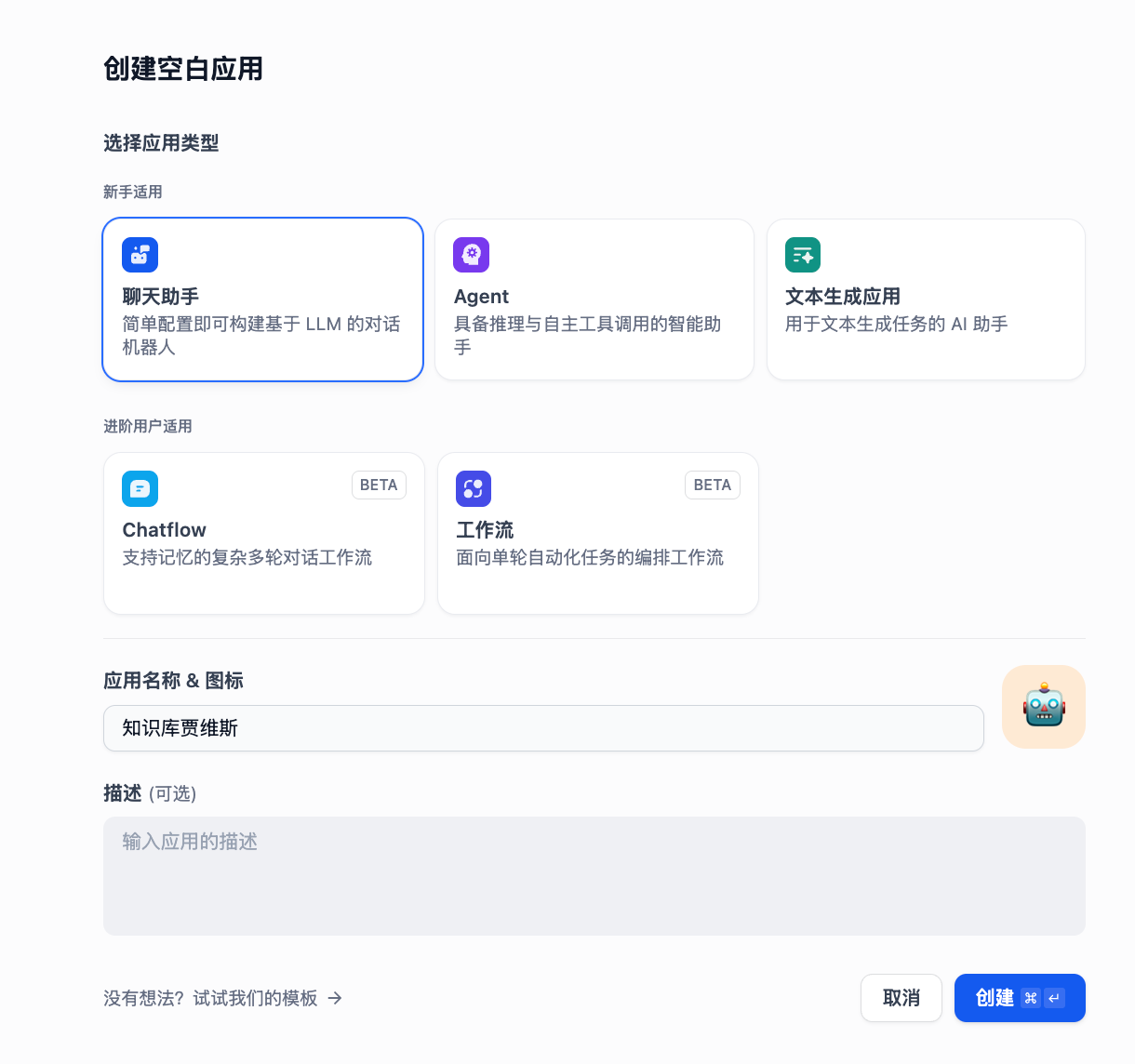
- 点击 “创建”点击“工作室”、“创建空白应用”
- 选择 “聊天助手”,输入名称,
- 点击添加上下文
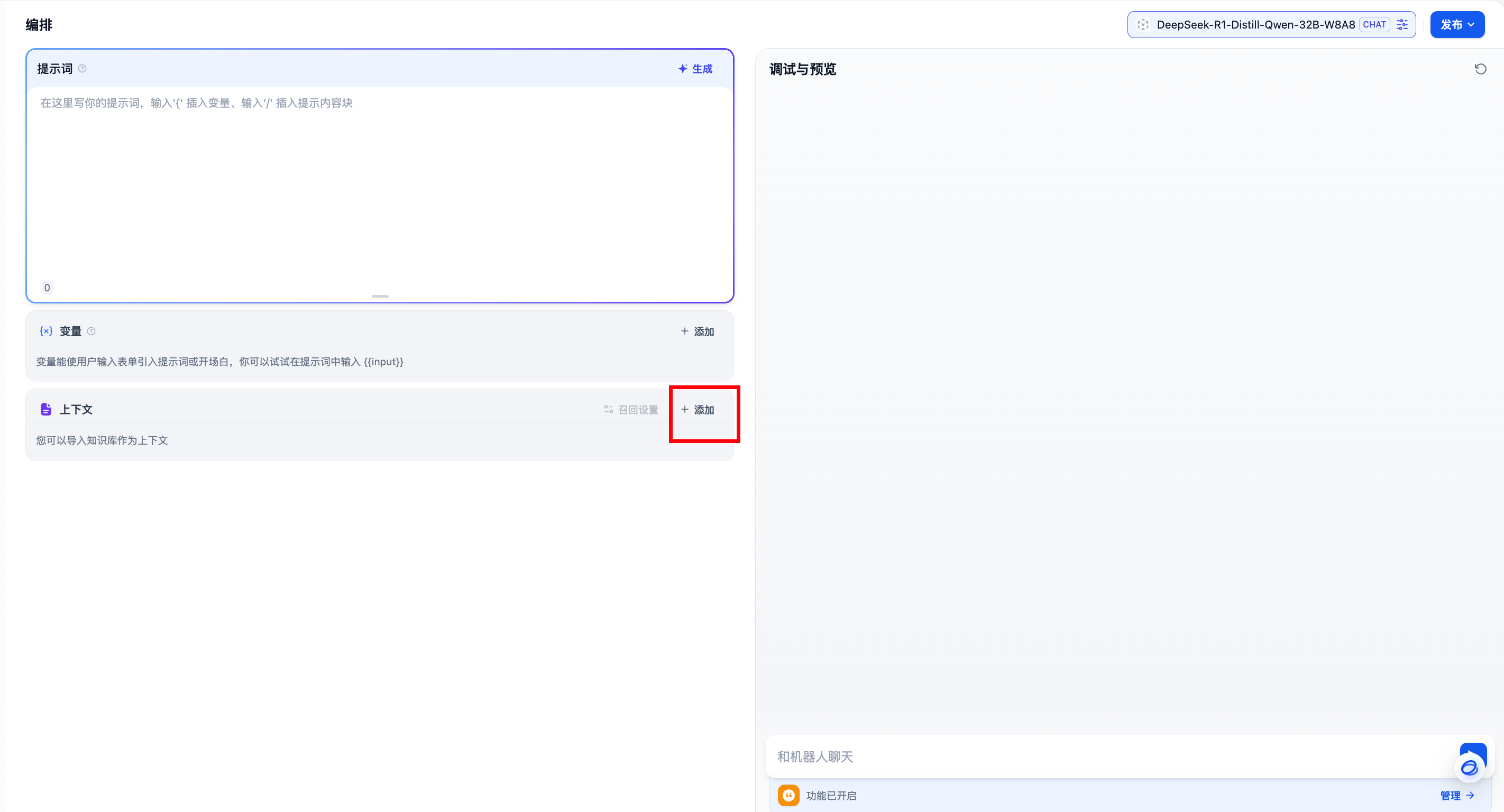
- 选择处理好的知识库
- 提问

回答正确: