视觉大模型VIT
VIT 原理
概念
VIT 是 Vision Transformer 的缩写。Vision Transformer 是一种基于 Transformer 架构的计算机视觉模型,最初由谷歌研究团队在 2020 年提出。它将 Transformer 架构(原本用于自然语言处理任务)应用于图像分类任务,取得了显著的效果。
Transformer很强,但视觉任务中的应用还有限。ViT尝试将纯Transformer结构引入到CV的基本任务--图像分类中。
自 VIT 被提出以来,已经有许多改进和变种出现,如 Swin Transformer、DeiT 等。这些模型在更广泛的视觉任务中(如目标检测、图像分割等)展示了强大的性能。
Vision Transformer 的引入标志着计算机视觉领域从传统的 CNN 向基于 Transformer 的新架构的一个重要转变。
研究背景
Transformer很强,但视觉任务中的应用还有限
Transformer提出后在NLP领域中取得了极好的效果,其全Attention的结构,不仅增强了特征提取能力,还保持了并行计算的特点,可以又快又好的完成NLP领域内几乎所有任务,极大地推动自然语言处理的发展。
但在其在计算机视觉领域的应用还非常有限。在此之前只有目标检测(0bject detection)中的DETR大规模使用了Transformer,其他领域很少,而纯Transformer结构的网络则是没有。
Transformer的优势:
- 并行计算
- 全局视野
- 灵活的堆叠能力
VIT的性能分析
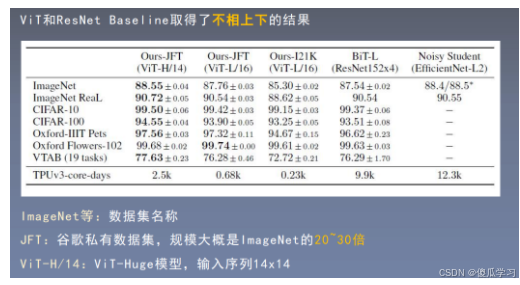
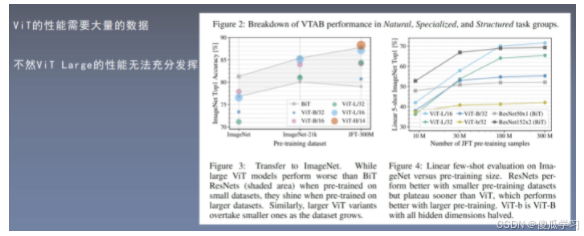
ViT的历史意义
-
展示了在计算机视觉中使用纯Transformer结构的可能
-
拉开了新一轮Transformer研究热潮的序幕
VIT 模型结构图
我们将图像分割为固定大小的块,对每个块进行线性嵌入,添加位置编码,然后将生成的向量序列输入到标准Transformer编码器中。为了进行分类,我们使用了标准方法,即在序列中添加一个额外的可学习“分类标记”。
ViT结构的数据流
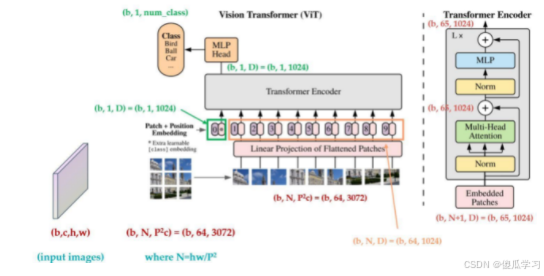
(b,c,h,w)
- b 代表batch size 批次大小
- c 代表通道数,彩色图片中c=3,就是三个通道rgb
- h w 分别代表图像的高和宽
(b,N,(P^2)c)
- b 代表batch size 批次大小(不更改)
- N 代表图像切分的块数patch(根据情况自定义宽高分成多少块N)
- P 代表切分后的图像大小 (P^2)c 是 32x32x3(宽高分别除以块数N,得到分割后的每一个图像块的宽高32x32,在将每个图像块的c通道的所有像素点平铺,最终是将宽高像素合并形成一维数据)
(b,65,1024)
3027考虑到维度太大,通过fc进行特征的降为,并将其降维维1024,所以通过fc后的每个图像块的形状为(b,64,1024),最后在加上一个哨兵(patch 0),最终输入encoder编码器中的维度为(b,65,1024)
Linear
在VIT(Vision Transformer)的模型结构中,"Linear Projection of Flattened Patches" 指的是将图像分割成小块(称为patches),然后对这些patches进行展平(flatten),最后通过线性投影(linear projection)将展平后的向量映射到一个更低维度的空间。作用在于将图像中的局部信息提取出来,并将其转换为可以输入到Transformer模型中的形式。
- 特征提取和编码:通过将图像分成小块并展平,可以有效地捕获图像的局部特征。这些特征通常包含有关颜色、纹理和形状等信息,对于理解图像内容至关重要。
- 减少输入维度:传统的图像数据非常大,直接输入到Transformer模型中会导致计算和内存消耗过大。将patches展平并通过线性投影映射到更低维度的向量,可以有效减少输入的维度,同时保留重要的特征信息。
- 提升模型性能:通过提取和编码局部特征,模型能够更好地理解图像的结构和内容,从而在进行后续的Transformer处理(如自注意力机制)时,提升模型在图像理解和处理任务上的性能。
经过FC之后的结果是(b,64,1024)然后输入到transformer的encoder中,再经过MLP Head 用额外的块patch 0 输出最终的分类(b,1,class_num)
patch 0
在Vision Transformer(VIT)中,需要额外输入一个小块(patch 0)通常是为了确保模型能够处理整个图像的信息。这种做法可以获得全局的信息:尽管Transformer模型以自注意力机制为核心,可以在不同位置之间建立关联,但在某些情况下,特别是对于涉及全局上下文的任务(如图像分类),引入额外的全局信息有助于模型更好地理解整个图像。
VIT 代码
前期准备
Source code
不是官方的repo,简化版本的,官方的跑不动时间太长,而且官方的是基于tensorflow框架
GitHub - lucidrains/vit-pytorch: Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in PytorchImplementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch - lucidrains/vit-pytorch![]() https://github.com/lucidrains/vit-pytorch
https://github.com/lucidrains/vit-pytorch
通过程序入口定位核心代码
下载vit-pytorch库查看源代码,点击Download ZIP
aip使用首先找到README.md自述文件
![]()
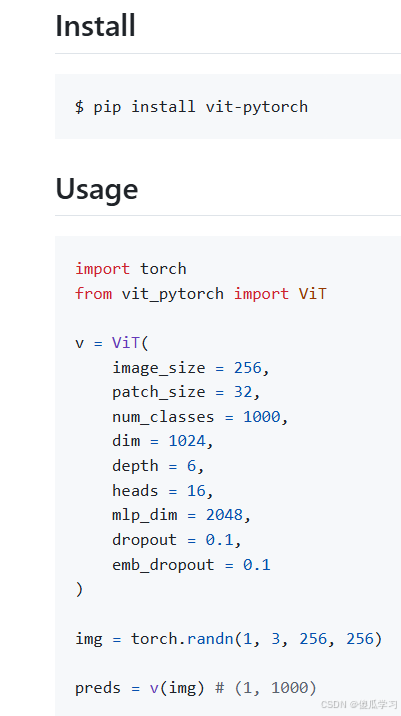
调用 VIT 类
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256, # 图片的大小
patch_size = 32, # 每块的大小 一共64块
num_classes = 1000, # 分类数目
dim = 1024, # fc的输出维度(隐藏层的维度)
depth = 6, # 堆Transformer 块的数量。
heads = 16, # 多头注意力层中的头数量。
mlp_dim = 2048, # mlp(多头注意力)的维度/MLP(前馈)层的维度。
dropout = 0.1, # dropout神经元丢去的概率
emb_dropout = 0.1 # float between [0, 1], default 0. 嵌入 Dropout 率。
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
print(preds.shape)参数
image_size: int. 图像大小。如果你有矩形图像,请确保图像大小是宽度和高度的最大值。patch_size: int. 分块大小。图像大小必须是分块大小的整数倍。分块的数量为:n = (图像大小 // 分块大小) ** 2,并且 n 必须大于 16。num_classes: int. 分类的类别数量。dim: int. 线性变换后输出张量的最后维度 nn.Linear(..., dim)。depth: int. Transformer 块的数量。heads: int. 多头注意力层中的头数量。mlp_dim: int. MLP(前馈)层的维度。channels: int, default3. 图像的通道数量。dropout: float between[0, 1], default0.. Dropout 率。emb_dropout: float between[0, 1], default0. 嵌入 Dropout 率。pool: string, eitherclstoken pooling ormeanpooling 池化方式,可以是 cls token 池化或平均池化。
VIT类(不是最新版代码)
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
# helpers
#如果输入不是个tuple就返回一个tuple
def pair(t):
return t if isinstance(t, tuple) else (t, t)
# classes
#layer norm
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
#fc层,过一层fc,然后gelu,然后再fc
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
#attention实现
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
#得到qkv
qkv = self.to_qkv(x).chunk(3, dim = -1)
#切分qkv
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
#dot product后除以根号下norm
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
#softmax
attn = self.attend(dots)
#乘到v上,再sum,得到z
out = einsum('b h i j, b h j d -> b h i d', attn, v)
#整理shape输出
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
#transformer block,分成了attention实现和fc实现两部分
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
#内部主要负责实现block的前向部分。
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):
super().__init__()
# 图像的宽高
image_height, image_width = pair(image_size)
# 块的宽高
patch_height, patch_width = pair(patch_size)
"""
用于确保图像的高度(image_height)和宽度(image_width)
都能被块的高度(patch_height)和宽度(patch_width)整除。
如果条件不满足,则会抛出一个错误提示:
“Image dimensions must be divisible by the patch size.”
这种检查通常在处理图像分割或基于块的操作时使用,
以确保图像可以被均匀地划分为若干个不重叠的小块(patches)。
"""
assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'
# 分成多少块num_patches
num_patches = (image_height // patch_height) * (image_width // patch_width)
# 每个块的宽高通道平铺
patch_dim = channels * patch_height * patch_width
"""
用于确保变量 pool 的值是字典 {'cls', 'mean'} 中的一个元素。
如果 pool 的值不是这两个选项之一,
则会抛出一个错误提示:“pool type must be either cls (cls token) or mean (mean pooling)”。
"""
assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'
"""
过线性投影(linear projection)将展平后的向量映射到一个更低维度的空间。
作用在于将图像中的局部信息提取出来,并将其转换为可以输入到Transformer模型中的形式。
"""
# 分成多少块num_patches
# 四维数据变为三维数据,并且使用线性层进行特征的降维,比如降为(b,num_patches, patch_dim)->(b,num_patches,dim)
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.Linear(patch_dim, dim),
)
# 位置编码
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
# 假如patch0哨兵
# nn.Parameter:将一个不可训练的张量转换成可训练的参数,并将其注册为模型的一个参数。
# 经过MLP Head 用额外的块patch 0 输出最终的分类(b,1,class_num)
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# 神经元丢弃
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, img):
# 数据准备阶段
# 图像分割为固定大小的块,并进行特征的降维(b,n,dim)(1, 64, 1024)
#输入端适配
#print("img:", img.shape)
x = self.to_patch_embedding(img)
#print("x:", x.shape)
# b 是batch_size n 是patch数量 _每块图像的特征维度
b, n, _ = x.shape # 1 64 1024
print("self.cls_token:", self.cls_token.shape)
#引入patch 0
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
print("cls_token:", cls_tokens.shape)
x = torch.cat((cls_tokens, x), dim=1) # # (1 65(dim=1) 1024) (b, n+1, dim)
# 位置编码
# self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))初始化一个和transformer输入数据一张形状的随机数据
# 将位置编码和x相加
#print("x:", x.shape)
# 位置编码
#x += self.pos_embedding[:, :(n + 1)]
x += self.pos_embedding
# 丢弃神经元
x = self.dropout(x)
#Transformer前向
x = self.transformer(x)
# 判断是使用的池化操作还是cls,并将分割图像块的特征融合,还是取patch0
#拿到最后输入进mlp的patch
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)输入端适配
图像切分重排
img = torch.randn(1, 3, 256, 256)
b = 1
c = 3
h = 256 -> h = h * p1 -> h = 8 p1 = 32
w = 256 -> w = w * p2 -> w = 8 p2 = 32
so (h w)-> 64
(p1 p2 c)->(32 32 3)-> 3072
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width), #图片切分重排
nn.Linear(patch_dim, dim), # Linear Projection of Flattened Patches 拉平
)einops.rearrange
einops是一个用来高效实现元素重排的库,主要用来代替一些需要集成使用reshape, repeat, expand, view, stack, permute才能实现的方法。恰好图片的切分重排就是这样的一个事情。
演示code:einops/docs/1-einops-basics.ipynb at main · arogozhnikov/einops · GitHubFlexible and powerful tensor operations for readable and reliable code (for pytorch, jax, TF and others) - einops/docs/1-einops-basics.ipynb at main · arogozhnikov/einops![]() https://github.com/arogozhnikov/einops/blob/master/docs/1-einops-basics.ipynb
https://github.com/arogozhnikov/einops/blob/master/docs/1-einops-basics.ipynb
nn.Sequential 是 PyTorch 中的一个容器模块,用于按顺序容纳和执行一系列子模块。通过使用 nn.Sequential,你可以将多个层(如切分重排和linear等)按顺序连接在一起,而不需要为每一层单独定义前向传播逻辑。这样可以让模型的定义更加简洁和清晰。
构造patch0
先把patch0复制给所有的批次,然后将patch0和原始数据融合在一起
torch.cat() 函数将给定的张量序列(sequence of tensors)沿指定的维度(dim)进行连接。
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)
x = torch.cat((cls_tokens, x), dim=1)positional embedding
与transformer不同,这里的位置编码模型是自己可以学习的随机变量,只需要初始化随机的参数
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
x += self.pos_embeddingTransformer Block
这里面有三个封装好的类,Attention,FeedForward
x = self.transformer(x)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x对照Transformer Encoder结构图来理解
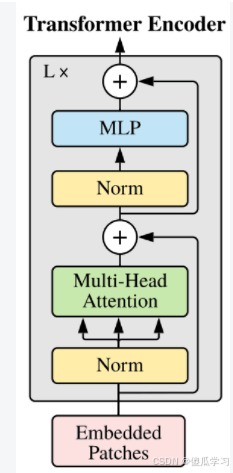
2PreNorm
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout))
PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))PreNorm 这个类的用法是用来在某个操作(这里是attention和MLP)之前应用层归一化(Layer Normalization)。PreNorm类接受两个参数:dim 和 fn。
-
dim是输入张量的维度,用于初始化nn.LayerNorm。 -
fn是一个可调用的对象(这里是attention和MLP),它会在经过层归一化的输入上应用。
nn.ModuleList与 nn.Sequential 的区别
nn.ModuleList 与 nn.Sequential 的主要区别在于:
-
nn.Sequential:用于定义前馈的顺序容器,所有模块按照定义的顺序依次执行,适合简单的前向传播过程。 -
nn.ModuleList:只是一个存储模块的列表,不会自动定义前向传播过程。你需要在forward方法中手动定义各个模块的执行顺序和方式。
MultiHead Attention
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim = -1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
# *x.shape会解包x.shape的所有元素,然后与self.heads一起形成一个包含所有这些元素的元组
# x.shape - > torch.Size([1, 65, 1024])
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim = -1)
#得到qkv
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = h), qkv)
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = self.attend(dots)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)得到QKV
关键代码:
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
qkv = self.to_qkv(x).chunk(3, dim = -1)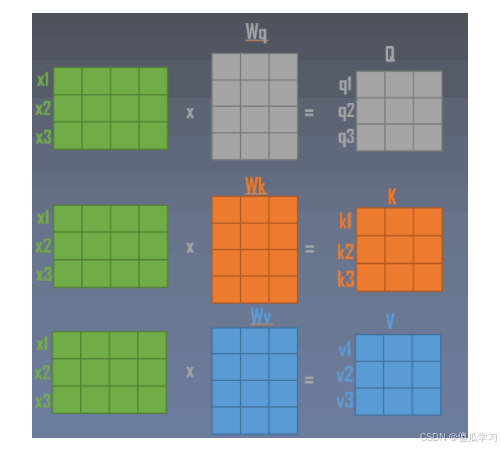
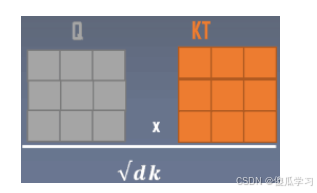
QK 矩阵乘法
关键代码:
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
新value计算
关键代码:
self.attend = nn.Softmax(dim = -1)
attn = self.attend(dots)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')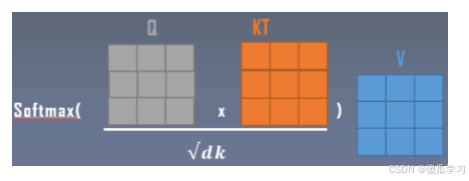
计算wo
关键代码:
project_out = not (heads == 1 and dim_head == dim)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
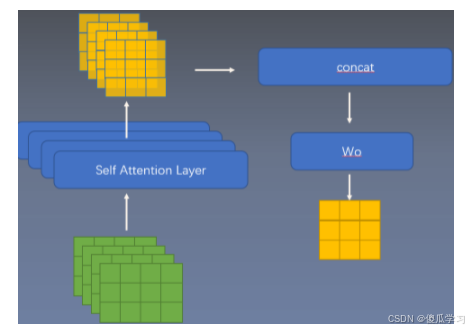
这段代码表示如果 project_out 为真(即 True 或非零值),则 self.to_out 被设置为一个包含 nn.Linear 和 nn.Dropout 的顺序容器;否则,self.to_out 被设置为 nn.Identity(),即不对输入做任何改变。
这意味着无论输入是什么,nn.Identity() 都不会对它做任何处理,只是简单地将输入原封不动地返回。
nn.Identity()主要用途
-
占位符:在模型构建过程中,
nn.Identity()可以用作占位符。当你希望在某些情况下不对数据进行处理时,它提供了一个简单的解决方案。 -
动态模型调整:有时在模型设计中你可能需要根据条件选择是否应用某些层。使用
nn.Identity()可以让你灵活地启用或禁用这些层,而无需改变模型结构的其余部分。 -
网络结构的默认行为:在某些复杂的网络结构中,你可能需要一个默认行为,以便在特定条件下不对数据进行任何操作。
nn.Identity()可以提供这种默认行为。
代码详解
chunk() 函数
在PyTorch中,chunk函数用于将张量沿指定维度分割成多个块。qkv = self.to_qkv(x).chunk(3, dim=-1)这行代码具体的作用如下:
-
self.to_qkv(x):这个操作通常是一个线性变换或卷积操作,用于将输入张量x映射到一个新的表示,这个表示包含查询(query),键(key)和值(value)的信息。假设self.to_qkv是一个线性层,输入x的形状为(b, n, d),则输出张量的形状可能是(b, n, 3*d)。 -
.chunk(3, dim=-1):这个操作将前一步的输出张量沿最后一个维度(即dim=-1)分成3个块。假设输入张量的形状为(b, n, 3*d),则chunk(3, dim=-1)将其分割成3个形状为(b, n, d)的张量。这些张量分别对应查询(query),键(key)和值(value)。
import torch
import torch.nn as nn
# 假设输入张量 x 形状为 (batch_size, sequence_length, embedding_dim)
batch_size = 2
sequence_length = 4
embedding_dim = 6
x = torch.randn(batch_size, sequence_length, embedding_dim)
# 定义一个线性层,输出的维度为 3 * embedding_dim
to_qkv = nn.Linear(embedding_dim, 3 * embedding_dim)
# 通过线性层得到新的表示
qkv = to_qkv(x)
# qkv shape: torch.Size([2, 4, 18])
print("qkv shape:", qkv.shape)
# 将 qkv 沿最后一个维度分割成 3 个张量
q, k, v = qkv.chunk(3, dim=-1)
"""
q shape: torch.Size([2, 4, 6])
k shape: torch.Size([2, 4, 6])
v shape: torch.Size([2, 4, 6])
"""
print("q shape:", q.shape)
print("k shape:", k.shape)
print("v shape:", v.shape)map() 函数
map(函数,可迭代对象)
-
使用可迭代对象中的每个元素调用函数,将返回值作为新可迭代对象元素;返回值为新可迭代对象。
FeedForward
关键代码:
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)nn.GELU() 是 PyTorch 中的一种激活函数,全称是 Gaussian Error Linear Unit(高斯误差线性单元)。GELU 激活函数被广泛应用于深度学习模型中,尤其是在 Transformer 模型中。
GELU 激活函数
GELU(x)=x⋅Φ(x),其中 Φ(x) 是标准正态分布的累积分布函数。
作用和优点
-
平滑性:GELU 是一个平滑的激活函数,相较于 ReLU (Rectified Linear Unit),它在输入值接近零时不会突然改变输出。这种平滑性可以帮助网络更稳定地训练。
-
非线性:GELU 引入了非线性,使得神经网络能够更好地学习复杂的模式。
-
统计意义:GELU 通过引入正态分布的概率性质,理论上具有更好的表现。
取值patch0
融合进行特征的融合
#拿到最后输入进mlp的patch
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]代码解析
-
条件判断:
if self.pool == 'mean'-
这部分代码检查
self.pool的值是否等于'mean'。
-
-
条件为真(
self.pool == 'mean'):x.mean(dim = 1)-
x.mean(dim = 1)计算张量x在第 1 维(即序列长度或 token 维度)上的平均值。 -
结果是一个形状为
[1, 1024]的张量,因为我们对序列长度维度求平均。
-
-
条件为假(
self.pool不等于'mean'):x[:, 0]-
x[:, 0]选择张量x在第 1 维(序列长度维度)的第 0 个元素。 -
结果是一个形状为
[1, 1024]的张量,因为我们只选择了patch 0 的特征向量。
-