五分钟图解Diffusion扩散模型
1 Diffusion文字生成图片——整体结构
1.1 整个生成过程
我们知道在使用 Diffusion 的时候,是通过文字生成图片,但是上一篇文章中讲的 Diffusion 模型输入只有随机高斯噪声和 time step。那么文字是怎么转换成 Diffusion 的输入的呢?加入文字后 Diffusion 又有哪些改变?下图可以找到答案。

文字生成图片全过程
实际上 Diffusion 是使用 Text Encoder 生成文字对应的 embedding(Text Encoder 使用 CLIP 模型),然后和随机噪声 embedding,time step embedding 一起作为 Diffusion 的输入,最后生成理想的图片。我们看一下完整的图:

token embedding、随机噪声embedding、time embedding一起输入diffusion
上图我们看到了 Diffusion 的输入为 token embedding 和随机 embedding,time embedding 没有画出来。中间的 Image Information Creator 是由多个 UNet 模型组成,更详细的图如下:
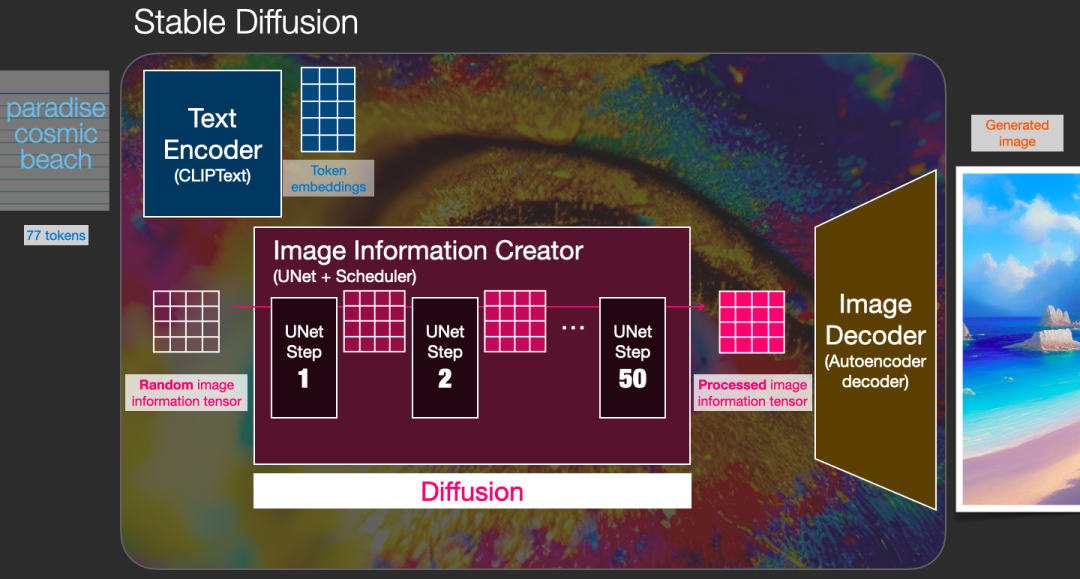
更详细的结构
可以看到中间的 Image Information Creator 是由多个 UNet 组合而成的,关于 UNet 的结构我们放在后面来讲。现在我们了解了加入文字 embedding 后 Diffusion 的结构,那么文字的 embedding 是如何生成的?接下来我们介绍下如何使用 CLIP 模型生成文字 embedding。
1.2 使用CLIP模型生成输入文字embedding
CLIP 在图像及其描述的数据集上进行训练。想象一个看起来像这样的数据集,包含 4 亿张图片及其说明:

图像及其文字说明
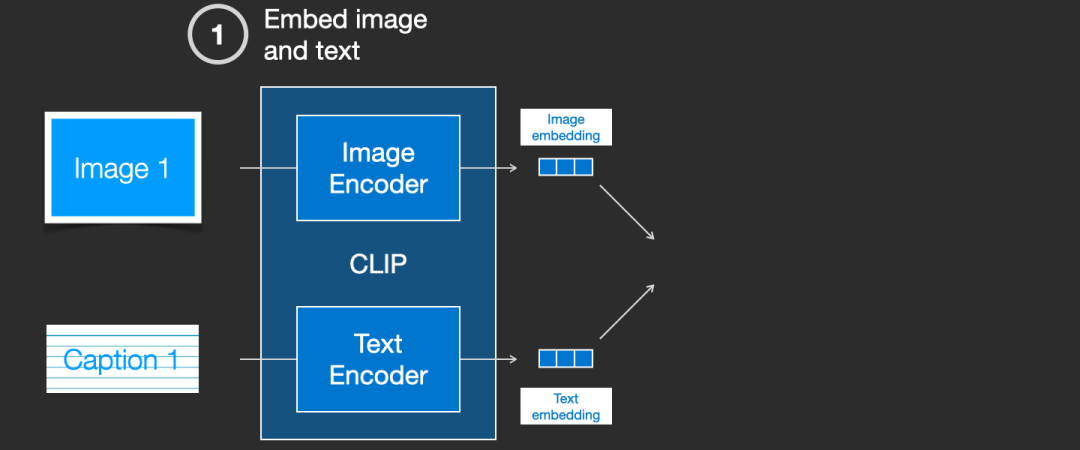
实际上 CLIP 是根据从网络上抓取的图像及其文字说明进行训练的。CLIP 是图像编码器和文本编码器的组合,它的训练过程可以简化为给图片加上文字说明。首先分别使用图像和文本编码器对它们进行编码。
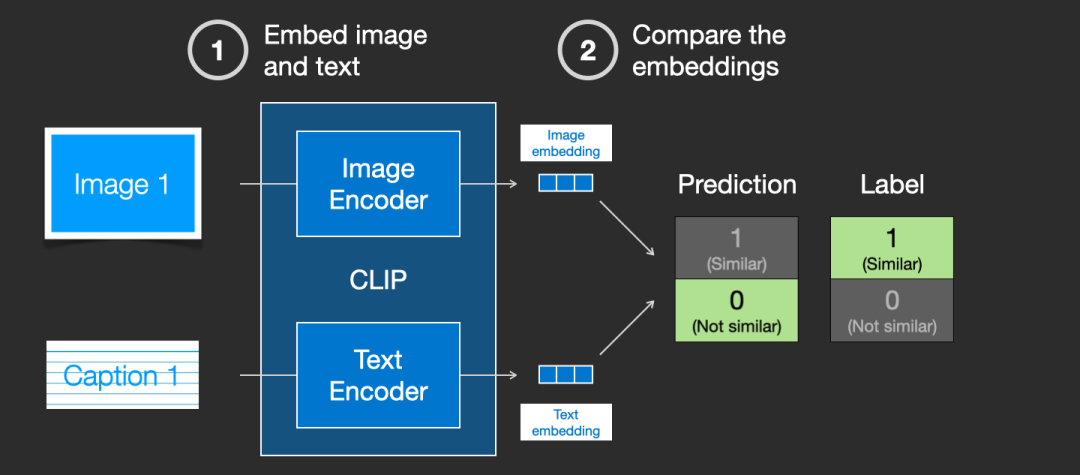
然后使用余弦相似度刻画是否匹配。最开始训练时,相似度会很低。
然后计算 loss,更新模型参数,得到新的图片 embedding 和文字 embedding。
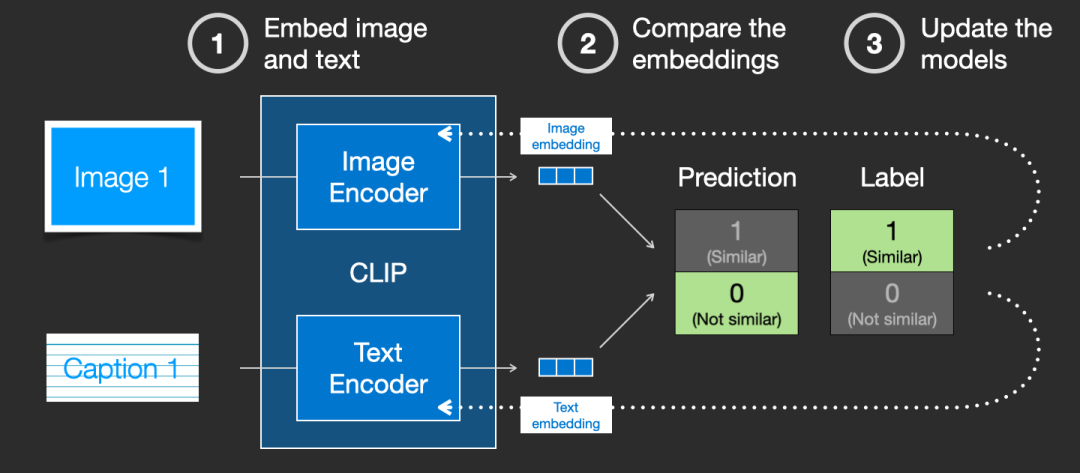
通过在训练集上训练模型,最终得到文字的 embedding 和图片的 embedding。有关 CLIP 模型的细节,可以参考对应的论文:
https://arxiv.org/pdf/2103.00020.pdf
1.3 UNet网络中如何使用文字embedding
前面已经介绍了如何生成输入文字 embedding,那么 UNet 网络又是如何使用的?实际上是在 UNet 的每个 ResNet 之间添加一个 Attention,而 Attention 一端的输入便是文字 embedding。如下图所示:
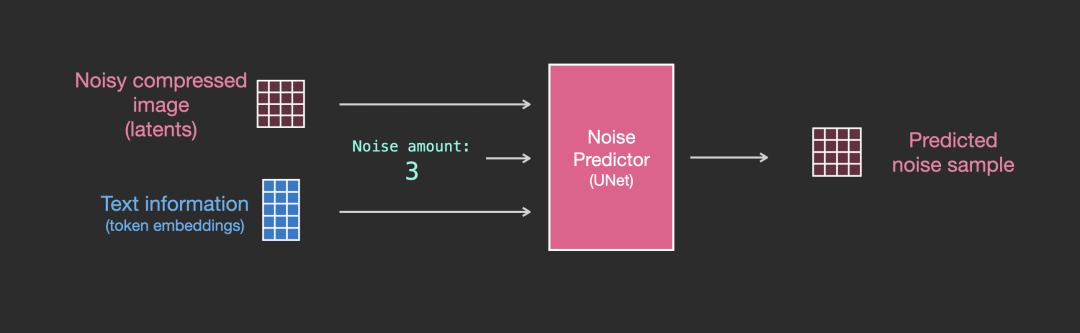
更详细的图如下:
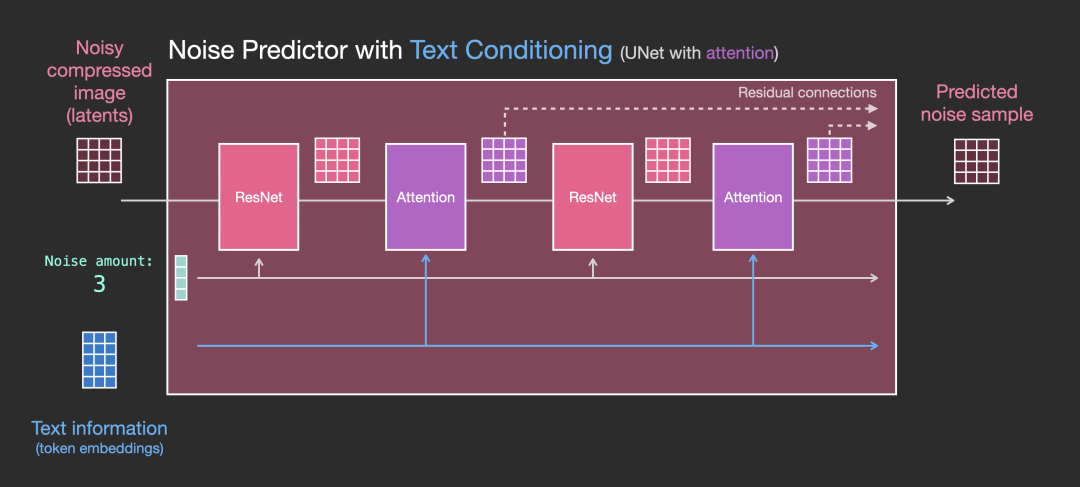
2 扩散模型Diffusion
前面介绍了 Diffusion 是如何根据输入文字生成图片的,让大家有个大概的了解,接下来会详细介绍扩散模型 Diffusion 是如何训练的,又是如何生成图片的。
2.1 扩散模型Duffison的训练过程
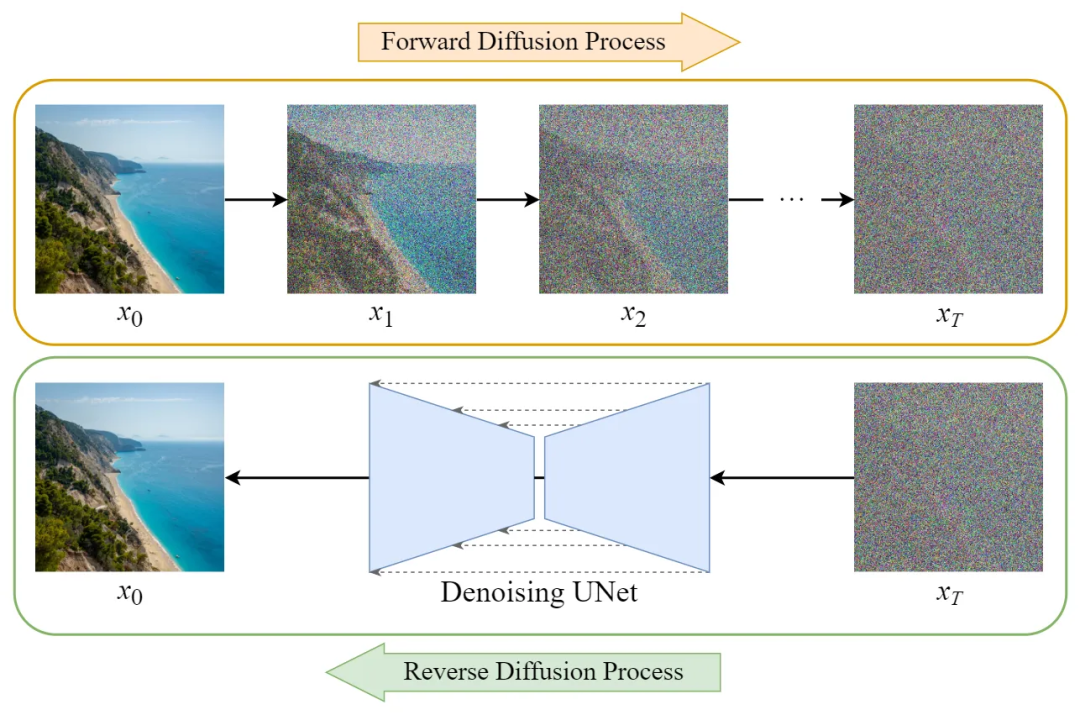
扩散模型Diffusion
Diffusion 模型的训练可以分为两个部分:
1. 前向扩散过程(Forward Diffusion Process)→图片中添加噪声;
2. 反向扩散过程(Reverse Diffusion Process)→去除图片中的噪声
2.2 前向扩散过程
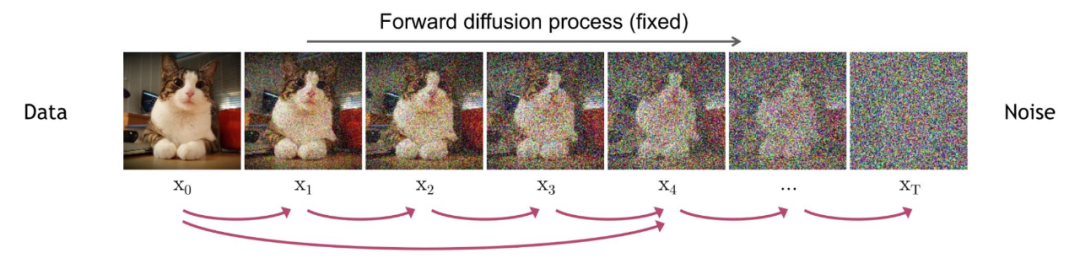
前向扩散过程是不断往输入图片中添加高斯噪声。
2.3 反向扩散过程
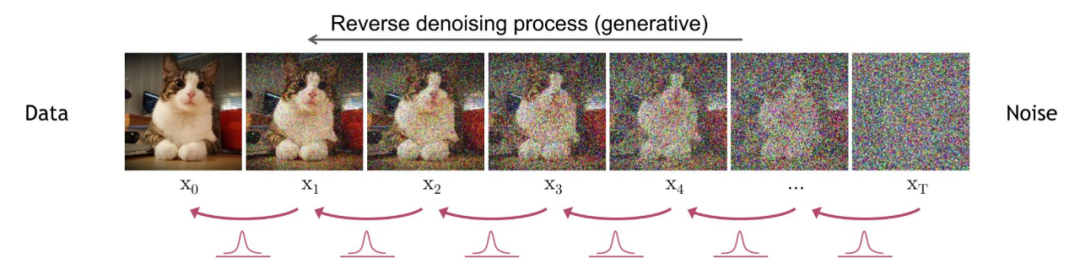
反向扩散过程是将噪声不断还原为原始图片。
2.4 训练过程
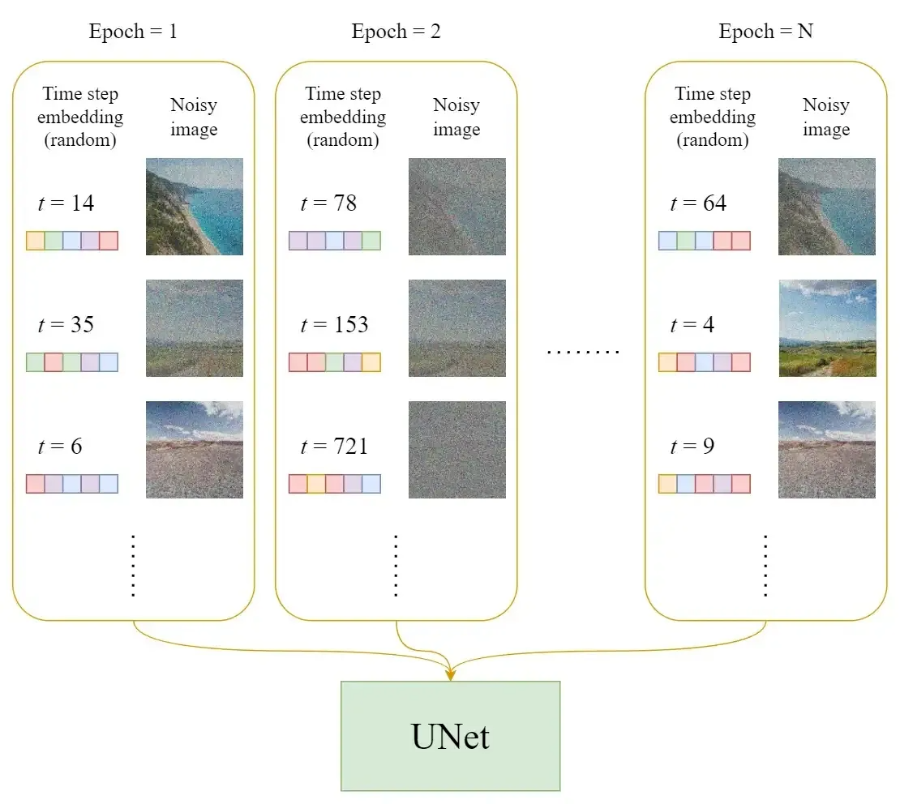
在每一轮的训练过程中,包含以下内容:
1. 每一个训练样本选择一个随机时间步长 t
2. 将 time step t 对应的高斯噪声应用到图片中
3. 将 time step 转化为对应 embedding
下面是每一轮详细的训练过程:
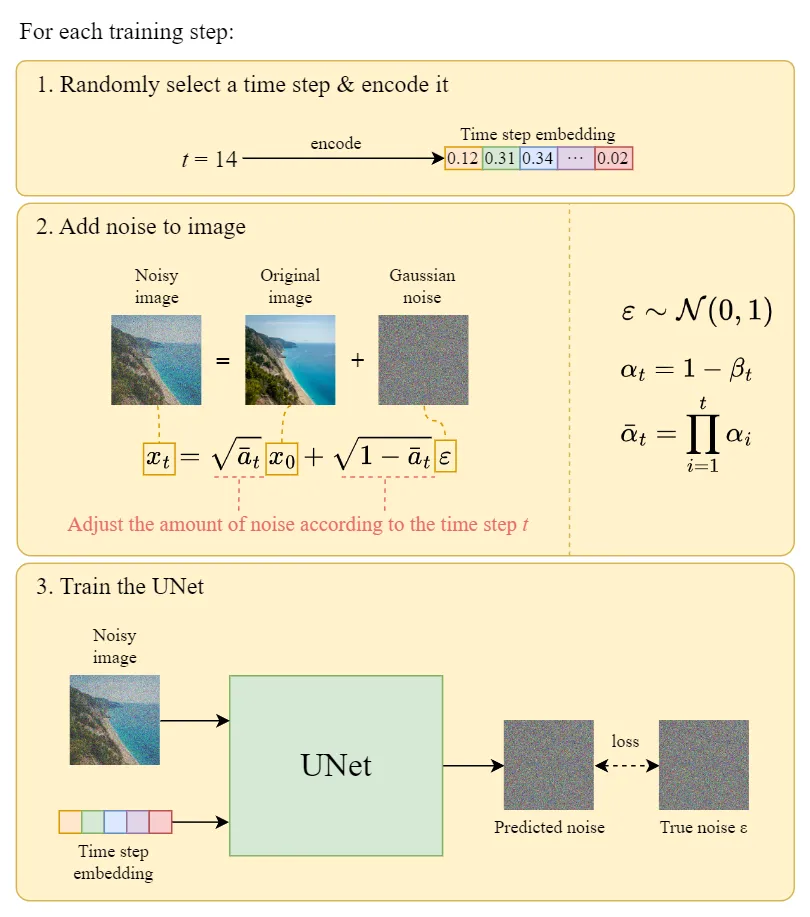
2.5 从高斯噪声中生成原始图片(反向扩散过程)
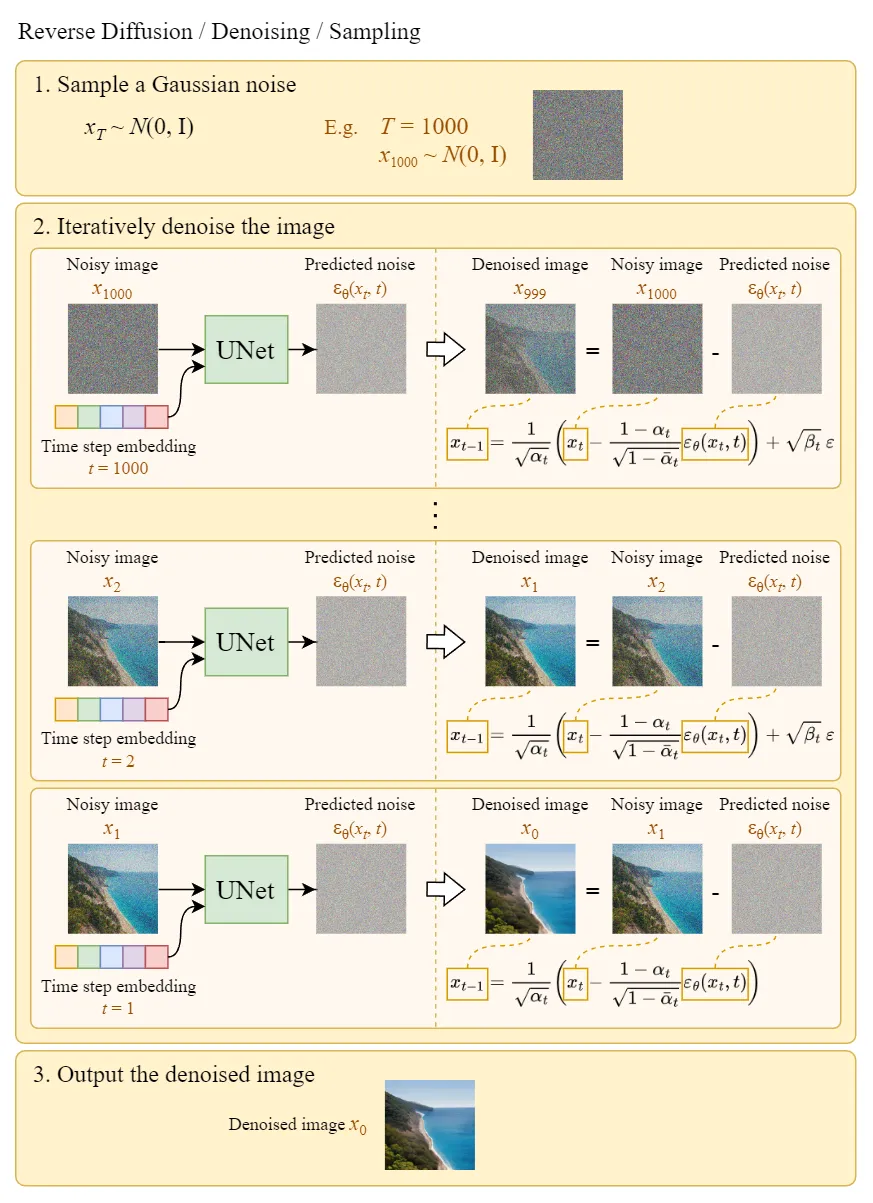
上图的 Sample a Gaussian 表示生成随机高斯噪声,Iteratively denoise the image 表示反向扩散过程,如何一步步从高斯噪声变成输出图片。可以看到最终生成的 Denoised image 非常清晰。
资料分享
为了方便大家学习,我整理了一份100G人工智能学习资料(如图)
包含数学与Python编程基础、深度学习+机器学习入门到实战,计算机视觉+自然语言处理+大模型资料合集,不仅有配套教程讲义还有对应源码数据集,更有零基础入门学习路线,不论你处于什么阶段,这份资料都能帮助你更好地入门到进阶。
需要的兄弟可以按照这个图的方式免费获取