【LangChain大模型应用与多智能体开发 ① 初识LangChain 】
爱哪有什么伟大的答案,
不过是在鸡飞狗跳的生活里,
把对方护进最柔软的肚皮。
—— 25.5.23
一、LangChain
1.什么是LangChain
LangChain是一个开源框架,旨在帮助开发者使用大型语言模型(LLMs)和聊天模型构建端到端的应用程序,它提供了一套工具、组件和接口,以简化创建由这些模型支持的应用程序的过程。LangChain的核心概念包括组件(Components)、链(Chains)、模型输入/输出(Model I/O),数据连接(Data Connection)、内存(Memory)和代理(Agents)等
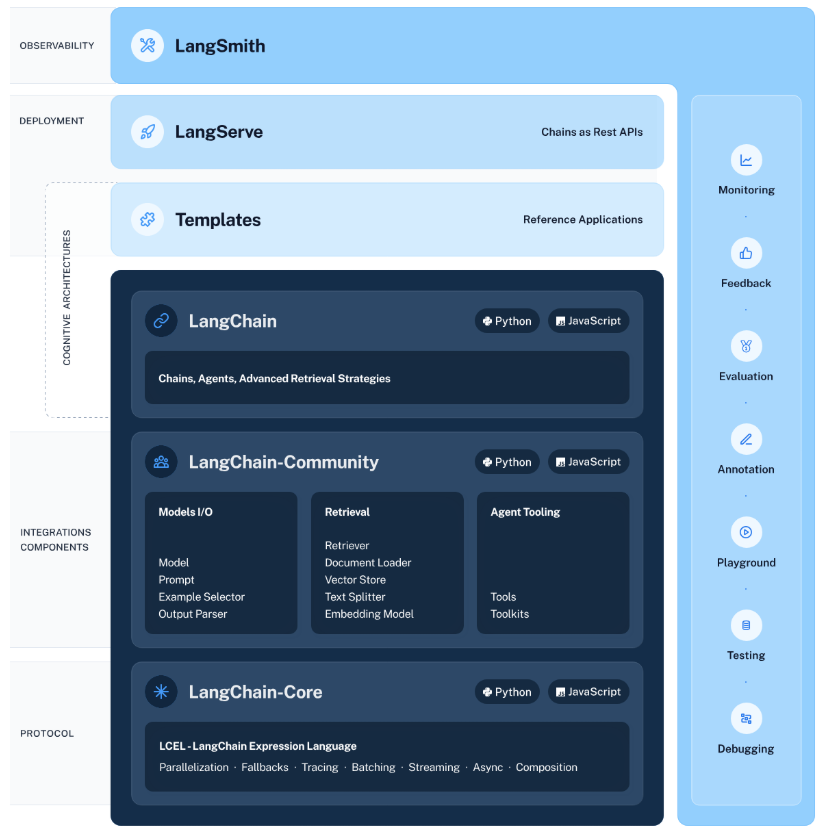
2.LangChain的一些关键特性和组件
① 组件(Components)
Ⅰ、模型输入/输出(Model I/O):负责管理与语言模型的交互,包括输入(提示,Prompts)和格式化输出(输出解析器,Output Parsers)。
Ⅱ、数据连接(Data Connection):管理向量数据存储、内容数据获取和转换,以及向量数据查询。
Ⅲ、内存(Memory):用于存储和获取对话历史记录的功能模块。
Ⅳ、链(Chains):串联Memory、Model I/O和Data Connection,以实现串行化的连续对话和推理流程。
Ⅴ、代理(Agents):基于链进一步串联工具,将语言模型的能力和本地、云服务能力结合。
Ⅵ、回调(Callbacks):提供了一个回调系统,可连接到请求的各个阶段,便于进行日志记录、追踪等数据导流。
② 模型输入/输出(Model I/O)
Ⅰ、LLMs:与大型语言模型进行接口交互,如OpenAI、Cohere等。
Ⅱ、Chat Models:聊天模型是语言模型的变体,它们以聊天信息列表为输入和输出,提供更结构化的消息。
③ 数据连接(Data Connection)
Ⅰ、向量数据存储(Vector Stores):用于构建私域知识库。
Ⅱ、内容数据获取(Document Loaders):获取内容数据。
Ⅲ、转换(Transformers):处理数据转换。
Ⅳ、向量数据查询(Retrievers):查询向量数据。
④ 内存(Memory)
用于存储对话历史记录,以便在连续对话中保持上下文。
⑤ 链(Chains)
是组合在一起以完成特定任务的一系列组件。
⑥ 代理(Agents)
基于链的工具,结合了语言模型的能力和本地、云服务。
⑦ 回调(Callbacks)
提供了一个系统,可以在请求的不同阶段进行日志记录、追踪等。
LangChain 的使用场景包括但不限于文档分析和摘要、聊天机器人、代码分析、工作流自动化、自定义搜索等。它允许开发者将语言模型与外部计算和数据源相结合,从而创建出能够理解和生成自然语言的应用程序。
要开始使用LangChain,开发者需要导入必要的组件和工具,组合这些组件来创建一个可以理解、处理和响应用户输入的应用程序。LangChain 提供了多种组件,例如个人助理、文档问答、聊天机器人、查询表格数据、与API交互等,以支持特定的用例。
LangChain 的官方文档提供了详细的指南和教程,帮助开发者了解如何设置和使用这个框架。开发者可以通过这些资源来学习如何构建和部署基于LangChain的应用程序。
3.LangChain可以构建哪些应用
LangChain 作为一个强大的框架,旨在帮助开发者利用大型语言模型(LLMs)构建各种端到端的应用程序。以下是一些可以使用 LangChain 开发的应用类型:
聊天机器人(Chatbots):创建能够与用户进行自然对话的聊天机器人,用于客户服务、娱乐、教育或其他交互式场景。
个人助理(Personal Assistants):开发智能个人助理,帮助用户管理日程、回答问题、执行任务等。
文档分析和摘要(Document Analysis and Summarization):自动分析和总结大量文本数据,提取关键信息,为用户节省阅读时间。
内容创作(Content Creation):利用语言模型生成文章、故事、诗歌、广告文案等创意内容。
代码分析和生成(Code Analysis and Generation):帮助开发者自动生成代码片段,或者提供代码审查和优化建议。
工作流自动化(Workflow Automation):通过自动化处理日常任务和工作流程,提高工作效率。
自定义搜索引擎(Custom Search Engines):结合语言模型的能力,创建能够理解自然语言查询的搜索引擎。
教育和学习辅助(Educational and Learning Aids):开发教育工具,如智能问答系统、学习辅导机器人等,以辅助学习和教学。
数据分析和报告(Data Analysis and Reporting):使用语言模型处理和分析数据,生成易于理解的报告和摘要。
语言翻译(Language Translation):利用语言模型进行实时翻译,支持多语言交流。
情感分析(Sentiment Analysis):分析文本中的情感倾向,用于市场研究、社交媒体监控等。
知识库和问答系统(Knowledge Bases and Q&A Systems):创建能够回答特定领域问题的智能问答系统。
LangChain 的灵活性和模块化设计使得开发者可以根据特定需求定制和扩展应用程序。通过将语言模型与外部数据源和API结合,LangChain 能够支持广泛的应用场景,从而创造出更加智能和用户友好的软件解决方案。
二、Chain的基本结构:提示、模型、输出解析器
1.基本示例:提示 + 模型 + 输出解析器
最基本和常见的用例是将提示模板和模型链接在一起。为了看看这是如何工作的,让我们创建一个接受主题并生成小红书短文的链:
使用管道符 “|” 链接提示模板与模型以及输出
ChatPromptTemplate.from_template():根据模板字符串创建聊天提示词,支持{变量名}占位符,可传入系统提示、用户消息等。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
template | str | ✅ | 提示词模板字符串,包含{变量}占位符(如"你好,{name}!")。 |
input_variables | List[str] | ❌ | 模板中用到的变量名列表(自动推断时可选)。 |
partial_variables | Dict | ❌ | 预先填充的固定变量(如系统角色)。 |
validate_template | bool | ❌ | 是否验证模板格式(默认True)。 |
ChatOpenAI():创建 OpenAI 聊天模型实例,支持调用gpt-3.5-turbo、gpt-4等接口。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
model_name | str | ✅ | 模型名称(如"gpt-3.5-turbo"、"gpt-4-1106-preview")。 |
temperature | float | ❌ | 生成随机性(0-2,默认 0.7):值越高越创意,越低越确定。 |
max_tokens | int | ❌ | 最大生成 token 数(默认None,由模型限制)。 |
openai_api_key | str | ❌ | OpenAI API 密钥(优先从环境变量OPENAI_API_KEY读取)。 |
request_timeout | Union[int, tuple] | ❌ | 请求超时时间(秒),支持元组(连接超时,读取超时)。 |
streaming | bool | ❌ | 是否启用流式输出(默认False)。 |
StrOutputParser():将模型返回的ChatMessage对象解析为纯文本字符串,忽略消息类型(如system/user)。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
keep_prompt | bool | ❌ | 是否保留原始提示词(默认False)。 |
join_char | str | ❌ | 多消息拼接符(默认\n)。 |
chain.invoke():触发 Chain 的执行流程,传入输入参数并获取模型响应。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
inputs | Dict | ✅ | 输入参数(键需匹配 Prompt 的变量名,如{"text": "苹果"})。 |
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAIprompt = ChatPromptTemplate.from_template("请根据下面的主题写一篇小红书营销的短文: {topic}")
model = ChatOpenAI(model="gpt-3.5-turbo-1106",openai_api_key=OPENAI_API_KEY)
output_parser = StrOutputParser()chain = prompt | model | output_parserchain.invoke({"topic": "康师傅绿茶"})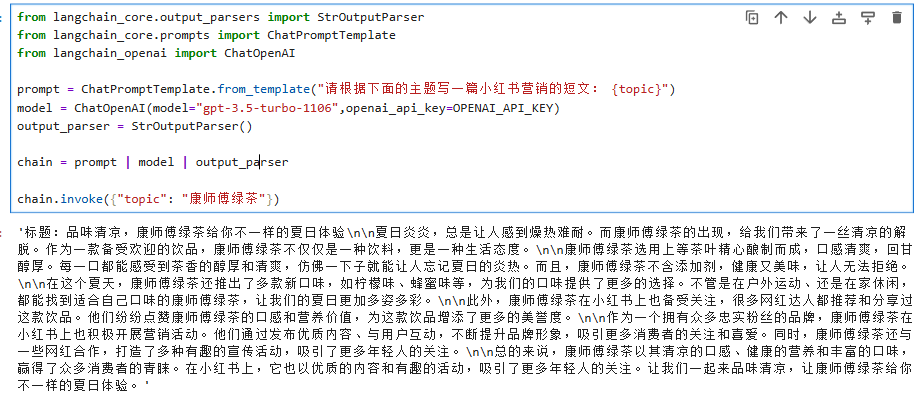
2.Prompt 提示
prompt 是一个 BasePromptTemplate ,这意味着它接受模板变量的字典并生成一个 PromptValue 。 PromptValue 是一个完整提示的包装器,可以传递给 LLM (它接受一个字符串作为输入)或 ChatModel (它接受一个序列作为输入的消息)。它可以与任何一种语言模型类型一起使用,因为它定义了生成 BaseMessage 和生成字符串的逻辑。
示例:
ChatPromptTemplate.from_template():根据模板字符串创建聊天提示词,支持{变量名}占位符,可传入系统提示、用户消息等。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
template | str | ✅ | 提示词模板字符串,包含{变量}占位符(如"你好,{name}!")。 |
input_variables | List[str] | ❌ | 模板中用到的变量名列表(自动推断时可选)。 |
partial_variables | Dict | ❌ | 预先填充的固定变量(如系统角色)。 |
validate_template | bool | ❌ | 是否验证模板格式(默认True)。 |
prompt.invoke():① 绑定变量到提示模板:将输入的变量值填充到提示模板的占位符中(如 {变量名})。② 触发后续处理流程:若 prompt 是 链(Chain) 的一部分:调用 LLM 模型生成回答,并返回处理结果。若 prompt 仅是 提示模板(PromptTemplate):仅返回格式化后的提示文本,不调用模型。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
inputs | Dict 或 str | ✅ | 输入变量值。 - 若模板含多个变量:需传入字典(如 {"name": "Alice", "age": 30})。- 若仅一个变量:可直接传入字符串(如 "Alice")。 |
**kwargs | 其他关键字参数 | ❌ | 其他可能的参数(取决于具体子类实现)。例如: - stop:停止生成的标记列表。- callbacks:回调函数列表。 |
from langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_template("请根据下面的主题写一篇小红书营销的短文: {topic}")prompt_value = prompt.invoke({"topic": "康师傅绿茶"})
print(prompt_value)
3.Model 模型
然后 PromptValue 被传递给 model 。在本例中,我们的 model 是 ChatModel ,这意味着它将输出 BaseMessage
message = model.invoke(prompt_value)
print(message)
4.Output parser 输出解析器
将 model 输出传递给 output_parser ,这是一个 BaseOutputParser ,意味着它接受字符串或 BaseMessage 作为输入。 StrOutputParser 特别简单地将任何输入转换为字符串。
StrOutputParser():将模型返回的ChatMessage对象解析为纯文本字符串,忽略消息类型(如system/user)。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
keep_prompt | bool | ❌ | 是否保留原始提示词(默认False)。 |
join_char | str | ❌ | 多消息拼接符(默认\n)。 |

output_parser.invoke(message)
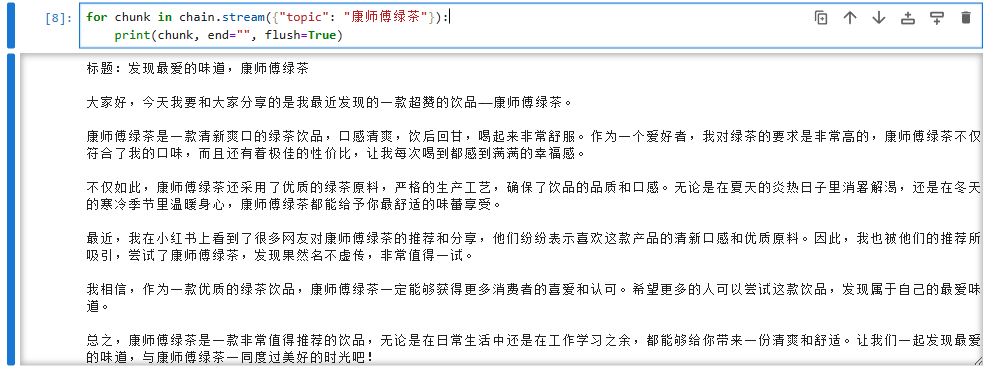
5.流式输出
chain.stream():在 LangChain 框架中,stream() 是 链(Chain) 的核心方法之一,用于流式生成输出。与普通的 invoke() 或 run() 一次性返回完整结果不同,stream() 会以 ** 迭代器(Iterator)** 的形式逐块返回生成内容,适用于需要实时展示输出或处理大文本的场景(如聊天机器人逐字回复、长文档生成等)。
| 参数名 | 类型 | 必选 | 说明 |
|---|---|---|---|
inputs | Dict | ✅ | 输入变量值(需与链的提示模板变量匹配),格式为字典(如 {"question": "你好"})。 |
streaming | bool | ❌ | 是否强制启用流式模式(通常链会自动识别,默认 True)。 |
**kwargs | 其他关键字参数 | ❌ | 传递给 LLM 的参数,例如: - max_tokens:最大生成 Token 数- temperature:生成随机性- stop:停止生成的标记列表 |
for chunk in chain.stream({"topic": "康师傅绿茶"}):print(chunk, end="", flush=True)