数据结构第1章 (竟成)
第 1 章 编程基础
1.1 前言
因为数据结构的代码大多采用 C 语言进行描述。而且,408 考试每年都有一道分值为 13 - 15 的编程题,要求使用 C/C++ 语言编写代码。所以,本书专门用一章来介绍 408 考试所需的 C/C++ 基础知识。有基础的考生可以快速浏览或者跳过本章。想要深入了解 C/C++ 语言的考生,可以参考其他专业书籍。
1.2 变量与数据类型
1.变量
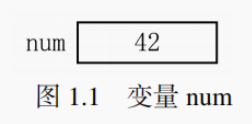
在 C 语言中,通过变量存储数据,不同类型的数据需要不同类型的变量。图 1.1 是一个整型变量的例子,方框代表存储空间,num 是变量名,42 是变量值。
在 C 语言中,所有变量必须先声明后使用。一个变量声明的同时赋初始值的实例如下:int x = 3, y = 4; int z = x + y;上述代码执行完后,int 型变量 x、y、z 的值分别为 3、4、7。相关的语法介绍如下:
(1) 可同时声明多个同类型的变量。在声明变量的同时可以进行初始化,即对其赋初始值。这里 x、y、z 都是在声明的时候就已经被赋值。
(2) C 语言变量名只能由字母、数字和下划线组成,且变量名不能以数字开头。变量名中的字母是区分大小写的。变量名不能是 C 语言关键字。2. 基本数据类型
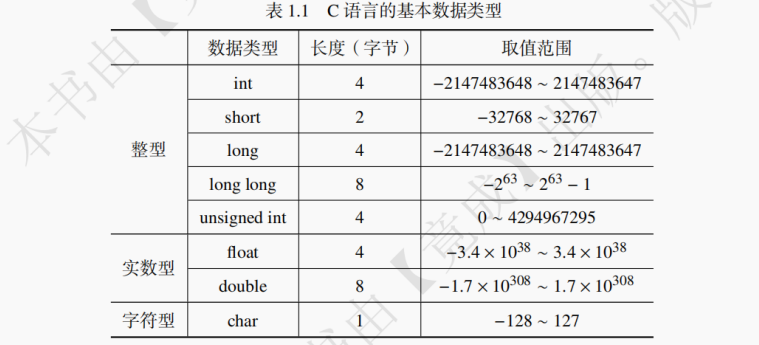
C 语言的基本数据类型如表 1.1 所示。
其中,不同的整型类型支持的取值范围不同。通常,使用 int 表示整数类型、float 表示浮点数类型、char 表示字符类型。
在 C 语言中,可以使用 sizeof 操作符获取变量所占空间的大小,并返回变量所占的字节数。sizeof 的参数不仅可以是变量,还可以是数据类型。例如:在 64 位系统中,sizeof (x) 和 sizeof (int) 的返回值都为 4(x 为一个 int 型变量)。
除了上述基本数据类型,C++ 中还有表示真假的布尔(bool)类型。C 语言在 C99 标准之前没有 bool 类型,但可以用 0 表示假,非 0 表示真。这里的真和假可以作为判断的依据,例如:如果 if 语句的判断条件的值为 0,则不会执行对应的操作语句;如果 if 的判断条件的值非 0,则会执行对应的操作语句。如以下的代码所示:if (0) {操作语句; // 判断条件的值为0,操作语句不执行 } if (1) {操作语句; // 判断条件的值非0,执行对应的操作语句 }1.2.1 指针
1.什么是指针?
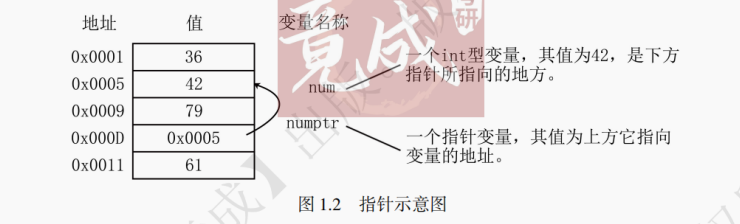
指针变量简称指针。指针变量与 int、float 等变量略有不同。指针变量存储的不是变量的值,而是变量对应的地址,即指针变量是用来存放地址的变量。如图 1.2 所示,num 是一个 int 型变量,num 变量值是 42,numptr 是一个指向 num 的指针变量,箭头代表对应指针的指向。
2.与指针相关的操作
在声明指针时,* 充当标识符,标识声明的变量是一个指针变量。在用指针访问变量时,* 表示获取指针指向地址的值。& 是取址符,&y 就是取得变量 y 的地址。此外,指针之间还可以直接进行赋值,使它们指向同一个变量。下面通过具体的例子来介绍:
//如图1.3所示: int a = 1, b = 2, c = 3; // 声明三个int型变量 int *p, *q; // 声明两个int型指针 // 指针p和指针q此时为野指针,其值在图中用××来表示//如图1.4所示: p = &a; // 将指针p指向变量a q = &b; // 将指针q指向变量b//如图1.5所示: c = *p; // 取得指针p所指向变量的值,并将其赋给变量c p = q; // 将p的指向改为q的指向,二者此时指向同一个变量 *p = 13; // 对p执行解引用操作,将p所指向的变量的值更改为13 // 此时*p等价于变量b,*q的值也应为13提示:空指针(NULL)代表空值,它指向一个不被使用的地址。可以将空指针赋值给任何指针类型变量。大多数系统都将 0 作为不被使用的地址,此时,NULL 也等价于常量 0。
1.2.2 结构体
除了基本的数据类型外,C 语言还允许用结构体实现自定义数据类型。结构体是 C 语言中一种重要的数据类型,该数据类型由一组称为成员(或称为域,或称为元素)的不同数据组成,其中每个成员可以具有不同的类型。结构体通常用来表示类型不同但是又相关的若干数据。
提示:考生有必要熟练掌握结构体的相关操作。因为在后续章节中,会经常用到结构体,在 408 考试的算法题中,有时也会要求给出特定结构体的定义。1.结构体的定义与创建
在 C 语言中,struct 关键字用于定义结构体,结构体最简单的定义方式为:
struct 结构体名 {成员列表 };提示:结构体定义必须以分号结尾,否则将无法编译通过。
例如:以下代码定义了一个用于记录学生成绩的结构体:struct stuInfo {int stuId, rank; // 学生ID、对应排名float score; // 学生分数 };以下代码定义了一个 stuInfo 型变量:
// 此句创建了一个stuInfo类型的变量,变量名为zhangSan struct stuInfo zhangSan;注意:在 C 语言中,如果采用这种结构体类型定义方式,定义一个该结构体变量时 struct 关键字不能省略。
上述两种操作也可以一步到位:在定义结构体类型的时候同时定义变量,只需要在末尾的 “}” 后面加上变量名即可。这种方式与 “int x, y, z;” 类似,定义与声明如下:struct stuInfo {int stuId, rank;float score; } zhangSan;定义结构体变量时常使用 typedef 关键字,其作用是给数据类型起一个 “别名”。例如:
typedef int stuId; // 给int取别名为stuId; // 下面两句都可以创建一个int型变量,是等价的 int zhangSan; stuId zhangSan;在 408 考试中,typedef 常用于给结构体类型取别名。这种方式在定义新的结构体变量时,可以省略 struct 关键字。例如:
typedef struct stuInfo { // 此处stuInfo也可省略int stuId, rank;float score; } stuInfo; // 给struct stuInfo {……} 取了一个stuInfo别名 stuInfo zhangSan; // 此句创建了一个stuInfo类型的变量,名为zhangSan在使用 typedef 定义结构体时,可以将结构体的定义拆分为四个部分:
(1) typedef struct 关键字:指明了这是一个结构体类型的定义,并为其取别名。
(2) typedef struct 后面的结构体名称:在已定义了结构体类型别名时这一部分可省略。
(3) 花括号内是结构体的成员列表:声明了该结构体包含的成员变量。上述代码包含了三个成员变量:stuId、rank 和 score,分别代表学生的 id、排名和分数。
(4) 结构体类型别名:即最后的 stuInfo。之后便可以把这个名称当作新的变量类型来使用。
在定义结构体类型时,当结构体成员中有指向该结构体类型变量的指针时,typedef struct 后面必须要加上该结构体的名称。以本书 5.2. 小节(第 116 页)中二叉树的结点为例:// 定义一个名为Node的结构体类型 typedef struct Node {int data; // 结点的data域struct Node *lChild, *rChild; // 结点的指针域,此句中struct不可省略 } Node;在上述代码中,分别定义了 lChild 和 rChild 两个指针。在结构体内部定义这两个指针时,需要用到结构体名 Node,因此应当在 typedef struct 的后面预先声明。只要完成了预先声明,结构体内部也可以使用它本身的类型来对变量进行定义,即实现递归定义。有如下两点需要注意:
① 在第 2 行代码 typedef struct Node 中,结构体名称 Node 不能省略,因为后面定义结构体指针变量要用;
② 在第 4 行代码 struct Node *lChild 中,结构体指针不能用别名 Node,因为别名 Node 还未定义;2. 结构体内部变量的访问
结构体变量访问其成员变量时,使用 “.” 运算符。而结构体指针访问其成员变量时,使用 “->” 运算符。如以下代码所示:
Node root, lc, rc; // 声明3个Node类型的变量 root.data = 1; root.lChild = &lc; root.rChild = &rc; // 初始化root root.lChild -> data = 2; // 通过指针对lc进行操作 root.rChild -> data = 3; // 通过指针对rc进行操作在 root.lChild -> data 这行代码中,因为 root 本身是一个 Node 类型的变量,故使用 “.” 而它的成员变量 lChild 是一个 Node 类型的指针,故使用 “->”。
1.3 数组和链表
1.3.1 数组
数组(Array)是有序排列的同类数据元素的集合。如图 1.6 所示。
提示:用于区分数组的各个元素的数字编号称为下标。
用基本数据类型来创建数组的示例如下:int arr1[10]; // int型数组,利用连续的空间存储10个int型数据 arr1[0] = 1; // 下标从0开始计数 arr1[9] = 10; // 最大下标为9 arr1[10] = 11; // 出现数组越界,会导致错误用结构体类型来创建(stuInfo 是上一节定义的结构体类型)数组的示例如下:
// stuInfo型数组,利用连续的地址空间存储50个stuInfo型数据 stuInfo students[50]; // 对students[50]数组中的第一个结构体元素的score成员变量赋值为80.0 students[0].score = 80.0;除上述两种数组创建方法外,还可用 malloc 函数或 new 关键字向内存的动态存储区申请一块连续的地址空间以创建数组。创建一个能够存放 100 个 int 型数据的数组 arr2 的代码如下:
int *arr2; // 定义一个int型指针arr2 // 用malloc函数申请大小为100个int数据的空间,并把首地址赋给arr2 arr2 = (int *)malloc(sizeof(int) * 100); // C++中可直接用new进行申请 int *arr2 = new int[100]; // 结束时要用delete []释放arr2数组空间 delete [] arr2;对于一个长度为 n 的数组,其下标从 0 开始,到 n - 1 结束。C 语言中的数组会被分配一块连续的地址空间,由于其内部元素的数据类型一致、占用存储空间的大小相等,便于通过数组的起始地址加上偏移量的方式,获得指定下标的元素地址,并访问该元素。因此,数组支持随机存取。例如,可以直接用 arr2 [10] 存取数组中下标为 10 的数组元素。
注意:C 语言数组下标从 0 开始,下标为 10 的数组元素其实是数组中第 11 个元素。
接下来介绍一下 C 语言中如何表示字符串(只推荐使用下列表示方法):// str字符数组不需要显式地指定数组大小,编译器会自动地根据字符串来判断大小数值 char str[] = "hello"; // s[0] == 'h'; 注意字符类型用单引号' '表示,字符串用双引号" "表示 // 也可以下面的形式表示字符串,此时s是指向字符串"hello"的首个字符的地址 char *s = "hello"; // 此时也可以使用s[i]来访问其第i个字符(但不可以修改)1.3.2 链表
链表是一种数据元素的逻辑地址相邻、物理地址不一定相邻的存储结构,通过链表中指针的链接次序来表示数据元素之间的逻辑顺序。由于存储空间的不连续性,当需要访问链表中的某个元素时,只能通过遍历链表的方式进行访问,故链表不支持随机存取,只能顺序存取。
与数组相比,链表的优点在于插入和删除元素比较方便,这个特征在后面的对应章节会详细介绍。链表还能够自由地扩展长度,而数组由于需要连续的空间,故在分配时就需要指定长度,当元素的数量超过数组长度时,就需要重新分配空间。
下面是一个单链表的实例,涉及了结构体的定义、指针等知识:typedef struct LinkNode { // 定义链表结点int data;struct LinkNode *next; // 指向链表下一个元素的地址 } LinkNode;LinkNode A, B, C; // 定义3个链表结点,其存储位置不一定连续 A.next = &B; // 将A的下一个元素设为B B.next = &C; // 将B的下一个元素设为C上述代码首先定义了 LinkNode 这个结构体,并声明了 3 个 LinkNode 变量,经过简单的链接操作后,得到一个如图 1.7 所示的 “A -> B -> C” 形式的链表。
1.4 程序结构
程序由一行行的代码构成,默认是顺序执行。在代码执行的过程中,常常需要根据特定的条件来选择执行相对应的代码,这种选择执行的方式对应的是分支结构。程序还可能多次执行相同的操作,直到满足特定条件,这种重复执行的方式对应的是循环结构。
1.4.1 分支结构
C 语言中的分支结构主要有两种,一是 if 语句,二是 switch 语句。if 语句更常用,这里只介绍 if 语句。if 语句的示例代码如下:
int x = 321; if (x % 3 == 0) { // C语言中用符号%取余数printf("%d能整除3", x);x = x + 1; } else if (x % 3 == 1)printf("%d除以3余1", x); else {printf("%d除以3余2", x); }if 语句有以下几个要素:
如上述代码第 2 行,if 后面接判断条件,判断条件需要用小括号包裹。如果条件为真,则执行紧接的大括号内的语句,否则跳转到 else 部分;
如上述代码第 5 行,如果上一个 if 条件不为真,else 后面还有 if(即 else if),则继续进行判断,否则直接执行 else 后面的代码块(如上述代码第 7 行);
else 后面如果有多行代码(即多个;分隔),则必须用大括号将分支对应的代码块括起来(如上述代码的第 3 到 4 行)。如果只有 1 行代码,则可以省略花括号(如上文代码的第 6 行)。
1.4.2 循环结构
循环结构有两种类型:for 循环和 while 循环,可根据实际情况选用(do - while 语句较少见,故不作介绍)。下面以遍历数组和遍历链表为例,分别介绍两种循环结构的用法。
1.for 循环 的示例代码如下:
const int N = 100; int main() {int arr[N]; //初始化一个长度为100的int型数组// ++操作符使得变量的数值+1for (int i = 0; i < N; ++i) { // 遍历数组中的每个元素if (i < 10) arr[i] = i * i; // 对前10个元素赋值else if (i < 50) continue; // 跳出当前循环,进入下一轮循环else break; // 结束循环,执行for循环之后的代码}return 0; }for 循环包括以下三个组成部分:
(1) for 关键字,指明这是一个 for 循环;
(2) 循环控制条件,即 for 之后由小括号包裹的部分。它又包括三个部分,由两个 “;” 分隔,从左到右依次是:循环初始设置,对应上述代码中的 “int i = 0”,只在首次循环时执行。它通常用来设置循环对应的下标的初始值,如设置 i 的初始值为 0,即数组的第一个下标。
进入循环的判断条件,对应上述代码中的 “i < N”。每次执行代码块之前,先求这个表达式的值,如果为 true,则进入循环,否则跳出循环。
循环代码块结束后的更新操作,对应上述代码中的 “++i”。每次执行完循环代码块后,执行更新操作,通常用来设置下一个循环的状态,例如上述代码更新了下标 i 的值。
(3) 循环代码块,每次进入循环都要执行这个代码块。它可能包含两个关键字:continue 和 break,这两个关键字的作用如下:continue 关键字:跳出本轮循环,进入下一轮循环。
break 关键字:结束循环,执行循环之后的代码。
2.while 循环 的示例代码如下:
int i = 0; while (i < 10) { // i大于或等于10时结束循环printf("%d\n", i); // 打印输出当前值的i值++i; }while 循环的功能与 for 循环相同。区别在于,while 的循环控制条件仅包含进入循环的判断条件,而循环初始设置通常在 while 语句之前,循环更新操作包含在循环代码块内部。continue 和 break 也可以用于 while 循环。
1.5 函数
1.5.1 函数定义
函数是 C 语言的基本模块,通过对函数模块的调用实现特定的功能。如果把函数比喻成一台机器,那么函数的参数就是机器所需的原材料,函数的返回值就是机器最终产出的产品。在一定程度上,函数的作用就是根据不同的参数产生不同的返回值 (对于不含返回值的函数,函数的作用就是对数据进行相应处理)。假如一个程序的很多地方需要对数组进行遍历操作,而每次执行的又都是同样的代码,可以把这段代码封装为一个函数,并在每次使用时进行调用。
提示:C 语言程序的执行总是从 main 函数开始,最后也是由 main 函数来结束整个程序。
图 1.8 以具体例子说明了函数的基本语法格式。其中 addArray 函数的功能是:对长度为 n 的数组中的各元素进行求和:
函数语法格式的要点如下:
(1) 返回值类型:函数执行结束之后的返回值的类型,可以是 void (返回值为空)、int、float 等一些基本数据类型,也可以是指针或自定义的结构体。
(2) 函数名:由用户确定,如上述函数示例中的 addArray。
(3) 参数列表:形式为 “参数类型 参数”,如 int n ,表示传入函数的参数是一个 int 型变量。传入的每一个参数都要声明参数类型,需要与变量的定义相区别,即若要传入两个 int 型变量,括号内写法应为 int a, int b 而非 int a, b 。
(4) 函数主体:函数主体包含一组定义函数执行任务的语句。
(5) 返回值:C 语言中使用 return 来返回函数需要传回的数据,且 return 后面的数据类型要与函数定义时的返回值类型保持一致。若函数返回值类型为 void,则无需返回具体值,但可以通过 return 语句来提前结束函数的执行。1.5.2 函数调用
在 C 语言中,函数调用有多种形式,例如:
// max函数返回a、b中较大的一个 int c = max(a, b); // 1.函数作为表达式中的一项 printf("%d", c); // 2.直接作为一个单独的语句使用(调用printf函数) printf("%d", max(a, b));// 3.函数的返回值作为另一个函数的实参注意:当函数作为表达式中的一项被调用,或者作为函数实参被调用时,要求函数有返回值,否则会报错。
函数还可以进行嵌套调用和递归调用,下面给出两者的定义和举例说明。
1.嵌套调用
嵌套调用是指在一个函数中调用另一个函数,调用方式与在 main 函数中调用其他函数是一致的。举例说明如下:
int max2(int a, int b) { // 返回两个整数中较大的一个return (a > b? a : b); //?:操作符含义见下面提示部分的解释 } int max4(int a, int b, int c, int d) { // 返回四个整数中最大的一个int ans;ans = max2(a, b); // 嵌套调用max2函数ans = max2(ans, c);ans = max2(ans, d);return ans; } int main() {int a, b, c, d, maxNum;// 接收来自键盘的四个值并赋给a, b, c, dscanf("%d %d %d %d", &a, &b, &c, &d);maxNum = max4(a, b, c, d);printf("%d", maxNum); // 打印输出a,b,c,d中的最大值 }上述代码中的 main 函数调用了 max4 函数,即发生了函数嵌套调用。
提示:max2 函数的定义中用到了三目运算符:“<表达式 1>? < 表达式 2>: < 表达式 3>”,它的意思是先求表达式 1 的值,如果为真,则执行表达式 2,并返回表达式 2 的结果;如果表达式 1 的值为假,则执行表达式 3,并返回表达式 3 的结果。举个例子:对于条件表达式 a? x : y,先判断条件 a 的真假,如果 a 的值为 true,那么返回表达式 x 的计算结果;否则,计算 y 的值,返回表达式 y 的计算结果。
注意:不能在函数中定义函数,即不能 “嵌套定义函数”。
分析该程序的执行过程如下:
(1) 程序执行总是从 main 函数开始,最后也是由 main 函数结束整个程序;
(2) 在 main 函数中调用 max4 函数,在执行到 “max = max4 (a, b, c, d);” 时,程序就跳转到 max4 函数执行;
(3) 在 max4 函数中又分别调用了三次 max2 函数,程序会分三次跳转到 max2 函数执行并依次将返回值赋给 ans 变量;
(4) max4 函数执行完毕,执行 “return ans;”,将 ans 的值作为返回值赋给 main 函数中的 maxNum 变量;
(5) main 函数将 maxNum 的值输出到控制台,执行完 main 函数后,程序运行结束。2. 递归调用
递归调用是指一个函数调用函数自身的行为。递归一般会有边界条件,即递归结束的条件,也称递归基。例如:斐波那契数列是满足 F (0) = 1, F (1) = 1, F (n) = F (n - 1) + F (n - 2) 的数列。以如下代码为例,F 函数调用了 F (n - 1) 和 F (n - 2),所以此函数是递归函数,“n == 0” 和 “n == 1” 就是两个递归基。
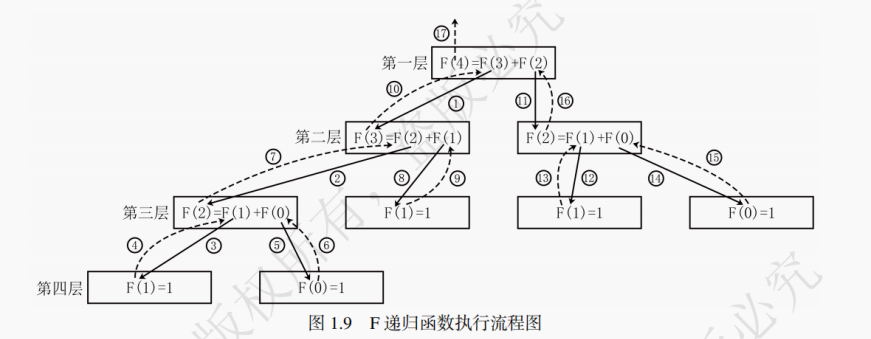
// 递归法求斐波那契数列中第n个位置上的数的值 int F(int n) {if (n == 0) { return 1; }if (n == 1) { return 1; } // 递归边界return F(n - 1) + F(n - 2); // 递归式 }以上述函数 F 为例,当 n 为 4 时,图 1.9 给出了 F 函数的具体执行流程,其中实线箭头表示 “递” 的步骤,虚线箭头表示 “归” 的过程。
如果需要求出斐波那契数列中第 n 个位置上的数,也可以采用迭代的方法,即在循环中参与运算的变量也是保存结果的变量,从某个值开始,不断地由上一步的结果计算 (或推导) 出下一步的结果。用迭代方式求解的代码如下:// 迭代法求斐波那契数列中第n个位置上的数的值 int fib(int n) {int first = 1, second = 1, cur = 0;if (n <= 1) { return 1; }for (int i = 2; i <= n; ++i) {cur = first + second;first = second;second = cur;}return cur; }对此不太熟悉的考生可以给出一个具体的 n,然后手动模拟上述程序的运行过程,以便深入理解迭代的算法思想。
关于递归和迭代的区别,有兴趣的考生可以查阅其他专业书籍,这里不再展开详述。1.5.3 C 语言函数的形参与实参
C 语言中函数的参数会出现在两个位置,在函数定义处的参数叫形参,在函数调用处的参数叫实参。下面给出两者的介绍:
形参(形式参数):在函数定义中出现,只有在该函数被调用时,才会为形参分配存储空间、接收传入函数的数据,形参才会得到具体的值。
实参(实际参数):在函数调用中出现,包含具体的数据。在发生函数调用时,实参内的值会传递给形参,从而被函数内部的代码使用。
形参和实参的示例代码如下所示:
void add(int x, int y) { // 函数定义,此处的x,y为形式参数int z = x + y;printf("%d", z); } add(3, 4); // 函数调用,此处的3,4为实际参数数据从实参向形参传递的过程叫做单向值传递。在函数内部对于形参的操作并不会影响实参的值。
注意:当数组名作为参数传入时,函数可以直接对该原数组中的元素进行操作。这是因为数组名对应的是数组的首地址,故参数传递中传递的是地址。形参数组取得该首地址之后,形参数组和实参数组便为同一数组,共享同一段内存空间。1.5.4 C/C++ 中的参数传递
在 C 语言中,参数传递的方式只有值传递。而在考试中,偶尔也会有 C++ 中的引用传递的情况,因此在这里也顺带介绍 C++ 中的引用传递。
注意:初学者在学习 C 语言时,可能会发现 C 语言有值传值和传指针的说法,这种说法也是正确的,传值和传指针的本质都是值传递。C 语言在传指针时,也只是把指针的值(即地址)传入。
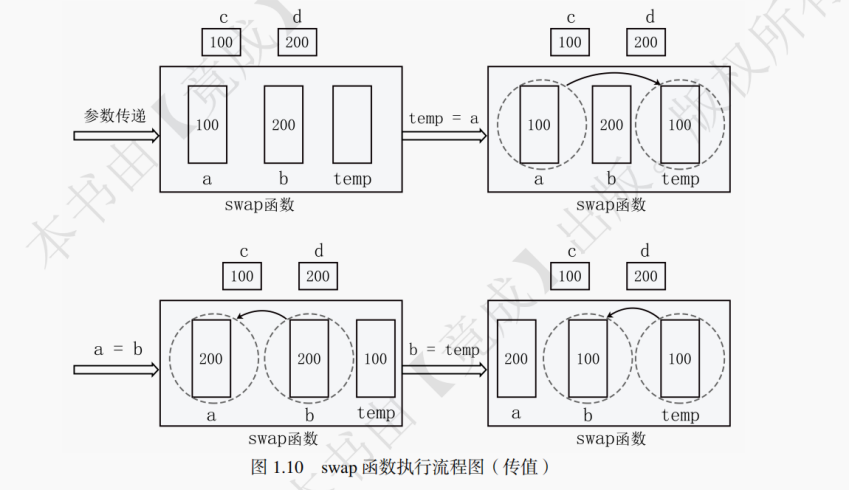
如果要设计一个 swap 函数,用于交换两个 int 型整数 c 和 d 的值,该如何设计呢?下面用 swap 函数的例子,分别介绍传值、传指针(传地址)和传引用。1.传值
初学者可能会写出这样的代码:
void swap(int a, int b) {int temp; // temp用于暂存a的值temp = a; // 暂存a的值a = b; // 把b的值赋给ab = temp; // 把temp中暂存的a的值赋给b }但不幸的是,这样的函数并不能真正完成交换两个变量的值的功能。考虑这样一种情况,初始情况下变量 c 的值为 100,变量 d 的值为 200。当在 main 函数中调用此函数来交换变量 c 和变量 d 的值时,会在函数内部重新创建两个变量 a 和 b 用于存储实参传递过来的值,这两个函数内部的变量只是外部实参的一个拷贝,而后的操作都是对这两个拷贝的操作,并不会影响到外部的实参。
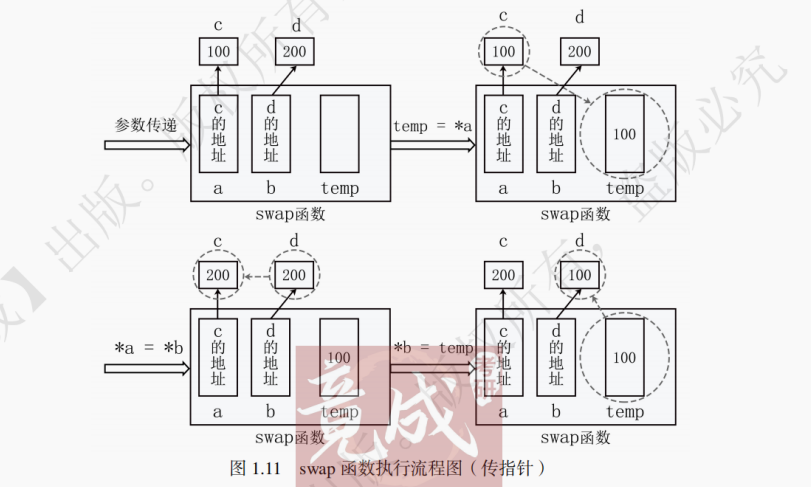
2.传指针 (传地址)
传指针(传地址)指的是在参数传递时传递的不是欲交换的数值,而是其地址。在 swap 函数中,形参为两个指针变量 a 和 b,当函数被调用时,传递给形参 a 和 b 的值为实参 c 和 d 的地址,于是,a 和 b 就变成了分别指向 c 和 d 的指针变量。通过对指针变量执行解引用操作(如 * a),就可以直接影响到指针指向变量的值,这就是在传地址方式中调用函数对实参进行操作的本质所在。
传指针的代码如下:void swap(int *a, int *b) { // 函数定义int temp;temp = *a;*a = *b;*b = temp; } swap(&c, &d); // 函数调用3.传引用
C++ 还提供了传引用这种参数传递方式,传引用能够达到和传指针同样的效果。所谓引用,是给已存在变量取一个别名,通过这个别名和原来的名称都能够找到这份数据。定义引用类型的格式类似于定义指针的格式,只是用 “&” 取代了 “”,例如:
数据类型 & 引用变量名 (对象名) = 引用实体;
注意:这里 “&” 的位置与定义指针时 “” 的位置一样,都是自由的。并且,传引用在形参定义时需添加 “&”,在函数内使用形参时,将其作为一个普通数据类型的变量进行相关操作即可。除此之外,“&” 还可以用于取地址操作以及位操作中的与运算。
在 C++ 内部,引用的本质是一个指针常量,它指向的内存地址不会发生变化,即形参的内存地址与实参的内存地址保持一致,但内存地址对应的存储单元中的值可以发生变化。故引用一经定义,就无法改变指向,但可以通过引用修改形参的数值。