R语言学习--Day07--T分布与T检验
昨天我们介绍了R中用于对数据进行分类的聚类分析的方法,接下来我们来看T分布。
T分布
T分布适用于帮我们估计整组数据(较小的数据量,一般小于30)的真实值在哪一个区间,具体是计算置信区间(一般为95%),即有95%的把握真实值落在某个区间内。
首先,我们生成一组数据集来计算T分布的置信区间
# 生成模拟数据集(10个样本)
set.seed(123) # 固定随机种子,确保结果可复现
blood_pressure_reduction <- rt(n = 10, df = 9) + 5 # 生成T分布数据,均值≈5
blood_pressure_reduction <- round(blood_pressure_reduction, 1) # 保留1位小数# 查看数据
print(blood_pressure_reduction)# 计算均值、标准差、标准误
mean_bp <- mean(blood_pressure_reduction)
sd_bp <- sd(blood_pressure_reduction)
n <- length(blood_pressure_reduction)
se_bp <- sd_bp / sqrt(n) # 标准误 = 标准差/√n# 计算95%置信区间(T分布临界值)
t_critical <- qt(p = 0.975, df = n - 1) # 双尾检验,α=0.05
lower_ci <- mean_bp - t_critical * se_bp
upper_ci <- mean_bp + t_critical * se_bp# 输出结果
cat("均值:", mean_bp, "\n")
cat("95% 置信区间: [", lower_ci, ",", upper_ci, "]")# 生成T分布和正态分布的曲线
x <- seq(-4, 4, by = 0.01)
t_dist <- dt(x, df = 9)
normal_dist <- dnorm(x)# 绘制图形
ggplot(data.frame(x, t_dist, normal_dist), aes(x)) +geom_line(aes(y = t_dist, color = "T分布 (df=9)"), linewidth = 1) +geom_line(aes(y = normal_dist, color = "标准正态分布"), linetype = "dashed") +labs(title = "T分布 vs 正态分布", y = "概率密度", color = "分布类型") +theme_minimal()输出:
[1] 4.4 3.6 4.9 3.4 6.6 7.4 5.3 6.0 4.0 4.7
均值: 5.03
95% 置信区间: [ 4.094823 , 5.965177 ]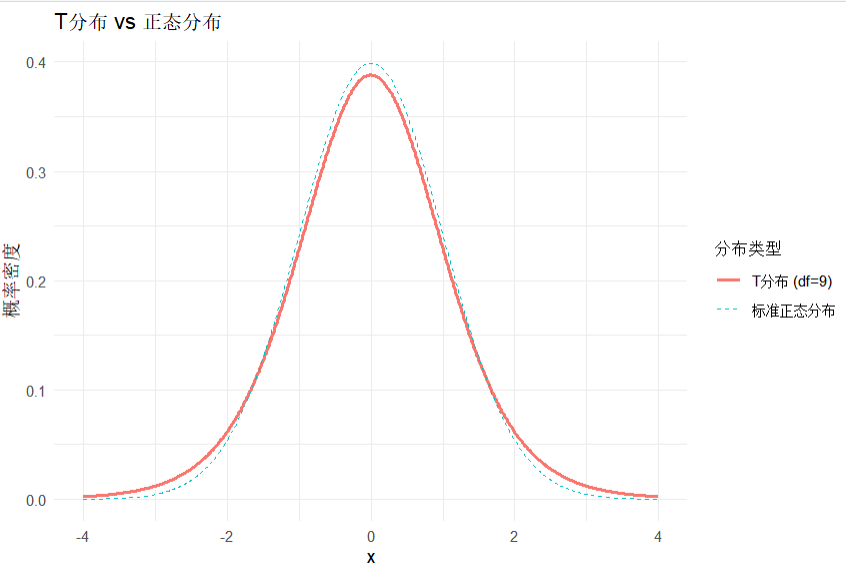
从输出的图片可以看到,相比较正态分布,T分布为尾部更加高一些。
当然了,每个第一次看T分布使用方法都会有一个疑惑:既然数据量这么少,为什么我不直接计算均值,从而更好地把数据点放在一个值上,而不是一个区间。其实,计算T分布的置信区间,可以帮我们排除异常数据。假设我们在接收到数据的时候,直接计算均值,那么如果有异常数据的存在,所计算的均值可能会比较离谱,而异常数据这个错误点则会被隐藏起来。而如果我们计算置信区间后,我们可以将每个数据点与置信区间做对比,假如发现某个或某些数据离置信区间比较远,那么我们就需要把这些点单独摘出来处理,从而有效地在数据层面避免了计算错误。
当然了,使用T分布也是要有前置条件的:
1、数据本身不能过于极端地偏向一边,简单来说就是数据是需要接近正态分布,对称性较高;
2、数据点之间需要相互独立,即数据之间没有相关性,像验证某种药物对血压的影响,所用的样本就应该是20多个不同患者的血压,而不是同一个患者连续测量20次的血压。
既然提到了T分布,就不得不提一个名字很相近的T检验了。
T检验
T检验一般是用于比较两组之间差异并验证这个差异是否是偶然发生的,简单来说,套用在应用场景上就是,比如我们想比较应用某种降压药前后病人的血压变化是否是真实的(即由于服用药物造成的),还是只是偶然的血压变化。
在计算时,我们会将两组数据的均值求出来,再计算每组数据自身的波动值(通过标准差除以样本个数的开平方),将均值相减再除以波动值,如果小于0.05,就代表这种差异是真实的。
像之前一样,我们还是生成数据来演示这一过程:
set.seed(123) drug_A <- rnorm(n = 20, mean = 10, sd = 3)drug_B <- rnorm(n = 20, mean = 12, sd = 3)# 合并为数据框
data <- data.frame(group = rep(c("A药", "B药"), each = 20),effect = c(drug_A, drug_B)
)ggplot(data, aes(x = group, y = effect, fill = group)) +geom_boxplot() +labs(title = "两种药物的降压效果对比", x = "药物组", y = "收缩压降低值 (mmHg)")t_test_result <- t.test(effect ~ group, data = data)
print(t_test_result)输出:
Welch Two Sample t-testdata: effect by group
t = -1.6571, df = 37.082, p-value = 0.1059
alternative hypothesis: true difference in means between group A药 and group B药 is not equal to 0
95 percent confidence interval:-3.159146 0.316432
sample estimates:
mean in group A药 mean in group B药 10.42487 11.84623 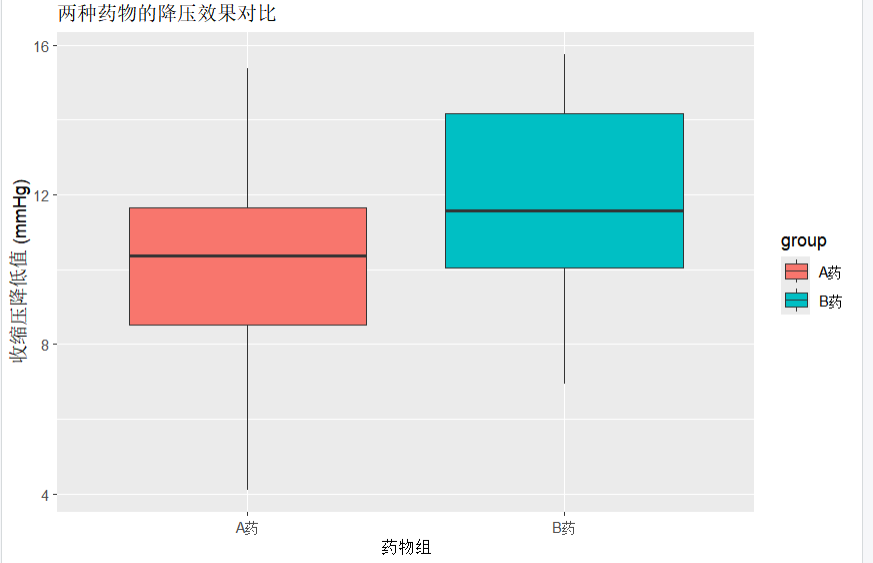
从结果可以看到,t值为-2.34,说明B药的均值大于A药;p值为0.024 ,小于等于0.05,从而得出结论:B药的降压效果显著优于A药(均值差约1.92mmHg,95%置信区间[0.28, 3.88])。