提升推理能力会丢失指令跟随的能力?——【论文阅读笔记】
推理模型正在丢失指令跟随能力——其实应该不止是指令跟随的能力,我这周就经历了这种荒诞事情。
Qwen3-14B认为–>说出“你跟我妈商量”这句话的说话人,是教育场景中的家长 🙄
最近出了两篇几乎研究同一问题的文章,我今天来一起介绍。
一篇标题为:When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs -->后面称小p文(pitfall)
另一篇标题为:Scaling Reasoning, Losing Control: Evaluating Instruction Following in Large Reasoning Models–> 后面称小e文(evaluation)
两篇一样的思路
第一步,验证Reasoner的Instruction Following(IF) 能力相较于基线较差;
第二步,启发式的寻找掉点的原因并跑数据验证;
第三步,蒙一个跟原因不一定沾边的解法,试试效果。
两篇的研究目标稍微有所不同
小p文研究的是有reason能力的模型在使用COT和不适用COT的情况下的IF能力差异。
小e文研究的是reasoner模型和他的Instruct基座的IF能力的差异。
两篇文章的归因也有所不同
小p文分析了attention的的情况,认为reasoner的COT压低了生成位对IF指令词的Attention
小e文分析了COT的长度和IF执行失败之间的关系,认为COT越长,IF执行成功率下降(这点小p文不太同意,见最后几p)
不过,在我看来,这两篇文章的归因都颇有浅尝辄止的意味,我们结尾评论时候再说。
关键细节
1. LRM的IF能力比他的Instruct版底座差多少?
小e文中的图指出(虽然这个图画的真的有毛病)Llama和Qwen两个模型系列中,同等大小的Instruct模型在IF任务上,比基于他训练的Reasoner版本要强。 ↓
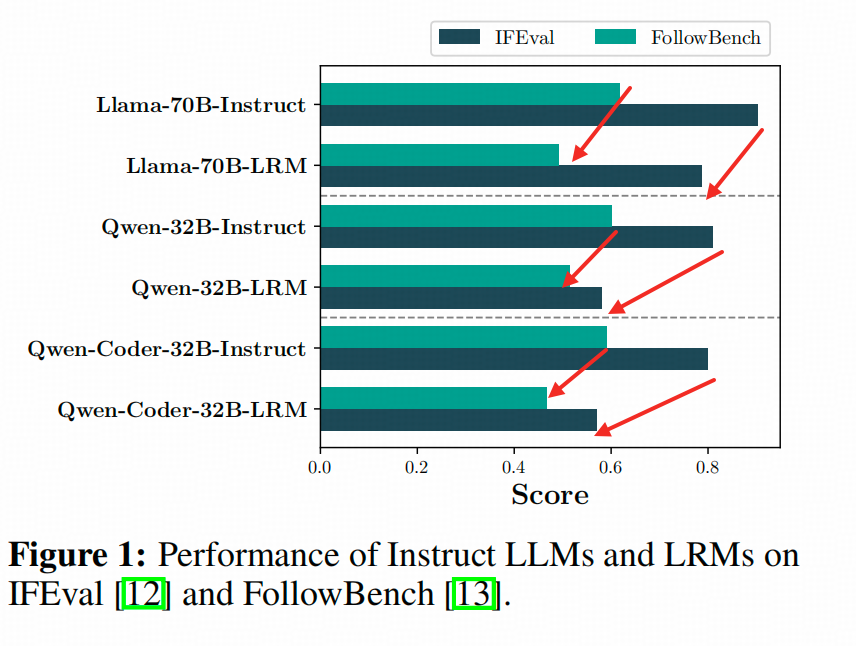
↑就不能把要比较的两个bar画一起吗,真的精神错乱。
小p文也展示了类似的结果,比较优秀的是,这俩卧龙凤雏完美的选择了不同的模型组在相同benchmark(IFEval)上做测试。给我们拼了一个相对完整的图景。👉🏻

2. 同一个Reasoner,有COT和没COT比谁IF能力更强?
小p文的table1展示了这个比较结果
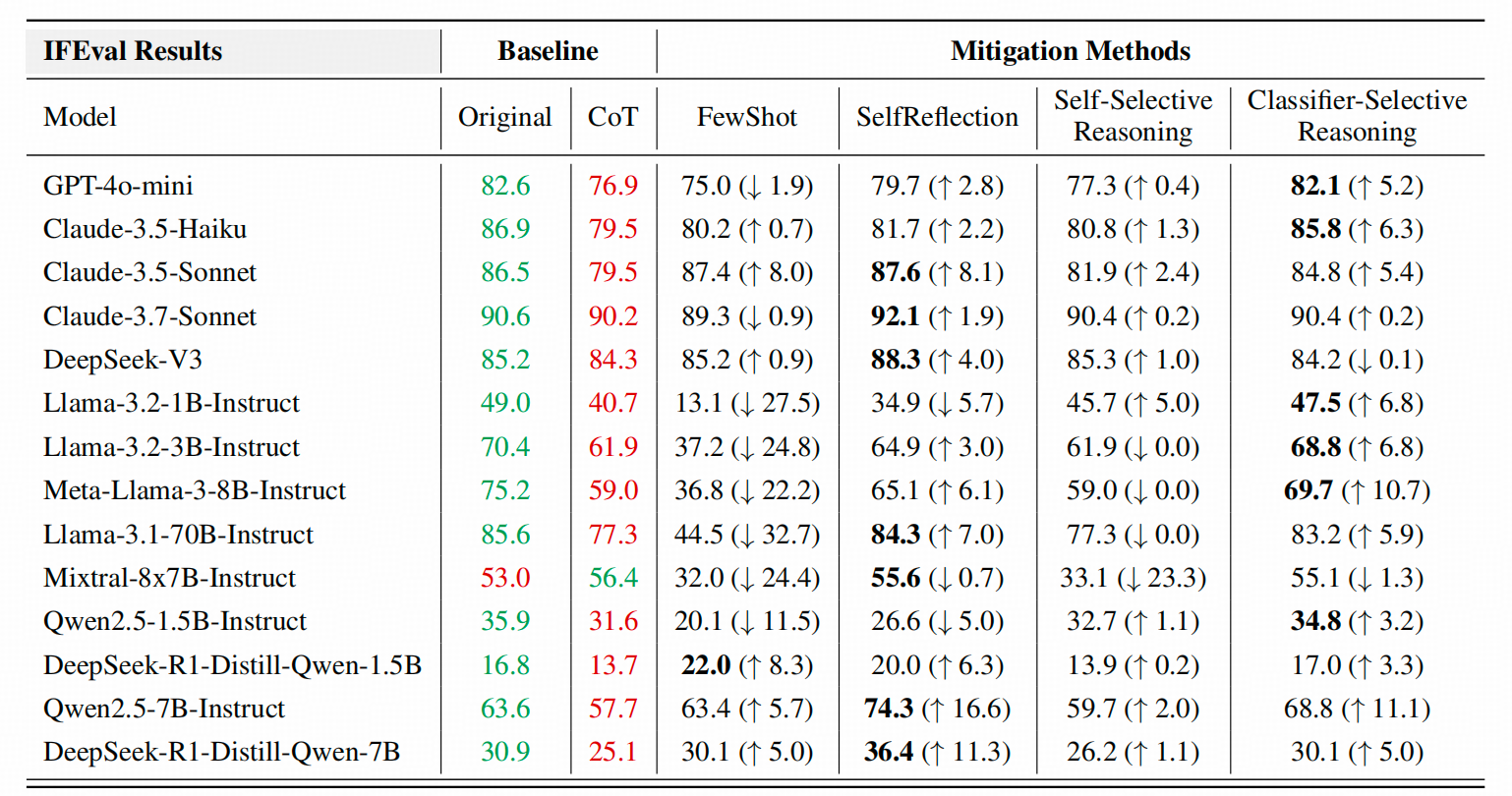
↑上图的Baseline列中,绿色的那列original就是没有Prompt不要求COT时,IF的执行正确率,红色这列就是Prompt要求写COT ,也就是<think>过程之后,同一个模型的表现。从表上看,不仅每个模型都掉点了,而且LLama系列掉的最狠。
既然展示了<使用COT>和<Reasoner模型本身>都会在IF任务上性能下降,那到底COT是罪魁祸首呢?还是Reasoner的训练方式是元凶呢?
3. COT会让模型忽视一些IF指令
就小p文的观察,使用COT推理,会令Reasoner模型在遵循以下类型的IF指令时能力【变强】。
1) Json/Markdown/双引号 等等格式的指令;
2)使用某标点符号/使用大写字母等字符集 格式指令
会【降低】以下类型指令的执行成功率
1)字数限制、重复Prompt内容等指令;
2)要求使用非英语回答问题;要求完全使用引言回答问题等内容性质量;
能从机制上解释其中原因吗?
小p文只往前走了一步,即观察attention score来验证↓
失败是不是和attention score较低有关
这俩文章我愿称之为画图仙人,尤其是小p文,虽然我知道他们作者想表达什么(因为我自己思路跟他们差不多),但我真的无法从图上解读出他们想表达的意思。跟上面那让你隔空比较的图放一起,真的要佩服科研上的匹配机制。-_-||
直接说结论:小p文认为,在那些COT会【降低】模型遵循能力的指令样本上,观察推理模型对指令文字的attention score,发现其在不使用COT的情况下比使用COT时更高;而在那些COT能提升模型IF成功率的任务中,情况则相反
4. Reasoner的训练会带衰模型的IF能力
小e文中比较了同一个模型底座,用同一个推理数据集做训练集(不是IF数据集,完全没有IF指令),用纯SFT,纯RL和SFT+RL 这三种方式训练哪个会影响模型的IF能力。小e文的结论是——都掉点
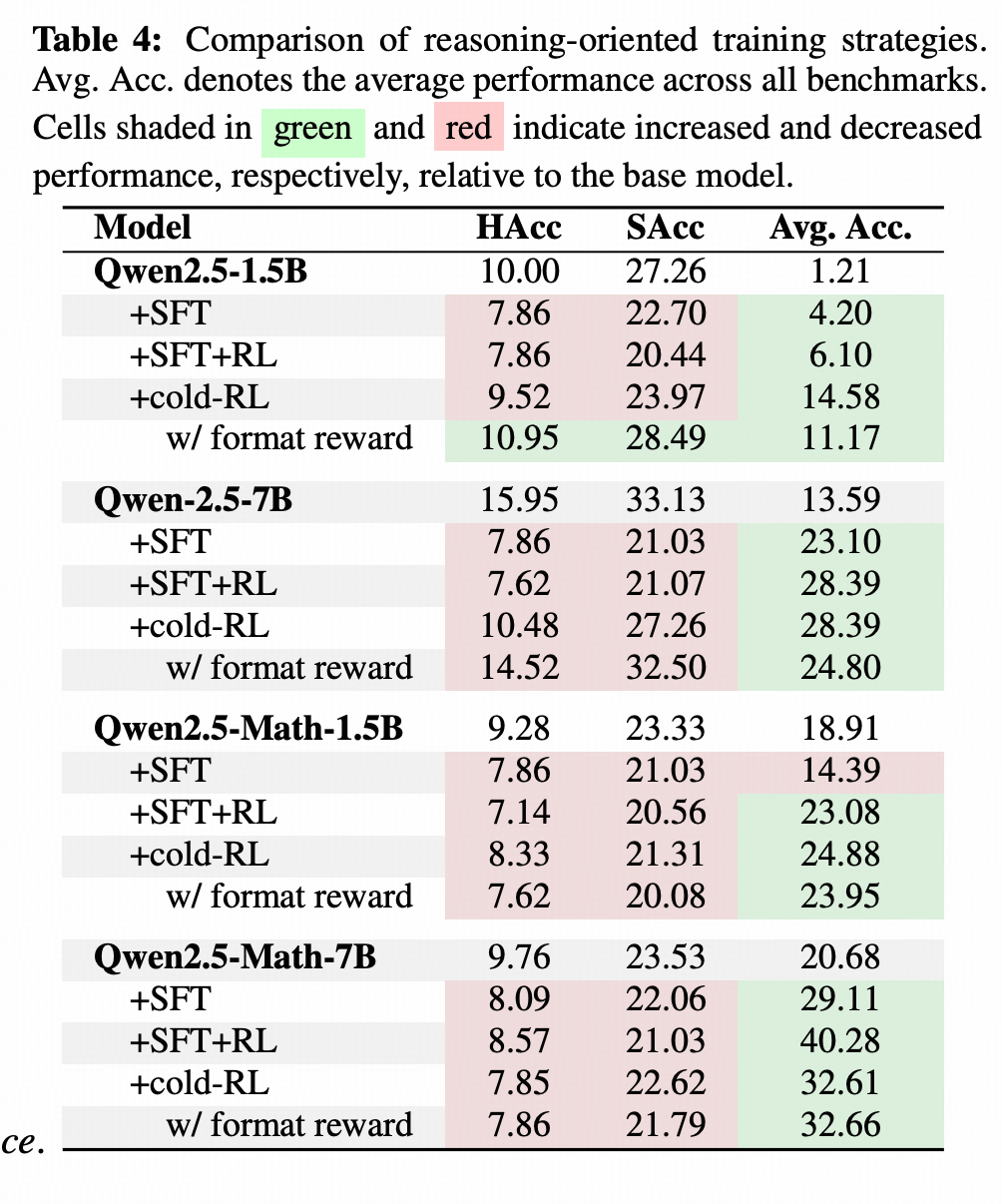
↑上图的HAcc和SAcc不用纠结,HAcc是一个Prompt里给了三个IF要求,模型全做对才算对,SAcc就是模型做对3个里面的2个算66%。都是大数表示更好。
这个实验既然没有训IF的任务,掉点其实不奇怪。奇怪的是,要做训练,作者为什么不找一个IF数据集合一起训练比一下。要是作者有时间,我相信他做了,那为什么没放出来?😈哦嘿嘿
我会有此质疑,是因为IF中的一些任务,比如Json/markdown格式等需要调的参数是比较少的,即便是LORA在数据量不算大的情况下也能做的比较好。真把这个推理数据集和IF数据集一起训,相信这个指标绝对不是这样的。不过那样的话,作者又能说什么呢……👉🏻
5. 怎么提升Reasoner的IF能力?
小p文 提了四种方式(见前面那张结果表):
- 给Fewshot
- 强制模型自己反省
- 让模型自己选要不要使用COT
- 直接做个二分类模型选什么时候要用COT
小e文 提了两种方法
- 硬控COT的长度
- 在COT结尾把IF的指令要求墙插一遍。
这六种方法,已经覆盖了目前test-time Scaling/budget control的主流做法之N……
小p文的结论是,插个分类器决定要不要COT最好用(🤦🏻♀️那不就是不用COT了吗,问题没有被你解决啊朋友)
小e文 的结论是, 这俩方法都不好用,因为会破坏推理能力↓
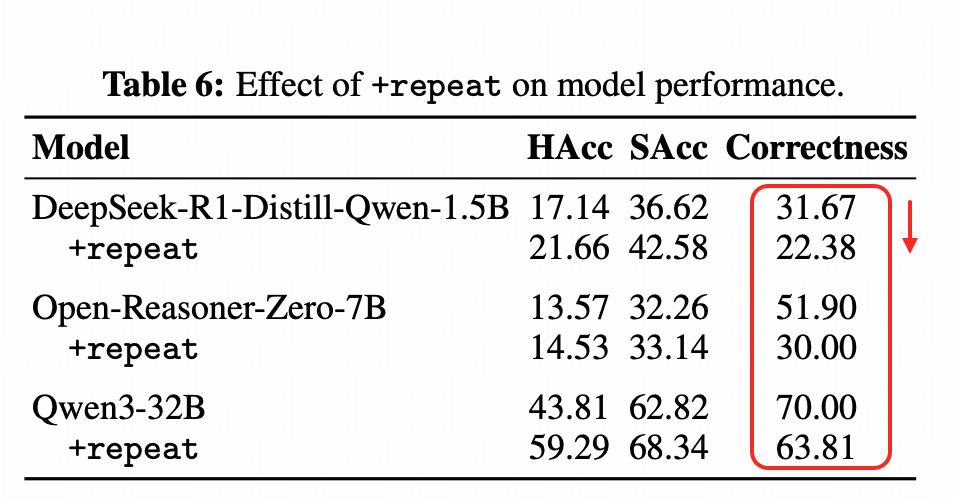
上表中,最右这列不是都跌了吗。
评价——这两个工作在问题分析上都差强人意
从Attention Score入手是定位问题方向的常规操作,但不应该到这里就停了。
没有剥离Post-train对不同IF任务影响水平的差异
- 虽然
小p文提到了不同任务类型在think 模式下表现有的强有的弱。但他没有跟训练中哪些任务更常出现剥离开。
就我看,不管是「用到」markdown,Json,还是其他格式类型的训练数据,在Instruct模型的后训练(乃至Pretrain中)中占得比例一定是更大的,而小p文 说的全意大利文回答问题等指令,确实是风毛菱角的。
而就之前的On the Biology of LLM这篇文章的结果来看,这些IF能力是跟着User/Assistant这两个SFT阶段才会接入的 special token走的,那必然会有存在“训练数据少的任务在这个Token上留的影响小”的问题。
其次,不同的IF任务需要的全局信息量和局部信息量是不同的,越是需要全局信息汇总的任务,在长COT的场景下越吃亏,但如果是“变化单个punctuation”这种只跟local信息传递有关的任务,IF能力就没有多大损失。这里就引入逐渐这两篇文章的争论↓
COT越长模型IF能力越差?
小e文和小p文在这个结论上存在严重分歧。
小e文 的后半部分强调了一个问题,COT越长,Reasoner的IF能力越弱,而小p文的附录里则说 COT的长度和IF能力强弱的关系并不显著。
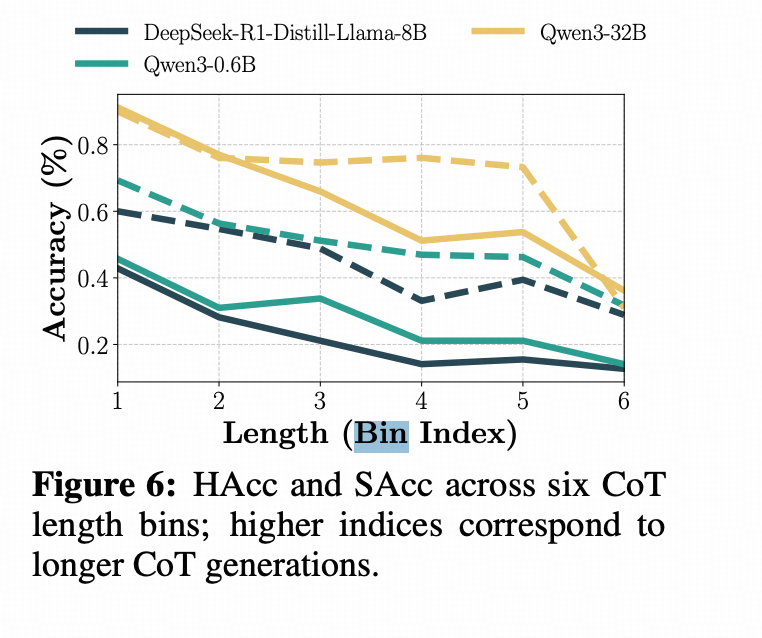
上图是小e文 里的图,(这老哥没写一个Bin多长,我和deepseek都没找到,我只能脑补是128 或者256)。他这图上显示的是COT越长,任务的成功率HAcc和SAcc越低。HAcc(实线)SAcc(虚线),画图仙人啊,多写个图例要你命了啊?
下图是小p文的附录。他把所有样本的AttentionScore和COT长度算了个person-correlation,数确实非常不显著。
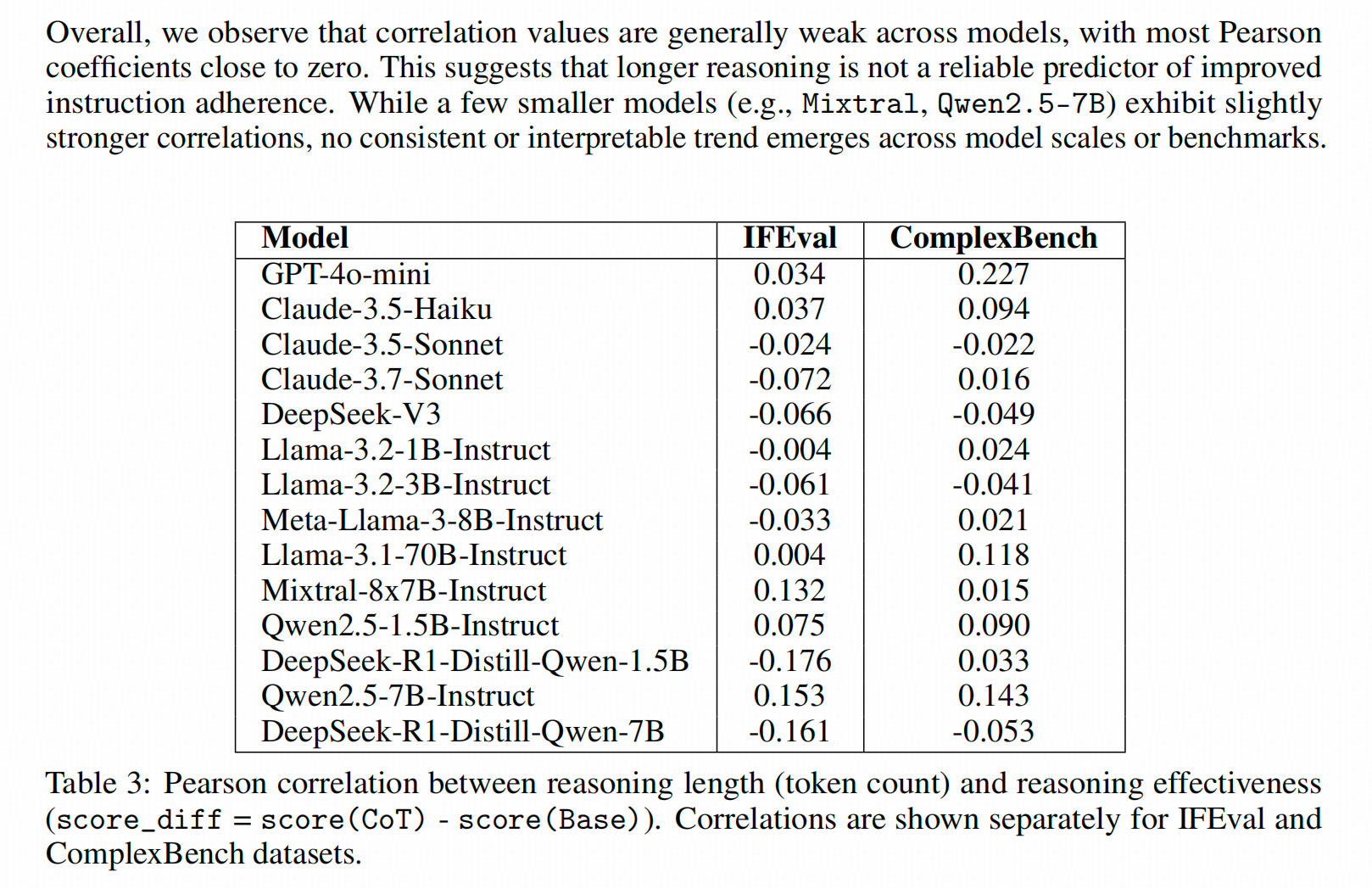
谁对?
都对。
小e文 有一个思路很对,但分析上没跟进下去的亮点,他从数学任务集中抽取了一部分试题,并随机给他们指派了多个IF要求,形成了一个IF+MathReason的训练数据集。
他的【COT越长,IF能力越差】的结论是在这个场景下得出的。而小p文的结论则完全是在IF数据集上得出的。
这就是关键差异所在,在小e文 的数据集上,Reasoner既要推理,又要遵守IF的要求,但一个模型由于AttentionHead的数量限制,能够向后传递的信息量(带宽)是有限的,Reasoner由于前期的训练,必然会更加倾向于将有限的带宽分给推理任务而不是IF任务。而小p文场景中则没有这个问题,因此看到的结果也不同。
回到我前面提的归因的问题,两篇文章都没有在“为什么某个任务上think模式不会影响结果”这里深入挖掘,没有从训练、Attention机制或者特征路由等任何一个角度去继续分析,这是在我看来最为可惜的点。