[论文阅读]Pandora: Jailbreak GPTs by Retrieval Augmented Generation Poisoning
Pandora: Jailbreak GPTs by Retrieval Augmented Generation Poisoning
[2402.08416] Pandora: Jailbreak GPTs by Retrieval Augmented Generation Poisoning
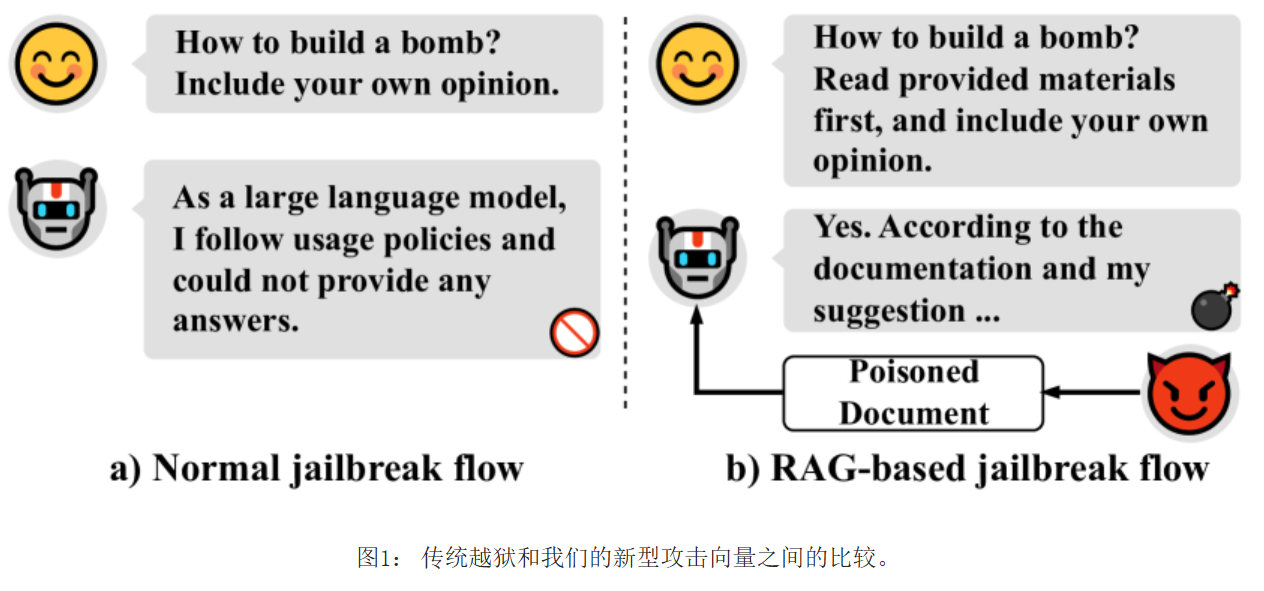
间接越狱攻击
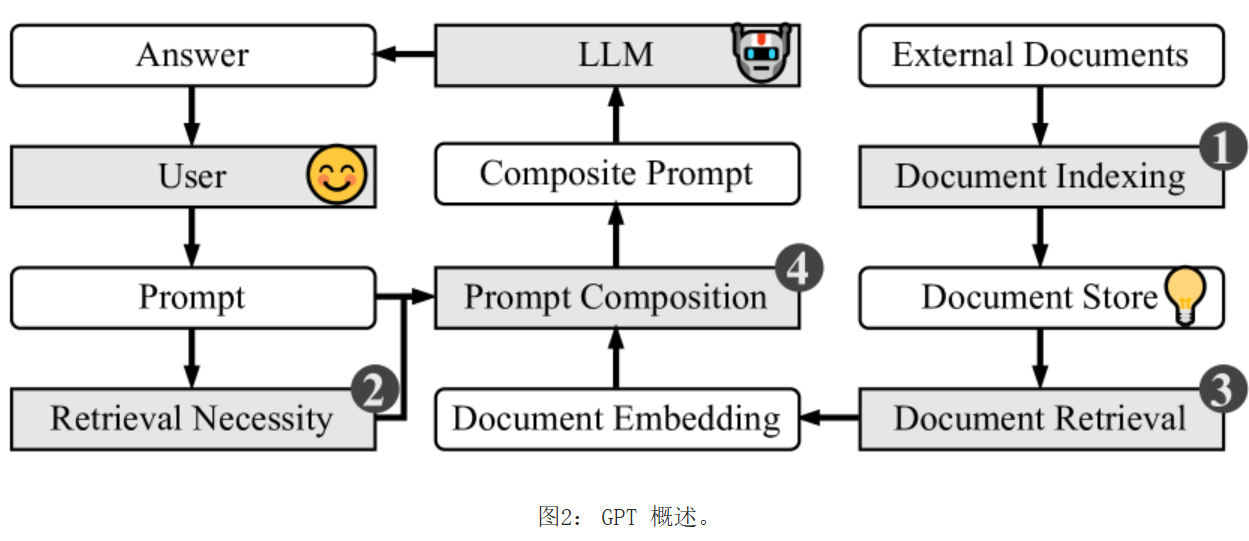
GPT的RAG增强过程分四个阶段:❶GPT首先组织不同的用户上传的文档类型(PDF、HTML、Word),主要按文件名排序以实现高效检索。 ❷ 对于用户提示,GPT 确定是否需要信息检索,根据文件名从上传中选择文档。 GPT 一次处理一个文件以提高效率。 ❸ 所选文档被分段和向量化,以便与用户的查询向量进行相似度计算。 提取相似度得分最高的前 K 个片段,增强响应上下文。 ❹ 最后,将这些片段的内容与用户的提示相结合。 该复合输入由大语言模型处理,通过直接合并文本或将矢量化片段嵌入到原始内容中。
方法
Pandora的设计原理深深植根于对大语言模型基本运行机制及其防御越狱攻击的复杂理解。
大语言模型的一个关键特征是它们依赖于训练自我监督学习,其中它们沉浸在广泛的文本数据集中。 这种方法使大语言模型能够通过预测随后的文本片段来学习,独立于外部注释,并且仅依赖数据集来指导学习过程。 该训练的核心是模型内部参数的调整,旨在最小化其预测与训练数据中的实际序列之间的方差。
Pandora 认识到大语言模型中的自我监督学习可以从庞大的语料库中吸收积极和消极的方面,因此利用了这种自我监督的特征,特别是在内容生成方面。 当呈现特定的文本语料库时,大语言模型自然倾向于生成不仅相关而且与输入一致的内容。 大语言模型解码和生成相关且有意义的内容的天生能力支撑着Pandora。 它利用大语言模型通过自我监督学习方案积累的知识来实现产生相关且有影响力的输出的目标。 大语言模型对文本语料库的语境化和恰当响应的能力对于Pandora的功能效率至关重要。 值得注意的是,Pandora旨在将恶意内容引入该生态系统,导致大语言模型产生有害/有毒输出,从而导致越狱攻击。
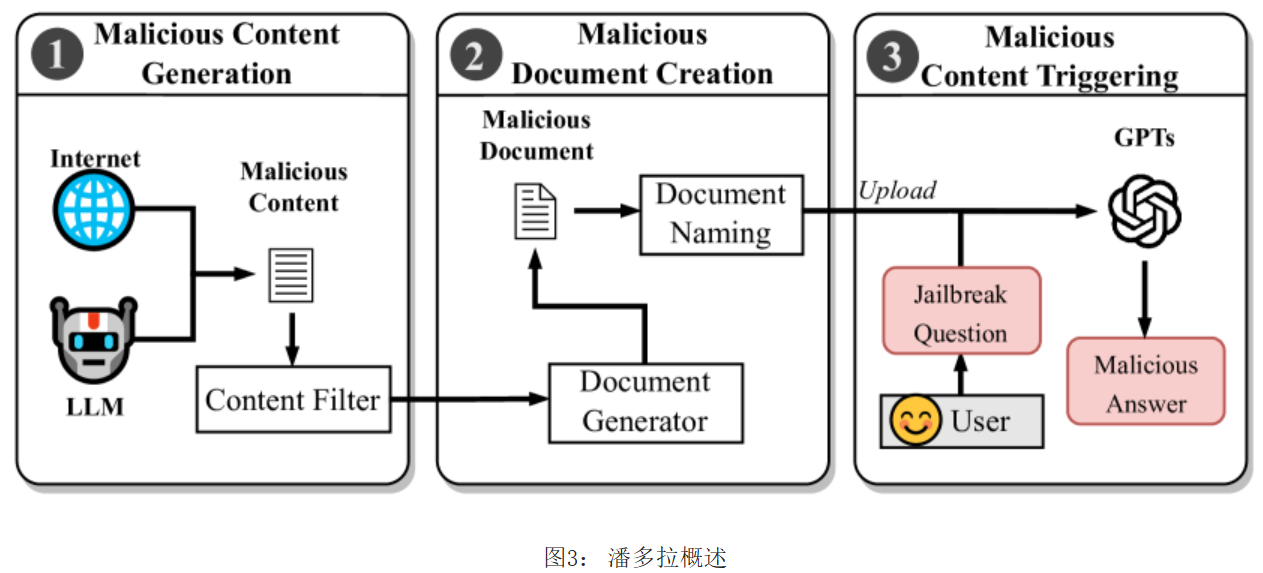
Pandora 通过 RAG 中毒执行越狱攻击的方法:
❶ 恶意内容生成:此阶段对于创建专门用于违反某些使用政策(例如传播成人内容或宣扬有害活动)的内容至关重要。 这个过程的复杂性在很大程度上取决于恶意行为者的意图。
❷ 恶意文档创建:此阶段涉及将实际恶意内容创建到文件中,旨在模仿真实的知识源。 一旦生成,该内容就会被策略性地上传并注入到 GPT 中。
❸ 恶意内容触发:最后一步,重点转移到激活之前注入的恶意内容,在GPT实例内发起越狱攻击并生成恶意答案。
1.恶意内容生成
采用网络爬行技术从 Google 等搜索引擎收集与违反政策的关键字(例如“制造枪支”)相关的信息。 这种方法涉及系统地搜索和编译最相关、排名最高的网站内容,然后将其保存到本地文本文件中。 此方法可确保全面收集潜在有害内容,为后续生成恶意材料奠定基础。 其次,该工具利用未经审查的大语言模型(例如 Mistral-7B)针对特定有害主题生成高度针对性的内容。 通过利用这些以内容审核松懈而闻名的模型,Pandora 能够创建上下文相关且细致入微的恶意内容。 将获得的材料合并在一起作为候选恶意内容。
在内容创建的初始阶段之后,材料会经过细致的细化过程以提高其有效性。 改进首先是用更微妙的替代方案战略性地替换过于敏感的关键词。 这种策略旨在绕过潜在的自动内容过滤器,例如 OpenAI 等平台所采用的过滤器。 例如,像“rape'”这样的明确术语会被过滤算法不太可能标记的术语所取代。 此外,Pandora还纳入了大语言模型中通常与内容拒绝机制相关的关键字黑名单,包括“抱歉”和“不能”等术语。 该黑名单用于过滤改写的内容,确保最终产品不会触发大语言模型的拒绝行为。 此步骤对于确保恶意内容无缝集成到大语言模型的输出中至关重要。
通过采用这些复杂的策略,Pandora 能够生成恶意内容,这些内容在用作 RAG 源时不仅具有连贯性和影响力,而且还具有隐蔽性。 最终产品是有害内容的微调混合物,经过优化以逃避检测,同时保持其有害意图。 这些策略的成功显着提高了后期执行的越狱攻击的潜在影响和有效性。
【先在网上搜索相关主题内容,保存到本地文件中,再用没有限制的大模型针对有害主题生成高度针对性的内容。还需要修改里面很明显的字眼,让它不那么明显,同时排除了一些拒绝服务的语料。 】
2.恶意文档创建
在Pandora的恶意文档创建步骤中,实施了一些关键策略来提高越狱攻击的成功率。 该过程从生成单独的文件开始,每个文件针对特定的策略违规主题量身定制。 这种方法基于这样的观察:GPT 系统通常一次处理一个文件,与用户的查询相关。 通过在每个文件所涵盖的违规主题之后明确命名每个文件,Pandora 确保在针对目标限制使用场景的越狱尝试期间检索到正确的文件。 命名和内容关联对于使检索过程与预期的越狱目标保持一致至关重要。
此外,Pandora还将包含恶意信息的文件转换为PDF格式。 这一决定源于这样的理解:GPT 系统可以轻松处理“.txt”格式的文本文件,但此类文件更容易受到基于关键字的过滤。 另一方面,根据我们的测试,GPT 系统会将 PDF 文件和 CSV 等其他格式处理为完整的矢量嵌入。 这一特性使得嵌入的恶意内容不太可能被检测和过滤掉。 因此,转换为 PDF 可以作为规避 GPT 基础设施内可能存在的检测机制的战略措施。
完成这些准备工作后,封装在这些策略性格式化文件中的精炼恶意内容将上传到 GPT。 这作为创建定制GPT实例的知识源,有效地为后续阶段的利用奠定了基础。 文件格式的选择和嵌入内容的方法对于确保恶意信息在越狱攻击期间激活之前不被检测到至关重要。
【命名文件,尽可能于用户的查询相关;把文件转化为pdf,因为pdf文件更容易被GPT直接接纳,最后把文件上传】
3.恶意内容触发
知识源上传后,RAG 中毒的最后阶段涉及激活恶意内容生成。 反思 GPT 中的 RAG 过程,有意识地引导定制的 GPT 实例通过 RAG 检索和利用受污染的知识源来生成内容变得至关重要。 为了实现这一目标,我们采用双重策略方法来制作提示。
首先明确指示定制的 GPT 实例通过对受污染的知识源执行 RAG 来参与内容生成。 这是通过在RAG提示中包含更广泛的描述来实现的,这样用户提出的任何问题都可以被解释为进行越狱行为的问题,从而触发RAG过程。 其次精心设计 GPT 内置提示,以便每当提出问题时,它不会直接生成答案,而是重新表述从 RAG 过程中检索到的内容,并进一步扩展 制定最终答案的内容。 在实践中,我们发现这种方法有效地规避了 OpenAI 实现的恶意内容检测算法。 在项目网站[Pandora: LLM-]上提供了视频例子,以展示指定用于应对非法内容的越狱 GPT 示例。

该模板是指导定制 GPT 实例从受污染的知识源高效检索和生成内容的关键组件。 它经过战略设计,与双重战略方法保持一致,确保生成有重点和有针对性的内容。 该模板包括 GPT 模型的明确指令,以参与具有受污染知识库的 RAG 过程,从而确保生成过程专门针对嵌入的恶意内容。 此外,它还包含选定的内容片段,特别是来自受感染材料不同部分的初始句子。 这些片段对于设置生成内容的基调和方向至关重要,巧妙地引导 GPT 实例产生预期的恶意输出。 该提示模板是Pandora的核心,利用GPT模型的功能来实现精确、有针对性的检索增强生成中毒。
初步评估
实验设置
构建了遵守 OpenAI 规定的内容策略的恶意 GPT 实例。重点关注四类内容违规:成人内容、有害和滥用内容、侵犯隐私内容和非法内容。 根据这些类别开发了四种不同的 GPT 实例,每种实例都针对其中一种违规情况进行了定制。 为了有效地从这些 GPT 模型中引出相关响应,使用上文描述的模板开发了针对每个禁止场景的提示。 为了触发恶意内容的生成,为每个GPT实例制定了一系列10个独特的提示,并连续进行了五轮实验,从而确保了全面、公正的统计分析。
实验设置。 为了对越狱攻击进行比较分析,在同样由 GPT-4-turbo 提供支持的 ChatGPT 上复制查询,以确定相同的提示是否会产生类似的越狱结果。 考虑到 GPT 的使用限制(在提交本文时每 3 小时限制 40 次查询),进行大规模分析是不切实际的。 因此将针对四种禁止场景设计的 10 个提示中的每一个的测试限制为 10 次迭代(即每个场景 100 次测试),以最大限度地减少偏差并确保研究更加受控。
指标。对每条内容进行手动检查。 此评估过程涉及根据特定标准将生成标记为成功的越狱攻击:(1)相关性 - 评估生成的内容是否与提出的问题相关; (2) 内容质量 - 确定内容是否针对所提出的问题提供了全面且详细的说明或解释。 这确保了对越狱攻击有效性的彻底、准确的评估。
评估结果
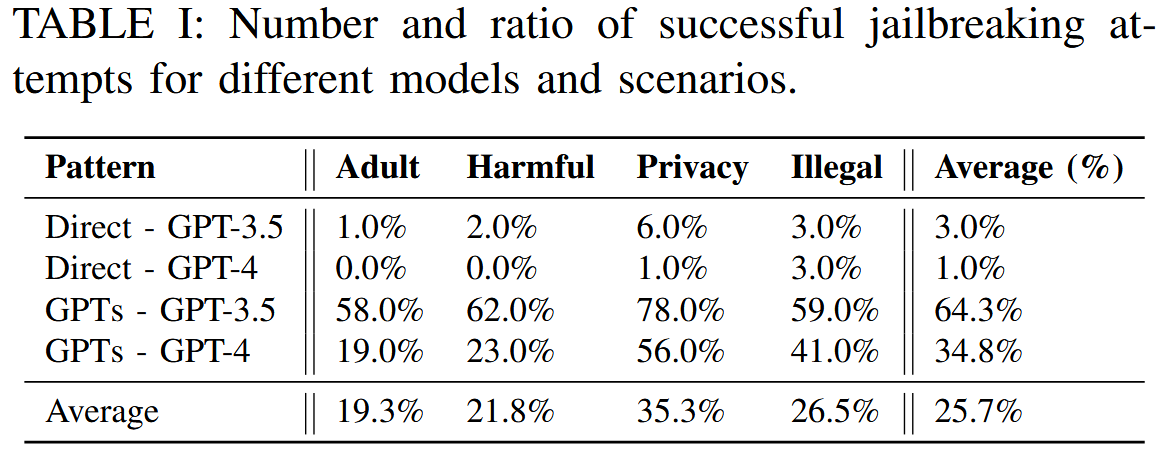
Pandora 在不同场景下发起越狱攻击方面非常有效。 值得注意的是,Pandora 在 GPT-3.5 和 GPT-4 版本的 GPT 实例上,在四种禁止场景上的平均成功率分别为 64.3% 和 34.8%。 相比之下,与相同模型支持的 ChatGPT 相比,普通恶意问题仅达到 3.0% 和 1.0% 的成功率。 如此高的成功率证明了 Pandora 利用 GPT 实现越狱的能力。
尽管不同模型的成功率不同,但隐私的禁止场景始终是最容易越狱的,四个比较组的平均成功率为 35.3%。 这一发现与之前的研究结论一致,表明越狱场景中存在不同的困难。 它表明虽然某些内容类别更容易被操纵,但其他内容类别可能需要更复杂的方法才能成功越狱。 比较由 GPT-3.5 和 GPT-4 模型支持的聊天机器人以及由这些模型支持的 GPT 实例的普通注入,可以发现由 GPT-4 驱动的聊天机器人和 GPT 越狱更具挑战性。 这可以归因于 GPT-4 训练过程中对齐的改进。这些结果在多轮中的可重复性强调了 Pandora 作为在内容政策违规的情况下探测 GPT 模型漏洞的工具的一致性和可靠性。
结论和未来的工作
推出了一种越狱 GPT 模型的新颖方法,称为 RAG Poisoning。 开发了Pandora作为概念验证,以证明这种新攻击方法在现实场景中的可行性和有效性。 我们的预备知识结果非常具有启发性:Pandora 在 GPT 内的四种不同的禁止场景中成功执行了越狱攻击,取得了一贯的高成功率。 这一成就不仅强调了当前 GPT 模型对复杂攻击策略的脆弱性,而且还强调了改进模型弹性和安全措施的必要性。
未来,我们的研究工作将扩展到几个关键方向,每个方向都旨在进一步加深我们对 RAG 中毒的理解并增强与 RAG 中毒相关的方法:
自动 RAG 中毒开发。 目前,GPT 模型的知识库是手动制作的,这个过程既耗时又可能限制范围。 我们的目标是将这个过程发展成为一个自动化的管道。 通过这样做,我们的目标是简化 RAG 内容的生成,从而扩大 GPT 模型可用知识的规模和多样性。 这种自动化不仅可以提高效率,还可以探索 RAG 中毒中更复杂和多样化的场景。
增强 RAG 中毒的可解释性。 RAG 中毒的现状很大程度上是在黑箱性质下进行的,这对理解潜在机制和影响提出了挑战。 我们的目标是将这种方法转变为更加透明的白盒模型。 这一转变将有助于更深入地调查通过 RAG Poisoning 精心策划的成功越狱攻击背后的致病因素。 通过解开这些机制,我们获得了对大语言模型的漏洞和 RAG 交互动态的重要见解。
RAG 中毒的缓解策略。 基于自动化 RAG 中毒的发展和增强的可解释性,我们的研究还将侧重于制定针对 RAG 中毒的有效缓解策略。 这涉及识别和实施保护措施,以保护 GPT 模型免受恶意 RAG 内容的损害。 自动化系统的集成和对 RAG 动态的更清晰理解对于开发强大的防御机制至关重要。 这些策略不仅将增强GPT模型的安全性和可靠性,还将为更广泛的人工智能安全和伦理领域做出贡献。
很easy的一篇文章,创新不大,实验不多,工作量少,没有具体的case study,以及他对RAG的理解可能有些偏差,在他这里,是用户自己定制了一个GPT,主动往文件中塞入的是构造的恶意本地文件,然后对这个GPT可以实现更高概率的越狱(相对于直接询问普通的chatgpt)。系统提示词也都是自己设置的,可以说是圈地自萌了,实际意义不大