【线程池】线程池的使用汇总
【线程池】线程池的使用汇总
- 【一】创建线程池
- 【1】方式一:使用 @Async 注解 + 自定义线程池
- 【2】方式二:使用 Java 原生 ExecutorService(简单直接)
- 【3】方式三:ThreadPoolExecutor创建
- 【4】方式四:Springboot引入,手动配置 ThreadPoolTaskExecutor(灵活控制)
- 【5】方式五:使用 CompletableFuture(异步编排)
- 【6】execute提交线程的几种写法
- (1)内部类Runnable
- (2)普通写法
- (3)使用lambda简写
- (4)线程池声明多个线程
- 【7】定时任务中使用线程池
- (1)初始化线程池
- (2)线程池内部设置登录用户信息
- 【8】确定线程池的参数
- 【二】线程池的案例
- 【1】如何捕捉线程池的异常
- (1)submit()使用get()获取异常信息
- (2)使用 try -catch
- 【2】如何获取线程池的返回结果
- (1)Future的案例一
- (2)FutureTask的案例二
- (3)CompletableFuture异步执行每一个查询操作
- 【3】如何设置线程池按顺序执行
- (1)使用CountDownLatch
- (2)使用Phaser
- (3)使用Future和Callable
- 【4】如何设置线程池内线程超时时间
- 【5】优雅的关闭线程池
- 【6】线程池内获取分布式锁
- 【7】关键信息的对比
- (1)Runnable 和 Callable 的区别
- (2)⭐️execute() 和 submit()的区别
- (3)shutdown() 和 shutdownNow() 的区别
- (4)isTerminated() 和 isShutdown() 的区别
- (5)invokeAll和invokeAny
- (6)invokeAll和invokeAny哪个更快
- 【三】使用建议
- 【1】手动通过 ThreadPoolExecutor 的构造函数来声明,避免使用Executors 类创建线程池
- 【2】检测线程池运行状态
- 【3】建议不同类别的业务用不同的线程池
- 【4】正确配置线程池参数
- 【5】避免重复创建线程池
- 【6】线程池和ThreadLocal共用的坑
【一】创建线程池
【1】方式一:使用 @Async 注解 + 自定义线程池
通过注解简化异步任务开发,支持自定义线程池参数。
(1)优点
(2)缺点
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {@Override@Bean(name = "taskExecutor")public Executor getAsyncExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(10);executor.setMaxPoolSize(20);executor.setQueueCapacity(100);executor.setThreadNamePrefix("async-");executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.initialize();return executor;}
}@Service
public class MyService {@Async("taskExecutor") // 指定使用的线程池public void asyncMethod() {// 异步执行的业务逻辑}
}
【2】方式二:使用 Java 原生 ExecutorService(简单直接)
使用 JDK 原生线程池工具类,适合快速实现异步任务。
(1)优点
简单便捷
(2)缺点
1-FixedThreadPool 和 SingleThreadExecutor:使用的是阻塞队列 LinkedBlockingQueue,任务队列最大长度为 Integer.MAX_VALUE,可以看作是无界的,可能堆积大量的请求,从而导致 OOM。
2-CachedThreadPool:使用的是同步队列 SynchronousQueue, 允许创建的线程数量为 Integer.MAX_VALUE ,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。
3-ScheduledThreadPool 和 SingleThreadScheduledExecutor:使用的无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。
(3)建议
1-使用有界队列,控制线程创建数量。
2-实际使用中需要根据自己机器的性能、业务场景来手动配置线程池的参数比如核心线程数、使用的任务队列、饱和策略等等。
3-我们应该显示地给我们的线程池命名,这样有助于我们定位问题。
public class TestThread05 {public static void main(String[] args) throws InterruptedException {ExecutorService executorService1 = Executors.newCachedThreadPool();ExecutorService executorService2 = Executors.newFixedThreadPool(10);ExecutorService executorService3 = Executors.newSingleThreadExecutor();for (int i = 0; i < 100; i++) {executorService1.execute(new MyTask(i));// executorService2.execute(new MyTask(i));// executorService3.execute(new MyTask(i));}}
}class MyTask implements Runnable {int i = 0;public MyTask(int i) {this.i=i;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName()+"--"+i);try {//模拟业务逻辑Thread.sleep(1000L);} catch (InterruptedException e) {e.printStackTrace();}}
}【3】方式三:ThreadPoolExecutor创建
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;public class ThreadPoolExecutorDemo {private static final int CORE_POOL_SIZE = 5;private static final int MAX_POOL_SIZE = 10;private static final int QUEUE_CAPACITY = 100;private static final Long KEEP_ALIVE_TIME = 1L;public static void main(String[] args) {//使用阿里巴巴推荐的创建线程池的方式//通过ThreadPoolExecutor构造函数自定义参数创建ThreadPoolExecutor executor = new ThreadPoolExecutor(CORE_POOL_SIZE,MAX_POOL_SIZE,KEEP_ALIVE_TIME,TimeUnit.SECONDS,new ArrayBlockingQueue<>(QUEUE_CAPACITY),new ThreadPoolExecutor.CallerRunsPolicy());for (int i = 0; i < 10; i++) {//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)Runnable worker = new MyRunnable("" + i);//执行Runnableexecutor.execute(worker);}//终止线程池executor.shutdown();while (!executor.isTerminated()) {}System.out.println("Finished all threads");}
}/*** 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。* @author shuang.kou*/
public class MyRunnable implements Runnable {private String command;public MyRunnable(String s) {this.command = s;}@Overridepublic void run() {System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());processCommand();System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());}private void processCommand() {try {Thread.sleep(5000);} catch (InterruptedException e) {e.printStackTrace();}}@Overridepublic String toString() {return this.command;}
}
【4】方式四:Springboot引入,手动配置 ThreadPoolTaskExecutor(灵活控制)
直接创建线程池 Bean,手动提交任务,适合需要灵活控制任务执行的场景。
(1)定义线程池 Bean。
(2)注入线程池并提交任务。
@Configuration
public class ThreadPoolConfig {@Beanpublic ThreadPoolTaskExecutor customThreadPool() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(5);executor.setMaxPoolSize(10);executor.setQueueCapacity(20);executor.setThreadNamePrefix("custom-");executor.initialize();return executor;}
}@Service
public class MyService {@Autowiredprivate ThreadPoolTaskExecutor customThreadPool;public void executeTask() {customThreadPool.execute(() -> {// 任务逻辑});}
}
【5】方式五:使用 CompletableFuture(异步编排)
适合复杂的异步任务编排和组合,支持链式调用和回调机制。
(1)结合线程池创建 CompletableFuture。
(2)使用 thenApply、thenAccept 等方法编排任务。
@Service
public class MyService {@Autowiredprivate ThreadPoolTaskExecutor taskExecutor;public CompletableFuture<String> asyncTask() {return CompletableFuture.supplyAsync(() -> {// 异步任务1return "result1";}, taskExecutor).thenApply(result -> {// 异步任务2(依赖任务1的结果)return result + " -> result2";}).exceptionally(ex -> {// 异常处理return "error: " + ex.getMessage();});}
}
【6】execute提交线程的几种写法
(1)内部类Runnable
@Override
public void submitTaskInstance() throws ExecutionException, InterruptedException {
...IndexStorageTaskRunnable runnable = new IndexStorageTaskRunnable(beSubmitedTask, ContextMap.currentContext(), instanceLock);executorService.execute(runnable);
...
}private class IndexStorageTaskRunnable implements Runnable {ContextMap userContextMap;IndIndexTaskInstance taskInstance;RLock rLock;public IndexStorageTaskRunnable(IndIndexTaskInstance taskInstance, ContextMap userContextMap, RLock rLock) {this.taskInstance = taskInstance;this.userContextMap = userContextMap;this.rLock = rLock;}@Overridepublic void run() {try {doStorage(instanceId);} catch (Exception e) {log.error("指标固化结果失败:{}", e.getMessage(), e);} finally {rLock.forceUnlock();long end = System.currentTimeMillis();log.info("指标固化处理完毕:耗时:{} 秒", (end - start) / 1000);indInstanceLogRepo.createInstanceLog(taskInstance, InstanceTypeEnum.INDEX.getCode(), "指标固化处理完毕:耗时:" + (end - start) / 1000 + " 秒", null);LogMDCUtil.clear();}}
}
(2)普通写法
public static void main(String[] args) {//声明线程计数器,每执行完一个线程减一,减为0后执行主线程//需要几个线程就写几,多些会一直等待,少些会出现比较慢的线程还没执行完就执行主线程问题final CountDownLatch latch = new CountDownLatch(2);//第一个子线程执行//ExecutorService Java提供的线程池方法ExecutorService es1 = Executors.newSingleThreadExecutor();es1.execute(new Runnable() {@Overridepublic void run() {try {//暂停三秒Thread.sleep(3000);System.out.println("线程1已执行");} catch (InterruptedException e) {throw new RuntimeException(e);}//线程执行完,方法进行减1操作latch.countDown();}});es1.shutdown();ExecutorService es2 = Executors.newSingleThreadExecutor();es2.execute(new Runnable() {@Overridepublic void run() {try {//暂停两秒Thread.sleep(2000);System.out.println("线程2已执行");} catch (InterruptedException e) {throw new RuntimeException(e);}latch.countDown();}});es2.shutdown();try {System.out.println("等待执行中");latch.await();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("程序执行完毕");
}(3)使用lambda简写
public static void main(String[] args) {//声明线程计数器,每执行完一个线程减一,减为0后执行主线程//需要几个线程就写几,多些会一直等待,少些会出现比较慢的线程还没执行完就执行主线程问题final CountDownLatch latch = new CountDownLatch(2);//第一个子线程执行//ExecutorService Java提供的线程池方法ExecutorService es1 = Executors.newSingleThreadExecutor();es1.execute(() -> {try {//暂停三秒Thread.sleep(3000);System.out.println("线程1已执行");} catch (InterruptedException e) {throw new RuntimeException(e);}//线程执行完,方法进行减1操作latch.countDown();});es1.shutdown();ExecutorService es2 = Executors.newSingleThreadExecutor();es2.execute(() -> {try {//暂停两秒Thread.sleep(2000);System.out.println("线程2已执行");} catch (InterruptedException e) {throw new RuntimeException(e);}//线程执行完,方法进行减1操作latch.countDown();});es2.shutdown();try {System.out.println("等待执行中");latch.await();} catch (InterruptedException e) {e.printStackTrace();}System.out.println("程序执行完毕");
}(4)线程池声明多个线程
线程池声明2个线程,如果es.execute() 执行超过2个时,需要等待前面的线程执行完再执行
public static void main(String[] args) {//声明线程计数器,每执行完一个线程减一,减为0后执行主线程//需要几个线程就写几,多些会一直等待,少些会出现比较慢的线程还没执行完就执行主线程问题final CountDownLatch latch = new CountDownLatch(2);//第一个子线程执行//ExecutorService Java提供的线程池方法ExecutorService es = Executors.newFixedThreadPool(2);es.execute(() -> {try {//暂停三秒Thread.sleep(3000);System.out.println("线程1已执行");} catch (InterruptedException e) {throw new RuntimeException(e);}//线程执行完,方法进行减1操作latch.countDown();});es.execute(() -> {try {//暂停两秒Thread.sleep(2000);System.out.println("线程2已执行");} catch (InterruptedException e) {throw new RuntimeException(e);}//线程执行完,方法进行减1操作latch.countDown();});try {System.out.println("等待执行中");latch.await();} catch (InterruptedException e) {e.printStackTrace();} finally {//关闭线程池es.shutdown();}System.out.println("程序执行完毕");
}【7】定时任务中使用线程池
(1)初始化线程池
在一个方法内重复创建了线程池,在执行完之后却没有关闭。比较经典的就是在定时任务内使用线程池时有可能犯这个问题
使用线程池单例,切勿重复创建线程池。示例代码如下
// 某个线上线程池配置如下
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(50, // 最小核心线程数50, // 最大线程数,当队列满时,能创建的最大线程数60L, TimeUnit.SECONDS, // 空闲线程超过核心线程时,回收该线程的最大等待时间new LinkedBlockingQueue<>(5000), // 阻塞队列大小,当核心线程使用满时,新的线程会放进队列new CustomizableThreadFactory("task"), // 自定义线程名new ThreadPoolExecutor.CallerRunsPolicy() // 线程执行的拒绝策略
);
@XxlJob("test")
public void test() throws Exception {threadPoolExecutor.execute(() -> {// 任务逻辑// ...});
}
或者使用在bean加载完成后,afterPropertiesSet方法自动注入一个实例
@Service
@Slf4j
public class IndIndexCalcEngineServiceImpl implements InitializingBean, IndIndexCalcEngineService {private ThreadPoolExecutor executorService = null;@Overridepublic void afterPropertiesSet() {executorService = (ThreadPoolExecutor) Executors.newFixedThreadPool(currentCalcThreadCoreNum);}}
使用局部线程池时,若任务执行完后没有执行shutdown()方法或有其他不当引用,极易造成系统资源耗尽。
(2)线程池内部设置登录用户信息
(1)创建用户上下文 Holder
首先创建一个用于存储当前用户信息的 ThreadLocal 容器:
public class UserContextHolder {private static final ThreadLocal<UserInfo> userThreadLocal = new ThreadLocal<>();public static void setUser(UserInfo user) {userThreadLocal.set(user);}public static UserInfo getUser() {return userThreadLocal.get();}public static void clear() {userThreadLocal.remove();}
}// 用户信息类
class UserInfo {private String username;private String userId;// 其他用户信息字段public UserInfo(String username, String userId) {this.username = username;this.userId = userId;}// getters and setterspublic String getUsername() { return username; }public String getUserId() { return userId; }
}
(2)创建自定义任务装饰器
这个装饰器负责在线程池执行任务前后管理 ThreadLocal 上下文:
import org.springframework.core.task.TaskDecorator;
import org.springframework.web.context.request.RequestAttributes;
import org.springframework.web.context.request.RequestContextHolder;public class ContextCopyingDecorator implements TaskDecorator {@Overridepublic Runnable decorate(Runnable runnable) {// 捕获主线程中的RequestAttributes和UserContextRequestAttributes originalRequestAttributes = RequestContextHolder.currentRequestAttributes();UserInfo originalUser = UserContextHolder.getUser();return () -> {try {// 在子线程中设置RequestAttributes和UserContextRequestContextHolder.setRequestAttributes(originalRequestAttributes);UserContextHolder.setUser(originalUser);// 执行实际任务runnable.run();} finally {// 任务执行完毕后清除上下文,防止线程复用时的上下文污染UserContextHolder.clear();RequestContextHolder.resetRequestAttributes();}};}
}
(3)配置线程池
创建一个配置类,定义线程池并应用我们的任务装饰器:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import java.util.concurrent.Executor;@Configuration
public class ThreadPoolConfig {@Bean(name = "customThreadPool")public Executor customThreadPool() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(5);executor.setMaxPoolSize(10);executor.setQueueCapacity(25);executor.setThreadNamePrefix("custom-thread-");// 设置任务装饰器executor.setTaskDecorator(new ContextCopyingDecorator());executor.initialize();return executor;}
}
(4)创建服务类使用线程池
创建一个服务类,演示如何在不使用 @Async 的情况下,手动使用线程池执行任务并访问用户上下文:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.concurrent.Executor;@Service
public class AsyncService {@Autowiredprivate final Executor customThreadPool;public void executeAsyncTask() {// 提交任务到线程池customThreadPool.execute(() -> {// 在线程池中访问用户上下文UserInfo user = UserContextHolder.getUser();if (user != null) {System.out.println("当前执行线程: " + Thread.currentThread().getName());System.out.println("当前用户: " + user.getUsername() + ", ID: " + user.getUserId());// 模拟业务处理processBusiness(user);} else {System.out.println("用户上下文丢失!");}});}private void processBusiness(UserInfo user) {// 模拟业务处理逻辑System.out.println("处理用户 " + user.getUsername() + " 的业务数据...");try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("业务处理完成");}
}
【8】确定线程池的参数
(1)避免使用无界队列
如 LinkedBlockingQueue 默认无界,可能导致 OOM,建议指定队列大小。
(2)合理设置线程数
IO 密集型任务:线程数可设为 2 * CPU核心数。
CPU 密集型任务:线程数设为 CPU核心数 + 1。
【二】线程池的案例
【1】如何捕捉线程池的异常
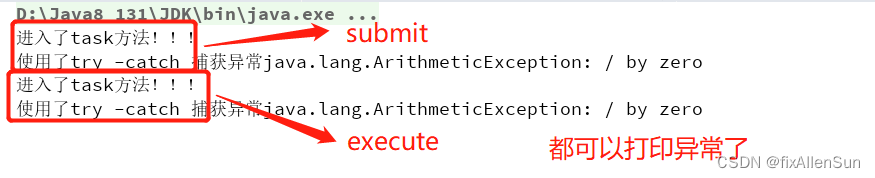
submit不打印异常信息,而execute则会打印异常信息!在不需要返回结果的情况下,最好用execute ,这样就算没有写try-catch,疏漏了异常捕捉,也不至于丢掉异常信息。
(1)submit()使用get()获取异常信息
submit()想要获取异常信息就必须使用get()方法!!
public class ThreadPoolException {public static void main(String[] args) {//创建一个线程池ExecutorService executorService= Executors.newFixedThreadPool(1);//当线程池抛出异常后 submit无提示,其他线程继续执行Future<?> submit = executorService.submit(new task());submit.get();}
}//任务类
class task implements Runnable{@Overridepublic void run() {System.out.println("进入了task方法!!!");int i=1/0;}
}

(2)使用 try -catch
public class ThreadPoolException {public static void main(String[] args) {//创建一个线程池ExecutorService executorService = Executors.newFixedThreadPool(1);//当线程池抛出异常后 submit无提示,其他线程继续执行executorService.submit(new task());//当线程池抛出异常后 execute抛出异常,其他线程继续执行新任务executorService.execute(new task());}
}
// 任务类
class task implements Runnable {@Overridepublic void run() {try {System.out.println("进入了task方法!!!");int i = 1 / 0;} catch (Exception e) {System.out.println("使用了try -catch 捕获异常" + e);}}
}打印结果:
【2】如何获取线程池的返回结果
(1)需要获取返回结果就使用submit提交线程任务,不使用execute
(2)submit提交配置Callable返回,submit(Callable c),而不使用Runable
1-submit(Runnable r):Runnable的run方法是void的,没有返回值,所以Future.get()是null。
2-submit(Runnable r,T result):T result就是传入的对象。我们可以通过自定义Runnable来将result传入到自定义的Runnable中,在run()方法中对结果写入到result中。其中返回的对象future.get()==result。不太好用,需要每次都自定义Runnable和result,太麻烦了。
(3)Future 接口以及 Future 接口的实现类 FutureTask 类都可以代表异步计算的结果
Callable callable = new Callable() {@Overridepublic Object call() throws Exception {String name = "777";name += "6666";return name;}
};Future f = executor.submit(callable);
System.out.println(f.get());
(1)Future的案例一
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;public class Main {public static void main(String[] args) {ExecutorService executorService = Executors.newCachedThreadPool();List<Future<String>> resultList = new ArrayList<Future<String>>();// 创建10个任务并执行for (int i = 0; i < 10; i++) {// 使用ExecutorService执行Callable类型的任务,并将结果保存在future变量中Future<String> future = executorService.submit(new TaskWithResult(i));// 将任务执行结果存储到List中resultList.add(future);}executorService.shutdown();// 遍历任务的结果for (Future<String> fs : resultList) {try {System.out.println(fs.get()); // 打印各个线程(任务)执行的结果} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {executorService.shutdownNow();e.printStackTrace();return;}}}
}
class TaskWithResult implements Callable<String> {private int id;public TaskWithResult(int id) {this.id = id;}/*** 任务的具体过程,一旦任务传给ExecutorService的submit方法,则该方法自动在一个线程上执行。** @return* @throws Exception*/public String call() throws Exception {System.out.println("call()方法被自动调用,干活!!! " + Thread.currentThread().getName());if (new Random().nextBoolean())throw new TaskException("Meet error in task." + Thread.currentThread().getName());// 一个模拟耗时的操作for (int i = 999999999; i > 0; i--);return "call()方法被自动调用,任务的结果是:" + id + " " + Thread.currentThread().getName();}
}class TaskException extends Exception {public TaskException(String message) {super(message);}
}执行结果:
call()方法被自动调用,干活!!! pool-1-thread-2
call()方法被自动调用,干活!!! pool-1-thread-6
call()方法被自动调用,干活!!! pool-1-thread-1
call()方法被自动调用,任务的结果是:0 pool-1-thread-1
call()方法被自动调用,任务的结果是:1 pool-1-thread-2
call()方法被自动调用,干活!!! pool-1-thread-4
call()方法被自动调用,干活!!! pool-1-thread-9
call()方法被自动调用,干活!!! pool-1-thread-8
call()方法被自动调用,干活!!! pool-1-thread-10
call()方法被自动调用,干活!!! pool-1-thread-5
call()方法被自动调用,干活!!! pool-1-thread-3
call()方法被自动调用,干活!!! pool-1-thread-7
call()方法被自动调用,任务的结果是:2 pool-1-thread-3
call()方法被自动调用,任务的结果是:3 pool-1-thread-4
java.util.concurrent.ExecutionException: com.company.TaskException: Meet error in task.pool-1-thread-5
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at com.company.Main.main(Main.java:29)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
Caused by: com.company.TaskException: Meet error in task.pool-1-thread-5
at com.company.TaskWithResult.call(Main.java:56)
at com.company.TaskWithResult.call(Main.java:40)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
(2)FutureTask的案例二
FutureTask是一个具体的实现类,ThreadPoolExecutor的submit方法返回的就是一个Future的实现,这个实现就是FutureTask的一个具体实例,FutureTask帮助实现了具体的任务执行,以及和Future接口中的get方法的关联。
import java.util.Date;
import java.text.SimpleDateFormat;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;public class Main {public static void main(String[] args) {SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");FutureTask<String> futureTask=new FutureTask<>(new Callable<String>() {//@Overridepublic String call() throws Exception {// TODO Auto-generated method stubreturn "回调完成";}});Thread thread = new Thread(futureTask);System.out.println("启动时间为:" + df.format(new Date()));thread.start();try {String str=futureTask.get();if(str.equals("回调完成"))System.out.println("异步任务完成!");elseSystem.out.println("Completed!");} catch (InterruptedException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (ExecutionException e) {// TODO Auto-generated catch blocke.printStackTrace();}}
}执行结果
启动时间为:2016-12-01 09:37:03
异步任务完成!
(3)CompletableFuture异步执行每一个查询操作
如下,我们定义了一个异步任务类,创建每一个查询操作的CompletableFuture异步任务放入线程中执行,并利用allOf等待全部任务执行完成,执行完成后组装查询信息到聚合对象中返回
/*** @author Luckysj @刘仕杰* @description 一个页面可能有多达10个左右的一个用户行为数据,我们可以通过多线程来提高查询速率* @create 2024/03/19 21:45:04*/
@Slf4j
@Component
public class MyFutureTask {@ResourceUserService userService;// 线程池@Resourceprivate ExecutorService executor;public UserBehaviorDataDTO getUserAggregatedResult(final Long userId) {System.out.println("MyFutureTask的线程:" + Thread.currentThread());try {// 1.发布文章数CompletableFuture<Long> articleCountFT = CompletableFuture.supplyAsync(() -> userService.countArticleCountByUserId(userId), executor);// 2.点赞数CompletableFuture<Long> LikeCountFT = CompletableFuture.supplyAsync(() -> userService.countLikeCountByUserId(userId), executor);// 3.粉丝数CompletableFuture<Long> fansCountFT = CompletableFuture.supplyAsync(() -> userService.countFansCountByUserId(userId), executor);// 4.消息数CompletableFuture<Long> msgCountFT = CompletableFuture.supplyAsync(() -> userService.countMsgCountByUserId(userId), executor);// 5.收藏数CompletableFuture<Long> collectCountFT = CompletableFuture.supplyAsync(() -> userService.countCollectCountByUserId(userId), executor);// 6.关注数CompletableFuture<Long> followCountFT = CompletableFuture.supplyAsync(() -> userService.countFollowCountByUserId(userId), executor);// 7.红包数CompletableFuture<Long> redBagCountFT = CompletableFuture.supplyAsync(() -> userService.countRedBagCountByUserId(userId), executor);// 8.卡券数CompletableFuture<Long> couponCountFT = CompletableFuture.supplyAsync(() -> userService.countCouponCountByUserId(userId), executor);// 等待全部线程执行完毕 这里一定要设超时时间,不然会一直等待CompletableFuture.allOf(articleCountFT, LikeCountFT, fansCountFT, msgCountFT, collectCountFT, followCountFT, redBagCountFT, couponCountFT).get(6, TimeUnit.SECONDS);// 必须设置合理的超时时间UserBehaviorDataDTO userBehaviorData = UserBehaviorDataDTO.builder().articleCount(articleCountFT.get()).likeCount(LikeCountFT.get()).fansCount(fansCountFT.get()).msgCount(msgCountFT.get()).collectCount(collectCountFT.get()).followCount(followCountFT.get()).redBagCount(redBagCountFT.get()).couponCount(couponCountFT.get()).build();return userBehaviorData;} catch (Exception e) {log.error("get user behavior data error", e);return new UserBehaviorDataDTO();}}这里用户服务类中我采用线程睡眠来模拟查询耗时
测试
访问测试接口,日志输出如下:
UserController的线程:Thread[http-nio-8080-exec-2,5,main]
MyFutureTask的线程:Thread[http-nio-8080-exec-2,5,main]
UserService获取ArticleCount的线程 pool-2-thread-1
UserService获取likeCount的线程 pool-2-thread-2
UserService获取MsgCount的线程 pool-2-thread-4
UserService获取CollectCount的线程 pool-2-thread-5
UserService获取FollowCount的线程 pool-2-thread-6
UserService获取RedBagCount的线程 pool-2-thread-7
UserService获取CouponCount的线程 pool-2-thread-8
获取CouponCount===睡眠:0s
获取RedBagCount===睡眠:1s
获取FollowCount===睡眠:1s
获取CollectCount==睡眠:2s
获取FansCount===睡眠:1s
UserService获取FansCount的线程 pool-2-thread-3
获取ArticleCount===睡眠:1s
获取MsgCount===睡眠:1s
获取likeCount===睡眠:2s
===============总耗时:2.019秒
可以看到,总耗时主要取决于耗时最长的那个操作,相比于串行查询肯定快多了
【3】如何设置线程池按顺序执行
(1)使用CountDownLatch
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ThreadOrderWithCountDownLatch {public static void main(String[] args) {ExecutorService executorService = Executors.newFixedThreadPool(3);// 用于线程a等待开始的信号量CountDownLatch startSignal = new CountDownLatch(1);// 用于线程b等待线程a完成的信号量CountDownLatch aDoneSignal = new CountDownLatch(1);// 用于线程c等待线程b完成的信号量CountDownLatch bDoneSignal = new CountDownLatch(1);Runnable taskA = () -> {try {startSignal.await();System.out.println("线程a执行");aDoneSignal.countDown();} catch (InterruptedException e) {e.printStackTrace();}};Runnable taskB = () -> {try {aDoneSignal.await();System.out.println("线程b执行");bDoneSignal.countDown();} catch (InterruptedException e) {e.printStackTrace();}};Runnable taskC = () -> {try {bDoneSignal.await();System.out.println("线程c执行");} catch (InterruptedException e) {e.printStackTrace();}};executorService.submit(taskA);executorService.submit(taskB);executorService.submit(taskC);// 释放线程a开始执行的信号startSignal.countDown();executorService.shutdown();}
}(2)使用Phaser
import java.util.concurrent.Phaser;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ThreadOrderWithPhaser {public static void main(String[] args) {ExecutorService executorService = Executors.newFixedThreadPool(3);Phaser phaser = new Phaser(1); Runnable taskA = () -> {System.out.println("线程a执行");phaser.arriveAndAwaitAdvance();};Runnable taskB = () -> {try {phaser.awaitAdvance(phaser.getPhase());System.out.println("线程b执行");phaser.arriveAndAwaitAdvance();} catch (Exception e) {e.printStackTrace();}};Runnable taskC = () -> {try {phaser.awaitAdvance(phaser.getPhase());System.out.println("线程c执行");} catch (Exception e) {e.printStackTrace();}};executorService.submit(taskA);executorService.submit(taskB);executorService.submit(taskC);phaser.arriveAndDeregister();executorService.shutdown();}
}(3)使用Future和Callable
import java.util.concurrent.*;public class ThreadOrderWithFuture {public static void main(String[] args) throws ExecutionException, InterruptedException {ExecutorService executorService = Executors.newFixedThreadPool(3);Callable<Void> taskA = () -> {System.out.println("线程a执行");return null;};Callable<Void> taskB = () -> {Future<Void> futureA = executorService.submit(taskA);try {futureA.get();System.out.println("线程b执行");} catch (Exception e) {e.printStackTrace();}return null;};Callable<Void> taskC = () -> {Future<Void> futureB = executorService.submit(taskB);try {futureB.get();System.out.println("线程c执行");} catch (Exception e) {e.printStackTrace();}return null;};executorService.submit(taskC);executorService.shutdown();}
}【4】如何设置线程池内线程超时时间
【5】优雅的关闭线程池
确保正在执行的任务完成、等待队列中的任务得到处理,并正确释放资源。
@PreDestroy
public void shutdown() {// 第一步:调用shutdown,拒绝新任务提交executor.shutdown();try {// 第二步:等待未完成任务结束if (!executor.awaitTermination(30, TimeUnit.SECONDS)) {// 第三步:超时后强制关闭executor.shutdownNow();}} catch (InterruptedException e) {// 第五步:如果当前线程被中断,也强制关闭executor.shutdownNow();}
}
【6】线程池内获取分布式锁
【7】关键信息的对比
(1)Runnable 和 Callable 的区别
Runnable自 Java 1.0 以来一直存在,但Callable仅在 Java 1.5 中引入,目的就是为了来处理Runnable不支持的用例。Runnable 接口不会返回结果或抛出检查异常,但是Callable 接口可以。所以,如果任务不需要返回结果或抛出异常推荐使用 Runnable 接口,这样代码看起来会更加简洁。
工具类 Executors 可以实现 Runnable 对象和 Callable 对象之间的相互转换
@FunctionalInterface
public interface Runnable {/*** 被线程执行,没有返回值也无法抛出异常*/public abstract void run();
}
@FunctionalInterface
public interface Callable<V> {/*** 计算结果,或在无法这样做时抛出异常。* @return 计算得出的结果* @throws 如果无法计算结果,则抛出异常*/V call() throws Exception;
}
(2)⭐️execute() 和 submit()的区别
(1)execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
execute方法的参数是一个 Runnable,也没有返回值。因此提交后无法判断该任务是否被线程池执行成功。
(2)submit()方法用于提交需要返回值的任务。线程池会返回一个 Future 类型的对象,通过这个 Future 对象可以判断任务是否执行成功,并且可以通过 Future 的 get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用 get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
submit() 有三种重载,参数可以是 Callable 也可以是 Runnable。
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
同时它会返回一个 Funture 对象,通过它我们可以判断任务是否执行成功。
获得执行结果调用 Future.get() 方法,这个方法会阻塞当前线程直到任务完成。
ExecutorService executorService = Executors.newFixedThreadPool(2);
//提交第一个任务返回结果
Future<String> future = executorService.submit(new Callable<String>() {@Overridepublic String call() throws Exception {log.debug("running");TimeUnit.SECONDS.sleep(1);return "ok";}
});
//提交第二个任务返回结果
Future<String> future2 = executorService.submit(() -> {log.debug("running");TimeUnit.SECONDS.sleep(1);return "success";
});try {String res = future.get();String res2 = future2.get();log.debug("res={}", res);log.debug("res2={}", res2);
} catch (Exception e) {e.printStackTrace();
}
(3)shutdown() 和 shutdownNow() 的区别
(1)shutdown() :关闭线程池,线程池的状态变为 SHUTDOWN。线程池不再接受新任务了,但是队列里的任务得执行完毕
(2)shutdownNow() :关闭线程池,线程的状态变为 STOP。线程池会终止当前正在运行的任务,并停止处理排队的任务并返回正在等待执行的 List
调用完 shutdownNow 和 shuwdown 方法后,并不代表线程池已经完成关闭操作,它只是异步的通知线程池进行关闭处理。如果要同步等待线程池彻底关闭后才继续往下执行,需要调用awaitTermination方法进行同步等待。
在调用 awaitTermination() 方法时,应该设置合理的超时时间,以避免程序长时间阻塞而导致性能问题。另外。由于线程池中的任务可能会被取消或抛出异常,因此在使用 awaitTermination() 方法时还需要进行异常处理。awaitTermination() 方法会抛出 InterruptedException 异常,需要捕获并处理该异常,以避免程序崩溃或者无法正常退出。
// ...
// 关闭线程池
executor.shutdown();
try {// 等待线程池关闭,最多等待5分钟if (!executor.awaitTermination(5, TimeUnit.MINUTES)) {// 如果等待超时,则打印日志System.err.println("线程池未能在5分钟内完全关闭");}
} catch (InterruptedException e) {// 异常处理
}
(4)isTerminated() 和 isShutdown() 的区别
(1)isShutDown (判断线程池是否已经关闭)
当调用 shutdown() 方法后返回为 true
(2)isTerminated (判断线程池的任务是否已经停止)
当调用 shutdown() 方法后,并且所有提交的任务完成后返回为 true
(5)invokeAll和invokeAny
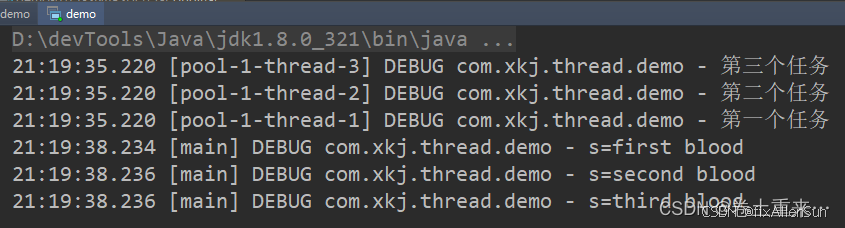
(1)invokeAll:提交一个任务集合返回任务集合的所有执行结果
带超时时间的invokeAll方法,如果规定的时间没有线程池中的任务没有执行完,会把后续的取消掉
ExecutorService executorService = Executors.newFixedThreadPool(3);List<Callable<String>> callableList = Arrays.asList(() -> {log.debug("第一个任务");TimeUnit.SECONDS.sleep(1);return "first blood";},() -> {log.debug("第二个任务");TimeUnit.SECONDS.sleep(2);return "second blood";},() -> {log.debug("第三个任务");TimeUnit.SECONDS.sleep(3);return "third blood";});try {List<Future<String>> futures = executorService.invokeAll(callableList);futures.forEach(f -> {try {String s = f.get();log.debug("s={}", s);} catch (Exception e1) {e1.printStackTrace();}});} catch (Exception e) {e.printStackTrace();}
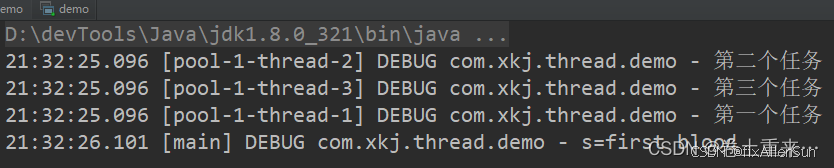
(2)invokeAny:任务集合中只要有一个任务执行完就返回结果,并取消其他任务
ExecutorService executorService = Executors.newFixedThreadPool(3);List<Callable<String>> callableList = Arrays.asList(() -> {log.debug("第一个任务");TimeUnit.SECONDS.sleep(1);return "first blood";},() -> {log.debug("第二个任务");TimeUnit.SECONDS.sleep(2);return "second blood";},() -> {log.debug("第三个任务");TimeUnit.SECONDS.sleep(3);return "third blood";});try {String future = executorService.invokeAny(callableList);log.debug("s={}", future);} catch (Exception e) {e.printStackTrace();}
(6)invokeAll和invokeAny哪个更快
(1)invokeAll:执行所有任务,等待全部完成后返回包含所有任务结果的列表(可能包含异常)。所有任务完成或线程池被中断的时候返回List<Future>。当业务逻辑必须等待所有任务完成并获取全部结果时,invokeAll 是唯一选择。当所有任务的执行时间差异较小时,invokeAll 的整体耗时约等于最长任务的耗时,此时无需使用 invokeAny 提前终止其他任务。因为终止其他任务也需要开销。
(2)invokeAny:执行所有任务,只要有一个成功完成就返回其结果,其他任务会被取消。适合 “竞争” 场景(如查询多个数据源,取第一个返回的结果),性能取决于最快的任务。
哪个更快取决于具体场景:
(1)任务耗时均匀且无依赖:
invokeAll 更快:因为所有任务并行执行,整体耗时约等于最长任务的耗时,此时无需使用 invokeAny 提前终止其他任务,终止其他任务也是需要开销的。
invokeAny 更慢:需要额外处理任务取消逻辑,即使所有任务几乎同时完成,也必须等待其中一个被选中并返回。
(2)任务耗时差异大:
invokeAny 可能更快:如果某个任务很快完成,其他耗时任务会被提前取消,节省资源。
invokeAll 更慢:必须等待所有任务完成,包括最慢的任务。
(3)任务有依赖或需全部结果:
只能使用 invokeAll,性能取决于最慢的任务。
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.*;public class InvokeAllVsInvokeAny {public static void main(String[] args) throws Exception {ExecutorService executor = Executors.newFixedThreadPool(3);// 场景1:所有任务耗时相近System.out.println("=== 任务耗时相近 ===");testUniformTasks(executor);// 场景2:任务耗时差异大System.out.println("\n=== 任务耗时差异大 ===");testVaryingTasks(executor);executor.shutdown();}private static void testUniformTasks(ExecutorService executor) throws Exception {List<Callable<String>> tasks = Arrays.asList(() -> { Thread.sleep(500); return "Task 1"; },() -> { Thread.sleep(550); return "Task 2"; },() -> { Thread.sleep(600); return "Task 3"; });long startAll = System.currentTimeMillis();executor.invokeAll(tasks);System.out.println("invokeAll 耗时: " + (System.currentTimeMillis() - startAll) + "ms");long startAny = System.currentTimeMillis();executor.invokeAny(tasks);System.out.println("invokeAny 耗时: " + (System.currentTimeMillis() - startAny) + "ms");}private static void testVaryingTasks(ExecutorService executor) throws Exception {List<Callable<String>> tasks = Arrays.asList(() -> { Thread.sleep(100); return "Fast Task"; },() -> { Thread.sleep(500); return "Medium Task"; },() -> { Thread.sleep(1000); return "Slow Task"; });long startAll = System.currentTimeMillis();executor.invokeAll(tasks);System.out.println("invokeAll 耗时: " + (System.currentTimeMillis() - startAll) + "ms");long startAny = System.currentTimeMillis();executor.invokeAny(tasks);System.out.println("invokeAny 耗时: " + (System.currentTimeMillis() - startAny) + "ms");}
}
使用总结:
(1)所有结果均需处理:invokeAll
(2)任务耗时相近:invokeAll
(3)任务耗时差距较大,且只需要一个结果:invokeAny
(4)任务间存在依赖:invokeAll
(5)需完整上下文或资源管理:invokeAll
(6)优先使用 invokeAll:除非明确需要 “最快结果” 且其他任务无副作用。
(7)结合 CompletableFuture:对于复杂的并行任务(如需要部分结果先行处理),可使用 CompletableFuture.allOf 替代 invokeAll,提供更灵活的组合方式。
【三】使用建议
【1】手动通过 ThreadPoolExecutor 的构造函数来声明,避免使用Executors 类创建线程池
Executors 返回线程池对象的弊端如下:
(1)FixedThreadPool 和 SingleThreadExecutor:使用的是阻塞队列 LinkedBlockingQueue,任务队列的默认长度和最大长度为 Integer.MAX_VALUE,可以看作是无界队列,可能堆积大量的请求,从而导致 OOM。
(2)CachedThreadPool:使用的是同步队列 SynchronousQueue,允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
(3)ScheduledThreadPool 和 SingleThreadScheduledExecutor : 使用的无界的延迟阻塞队列DelayedWorkQueue,任务队列最大长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致 OOM。
说白了就是:使用有界队列,控制线程创建数量。
除了避免 OOM 的原因之外,不推荐使用 Executors提供的两种快捷的线程池的原因还有:
(1)实际使用中需要根据自己机器的性能、业务场景来手动配置线程池的参数比如核心线程数、使用的任务队列、饱和策略等等。
(2)我们应该显示地给我们的线程池命名,这样有助于我们定位问题
【2】检测线程池运行状态
可以通过一些手段来检测线程池的运行状态,比如 SpringBoot 中的 Actuator 组件
还可以利用 ThreadPoolExecutor 的相关 API 做一个简陋的监控。从下图可以看出, ThreadPoolExecutor提供了获取线程池当前的线程数和活跃线程数、已经执行完成的任务数、正在排队中的任务数等等
一个简单的 Demo。printThreadPoolStatus()会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数
/*** 打印线程池的状态** @param threadPool 线程池对象*/
public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-images/thread-pool-status", false));scheduledExecutorService.scheduleAtFixedRate(() -> {log.info("=========================");log.info("ThreadPool Size: [{}]", threadPool.getPoolSize());log.info("Active Threads: {}", threadPool.getActiveCount());log.info("Number of Tasks : {}", threadPool.getCompletedTaskCount());log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());log.info("=========================");}, 0, 1, TimeUnit.SECONDS);
}
【3】建议不同类别的业务用不同的线程池
一般建议是不同的业务使用不同的线程池,配置线程池的时候根据当前业务的情况对当前线程池进行配置,因为不同的业务的并发以及对资源的使用情况都不同,重心优化系统性能瓶颈相关的业务
【4】正确配置线程池参数
(1)CPU 密集型任务 (N): 这种任务消耗的主要是 CPU 资源,线程数应设置为 N(CPU 核心数)。由于任务主要瓶颈在于 CPU 计算能力,与核心数相等的线程数能够最大化 CPU 利用率,过多线程反而会导致竞争和上下文切换开销。
(2)I/O 密集型任务(M * N): 这类任务大部分时间处理 I/O 交互,线程在等待 I/O 时不占用 CPU。 为了充分利用 CPU 资源,线程数可以设置为 M * N,其中 N 是 CPU 核心数,M 是一个大于 1 的倍数,建议默认设置为 2 ,具体取值取决于 I/O 等待时间和任务特点,需要通过测试和监控找到最佳平衡点。
CPU 密集型任务不再推荐 N+1,原因如下:
(1)“N+1” 的初衷是希望预留线程处理突发暂停,但实际上,处理缺页中断等情况仍然需要占用 CPU 核心。
(2)CPU 密集场景下,CPU 始终是瓶颈,预留线程并不能凭空增加 CPU 处理能力,反而可能加剧竞争。
如何判断是 CPU 密集任务还是 IO 密集任务?
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
【5】避免重复创建线程池
不要在接口或者调度任务重重复创建线程池
@GetMapping("wrong")
public String wrong() throws InterruptedException {// 自定义线程池ThreadPoolExecutor executor = new ThreadPoolExecutor(5,10,1L,TimeUnit.SECONDS,new ArrayBlockingQueue<>(100),new ThreadPoolExecutor.CallerRunsPolicy());// 处理任务executor.execute(() -> {// ......}return "OK";
}
【6】线程池和ThreadLocal共用的坑
线程池和 ThreadLocal共用,可能会导致线程从ThreadLocal获取到的是旧值/脏数据。这是因为线程池会复用线程对象,与线程对象绑定的类的静态属性 ThreadLocal 变量也会被重用,这就导致一个线程可能获取到其他线程的ThreadLocal 值。
解决上述问题比较建议的办法是使用阿里巴巴开源的 TransmittableThreadLocal(TTL)。TransmittableThreadLocal类继承并加强了 JDK 内置的InheritableThreadLocal类,在使用线程池等会池化复用线程的执行组件情况下,提供ThreadLocal值的传递功能,解决异步执行时上下文传递的问题。