[逻辑回归]机器学习-part11
十二 逻辑回归
1.概念
逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广泛。
逻辑回归一般用于二分类问题,比如:
是好瓜还是坏瓜
健康还是不健康
可以托付终身还是不可以
2.原理
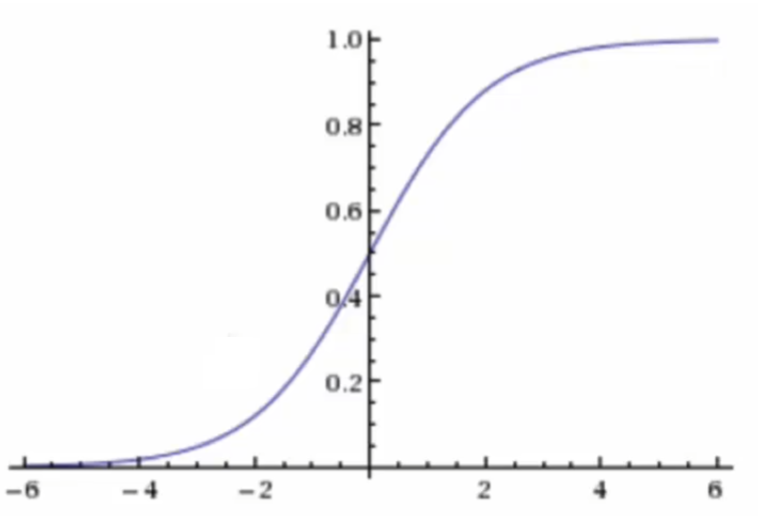
Sigmoid 函数映射 :然后将线性组合的结果通过 Sigmoid 函数进行映射。Sigmoid 函数的公式为 ![]() 。它的输出范围在 (0,1) 之间,可以将线性组合的结果转换为概率值。例如,当 z 很大的时候,σ(z) 趋近于 1;当 z 很小的时候,σ(z) 趋近于 0。这样,模型就可以根据这个概率值来判断样本属于正类(如 1)还是负类(如 0)。一般设定一个阈值(如 0.5),当输出概率大于等于这个阈值时,预测为正类;否则预测为负类。
。它的输出范围在 (0,1) 之间,可以将线性组合的结果转换为概率值。例如,当 z 很大的时候,σ(z) 趋近于 1;当 z 很小的时候,σ(z) 趋近于 0。这样,模型就可以根据这个概率值来判断样本属于正类(如 1)还是负类(如 0)。一般设定一个阈值(如 0.5),当输出概率大于等于这个阈值时,预测为正类;否则预测为负类。
损失函数 - 对数似然损失函数(交叉熵损失) :为了衡量模型预测结果和真实标签之间的差异,逻辑回归采用对数似然损失函数。对于单个样本,其损失函数可以表示为−[y⋅lnσ(z)+(1−y)⋅ln(1−σ(z))],其中 y 是样本的真实标签(0 或 1)。这个损失函数的直观理解是:当模型预测概率和真实标签越接近,损失越小;反之,损失越大。为了得到更好的模型参数,需要最小化这个损失函数。通常使用梯度下降算法来优化模型参数 w 和 b,通过计算损失函数对 w 和 b 的梯度,不断更新它们的值,使得损失函数逐渐减小。
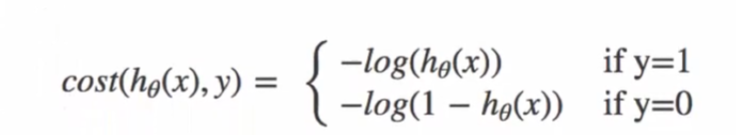
损失函数图:
当y=1时:
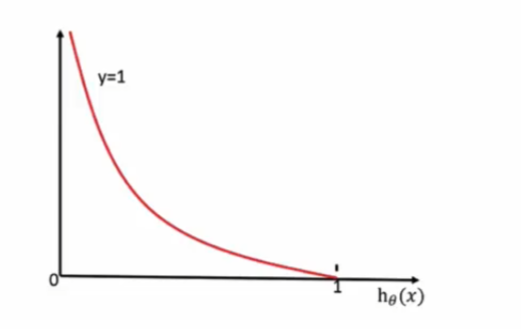
通过损失函数图像,我们知道:
当y=1时,我们希望h\theta(x) 值越大越好
当y=0时,我们希望h\theta(x) 值越小越好
综合0和1的损失函数:
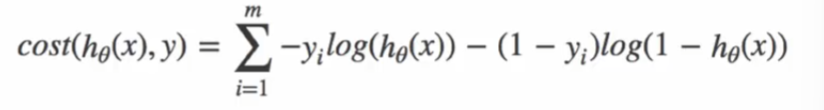
手动算一下下:

然后使用梯度下降算法,去减少损失函数的值,这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率.
3.API
逻辑斯蒂
sklearn.linear_model.LogisticRegression() 参数:fit_intercept bool, default=True 指定是否计算截距max_iter int, default=100 最大迭代次数。迭代达到此数目后,即使未收敛也会停止。 模型对象:.coef_ 权重.intercept_ 偏置predict()预测分类predict_proba()预测分类(对应的概率)score()准确率
4.示例
#导包 import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris #加载数据 X,y = load_iris(return_X_y=True) print(y) #二分类 删除第三类 X=X[y!=2] y=y[y!=2] print(y) #数据集划分 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33) print(X_train.shape,y_train.shape) #逻辑回归模型 model=LogisticRegression() #训练 model.fit(X_train,y_train) #权重 print(model.coef_) #偏置 print(model.intercept_) #预测分类 y_predict=model.predict(X_test) print(y_predict) print(y_test) #预测分类对应的概率 proba=model.predict_proba(X_test) print(proba) #评估 print(model.score(X_test,y_test))