LangChain文档加载器实战:构建高效RAG数据流水线
导读:在现代数据驱动的应用开发中,RAG(Retrieval-Augmented Generation)系统因其高效的数据处理能力和强大的生成能力而备受关注。然而,作为 RAG 系统的第一步,文档加载器的设计与实现却常常成为开发者面临的挑战之一。本文从基础到实战,全面解析了文档加载器的核心技术及其在 RAG 系统中的作用。
文章首先梳理了 RAG 系统的整体架构和技术链路,帮助读者理解文档加载器在整个流程中的重要性。接着,详细介绍了 LangChain 中的BaseLoader接口以及多种常见的文档加载器(如文件加载器、网页加载器和数据库加载器),并提供了丰富的代码示例,让初学者能够快速上手。此外,文章还深入探讨了高级技巧,例如如何结合 OCR 工具处理图片文本,以及批量加载文档的最佳实践。
通过阅读本文,你将不仅学会如何选择和使用适合的文档加载器,还能掌握解决常见问题的方法。比如,为什么某些 PDF 文件无法正确加载?如何优化文本分块策略以提升后续处理效率?这些问题的答案都在文中等待你去发现。
如果你对 RAG 系统或文档加载技术感兴趣,这篇文章将是你的必备指南。它不仅能帮你解决实际开发中的难题,还会启发你对未来发展方向的思考。快来阅读全文,开启你的技术探索之旅吧!
引言
在现代数据驱动的应用开发中,RAG(Retrieval-Augmented Generation)系统因其高效的数据处理能力和强大的生成能力而备受关注。作为 RAG 系统的核心组件之一,文档加载器(Document Loaders)负责将多样化的外部数据源转换为统一格式的文档对象,为后续的文本嵌入、向量存储和检索等步骤奠定基础。
第一部分:RAG 系统的整体架构与链路分析
1.1 RAG 系统简介
RAG 系统是一种结合了检索增强(Retrieval)和生成模型(Generation)的混合架构,广泛应用于问答系统、搜索引擎和内容生成等领域。其核心思想是通过高效的检索机制从大规模数据集中提取相关信息,并将其输入到生成模型中以生成高质量的输出。
1.2 技术链路环节
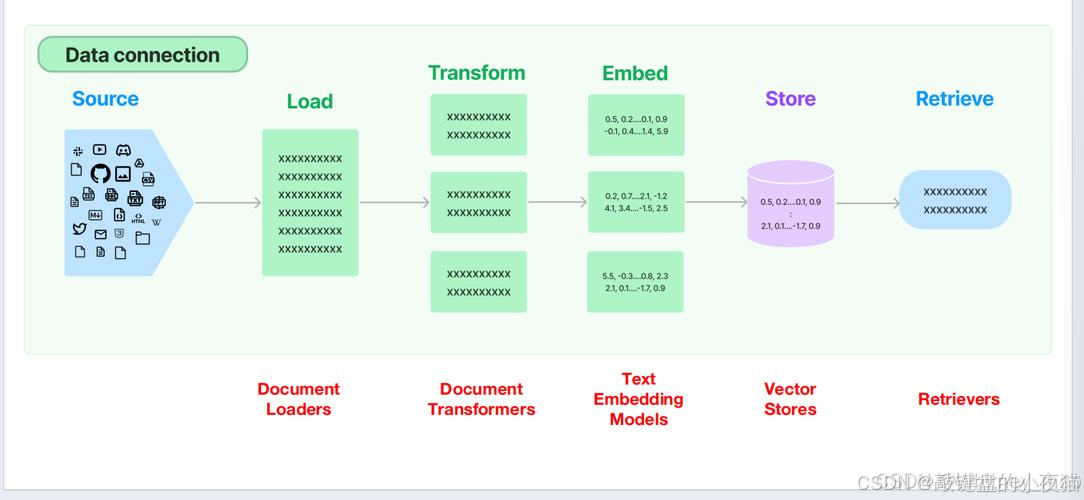
RAG 系统的典型技术链路可以分为以下几个关键步骤:
- 数据加载:将原始数据(如 PDF、网页、数据库等)转换为统一格式的文档对象。
- 文档转换:对文档进行预处理,包括文本清洗、分块等操作。
- 文本嵌入:使用嵌入模型将文本转换为向量表示。
- 向量存储:将向量存储到高效的向量数据库中。
- 检索与生成:通过检索算法找到相关文档,并将其输入到生成模型中生成最终结果。
以下是 RAG 数据流水线的简化示意图:

原始数据 → 数据加载(PDF/数据库/网页) → 预处理(文本清洗/分块) → 向量化(嵌入模型) → 存储 → 检索增强生成
1.3 文档加载器的重要性
文档加载器作为 RAG 系统的第一步,直接决定了后续处理的质量。它需要能够适配多种数据源(如文件、网页、数据库等),并将这些数据转换为统一格式的 Document 对象,便于后续处理。
第二部分:文档加载器的基本概念与分类
2.1 LangChain 中的文档加载器接口
LangChain 提供了一个统一的接口 BaseLoader,用于加载和解析各种类型的文档。该接口的核心设计理念是通过生成器实现惰性加载,避免一次性将所有文档加载到内存中。
class BaseLoader(ABC):"""Interface for Document Loader.Implementations should implement the lazy-loading method using generatorsto avoid loading all Documents into memory at once."""
每个加载器返回一个包含以下字段的 Document 对象:
page_content: 文本内容metadata: 元数据(如来源、创建时间、作者等)
2.2 常见的文档加载器分类
根据数据源的不同,LangChain 提供了多种类型的文档加载器:
2.2.1 文件加载器 (File Loaders)
| 加载器类型 | 功能描述 |
|---|---|
TextLoader | 加载纯文本文件 (.txt) |
CSVLoader | 解析 CSV 文件,按行生成 Document |
PyPDFLoader | 提取 PDF 文本及元数据 |
Docx2txtLoader | 读取 Word 文档 (.docx) |
UnstructuredFileLoader | 通用文件解析(支持多种格式) |
2.2.2 网页加载器 (Web Loaders)
| 加载器类型 | 功能描述 |
|---|---|
WebBaseLoader | 抓取静态网页文本内容 |
SeleniumURLLoader | 处理需要 JavaScript 渲染的页面 |
2.2.3 数据库加载器 (Database Loaders)
| 加载器类型 | 功能描述 |
|---|---|
SQLDatabaseLoader | 执行 SQL 查询并加载结果 |
MongoDBLoader | 从 MongoDB 中读取数据 |
第三部分:常见文档加载器的使用方法与案例实战
3.1 TextLoader - 加载纯文本文件
TextLoader 是最简单的加载器之一,适用于加载纯文本文件。
from langchain_community.document_loaders import TextLoader# 初始化加载器
loader = TextLoader("data/test.txt", encoding="utf-8")
documents = loader.load()print(f"文档长度: {len(documents)}")
print(f"前100个字符: {documents[0].page_content[:100]}")
print(f"元数据: {documents[0].metadata}")
3.2 CSVLoader - 加载 CSV 文件
CSVLoader 可以将 CSV 文件的每一行转换为一个 Document 对象。
from langchain_community.document_loaders import CSVLoader# 初始化加载器
loader = CSVLoader("data/test.csv", csv_args={"delimiter": ","})
documents = loader.load()print(f"文档数量: {len(documents)}")
print(f"第一个文档的元数据: {documents[0].metadata}")
print(f"第一个文档的内容: {documents[0].page_content}")
3.3 PyPDFLoader - 加载 PDF 文件
PyPDFLoader 专门用于加载和解析 PDF 文件,支持按页分割或合并全文。
from langchain_community.document_loaders import PyPDFLoader# 初始化加载器
loader = PyPDFLoader("data/test.pdf")
pages = loader.load()print(f"总页数: {len(pages)}")
print(f"第一页内容: {pages[0].page_content[:200]}...")
print(f"元数据: {pages[0].metadata}")# 加载指定页码范围
pages = loader.load([1, 2, 3]) # 第2页到第4页
3.4 WebBaseLoader - 加载静态网页
WebBaseLoader 可以抓取静态网页的内容,并自动清理 HTML 标签。
import os
from langchain_community.document_loaders import WebBaseLoader# 设置 User-Agent
os.environ['USER_AGENT'] = 'Mozilla/5.0'# 初始化加载器
urls = ['https://www.cnblogs.com']
loader = WebBaseLoader(urls)
docs = loader.load()print(f"提取的文本长度: {len(docs[0].page_content)}")
print(f"前200个字符: {docs[0].page_content[:200]}")
print(f"元数据: {docs[0].metadata}")
3.5 Docx2txtLoader - 加载 Word 文档
Docx2txtLoader 用于加载 Microsoft Word 文档,忽略复杂格式。
from langchain_community.document_loaders import Docx2txtLoader# 初始化加载器
loader = Docx2txtLoader("data/test.docx")
documents = loader.load()print(f"文本长度: {len(documents[0].page_content)}")
print(f"前200个字符: {documents[0].page_content[:200]}")
print(f"元数据: {documents[0].metadata}")
第四部分:高级技巧与问题解决
4.1 图片文本提取
对于包含图片的 PDF 文件,PyPDFLoader 默认无法提取图片中的文本。此时可以结合 OCR 工具(如 RapidOCR-ONNXRuntime)进行处理。
pip install rapidocr-onnxruntimefrom langchain_community.document_loaders import PyPDFLoaderloader = PyPDFLoader("data/pdf-img.pdf", extract_images=True)
pages = loader.load()
print(pages[0].page_content)
4.2 常见问题与解决方案
| 问题描述 | 原因分析 | 解决方案 |
|---|---|---|
| PDF 内容为空 | 扫描版 PDF 或加密文件 | 使用 OCR 工具提取图片文本;解密后加载 |
| 文本分块不理想 | 分块策略不合适 | 调整分块大小或分隔符 |
4.3 批量处理文档
可以通过遍历文件夹的方式批量加载多个文档。
import os
from langchain_community.document_loaders import PyPDFLoaderpdf_folder = "data/"
all_pages = []for filename in os.listdir(pdf_folder):if filename.endswith(".pdf"):file_path = os.path.join(pdf_folder, filename)loader = PyPDFLoader(file_path)all_pages.extend(loader.load())print(f"共加载 {len(all_pages)} 页")
第五部分:未来发展方向与展望
随着自然语言处理技术的不断发展,文档加载器的功能也在不断扩展。未来的发展方向可能包括:
- 更智能的文本提取:结合机器学习算法,提升对复杂文档(如表格、图表)的解析能力。
- 跨平台支持:提供更多轻量级工具,支持移动端和嵌入式设备。
- 多模态数据处理:支持音频、视频等多模态数据的加载与解析。
总结
本文详细介绍了 RAG 系统中的文档加载技术,从基础概念到实际应用进行了全面解析。通过掌握这些技术,你可以更高效地处理多样化的数据源,为构建高性能的 RAG 系统打下坚实的基础。
如果你有任何疑问或建议,欢迎在评论区留言,我们一起探讨!