卷积神经网络基础(十一)
之前学习了四种更新优化路径方法:SGD、Momentum、AdaGrad以及Adam。这篇文章我们将要了解权重的设定方法。
6.2 权重的初始值
6.2.1 权重初始值可以设为0吗?
神经网络学习中权重初始值极为重要,实际上,设定什么样的权重初始值往往关系到神经网络学习的成功与否。本节会介绍权重初始值的设置的推荐值并通过实验确认。
后面我们会介绍抑制过拟合、提高泛化能力的技巧——权值衰减(weight decay)。 也就是通过减小权重参数的值为目的进行学习的方法。通过减小权重参数的值抑制过拟合发生。
如果想减小权重的值,初始值设为较小的值是最好的方法。而实际上,这之前权重初始值都是设定为0.01*np.random(10,100)这样的值,使用高斯分布生成的值乘以0.01后得到的值(标准差为0.01的高斯分布)
如果初始值设为0会不会最好呢?实际上,并不行,这样反而会导致神经网络无法学习。在误差反向传播法中,所有的权重值都会进行相同的更新。比如在两层神经网络中,假设第一层和第二层的权重为0,这样一来,正向传播时输入层权重为0,第二层神经元全部被传递相同的值,这就意味着反向传播时第二层权重全部进行相同的更新。因此,权重被更新为相同的值,并拥有了对称的值。这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化”,严格来说是为了瓦解权重的对称结构,必须随机生成初始值。
6.2.2 隐藏层的激活值分布
观察隐藏层的激活值(激活函数层的输出值,有的文献中会将层之间流动的数据称为“激活值”),的分布,可以获得很多启发。我们通过一个实验来说明,向一个五层神经网络(激活函数为sigmoid)传入随机生成的输入数据,用直方图绘制各层激活值的数据分布。部分代码如下:
import numpy as npimport matplotlib.pyplot as pltdef sigmoid(x):return 1 / (1 + np.exp(-x))x = np.random.randn(1000, 100) # 1000个数据
node_num = 100 # 各隐藏层的节点(神经元)数
hidden_layer_size = 5 # 隐藏层有5层
activations = {} # 激活值的结果保存在这里
for i in range(hidden_layer_size):if i != 0:x = activations[i-1]w = np.random.randn(node_num, node_num) * 1z = np.dot(x, w)a = sigmoid(z) # sigmoid函数activations[i] = a这里假设神经网络有五层,每层100个神经元。然后用高斯分布随机生成1000个数据作为输入数据,并把他们传给五层神经网络。每层的激活值的结果保存在activations变量中。代码段中需要注意的是权重的尺度。虽然这次使用的是标准差为1的高斯分布,但实验的目的是通过改变这个尺度(标准差),观察激活值的分布如何变化。下面我们将保存在activations中的各层数据绘制成直方图。
代码如下:
# 绘制直方图
for i, a in activations.items():plt.subplot(1, len(activations), i+1)plt.title(str(i+1) + "-layer")plt.hist(a.flatten(), 30, range=(0,1))plt.show()运行代码得到如下结果:
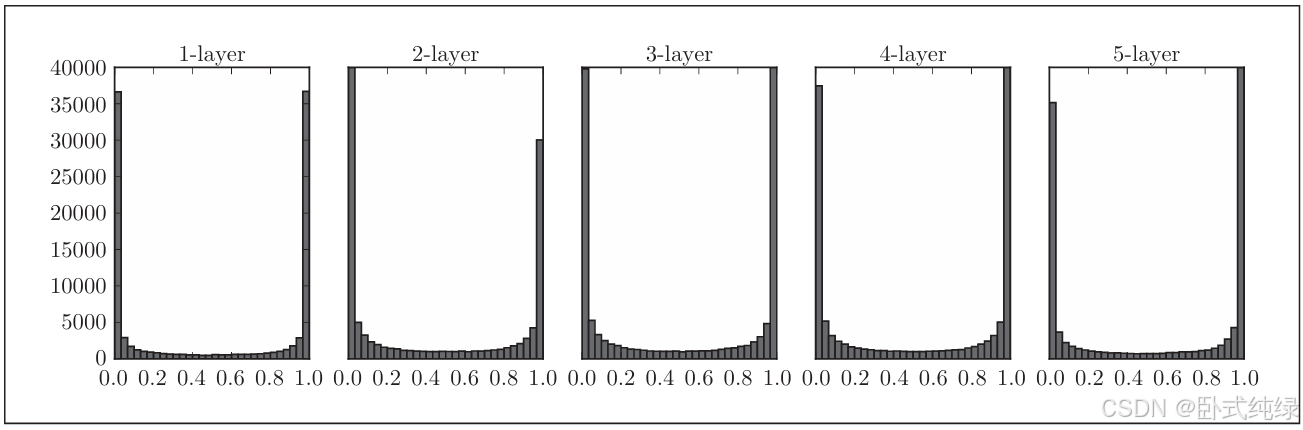
可以看到,各层的激活值呈偏向0和1的分布。sigmoid函数是S型函数,随着输出不断靠近0或1,导数的值逐渐接近0.因此偏向0和1的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失(gradient vanishing)。层次加深的深度学习中这个问题会更加严重。
下面将权重标准差设为0.01,进行相同的实验,实验代码只需要将设定权重初始值的地方换成下面的代码即可:
# w = np.random.randn(node_num, node_num) * 1w = np.random.randn(node_num, node_num) * 0.01得到结果如下:
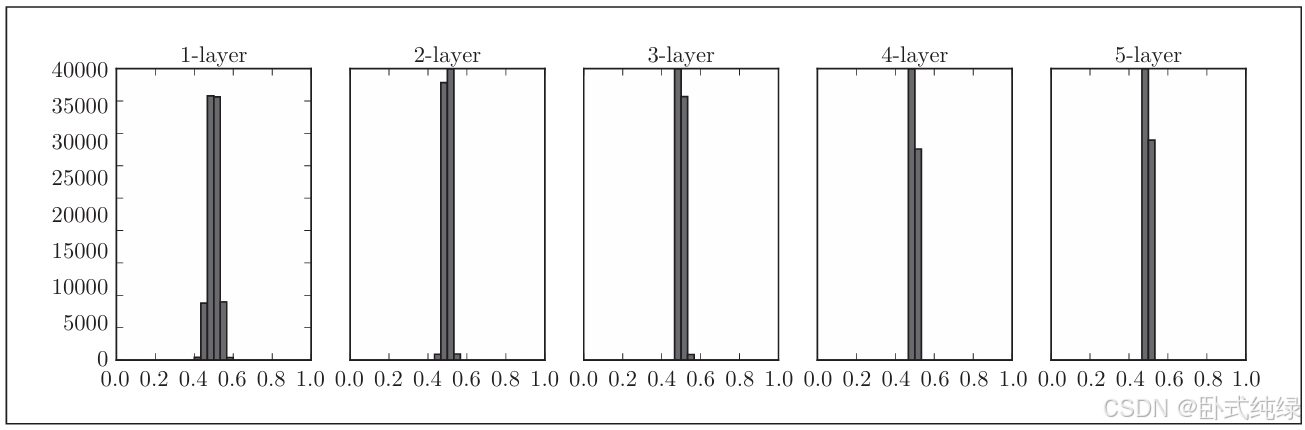
这次集中在0.5附近的分布,不像刚刚偏向0和1,所以不会有梯度消失的问题,但是激活值的分布有所偏向,说明在表现力上会有很大问题。为什么呢?因为如果多个神经元都输出几乎相同的值,那他们的存在就没有意义了。比如,如果100个神经元都输出几乎相同的值,那么也可以由1个神经元来表达基本i相同的事情。因此激活值在分布上有所偏向会出现“表现力受限”的问题。

接着我们使用Xavier Glorot等人论文中推荐的权重初始值。其为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度,推导出的结论是:如果前一层的节点数为n,则初始值使用标准差为的分布。
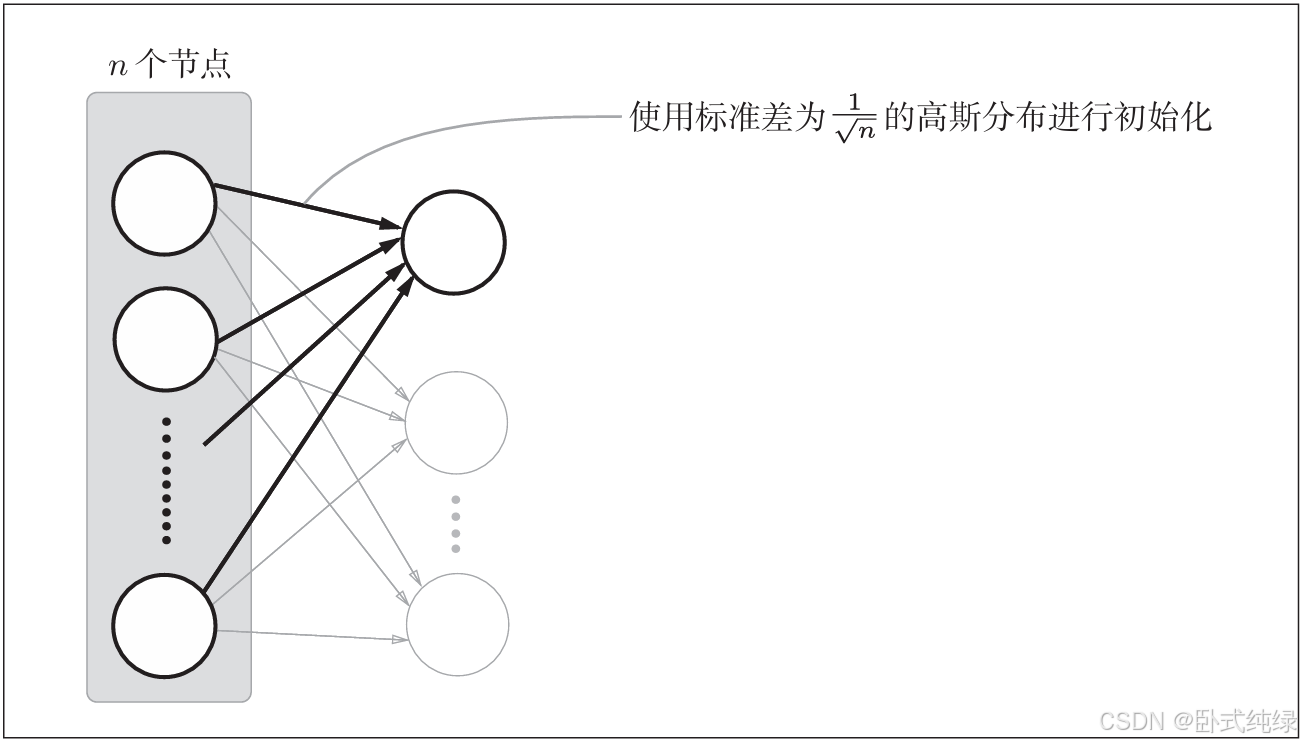
使用该初始值后,前一层节点数越多,要设定为目标节点的初始值的权重尺度就越小。现在使用该初始值进行实验,实验代码只需要将设定权重初始值的地方换成如下内容即可:
node_num = 100 # 前一层的节点数
w = np.random.randn(node_num, node_num) / np.sqrt(node_num)使用该初始值得到的结果如下:
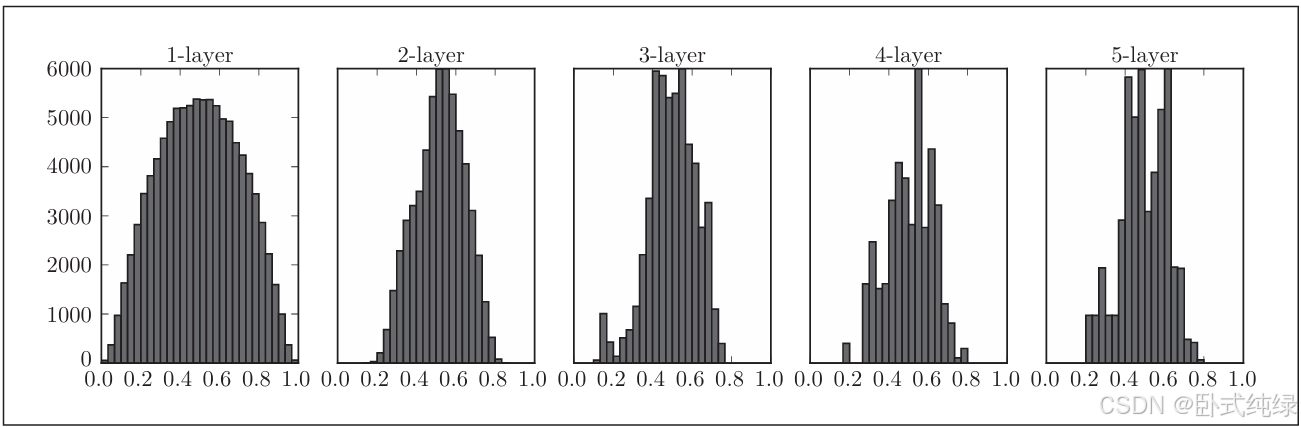
可以看到,越是后面的层,图像越歪斜,但是呈现了比之前更有广度的分布,各层间传递的数据有适当的广度。所以sigmoid函数的表现力不受限制,有望进行更高效的学习。
