文件操作和IO-3 文件内容的读写
文件内容的读写——数据流
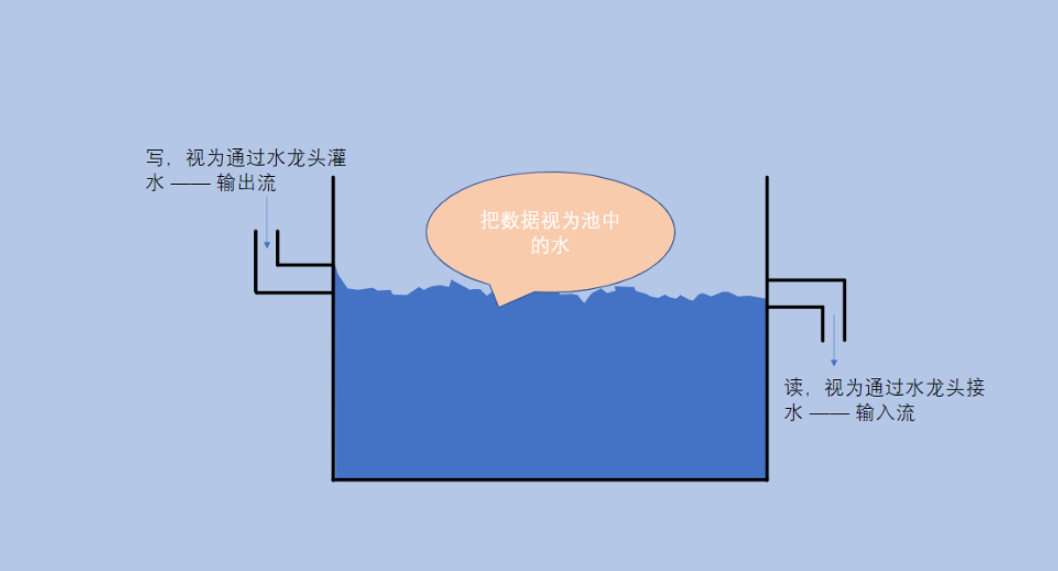
流是操作系统提供的概念,Java对操作系统的流进行了封装。
数据流就像水流,生生不息,绵延不断。
水流的特点:比如要100mL的水,可以一次接10mL,分10次接完,也可以一次接5mL,分20次接完,也可以一次接100mL水一次接完……(此处我们接的方法有无数多种,但最终得到的效果是一样的)
文件中的数据流也是类似的情况:比如要读写100字节的数据,可以一次读写10字节,分10次完成。也可以一次读写5字节,分20次完成。也可以一次读写1字节,分100次读写完。也可以一次读写100字节,1次读完……(此处对小儿的方式也是任意多的情况,最终得到的效果也是一样的)
 Java标准库种对于流进行了一系列的封装,提供了一组类来负责进行这些工作。针对这些类,大概可以两个类别:
Java标准库种对于流进行了一系列的封装,提供了一组类来负责进行这些工作。针对这些类,大概可以两个类别:
1、字节类:以字节为单位进行读写,一次最少读写一个字节。
代表类:InputStream(针对文件进行读操作) OutputStream(针对文件进行写操作)
2、字符流:以字符为单位进行读写,一次最少读取一个字符。比如:如果是utf8编码表示汉字,3个字节表示一个汉字,每次读写都得以3个字节为单位(即以一个汉字为单位)来进行读写
代表类:Reader(针对文件进行读操作) Writer(针对文件进行写操作)
读写文件在编程语言中的固定套路:1、打开文件 2、关闭文件 3、读文件 4、写文件
字节流
InputStream
方法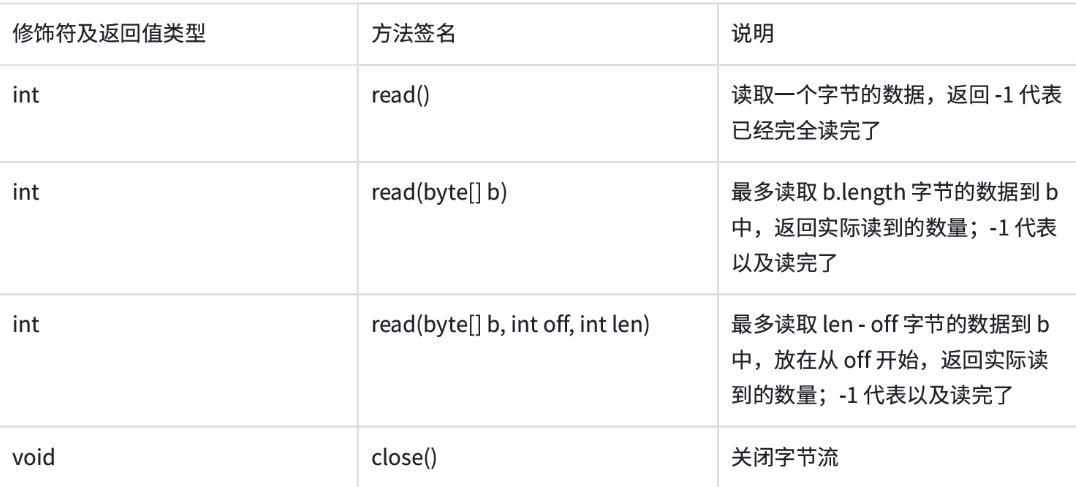
注意:inputStream是一个抽象类,要是有还需要具体的实现类。关于InputStream的实现类有很多,基本可以认为不同的输入类型都可以对应一个InputStream类,我们此处是从文件中读取,使用FileInputStream 。![]()
这是InputStream类的源码,被abstract修饰表示这是一个抽象类。
有些类,我们不希望它能够创建出实例来。就使用abstract来修饰它,编译器就可以进行检查,如果想要创建实例就会编译报错。所谓面向对象,就是通过代码抽象来表示实际事物的一种方式。
抽象这个词语本身很难理解,但是这个词语又是计算机比较常见的词语。那么,我们作为程序员又应该如何理解抽象呢?可以尝试理解抽象的反义词——形象/具体。
如图,这是一只具体的小猫
具体的猫,我们就能看到更多的信息,比如:这只猫是中华田园猫,毛色是黑白相间的,眼睛是棕色的,胡须是白色的……
抽象的小猫:
只具备猫的最基本特征,但无法获得更多的信息。
信息越多,就越具体。信息越少,就越抽象。
我们程序员写代码,很多时候,就是要用抽象的方式来比较表示具体的事物。


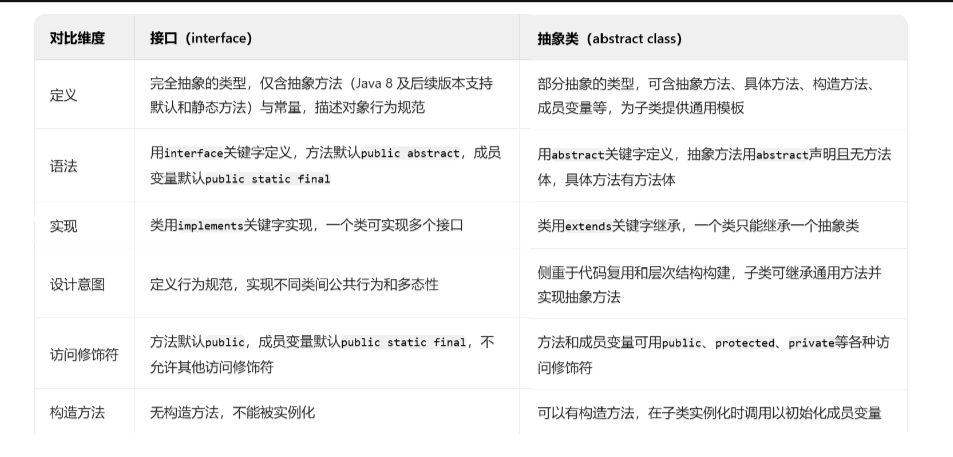
古老的面试题:interface和abstract之间的区别
FileInputStream
构造方法
实例化FileInputStream对象的过程,也就是打开文件的过程。
代码如下:
public static void main(String[] args) throws FileNotFoundException {InputStream inputStream = new FileInputStream("./test.txt");}注意:在创建FileInputStream对象时需要抛出一个FileNotFoundException(文件未被找到)异常!!!
我们刚才讲过,在各种编程语言中,读写文件需要打开文件、关闭文件、读文件、写文件。我们现在既然打开了文件,就要考虑关闭文件。
close方法
关闭文件需要使用close方法,这个方法同样也需要抛出一个IOException,它是上面的FileNotFoundException的父类,所以我们总的只需要抛出一个IOException。
public static void main(String[] args) throws IOException {InputStream inputStream = new FileInputStream("./test.txt");inputStream.close();}关闭文件的操作,也可以理解是释放了文件的相关资源。
我们在计算机是如何工作那篇博客中讲过,进程是由一个PCB(进程控制块)组成的,PCB中有一个属性是文件描述符表,记录了当前进程都打开了那些文件。用顺序表/数组存储,数组中的每个元素都是一个结构体,这个结构体就具体地描述了打开的文件在文件系统上的一些属性。每次打开一个文件,都是需要在文件描述符表中占据一个位置的,如果不关闭一直打开的话,就会导致文件描述符表被耗尽(文件描述符表的长度是有上限的)。当文件描述符表被耗尽了以后,后续打开文件就会打开失败,从而导致文件资源泄露,内存泄漏。
那为什么文件描述符表不能整个像ArrayList一样的自动扩容机制呢???
这会付出很大的代价,对于操作系统内核来说对于性能的要求是很高的,内核的任务很重,所以对性能的要求会很高,如果要进行上述自动扩容操作,要十分慎重。有可能因为扩容引起了系统卡顿,就得不偿失了
而内存泄漏问题,由于Java提供了GC(垃圾回收机制),我们不太需要担心内存泄漏问题,相当于是给我们的家里请了一位保洁阿姨,每隔一段时间就会帮我们收拾屋子,丢丢垃圾啥的。
如果我们的代码像上面那么写,那么是有可能执行不到关闭文件这里的(中间执行其他逻辑时可能会有return或者抛出异常):
public static void main(String[] args) throws IOException {//打开文件InputStream inputStream = new FileInputStream("./test.txt");//其他逻辑//关闭文件inputStream.close();}所以我们可以使用finally来确保这一步close方法一定能执行到。但又出现问题了:inputStream是在try代码块中被实例化的,是一个局部变量,在finally里面根本不认识inputStream这个变量。所以我们需要将inputStream定义在try的外面。
代码如下:
public static void main(String[] args) throws IOException {InputStream inputStream = null;//打开文件try {inputStream = new FileInputStream("./test.txt");//其他逻辑}finally {//关闭文件inputStream.close();}}Java中还提供了另一个版本:try-with-resources。注意:只有实现了Closeable接口的类,才能使用该方法,此时try方法就会自动帮我们调用close方法释放资源了。
代码如下:
public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {}}read方法

第一个:无参数版本,每次调用读取一个字节,返回值是读取到的这个字节的值,看起来返回值是int,实际上是byte,因为这个方法读到文件的末尾继续读会返回-1(byte的取值范围是0~255),所以看起来返回值是int。
第二个:一个参数,传入的参数是字节数组,是一个“输出型参数”。从输入流中读取一定字节并将其存储到缓冲区数组b中。(此处的byte[ ]是引用类型,方法内部针对数组内容进行修改,方法执行结束之后,方法外部也仍然生效)。
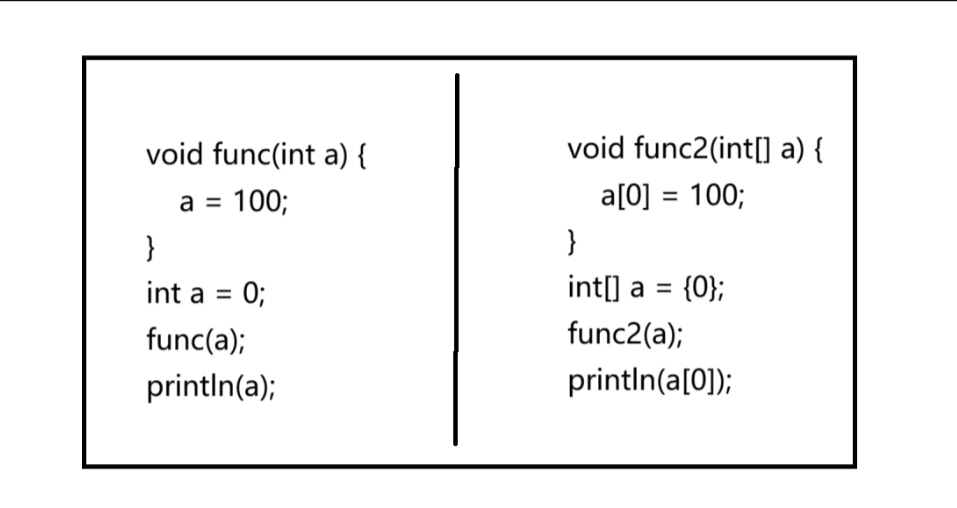
上面两组代码的打印分别是多少呢?
第一组的打印结果是0。原因:func方法外的a是实参,而在func方法中传入的a是形参,函数对形参的修改,并不会改变函数实参的值,所以打印的结果仍然为0。
第二组的结果是100。原因:方法内部是针对数组内容进行修改的,数组是引用类型,a[0] = 100是解引用操作,方法执行结束之后,方法外部也能生效。
那这个代码的结果是啥呢?
结果是“”。原因:上面代码执行的操作实际上是对引用赋值(并非是解引用操作),也就相当于方法内的形参引用s指向了一个新的对象(字符串),而方法外实参所指向的对象并没有改变。

第三个:第三个参数版本,大体和第二个版本一样,只是增添了开始和结束的位置。off-->offset
注意:read的第二个和第三个版本,返回的int就不是读取到的值了,而是实际读取到的字节的个数。默认情况下,read会尝试把数组填满,但是文件的实际剩余的长度可能并不足以被填满,所以返回值会告诉我们实际填了多少个字节。
代码示例:
首先,先准备好我们要读的文件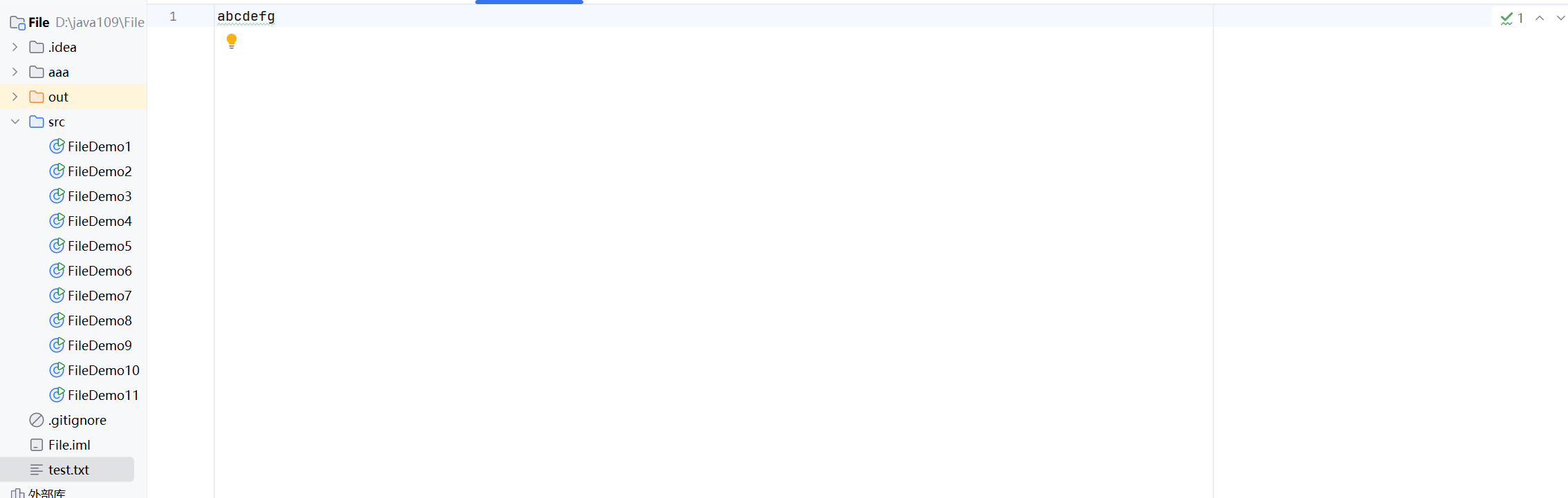
下面,我们将编写代码以16进制的形式打印上面的文件:
public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {while(true) {int x = inputStream.read();if(x == -1){break;}System.out.printf("%x ",x);}}}因为是以16进制的形式打印,所以输出结果是61 62 63 64 65 66 67:
一个参数的版本:
public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {while(true) {byte[] buffer = new byte[1024];int x = inputStream.read(buffer);if(x == -1){break;}for (int i = 0; i < x; i++) {System.out.printf("%x ",buffer[i]);}}}}打印结果:
buffer也是计算机中的常用术语,表示“缓冲器”,往往是一个内存空间。读文件是把硬盘中的数据读到内存中,上面的写法,一次能够读若干个字节,要比一次读一个字节更加高效。
操作硬盘,本身就是一个比较低效的操作,我们程序员期望的是,低效的操作,出现的次数越少越好,效率就会更高!!!
如果此时test.txt文件中的是汉字的话,我们也可以基于字节数组构成String进行打印。
先把刚才的文件内容改成汉字:
代码如下:
public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")) {while(true) {byte[] buffer = new byte[1024];int x = inputStream.read(buffer);if(x == -1){break;}String s = new String(buffer,0,x);System.out.println(s);}}}注意:在 String s = new String(buffer, 0, n); 此处构造 String 是通过前 n 个字节构造,而不是整个数组,实际读取文件的内容可能不足 1024个字节。
OutputStream
方法:
OutputStream同样是一个抽象类,使用时也是需要具体实现类。
FileOutputStream
write方法:

第一个版本:一次写一个字节。
第二个版本:一次写若干个字节。
第三个版本:将若干个字节写在数组的指定部分。
代码示例:
public static void main(String[] args) throws IOException {try(OutputStream outputStream = new FileOutputStream("./test.txt")){byte[] buffer = new byte[]{97,98,99,100,101,102,103};outputStream.write(buffer);}} 运行结果:
可以看到我们刚才的“你好”被消除了,然后重新写上了abcdefg(97~103对应得ASCLL码值)。
注意:此处的OutputStream操作默认会把文件之前的内容清空掉,然后从头重新写!!!(并不是write方法引起的,而是在打开文件时就已经清除了)
如果我们想在原来写的基础上添加内容,也可以使用追加写的方式,不清空文件内容,把新的内容写到文件末尾。
只需要在创建OutptStream对象时,在后面追加一个append参数即可:
执行结果:

字符流
Reader
Reader的使用方法和InputStream差不多 ,但是此处读就是以1个字符为最小单位了。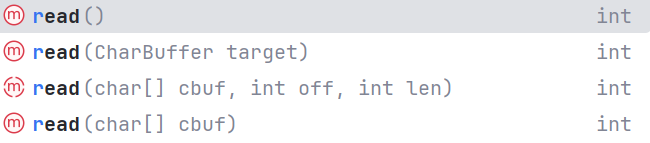
代码如下:
public static void main(String[] args) throws IOException {try(Reader reader = new FileReader("./test.txt")){while(true) {char[] butter = new char[1024];int n = reader.read(butter);if (n == -1){break;}for (int i = 0; i < n; i++) {System.out.print(butter[i] + " ");}}}}文件内容: 
运行结果:

那此时大家可能就会有疑问,一个字符不是占2个字节吗?那如果文件里的是中文,中文按照utf8编码,每个字符是3个字节,但是此处读取来的字符这么就成2个字节了呢 ?
代码如下:
public static void main(String[] args) throws IOException {try(Reader reader = new FileReader("./test.txt")){while(true) {char[] butter = new char[1024];int n = reader.read(butter);//read时会把utf8转为unicodeif (n == -1){break;}String s = new String(butter,0,n);//基于unicode构造成StringSystem.out.println(s);}}}上面的代码,相当于把文件中的utf8编码在按照字符读取的时候,先转成unicode,每个char里面存储的是对应的unicode的值。然后基于unicode最终再构造成utf8的String(这个过程已经被Java内部封装过了,没办法直接感受到~~)。
先把文件改成中文字符:
运行结果如下:


Writer
Writer字符流和OutputStream的使用方法差不多,只是和Reader一样以1字符为最小单位进行写操作。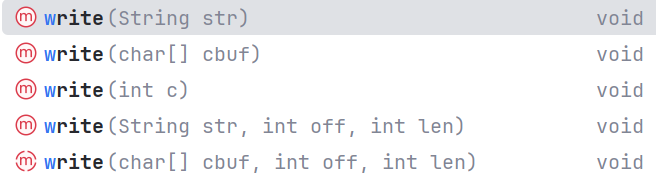

代码示例:
public static void main(String[] args) throws IOException {try (Writer writer = new FileWriter("./test.txt",true)){char[] buffer = new char[]{97,98,99,100};writer.write(buffer);}} 运行结果:
总结:
补充:也可以使用Scammer来辅助我们进行读取文件,Scanner里面的System.in本质上就是一个InputStream。
代码示例:
public static void main(String[] args) throws IOException {try(InputStream inputStream = new FileInputStream("./test.txt")){Scanner scanner = new Scanner(inputStream);while(scanner.hasNext()){String s = scanner.next();System.out.println(s);}}}运行结果:
