【语法】C++的map/set
目录
平衡二叉搜索树
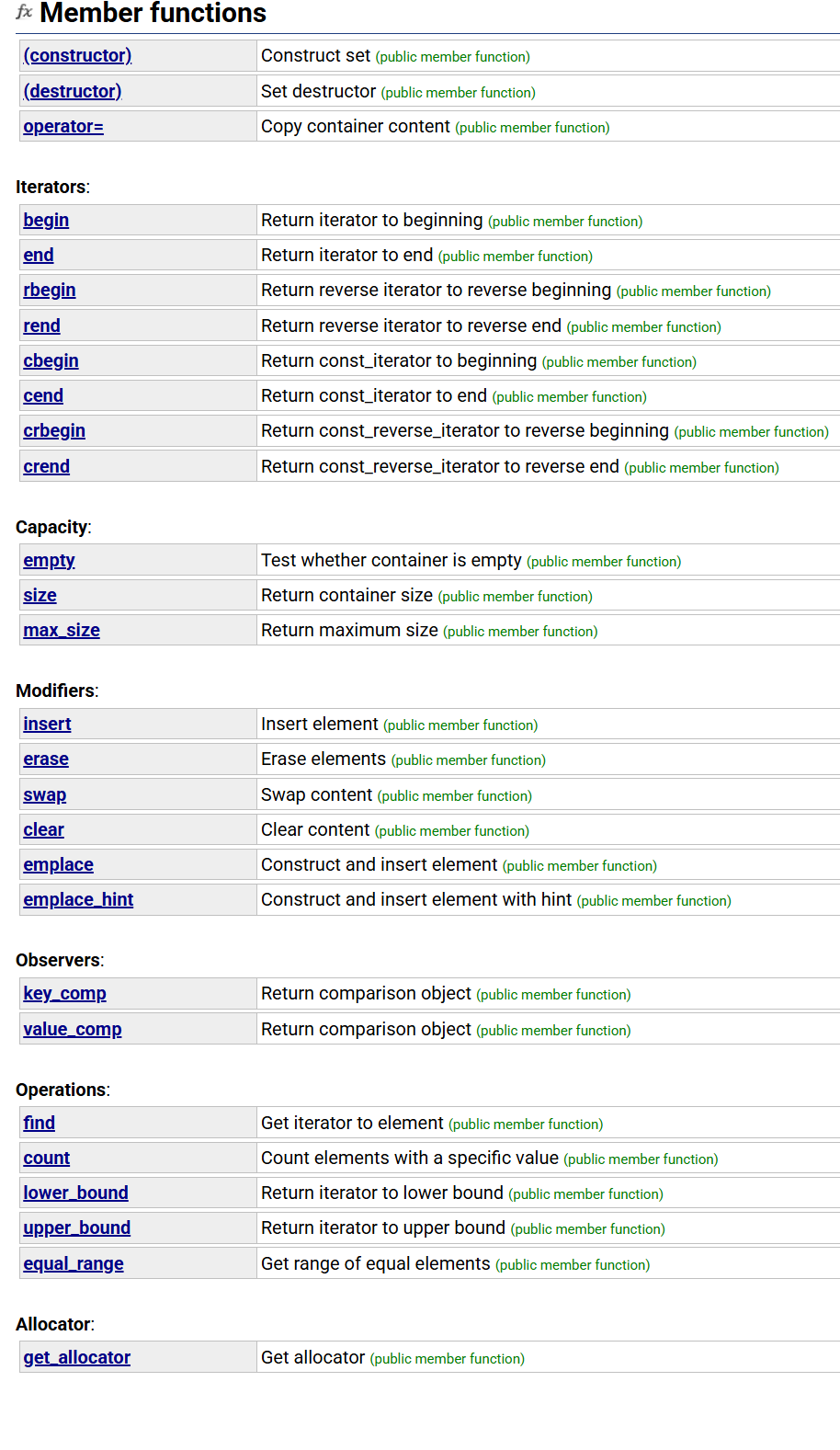
set
insert()
find()
erase()
swap()
map
insert()
迭代器
erase()
operator[]
multiset和multimap
在之前学习的STL中,string,vector,list,deque,array都是序列式容器,它们的特点是元素按照线性顺序排列,并且可以通过位置(索引)来访问元素;stack,queue,priority_queue都是容器适配器,它们基于现有的容器(如vector,deque,list)提供特定的接口,实现特定的数据结构。
而本篇要学习的map/set是关联式容器,它们的特点是通过键值对存储数据,支持高效的查找操作,元素通常按某种排序规则组织。
map/set的底层就是二叉搜索树,若对二叉搜索树不了解的,可以去看这篇博客
【数据结构】map_set前传:二叉搜索树(C++)
只不过在二叉搜索树的基础上加入了平衡机制,即平衡二叉搜索树
平衡二叉搜索树
众所周知,二叉搜索树的优势是找到一个数据的时间复杂度为O(logN),而在数组中是O(N)
但下面二叉搜索树中查找数据的时间复杂度还是O(logN)吗?
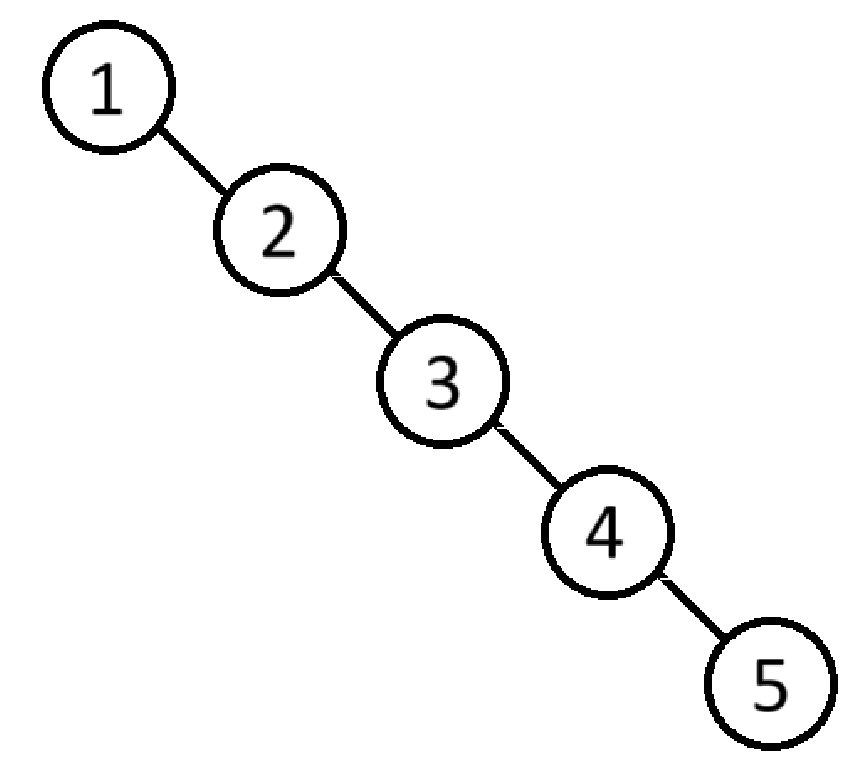
若只有一边有数据,就失去了搜索树的特性,现在的时间复杂度就变为了O(N)
为了解决这个问题,就引入了平衡一概念
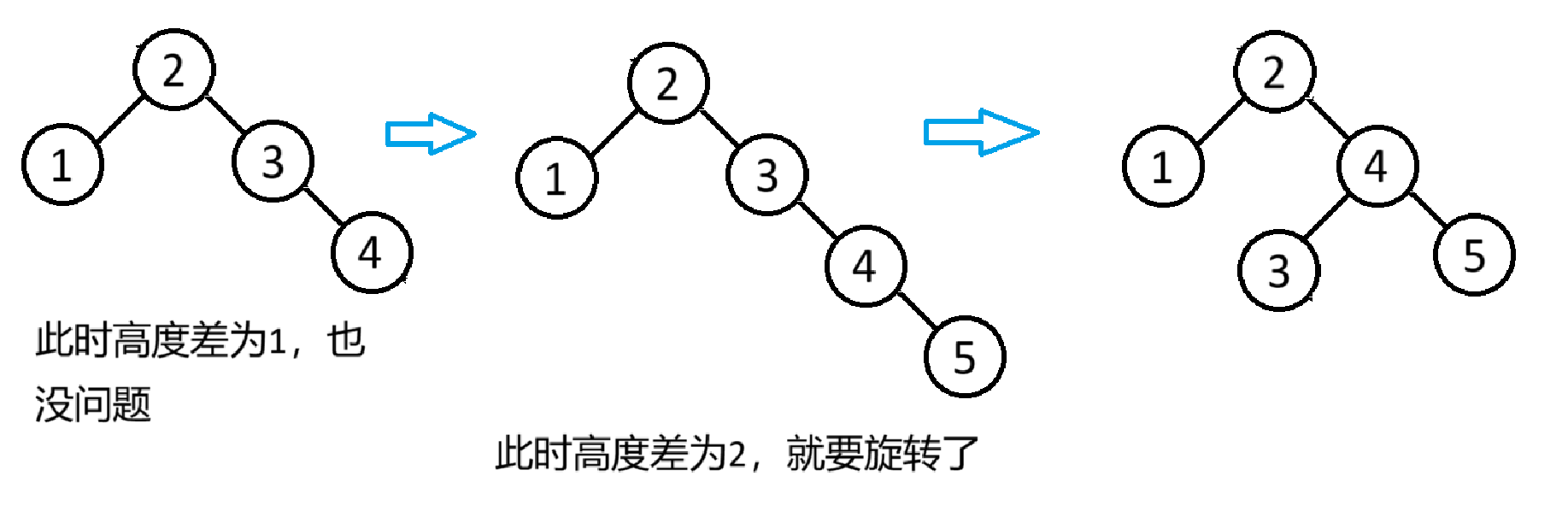
在平衡二叉搜索树中,若根节点的左右子树高度差超过1,就会发生旋转
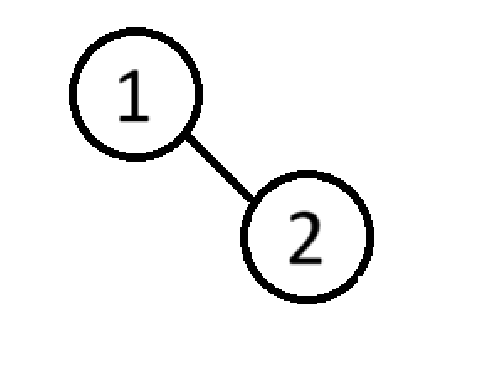
此时这棵树的左右子树高度差为1,不会发生旋转
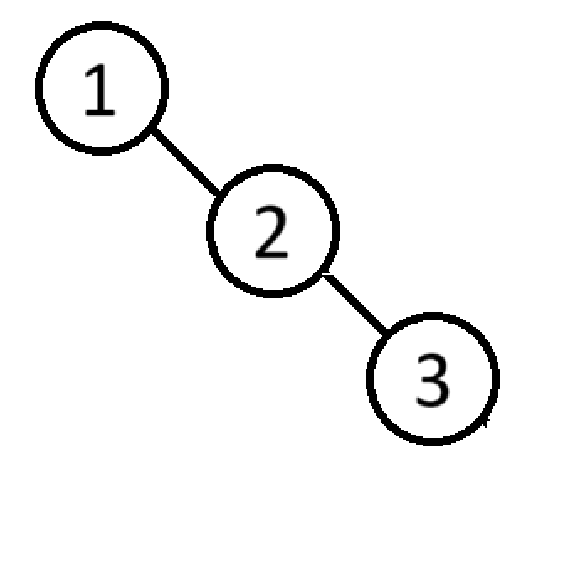
但此时左右高度差为2,就会发生旋转
具体旋转的原理在模拟实现map/set时会讲到
set和map的区别就是set是K模型,而map是K/V模型
set

set模板中,第一个参数是key的类型,第二个是一个仿函数,默认为less,即比根小放左边,比根大放右边,若传的是greater<T>,则比根大的放左边,比根小的放右边。第三个参数即内存分配器,暂时不用管
set的用法和前面学过的容器都大差不差,这里就挑几个重点的讲
insert()
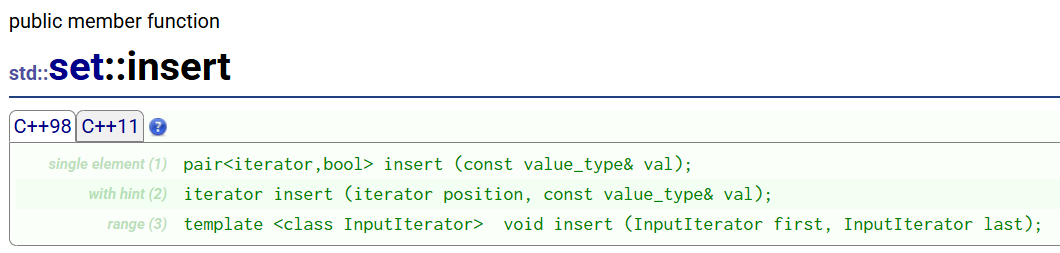
一般只会用第一个,剩下两个用的非常少
map/set中只能用insert来添加数据,因为它们是关联式容器,不能像序列式容器一样尾插头插
#include <iostream>
#include <set>
using namespace std;int main()
{set<int> s;s.insert(4);s.insert(1);s.insert(4);s.insert(2);for(auto& e : s)cout << e << " ";return 0;
}输出结果:

map/set在遍历数据时只能用迭代器或范围for(范围for底层其实也是迭代器),并且默认是升序排列,也就是中序遍历,若在定义时Compare参数设置成了greater<T>,输出时就会按降序排列
并且map/set中不允许有重复值的出现,所以这里虽然插入了两次4,但树中只会有一个
所以map/set还有个作用是排序+去重
和二叉搜索树一样,map/set中的key也是不允许修改的,因为修改会破坏搜索树的结构
如果尝试修改一个数据,就会编译报错
int main()
{set<int> s;s.insert(4);s.insert(1);s.insert(4);s.insert(2);set<int>::iterator it;for(it=s.begin();it!=s.end();it++)*it = 1;return 0;
}
find()
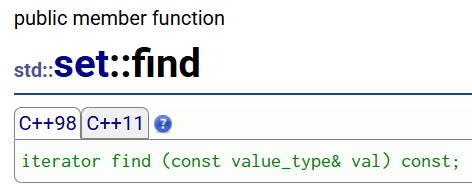
find用来查找一个key,并返回它的迭代器,若没有找到,就返回最后一个元素的下一个位置的迭代器,即end()
但除了map/set中提供的find,<algorithm>库中也有一个通用find函数

它也同样可以完成map/set中查找数据的工作
int main()
{set<int> s;s.insert(4);s.insert(1);s.insert(4);s.insert(2);set<int>::iterator it1 = s.find(4);//map/set库中的findcout << *it1 << endl;set<int>::iterator it2 = find(s.begin(), s.end(), 4);//<algorithm>库中的findcout << *it2 << endl;return 0;
} 输出结果:

它们两个确实都可以完成查找的工作,但他们的时间复杂度不一样
map/set库中的find函数,用的是搜索树的特性去查找数据,时间复杂度为O(logN),<algorithm>库中的find函数因为是通用的,所以只会从左往右依次去找,所以时间复杂度为O(N)
<algorithm>库的find函数实现:

erase()
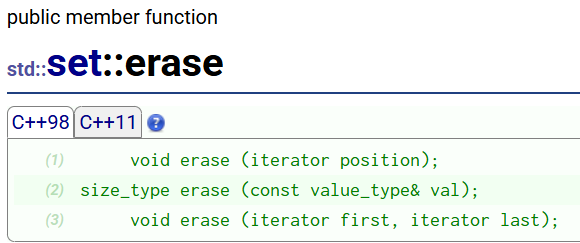
map/set只允许用erase来删除数据,没有头删,尾删。
这里介绍前两种用法
第一种用法是传要删除节点的迭代器。既然要传迭代器,那就可以用到find先来返回一个数据位置的迭代器
int main()
{set<int> s;s.insert(4);s.insert(1);s.insert(4);s.insert(2);set<int>::iterator it = s.find(1);s.erase(it);for(auto i : s)cout << i << " ";return 0;
}输出结果:
然而这样还有些不妥,如果要查找的数在树中没有,删除时就会报错
因此,要加个判断条件,上面说过,当find函数未找到时会返回end()
int main()
{set<int> s;s.insert(4);s.insert(1);s.insert(4);s.insert(2);set<int>::iterator it = s.find(9);if(it != s.end())//如果找到数据才会删除s.erase(it);for(auto i : s)cout << i << " ";return 0;
}erase除了可以传迭代器,还可以传一个具体的数据
int main()
{set<int> s;s.insert(4);s.insert(1);s.insert(4);s.insert(2);s.erase(1);for(auto i : s)cout << i << " ";return 0;
}输出结果:
如果直接传值的方式给函数传了一个不存在的值,也不会报错,因为函数内部也是第一种穿迭代器找法的步骤
set<int>::iterator it = s.find(1);
if(it != s.end())s.erase(it);
//等同于下面
s.erase(1);swap()

map/set中也有内置的swap函数,set的swap用于完成两个set对象的交换,map同理。而众所周知, <algorithm>库中也有一个swap函数,同样可以交换两个同类型对象
int main()
{set<int> s1;for(int i = 1;i<10;i++)s1.insert(i);set<int> s2;for(int i = 10;i<20;i++)s2.insert(i);s1.swap(s2);//set自带的swap(s1,s2);//算法库中的for(auto i:s1)cout<<i<<" ";cout<<endl;for(auto i:s2)cout<<i<<" ";cout<<endl;return 0;
}输出结果:

可以看到,两个swap都可以实现交换
map/set中内置的swap,因为是树型结构,所以只需要交换头结点即可,时间复杂度是O(1),但算法库中的swap平常来说需要将容器中的全部数据一一交换,时间复杂度为O(N)。
但是,swap会针对STL中的容器进行特化,当然,也包括map/set,当算法库中的swap中参数为map/set类型时,会去调用map/set内的swap完成交换操作。
所以,对于map/set来说,两个swap一样
不过自定义类型就没这么好运了,除非自己加上针对这一类型的特化
map
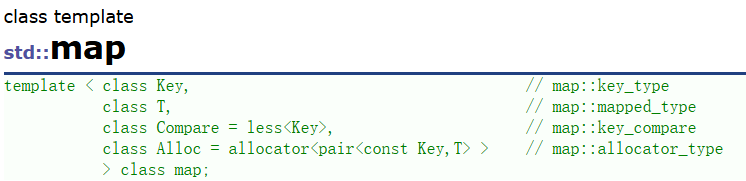
map是K/V模型,所以比set多了一个参数T,即value
在讲map的其他接口前,需要先了解一下pair类
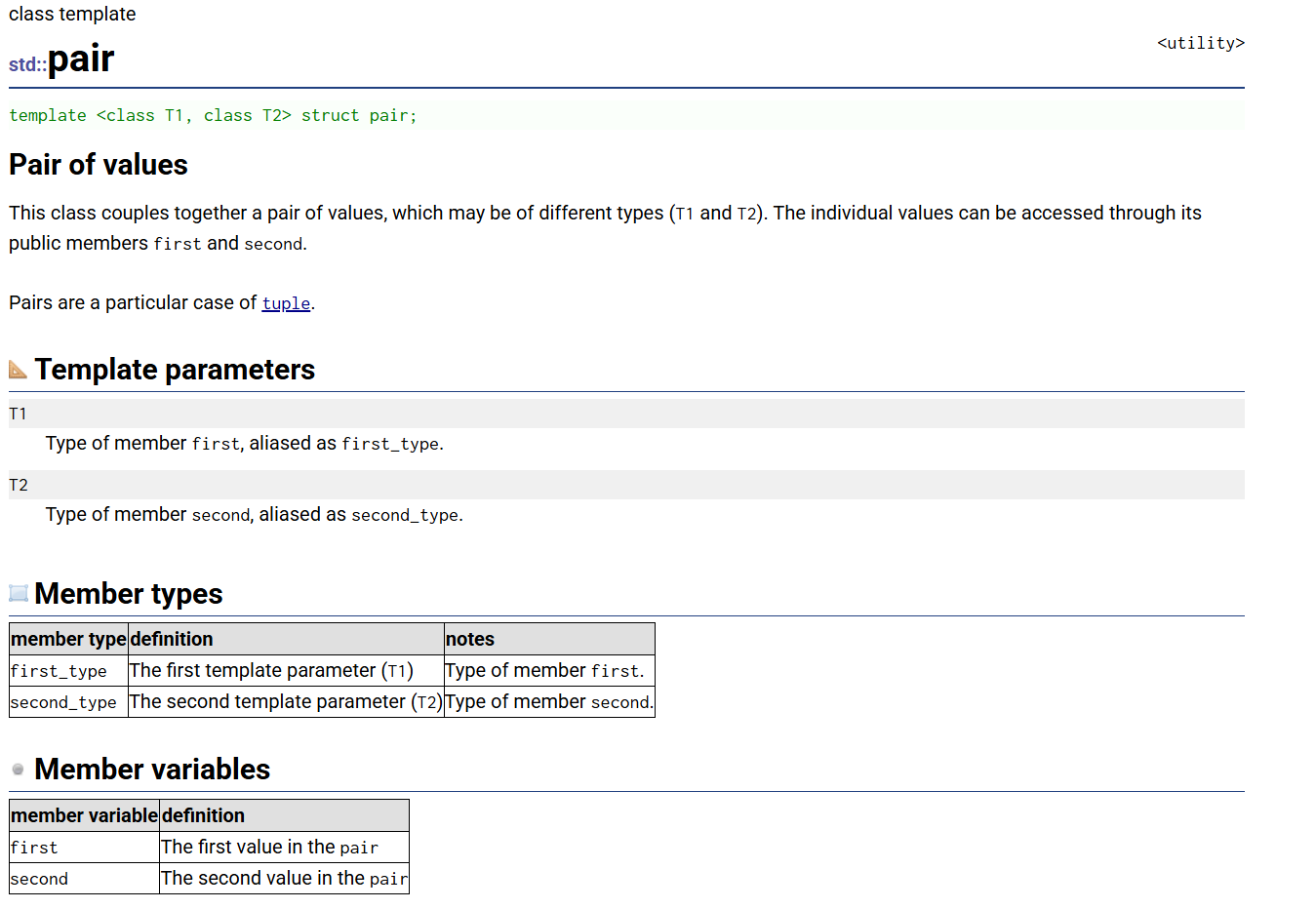
简单点说,pair类用于存一个键值对,first成员变量用于存key,second成员变量用于存value
map的大部分接口也和set差不多,这里也只挑几个比较重要的说
insert()
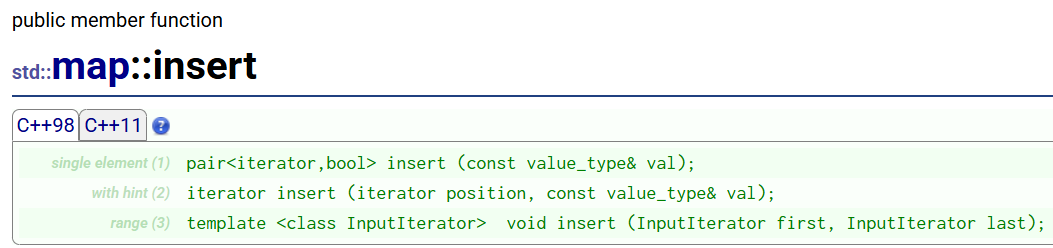
map的insert和set的有点不一样,可以看到,它要传的参数是一个value_type类型,这是个什么东西?
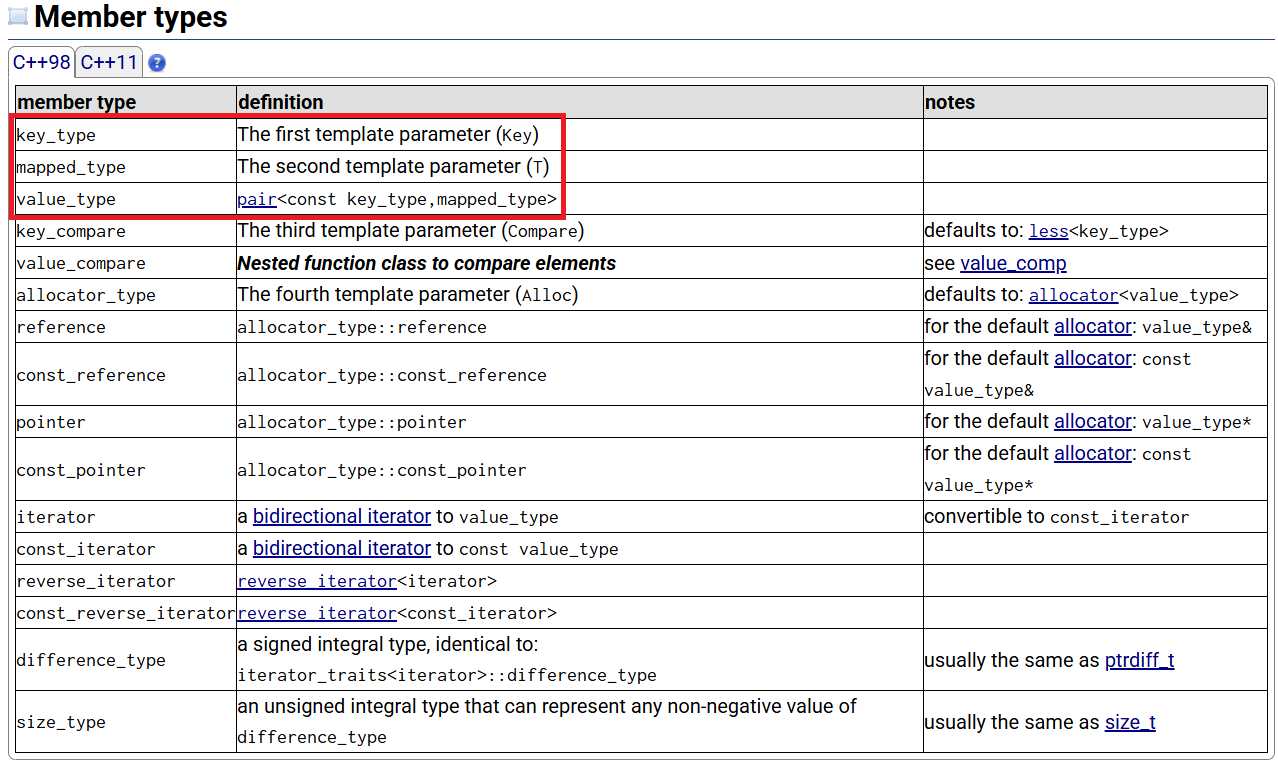
通过查文档,可知value_type其实是指的刚才说过的pair,而pair中要传的key_type和mapped_type其实分别是pair的first和second值
而map的insert不能像下面这样传参
m.insert(1,1);必须传一个pair类型
m.insert(pair<int,int>(1,1));//匿名对象第一个参数是K/V模型中的key,第二个参数是K/V模型中的value
既然insert中传的参数是pair,就代表map中节点所存的数据就是pair类型
全局中有一个函数叫make_pair

可以根据两个参数返回一个pair类型
make_pair的实现:

所以更多人会喜欢这样传参
m.insert(make_pair(1,1));这样不需要传两个模板类型,make_pair函数会自动推演,更简便
并且,map/set的insert的返回值都是一个pair<iterator,bool>类型,这是干什么用的呢?
前面说过,map/set不允许有重复数据,所以如果插入重复数据会插入失败,要判断是否插入失败,就需要用到这个返回值
这是set::insert的返回值描述

这是map::insert的返回值描述

两者返回的都是一个pair<iterator,bool>类型,对于iterator,若插入的值本来树中没有,就指向新插入值的迭代器,若插入的值树中已经有了,就指向这个元素的迭代器;对于bool,若插入的值本来树中没有,就是true,若插入的值树中已经有了,就是false
int main()
{set<int> s;s.insert(1);pair<set<int>::iterator,bool> p =s.insert(1);//插入重复数据cout << "pair::first is " << *(p.first) << ";\t" << "pair::second is "<< p.second << endl;map<int,int> m;m.insert(pair<int,int>(1,1));pair<map<int,int>::iterator,bool> q =m.insert(pair<int,int>(1,1));//插入重复数据cout << "pair::first is " << q.first->first << ":" << q.first->second << ";\t" << "pair::second is " << q.second << endl;return 0;
}输出结果:

迭代器
既然map的节点中锁存的是pair类型,那按照之前的迭代器方法就肯定不行了
int main()
{map<int,int> m;m.insert(pair<int,int>(1,1));m.insert(pair<int,int>(2,2));m.insert(pair<int,int>(3,3));map<int,int>::iterator it = m.begin();while(it!=m.end()){cout << *it << endl;it++;}return 0;
}报错:
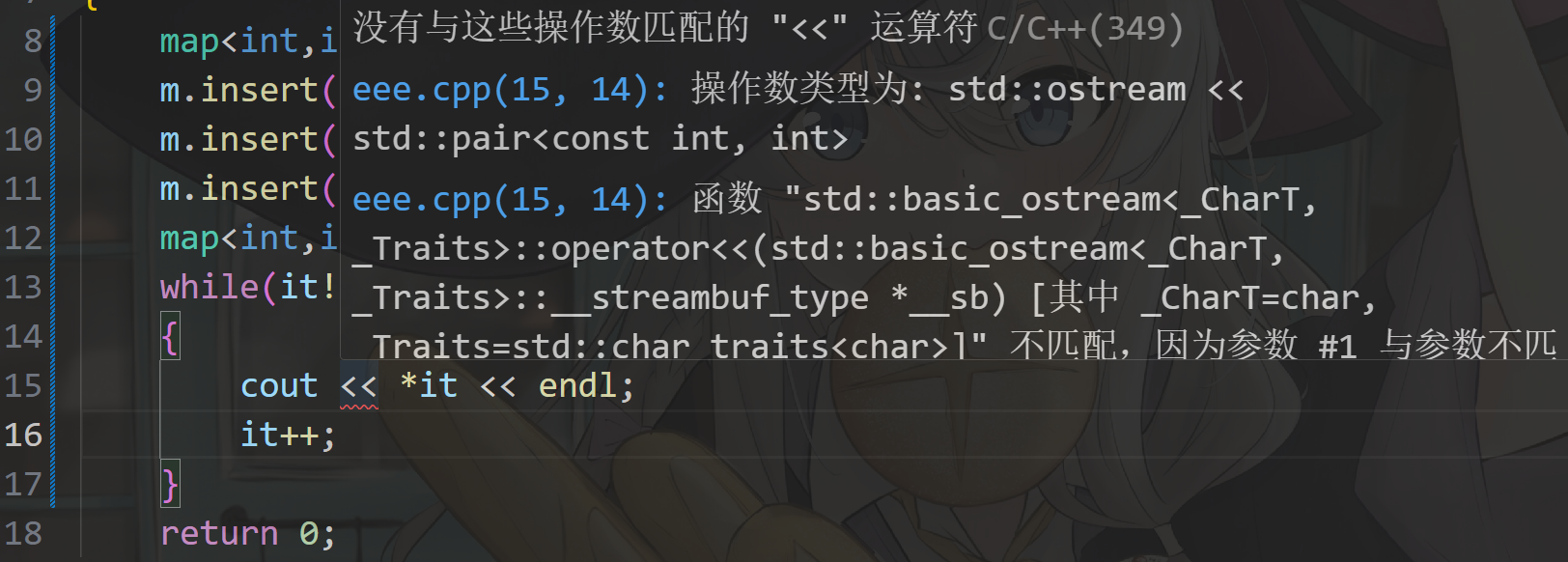
因为此时迭代器解引用返回的是一个pair类型,pair中有两个变量,再加上并没有给pair类型重载<<运算符,这里就会报错
那么我们可以指定要输出pair类型中的哪一个值
int main()
{map<int,int> m;m.insert(pair<int,int>(1,1));m.insert(pair<int,int>(2,2));m.insert(pair<int,int>(3,3));map<int,int>::iterator it = m.begin();while(it!=m.end()){cout << (*it).first << " " << (*it).second << endl;//first就是key, second就是valueit++;}return 0;
}输出结果:
在map中,迭代器的*运算符重载就是会返回一个pair类型,但->运算符重载会返回一个pair类型指针
int main()
{map<int,int> m;m.insert(make_pair(1,1));m.insert(make_pair(2,2));m.insert(make_pair(3,3));map<int,int>::iterator it = m.begin();while(it != m.end()){cout << it->first << " " << it->second << endl;//map迭代器的->运算符重载返回一个pair指针it++;}cout<<endl;return 0;
}有些人可能会问:既然->返回的是一个pair指针,那不应该再解引用一次才能取到值吗?
例如it->->first。
这是因为当调用operator->()时,如果返回的是一个指针,会自动进行解引用操作,因此,it->first已经隐含了两次"->"操作 ,无需再加一次解引用
或者用范围for
int main()
{map<int,int> m;m.insert(pair<int,int>(1,1));m.insert(pair<int,int>(2,2));m.insert(pair<int,int>(3,3));for(auto& i : m)cout << i.first << " " << i.second << endl;return 0;
}erase()
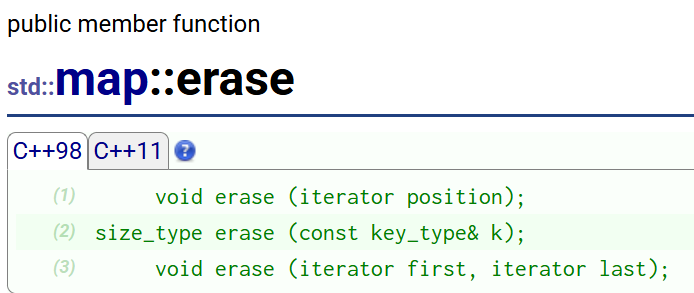
这里的erase用法和set的一样,都是可以传一个迭代器或具体的key,但需要注意的是,不能通过传value来删除
//传迭代器的方法
map<int,int>::iterator it = m.find(1);//找到key为1的节点
if(it!=m.end())//如果找到该节点m.erase(it);//删除key为1的节点
//传key的方法
m.erase(1);//如果找到key为1的节点,则删除operator[]
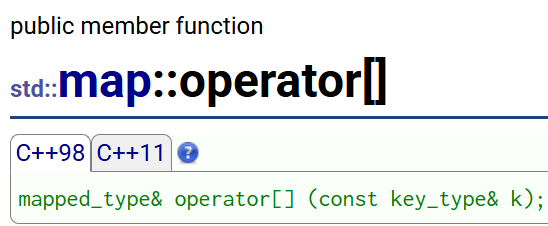
"[]"重载可以取出指定key位置的value
int main()
{map<string,string> m;m.insert(make_pair("string","字符串"));m.insert(make_pair("int","整数"));m.insert(make_pair("for","循环"));m.insert(make_pair("while","循环"));cout <<"for:" << m["for"] << endl << "while:" << m["while"] << endl;return 0;
}
接下来讲讲map的一个应用层面——频率统计
通过遍历数据,将元素作为键,出现次数作为值,可以方便地统计每个元素的出现频率。
int main()
{vector<string> s = {"塞尔达","林克","究极手","林克","呀哈哈","塞尔达"};map<string,int> cnt;//统计每个字符串所出现的次数for(const auto& i : s)//遍历数组{map<string,int>::iterator it = cnt.find(i);if(it != cnt.end())//如果这个字符串已经出现过,则次数加1it->second++;else//如果没有出现过,则插入一个字符串,次数为1cnt.insert(make_pair(i,1));}for(const auto& i : cnt)cout << i.first << " " << i.second << endl;return 0;
}输出结果:

但现在知道insert的返回值后,其实可以用返回值来判断插入是否成功
int main()
{vector<string> s = {"塞尔达","林克","究极手","林克","呀哈哈","塞尔达"};map<string,int> cntMap;//统计每个字符串所出现的次数for(const auto& i : s)//遍历数组{pair<map<string,int>::iterator,bool> p = cntMap.insert(make_pair(i,1));//插入一个节点if(p.second == false)//如果插入失败p.first->second++;//就让原本的节点value+1}for(const auto& i : cntMap)cout << i.first << " " << i.second << endl;return 0;
}输出结果和上面的也是一样的
但如果用"[]"来解决这个问题,会发现非常简单
int main()
{vector<string> s = {"塞尔达","林克","究极手","林克","呀哈哈","塞尔达"};map<string,int> cnt;//统计每个字符串所出现的次数for(const auto& i : s)//遍历数组{cnt[i]++;}for(const auto& i : cnt)cout << i.first << " " << i.second << endl;return 0;
}该程序也可以实现和上面一模一样的输出,那"[]"的原理是什么呢?
调用"[]"其实就等价于下面代码
(*((this->insert(make_pair(k,mapped_type()))).first)).second
//k是传过去的key简单剖析一下就是这样

对于insert的返回值,上面说过,是一个pair<iterator,bool>类型,这里取出返回值的first,也就是取出插入值的迭代器,再取出second,也就是取出该键值的value
对于没有插入过的键值,返回值的first成员会指向新插入键值的迭代器,再取出该迭代器的second成员,也就是value。这里的value会插入为默认值,若是int就是0,若是sting就是空字符串。对于int的情况,在0的基础上++就是1;即operator[]会插入pair<str,0>,返回映射对象(value)的引用对它++;
对于插入过的键值,这里会插入失败,但iterator还是指向树中已有的那个键值元素,再取出该迭代器的second成员,即value,++后会在原来次数的基础上+1;即operator[]返回对应的映射对象(value)的引用,对它++。
并且[]还可以用于修改指定key的value值
int main()
{vector<string> s = {"塞尔达","林克","究极手","林克","呀哈哈","塞尔达"};map<string,int> cntMap;//统计每个字符串所出现的次数for(const auto& i : s)//遍历数组{cntMap[i]++;}cntMap["林克"] = 114;for(const auto& i : cntMap)//遍历mapcout << i.first << " " << i.second << endl;return 0;
}输出结果:

因此,operator[][有三层作用
- 插入
- 查找k对应的映射对象(value)
- 修改k对应的映射对象(value)
cntMap["加农多夫"];//插入
cntMap["加农多夫"] = 1;//修改
cout << cntMap["加农多夫"] << endl;//查找
cntMap["野兽先辈"] = 514;//插入+修改一般不会用[]去查找,因为如果key不在会插入数据
multiset和multimap
前面说过,搜索树的key都是唯一的,不允许有重复,但multiset和multimap允许重复,它们都包含在map/set的头文件中
它们的用法和各自的map/set几乎完全一样
int main()
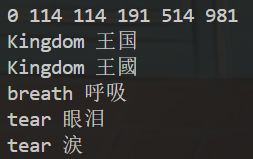
{multiset<int> s;//与set唯一的区别就是允许键值冗余s.insert(114);s.insert(514);s.insert(191);s.insert(981);s.insert(0);s.insert(114);//可以有重复的key插入for(const auto& i : s)cout << i << " ";cout << endl;multimap<string,string> m;//与set唯一的区别就是允许键值冗余m.insert(make_pair("Kingdom","王国"));m.insert(make_pair("breath","呼吸"));m.insert(make_pair("tear","眼泪"));m.insert(make_pair("tear","涙"));//可以有重复的key插入m.insert(make_pair("Kingdom","王國"));for(const auto& i : m)cout << i.first << " " << i.second << endl;return 0;
}输出结果:
有一个不同的地方是multiset/multimap的find
int main()
{multiset<int> s;s.insert(114);s.insert(514);s.insert(191);s.insert(981);s.insert(0);s.insert(114);//可以有重复的key插入s.insert(114);for(const auto& i : s)cout << i << " ";cout << endl;multiset<int>::iterator it = s.find(114);//找到的是按顺序的第一个114while(it != s.end()){cout << *it << " ";*it++;}return 0;
}输出结果:
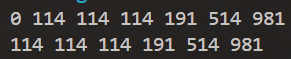
若查找的数据有多个重复值,那find找到的是按顺序时的第一个114
multimap也同理
不过multimap的insert的返回值不是pair,而是iterator,因为multimap不可能插入失败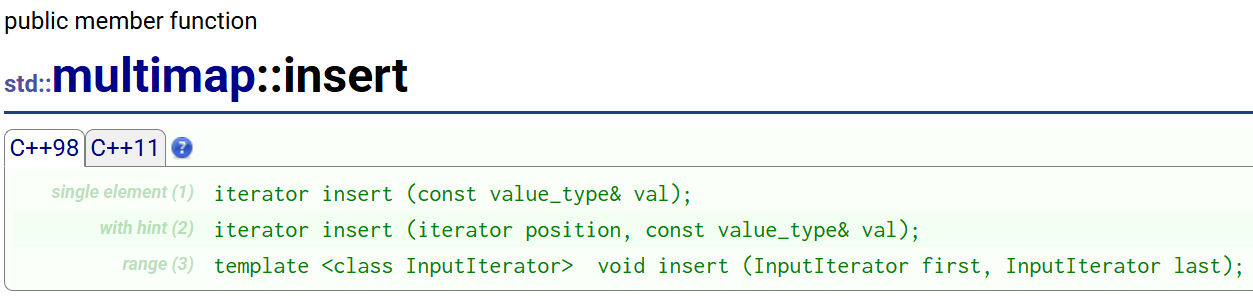
而且因为multimap可能有多个重复的键值,如果用[]就不知道应该返回那个value,所以也不支持operator[]
int main()
{multimap<string,string> dict;dict.insert(make_pair("apex","巅峰"));dict.insert(make_pair("apex","顶点"));dict.insert(make_pair("pull","拉"));dict.insert(make_pair("push","推"));dict["apex"] = "Apex英雄";//这里会报错return 0;
}报错: